EECS 349 (Machine Learning) Homework 4, Fall 2011. 2. Submit this .zip file via blackboard. DUE...
5
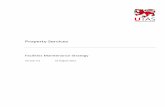
EECS 349 (Machine Learning) Homework 4, Fall 2011 WHAT TO HAND IN You are to submit the following things for this homework: 1. A PDF document containing answers to the homework questions….unless you’ve used code to solve any problems, then show your work by including the source files and make the submission a .zip containing the .pdf and source code. HOW TO HAND IT IN To submit your homework: 1. Name the file in the following manner, firstname_lastname_hw4.zip. For example, Bryan_Pardo_hw4.zip. 2. Submit this .zip file via blackboard. DUE DATE: the start of class on Wed, Nov 30, 2011 Dow n Up Sam e 0.3 0.2 0.5 Same 0.3 0.2 0.5 Up 0.3 0.2 0.5 Down Same Up Down Transition Probability (A) 0.6 0.2 0.2 Same 0.2 0.3 0.5 Up 0.4 0.5 0.1 Down Tea OJ Coffee Observation Probability (B) 0.4 0.3 0.3 Same Up Down Starting Probability (π ) 0.1 0.3 0.6 Same 0.2 0.2 0.6 Up 0.5 0.3 0.2 Down Same Up Down Transition Probability (A) 0.7 0.1 0.2 Same 0.1 0.3 0.6 Up 0.3 0.6 0.1 Down Tea OJ Coffee Observation Probability (B) 0.2 0.3 0.5 Same Up Down Starting Probability (π ) Model 1 Model 2 end state end state observation observation
Transcript of EECS 349 (Machine Learning) Homework 4, Fall 2011. 2. Submit this .zip file via blackboard. DUE...

EECS 349 (Machine Learning) Homework 4, Fall 2011
WHAT TO HAND IN You are to submit the following things for this homework:
1. A PDF document containing answers to the homework questions….unless you’ve used code to solve any problems, then show your work by including the source files and make the submission a .zip containing the .pdf and source code.
HOW TO HAND IT IN To submit your homework:
1. Name the file in the following manner, firstname_lastname_hw4.zip. For example, Bryan_Pardo_hw4.zip.
2. Submit this .zip file via blackboard.
DUE DATE: the start of class on Wed, Nov 30, 2011
Down
Up
Same
0.3 0.2 0.5 Same
0.3 0.2 0.5 Up
0.3 0.2 0.5 Down
Same Up Down
Transition Probability (A)
0.6 0.2 0.2 Same
0.2 0.3 0.5 Up
0.4 0.5 0.1 Down
Tea OJ Coffee
Observation Probability (B)
0.4 0.3 0.3
Same Up Down
Starting Probability (π)
0.1 0.3 0.6 Same
0.2 0.2 0.6 Up
0.5 0.3 0.2 Down
Same Up Down
Transition Probability (A)
0.7 0.1 0.2 Same
0.1 0.3 0.6 Up
0.3 0.6 0.1 Down
Tea OJ Coffee
Observation Probability (B)
0.2 0.3 0.5
Same Up Down
Starting Probability (π)
Model 1 Model 2
end state end state
observation observation

EECS 349 (Machine Learning) Homework 4, Fall 2011
The figure on the previous page shows two hidden Markov models for IBM’s stock price. For both models, each hidden state indicates the difference between the IBM’s starting value and ending value for a single day. Thus, “Down” means it was a day where the stock decreased. *NOTE* For the transition probability table, rows indicate starting states and columns indicate ending states. Every morning, the president of IBM orders a drink on the way to work. Sometimes it is tea, sometimes coffee, sometimes orange juice (OJ). Over time both hidden Markov models were built by observing his morning drink purchase and then correlating them with the actual performance of IBM’s stock.
Observation Sequence 1: {Coffee, Coffee, Coffee, Tea, Tea}
Observation Sequence 2: {OJ, Coffee, Tea, Coffee, Coffee}
Observation Sequence 3: {Tea, Coffee, Tea, Coffee, Tea, Coffee } Problem 1 (1 point): Assume you have witnessed Observation Sequence 1 and Observation Sequence 2. Determine whether Model 1 or Model 2 is the more likely of the two models (assume the prior probability of each model is 0.5). Explain your reasoning and show your calculations. What is the name of the algorithm you used to calculate your results? Problem 2 (1 point): Give two approaches to modeling state duration for HMMs. Compare their strengths and weaknesses. (Hint: read the Rabiner paper on the course website)
Problem 3 (1 point): Go to the course website calendar and download the paper assigned as reading for Nov 14 by clicking on the link “TD Gammon paper.” Read the paper and answer the following questions.
A) (1/2 point) Why is brute-force search not feasible as a way to program computers to play backgammon?
B) (1/2 point) Why do they use the learning rule described in this paper instead of the standard back propagation of error algorithm typically used for neural networks?
r = 0 r = 0
r = 0 r = -10
r = 0 r = 0
r = 50
r = 0
r = 0
A
B
C
1 2 3
Adventure 1 = {C1, B1, B2} Adventure 2 = {C1, B1, A1, A2, A3} Adventure 3 = {C1, C2, B2} Adventure 4 = {C1, C2, C3, B3, A3} Adventure 5 = {C1, C2, C3, B3, B2}
MINI Wumpus World

