
Documento claves hash
38
UNIVERSIDAD CENTRAL DEL ECUADOR FACULTAD DE INGENIERÍA CIENCIAS FÍSICAS Y MATEMÁTICAS BÚSQUEDA POR TRANSFORMACIÓN DE CLAVES (HASH) DOCENTE: Wagner Lucero GRUPO: “NO A LA SEGUNDA MATRICULA” AUTORES: Jennifer Bedón (coordinadora) Jean Gomez (comunicador) Jeniffer Guaman (relatora) Henry Lagla (vigía de tiempo) Edison Macas (utilero) PARALELO: 10
-
Upload
santybizzle -
Category
Documents
-
view
45 -
download
0
description
Documento claves hash
Transcript of Documento claves hash

UNIVERSIDAD CENTRAL DEL ECUADOR
FACULTAD DE INGENIERÍA CIENCIAS FÍSICAS Y
MATEMÁTICAS
BÚSQUEDA POR TRANSFORMACIÓN DE CLAVES (HASH)
DOCENTE: Wagner Lucero
GRUPO: “NO A LA SEGUNDA MATRICULA”
AUTORES:
Jennifer Bedón (coordinadora)
Jean Gomez (comunicador)
Jeniffer Guaman (relatora)
Henry Lagla (vigía de tiempo)
Edison Macas (utilero)
PARALELO: 10
Quito, Febrero 10 del 2015

Contenido
INTRODUCCIÓN............................................................................................................................3
OBJETIVOS....................................................................................................................................4
Objetivo general:.....................................................................................................................4
Objetivos específicos:..............................................................................................................4
BÚSQUEDA POR TRANSFORMACIÓN DE CLAVES (HASH).............................................................5
1.1 ALGORITMO HASHING.......................................................................................................5
1.2 TABLAS HASH.....................................................................................................................6
1.2.1 Tipos de Tablas Hash..................................................................................................8
1.3 MÉTODOS DE TRANSFORMACIÓN DE CLAVES..................................................................9
1.3.1 Función Módulo (Por División).................................................................................10
1.3.2 Función Cuadrado.....................................................................................................11
1.3.3 Función Plegamiento...............................................................................................11
1.3.3 Truncamiento............................................................................................................12
1.4 MÉTODOS DE TRATAMIENTO DE COLISIONES................................................................13
1.4.1 Reasignación.............................................................................................................14
1.4.2 Arreglos Anidados.....................................................................................................20
1.4.3 Encadenamiento.......................................................................................................21
IMPLEMENTACIÓN DEL MÉTODO HASH EN JAVA.................................................................23
IMPLEMENTACIÓN DEL MÉTODO HASH EN C++...................................................................26
HERRAMIENTAS PARA REALIZAR EL VIDEO...........................................................................28
CONCLUSIONES......................................................................................................................29
RECOMENDACIONES.............................................................................................................29
BIBLIOGRAFIA........................................................................................................................30
2

INTRODUCCIÓN
El método hash consiste en facilitar la forma de encontrar los datos en los arreglos En consecuencia, las aplicaciones h(k), a las que desde ahora llamaremos funciones hash, tienen la particularidad de que podemos esperar que h( ki ) = h( kj ) para bastantes pares distintos ( ki,kj ). El objetivo será pues encontrar una función hash que provoque el menor número posible de colisiones (ocurrencias de sinónimos), aunque esto es solo un aspecto del problema, el otro será el de diseñar métodos de resolución de colisiones cuando éstas se produzcan.
Se trata de abordar de forma sencilla este concepto para aquellos que no lo conozcan. Podemos decir que un HASH no es más que un número o resumen. De hecho, esta es solo una herramienta más que se puede implementar a los arreglos, se puede decir que un fichero es como un flujo de bits y le aplicamos un algoritmo de HASH lo que obtenemos es otro conjunto de bits (de longitud fija y que depende del número de bits de salida del algoritmo o función que utilicemos) que depende bit a bit del contenido del flujo original de bits que sirvió como entrada al algoritmo.Además, cumplen las siguientes propiedades:
• Todos los Hashes generados con una función de hash tienen el mismo tamaño, sea cual sea el mensaje utilizado como entrada.
• Dado un mensaje, es fácil y rápido mediante un ordenador calcular su HASH.
• Es imposible reconstruir el mensaje original a partir de su HASH.
• Es imposible generar un mensaje con un HASH determinado.Es decir, un algoritmo de HASH no es un algoritmo de encriptación, aunque sí se utiliza en esquemas de cifrado, como algoritmos de cifrado asimétrico (por ejemplo en el RSA).
3

OBJETIVOS
Objetivo general:
Adquirir conocimientos sustentables acerca de la Búsqueda por Transformación de Claves (Hash) mediante el uso de la memoria técnica que dará al estudiante facilidad para comprender este método de búsqueda, y así los estudiantes puedan resolver problemas donde será necesario utilizar los conocimientos adquiridos.
Objetivos específicos:
• Conocer los métodos que utiliza la Búsqueda por Transformación de Claves (Hash) y aplicarlos en algoritmos.
• Realizar algoritmos de búsqueda en los diferentes lenguajes estudiados que son: C++, Visual Basic y Java.
• Realizar presentaciones en Prezi y Power Point.
• Realizar un video tutorial sobre este método de búsqueda y subirlo a YouTube.
4

