
Distributed Realtime Computation using Apache Storm
25
Distributed Realtime Computation using By Saurabh Minni
-
Upload
the100rabh -
Category
Data & Analytics
-
view
288 -
download
1
Transcript of Distributed Realtime Computation using Apache Storm

Distributed Realtime Computation using
By Saurabh Minni

Who am I
Saurabh Minni also on the web as @the100rabh
Yet another developer in Bangalore
I just love tinkering with different technologies
Currently working as Technical Architect at Near
Been part of planning for Barcamp Bangalore since 2007
Author of Apache Kafka Cookbook - https://www.
packtpub.com/big-data-and-business-intelligence/apache-
kafka-cookbook

What is Apache Storm
From Apache Storm website :
“Apache Storm is a free and open source distributed realtime computation system. Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing. Storm is simple, can be used with any programming language, and is a lot of fun to use!”

Important terms in Apache Storm
● Topology
Spout A
Spout B
Bolt A2
Bolt A1
Bolt B1
Bolt A3
Important terms in Apache Storm
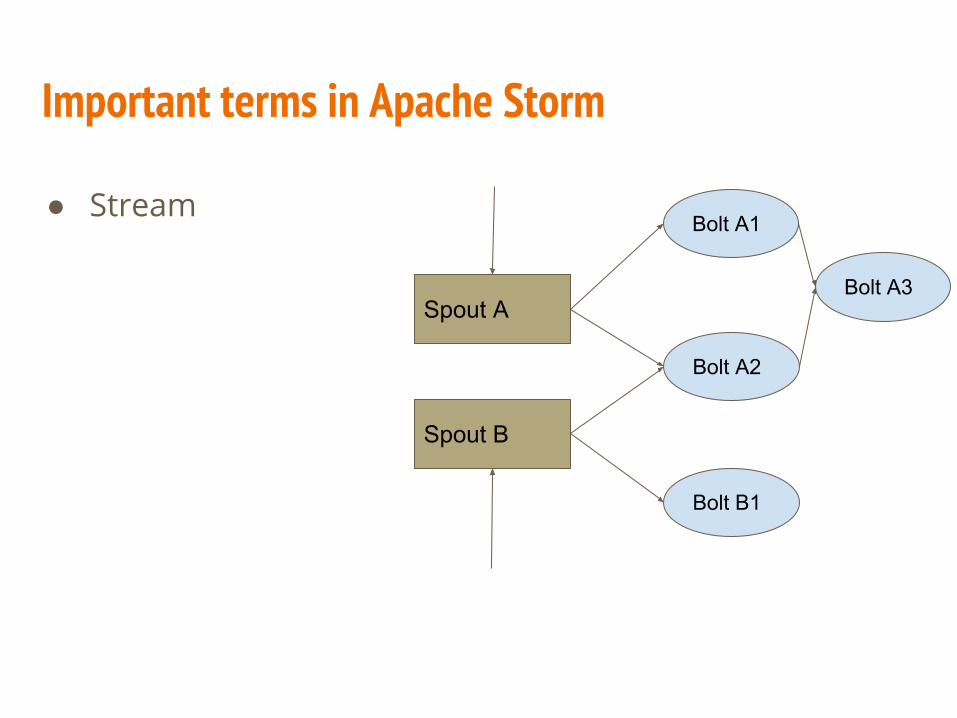
● Stream
Spout A
Spout B
Bolt A2
Bolt A1
Bolt B1
Bolt A3

Important terms in Apache Storm
● Spout
Spout A
Spout B
Bolt A2
Bolt A1
Bolt B1
Bolt A3

Important terms in Apache Storm
● Bolt
Spout A
Spout B
Bolt A2
Bolt A1
Bolt B1
Bolt A3

Important terms in Apache Storm
● Stream groupings○ how that stream should be partitioned among the bolt's tasks○ Types
■ Shuffle■ Field■ Partial Key■ Direct■ Local or Shuffle■ All ■ None

Important terms in Apache Storm
● Reliability○ Storm guarantees that every spout tuple will be
fully processed○ tree of tuples triggered by every spout tuple and
determining when that tree of tuples has been successfully completed
○ Storm fails to detect that a spout tuple has been completed within that timeout, then it fails the tuple and replays it later.

Important terms in Apache Storm
● Tasks○ task corresponds to one thread of execution○ stream groupings define how to send tuples
from one set of tasks to another set of tasks○ You can control the parallelism in each spout
and bolt as well

Important terms in Apache Storm
● Workers○ Each worker process is a physical JVM○ executes a subset of all the tasks for the
topology○ Storm tries to spread the tasks evenly across all
the workers.

