
Distributed Synchronization. Clock Synchronization When each machine has its own clock, an event...
70
Distributed Synchronization
-
Upload
frederick-simpson -
Category
Documents
-
view
227 -
download
0
Transcript of Distributed Synchronization. Clock Synchronization When each machine has its own clock, an event...

Distributed Synchronization

Clock Synchronization
When each machine has its own clock, an event that occurred after another event may nevertheless be assigned an earlier time.

Physical Clocks Clock SynchronizationMaximum resolution desired for global time keeping determines the maximum difference which can be tolerated between “synchronized” clocks
The time keeping of a clock, its tick rate should satisfy:
The worst possible divergence δ between two clocks is thus:
So the maximum time Δt between clock synchronization operations that can ensure δ is:
11
tC
t 2
2
t

Physical Clocks Clock Synchronization
Christian’s Algorithm– Periodically poll the machine with access to the reference time source
– Estimate round-trip delay with a time stamp
– Estimate interrupt processing time • figure 3-6, page 129 Tanenbaum
– Take a series of measurements to estimate the time it takes for a timestamp to make it from the reference machine to the synchronization target
– This allows the synchronization to converge within δ with a certain degree of confidence
Probabilistic algorithm and guarantee

Physical Clocks Clock Synchronization
Wide availability of hardware and software to keep clocks synchronized within a few milliseconds across the Internet is a recent development– Network Time Protocol (NTP) discussed in papers by David Mill(s)– GPS receiver in the local network synchronizes other machines– What if all have GPS receivers
Increasing deployment of distributed system algorithms depending on synchronized clocks
Supply and demand constantly in flux
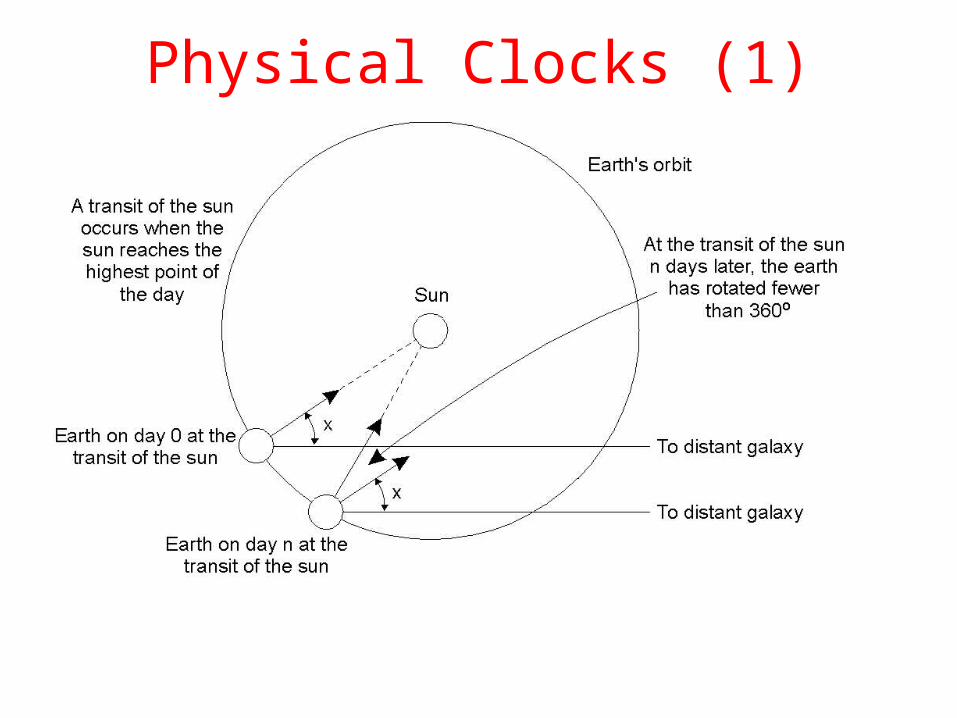
Physical Clocks (1)
Computation of the mean solar day.

