
Download slides - ChemAxon
21
IBM Research 1 © 2011 International Business Machines Corporation 1 IBM Research Source – J Kreulen
Transcript of Download slides - ChemAxon

IBM Research 1 © 2011 International Business Machines Corporation 1
IBM Research
Source – J Kreulen

IBM Research 2 © 2011 International Business Machines Corporation 2
IBM Research
Computer Curation of Patents &
Scientific Literature - (Information Analytical Services )
Transforming Information Into Value
Stephen K Boyer Ph.D.
Collabra, Inc [email protected]
408-858-5544

IBM Research 3 © 2011 International Business Machines Corporation 3
IBM Research
Patents also have (Manually Created) Chemical Complex Work Units (CWU’s)
As text
Chemical names found in the text of
documents
As bitmap images
Pictures of chemicals found in the document
Images
Patents (and scientific papers) contain molecular data in many different forms -
IBM Research 4 © 2011 International Business Machines Corporation 4
IBM Research
4
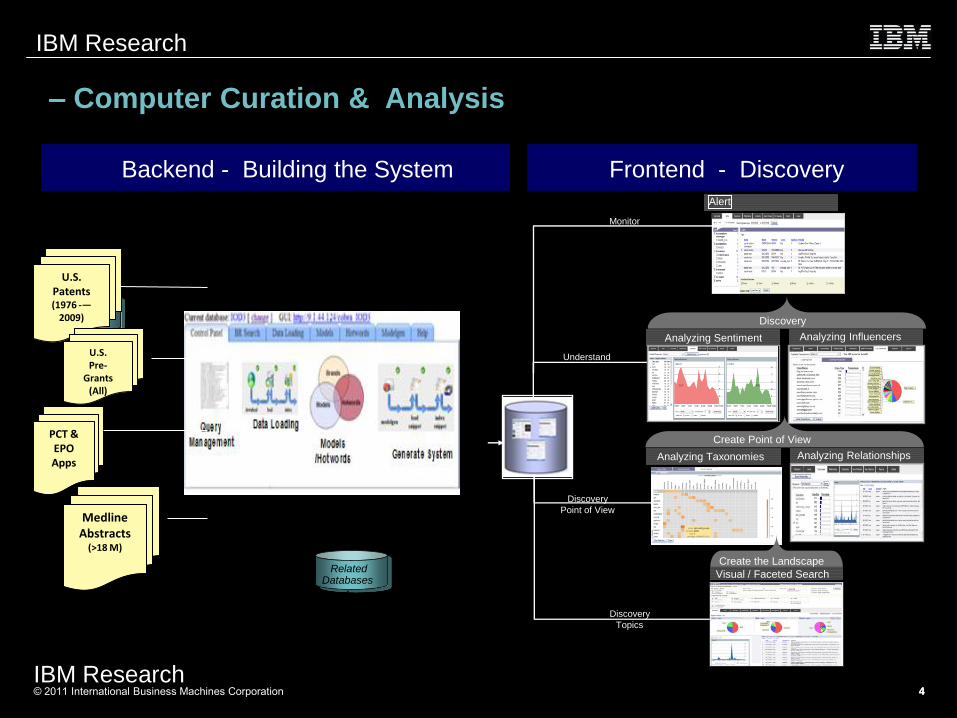
– Computer Curation & Analysis
Alert
Understand
Discovery
Point of View
Analyzing Taxonomies Analyzing Relationships
Create Point of View
Persistence Queries
Related Databases
Analyzing Sentiment Analyzing Influencers
Discovery
Monitor
Discovery
Topics
Visual / Faceted Search