Important terms in Apache Storm
● Tuple○ Storm uses tuples as its data model○ A tuple is a named list of values○ field in a tuple can be an object of any type like
the primitive types, strings, and byte arrays○ Use can implement the serializer for custom
class objects
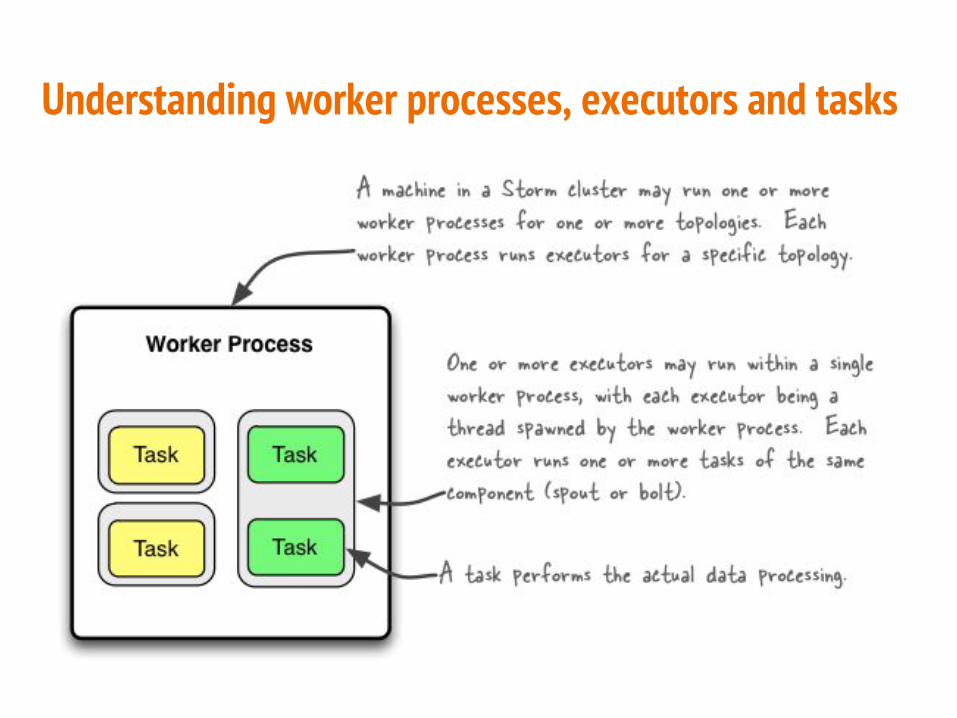
Understanding worker processes, executors and tasks
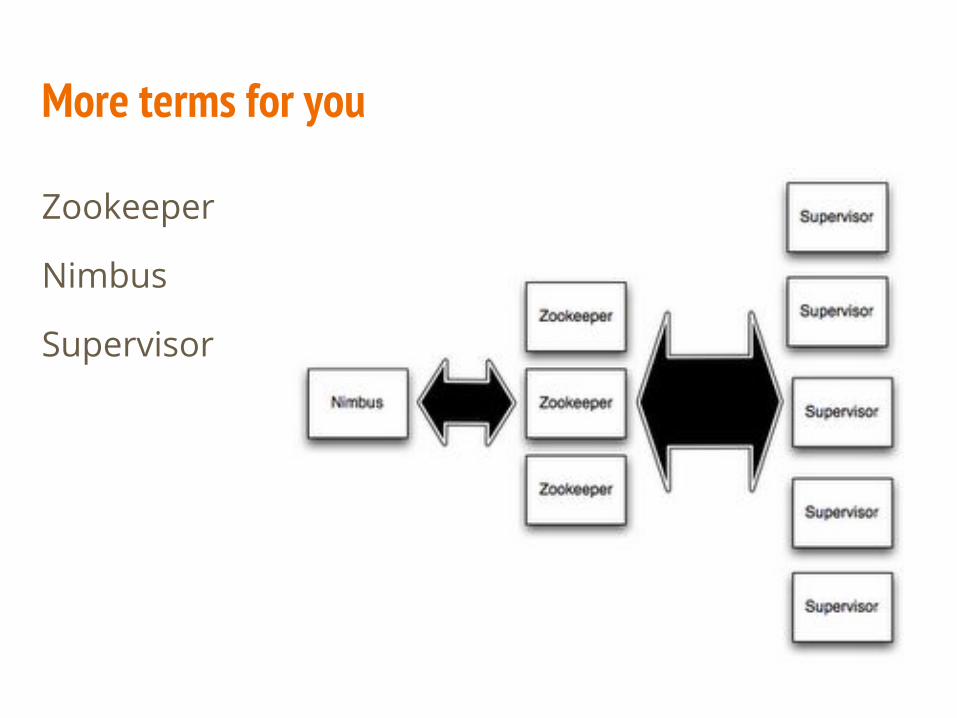
More terms for you
Zookeeper
Nimbus
Supervisor

Some important configuration options● nimbus.seeds
○ The worker nodes need to know which machines are the candidate of master in order to download topology jars and confs.
● supervisor.slots.ports○ For each worker machine, you configure how many
workers run on that machine with this config○ defines which ports are open for use
supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
nimbus.seeds: ["111.222.333.44"]