BÚSQUEDA POR TRANSFORMACIÓN DE CLAVES (HASH)
Este método permite asignar a un valor una posición determinada de un arreglo y de igual forma permite recuperarla fácilmente, igualmente convierte una clave dada en una dirección (índice), dentro del arreglo.
Además gracias a que no hay necesidad de tener los elementos ordenados aumenta la velocidad de búsqueda. Cuenta también con la ventaja de que el tiempo de búsqueda es prácticamente independiente del número de componentes del arreglo.
Para trabajar con este método de búsqueda debe elegirse previamente:
1. Una función hash que sea fácil de calcular y que distribuya uniformemente las claves.
2. Un método para resolver colisiones. Si estas se presentan se debe contar con algún método que genere posiciones alternativas
Uso de funciones Hash:
1. Proteger la confidencialidad de una contraseña2. Garantizar la integridad de los datos3. Verificar la identidad del emisor de un mensaje mediante firmas digitales
La eficiencia de una función Hash depende de:
1. La distribución de los valores de llave o clave que realmente se usan.2. El número de valores de llave o clave que realmente están en uso con respecto
al tamaño del espacio de direcciones.3. El número de registros que pueden almacenarse en una dirección dada sin
causar una colisión.4. La técnica usada para resolver el problema de las colisiones.
1.1 ALGORITMO HASHING
Algoritmo que se utiliza para generar un valor de Hash para algún dato, como por ejemplo claves. Un algoritmo de Hash hace que los cambios que se produzcan en los
5

datos de entrada provoquen cambios en los bits del Hash. Gracias a esto, los Hash permiten detectar si un dato ha sido modificado. (Vilugron, 2014)
Costos
Tiempo de procesamiento requerido para la aplicación de la función Hash. Tiempo de procesamiento y los accesos E/S requeridos para solucionar las
colisiones.
1.2 TABLAS HASH
Robert Sedgewick y Kevin Wayne mencionan en su obra “Algorithms, 4th Edition” que:
If keys are small integers, we can use an array to implement a symbol table, by interpreting the key as an array index so that we can store the value associated with key i in array position i. In this section, we consider hashing, an extension of this simple method that handles more complicated types of keys. We reference key-value pairs using arrays by doing arithmetic operations to transform keys into array indices.
Search algorithms that use hashing consist of two separate parts. The first step is to compute a hash function that transforms the search key into an array index. Ideally, different keys would map to different indices. This ideal is generally beyond our reach,
6
Ventajas
Se pueden usar los valores naturales de la llave, puesto que se traducen internamente a direcciones fáciles de localizar.
Se logra independencia lógica y física, debido a que los valores de las llaves son independientes del espacio de direcciones.
No se requiere almacenamiento adicional para los índices.
Desventajas
No pueden usarse registros de longitud variable.
El archivo no está clasificado.
No permite claves repetidas.
Solo permite acceso por una sola llave.