Physical Clocks (2)
TAI seconds are of constant length, unlike solar seconds. Leap seconds are introduced when necessary to keep in phase with
the sun.
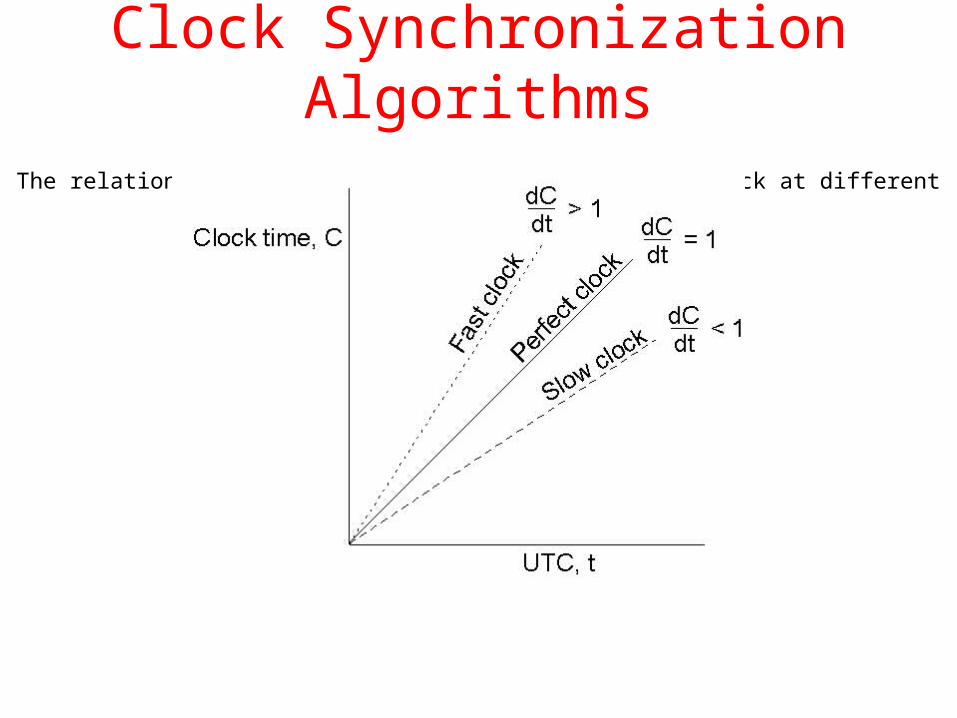
Clock Synchronization Algorithms
The relation between clock time and UTC when clocks tick at different rates.
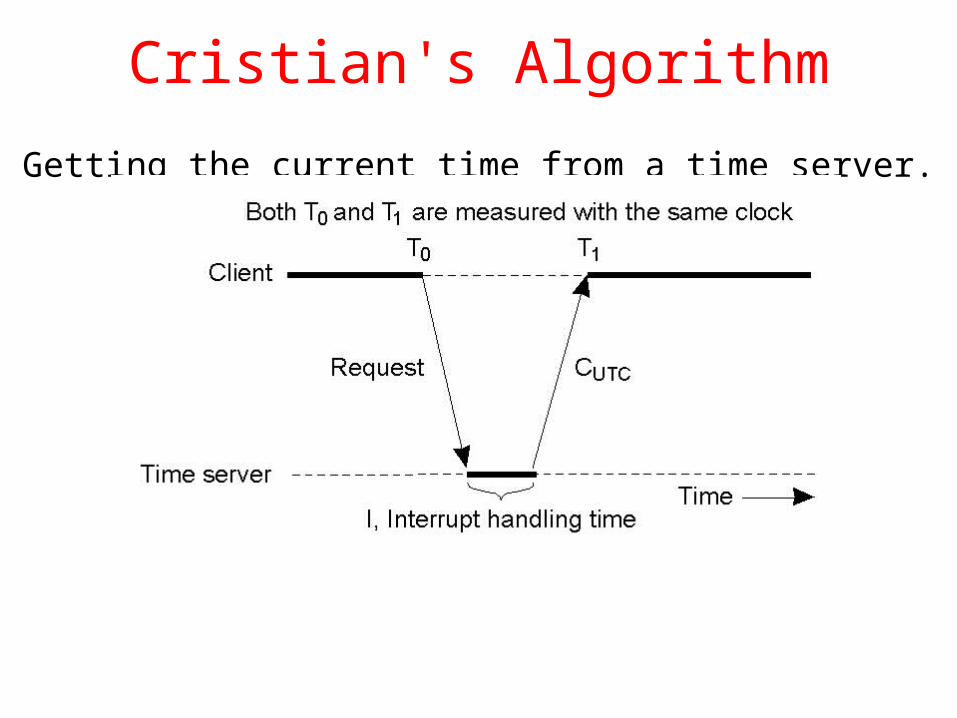
Cristian's Algorithm
Getting the current time from a time server.
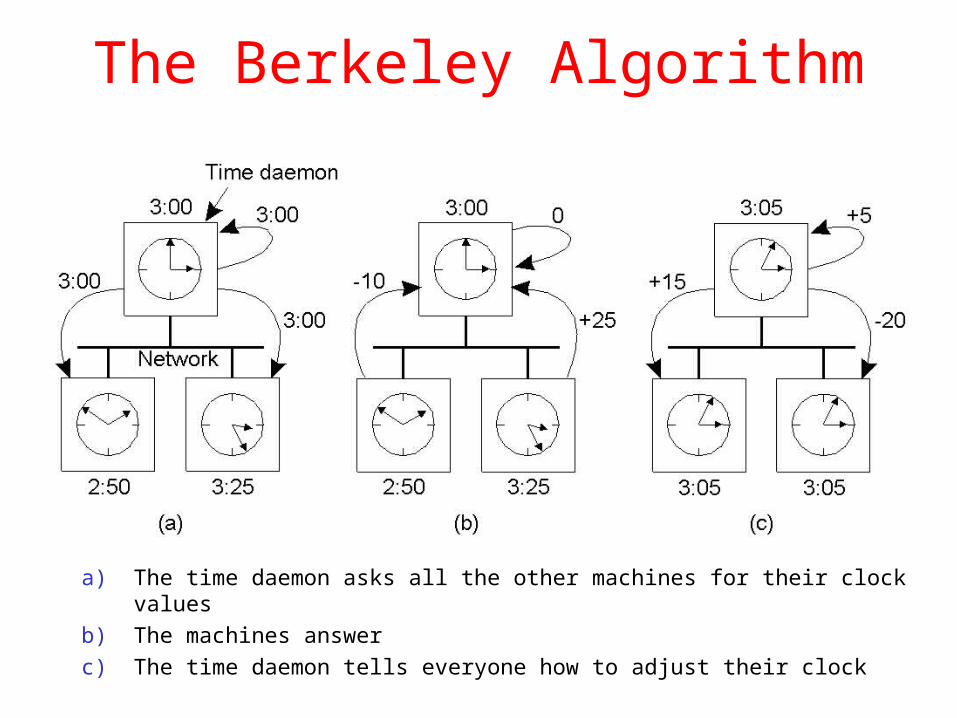
The Berkeley Algorithm
a) The time daemon asks all the other machines for their clock values
b) The machines answer
c) The time daemon tells everyone how to adjust their clock

Lamport Timestamps
a) Three processes, each with its own clock. The clocks run at different rates.
b) Lamport's algorithm corrects the clocks.

Example: Totally-Ordered Multicasting
Updating a replicated database and leaving it in an inconsistent state.
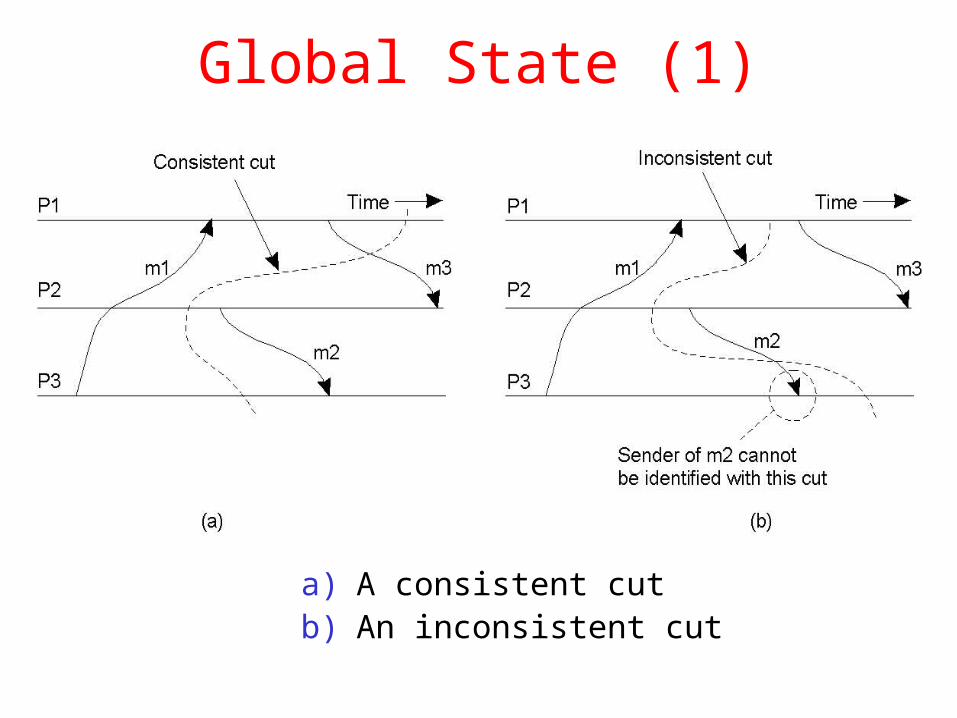
Global State (1)
a) A consistent cutb) An inconsistent cut

