
Distributed Systems Models - DISI
43
Distributed Algorithms Models Alberto Montresor University of Trento, Italy 2016/04/26 This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Transcript of Distributed Systems Models - DISI

Distributed AlgorithmsModels
Alberto Montresor
University of Trento, Italy
2016/04/26
This work is licensed under a Creative CommonsAttribution-ShareAlike 4.0 International License.
references
V. Hadzilacos and S. Toueg.A modular approach to fault-tolerant broadcasts and relatedproblems.In S. Mullender, editor, Distributed Systems (2nd ed.).Addison-Wesley, 1993.http:
//www.disi.unitn.it/~montreso/ds/papers/FTBroadcast.pdf.

Contents
1 TaxonomyClient-serverMulti-tierCluster computingCloud computingPeer-to-peer systems
2 Modeling Distributed SystemsComputationInteractionFailuresTime

Taxonomy
Taxonomy of Distributed Systems
Architectures:
Client-server
Multi-tier
Clusters
Cloud computing
Peer-to-Peer
Sensor networks → See companion course
Alberto Montresor (UniTN) DS - Models 2016/04/26 1 / 35
Taxonomy Client-server
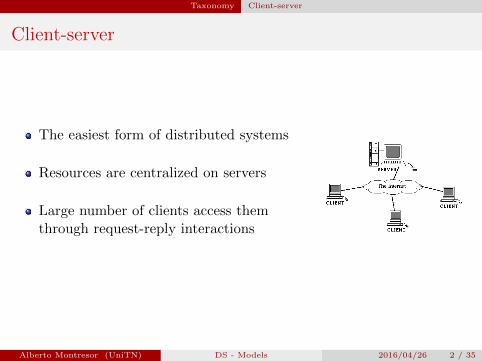
Client-server
The easiest form of distributed systems
Resources are centralized on servers
Large number of clients access themthrough request-reply interactions
Alberto Montresor (UniTN) DS - Models 2016/04/26 2 / 35

Taxonomy Client-server
Client-server: problem examples
Reliable message delivery
TCP/IP: Guarantee the delivery of message in FIFO order
Resource lease
DHCP: Lend limited resources for a predefined period of time
Remote procedure call
Allow invocation of procedures/methods/functions on remote objects
RPC (’60)CORBA (’90)Java RMI, .Net WCFJSON-RPC, XML-RPCGoogle Protocol Buffers, Apache Thrift, Apache Avro, TwitterFinagle
Alberto Montresor (UniTN) DS - Models 2016/04/26 3 / 35
Taxonomy Multi-tier
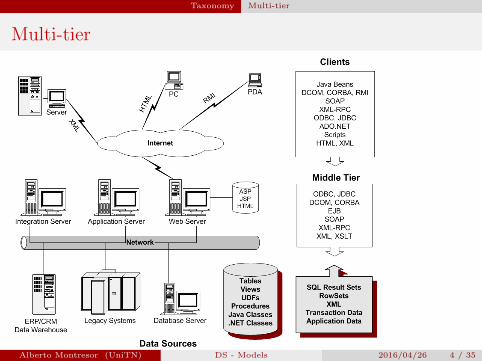
Multi-tier
Alberto Montresor (UniTN) DS - Models 2016/04/26 4 / 35

Taxonomy Multi-tier
Multi-tier: problem examples
Total order broadcast
Processes may not only to agree on which actions they should execute...But also in the order in which they are executed
Example
Initial state: Process A: c = 1, Process B: c = 1
Process A: [c← c · 3] [c← c + 1]
Process B: [c← c + 1] [c← c · 3]
Inconsistency!
Alberto Montresor (UniTN) DS - Models 2016/04/26 5 / 35
Taxonomy Cluster computing
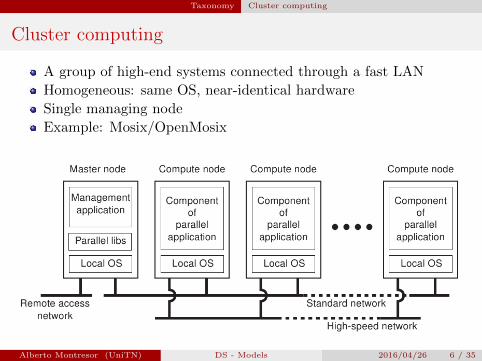
Cluster computing
A group of high-end systems connected through a fast LAN
Homogeneous: same OS, near-identical hardware
Single managing node
Example: Mosix/OpenMosix
Alberto Montresor (UniTN) DS - Models 2016/04/26 6 / 35