EECS 349 (Machine Learning) Homework 4, Fall 2011
The mini Wumpus world is shown above. In this world, you always start in state C1. Thereafter, you may move horizontally or vertically (not diagonally) to any adjacent state. Thus, the set of moves are U,D,L,R (standing for up, down, left and right). Moves outside the world are impossible. For a state such as C1, there are only 2 possible moves: U and R. An adventure ends when you either encounter the Wumpus (a little red dragon) or find the pot of gold. Here, the immediate reward for being in any one state is shown to you. You also have the history of locations recorded for our hero on five adventures in the mini Wumpus world. Problem 4 (2 points): A) (1 point) Given the mini Wumpus world and the five adventures (shown above), approximate the Q-function for each allowed state-action pair and show the Q-function in a table. The algorithm for this is in Table 13.1 of the textbook. Show your work. If you wrote a computer script to do the work, submit the source code in a zip file with the answers to these questions. Code should be commented and a readme should explain how to use it. If you did it by hand, show the steps. Assume your learning rate g = 0.5 and process the adventures in ascending order: Adventure 1, then Adventure 2 and so on. B) (1 point) Give the value of the policy function for each state, given the Q-function approximation you learned in part A.
Problem 5 (1 point)
A) (1/2 point) Explain the concepts of eager learning and lazy learning methods. Give several examples for both methods.
B) (1/2 points) What are the pros and cons of lazy learning methods?
Problem 6 (2 points) This question contrasts an eager learning method (linear regression) and a lazy learning method (locally weighted regression) to help you understand their relationships and differences.
Let us consider a 1-d regression problem, where we have n prior instances (xi, yi ) where x is the
input and y is the output. We want to predict ! for a new query input !. In linear regression, we model the data by a linear function
! = !" + !
Here, the ‘^’ indicates an estimate of the true y. We can rewrite this function as
! = !!!
where ! = (!, 1)!, ! = (!, !)! are column vectors. We learn ! by minimizing the fitting error over all training data. The error is usually defined as

EECS 349 (Machine Learning) Homework 4, Fall 2011
!(!) =12
(!! − !!)!!
!!!
=12
(!! − !!!!)!!
!!!
=12(! − !")!(! − !")
where ! is a column vector with elements !!, ! is a matrix with rows !!!, i.e. (!! , 1).
By taking derivative w.r.t. ! and setting the derivative to zero, we can calculate ! as:
! = (!!!)!!!!!
Now consider using locally weighted (linear) regression instead to solve this problem. We will perform a linear regression around the new input point !, using weighted training data according to their distance to !. To do this, remember from lecture that we want to minimize the following error function
E(! ) = 12
k(i)(i=1
N
! yi " yi )2 =12
k(i)(i=1
N
! yi " ziT! )2
where k(i) is the kernel function, which models the "influence" of the ith training point on the estimate of the output y for some new query input !. For example, it can be defined as
!(!) = !"#{−(!! − !)!
2!!}
A) (1/2 point) First prove that !(!) in locally weighted linear regression can be written as !!(! − !")!!(! − !") with an appropriate diagonal matrix !.
B) (1/2 point) Now, for locally weighted linear regression, find the derivative of !(!) with respect to ! and set it to zero to get a closed-form equation for !, using !, ! and !. (Hint: this is similar to the derivation in calculating ! in linear regression)
C) (1 point) Explain why locally weighted regression is a lazy learning method that can only run when we know what the query x is. (Hint: think about how you would calculate y for some new query point x)

EECS 349 (Machine Learning) Homework 4, Fall 2011
Problem 7 (2 points). The Baysian Belief Network topology below reflects "causal" knowledge: A burglar can set the alarm off. An earthquake can set the alarm off. The alarm can cause Mary to call. The alarm can cause John to call.
A) (1 point) Calculate the P(Burglary=True | JohnCalls=True, MaryCalls = True) using the network. Show your work. B) (1/2 point) The shape of a Bayesian Belief Network is a design choice. Redesign the network above to be a Naïve Bayesian Classifer. Draw your redesigned network. Say how many values each variable can take. You don’t need to determine the probabilities in your table. C) (1/2 point) Explain the design choices you made in B). Explain why you would or wouldn’t choose to use this network in the place of the one given for this problem.