Create the Landscape
Backend - Building the System Frontend - Discovery
Dat
a So
urc
es
U.S. Patents (1976 -—
2009)
U.S. Pre-
Grants (All)
PCT & EPO Apps
Medline Abstracts
(>18 M)
IBM Research 5 © 2011 International Business Machines Corporation 5
IBM Research
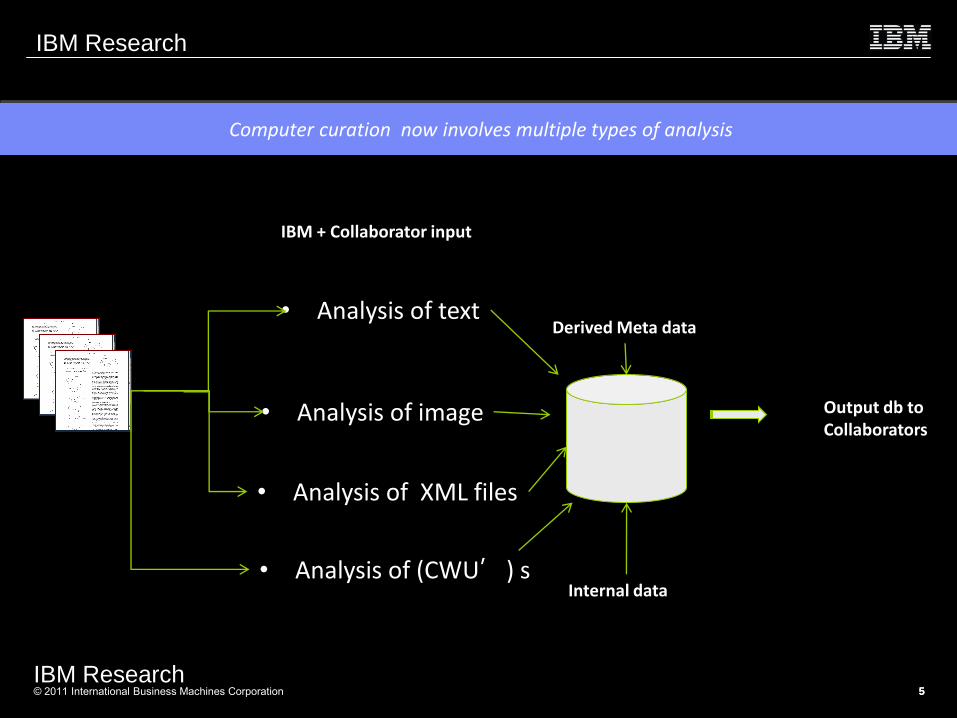
Computer curation now involves multiple types of analysis
• Analysis of text
• Analysis of image
• Analysis of XML files
Derived Meta data
Internal data
IBM + Collaborator input
Output db to Collaborators
• Analysis of (CWU’) s
IBM Research 6 © 2011 International Business Machines Corporation 6
IBM Research
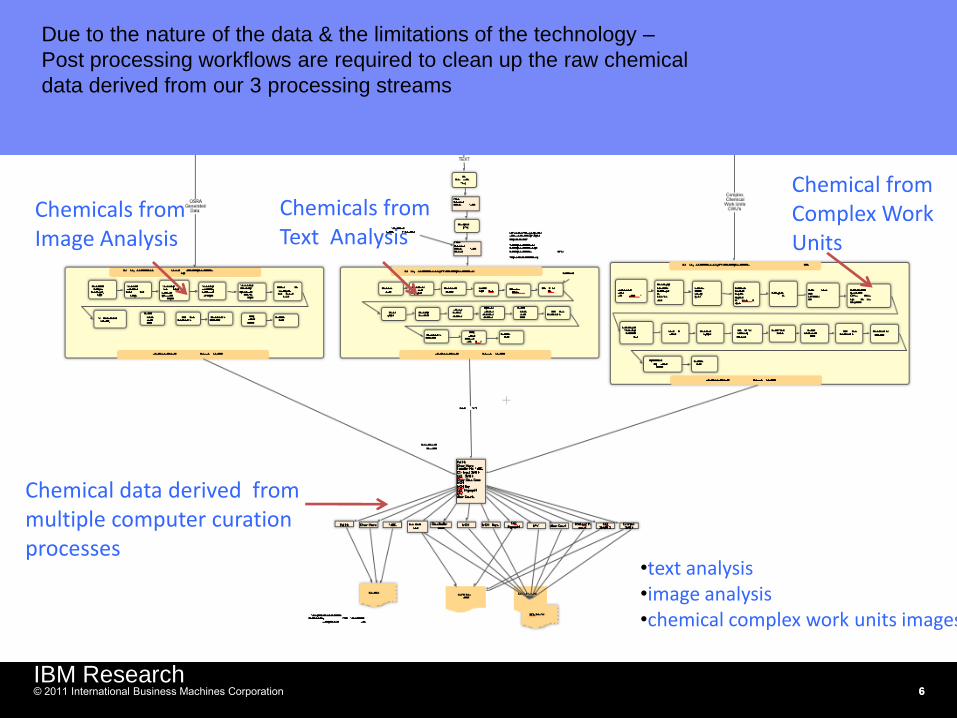
Chemical from Complex Work Units
Chemicals from Image Analysis
Chemicals from Text Analysis
Chemical data derived from multiple computer curation processes
•text analysis •image analysis •chemical complex work units images -
Due to the nature of the data & the limitations of the technology –
Post processing workflows are required to clean up the raw chemical
data derived from our 3 processing streams
IBM Research 7 © 2011 International Business Machines Corporation 7
IBM Research
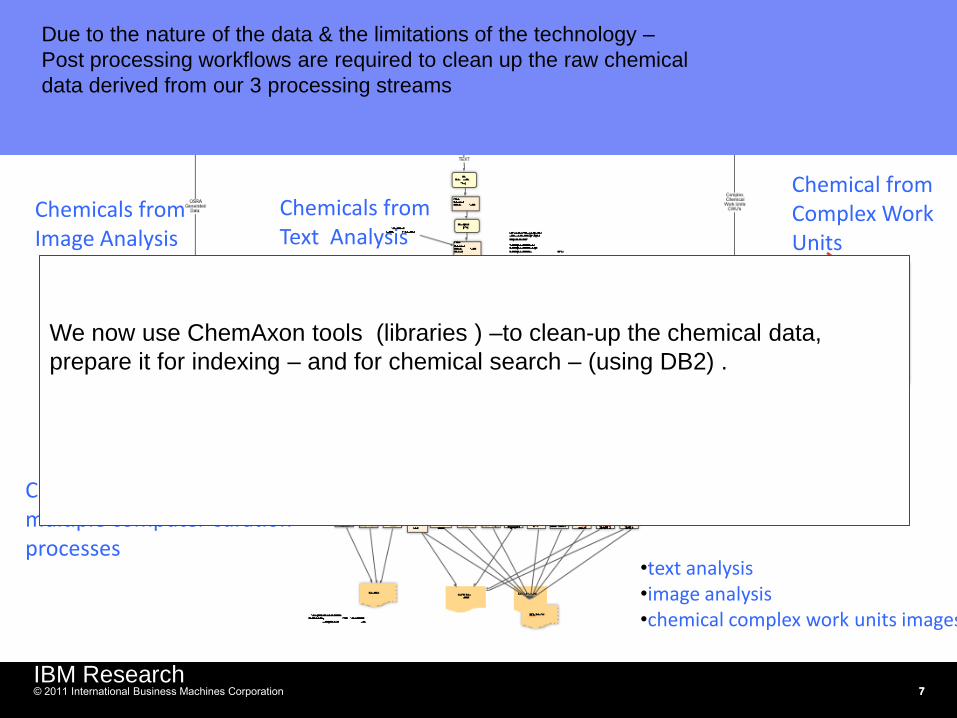
Chemical from Complex Work Units
Chemicals from Image Analysis
Chemicals from Text Analysis
Chemical data derived from multiple computer curation processes