Taxonomy Cluster computing
Cluster computing: problem examples
Load balancing
Different nodes may be subject to different computational load
Possible techniques for load balancing:I Assign new tasks to under-loaded nodesI Migrate tasks from overloaded nodes to underloaded nodes
Message passing / synchronization
PVM, the Parallel Virtual MachineI provides a run-time environment for message-passing, task and
resource management, and fault notification
MPI, the Message Passing InterfaceI a standardized and portable message-passing system designed by a
group of researchers from academia and industry to function on awide variety of parallel computers
Alberto Montresor (UniTN) DS - Models 2016/04/26 7 / 35

Taxonomy Cloud computing
Cloud computing
Informal definition
Cloud computing is a general term that describes a new class ofnetwork-based computing taking place over the Internet (utilitycomputing)
A collection/group of integrated and networked hardware, softwareand Internet infrastructure (called a platform).
Using the Internet for communication and transport provideshardware, software and networking services to clients.
These platforms hide the complexity and details of the underlyinginfrastructure from users and applications by providing graphicalinterfaces or API
Alberto Montresor (UniTN) DS - Models 2016/04/26 8 / 35
Taxonomy Cloud computing
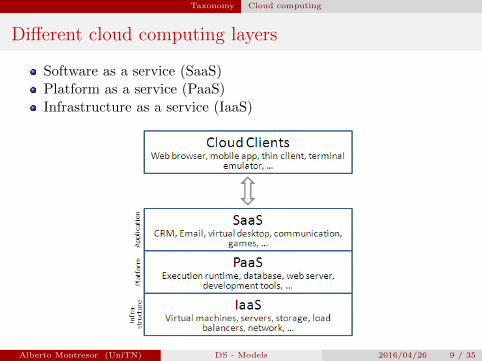
Different cloud computing layers
Software as a service (SaaS)Platform as a service (PaaS)Infrastructure as a service (IaaS)
Figure: Source: WikipediaAlberto Montresor (UniTN) DS - Models 2016/04/26 9 / 35

Taxonomy Cloud computing
An example: Amazon
Compute– Elastic Compute Cloud (EC2)– Elastic MapReduce– Auto Scaling
Content Delivery– CloudFront
Database– DynamoDB– Relational DB Service (RDS)
E-Commerce– Fulfillment Web Service (FWS)
Messaging– Simple Queue Service (SQS)– Simple Notification Service (SNS)
Monitoring– CloudWatch
Networking– Virtual Private Cloud (VPC)– Elastic Load Balancing
Payments & Billing– Flexible Payments Service (FPS)– DevPay
Storage– Simple Storage Service (S3)– Elastic Block Storage (EBS)– AWS Import/Export
Alberto Montresor (UniTN) DS - Models 2016/04/26 10 / 35

Taxonomy Peer-to-peer systems
Peer-to-peer
Definition
A peer-to-peer system is a collection of peer nodesEach peer is both a server and a client (“servent”)
Provides resources to other peers
Consumes resources from other peers
Characteristics:
Put together resources at the edge of the Internet
Share resources by direct exchange between nodes
Perform critical functions in a decentralized manner
Alberto Montresor (UniTN) DS - Models 2016/04/26 11 / 35
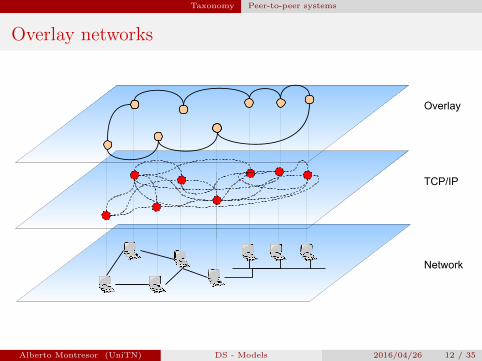
Taxonomy Peer-to-peer systems
Overlay networks
Network
TCP/IP
Overlay
Alberto Montresor (UniTN) DS - Models 2016/04/26 12 / 35