so we have to face the possibility that two or more different keys may hash to the same array index. Thus, the second part of a hashing search is a collision-resolution process that deals with this situation.
Hash functions. If we have an array that can hold M key-value pairs, then we need a function that can transform any given key into an index into that array: an integer in the range [0, M-1]. We seek a hash function that is both easy to compute and uniformly distributes the keys.
Basado en lo expuesto anteriormente se destaca la importancia de las tablas hash ya que sin ellas no se podría utilizar el Método Por transformación de claves; además facilitan la clasificación de la información dada permitiendo que la búsqueda sea rápida y efectiva, finalmente se puede decir que una tabla bien estructurada evitaría que existan excesivas colisiones.
Las tablas hash son estructuras tipo vector que ayudan a asociar claves con valores o datos.
Observación:No se debe buscar directamente el valor deseado, sino a través de una función de dispersión h(x) localizar la posición del valor buscado. (Olmos, 2014)
Una tabla hash se construye con tres elementos básicos:
1. Un vector capaz de almacenar “m” elementos2. Función de dispersión que permita a partir de los datos (llamados clave)
obtener el índice donde estará el dato en el arreglo3. Una función de resolución de colisiones
7
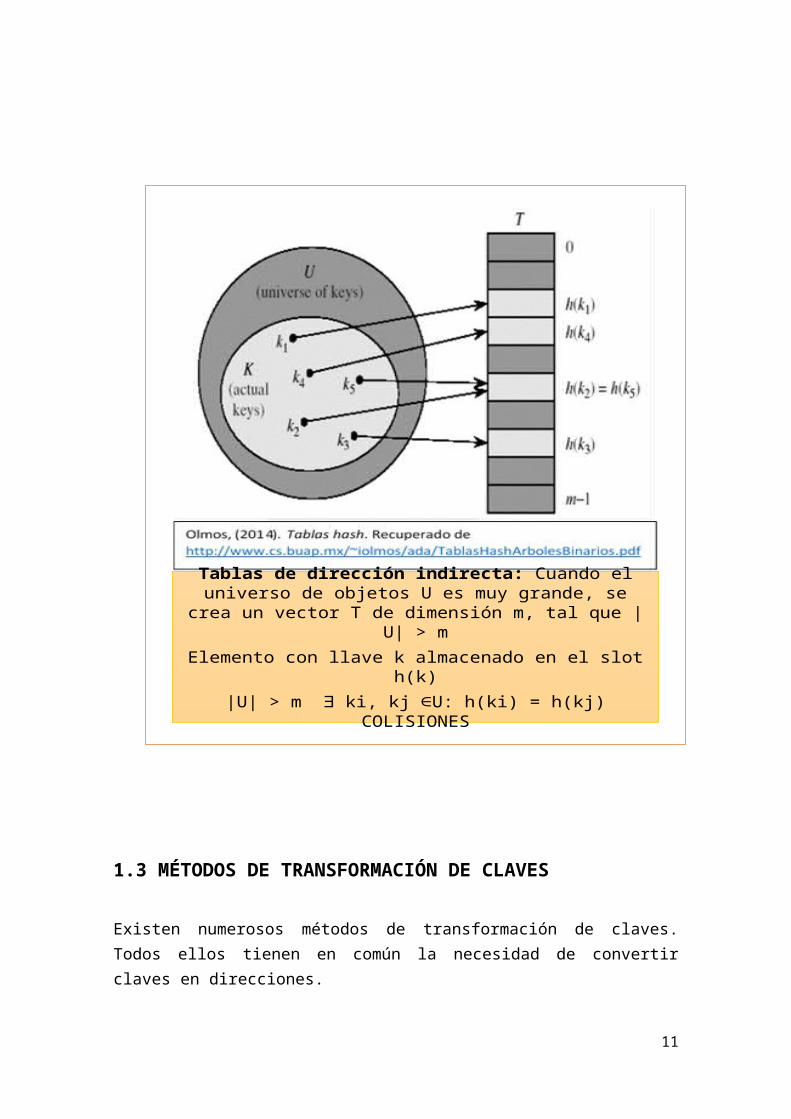
Olmos, (2014). Tablas hash. Recuperado de http://www.cs.buap.mx/~iolmos/ada/TablasHashArbolesBinarios.pdf

Para el diseño de una tabla hash, es de gran importancia cumplir con lo siguiente:
Función sencilla para una evaluación rápida Distribuir uniformemente en el espacio de almacenamiento Evitar (si es posible) la aparición de sinónimos o colisiones Para dos claves similares, generar posiciones distantes
1.2.1 Tipos de Tablas Hash
Existen diferentes tipos de tablas hash:
8
Tablas de dirección directa: cuando el universo de objetos U es relativamente pequeño
Elemento con llave k almacenado en el slot k

1.3 MÉTODOS DE TRANSFORMACIÓN DE CLAVES
Existen numerosos métodos de transformación de claves. Todos ellos tienen en común la necesidad de convertir claves en direcciones.
Cuando se desea localizar un elemento de clave x, el indicador de direcciones indicará en qué posición del array estará situado el elemento.
9
Tablas de dirección indirecta: Cuando el universo de objetos U es muy grande, se crea un vector T de dimensión m, tal que |U|
> mElemento con llave k almacenado en el slot h(k)
|U| > m ki, kj U: h(ki) = h(kj) COLISIONES∃ ∈

1.3.1 Función Módulo (Por División)
Se lo utiliza cuando la distribución de los valores de claves no es conocida.
La función de este método es dividir el valor de la clave entre un número apropiado, y después utilizar el residuo de la división como dirección relativa para el registro. (Castro, 2014)
Suponga que se tiene un arreglo de N elementos y K es la clave del dato a buscar.
La función hash queda:
H (k) = (K mod N) +1
Para lograr una mayor uniformidad en la distribución, N debe ser un número primo. (El número primo próximo a N)
Existen varios factores que deben considerarse para seleccionar el divisor:
divisor > n: suponiendo que solamente un registro puede ser almacenado en una dirección relativa dada.
Seleccionarse el divisor de tal forma que la probabilidad de colisión sea minimizada.
Por ejemplo:
Sea N=100, el tamaño del arreglo
Sus direcciones de 1-100.
Sea K1 = 7259
K2 = 9359
Dos claves que deban asignarse posiciones en el arreglo
H (K1) = (7259 mod 100) +1=60
H (K2) = (9359 mod 100) +1=60
Donde H (K1) es igual a H (K2) y K1 es distinto de K2, es una colisión
Se aplica N igual a un valor primo en lugar de utilizar N=100
H (K1) = (7259 mod 97) +1=82
H (K2) = (9359 mod 97) +1=48
10
Con N=97 se ha eliminado la colisión
1.3.2 Función Cuadrado
Consiste en elevar al cuadrado la clave y tomar los dígitos centrales como dirección. El número de dígitos a tomar queda determinado por el rango del índice. Sea K la clave del dato buscar. (Takeyas, 2012)
La función hash queda definida por la siguiente fórmula:
H (K) = dígitos_centrales (K2) + 1
La suma de una unidad a los dígitos centrales es para obtener un valor entre 1 y N.
El siguiente ejemplo presenta un caso de función hash cuadrado: Sea N= 100 el
tamaño del arreglo, y sean sus direcciones los números entre 1 y 100.
Sean K1 = 186 y K2 = 581 dos claves a las que deban asignarse posiciones en el
arreglo. Se aplica la fórmula anterior para calcular las direcciones
correspondientes a K1 y a K2.
K12 = 186^2 = 03 45 96
K22 = 581^2 = 33 75 61
H (K1) = dígitos_centrales (03 45 96) + 1 = 46
46 sería la dirección correspondiente
H (K2) = dígitos_centrales (33 75 61) + 1 = 76
76 sería la dirección correspondiente
Como el rango de índices en nuestro ejemplo, varía de 1 a 100 se toman solamente los dos dígitos centrales del cuadrado de las claves.
1.3.3 Función Plegamiento
Consiste en dividir la clave en partes de igual número de dígitos (la última puede tener menos dígitos) y operar con ellas, tomando como dirección los dígitos menos significativos. La operación entre las partes puede hacerse por medio de sumas o multiplicaciones. Sea K la clave del dato a buscar. (Takeyas, 2012)
11