•text analysis •image analysis •chemical complex work units images -
Due to the nature of the data & the limitations of the technology –
Post processing workflows are required to clean up the raw chemical
data derived from our 3 processing streams
We now use ChemAxon tools (libraries ) –to clean-up the chemical data,
prepare it for indexing – and for chemical search – (using DB2) .

IBM Research 8 © 2011 International Business Machines Corporation 8
IBM Research
Dat
a So
urc
es
View selected
Documents & Reports
U.S. Patents (1976 -—
2009)
U.S. Pre-
Grants (All)
PCT & EPO Apps
Medline Abstracts
(>18 M)
Selected Internet Content
User Applications
In-House
Content
Knime or Pipeline Pilot
BIW
SIMPLE
Chem Axon Search
Cognos/DDQB/ Other Apps
Parse & Extract
data
Annotator 1
Annotator 2
Database
+ compu ted Meta Data
e Classifier & Other Data Associations
Annotation Factory
Computational Analytics
ChemVerse (Semantic
Associations)
Computer Curation Process Overview
IP Database (e.g. DB2)
ADU*
* ADU = Automated Data Update
ChemVerse
db
ChemVerse
Services Hosted at IBM Almaden

IBM Research 9 © 2011 International Business Machines Corporation 9
IBM Research
Johnson & Johnson
Novartis
Bristol Myers
Squibb
Merck
By comparing the most relevant
concepts in patent data, we observed
patterns emerging.
