
Dispensa di analisi dei dati
172
Dispensa di Analisi dei Dati S B V Versione non definitiva. Licenza Creative commons
-
Upload
stefano-bussolon -
Category
Documents
-
view
5.819 -
download
4
description
Transcript of Dispensa di analisi dei dati

Dispensa di Analisi dei Dati
S B
V Versione non definitiva.
Licenza Creative commons


Indice
Introduzione all'analisi dei dati . Analisi dei dati: a cosa serve? . . . . . . . . . . . . . . . . . . . . . . .
.. Un esempio: twier e la borsa . . . . . . . . . . . . . . . . . . . La ricerca . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. Aeggiamento critico . . . . . . . . . . . . . . . . . . . . . . . . Validità . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. Tipi di validità . . . . . . . . . . . . . . . . . . . . . . . . . . . . L'analisi dei dati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. Statistica esplorativa . . . . . . . . . . . . . . . . . . . . . . . .. Statistica descriiva univariata . . . . . . . . . . . . . . . . . . .. Statistie esplorative bivariate . . . . . . . . . . . . . . . . . .
. Statistica inferenziale . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Gli errori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Campionamento . . . . . . . . . . . . . . . . . . . . . . . . . . .. Intervalli di confidenza . . . . . . . . . . . . . . . . . . . . . . .. Testare un'ipotesi . . . . . . . . . . . . . . . . . . . . . . . . . .. Scegliere la statistica appropriata . . . . . . . . . . . . . . . . .
. Esercizi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
L'approccio simulativo . Gli errori di campionamento . . . . . . . . . . . . . . . . . . . . . . .
.. Distribuzione degli errori . . . . . . . . . . . . . . . . . . . . . . Introduzione all'approccio simulativo . . . . . . . . . . . . . . . . . . .
.. Generare popolazione e campioni . . . . . . . . . . . . . . . . .. Campioni di numerosità . . . . . . . . . . . . . . . . . . . .
. Intervallo di confidenza . . . . . . . . . . . . . . . . . . . . . . . . . . . Bootstrapping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. Generare molti campioni da un campione . . . . . . . . . . . . .. Confronto fra le distribuzioni . . . . . . . . . . . . . . . . . . . .. Usare l'approccio parametrico . . . . . . . . . . . . . . . . . .

INDICE
Intervallo di confidenza, calcolo parametrico . L'intervallo di confidenza . . . . . . . . . . . . . . . . . . . . . . . . .
.. La simulazione . . . . . . . . . . . . . . . . . . . . . . . . . . .. Dalla simulazione alla stima . . . . . . . . . . . . . . . . . . . .. La distribuzione t di Student . . . . . . . . . . . . . . . . . . .
. Confronto fra un campione ed una popolazione . . . . . . . . . . . . . .. Il p-value . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Primo esempio . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Secondo esempio . . . . . . . . . . . . . . . . . . . . . . . . .
Confronto fra variabili categoriali: χ2 . Variabili nominali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Confronto di una distribuzione campionaria con una distribuzione teorica
.. Un esempio: distribuzione occupati . . . . . . . . . . . . . . . . Stima dell'errore . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . La simulazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . La distribuzione χ2 . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. La funzioneisq.test . . . . . . . . . . . . . . . . . . . . . . . . Confronto fra due variabili nominali . . . . . . . . . . . . . . . . . . .
.. Calcolare le frequenze aese . . . . . . . . . . . . . . . . . . .
T test: confronto fra medie di due campioni . Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Calcolo non parametrico . . . . . . . . . . . . . . . . . . . . . . . . . .
.. La simulazione . . . . . . . . . . . . . . . . . . . . . . . . . . .. La distribuzione U Mann-Whitney-Wilcoxon . . . . . . . . . .
. Approccio parametrico . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Assunzioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. R: p-value usando la distribuzione . . . . . . . . . . . . . . . . .. Uso della funzione t.test . . . . . . . . . . . . . . . . . . . . .. Conclusioni . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Correlazione e regressione lineare . Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. La rea di regressione . . . . . . . . . . . . . . . . . . . . . . . . Analisi inferenziale . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. Correlazione e causazione . . . . . . . . . . . . . . . . . . . . .. Modelli Lineari Generalizzati . . . . . . . . . . . . . . . . . . .
. Approccio intuitivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. La simulazione . . . . . . . . . . . . . . . . . . . . . . . . . . .. Alcuni esempi . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Uso della distribuzione teorica . . . . . . . . . . . . . . . . . .
. Regressione lineare . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Regressione lineare: il modello . . . . . . . . . . . . . . . . . . .. Assunti della regressione lineare . . . . . . . . . . . . . . . . . .. R: la funzione lm () . . . . . . . . . . . . . . . . . . . . . . .

