
NoSQL Databases: An Introduction and Comparison between Dynamo, MongoDB and Cassandra
description

1
CassandraCassandrachengxiaojun

2
BackendBackend
• Amazon Dynamo• Facebook Cassandra ( Dynama 2.0 )
– Inbox search• Apache

3
CassandraCassandra
• Dynamo-like features– Symmetric, P2P architecture– Gossip-based cluster management– DHT– Eventual consistency
• Bigtable-like features– Column family – SSTable disk storage
• Commit log• Memtable• Immutable Sstable files

4
Data Model(1/2)Data Model(1/2)
• A table is a distributed multi dimensional map indexed by a key– Keyspace– Column– Super Column– Column Family Types
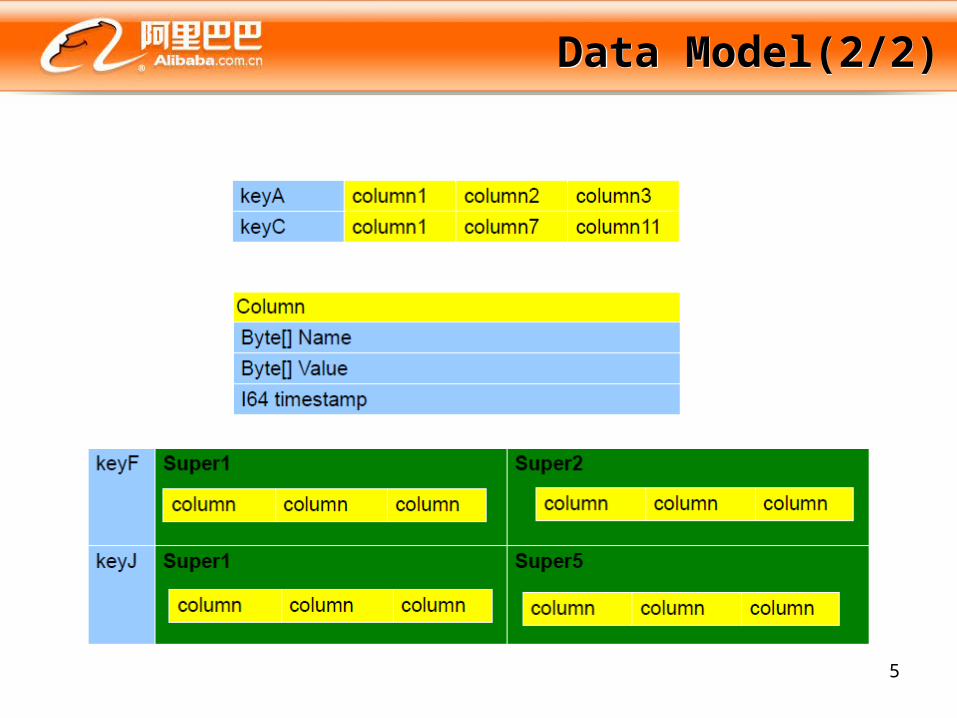
5
Data Model(2/2)Data Model(2/2)

