
PSG Institute of Technology and Applied Research, Coimbatore
Upload
lorin-gibsonCategory
view
230download
4
Dr. G Sudha SadhasivamProfessor, CSE
PSG College of TechnologyCoimbatore
INTRODUCTION TO HADOOP

Contents
• Distributed System
• DFS
• Hadoop
• Why its is needed?
• Issues
• Mutate / lease

Operating systems• Operating system - Software that supervises
and controls tasks on a computer. Individual OS:– Batch processing jobs are collected, placed in
a queue, no interaction with job during processing– Time shared computing resources are provided
to different users, interaction with program during execution
– RT systems fast response, can be interrupted

Distributed Systems• Consists of a number of computers that are connected and
managed so that they automatically share the job processing load among the constituent computers.
• A distributed operating system is one that appears to its users as a traditional uniprocessor system, even though it is actually composed of multiple processors.
• It gives a single system view to its users and provides a single service.
• Users are transparent to location of files. It provides a virtual computing env.
Eg The Internet, ATM banking networks, mobile computing networks, Global Positioning Systems and Air Traffic Control
DISTRIBUTED SYSTEM IS A COLLECTION OF INDEPENDENT COMPUTERS THAT APPEARS TO IS USERS AS A SINGLE COHERENT SYSTEM

Network Operating System• In a network operating system the users are aware of the existence of multiple computers.• The operating system of individual computers must have facilities to have communication
and functionality.• Each machine runs its own OS and has its own user. • Remote login and file access• Less transparent but more independency
Application
Application
Application
Distributed Operating System Services
Application Application Application
Network OS
Network OS
Network OS
Distributed OS Networked OS

DFS• Resource sharing is the motivation behind distributed
Systems. To share files file system
• File System is responsible for the organization, storage, retrieval, naming, sharing, and protection of files.
• The file system is responsible for controlling access to the data and for performing low-level operations such as buffering frequently used data and issuing disk I/O requests
• The goal is to allow users of physically distributed computers to share data and storage resources by using a common file system.

HadoopWhat is Hadoop?
It's a framework for running applications on large clusters of commodity hardware which produces huge data and to process it
Apache Software Foundation Project Open source Amazon’s EC2 alpha (0.18) release available for download
Hadoop Includes HDFS a distributed filesystem Map/Reduce HDFS implements this programming model. It
is an offline computing engine
ConceptMoving computation is more efficient than moving large data

• Data intensive applications with Petabytes of data.• Web pages - 20+ billion web pages x 20KB = 400+
terabytes – One computer can read 30-35 MB/sec from disk
~four months to read the web– same problem with 1000 machines, < 3 hours
• Difficulty with a large number of machines– communication and coordination– recovering from machine failure– status reporting– debugging– optimization– locality

FACTSSingle-thread performance doesn’t matterWe have large problems and total throughput/price more important
than peak performanceStuff Breaks – more reliability• If you have one server, it may stay up three years (1,000 days)• If you have 10,000 servers, expect to lose ten a day“Ultra-reliable” hardware doesn’t really helpAt large scales, super-fancy reliable hardware still fails, albeit less
often– software still needs to be fault-tolerant– commodity machines without fancy hardware give better
perf/price
DECISION : COMMODITY HARDWARE.
DFS : HADOOP – REASONS?????WHAT SOFTWARE MODEL????????

HDFS Why? Seek vs Transfer• CPU & transfer speed, RAM & disk size double every 18
- 24 months• Seek time nearly constant (~5%/year)• Time to read entire drive is growing vs transfer rate.• Moral: scalable computing must go at transfer rate• BTree (Relational DBS)
– operate at seek rate, log(N) seeks/access-- memory / stream based
• sort/merge flat files (MapReduce)– operate at transfer rate, log(N) transfers/sort
-- Batch based

Characteristics
• Fault tolerant, scalable, Efficient, reliable distributed storage system
• Moving computation to place of data• Single cluster with computation and data.• Process huge amounts of data.• Scalable: store and process petabytes of data.• Economical:
– It distributes the data and processing across clusters of commonly available computers.
– Clusters PCs into a storage and computing platform. – It minimises no of CPU cycles, RAM on individual
machines etc.• Efficient:
– By distributing the data, Hadoop can process it in parallel on the nodes where the data is located. This makes it extremely rapid.
– Computation is moved to place where data is present.• Reliable:
– Hadoop automatically maintains multiple copies of data– Automatically redeploys computing tasks based on failures.