Global State (2)
a) Organization of a process and channels for a distributed snapshot
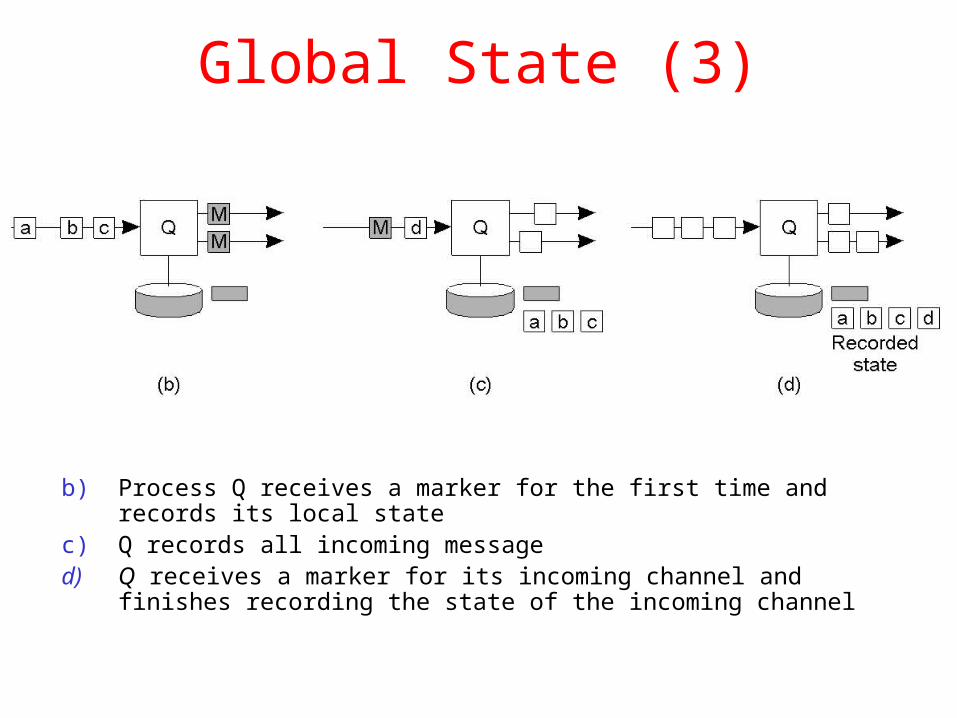
Global State (3)
b) Process Q receives a marker for the first time and records its local state
c) Q records all incoming messaged) Q receives a marker for its incoming channel and finishes recording
the state of the incoming channel
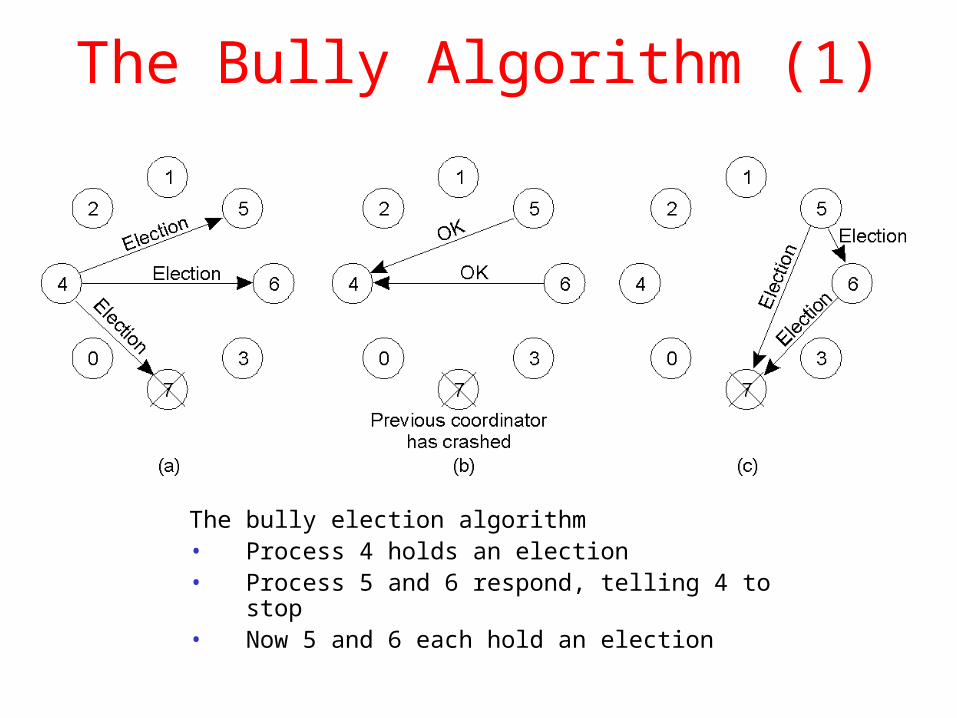
The Bully Algorithm (1)
The bully election algorithm• Process 4 holds an election• Process 5 and 6 respond, telling 4 to stop• Now 5 and 6 each hold an election

Mutual ExclusionDistributed components still need to coordinate their actions, including but not limited to access to shared
data– Mutual exclusion to some limited set of operations and data is thus required
Consider several approaches and compare and contrast their advantages and disadvantages
Centralized Algorithm– The single central process is essentially a monitor
– Central server becomes a semaphore server
– Three messages per use: request, grant, release
– Centralized performance constraint and point of failure

Mutual ExclusionDistributed Algorithm Factors
Functional Requirements1) Freedom from deadlock
2) Freedom from starvation
3) Fairness
4) Fault tolerance
Performance Evaluation– Number of messages
– Latency
– Semaphore system Throughput
Synchronization is always overhead and must be accounted for as a cost

Mutual Exclusion Distributed Algorithm Factors
Performance should be evaluated under a variety of loads
– Cover a reasonable range of operating conditions
We care about several types of performance– Best case
– Worst case
– Average case
Different aspects of performance are important for different reason and in different contexts

Mutual ExclusionLamport’s Algorithm
Every site keeps a request queue sorted by logical time stamp
– Uses Lamport’s logical clocks to impose a total global order on events associated with synchronization
Algorithm assumes ordered message delivery between every pair of communicating sites
– Messages sent from site Sj in a particular order arrive at Sj in the same order
– Note: Since messages arriving at a given site come from many sources the delivery order of all messages can easily differ from site to site

Lamport’s Algorithm Request Resource r
Thus, each site has a request queue containing resource use requests and replies
Note that the requests and replies for any given pair of sites must be in the same order in queues at both sites– Because of message order delivery assumption
i
jii
euerequest_qu queuse local on therequest theplaces and S toj),REQUEST(ts sends S Site 1) rR
i resource using processes all ofset theis R- i
j
i
iij
euerequest_quon request theplaces and S site tomessage REPLY stamped timea
returnsit S site from ),REQUEST(ts receives S siteWhen 2) i

Lamport’s Algorithm Entering CS for Resource r
Site Si enters the CS protecting the resource when
– This ensures that no message from any site with a smaller timestamp could ever arrive
– This ensures that no other site will enter the CS
Recall that requests to all potential users of the resource and replies from then go into request queues of all processes including the sender of the message
i),(tsn larger tha stamp time a with sitesother all from message a received has S Site L1)
i
i
i
i
euerequest_qu queue theof head at the is S site fromrequest The L2)