Taxonomy Peer-to-peer systems
Peer-to-peer systems: problem examples
P2P key-value stores
A peer-to-peer service that offers an associative Map interface:
put(Key k, Value v): associate a value v to the key k
Value get(Key k): returns the value associated to key k
(Distributed) Hash Tables:
Hash tables map keys to memory locations
Distributed hash tables map keys to nodes
Organization:
Each node is responsible for a portion of the key space
Messages are routed between nodes to reach responsible nodes
Replication used to tolerate failures
Alberto Montresor (UniTN) DS - Models 2016/04/26 13 / 35
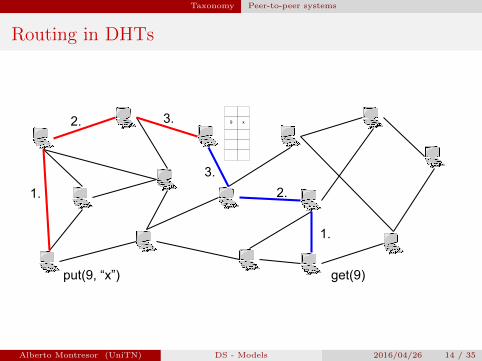
Taxonomy Peer-to-peer systems
Routing in DHTs
put(9, “x”) get(9)
1.
2. 3.
1.
2.
3.
9 x
Alberto Montresor (UniTN) DS - Models 2016/04/26 14 / 35

Modeling Distributed Systems
Contents
Modeling distributed systems
Computation: Processes, deterministic vs probabilistic behavior
Interaction: Processes interact through messages, which result in:I Communication, i.e. information flowI Coordination, i.e. synchronization and ordering of activities
Failures: Which kind of failures can occur?I Benign vs malicious (Byzantine)I Process vs communication
Time: Determining whether we can make any assumption on timebounds on communication and computation speeds.
Alberto Montresor (UniTN) DS - Models 2016/04/26 15 / 35

Modeling Distributed Systems Computation
Computation
Process: the unit of computation in a distributed system.Sometimes we may call it node, host, etc.
Process set: denoted by Π, it is composed by a collection of nuniquely identified processes, like p1, p2, . . . , pn.
Typical assumptions:I The set is static (n is well-defined);I Processes do know each otherI All processes run a copy of the same algorithm; the sum of all these
copies constitutes the distributed algorithm
But in extreme distributed systems:I Dynamic setI Too many, too dynamic to know them allI Multiple algorithms
Alberto Montresor (UniTN) DS - Models 2016/04/26 16 / 35

Modeling Distributed Systems Computation
Deterministic vs probabilistic
Deterministic process: the local computation and the messagessent by a process is determined by the current state and themessages previously received.
Probabilistic process: processes may make used of random oraclesto choose the local computation to be performed or the nextmessage to be sent.
Alberto Montresor (UniTN) DS - Models 2016/04/26 17 / 35

Modeling Distributed Systems Interaction
Interaction
Processes communicate through messagesI send(m, p): sends a message m to pI receive(m): receives a messages m
In some cases, messages may be uniquely identified byI Sender of the messageI A sequence number local to the sender
General assumption: every pair of processes is connected by abi-directional communication channel
I Through routingI Not true for P2P systems
Alberto Montresor (UniTN) DS - Models 2016/04/26 18 / 35

Interaction
Processes communicate through messagesI send(m, p): sends a message m to pI receive(m): receives a messages m
In some cases, messages may be uniquely identified byI Sender of the messageI A sequence number local to the sender
General assumption: every pair of processes is connected by abi-directional communication channel
I Through routingI Not true for P2P systems2
018-1
2-1
6
DS - Models
Modeling Distributed Systems
Interaction
Interaction
• In the receive operation, we do not specify the original sender; can be
• Fully connected topology may be obtained through routing. For
example, consider the following architectures:
– Fully connected mesh– broadcast medium (Ethernet, wireless)– Ring– “Internet” with routers