K está formada por los dígitos d1, d2,..., dn. La función hash queda definida por la siguiente fórmula:
H (K) = dígmensig ((d1... di) + (di+1... dj) +... + (dl... dn)) + 1
Dígnense: dígitos menos significativos
El operador que aparece en la fórmula operando las partes de la clave es el de suma. Pero puede ser el de la multiplicación. La suma de una unidad a los dígitos menos significativos (dígmensig) es para obtener un valor entre 1 y N.
Ejemplo: Sean N = 100 el tamaño del arreglo, y sean sus direcciones los números entre 1 y 100. Sean K1 = 280304 y K2 = 484001 dos claves a las que deban asignarse posiciones en el arreglo. Se aplica la anterior fórmula para calcular las direcciones correspondientes a K1 y K2.
H (K1) = dígmensig (28 + 03 + 04) + 1 = dígmensig (35) + 1 = 36
H (K2) = dígmensig (48 + 40 + 01) + 1 = dígmensig (81) + 1 = 82
De la suma de las partes se toman solamente dos dígitos porque los índices del arreglo varían de 1 a 100.
1.3.3 Truncamiento
El truncamiento consiste en tomar algunos dígitos de la clave y con estos formar una posición en un array. Se ignora parte de la clave para con el resto formar un índice de almacenamiento.
La idea consiste en tener un listado de números, seleccionar por ejemplo la posición 2, 4 y 5; para así tener una posición en donde poder almacenar la clave. Llevando esto a un ejemplo práctico:
5700931 703
3498610 481
0056241 064
9134720 142
5174829 142
12

Lo positivo del truncamiento y una de las ventajas por sobre otros métodos de búsqueda y ordenamiento es que no solo funciona con valores numéricos, también funciona con caracteres alfabéticos, esto se puede aplicar de dos formas:
1) Transformar cada carácter en un número asociado a su posición en el abecedario.
2) Transformar cada carácter en un número asociado a su valor según el código ASCII.
Una vez obtenida la clave en forma numérica, se puede utilizar normalmente.
La elección de los dígitos a considerar es arbitraria, pueden tomarse posiciones pares o impares. Luego se les puede unir de izquierda a derecha o de derecha a izquierda.
La función queda definida por:
H (K)=dígitos (t1 t2 t3… tn)+1
Existen casos en los que a la clave generada se les agrega una unidad, esto es para los casos en el que el vector de almacenamiento tenga valores entre 1 y el 100, así se evita la obtención de un valor 0.
H (K1)=dígitos (7 2 5 9)+1=76
H (K2)=dígitos (9 3 5 9)+1=96
Una de las principales desventajas de utilizar truncamiento y en sí el método de hashing es que dos o más claves pueden tomar una misma posición dentro de la tabla de hash, a esto es a lo que se le llama Colisión. Cuando hay colisiones se requiere de un proceso adicional para encontrar la posición disponible para la clave, lo cual disminuye la eficiencia del método. (Guzmán, 2014)
1.4 MÉTODOS DE TRATAMIENTO DE COLISIONES
La elección de un método adecuado para resolver colisiones es tan importante como la elección de una buena función hash. Cuando la función hash obtiene una misma dirección para dos claves diferentes, se está ante una colisión.
13

Algunos métodos más utilizados para resolver colisiones son los siguientes:
Reasignación Arreglos anidados Áreas de desborde
1.4.1 Reasignación
Existen varios métodos que trabajan bajo el principio de comparación y reasignación de elementos. Se analizaran tres de ellos:
Prueba lineal Prueba cuadrática Doble dirección hash
1.4.1.1 Prueba Lineal
Consiste en que una vez detectada la colisión se debe de recorrer el arreglo secuencialmente a partir del punto de colisión, buscando al elemento. El proceso de búsqueda concluye cuando el elemento es hallado, o bien cuando se encuentra una posición vacía. Se trata al arreglo como a una estructura circular: el siguiente elemento después del último es el primero.
La principal desventaja de este método es que puede haber un fuerte agrupamiento alrededor de ciertas claves, mientras que otras zonas del arreglo permanecerían vacías. Si las concentraciones de claves son muy frecuentes, la búsqueda será́� principalmente secuencial perdiendo as las ventajas del método hash. í́� (Takeyas, 2012)
Con el ejemplo se ilustra el funcionamiento del algoritmo:
14
(Takeyas, 2012). Administración de archivos [Prueba Cuadrática]. Recuperado de http://www.teclaredo.edu.mx/takeyas/Apuntes/Administracion_Archivos/Apuntes/Colisiones.PDF