Lamport’s Algorithm Releasing the CS
The site holding the resource is releasing it, call that site
– Note that the request for resource r had to be at the head of the request_queue at the site holding the resource or it would never have entered the CS
– Note that the request may or may not have been at the head of the request_queue at the receiving site
iS
rR j
ii
S tomessage i)RELEASE(r, a sends and euerequest_qu offront thefromrequest its removes S Site 1)
ji
j
euerequest_qu from r),REQUEST(ts removesit message i)RELEASE(r, a receives S site When 2)
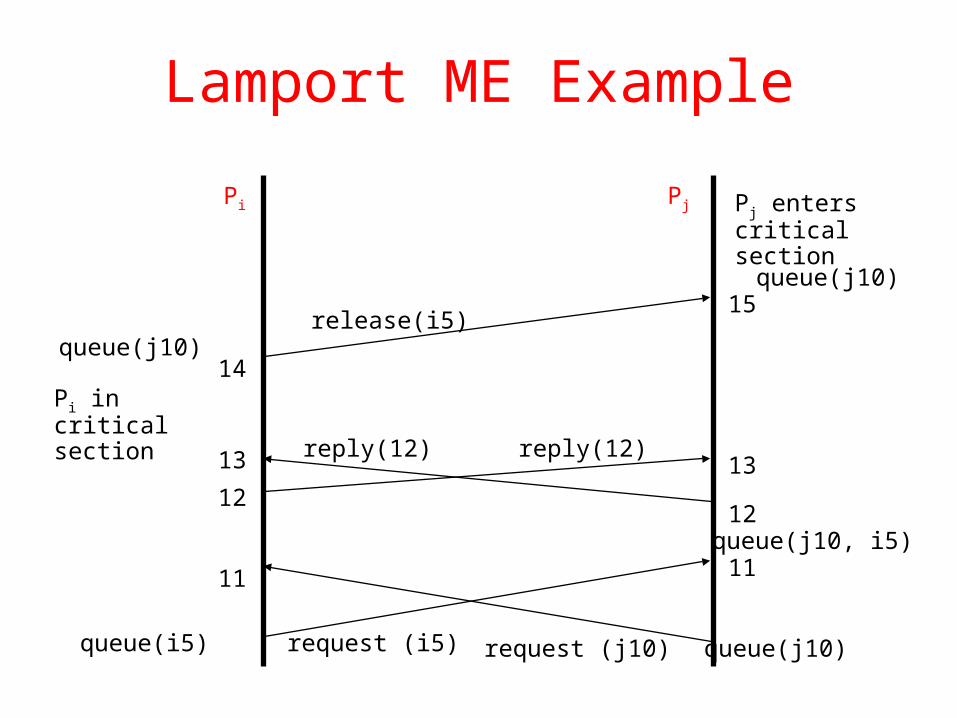
Lamport ME Example
request (i5) queue(j10)
reply(12)
queue(i5)
Pi incriticalsection
queue(j10, i5)
request (j10)
release(i5)queue(j10)
queue(j10)
Pj enterscriticalsection
reply(12)
11 11
14
12
13
12
13
15
Pi Pj

Lamport’s AlgorithmComments
Performance: 3(N-1) messages per CS invocation since each requires (N-1) REQUEST, REPLY,
and RELEASE messages
Observation: Some REPLY messages are not required
– If sends a request to and then receives a REQUEST from with a timestamp smaller than its own REQUEST
– need not send a reply to because it already has enough information to make a decision
– This reduces the messages to between 2(N-1) and 3(N-1)
As a distributed algorithm there is no single point of failure but there is increased overhead
iS
jSiS
iS
jS

Ricart and AgrawalaRefine Lamport’s mutual exclusion by merging the REPLY and RELEASE messages
– Assumption: total ordering of all events in the system implying the use of Lamport’s logical clocks with tie breaking
Request CS (P) operation:1) Site requesting the CS creates a message and sends it to all processes using the CS including itself
– Messages are assumed to be reliably delivered in order
– Group communication support can play an obvious role
i),REQUEST(tsiiS

Ricart and AgrawalaReceive a CS Request
If the receiver is not currently in the CS and does not have pending request for it in its request_queue – Send REPLY
If the receiver is already in the CS – Queue the request, sending no reply
If the receiver desires the CS but has not entered– Compare the TS of its request to that just received– REPLY if received is newer– Queue the request if pending request is newer

Ricart and AgrawalaEnter a CS
– A process enters the CS when it receives a REPLY from every member of the group that can use the CS
Leave a CS– When the process leaves the CS it sends a REPLY to the senders of all pending messages on its queue
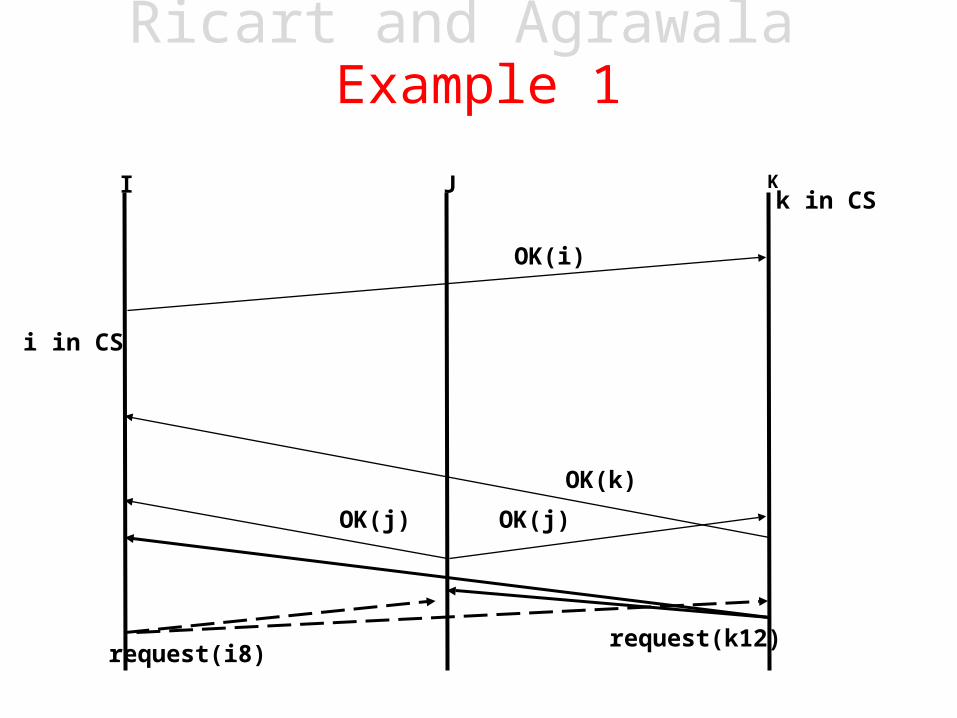
i in CS
k in CS
request(i8)request(k12)
OK(j)OK(j)
OK(k)
OK(i)
I J K
Ricart and Agrawala Example 1
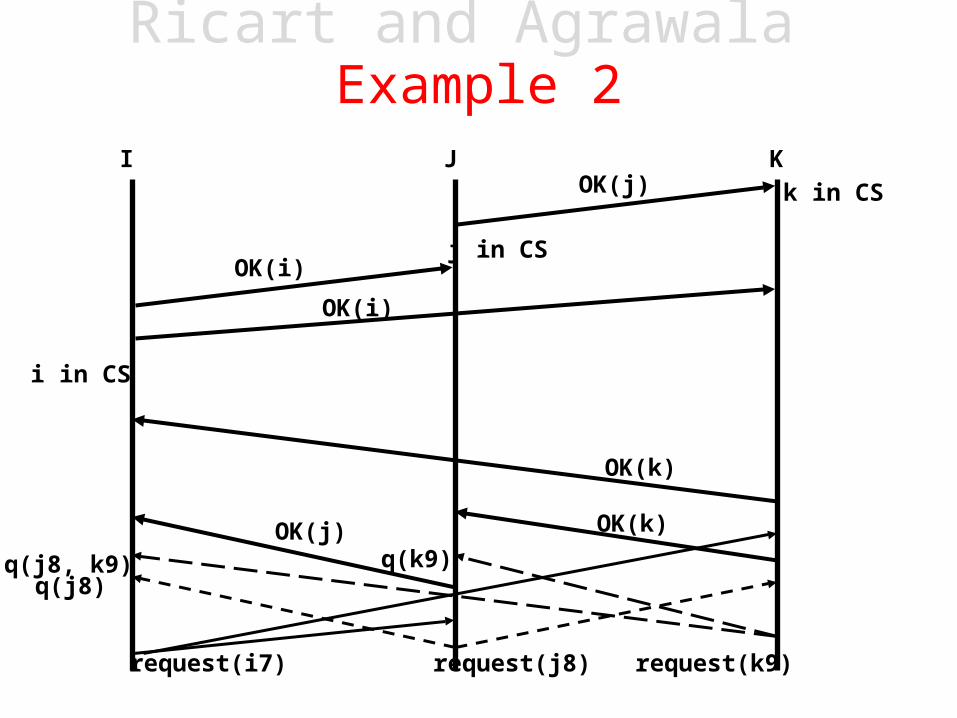
request(i7)
I J K
request(j8) request(k9)
OK(k)OK(j)
OK(k)
i in CS
OK(i)
k in CS
q(j8)q(j8, k9) q(k9)
j in CSOK(i)
Ricart and Agrawala Example 2
OK(j)