Modeling Distributed Systems Failures
Process failures
In a distributed systems, both processes and communication channelsmay fail, i.e. depart from what is considered its correct behavior.Hadzilacos and Toueg provide a taxonomy.
Benign process failures
Fail-stop: A process stops executing events, and other processesmay detect this fact.
Crash: A process stops executing events
Malicious process failures
Arbitrary failure, or Byzantine: any type of error may occur. Thismay be caused by:
I A software bugI A malicious behavior inspired by an intelligent adversary
Alberto Montresor (UniTN) DS - Models 2016/04/26 19 / 35

Modeling Distributed Systems Failures
Process failures
A process that never fails is correct
A process that eventually fails is faulty
Several protocols are designed to work correctly if the number offailures f is bounded (for example, f < n/3).
In some models, processes may perform a recovery action:I After some time, a process may resume functioningI It suffers amnesia: the local state maintained in volatile memory is
lostI To limit the effects of amnesia, a log can be maintained
Alberto Montresor (UniTN) DS - Models 2016/04/26 20 / 35

Process failures
A process that never fails is correct
A process that eventually fails is faulty
Several protocols are designed to work correctly if the number offailures f is bounded (for example, f < n/3).
In some models, processes may perform a recovery action:I After some time, a process may resume functioningI It suffers amnesia: the local state maintained in volatile memory is
lostI To limit the effects of amnesia, a log can be maintained2
018-1
2-1
6
DS - Models
Modeling Distributed Systems
Failures
Process failures
To avoid the problem of amnesia completely, every read/write would have to
pass through permanent memory; too expensive

Modeling Distributed Systems Failures
Communication failures
Benign communication failures
Process p performs send of a message m to process q
Message m is inserted in a local outgoing buffer of p(Send-omission)
Message m is transmitted from p to q (Omission)
Message m is inserted in a local incoming buffer of q(Receive-omission)
Process q performs receive of m
Malign communication failures
Messages created out of nothing, duplicated messages, etc.These problems can easily be solved through encryption techniques.
Alberto Montresor (UniTN) DS - Models 2016/04/26 21 / 35

Modeling Distributed Systems Failures
Communication failures
Possible causes of message failures:
Buffer overflow in the operating system
Congestion, routing errors in routers
Partitioning:I Processes are subdivided in disjoint sets called partitionsI Communication inside a partition is possibleI Communication between partitions is not possible
When a partition disappears, we say that partitions merge
Alberto Montresor (UniTN) DS - Models 2016/04/26 22 / 35

Modeling Distributed Systems Failures
Modeling (faulty) communication channels
The idea: the channels cannot systematically drop a specific message.This is the minimum abstraction needed to create reliable channels.
Fair-Loss Channels
Validity – Fair Loss: If a message m is sent infinitely often by aprocess p to a process q and neither p and q crash, then q willreceive m infinitely often
Integrity – Finite Duplication: If a message m is sent a finitenumber of times by a process p to a process q, then m cannot bereceived by q an infinite number of times
Integrity – No creation: If a message m is delivered by someprocess p, then m was previously sent by some process q to p
Alberto Montresor (UniTN) DS - Models 2016/04/26 23 / 35