Cluster node runs both DFS and MR

• Data Model– Data is organized into files and directories– Files are divided into uniform sized blocks and
distributed across cluster nodes– Replicate blocks to handle hardware failure– Checksums of data for corruption detection
and recovery– Expose block placement so that computes can
be migrated to data• large streaming reads and small random reads • Facility for multiple clients to append to a file

• Assumes commodity hardware that fails– Files are replicated to handle hardware
failure– Checksums for corruption detection and
recovery– Continues operation as nodes / racks added
/ removed
• Optimized for fast batch processing– Data location exposed to allow computes to
move to data– Stores data in chunks/blocks on every node
in the cluster– Provides VERY high aggregate bandwidth

• Files are broken in to large blocks.
– Typically 128 MB block size
– Blocks are replicated for reliability
– One replica on local node, another replica on a remote rack, Third replica on local rack, Additional replicas are randomly placed
• Understands rack locality
– Data placement exposed so that computation can be migrated to data
• Client talks to both NameNode and DataNodes
– Data is not sent through the namenode, clients access data directly from DataNode
– Throughput of file system scales nearly linearly with the number of nodes.

Block Placement

Hadoop Cluster Architecture:

Components• DFS Master “Namenode”
– Manages the file system namespace– Controls read/write access to files – Manages block replication– Checkpoints namespace and journals
namespace changes for reliability
Metadata of Name node in Memory– The entire metadata is in main memory– No demand paging of FS metadata
Types of Metadata: List of files, file and chunk namespaces; list of
blocks, location of replicas; file attributes etc.

DFS SLAVES or DATA NODES• Serve read/write requests from clients• Perform replication tasks upon instruction by namenodeData nodes act as:1) A Block Server
– Stores data in the local file system – Stores metadata of a block (e.g. CRC)– Serves data and metadata to Clients
2) Block Report: Periodically sends a report of all existing blocks to the NameNode
3) Periodically sends heartbeat to NameNode (detect node failures)
4) Facilitates Pipelining of Data (to other specified DataNodes)

• Map/Reduce Master “Jobtracker”– Accepts MR jobs submitted by users– Assigns Map and Reduce tasks to Tasktrackers– Monitors task and tasktracker status, re
executes tasks upon failure
• Map/Reduce Slaves “Tasktrackers”– Run Map and Reduce tasks upon instruction
from the Jobtracker– Manage storage and transmission of
intermediate output.

SECONDARY NAME NODE
• Copies FsImage and Transaction Log from NameNode to a temporary directory
• Merges FSImage and Transaction Log into a new FSImage in temporary directory
• Uploads new FSImage to the NameNode– Transaction Log on NameNode is purged

HDFS Architecture
• NameNode: filename, offset > block id, block > datanode• DataNode: maps block > local disk• Secondary NameNode: periodically merges edit logsBlock is also called chunk

JOBTRACKER, TASKTACKER AND JOBCLIENT

HDFS API
• Most common file and directory operations supported:
– Create, open, close, read, write, seek, list, delete etc.
• Files are write once and have exclusively one writer
• Some operations peculiar to HDFS:
– set replication, get block locations
• Support for owners, permissions

DATA CORRECTNESS
• Use Checksums to validate data– Use CRC32
• File Creation– Client computes checksum per 512 byte
– DataNode stores the checksum
• File access– Client retrieves the data and checksum from
DataNode
– If Validation fails, Client tries other replicas

