
Edouard Duchesnay - unicog.org Duchesnay CEA, I2BM, NeuroSpin ... From condition to image using mass...
38
1 E. Duchesnay, I 2 BM/NeuroSpin NeuroSpin, 10 Jan. 2010 Feature selection in neuroimaging Edouard Duchesnay CEA, I 2 BM, NeuroSpin, LNAO France
Transcript of Edouard Duchesnay - unicog.org Duchesnay CEA, I2BM, NeuroSpin ... From condition to image using mass...

1E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Feature selection in neuroimaging
Edouard Duchesnay
CEA, I2BM, NeuroSpin, LNAOFrance

2E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Outline
• Classification principles in neuroimaging
• Overfitting or curse of dimensionality
• Dimension reduction
• Unsupervised dimension reduction
• Supervised dimension reduction: feature selection
– Filters
– Wrappers
– Embedded
– FS as regularization
• Dimension selection
• Validation

3E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Outline
• Classification principles in neuroimaging
• Overfitting or curse of dimensionality
• Dimension reduction
• Unsupervised dimension reduction
• Supervised dimension reduction: feature selection
– Filters
– Wrappers
– Embedded
– FS as regularization
• Dimension selection
• Validation

4E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Approaches: Mass univariate / MultivariateFrom condition to image using mass univariate analysis
1 voxelsignal
f (target) =
From image to condition using multivariate analysis
f( ) = target (subject informations ex.: group, sex, age, )
Describe signal by condition: stimuli, mental states, disease, etc.Answer the question: where are the differences ?At a group level
Reverse this operation: infer condition from signal
Individual analysis (classification)Computer aided diagnosis-“Black box”+Network of abnormalities (biomarkers)

5E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
From image to target(s) using multivariate analysis
f( ) = target (subject informations ex.: group, sex, age, )
Reverse the previous analysis infer target from signal
Multivariate:
•Two approaches :●Classification : predict group label (ex. patient or control)●Regression : predict quantitative value (ex. motor score)

6E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Classification : principles
Space of the brain features (multivariate)
Cross-validation: -Predict unseen (test) image: or-Compare predicted label with true target
?
Given a training data set : pairsof (features, label), learn the characteristic of each category in the feature space:
-In this case predicted = true
-Repeat for all samples-Average

7E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Linear methods
weight 1 weight 2 ... ... weight Pweight 0
feat. 1 feat. 2 ... ... feat. P* * * * *
+ + + + +
Prediction rule of linear discriminant classifier (combine features):
Learn: How to learn w the weight vector such:
~n
p
wX
1
p
×n
1
Train data (images)
p number of features ~ 105
n number of samples ~ 100
Y
Find w that minimize a prediction erroron training data:
True value Predicted value
= predictedtarget
True targetPredicted target