6
APIsAPIs
• Paper:– insert(table; key; rowMutation)– get(table; key; columnName)– delete(table; key; columnName)
• Wiki:– http://wiki.apache.org/cassandra/API
7
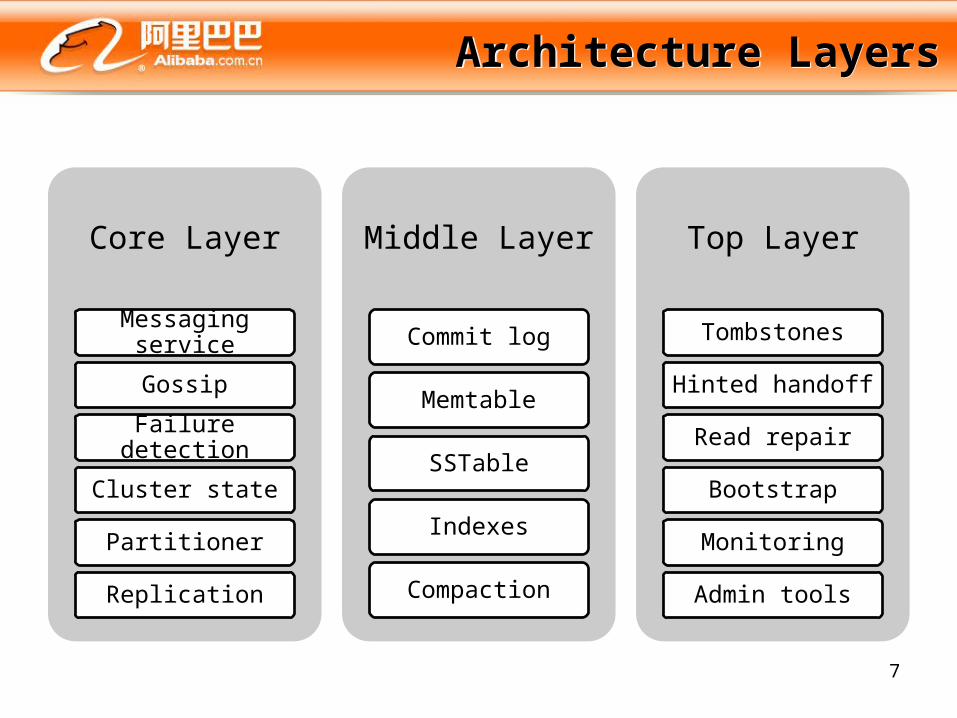
Architecture LayersArchitecture Layers
Core Layer
Messaging service
Gossip
Failure detection
Cluster state
Partitioner
Replication
Middle Layer
Commit log
Memtable
SSTable
Indexes
Compaction
Top Layer
Tombstones
Hinted handoff
Read repair
Bootstrap
Monitoring
Admin tools
8
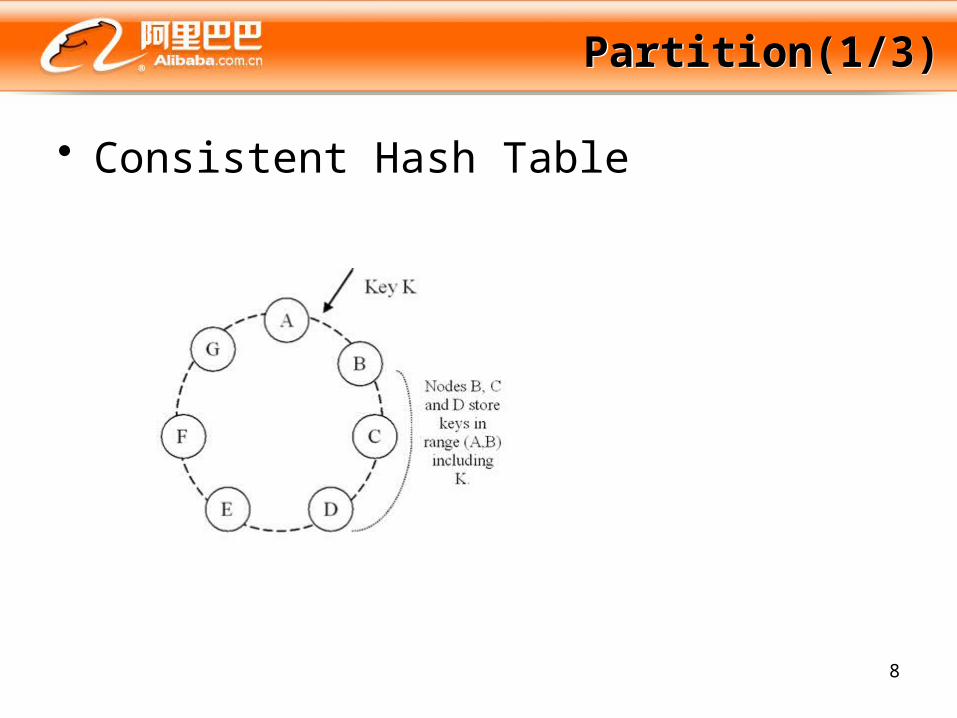
Partition(1/3)Partition(1/3)
• Consistent Hash Table

9
Partition(2/3)Partition(2/3)
• Problems:– the random position assignment of each node on the
ring leads to non-uniform data and load distribution– the basic algorithm is oblivious to the heterogeneity
in the performance of nodes.• Two Ways:
– Dynamo• One node is assigned to multiple positions in the circle
– Cassandra• Analyze load information on the ring and have lightly
loaded nodes move on the ring to alleviate heavily load nodes.