Ricart and AgrawalaObservations
The algorithm works because the global logical clock ensures a global total ordering on events– This ensures, in turn, that the decision about who enters the CS is unambiguous
Single point of failure is now N points of failure – A crashed group member cannot be distinguished from a busy CS– Distributed and “optimized” version is N times more vulnerable than the centralized version!– Explicit message denying entry helps reliability and converts this into busy wait

Ricart and AgrawalaObservations
Either group communication support is used, or each user of the CS must keep track of all other potential
users correctly– Powerful motivation for standard group communication primitives
Argument against a centralized server said that a single process involved in each CS decision was bad– Now we have N processes involved in each decision
Improvements: get a majority - Makaewa’s algorithm
Bottom Line: a distributed algorithm is possible– Shows theoretical and practical challenges of designing distributed algorithms
that are useful

Token Passing Mutex
General structure– One token per CS token denotes permission to enter
– Only process with token allowed in CS
– Token passed from process to process logical ring
Mutex– Pass token to process i + 1 mod N
– Received token gives permission to enter CS• hold token while in CS
– Must pass token after exiting CS
– Fairness ensured: each process waits at most N-1 entries to get CS

Token Passing Mutex
Correctness is obvious– No starvation since passing is in strict order
Difficulties with token passing mutex– Idle case of no process entering CS pays overhead of constantly passing
the token
– Lost tokens: diagnosis and creating a new token
– Duplicate tokens: ensure generation of only one token
– Crashes: require a receipt to detect dead destinations
– Receipts double the message overhead
Design challenge: holding time for unneeded token
– Too short high overhead, too long high CS latency

Mutex ComparisonCentralized
– Simplest and most efficient
– Centralized coordinator crashes create the need to detect crash and choose a new coordinator
– M/use: 3; Entry Latency: 2
Distributed– 3(N-1) messages per CS use (Lamport)
– 2(N-1) messages per CS use (Ricart & Agrawala)
– If any process crashes with a non-empty queue, algorithm won’t work
– M/use: 2(N-1); Entry Latency: 2(N-1)

Mutex ComparisonToken Ring
– Ensures fairness – Overhead is subtle no longer linked to CS use– M/use: 1 ; Entry Latency: 0 N-1– This algorithm pays overhead when idle– Need methods for re-generating a lost token
Design Principle: building fault handling into algorithms for distributed systems is hard– Crash recovery is subtle and introduces overhead in normal operation
Performance Metrics: M/use and Entry Latency

Centralized approaches often necessary– Best choice in mutex, for example
– Need method of electing a new coordinator when it fails
General assumptions– Give processes unique system/global numbers (e.g. PID)
– Elect process using a total ordering on the set
– All processes know process number of members
– All processes agree on new coordinator
– All do not know if it is up or down election algorithm is responsible for determining this
Design challenge: network delay vs. crashed peer
Election Algorithms

Bully AlgorithmSuppose the coordinator doesn’t respond to P1 request
– P1 holds an election by sending an election message to all processes with higher numbers– If P1 receives no responses, P1 is the new coordinator– If any higher numbered process responds, P1 ends its election
Process receives an election request – Reply to the sender tells it that it has lost the election– Holds an election of its own– Eventually all but highest surviving process give up
Process recovering from a crash takes over if highest

Example: Processes 0-7, 4 detects that 7 has crashed
4 holds election and loses
5 holds election and loses
6 holds election and wins
Message overhead variable
Who starts an election matters
Solid lines say “Am I leader?”
Dotted lines say “you lose”
Hollow lines say “I won”
6 becomes the coordinator
When 7 recovers it is a bully and sends “I win” to all
Bully Algorithm
2 1
54
0
73
6

Processes have a total order known by all– Each process knows its successor forming a ring
– Ring: mod N
– So the successor of Pi is P(i+1) mod N
– No token involved
Any process Pi noticing that the coordinator is not responding
– Sends an election message to its successor P(i+1) mod N
– If successor is down, send to next member timeout
– Receiving process adds its number to the message and passes it along
Ring Algorithm

When election message gets back to election initiator– Change message to coordinator– Circulate to all members– Coordinator is highest process in the total order– All processes know the order and thus all will agree no matter how the election started
Strength– Only one coordinator chosen
Weakness– Scalability: latency increases with N because the algorithm is sequential
Ring Algorithm

What if more than one process detects a crashed coordinator?– More than one election will be produced: message storm– All messages will contain the same information: member process numbers and order of members– Same coordinator is chosen (highest number)
Refinement might include filtering duplicate messages
Some duplicates will happen– Consider two elections chasing each other– Eliminate one initiated by lower numbered process– Duplicated until lower reaches source of the higher
Ring Algorithm
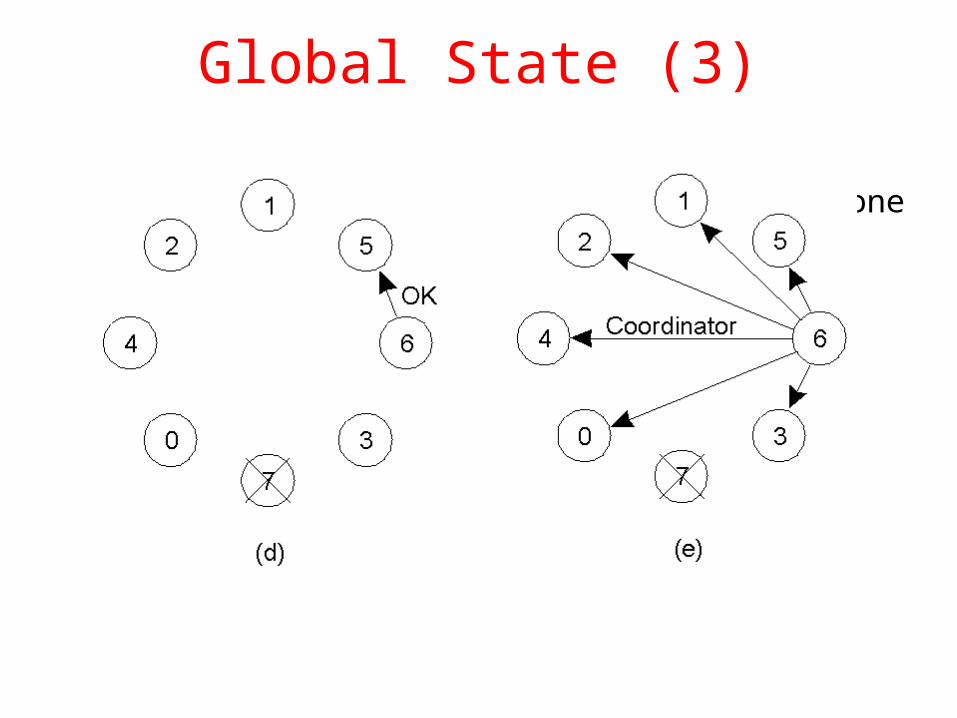
Global State (3)
d) Process 6 tells 5 to stope) Process 6 wins and tells everyone

