
Distributed Selfish Replication
23
1 Distributed Selfish Replication Nikolaos Laoutaris Orestis Telelis Vassilios Zissimopoulos Ioannis Stavrakakis {laoutaris,telelis,vassilis,ioannis}@di. uoa.gr Department of Informatics and Telecommunications, University of Athens, Greece
-
Upload
kyla-price -
Category
Documents
-
view
45 -
download
0
description
Distributed Selfish Replication. Nikolaos Laoutaris Orestis Telelis Vassilios Zissimopoulos Ioannis Stavrakakis {laoutaris, telelis, vassilis,ioannis}@di.uoa.gr. Department of Informatics and Telecommunications, University of Athens, Greece. - PowerPoint PPT Presentation
Transcript of Distributed Selfish Replication

1
Distributed Selfish Replication
Nikolaos LaoutarisOrestis Telelis
Vassilios Zissimopoulos Ioannis Stavrakakis
{laoutaris,telelis,vassilis,ioannis}@di.uoa.gr
Department of Informatics and Telecommunications, University of Athens, Greece

2
A Distributed replication group (Leff et al., IEEE TPDS ‘93)
vj
tr
ts
tl
origin server
group
Cj: vj’s storage capacityrij: vj’s request rate for obj. oi
access cost: tl <tr< ts
•n nodes•Ν objects
Applications Content
distribution Shared
memory Network file
systems

3
Two main issues to address
Object placement which objects to replicate in each node? …will be the focus of this talk
Request routing how to find a node that replicates the
requested object? … our object placement solution facilitates
perfect routing routing to the closest node that’s holding the
object

4
Two popular obj. placement strategies
Socially Optimal (SO) placement strategy minimizes the average access cost in the entire group requires complete information (all request vectors) and
a centralized algorithm Leff et al.: SO by casting the object placement problem as a
capacitated transportation problem (polynomial complexity) SO appropriate under a single authority (e.g., CDN operator)
Greedy Local (GL) placement strategy each node acting in isolation (completely uncooperative) node vj replicates the Cj most popular objects according to
the local demand rj
requires only local information (the local request vector)

5
What happens when nodes are selfish?
a selfish node: seeks to minimize its local access cost is a better model for applications with:
multiple/independent authorities e.g., P2P, distributed web-caching
our main research goal will be to:
“Find appropriate object placement strategies for distributed replication groups of selfish nodes”

6
Why not use SO or GL?
the SO strategy: can mistreat some nodes (example coming
next) requires transmitting too much information
the GL strategy: being uncooperative leads to poor performance
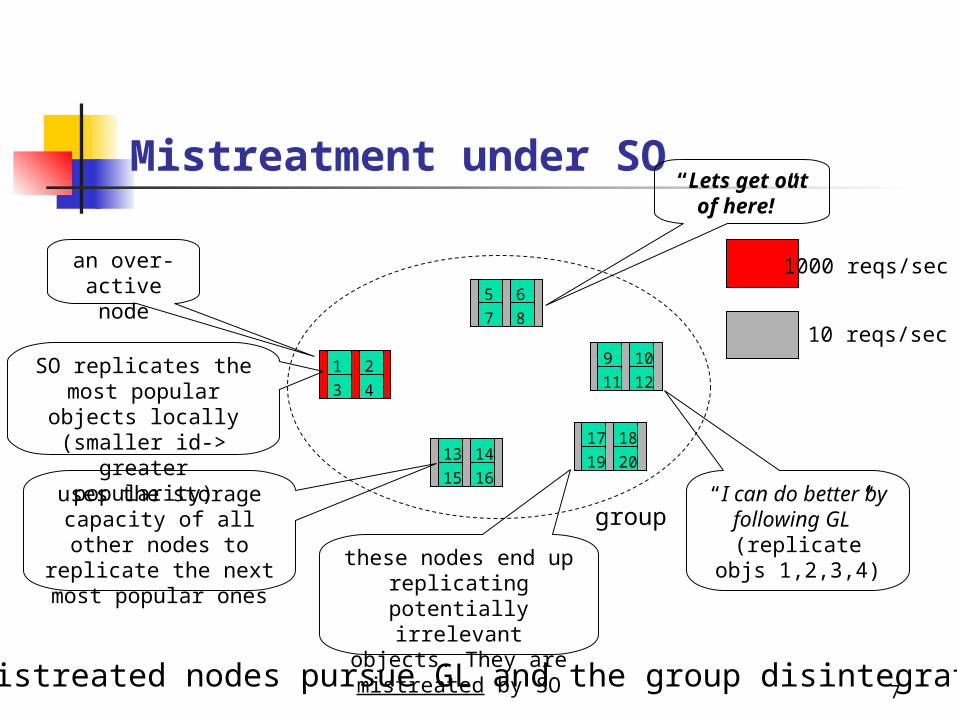
7
Mistreatment under SO
group
an over-active node
10 reqs/sec
1000 reqs/sec
1 2
3 4SO replicates the
most popular objects locally
(smaller id-> greater popularity)
5 6
7 8
9 10
11 12
13 14
15 16
17 18
19 20
uses the storage capacity of all other nodes to replicate
the next most popular ones
these nodes end up replicating potentially
irrelevant objects. They are mistreated
by SO
“I can do better by following GL”(replicate objs
1,2,3,4)
“Lets get out of here!”
… mistreated nodes pursue GL and the group disintegrates

8
The problem with nodes following GL
Poor performance under common scenarios
Uncooperativeness is harmful to both the social and the local utility
Lets assume that the nodes: have similar demand patterns are adjacent (trtl) then fetching an object locally or remotely costs the same
If all nodes follow GL: they will be replicating the same few objects multiple
times this is inefficient. Clearly they can do much better by:
replicating different objects, and fetching the missing ones from their (adjacent) neighbors

9
The bottom line…
Seems that a selfish node faces a deadlock
(1) it cannot blindly trust the SO strategy because SO might mistreat him
(2) it is not satisfied with the potentially poor performance of the (uncooperative) GL
Research question: How can we claim the (freely) available “cooperation gain”without risking a mistreatment and do that without complete information?