1.4.1.2 Prueba Cuadrática
Este método es similar al de la prueba lineal. La diferencia consiste en que en el cuadrático las direcciones alternativas se generan como D + 1, D + 4, D + 9,. . ., D + i² en vez de D + 1, D + 2,..., D + i. “La principal desventaja de este método es que pueden quedar casillas del arreglo sin visitar”. (Takeyas, 2012)
Además, como los valores de las direcciones varían en 1² unidades, resulta difícil determinar una condición general para detener el ciclo. Este problema podría solucionarse empleando una variable auxiliar, cuyos valores dirijan el recorrido del arreglo de tal manera que garantice que serán visitadas todas las casillas. A continuación se presenta un ejemplo que ilustra el funcionamiento:
Este método se genera a partir de la elevación de un valor al cuadrado, donde ese valor inicia con el número 1 y lo suma a la dirección que se encuentra en colisión (d+i2), si se genera nuevamente una colisión el valor del número se incrementa, se eleva al cuadrado y se suma a la dirección inicial (d+1, d+4, d+9, d+16, …, d+i2), este proceso se repite hasta que se encuentre una dirección vacía. “Está generación de direcciones puede llegar a exceder el tamaño de la estructura, si es así, la dirección inicia en uno y el valor inicial a elevar es el cero”. (Takeyas, 2012)
Este método es similar al de la prueba lineal. La diferencia consiste en que, en lugar de buscar en las posiciones con direcciones: dir_Hash, dir_Hash + 1, dir_Hash + 2, dir_Hash + 3,.... {Buscamos linealmente en las posiciones con direcciones: dir_Hash,
15
(Takeyas, 2012). Administración de archivos [Prueba Cuadrática]. Recuperado de http://www.teclaredo.edu.mx/takeyas/Apuntes/Administracion_Archivos/Apuntes/Colisiones.PDF

dir_Hash + 1, dir_Hash + 4, dir_Hash + 9,..., dir_Hash+i 2 {Si el número m de posiciones en la tabla T es un número primo y el factor de carga no excede del 50%, sabemos que siempre insertaremos el nuevo elemento X y que ninguna celda será consultada dos veces durante un acceso.
Desventaja:
• Pueden quedar casillas sin visitar, además resulta difícil definir una condición general para detener el ciclo.
• Se puede utilizar una variable auxiliar, que dirija el recorrido de tal forma que garanticen que serán visitadas todas las casillas. (Fidalgo., 2013)
Ejemplo adquirido de Fernández Carlos A. en su obra Estructura de Datos menciona que:
V = [25, 43, 56, 35, 54, 13, 80, 104, 55]
Usando la función hash:
H (K)= (k mod 10) + 1
Prueba Cuadrática (V, N, K)
//Este algoritmo busca el dato con clave K en el arreglo V de N elementos. //Resuelve el problema de las colisiones por medio de la prueba cuadrática//D, DX e I son variables de tipo entero
D = H [K] //Genera direcciónSi (V [D] == K) entonces{
Escribir “El elemento está en la posición D”
Si no{
Hacer I = 1 y DX = D + I2;{
Repetir mientras (V [DX] <> K) y (V [DX] <> VACÍO){
Hacer I = I + 1; DX = D + I2 ;{
Si (DX > N) Entonces}
Hacer I=0; DX=1 y D=1;}
}}
16

}}
Si (V [DX] == K) entonces{ Escribir “El elemento esta en la posición DX”} Si no{
Escribir “El elemento no está en el arreglo”}
}
Código. Prueba Cuadrática.
public static int pruebaCuadratica (int X, int[] A)
{
int m = A.length;
int dirHash = X%m;
if (A[dirHash] == X) return dirHash;
else {
int i = 1;
int cont = 0;
int dirReh = (dirHash + 1)%m;
while ((A[dirReh] != X) && (A[dirReh] != 0) && (cont < m*10))
{
i++;
dirReh = (dirHash + (i*i))%m;
cont++;
}
if (A[dirReh] == X) return dirReh;
else return -1;
}
}
17