8E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Outline
• Classification principles in neuroimaging
• Overfitting or curse of dimensionality
• Dimension reduction
• Unsupervised dimension reduction
• Supervised dimension reduction: feature selection
– Filters
– Wrappers
– Embedded
– FS as regularization
• Dimension selection
• Validation
9E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
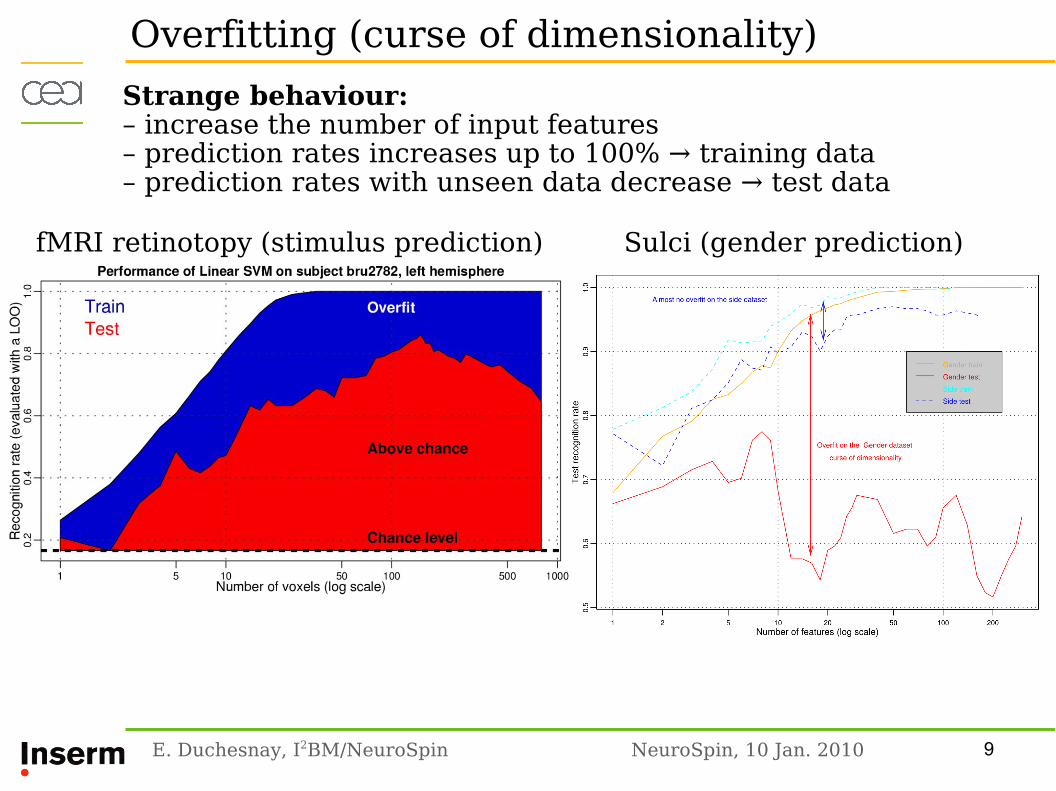
fMRI retinotopy (stimulus prediction) Sulci (gender prediction)
Overfitting (curse of dimensionality)
Strange behaviour:– increase the number of input features– prediction rates increases up to 100% → training data– prediction rates with unseen data decrease → test data

10E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Poor estimation of the parameters→ Wrong decision surface
– Multivariate → high dimensional space ~thousands of voxels– But only less than ~100 samples
Overfitting (curse of dimensionality)

11E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
1D => 2 subjects2D => 4 subjects
3D => 8 subjects
Problem: overfitting (curse of dimensionality)
?
Data size
Parameters size(var./covar. mat.)
N
D
N: # of samples, D: # of features, D>>N– general situation: N>100, D>1000
Sampling density collapse (it is proportional to: N1/D )– To keep the same sampling density, N must be raised to the D
→ Keep N ~ D→ dimension reduction
Poor estimation of the parameter

12E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Outline
• Classification principles in neuroimaging
• Overfitting or curse of dimensionality
• Dimension reduction
• Unsupervised dimension reduction
• Supervised dimension reduction: feature selection
– Filters
– Wrappers
– Embedded
– FS as regularization
• Dimension selection
• Validation

13E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Dealing with high dimensional data
Dimension reductionDimension reduction
X
X
ClassificationRegularization
ClassificationRegularization
D features
N samples
Two way to deal withHigh dimensional data

14E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Dimension reduction
Supervised (goal driven)→ Feature selection- Maximum image/targetcovariance
Supervised (goal driven)→ Feature selection- Maximum image/targetcovariance
Unsupervised (data driven)- Maximum image variability
Unsupervised (data driven)- Maximum image variability
Dimension reduction- Look for low dimensional image representation
Dimension reduction- Look for low dimensional image representation
Linear(Max var.)- PCA- ICA
Linear(Max var.)- PCA- ICA
Non linear(Manifold learning)- Isomap- LLE- Kernel PCA
Non linear(Manifold learning)- Isomap- LLE- Kernel PCA
Univariate- Filters (GLM)
“Voxel based analysis”“Genome Wide Assoc. Studies”
Univariate- Filters (GLM)
“Voxel based analysis”“Genome Wide Assoc. Studies”
Multivariate- Wrapper- Embedded
Multivariate- Wrapper- Embedded