Genentech is staking out white space
in the areas not covered by the other
major pharmaceuticals.
Pharmaceutical Industry Patent Landscape
AstraZeneca
Amgen
Total # of
patents
Pfizer
Merck
BMS
Novartis
J&J
AstraZeneca
Amgen
Total # of
patents
Pfizer
Merck
BMS
Novartis
J&J
Looking at US patent data for the last 18
years shows how pharmaceutical
companies are positioning themselves in
the market.
Leading companies like Pfizer,
AstraZeneca, and Amgen are increasing
their patent activity while other companies
are decreasing.
IBM Research 10 © 2011 International Business Machines Corporation 10
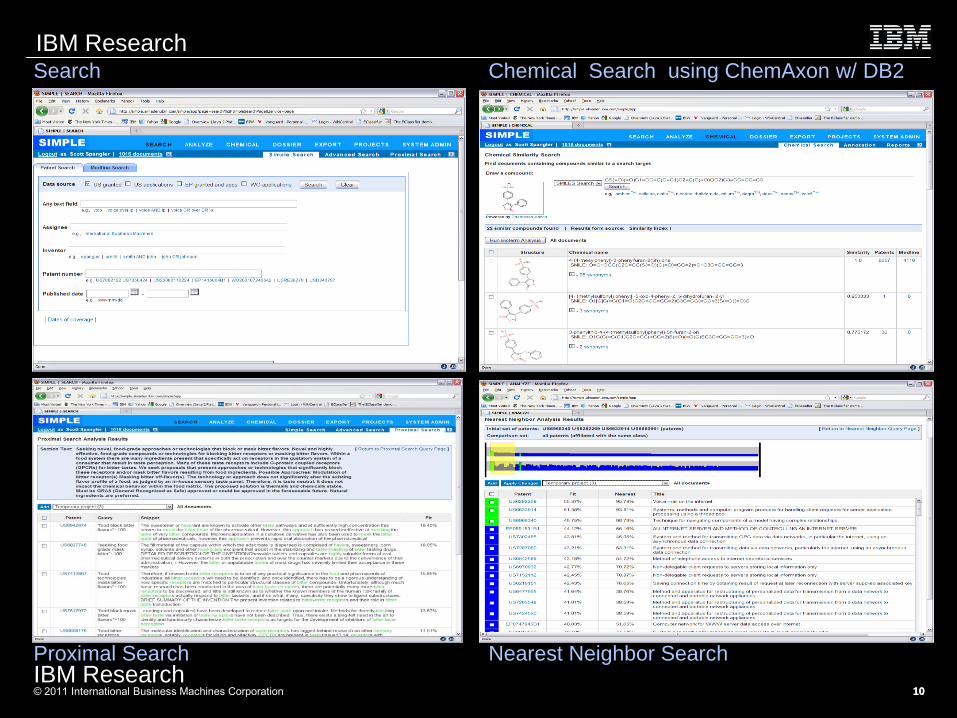
IBM Research Search Chemical Search using ChemAxon w/ DB2
Proximal Search Nearest Neighbor Search

IBM Research 11 © 2011 International Business Machines Corporation 11
IBM Research
BioTerm Analysis
Clustering Claims Originality
Discovery
IBM Research 12 © 2011 International Business Machines Corporation 12
IBM Research
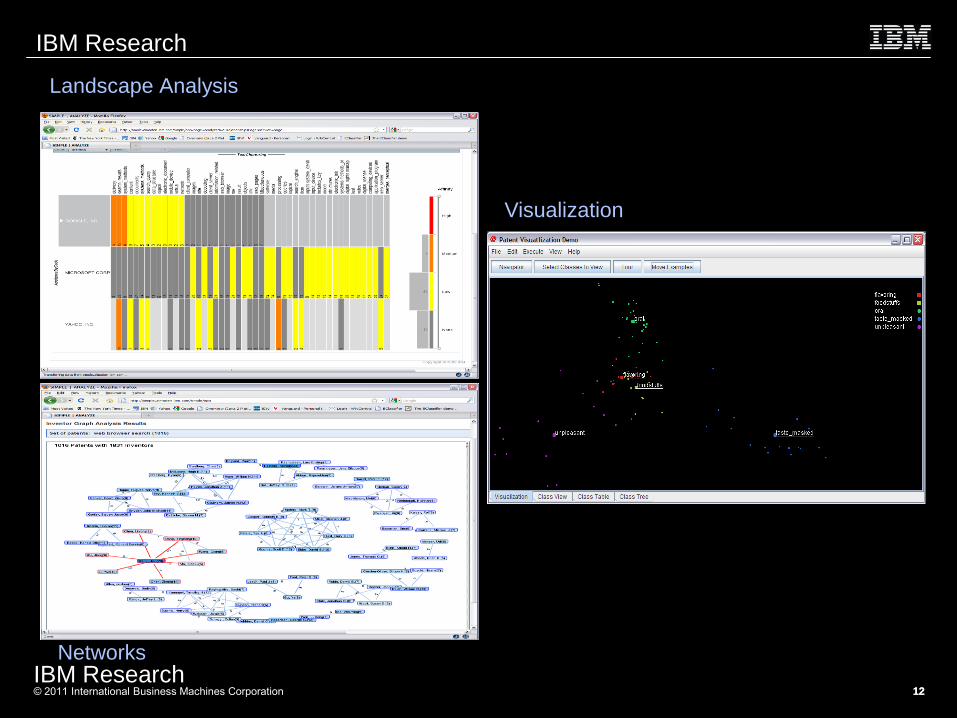
Landscape Analysis
Visualization
Networks

IBM Research 13 © 2011 International Business Machines Corporation 13
IBM Research
Looking Forward …..From Simple -------to--------- DeepQA
Moving SIMPLE – to –SIIP (IBM- Global Businesses Services )
Using our base to move into DeepQA
Aggregating the data for Cognitive Computing

IBM Research 14 © 2011 International Business Machines Corporation 14
IBM Research
DeepQA: Massively Parallel Probabilistic Architecture
Question/T
opic
Analysis
Question
Hypothesis & Evidence
Scoring
Answer,
Confidence
Synthesis Final Merging
& Ranking
Query
Decomposition
Hypothesis
Generation
Hypothesis &