10
Partition(3/3)Partition(3/3)
• Each Cassandra server [node] is assigned a unique Token that determines what keys it is the first replica for.
• Choice– InitialToken: assigned– RandomPartitioner :Tokens are integers from 0 to
2**127. Keys are converted to this range by MD5 hashing for comparison with Tokens.
– NetworkTopologyStrategy:calculate the tokens the nodes in each DC independently. Tokens still needed to be unique, so you can add 1 to the tokens in the 2nd DC, add 2 in the 3rd, and so on.

11
Replication(1/4)Replication(1/4)
• high availability and durability• replication_factor:N

12
Replication(2/4)Replication(2/4)
• Strategy– Rack Unaware– Rack Aware– Datacenter Aware– …

13
Replication(3/4)Replication(3/4)
• Cassandra system elects a leader amongst its nodes using a system called Zookeeper
• All nodes on joining the cluster contact the leader who tells them for what ranges they are replicas for
• The leader makes a concerted effort to maintain the invariant that no node is responsible for more than N-1 ranges in the ring.
• The metadata about the ranges a node is responsible is cached locally at each node and in a fault-tolerant manner inside Zookeeper
• This way a node that crashes and comes back up knows what ranges it was responsible for.

14
Replication(4/4)Replication(4/4)
• Cassandra provides durability guarantees in the presence of node failures and network partitions by relaxing the quorum requirements

15
Data VersioningData Versioning
• Vector clocks

16
ConsistencyConsistency
W + R > N

17
ConsistencyConsistency
• put() :– the coordinator generates the vector clock for the new version and
writes the new version locally. – The coordinator then sends the new version (along with the new
vector clock) to the N highest-ranked reachable nodes. – If at least W-1 nodes respond then the write is considered
successful.• get()
– the coordinator requests all existing versions of data for that key from the N highest-ranked reachable nodes in the preference list for that key, a
– waits for R responses before returning the result to the client. – If the coordinator ends up gathering multiple versions of the data, it
returns all the versions it deems to be causally unrelated. The divergent versions are then reconciled and the reconciled version superseding the current versions is written back.

Handling Temporary FailuresHandling Temporary Failures
• Hinted handoffif node A is temporarily down or unreachable during a write operation then a replica that would normally have lived on A will now be sent to node D.
The replica sent to D will have a hint in its metadata that suggests which node was the intended recipient of the replica (in this caseA).
Nodes that receive hinted replicas will keep them in a separate local database that is scanned periodically. Upon detecting that A has recovered, D will attempt to deliver thereplica to A.
Once the transfer succeeds, D may delete the object from its local store without decreasing the total number of replicas in the system.

Handling permanent failuresHandling permanent failures
• Replica synchronization: anti-entropy– To detect the inconsistencies between replicas faster and to
minimize the amount of transferred data

20
Cassandra Consistency For ReadCassandra Consistency For Read
Level BehaviorANY Not supported. You probably want ONE instead.
ONE
Will return the record returned by the first replica to respond. A consistency check is always done in a background thread to fix any consistency issues when ConsistencyLevel.ONE is used. This means subsequent calls will have correct data even if the initial read gets an older value. (This is called ReadRepair)
QUORUM
Will query all replicas and return the record with the most recent timestamp once it has at least a majority of replicas (N / 2 + 1) reported. Again, the remaining replicas will be checked in the background.
LOCAL_QUORUM
Returns the record with the most recent timestamp once a majority of replicas within the local datacenter have replied.
EACH_QUORUM
Returns the record with the most recent timestamp once a majority of replicas within each datacenter have replied.
ALLWill query all replicas and return the record with the most recent timestamp once all replicas have replied. Any unresponsive replicas will fail the operation.