A Ring Algorithm
Election algorithm using a ring.
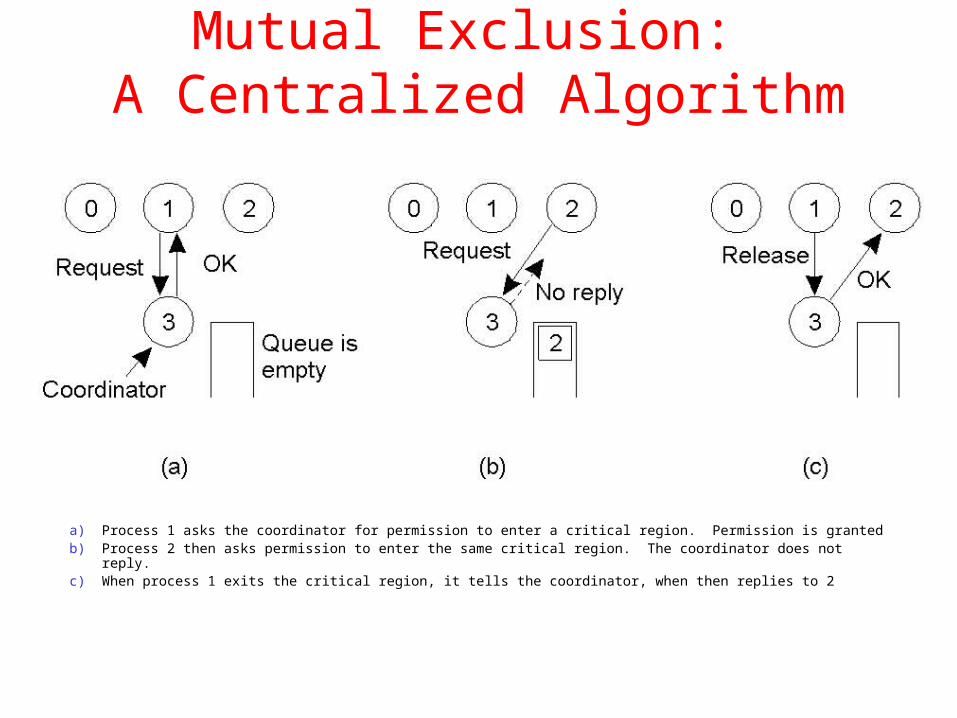
Mutual Exclusion: A Centralized Algorithm
a) Process 1 asks the coordinator for permission to enter a critical region. Permission is grantedb) Process 2 then asks permission to enter the same critical region. The coordinator does not reply.c) When process 1 exits the critical region, it tells the coordinator, when then replies to 2
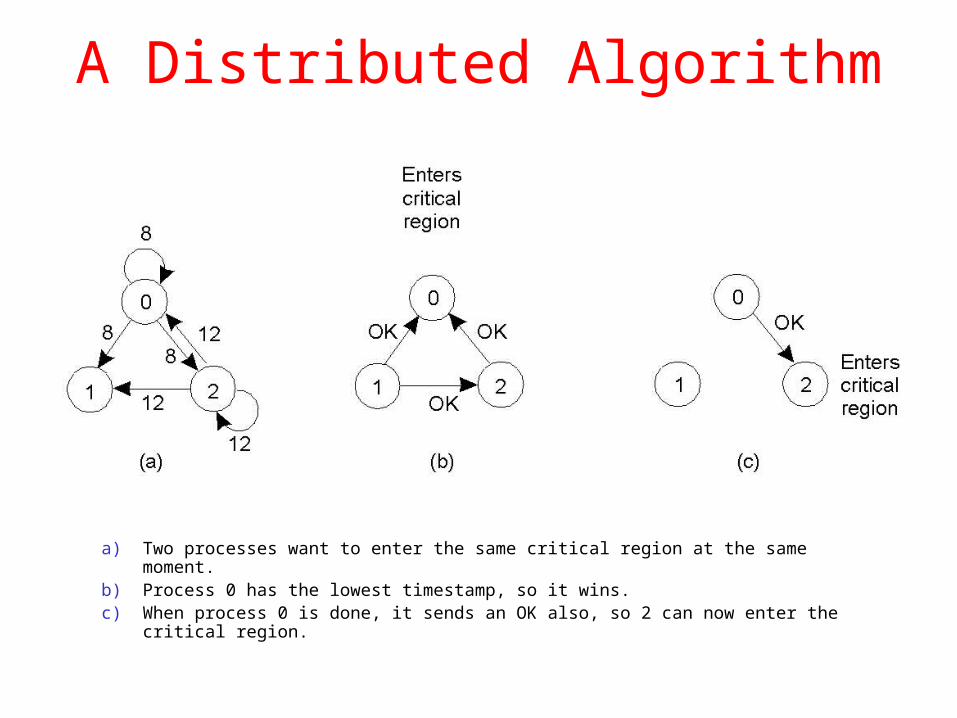
A Distributed Algorithm
a) Two processes want to enter the same critical region at the same moment.b) Process 0 has the lowest timestamp, so it wins.c) When process 0 is done, it sends an OK also, so 2 can now enter the critical
region.
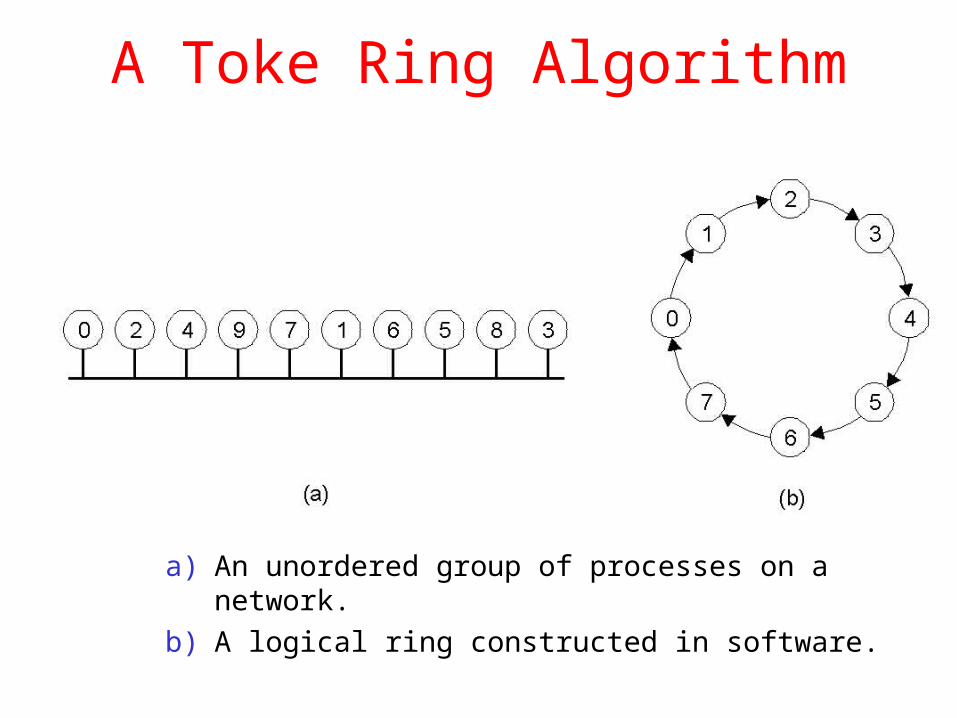
A Toke Ring Algorithm
a) An unordered group of processes on a network.
b) A logical ring constructed in software.
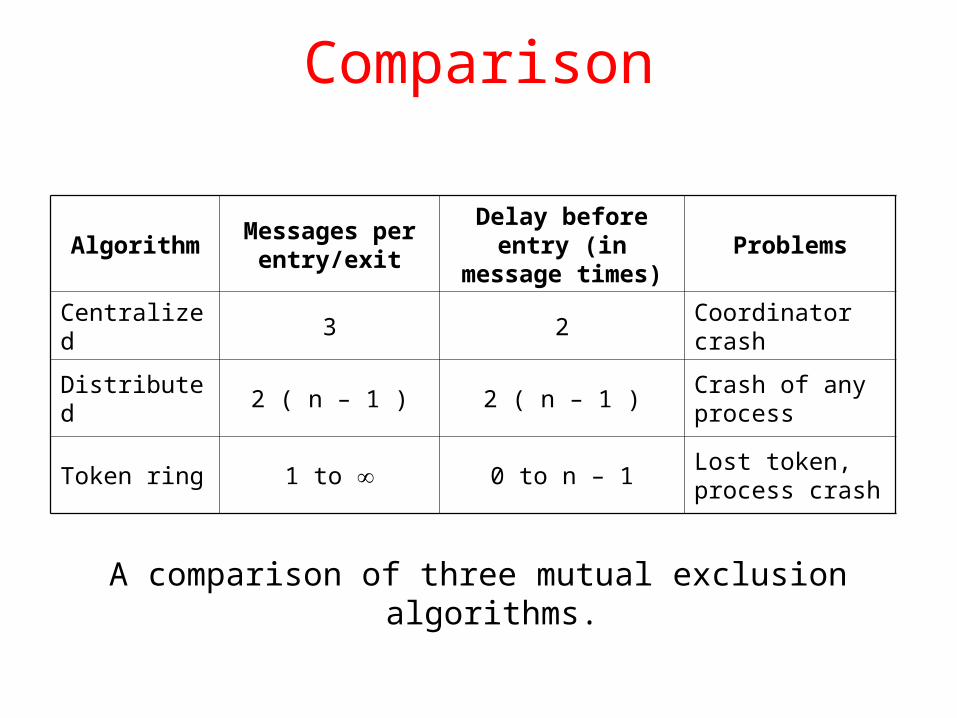
Comparison
A comparison of three mutual exclusion algorithms.
AlgorithmMessages per
entry/exitDelay before entry (in message times)
Problems
Centralized 3 2 Coordinator crash
Distributed 2 ( n – 1 ) 2 ( n – 1 )Crash of any process
Token ring 1 to 0 to n – 1Lost token, process crash