Evidence Scoring
Soft
Filtering
Hypothesis
Generation
Hypothesis &
Evidence Scoring Soft
Filtering
Hypothesis
Generation
. . .
Trained
Models
Primary
Search
Candidate
Answer
Generation
A.
Sources Supporting
Evidence
Retrieval
Deep
Evidence
Scoring
Answer
Scoring
E.
Sources
Evidence
Retrieval
Deep
Evidence
Scoring
14
DeepQA generates and scores many hypotheses using an extensible collection of Natural Language Processing,
Machine Learning and Reasoning Algorithms. These gather and weigh evidence over both unstructured and
structured content to determine the answer with the best confidence.
Source – J Kreulen

IBM Research 15 © 2011 International Business Machines Corporation 15
IBM Research
Factors to
consider
Current Watson capability
tuned to play Jeopardy
What is needed to purpose configure
Watson for specific Application
Knowledge Domain:
Open vs. Closed
Open domain to consider general
knowledge
Need to have domain-specific ontologies for specific
applications
Availability of
Knowledge Sources
Extensive availability of knowledge
sources
Develop/assemble sufficient knowledge sources for the
application at hand.
Training Data Watson used 20 years worth of
Jeopardy data to train the system
Availability of sufficient sample data for training is
critical to the performance of Watson.
Speech to Text Watson can handle some speech-to-
text but it is not perfect
It may be better to go first with just text and then
integrate speech-to-text capabilities
Response Time
(Latency)
Watson used 15TB of system memory
and massive processing to respond
within 3 seconds for Jeopardy
What is the application requirement for response time?