Show me the
Code

Design patterns for distributed realtime computation
1. Streaming joins
2. Batching
3. BasicBolt
4. In-memory caching + fields grouping combo
5. Streaming top N
6. TimeCacheMap for efficiently keeping a cache of things that have been recently updated
7. CoordinatedBolt and KeyedFairBolt for Distributed RPC

Joins
A streaming join combines two or more data streams together based on some common field.
The join type you need will vary per application. Some applications join all tuples for two streams over a finite window of time, whereas other applications expect exactly one tuple for each side of the join for each join field. Other applications may do the join completely differently. The common pattern among all these join types is partitioning multiple input streams in the same way. This is easily accomplished in Storm by using a fields grouping on the same fields for many input streams to the joiner bolt.
builder.setBolt("join", new MyJoiner(), parallelism) .fieldsGrouping("1", new Fields("joinfield1", "joinfield2")) .fieldsGrouping("2", new Fields("joinfield1", "joinfield2")) .fieldsGrouping("3", new Fields("joinfield1", "joinfield2"));

Batching
Oftentimes for efficiency reasons or otherwise, you want to process a group of tuples in batch rather than individually. For example, you may want to batch updates to a database or do a streaming aggregation of some sort.
If you want reliability in your data processing, the right way to do this is to hold on to tuples in an instance variable while the bolt waits to do the batching. Once you do the batch operation, you then ack all the tuples you were holding onto.
If the bolt emits tuples, then you may want to use multi-anchoring to ensure reliability.

BasicBolt
Many bolts follow a similar pattern of reading an input tuple, emitting zero or more tuples based on that input tuple, and then acking that input tuple immediately at the end of the execute method. Bolts that match this pattern are things like functions and filters. This is such a common pattern that Storm exposes an interface called IBasicBolt that automates this pattern for you. See Guaranteeing message processing for more information.

In-memory caching + fields grouping combo
It's common to keep caches in-memory in Storm bolts. Caching becomes particularly powerful when you combine it with a fields grouping. For example, suppose you have a bolt that expands short URLs (like bit.ly, t.co, etc.) into long URLs. You can increase performance by keeping an LRU cache of short URL to long URL expansions to avoid doing the same HTTP requests over and over. Suppose component "urls" emits short URLS, and component "expand" expands short URLs into long URLs and keeps a cache internally. Consider the difference between the two following snippets of code:
builder.setBolt("expand", new ExpandUrl(), parallelism) .shuffleGrouping(1);
builder.setBolt("expand", new ExpandUrl(), parallelism) .fieldsGrouping("urls", new Fields("url"));
The second approach will have vastly more effective caches, since the same URL will always go to the same task. This avoids having duplication across any of the caches in the tasks and makes it much more likely that a short URL will hit the cache.

Streaming top N
A common continuous computation done on Storm is a "streaming top N" of some sort. Suppose you have a bolt that emits tuples of the form ["value", "count"] and you want a bolt that emits the top N tuples based on count. The simplest way to do this is to have a bolt that does a global grouping on the stream and maintains a list in memory of the top N items.
This approach obviously doesn't scale to large streams since the entire stream has to go through one task. A better way to do the computation is to do many top N's in parallel across partitions of the stream, and then merge those top N's together to get the global top N. The pattern looks like this:
builder.setBolt("rank", new RankObjects(), parallelism) .fieldsGrouping("objects", new Fields("value"));builder.setBolt("merge", new MergeObjects()) .globalGrouping("rank");
This pattern works because of the fields grouping done by the first bolt which gives the partitioning you need for this to be semantically correct. You can see an example of this pattern in storm-starter here.

Streaming top N (Contd)
If however you have a known skew in the data being processed it can be advantageous to use partialKeyGrouping instead of fieldsGrouping. This will distribute the load for each key between two downstream bolts instead of a single one.
builder.setBolt("count", new CountObjects(), parallelism) .partialKeyGrouping("objects", new Fields("value"));builder.setBolt("rank" new AggregateCountsAndRank(), parallelism) .fieldsGrouping("count", new Fields("key"))builder.setBolt("merge", new MergeRanksObjects()) .globalGrouping("rank");
The topology needs an extra layer of processing to aggregate the partial counts from the upstream bolts but this only processes aggregated values now so the bolt it is not subject to the load caused by the skewed data. You can see an example of this pattern in storm-starter here.

TimeCacheMap
You sometimes want to keep a cache in memory of items that have been recently "active" and have items that have been inactive for some time be automatically expires. TimeCacheMap is an efficient data structure for doing this and provides hooks so you can insert callbacks whenever an item is expired.

CoordinatedBolt and KeyedFairBolt for Distributed RPC
When building distributed RPC applications on top of Storm, there are two common patterns that are usually needed. These are encapsulated by CoordinatedBolt and KeyedFairBolt which are part of the "standard library" that ships with the Storm codebase.
CoordinatedBolt wraps the bolt containing your logic and figures out when your bolt has received all the tuples for any given request. It makes heavy use of direct streams to do this.
KeyedFairBolt also wraps the bolt containing your logic and makes sure your topology processes multiple DRPC invocations at the same time, instead of doing them serially one at a time.


