21
Cassandra Consistency For WriteCassandra Consistency For Write
Level Behavior
ANY Ensure that the write has been written to at least 1 node, including HintedHandoff recipients.
ONE Ensure that the write has been written to at least 1 replica's commit log and memory table before responding to the client.
QUORUM Ensure that the write has been written to N / 2 + 1 replicas before responding to the client.
LOCAL_QUORUM
Ensure that the write has been written to <ReplicationFactor> / 2 + 1 nodes, within the local datacenter (requires NetworkTopologyStrategy)
EACH_QUORUM
Ensure that the write has been written to <ReplicationFactor> / 2 + 1 nodes in each datacenter (requires NetworkTopologyStrategy)
ALL Ensure that the write is written to all N replicas before responding to the client. Any unresponsive replicas will fail the operation.

22
Cassandra Read RepairCassandra Read Repair
• Cassandra repairs data in two ways:– Read Repair: every time a read is performed, Cassandra
compares the versions at each replica (in the background, if a low consistency was requested by the reader to minimize latency), and the newest version is sent to any out-of-date replicas.
– Anti-Entropy: when nodetool repair is run, Cassandra computes a Merkle tree for each range of data on that node, and compares it with the versions on other replicas, to catch any out of sync data that hasn't been read recently. This is intended to be run infrequently (e.g., weekly) since computing the Merkle tree is relatively expensive in disk i/o and CPU, since it scans ALL the data on the machine (but it is is very network efficient).

23
BootstrappingBootstrapping
• New node• Position
– specify an InitialToken– pick a Token that will give it half the keys from the node with the most disk
space used• Note:
– You should wait long enough for all the nodes in your cluster to become aware of the bootstrapping node via gossip before starting another bootstrap
– Relating to point 1, one can only bootstrap N nodes at a time with automatic token picking, where N is the size of the existing cluster.
– As a safety measure, Cassandra does not automatically remove data from nodes that "lose" part of their Token Range to a newly added node.
– When bootstrapping a new node, existing nodes have to divide the key space before beginning replication.
– During bootstrap, a node will drop the Thrift port and will not be accessible from nodetool
– Bootstrap can take many hours when a lot of data is involved

24
Moving or Removing nodesMoving or Removing nodes
• Remove nodes– Live node: nodetool decommission
• the data will stream from the decommissioned node
– Dead node: nodetool removetoken• the data will stream from the remaining replicas
• Mode nodes– nodetool move: decommission + bootstrap
• LB– If you add nodes to your cluster your ring will be unbalanced and
only way to get perfect balance is to compute new tokens for every node and assign them to each node manually by using nodetool move command.

25
MembershipMembership
• Scuttlebutt– Based on Gossip– efficient CPU utilization – efficient utilization of the gossip channel
• anti-entropy Gossip– Paper:Efficient Reconciliation and Flow
Control for Anti-Entropy Protocols