1.4.1.3 La doble dirección hash
Consiste en generar otra dirección hash, una vez que se detecta la colisión, la generación de la nueva dirección se hace a partir de la dirección previamente obtenida más uno. La función hash que se aplique para generar la nueva dirección puede no ser la misma a la utilizada en el proceso anterior, para esto no existe una regla establecida, lo que permite utilizar cualquiera de las funciones hash conocidas hasta ahora.
“En este método se debe generar otra dirección aplicando una función hash H2 a la dirección previamente obtenida”. (Fidalgo., 2013)
Entonces buscamos linealmente en las posiciones que se encuentran a una distancia H 2(X), 2 H 2(X), 3 H 2(X), ... { La función hash H 2 que se aplique a las sucesivas direcciones puede ser o no ser la misma que originalmente se aplicó a la clave. No existe una regla que permita decidir cuál será la mejor función a emplear en el cálculo de las sucesivas direcciones. Pero una buena elección sería H 2(X) = R – (X%R), siendo R un número primo más pequeño que el tamaño del array. Y se obtienen unos resultados mejores cuando el tamaño del array es un número primo
Ejemplo:
V = [25, 43, 56, 35, 54, 13, 80, 104]
H (K)= (k mod 10) +1
DobleDireccion (V, N, K)
//Este algoritmo busca el dato con clave K en el arreglo V de N elementos. //Resuelve el problema de las colisiones por medio de la doble dirección hash
18

//D y DX son variables de tipo enteroD=H [K] //Genera direcciónSi (V [D] == K) entonces{
Escribir “El elemento esta en la posición D” Si no
{ Hacer DX = H’ (D);
{ Repetir mientras (DX <=N) y (V [DX]<> K) y (V[DX]<>VACÍO) y (DX<>D)
Hacer DX = H’ (DX) ;}Si (V [DX] == K) entonces{
Escribir “El elemento está en la posición DX”Si no{
Escribir “El elemento no está en el arreglo”}
}}
Código. Doble dirección Hash.
Public static int dobleDireccionamiento(int X, int R, int[] A){
int m = A.length;
int dirHash = X%m;
if (A[dirHash] == X) return dirHash;
else {
int dirHash2 = R – (X%R);
int i = 1;
int dirReh = (dirHash + dirHash2)%m;
while ((A[dirReh] != X) && (A[dirReh] != 0))
{
i++;
dirReh = (dirHash + i*dirHash2)%m;
}
19

If (A[dirReh] == X) return dirReh;
else return -1;
}
}
1.4.2 Arreglos Anidados
Arreglos anidados Este método consiste en que cada elemento del arreglo tenga otro arreglo en el cual se almacena los elementos colisionados. Si bien la solución parece ser sencilla, es claro también que resulta ineficiente. Al trabajar con arreglos depende del espacio que se halla asignado a este lo cual conduce a un nuevo problema difícil de solucionar: elegir un tamaño adecuado de arreglo que permita el equilibrio entre el coste de memoria y el número de valores colisionados que pudiera almacenar. (fernandez, 2010)
En cada elemento del arreglo tenga otro arreglo, donde se almacenan los elementos colisionados
1. Solución ineficiente2. costo de memoria3. Número de valores colisionados
20
(Takeyas, 2012). Administración de archivos [Arreglos Anidados]. Recuperado de http://www.teclaredo.edu.mx/takeyas/Apuntes/Administracion_Archivos/Apuntes/Colisiones.PDF

Ejemplo:
V = [25, 43, 56, 35, 54, 13, 80, 104]
Usando la función hash:
H (K)= (k mod 10) +1
80 - - - - - - 43 54 25 56 - - - - - 13 104 35 - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1.4.3 Encadenamiento
Cada elemento del arreglo tiene un apuntador a una lista ligad, la cual se ira generando e ira almacenando los valores colisionados. (takeyas, 2012)
Es un método eficiente debido al dinamismo de las listas
Desventajas
Ocupa un espacio adicional al de la tabla Requiere un manejo de lista ligada Si la lista crecen demasiado se pierde el acceso directo del método hash
21
80 - - - -
-
-
43
54
25
56
-
-
-
-
-
13
104
35
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-

Ejemplo:
V=[ 25, 43, 56, 35, 54, 13, 80, 104 ]
Almacenados usando la función hash:
H(K)= (k mod 10) +1
22
35
104
13
56
80
255443

IMPLEMENTACIÓN DEL MÉTODO HASH EN JAVA
package main;
import java.util.Random;
import java.util.Scanner;
public class Hash1 {
public static void main(String[] args) {
Integer arreglo[] = new Integer[6];
double auxiliar;
Random numeros = new Random();
for (int i = 0; i < arreglo.length; i++) {
auxiliar = numeros.nextDouble();
auxiliar = auxiliar * 100;
arreglo[i] = (int) auxiliar;//cast toma la part entera
}
imprimir(arreglo);
Integer arregloindice[] = new Integer[6];
for (int i = 0; i < arregloindice.length; i++) {
int indice = arreglo[i] % 5;
if (arregloindice[indice] == null) {
arregloindice[indice] = arreglo[i];
} else {
System.out.println("Ocurre una colision en " + indice);
for (int j = 0; j < arregloindice.length; j++) {
if (arregloindice[j] == null) {
arregloindice[j] = arreglo[i];
23