DeadlocksDefinition: Each process in a set is waiting for a resource to be released by another process in set
– The set is some subset of all processes– Deadlock only involves the processes in the set
Remember the necessary conditions for DL
Remember that methods for handling DL are based on preventing or detecting and fixing one or more necessary conditions

Deadlocks Necessary Conditions
Mutual exclusion– Process has exclusive use of resource allocated to it
Hold and Wait– Process can hold one resource while waiting for another
No Preemption– Resources are released only by explicit action by controlling process
– Requests cannot be withdrawn (i.e. request results in eventual allocation or deadlock)
Circular Wait– Every process in the DL set is waiting for another process in the set,
forming a cycle in the SR graph

Deadlock Handling StrategiesNo strategy
Prevention– Make it structurally impossible to have a deadlock
Avoidance– Allocate resources so deadlock can’t occur
Detection– Let deadlock occur, detect it, recover from it

No Strategy The “Ostrich Algorithm”
Assumes deadlock rarely occurs– Becomes more probable with more processes
Catastrophic consequences when it does occur– May need to re-boot all or some machines in system
Fairly common and works well when – DL is rare and – Other sources of instability are more common
How reboots of Window or MacOS are prompted by DL?

Deadlock Prevention
Ordered resource allocation most common example
– Consider link with two-phase-locking grow and shrink
Works but requires global view of all resources– A total order on resources must exist for the system
– Process code must allocate resources in order
Under utilizes resources when period of use of a resource conflict with the total resource order– Consider process Pi and Pk using resources R1 and R2
– Pi uses R1 90% of its execution time and R2 10%
– Pk uses R2 90% of its execution time and R1 10%
– One holds one resource far too long

Deadlock Avoidance
General method: Refuse allocations that may lead to deadlock
– Method for keeping track of states
– Need to know resources required by a process
Banker’s algorithm– Must know maximum number allocated to Pi
– Keep track of resources available
– For each request, make sure maximum need will not exceed total available
– Under utilizes resources
Never used– Advance knowledge not available and CPU-intensive

Deadlock Detection and ResolutionAttractive for two main reasons
– Prevention and avoidance are hard, have significant overhead, and require information difficult or impossible to obtain– Deadlock is comparatively rare in most systems so a form of the argument for optimistic concurrency control applies: detect and fix comparatively rare situations
Availability of transactions helps– DL resolution requires us to kill some participant(s)– Transactions are designed to be rolled back and restarted

Centralized Deadlock Detection
General method: Construct a resource graph and analyze it
– Analyze through resource reductions
– If cycle exists after analysis, deadlock has occurred
– Processes in cycle are deadlocked
Local graphs on each machine– Pi requests R1
– R1’s machine places request in local graph
– If cycle exists in local graph, perform reductions to detect deadlock
Need to calculate union of all local graphs– Deadlock cycle may transcend machine boundaries

Cycles don’t always mean deadlock!
P2 P3
P1
Graph Reduction
P2 P3
P1
P2 P3No Deadlock
Deadlock
R1 R2
P3
P1
P2P2 P3
P1
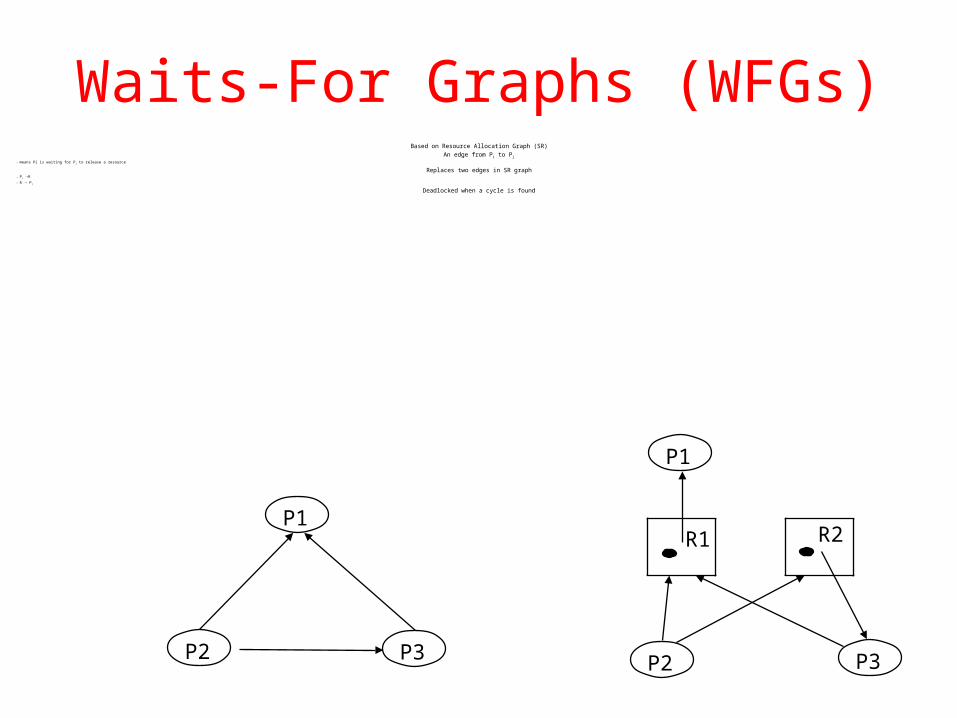
Waits-For Graphs (WFGs)Based on Resource Allocation Graph (SR)
An edge from Pi to Pj
– means Pi is waiting for P j to release a resource
Replaces two edges in SR graph– Pi R
– R Pj
Deadlocked when a cycle is found