What accuracy is required? This will drive how Watson
will be configured.
Language support
(Cross/Multi Lingual)
Watson’s core algorithms are
language agnostic. The jeopardy
application supports only English.
Language-specific parsers will have to be developed if
Watson has to support multiple languages.
Question
Type
Watson processes by decomposing
and classifying the questions. Most of
the questions in Jeopardy are fact-
based questions.
What type of questions are relevant for the application?
If it requires special instructions to understand or using
audio/visual aids then they are not good candidates for
Watson.
Answer
Type
Watson is designed to be a powerful
general purpose natural language QA
system. It is not designed to be task-
oriented.
Watson can handle multi-step processing but it is not
suitable for process-oriented questions (e.g. did we
complete all preceding tasks A and B before starting
task C)
Quick view of considerations in applying Watson-type capabilities
Source – J Kreulen

IBM Research 16 © 2011 International Business Machines Corporation 16
IBM Research
InfoSphere Warehouse DB2, Informix, Netezza
Aggregating and storing data and content
InfoSphere BigInsights “Big Data” analysis (Hadoop)
IBM Content Analytics Natural Language Processing and content analysis leveraging UIMA
InfoSphere Streams Massively parallel analysis
IBM Power Systems Thousands of parallel processes
Related Innovations
Business Analytics BI, Predictive Analytics
and more
IBM Global Business Services
Research, expertise and analytical assets
ECM Solutions IBM eDiscovery Analyzer
IBM Classification Module IBM OmniFind Enterprise Search
Used by Watson
Workload Optimized Systems Integrated, Optimized by Workload
The Components of Deep QA
Source – J Kreulen
IBM Research 17 © 2011 International Business Machines Corporation 17
IBM Research
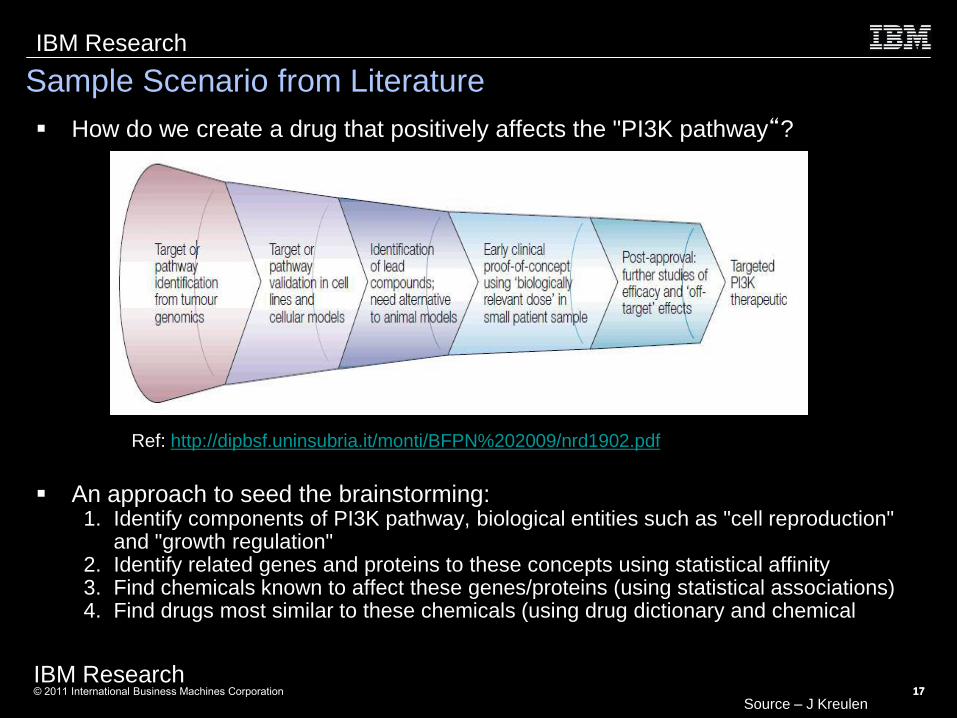
Sample Scenario from Literature
How do we create a drug that positively affects the "PI3K pathway“?