System.out.println("se guardo en la posicion: " + j);
break;
}
}
}
}
System.out.println("Tabla hash");
imprimir(arregloindice);
int buscar;
Scanner leer = new Scanner(System.in);
System.out.println("ingrese el numero que desea buscar");
buscar = leer.nextInt();
buscar(arregloindice, buscar);
}
public static void imprimir(Integer[] arreglo) {
for (int i = 0; i < arreglo.length; i++) {
System.out.print(arreglo[i] + " ");
}
System.out.println();
}
public static void buscar(Integer[] arreglo, int dato) {
int contador=0;
for (int i = 0; i < arreglo.length; i++) {
if (dato == arreglo[i]) {
System.out.println("el numero se encuentra en el indice: " + i);
24

} else {
contador++;
}
}
if (contador==arreglo.length) {
System.out.println("numero no encontrado");
}
}
}
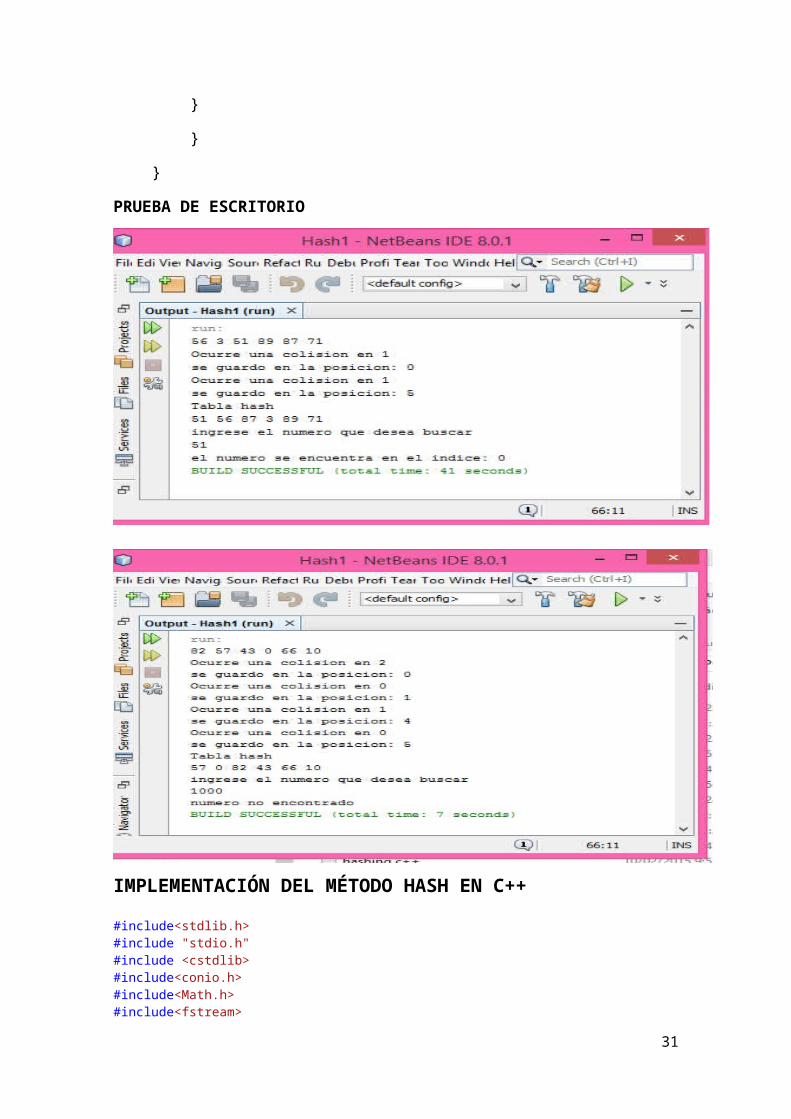
PRUEBA DE ESCRITORIO
25

IMPLEMENTACIÓN DEL MÉTODO HASH EN C++
#include<stdlib.h>#include "stdio.h"#include <cstdlib>#include<conio.h>#include<Math.h>#include<fstream>#include "stdafx.h"#include <iostream>#include "conio.h"using namespace std;
typedef struct no no_hash;struct no{ int data; int state; /* 0 para VACIO, 1 para REMOVIDO e 2 para OCUPADO */};// Calcula la función de distribuciónint funcion(int k, int m, int i){ return ((k+i)%m);}// Crea la tabla hash no_hash *Crea_Hash(int m){ no_hash *temp; int i; if((temp = (no_hash*)malloc(m*sizeof(no_hash))) != NULL) { for(i = 0; i < m; i++) temp[i].state = 0; return temp; } else exit(0);}// Inserta un elemento k en la tabla T de tamañ mvoid Inserta_Hash(no_hash *T, int m, int k){ int j, i = 0; do { j = funcion(k, m, i); if(T[j].state == 0 || T[j].state == 1) { T[j].data = k; T[j].state = 2; cout<<"\nElemento insertado con éxito!"; return; } else i++; }while(i < m); cout<<"\nTabla llena!";}int Busca_Hash(no_hash *T, int m, int k, int i){ int j; if(i < m) {
26