15E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Outline
• Classification principles in neuroimaging
• Overfitting or curse of dimensionality
• Dimension reduction
• Unsupervised dimension reduction
• Supervised dimension reduction: feature selection
– Filters
– Wrappers
– Embedded
– FS as regularization
• Dimension selection
• Validation

16E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Linear unsupervised dimension reduction
Supervised (goal driven)→ Feature selection- Maximum image/targetcovariance
Supervised (goal driven)→ Feature selection- Maximum image/targetcovariance
Unsupervised (data driven)- Maximum image variability
Unsupervised (data driven)- Maximum image variability
Dimension reduction- Look for low dimensional image representation
Dimension reduction- Look for low dimensional image representation
Linear(Max var.)- PCA- ICA
Linear(Max var.)- PCA- ICA
Non linear(Manifold learning)- Isomap- LLE- Kernel PCA
Non linear(Manifold learning)- Isomap- LLE- Kernel PCA
Univariate- Filters (GLM)
“Voxel based analysis”“Genome Wide Assoc. Studies”
Univariate- Filters (GLM)
“Voxel based analysis”“Genome Wide Assoc. Studies”
Multivariate- Wrapper- Embedded
Multivariate- Wrapper- Embedded

17E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Linear unsupervised dimension reduction
Linear methods
→ Find a new base → Maximize image variability→ “Orthogonal” base
– PCA– ICA

18E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Non linear unsupervised dimension reduction
Supervised (goal driven)→ Feature selection- Maximum image/targetcovariance
Supervised (goal driven)→ Feature selection- Maximum image/targetcovariance
Unsupervised (data driven)- Maximum image variability
Unsupervised (data driven)- Maximum image variability
Dimension reduction- Look for low dimensional image representation
Dimension reduction- Look for low dimensional image representation
Linear(Max var.)- PCA- ICA
Linear(Max var.)- PCA- ICA
Non linear(Manifold learning)- Isomap- LLE- Kernel PCA
Non linear(Manifold learning)- Isomap- LLE- Kernel PCA
Univariate- Filters (GLM)
“Voxel based analysis”“Genome Wide Assoc. Studies”
Univariate- Filters (GLM)
“Voxel based analysis”“Genome Wide Assoc. Studies”
Multivariate- Wrapper- Embedded
Multivariate- Wrapper- Embedded

19E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
→ Eigen methods
→ Problems:- Not enough samples to reliably detect the structure embedded within the data- Variability of interest may be orthogonalto maximum variability
→ Eigen methods
→ Problems:- Not enough samples to reliably detect the structure embedded within the data- Variability of interest may be orthogonalto maximum variability
Manifolds learningLook for mapping to a low dimensional space– Isomap [Tenenbaum00]– LLE [Roweis00]– Kernel PCA [Schölkopf99]
Manifolds learningLook for mapping to a low dimensional space– Isomap [Tenenbaum00]– LLE [Roweis00]– Kernel PCA [Schölkopf99]
→ Eigen methods
→ Problems:- Not enough samples to reliably detect the structure embedded within the data- Variability of interest may be orthogonalto maximum variability
→ Eigen methods
→ Problems:- Not enough samples to reliably detect the structure embedded within the data- Variability of interest may be orthogonalto maximum variability
→ Eigen methods
→ Problems:- Not enough samples to reliably detect the structure embedded within the data- Variability of interest may be orthogonalto maximum variability
→ Eigen methods
→ Problems:- Not enough samples to reliably detect the structure embedded within the data- Variability of interest may be orthogonalto maximum variability
?
Non linear unsupervised dimension reduction

20E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Dimension reduction supervised vs unsupervised
Supervised (goal driven)- Maximum image/targetcovariance
Supervised (goal driven)- Maximum image/targetcovariance
Unsupervised (data driven)- Maximum image variability
Unsupervised (data driven)- Maximum image variability
Dimension reduction- Look for low dimensional image representation
Dimension reduction- Look for low dimensional image representation

21E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Outline
• Classification principles in neuroimaging
• Overfitting or curse of dimensionality
• Dimension reduction
• Unsupervised dimension reduction
• Supervised dimension reduction: feature selection
– Filters
– Wrappers
– Embedded
– FS as regularization
• Dimension selection
• Validation