Modeling Distributed Systems Failures
Modeling (correct) communication channels
The idea: channels are reliable, messages are never lost. It can beimplemented, but there is a price to be payed: asynchrony.
Perfect Channels
Validity – Reliable delivery: If p sends a message to q, and neitherof p and q crash, then q will eventually receive m
Integrity – No duplication: No message is delivered to a processmore than once
Integrity – No creation: If a message m is delivered by someprocess p, then m was previously sent by some process q to p
Alberto Montresor (UniTN) DS - Models 2016/04/26 24 / 35
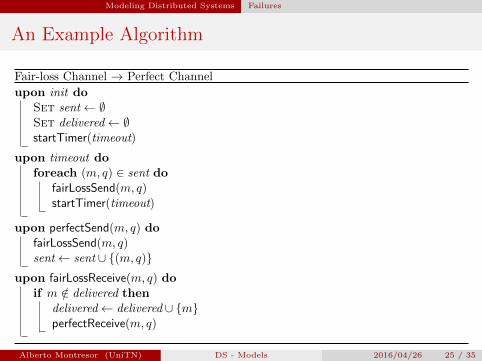
Modeling Distributed Systems Failures
An Example Algorithm
Fair-loss Channel → Perfect Channel
upon init doSet sent← ∅Set delivered← ∅startTimer(timeout)
upon timeout doforeach (m, q) ∈ sent do
fairLossSend(m, q)startTimer(timeout)
upon perfectSend(m, q) dofairLossSend(m, q)sent← sent ∪ {(m, q)}
upon fairLossReceive(m, q) doif m /∈ delivered then
delivered← delivered ∪ {m}perfectReceive(m, q)
Alberto Montresor (UniTN) DS - Models 2016/04/26 25 / 35

Modeling Distributed Systems Failures
Safety and liveness
Safety
“Something bad will never happen”
In other words, a distributed program should never enter anunacceptable state.
No message is delivered to a process more than once.
Liveness
“Something good eventually does happen”
In other words, a distributed program eventually enters a desirablestate.
If p sends a message to q, and neither of p and q crash, theneventually q will receive m.
Alberto Montresor (UniTN) DS - Models 2016/04/26 26 / 35

Modeling Distributed Systems Time
Time
Global clockI For presentation simplicity, it may be convenient to assume the
presence of a global real-time clock, outside the control of processes.I This can be used to provide a global ordering of steps in a
distributed systems
In reality:I Each process is associated with a local clockI Local clocks may not report the perfect timeI Clock drift rate: refers to the relative amount that a computer clock
differs from a perfect reference clock.
Synchronization is possible, but expensive:I Atomic clocksI GPSI See: Google TrueTime API:
Alberto Montresor (UniTN) DS - Models 2016/04/26 27 / 35

Time
Global clockI For presentation simplicity, it may be convenient to assume the
presence of a global real-time clock, outside the control of processes.I This can be used to provide a global ordering of steps in a
distributed systems
In reality:I Each process is associated with a local clockI Local clocks may not report the perfect timeI Clock drift rate: refers to the relative amount that a computer clock
differs from a perfect reference clock.
Synchronization is possible, but expensive:I Atomic clocksI GPSI See: Google TrueTime API:
2018-1
2-1
6
DS - Models
Modeling Distributed Systems
Time
Time
• GPS does not work into buildings
• Atomic clocks: cost not justified

Modeling Distributed Systems Time
Time measures associated to communication
Latency: The delay between the start of message sending from oneprocess and the beginning of its receipt by another. Possiblecauses:
I the actual time for bit transmission (e.g., satellite link)I the delay for accessing the network, especially in case of congestionI the time taken by the operating system to handle the message both
at sender and receiver
Bandwidth: Total amount of information that can be transmittedover a communication channel in a given time.
Jitter: Variation in the time taken to deliver a series of messages.Mostly related with multimedia data.
Alberto Montresor (UniTN) DS - Models 2016/04/26 28 / 35

Modeling Distributed Systems Time
Asynchronous vs synchronous
Distributed Systems vs Time
Distributed systems make difficult to reason about time, not only forlack of clock synchronization. It is also difficult to pose time bounds onevents and communication.
We may think about several different models:
Asynchronous distributed systems
Synchronous distributed systems
Partially synchronous distributed systems
Alberto Montresor (UniTN) DS - Models 2016/04/26 29 / 35

Asynchronous vs synchronous
Distributed Systems vs Time
Distributed systems make difficult to reason about time, not only forlack of clock synchronization. It is also difficult to pose time bounds onevents and communication.
We may think about several different models:
Asynchronous distributed systems
Synchronous distributed systems
Partially synchronous distributed systems2018-1
2-1
6
DS - Models
Modeling Distributed Systems
Time
Asynchronous vs synchronous
• Asynchronous distributed systems
– No assumptions can be made.– Most of the problems cannot be solved
• Synchronous distributed systems
– Precise assumptions are possible on computation,communication time and clocks.
– Not really realistic / difficult to implement
• Partially synchronous distributed systems
– Some assumptions can be made, others not, OR– Assumptions can be made statistically, OR– Assumptions hold for arbitrarily long periods of time

