
Distributed streaming k means
13
-
Upload
jose-luis-lopez-pino -
Category
Technology
-
view
1.655 -
download
0
Transcript of Distributed streaming k means


Clustering
Group a set of objects
Objects in the same group should be similar
For each group we have an object called centre
Minimise the distance to the central point
Unsupervised learning:
Un-labelled data
No training data

Lloyd’s K-means algo.
Centres ← Randomly pick k points
Iterate:
Assign each point to the closest centre
Calculate the new centre points: centroids of each cluster
Problems:
It iterates over the whole list of points -> Not suitable for vast amounts of data.
Bad initialization.

K-means++
Centers ← Randomly pick ONE point from X
Until we have enough centres:
Choose from X the next centre with probability 𝐷(𝑝,𝑐)2
𝐷(𝑥)2𝑖∈𝑋
The probability increases when the distance to the closest centre is high.

K-means#
Centers ← Randomly pick 3 log k points from X
Until we have enough centres:
Choose from X the next 3 log k centres with
probability 𝐷(𝑝,𝑐)2
𝐷(𝑥)2𝑖∈𝑋
It improves the coverage of the clusters of the optimal solution.
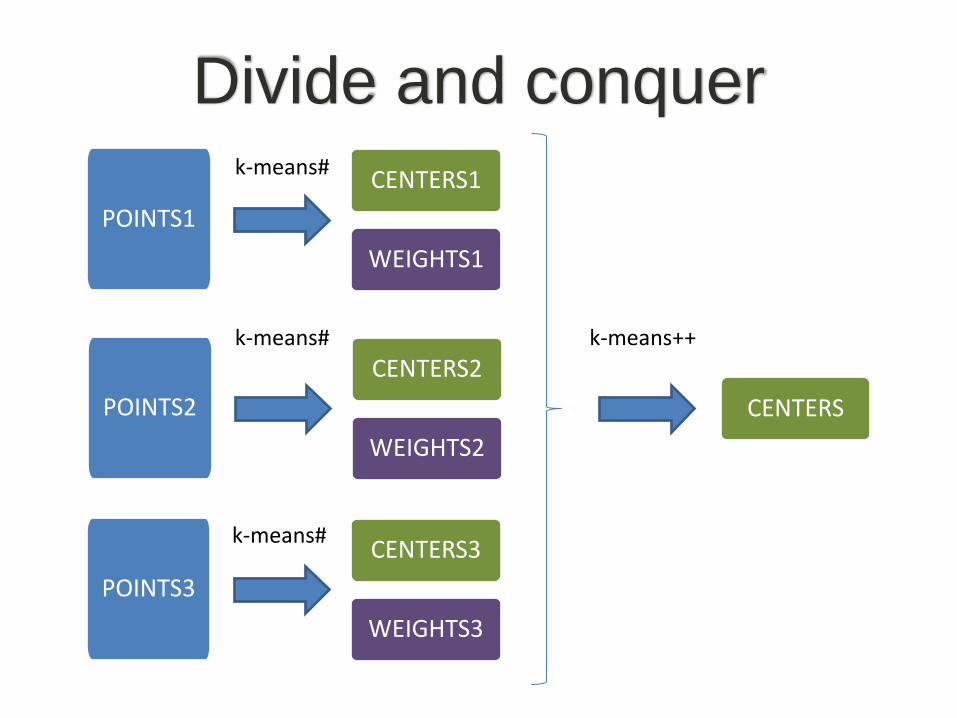
POINTS1
CENTERS1
WEIGHTS1
POINTS2
CENTERS2
WEIGHTS2
POINTS3
CENTERS3
WEIGHTS3
CENTERS
k-means#
k-means#
k-means#
k-means++
Divide and conquer

Fast streaming k-means
One pass over
the points
selecting those
that are far away
from the already
selected
When there is no
space enough,
we remove those
centres that are
less interesting
Finally, we run
Lloyd’s algorithm
on the centres
using the
weights


Basic Method
Single-pass k-means (explained before)
Output: Not-so-good clustering but a good candidate
Use weighted centers/ facilities from Step-1
Output: Good clustering with fewer clusters
Finding Nearest Neighbor: Most time consuming step
NN based on random Projection- Simple
Compact Projection: Simple and Efficient Near Neighbor
Search with Practical Memory Requirements [1]
Empirically, Projection search is a bit better than 64 bit LSH[4]

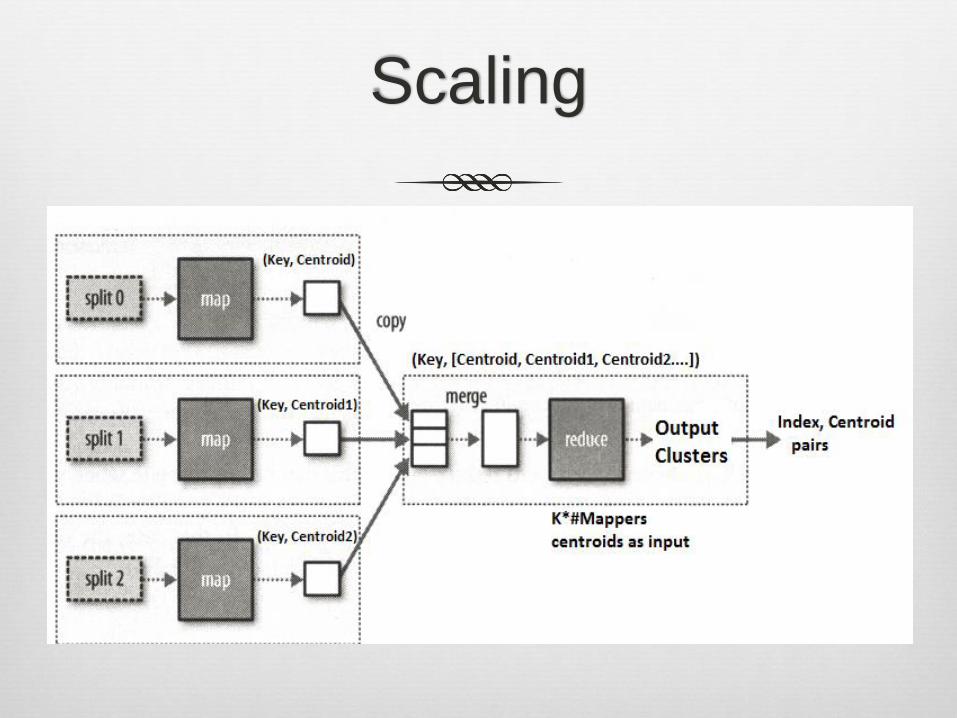
Scaling
Map:
Roughly cluster input data using Streaming k-means
Output: Weighted Centers (Cluster’s Center and the number of points it contains)
Reduce:
All centers passed to a single reducer
Apply batch k-means or again one-pass (if there are too many centers)
Can use Combiner but not necessary
Scaling

References
Compact Projection: Simple and Efficient Near Neighbor Search with Practical Memory Requirements by Kerui Min et al.
Fast and Accurate k-means for large datasets by Shindler et al.
Streaming k-Means Approximation by Jaiswal et al.
Large Scale Single pass k-Means Clustering at Scale by Ted Dunning
Apache Mahout

Questions?


