26
Failure DetectionFailure Detection
• The φ Accrual Failure Detector– Idea: the failure detection module doesn't emit
a Boolean value stating a node is up or down. Instead the failure detection module emits a value which represents a suspicion level for each of monitored nodes
27
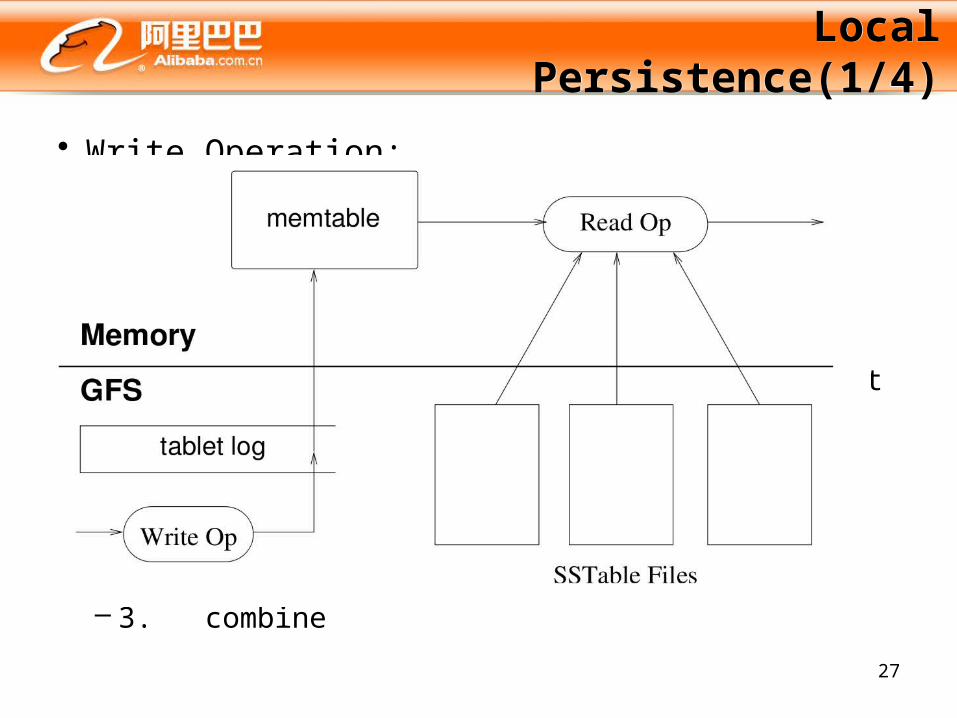
Local Persistence(1/4)Local Persistence(1/4)
• Write Operation:– 1. write into a commit log– 2. an update into an in-memory data structure– 3. When the in-memory data structure crosses a
certain threshold, calculated based on data size and number of objects, it dumps itself to disk
• Read Operation:– 1. query the in-memory data structure– 2. look into the files on disk in the order of newest
to oldest– 3. combine

28
Local Persistence(2/4)Local Persistence(2/4)
• Commit log– all writes into the commit log are sequential– Fixed size – Create/delete– Durability and recoverability

29
Local Persistence(3/4)Local Persistence(3/4)
• Memtable– Per column family– a write-back cache of data rows that can be
looked up by key– sorted by key

30
Local Persistence(4/4)Local Persistence(4/4)
• SStable– Flushing
• Once flushed, SSTable files are immutable; no further writes may be done.
– Compaction• merging multiple old SSTable files into a single new one• Since the input SSTables are all sorted by key, merging can be done
efficiently, still requiring no random i/o.• Once compaction is finished, the old SSTable files may be deleted• Discard tombstones
– index• All writes are sequential to disk and also generate an index for efficient
lookup based on row key. These indices are also persisted along with the data file
• In order to prevent lookups into les that do not contain the key, a bloom filter, summarizing the keys in the le, is also stored in each data le and also kept in memory.
• In order to prevent scanning of every column on disk we maintain column indices which allow us to jump to the right chunk on disk for column retrieval.

31
Facebook inbox searchFacebook inbox search
Column Family : terms_cf
Super Column : term1 Super Column: term2 …
mail1 mail2 mail4 … Mail2 mail3 mail4 …
content1
content2
content4
… content2
content3
content4
Column Family : interaction_cf
Super Column : user1 Super Column: user2 …
mail1 Mail3 mail4 … Mail2 mail3 Mail8 …
content1 Content3
content4 … content2 content3 content8
Key: userN

32
ReferenceReference
• http://s3.amazonaws.com/AllThingsDistributed/sosp/amazon-dynamo-sosp2007.pdf
• http://www.cs.cornell.edu/projects/ladis2009/papers/lakshman-ladis2009.pdf• http://wiki.apache.org/cassandra/FrontPage











![Coupling Decentralized Key-Value Stores with Erasure Codingpclee/www/pubs/socc19.pdf · [10], Dynamo [19], Cassandra [31], and Memcached [8]) distribute data across nodes (or servers1)](https://static.fdocuments.us/doc/165x107/60009a64adb04f73302aa25e/coupling-decentralized-key-value-stores-with-erasure-pcleewwwpubssocc19pdf.jpg)