Modeling Distributed Systems Time
Asynchronous vs synchronous
Asynchronous distributed system
There are no bounds on the relative speed of process execution.
There are no bounds on message transmission delays.
There are no bounds on clock drift.I OR, since we cannot count on their precision at all, there are no
clocks.
Alberto Montresor (UniTN) DS - Models 2016/04/26 30 / 35

Modeling Distributed Systems Time
Asynchronous vs synchronous
Comments
These are not assumptions! These are “lack of assumptions”!
The worst possible model: services as simple as:I failure detectionI time-based coordination
are not possible
Advantages:I simple semanticsI easier to port to more “powerful” modelsI More realistic: several sources of asynchrony are present in a
large-scale network (like the Internet)
Alberto Montresor (UniTN) DS - Models 2016/04/26 31 / 35

Modeling Distributed Systems Time
Asynchronous vs synchronous
Synchronous Distributed Systems
Synchronous computation:There is a known upper bound on the relative speed of processexecution.
Synchronous communication:There is a known upper bound on message transmission delays.
Synchronous clocks:Processes are equipped with local clocks. There is a known upperbound on the drift rates of local clocks with respect to a globalreal-time clock.
Alberto Montresor (UniTN) DS - Models 2016/04/26 32 / 35

Modeling Distributed Systems Time
Asynchronous vs synchronous
Comments
The best possible model. Can be built, but not with standardhardware/software.
I Synchronous Ethernet vs CSMA/CD EthernetI Real-time OS vs normal OS
Many interesting properties:I Timed failure detection (e.g., ping)I Coordination based on time (e.g., lease)I Worst-case performance analysisI Synchronized clocks
Alberto Montresor (UniTN) DS - Models 2016/04/26 33 / 35

Modeling Distributed Systems Time
Asynchronous vs synchronous
Partial synchrony
For most systems we know of, it is relatively easy to define physicaltime bounds that are respected most of the time. There are howeverperiods where the timing assumptions do not hold.
Delays on processes:I Machines may run out of memory, slowing down processesI A typical case of “no bound on relative speeds of processes”
Delays on messages:I Network may congested, and messages may be dropped.I Re-transmission protocols can ensure reliability, but at the price of
asynchronyMessages may be re-transmitted an arbitrary number of times.
Alberto Montresor (UniTN) DS - Models 2016/04/26 34 / 35
Asynchronous vs synchronous
Partial synchrony
For most systems we know of, it is relatively easy to define physicaltime bounds that are respected most of the time. There are howeverperiods where the timing assumptions do not hold.
Delays on processes:I Machines may run out of memory, slowing down processesI A typical case of “no bound on relative speeds of processes”
Delays on messages:I Network may congested, and messages may be dropped.I Re-transmission protocols can ensure reliability, but at the price of
asynchronyMessages may be re-transmitted an arbitrary number of times.
2018-1
2-1
6
DS - Models
Modeling Distributed Systems
Time
Asynchronous vs synchronous
In this sense, practical systems are partially synchronous

Modeling Distributed Systems Time
Asynchronous vs synchronous
How to express partial synchrony? A possibility is the following:
Timing assumptions only hold eventually.
Theoretically, it means:
There is a time after which the system is synchronous forever
The system is initially asynchronous and only after a long timebecomes synchronous
How to read it:
The system is not always synchronous
There is no known bound to the period in which it is asynchronous
We expect that there are periods during which the system issynchronous
Some of these periods are long enough to terminate protocolexecution
Alberto Montresor (UniTN) DS - Models 2016/04/26 35 / 35

Reading Material
V. Hadzilacos and S. Toueg. A modular approach to fault-tolerant broadcastsand related problems.
In S. Mullender, editor, Distributed Systems (2nd ed.). Addison-Wesley, 1993.
http://www.disi.unitn.it/~montreso/ds/papers/FTBroadcast.pdf


