22E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Non linear unsupervised dimension reduction
Supervised (goal driven)→ Feature selection- Maximum image/targetcovariance
Supervised (goal driven)→ Feature selection- Maximum image/targetcovariance
Unsupervised (data driven)- Maximum image variability
Unsupervised (data driven)- Maximum image variability
Dimension reduction- Look for low dimensional image representation
Dimension reduction- Look for low dimensional image representation
Linear(Max var.)- PCA- ICA
Linear(Max var.)- PCA- ICA
Non linear(Manifold learning)- Isomap- LLE- Kernel PCA
Non linear(Manifold learning)- Isomap- LLE- Kernel PCA
Univariate- Filters (GLM)
“Voxel based analysis”“Genome Wide Assoc. Studies”
Univariate- Filters (GLM)
“Voxel based analysis”“Genome Wide Assoc. Studies”
Multivariate- Wrapper- Embedded
Multivariate- Wrapper- Embedded

23E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Univariate feature selection
Filters – Pre-processing– Rank features independently of the final predictors– Generally assimilated to mass-univariate feature ranking
* Parametric: t-test, Anova, → GLM* Non parametric: Wilcoxon, ROC, Gini impurity
– Voxel Based Analysis like methods (VBM etc.)– Genome Wide Association Analysis (GWAS)
Provide a first insight of the problem complexity(+ ) Robust to overfitting( – ) But they are blind to discriminant combination of features
How many best ranked features ?– Multiple comparison issues

24E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Univariate “filter” (t-test, Wilcoxon test, etc.)
Univariate feature selection
SimpleProblem:
Peak at smallp-values
ComplexProblem
Flat histo.

25E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Non linear unsupervised dimension reduction
Supervised (goal driven)→ Feature selection- Maximum image/targetcovariance
Supervised (goal driven)→ Feature selection- Maximum image/targetcovariance
Unsupervised (data driven)- Maximum image variability
Unsupervised (data driven)- Maximum image variability
Dimension reduction- Look for low dimensional image representation
Dimension reduction- Look for low dimensional image representation
Linear(Max var.)- PCA- ICA
Linear(Max var.)- PCA- ICA
Non linear(Manifold learning)- Isomap- LLE- Kernel PCA
Non linear(Manifold learning)- Isomap- LLE- Kernel PCA
Univariate- Filters (GLM)
“Voxel based analysis”“Genome Wide Assoc. Studies”
Univariate- Filters (GLM)
“Voxel based analysis”“Genome Wide Assoc. Studies”
Multivariate- Wrapper- Embedded
Multivariate- Wrapper- Embedded

26E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Wrappers (1) principles
Wrappers – Greedy strategy of forward/backward/hybrid feature selection– Stepwise like methods– Optimize an objective function
Provide a first insight of the problem complexity( – ) Prone to overfit local minima(+ ) Detect discriminant features combination
Forward selectionWhile available_features is not empty
– f = arg max objective_function(f+active_features)– active_features = active_features + f– available_features = available_features - f

27E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Output: sets of features subset of increasing size (from 1 to D)
Parametric classifier (LDA)– Pillai-Bartlett trace: (V total variance, B between variance)
SVM– Use bounds of probability of classification error on a test set:
– #Support Vectors (SVs) – Margin bound– Radius margin bound
In all case: cross-validation on train dataset
Objective function– tightly linked with the final classifier
Wrappers (2) objective function

28E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Output: sets of features subset of increasing size (from 1 to D)
– Not a preprocessing step– Plug the feature selection within the learning of the prediction function– Iterative procedure
Multivariate feature selection: embeded
[Guyon03] JMLR Special Issue on Variable and Feature Selection[Guyon06] Springer book Feature extraction
RFEWhile D > 0
– w ← Fit predictor(XD,y)– Rank features according to weight vector w– select D' best ranked features – Reduce dataset to D' best ranked feature: XD = XD'
(typically D' = 0.9*D)
Example: Recursive Feature Elimination (RFE) [Guyon02]– Generally known as SVM-RFE– But can work with any linear predictor that produces a Projection vector w