j = funcion(k, m, i); if(T[j].state == 0) return -1; else if(T[j].state == 1) return Busca_Hash(T, m, k, i+1); else if(T[j].data == k) return j; else return Busca_Hash(T, m, k, i+1); } return -1;}int Remove_Hash(no_hash *T, int m, int k){ int i; i = Busca_Hash(T, m, k, 0); if(i == -1) return -1; else { T[i].state = 1; return 1; }}void main() { int m, i, k; char resp; no_hash *T; cout<<"\nEntre con el tamaño de la tabla: "; cin>>m; T = Crea_Hash(m); while(1) { cout<<"\nInsertar (i) Buscar (b) Remover (r) Salir (s)\n"; resp = getche(); getch(); switch(resp) { case 'i': cout<<"\nIngrese el número a ser insertado en la tabla: "; cin>>k; Inserta_Hash(T, m, k); break; case 'b': cout<<"\nIngrese el número a ser buscado en la tabla: "; cin>>k; i = Busca_Hash(T, m, k, 0); if(i == -1) cout<<"\nNumero no encontrado!"; else cout<<"\nNumero encontrado!"; break; case 'r': cout<<"\nIngrese el número a ser eliminado de la tabla: "; cin>>k; i = Remove_Hash(T, m, k); if(i == -1) cout<<"\nNumero no encontrado!"; else cout<<"\nNumero eliminado con éxito!";
27

break; case 's': exit(0); break; } }
getch();}
PRUEBA DE ESCRITORIO
HERRAMIENTAS PARA REALIZAR EL VIDEO
Se utilizara CamStudio que es un software open source o de código abierto que nos permite grabar nuestra pantalla en formato .AVI. Funciona únicamente con Windows.
Se la escogió porque no llega a abrumar al usuario, tiene una gran cantidad de opciones y funcionalidades. Contiene características propias de la edición de video, como cortar y pegar planos o añadir distintas clases de transiciones, además es totalmente gratuito.
CONCLUSIONES
28

Una tabla hash es una estructura de datos que soporta la recuperación, eliminación e inserción de elementos de forma muy rápida.
Las tablas hash permiten que el coste medio de las operaciones insertar, buscar y eliminar sea constante, siempre que el factor de carga no sea excesivo para reducir la probabilidad de colisión.
Una función hash debe ser fácilmente calculable, sin costosas operaciones, también debe tener una buena distribución de valores entre todas los componentes de la tabla.
Una buena función hash distribuye equitativamente la asignación de claves a través de las posiciones de la tabla hash.
Si la función está mal diseñada producirá muchas colisiones. La fortaleza de una función hash requiere que estas colisiones sean las mínimas
posibles y que encontrarlas sea lo más difícil posible.
RECOMENDACIONES
Tome en cuenta los requisitos para elaborar una buena tabla hash. Escoja el tipo de tabla adecuado para nuestro algoritmo. Trate de que el número de colisiones sea casi nulo. En caso de que existan colisiones opte por el método de tratamiento más
adecuado para su algoritmo. Tomar en cuenta los métodos que se han explicado en este documento para
resolver las colisiones. Tener en cuenta que tipo de lenguaje de programación se está utilizando para
el algoritmo. Note que este método de búsqueda es más sencillo de programar en java. Recuerde que también existe un material de ayuda en el cual se explica de
forma más sencilla como funciona el método de búsqueda por transformación de claves, además contiene un ejercicio explicado paso a paso de cómo se programa.
29

BIBLIOGRAFIA
Castro, A. (23 de octubre de 2014). slideshare. Obtenido de Función Hash: metodos de división y de medio Cuadrado.: http://es.slideshare.net/analivecastrovargas/funcion-hash-metodos-de-divisi
fernandez, c. a. (12 de 2010). estructura de datos para arreglos. Recuperado el 02 de 02 de 2015, de estructura de datos para arreglos: http://www.utm.mx/~caff/doc/Notas%20de%20Estructura%20de%20datos.pdf
Fidalgo., R. L. (2013). Algoritmos de Busqueda y Ordenacion.
Guzmán, L. (17 de abril de 2014). Slideshare. Obtenido de Algoritmos de busqueda - hash truncamiento: http://es.slideshare.net/lutzhooo/algoritmos-de-busqueda-33624661
Olmos, I. (2 de diciembre de 2014). Tablas Hash y árboles. Obtenido de www.cs.buap.mx/~iolmos/ada/TablasHashArbolesBinarios.pdf
Sedgewick , R., & Wayne, K. (5 de mayo de 2014). Algorithms, 4th Edition. Obtenido de http://algs4.cs.princeton.edu/34hash/
takeyas, i. b. (16 de 03 de 2012). administracion de archivos. Recuperado el 02 de 02 de 2015, de administracion de archivos: http://www.teclaredo.edu.mx/takeyas/Apuntes/Administracion_Archivos/Apuntes/Colisiones.PDF
Takeyas, I. B. (2012). Administracion de Archivos. Obtenido de http://www.teclaredo.edu.mx/takeyas/Apuntes/Administracion_Archivos/Apuntes/Colisiones.PDF
Vilugron, J. (16 de abril de 2014). slidechare. Obtenido de Algoritmos de Búsqueda: http://es.slideshare.net/javiervilugron/algoritmo-de-busqueda-truncamiento
30
31


