Ref: http://dipbsf.uninsubria.it/monti/BFPN%202009/nrd1902.pdf
An approach to seed the brainstorming: 1. Identify components of PI3K pathway, biological entities such as "cell reproduction"
and "growth regulation" 2. Identify related genes and proteins to these concepts using statistical affinity 3. Find chemicals known to affect these genes/proteins (using statistical associations) 4. Find drugs most similar to these chemicals (using drug dictionary and chemical
similarity)
Source – J Kreulen
IBM Research 18 © 2011 International Business Machines Corporation 18
IBM Research
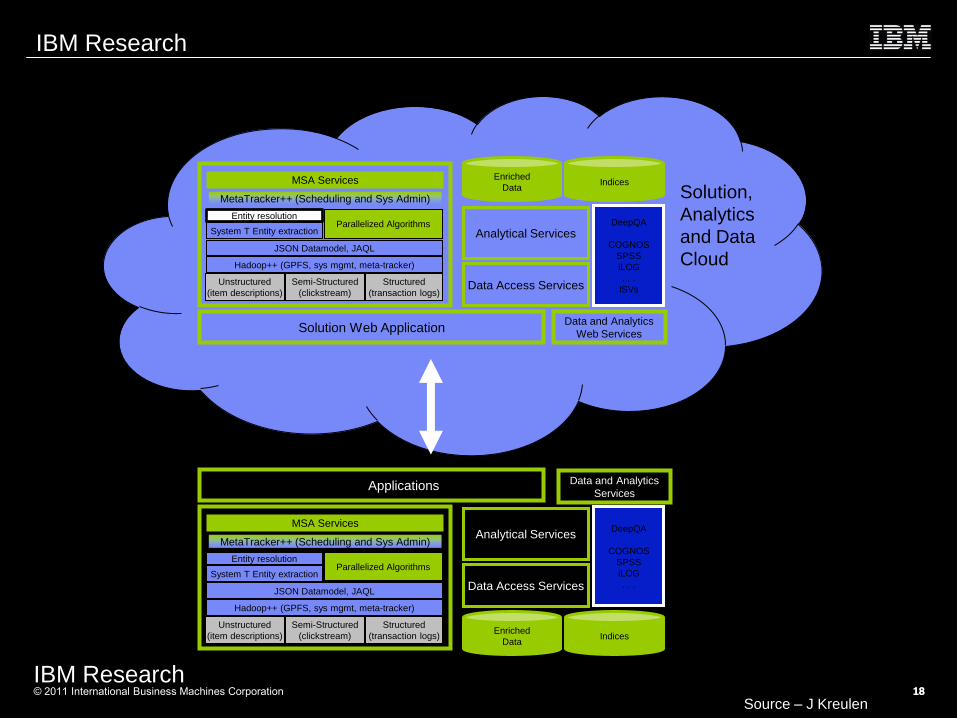
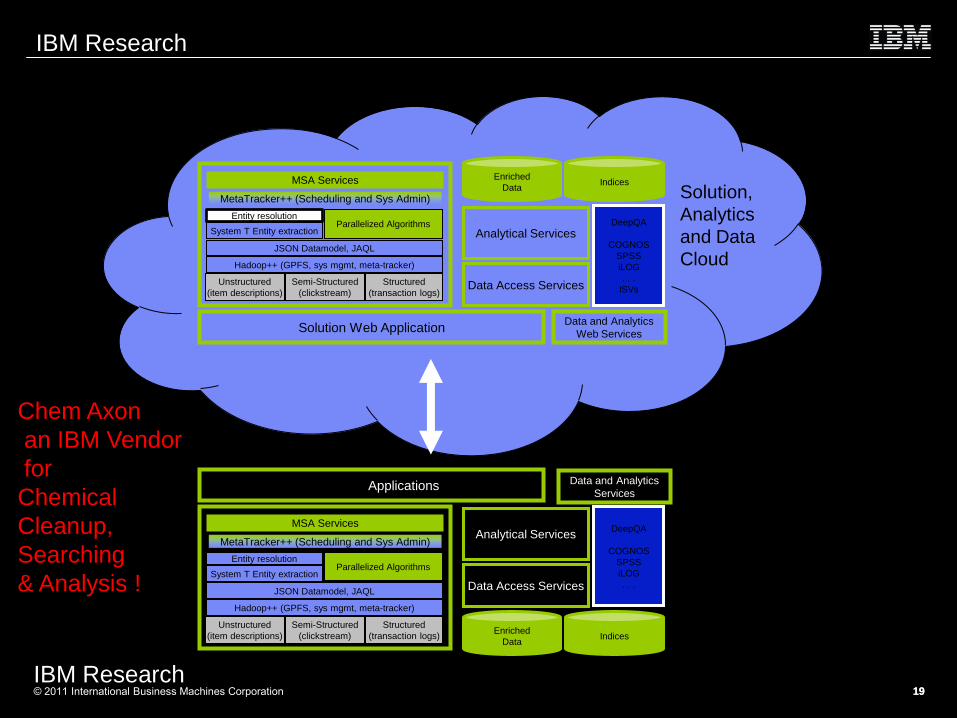
Cloud / Enterprise Integration
Hadoop++ (GPFS, sys mgmt, meta-tracker)
JSON Datamodel, JAQL
System T Entity extraction
Entity resolution
Unstructured
(item descriptions)
Semi-Structured
(clickstream)
Structured
(transaction logs)
Parallelized Algorithms
MSA Services
Enriched
Data Indices
Data Access Services
Analytical Services DeepQA
COGNOS
SPSS
iLOG
. . .
Solution Web Application Data and Analytics
Web Services
MetaTracker++ (Scheduling and Sys Admin)
Enterprise Applications Data and Analytics
Services
Hadoop++ (GPFS, sys mgmt, meta-tracker)
JSON Datamodel, JAQL
System T Entity extraction
Entity resolution
Unstructured
(item descriptions)
Semi-Structured
(clickstream)
Structured
(transaction logs)
Parallelized Algorithms
MSA Services Enriched
Data Indices
Data Access Services
Analytical Services DeepQA
COGNOS
SPSS
iLOG
. . .
ISVs
MetaTracker++ (Scheduling and Sys Admin) Solution,
Analytics
and Data
Cloud
Enterprise
Source – J Kreulen