10
The Equilibrium (EQ) placement strtgy
is our approach for breaking the deadlock fills the gap between SO and GL in both:
performance (access cost) required amount of information
is based on the concept of pure Nash equilibrium from game theory
forbids the mistreatment of any one node all nodes do at least as good as GL and typically much better (cooperation driven by
selfish motives) requires the exchange of a small amount of
information
no reason for a node to abandon the group
then

11
The Distributed Selfish Replication (DSR) game
nodes players n players
local placements strategies player vj can choose among (N choose Cj) possible
strategies global placement outcome of the game
global placement=sum of the individual local placements reduction of access cost payoff function
DSR is a non-cooperative, non-zero-sum, n-player game
pure Nash equilibria?

12
Our approach for finding EQ strategies for the DSR game
starting with the DSR game in normal form we assume that nodes act sequentially following
some pre-defined order (v1,v2,…,vn) this resembles an extensive game formulation
we use the ordering as a device for finding pure Nash equilibrium strategies for
the original DSR game … in a distributed manner without requiring
complete information

13
Our first algorithm: TSLS
Two Step Local Search Step 0 (initialization):
each node computes its GL placement
gij=rij(ts-tl), if oi not replicated in another node
rij(tr-tl), if oi replicated in another node
distance reduction with respect to the previous closer copy
incomplete information• only the strategies are
revealed • but not the payoff
functions
Step 1 (improvement): nodes line up; node vj:
“observes” the placements of the other nodes proceeds to improve its GL placement according to the
following definition of “excess gain”

14
TSLS (continued)
each node solves a 0/1 Knapsack problem unit-weight objects, value gij, integral knapsack capacity greedy solution optimal
at the end of Step 1 of TSLS -> Nash eq. plcmnt no node can benefit unilaterally
proof: vj’s OPT placement at the time of its turn to improve:
remains OPT until the end of TSLS despite the changes performed from nodes that follow vj
only multiple objects are evicted during Step 1 only unrepresented objects are inserted during Step 1
so a node might exchange some
multiple objects from its GL placement with unrepresented ones

15
Comments on the use of ordering
TSLS without ordering may never converge to an EQ placement
nodes inserting/evicting the same objects indefinitely
impact of ordering on individual gains: sometimes a certain turn (higher or lower) gives
an advantage to a node identifying the OPT turn for a node requires
knowing the remote payoff functions (not possible)
when demand patterns (thus the payoffs also) are alike -> then higher turns (towards the end of Step 1) are better
simple “merit based” protocol for deciding turns
more important
nodes getting a
better turn

16
Eliminating the impact of ordering
Suppose that the nodes are identical same capacity, demand pattern, request rate
TSLS+”merit-based” protocol give some nodes an advantage (better turn) hard to justify since:
nodes are identical thus lack any kind of difference in merit
We would like to have an algorithm where: a node’s turn does not have a large impact
on the amount of gain that it gets

17
TSLS(k): improving the TSLS fairness
Same as TSLS but: at Step 1 -> up to k changes allowed
k (multiple) objects belonging to the GL placement substituted by k (unrepresented) ones
if more changes are desirable a node has to wait for the next round
TSLS(k) requires multiple rounds to converge to EQ we show that convergence is guaranteed for small k a node’s has a diminishing effect on
the amount of gain it receives for large k TSLS(k) reduces to TSLS

18
Distributed protocol
Decide turn according to “merit” e.g., jth largest node getting the jth better turn
Phase 0: compute GL placements all nodes in parallel each node to multicast its own
Phase 1: improve the GL placements nodes lining up each one improving its GL plcmnt and multicasting the
differences 1 round for TSLS, M rounds for TSLS(k) M ceil(Cmax/k)

19
Main benefit reduced information
centralized algorithm has to send up to n*N (obj. id, obj. rate)
pairs to a central node our protocol
transmits up to ΣCj obj. ids large reduction on the amount of info
sent typically ΣCj << N obj ids encoded easily (can use Bloom
filters) (obj. id, obj. rate) pairs harder to represent
to represent allthe rate vectors
aggregate storagecapacity
known placements perfect routing

20
Example n=2, N=100, C1= C2 =40, Zipf-like(0.8)
demand, tl=0, tr=1, ts=2, ρ1=1

21

22
Wrap up
many content distribution applications involve selfish nodes
previous socially optimal object placement solutions not suitable
new EQ strategies: avoid mistreatment problems harness the freely available cooperation
gain require limited information to be
implemented only the local demand pattern remote placements (but not the remote demands)

23
The end
Q ?


![[MS-FRS2]: Distributed File System Replication Protocol... · [MS-FRS2]: Distributed File System Replication Protocol ... No changes to the meaning, language, or formatting of the](https://static.fdocuments.us/doc/165x107/5f0bad677e708231d431ad5e/ms-frs2-distributed-file-system-replication-protocol-ms-frs2-distributed.jpg)