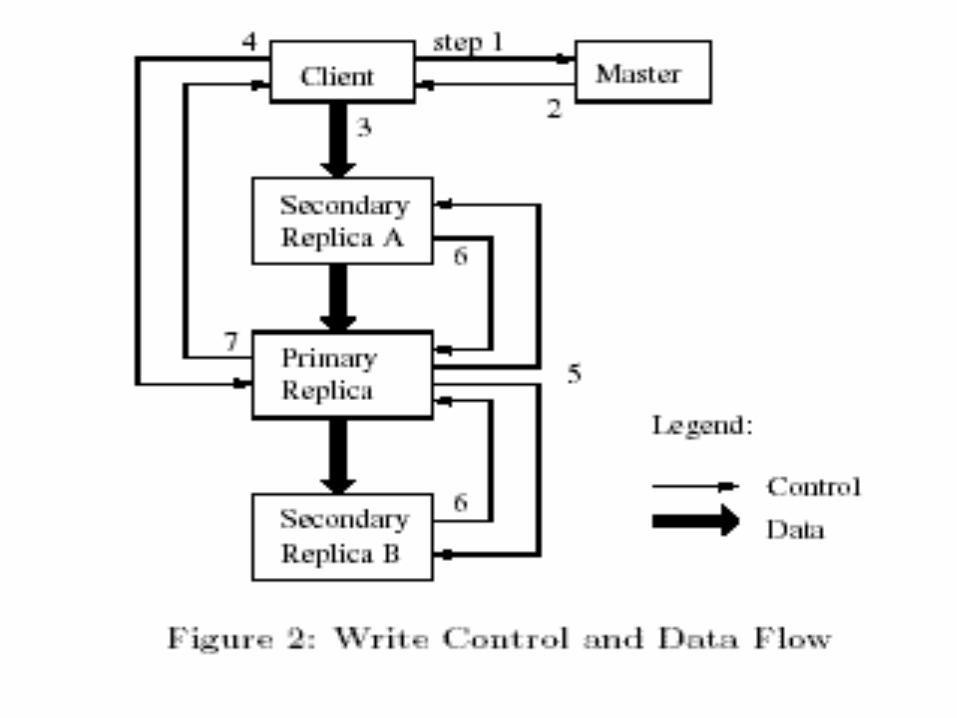
MUTATION ORDER AND LEASES
• A mutation is an operation that changes the contents / metadata of a chunk such as append / write operation.
• Each mutation is performed at all replicas.• Leases (order of mutations) are used to maintain
consistency• Master grants chunk lease to one replica
(primary)• Primary picks the serial order for all mutations to
the chunk• All replicas follow this order (consistency)

Software Model - ???
• Parallel programming improves performance and efficiency.
• In a parallel program, the processing is broken up into parts, each of which can be executed concurrently
• Identify whether the problem can be parallelised (fib)• Matrix operations with independency

Master/Worker
• The MASTER: – initializes the array and splits it up according
to the number of available WORKERS – sends each WORKER its subarray – receives the results from each WORKER
• The WORKER: – receives the subarray from the MASTER – performs processing on the subarray – returns results to MASTER

The area of the square, denoted As = (2r)^2 or 4r^2.
The area of the circle, denoted Ac, is pi * r2.
• pi = Ac / r^2• As = 4r^2• r^2 = As / 4• pi = 4 * Ac / As• pi= 4 * No of pts on
the circle / num of points on the square
CALCULATING PI

• Randomly generate points in the square • Count the number of generated points that are
both in the circle and in the square MAP (find ra = No of pts on the circle / num of points on the square)
• ra = the number of points in the circle divided by the number of points in the square gather all ra
• PI = 4 * r REDUCE
Parallelised calculation of points on the circle (MAP)
Then merged in to find PI REDUCE

Cluster node runs both DFS and MR

WHAT IS MAP REDUCE PROGRAMMING
• Restricted parallel programming model meant for large clusters– User implements Map() and Reduce()
• Parallel computing framework (HDFS lib)– Libraries take care of EVERYTHING else
(abstraction)• Parallelization• Fault Tolerance• Data Distribution• Load Balancing
• Useful model for many practical tasks

Conclusion• Why commodity hw ? because cheaper designed to tolerate faults• Why HDFS ? network bandwidth vs seek latency• Why Map reduce programming model? parallel programming large data sets moving computation to data single compute + data cluster

