IBM Research 19 © 2011 International Business Machines Corporation 19
IBM Research
Cloud / Enterprise Integration
Hadoop++ (GPFS, sys mgmt, meta-tracker)
JSON Datamodel, JAQL
System T Entity extraction
Entity resolution
Unstructured
(item descriptions)
Semi-Structured
(clickstream)
Structured
(transaction logs)
Parallelized Algorithms
MSA Services
Enriched
Data Indices
Data Access Services
Analytical Services DeepQA
COGNOS
SPSS
iLOG
. . .
Solution Web Application Data and Analytics
Web Services
MetaTracker++ (Scheduling and Sys Admin)
Enterprise Applications Data and Analytics
Services
Hadoop++ (GPFS, sys mgmt, meta-tracker)
JSON Datamodel, JAQL
System T Entity extraction
Entity resolution
Unstructured
(item descriptions)
Semi-Structured
(clickstream)
Structured
(transaction logs)
Parallelized Algorithms
MSA Services Enriched
Data Indices
Data Access Services
Analytical Services DeepQA
COGNOS
SPSS
iLOG
. . .
ISVs
MetaTracker++ (Scheduling and Sys Admin) Solution,
Analytics
and Data
Cloud
Enterprise
Chem Axon
an IBM Vendor
for
Chemical
Cleanup,
Searching
& Analysis !

IBM Research 20 © 2011 International Business Machines Corporation 20
IBM Research
I would like to acknowledge the IBM Almaden Research – team
Jeff Kreulen
Ying Chen
Scott Spangler
Alfredo Alba
Tom Griffin
Eric Louie
Su Yan
Issic Cheng
Prasad Ramachandran
Bin He
Ana Lelescu
Qi He
Linda Kato
Ana Lelescu
Brad Wade
John Colino
Meenakshi Nagarajan
Timothy J Bethea
German Attanasio
+ a host of folks from
IBM China Labs -

IBM Research 21 © 2011 International Business Machines Corporation 21
IBM Research
Thank you.
IBM Almaden Research Center
Source – J Kreulen


