Centralized Deadlock Detection
All hosts communicate resource state to coordinator
– Construct global resource graph on coordinator
– Coordinator must be reliable and fast
– When to construct the graph is an important choice
Report every resource operation (request, acquire, release)
– Large overhead and significant use latency
Periodically send set of operations
– Lower overhead and use latency, detection latency
Whenever a need for cycle detection is indicated
– Central or local decision
All have drawbacks b/c of false deadlocks

False DeadlockProblem: messages may not arrive in a timely fashion
– Inconsistent and out-of-date world view at a particular machine– In particular, out-of-order arrival
Assume two processes on two machines and two resources– P2 releases R2 (message A)– P1 requests instance of R2 (message B)
P1
R1 M1
P2
R2R1M2
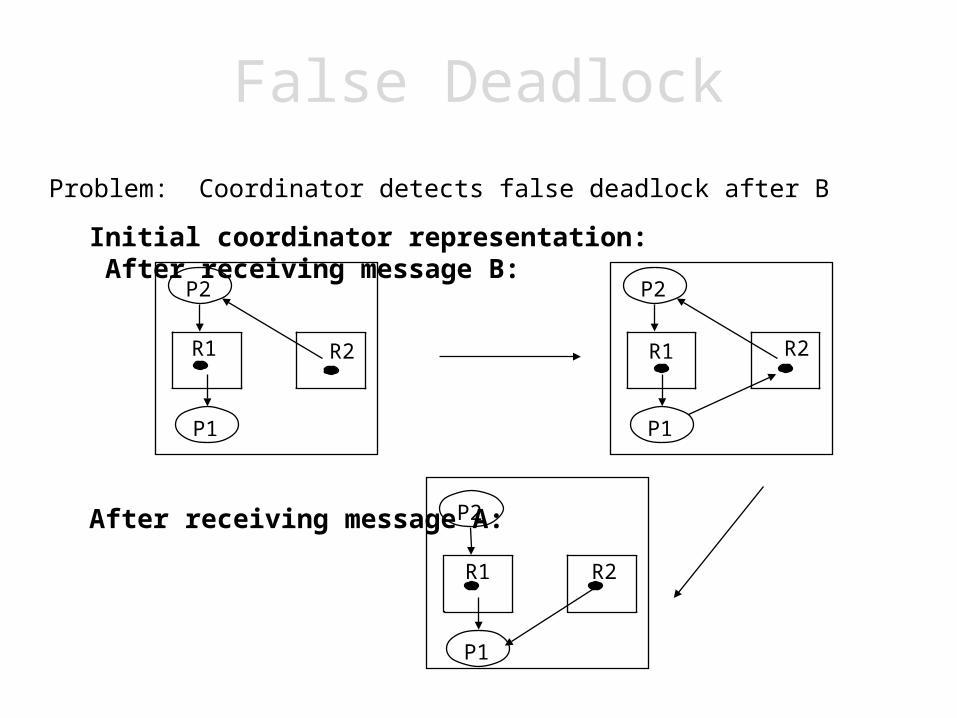
Problem: Coordinator detects false deadlock after B
False Deadlock
Initial coordinator representation: After receiving message B:
After receiving message A: P2
R2R1
P1
P2
R2R1
P1
P2
R2R1
P1

False Deadlock
Lack of global message delivery order causes false DL
– Could apply Lamport’s global virtual clock
– Expensive
Coordinator detects potential DL– Requests all outstanding messages with lower timestamp
Aim is to establish a common global message order– Establishes a total order on resource operations
– Establishes a common world view and thus common decision making
Fixes some false deadlocks, but others are harder

Distributed Deadlock DetectionChandry-Misra-Haas algorithm
– Processes can request more than one resource with a single message process can wait on several resources– Amortize message overhead– Speed growing phase
Use waits-for graph to represent system state– Dependencies across machine boundaries make looking for cycles hard
A process sends probe messages when it has to wait– If message gets back, deadlock has occurred

Distributed Deadlock DetectionWhen process has to wait
– Send message to process holding resources– Recipient forwards to all processes it is waiting on– Creates concurrent probe of wait-for graph for cycles
If message gets back to originator – Cycle exists in wait-for graph so deadlock has occurred– Note that first field of message will always be the initiator
Many messages every time a process blocks

Distributed Deadlock DetectionAn Example
P0 gets blocked, resource held by P1
– Initial message from P0 to P1 : (0, 0, 1)
P1 waiting on P2
– P1 sends message (0, 1, 2) to P2
P2 waiting on P3: (0, 2, 3)
P3 waiting on P4 and P5: (0, 3, 4) and (0, 3, 5)
P5 chain ends, but P4 P6 P8
But P8 is waiting on P0: – P0 gets message, sees itself as the initiator: (0, 8, 0)
– A cycle thus exists
– P0 knows there is deadlock

Distributed DeadlockResolution
Some process in the cycle must be killed– Structuring resource use as transactions makes this better behaved and easier to understand
Race Condition:– Two processes block at the same time and send probes– Both discover the cycle in parallel– Damping difficult as it is hard to tell what messages may be killed killing process must know the cycle
Practice should emphasize the simplest and cheapest– Most cycles are between two processes– Example of importance of gathering performance data

Distributed Deadlock Prevention
Prevention– Careful design to make deadlocks structurally impossible
Make sure at least one of the 4 necessary conditions for deadlock cannot hold
– Process can only hold one resource at a time
– Request all resources initially
– Process releases all resources before requesting new one
– Resource ordering
All are cumbersome in practice
Distribution opens some new possibilities– Lamport clocks create total order preventing cycles

SummaryWe began with clocks and saw how relaxing the semantic requirement for real-time made Lamport’s logical clocks possible
Given global clocks, virtual or real, we considered mutual exclusion – Centralized algorithms keep information in one place effectively becoming a monitor
– Distribution handles mutual exclusion in parallel at the cost of O(N) messages per CS use
– Token algorithm reduced messages under some circumstances but introduced heartbeat overhead
Each has strengths and weaknesses

Summary
Many distributed algorithms require a coordinator– Creating the need to select, monitor, and replace the coordinator as required
Election algorithms provide a way to select a coordinator
– Bully algorithm– Ring algorithm
Transactions provide a high level abstraction with significant power for organizing, expressing, and
implementing distributed algorithms– Mutual Exclusion– Locking– Deadlock

SummaryTransactions are useful because they can be aborted
Concurrency control issues were considered– Locking– Optimistic
Deadlock– Detection– Prevention
Yet again– Distributed systems have the same problems– Only more so


