29E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Feature selection as regularization
Dimension reductionDimension reduction
X
X
ClassifierRegularizationForce small w
ClassifierRegularizationForce small w
D features
N samplesX
ClassifierL1 Regularization
=Feature selection
ClassifierL1 Regularization
=Feature selection
D features

30E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
L2 penalization (q=2) → Ridge– Small |β|
2 → reduce covariance effects
– Ridge regression– Bayesian prior on β
L1 penalization (q=1) → Shrinkage
– Small |β|1 → disable some features
– Lasso [Tibshirani96, Efron04]
L1+L2 combine Ridge + shrinkage– elasticnet [Zou05]
Fit the data:Find β that minimize errors on y
i's Penalize β
Feature selection as regularization

31E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Benchmark some methodsData: 10 independent informative features + 2 mutually informative features + 2000 noisy features

32E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Outline
• Classification principles in neuroimaging
• Overfitting or curse of dimensionality
• Dimension reduction
• Unsupervised dimension reduction
• Supervised dimension reduction: feature selection
– Filters
– Wrappers
– Embedded
– FS as regularization
• Dimension selection
• Validation

33E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
ClassificationClassification
Dimension reductionDimension reduction
Dimension selectionDimension selection
The dimension selection problem

34E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Recall, output of previous step:F1: Best featureF2: Best combination of 2 features...FP: Best combination of P features
=> Choose Fi : model selection problem Bias/Variance trade-off, (parsimonious model)
Dimension selection (Model selection)
Estimated generalization = k1 Quality of fit + k
2 Model penalization
(1) Quality Of fit term- Training error- Likelihood
(2) Capacity- Number of parameters- LOO Bounds
(3) Calibrate the trade-off

35E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Dimension selection (Model selection)
Parametric framework:Penalized BIC [1]
[1] Chen, et al, "Clustering via the Bayesian Information Criterion with Applications in Speech Recognition", Proc. ICASSP'98,
Estimate from random permutation:
SVM framework:Training error + k #SVs
k
Global minimum: choose F6
Results on real data k=slope

36E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Put everything together
Dimension reductionDimension reduction
Dimension selectionDimension selection
ClassificationClassification
Choose one framework: parametric or SVM

37E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Outline
• Classification principles in neuroimaging
• Overfitting or curse of dimensionality
• Dimension reduction
• Unsupervised dimension reduction
• Supervised dimension reduction: feature selection
– Filters
– Wrappers
– Embedded
– FS as regularization
• Dimension selection
• Validation

38E. Duchesnay, I2BM/NeuroSpin NeuroSpin, 10 Jan. 2010
Avoid common validation biasFeature selection IS NOT a PREPROCESSING STEPIt must be performed ONLY on TRAIN SAMPLES
Train samples labelsAll samples labels
Train & Classification (predict label)Train & Classification (predict label)
Dimension reduction (feat. sel., etc.)Dimension reduction (feat. sel., etc.)Dimension reduction (feat. sel., etc.)Dimension reduction (feat. sel., etc.)
labels
Test sample label
Train & Classification (predict label)Train & Classification (predict label)
Wrong Correct
Test sample true label
Dimension reduction overfit the dataRecognition rate is optimistically biasedSimilar/worst to false positive in multiple testing
Train samples




![[Product Monograph Template - Standard] - Duchesnay®/Mictoryl® Pediatric Product Monograph Page 2 of 39 Table of Contents Part I: HEALTH PROFESSIONAL INFORMATION 3 SUMMARY PRODUCT](https://static.fdocuments.us/doc/165x107/5afc162a7f8b9a8b4d8bac43/product-monograph-template-standard-duchesnay-pediatric-product-monograph.jpg)









![Ripples of consciousness - unicog.org · Ripples of consciousness Jacobo 1 D. Sitt1,2,3, ... involved, as predicted by previous studies [4]. One ... scale at which information ...Published](https://static.fdocuments.us/doc/165x107/5b238e777f8b9ae4078b48be/ripples-of-consciousness-ripples-of-consciousness-jacobo-1-d-sitt123-.jpg)