INDICE
.. Varianza dei residui, R2 . . . . . . . . . . . . . . . . . . . . . . Violazione degli assunti . . . . . . . . . . . . . . . . . . . . . . . . . . . Coefficiente di Spearman . . . . . . . . . . . . . . . . . . . . . . . . .
.. arto esempio, sigmoide . . . . . . . . . . . . . . . . . . . . . Conclusioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Analisi della Varianza . Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. Confronto a coppie . . . . . . . . . . . . . . . . . . . . . . . . . Varianze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. Varianza spiegata e previsioni . . . . . . . . . . . . . . . . . . .. Un esempio: gli affii in una cià . . . . . . . . . . . . . . . .
. Inferenza e previsioni . . . . . . . . . . . . . . . . . . . . . . . . . . . .. L'analisi della Varianza . . . . . . . . . . . . . . . . . . . . . .
. Distribuzione dell'errore, inferenza . . . . . . . . . . . . . . . . . . . . .. La distribuzione Fisher-Snedecor . . . . . . . . . . . . . . . . . .. R: uso di aov . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. Anova a due vie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Due variabili indipendenti . . . . . . . . . . . . . . . . . . . . .. Un esempio: antidepressivi e aività aerobica . . . . . . . . . . .. Il calcolo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Modello lineare . . . . . . . . . . . . . . . . . . . . . . . . . . .. L'esempio dei traamenti per la depressione . . . . . . . . . . .
. Confronti multipli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. La correzione di Bonferroni . . . . . . . . . . . . . . . . . . . . .. Il test di Tukey . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Analisi della Varianza: assunti . . . . . . . . . . . . . . . . . .
. Test non parametrico . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Il test di Kruskal-Wallis . . . . . . . . . . . . . . . . . . . . . .
. Conclusioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Casi di studio . Il framing effect nella scelta di un paceo turistico: un esperimento
on line . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Metodo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Conclusioni . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. Depressione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Confronto fra variabili ad intervalli . . . . . . . . . . . . . . . . . . .
.. Disegno i grafici delle variabili . . . . . . . . . . . . . . . . . .. Correlazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Conclusioni . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. Differenza fra masi e femmine . . . . . . . . . . . . . . . . . . . . . .. Test non parametrico . . . . . . . . . . . . . . . . . . . . . . .
. estionario parole-non parole . . . . . . . . . . . . . . . . . . . . . . .. Filtro i dati . . . . . . . . . . . . . . . . . . . . . . . . . . . . .

INDICE
.. Rapporto fra scolarità e media di risposte corree . . . . . . . . .. Confronto per genere . . . . . . . . . . . . . . . . . . . . . . .
. Il problema della violazione degli assunti . . . . . . . . . . . . . . . . . .. Possibili soluzioni . . . . . . . . . . . . . . . . . . . . . . . . .
. Calcolo su dati artificiali . . . . . . . . . . . . . . . . . . . . . . . . . . .. Correlazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Analisi della varianza a due vie . . . . . . . . . . . . . . . . .
A Primi passi con R A. Scaricare e avviare R . . . . . . . . . . . . . . . . . . . . . . . . . . . .
A.. Scaricare R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A.. Usare R come una calcolatrice . . . . . . . . . . . . . . . . . . A.. Operazioni booleane . . . . . . . . . . . . . . . . . . . . . . .
A. Help . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A. Funzioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
A.. Creare e manipolare matrici . . . . . . . . . . . . . . . . . . . A.. Filtri . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A.. Data frames . . . . . . . . . . . . . . . . . . . . . . . . . . . . A.. Liste . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
A. Le distribuzioni teorie . . . . . . . . . . . . . . . . . . . . . . . . . . A.. La distribuzione normale . . . . . . . . . . . . . . . . . . . . . A.. Altre distribuzioni . . . . . . . . . . . . . . . . . . . . . . . . .
B R: analisi descrittiva B. Analisi descriive . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
B.. Leggere un file di dati . . . . . . . . . . . . . . . . . . . . . . . B.. Visualizzare il sommario . . . . . . . . . . . . . . . . . . . . . B.. Variabili nominali . . . . . . . . . . . . . . . . . . . . . . . . . B.. Variabili a rapporti . . . . . . . . . . . . . . . . . . . . . . . .

Capitolo
Introduzione all'analisi dei dati
Indice. Analisi dei dati: a cosa serve? . . . . . . . . . . . . . . . . . . .
.. Un esempio: twier e la borsa . . . . . . . . . . . . . . . . . La ricerca . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. Aeggiamento critico . . . . . . . . . . . . . . . . . . . . . Validità . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. Tipi di validità . . . . . . . . . . . . . . . . . . . . . . . . . L'analisi dei dati . . . . . . . . . . . . . . . . . . . . . . . . . .
.. Statistica esplorativa . . . . . . . . . . . . . . . . . . . . . .. Statistica descriiva univariata . . . . . . . . . . . . . . . .. Statistie esplorative bivariate . . . . . . . . . . . . . . .
. Statistica inferenziale . . . . . . . . . . . . . . . . . . . . . . . .. Gli errori . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Campionamento . . . . . . . . . . . . . . . . . . . . . . . .. Intervalli di confidenza . . . . . . . . . . . . . . . . . . . .. Testare un'ipotesi . . . . . . . . . . . . . . . . . . . . . . . .. Scegliere la statistica appropriata . . . . . . . . . . . . . .
. Esercizi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. Analisi dei dati: a cosa serve?``I keep saying that the sexy job in the next years will be statisticians.And I'm not kidding.'' Hal Varian, ief economist at Google
La citazione è traa da un articolo apparso sul New York Times nell'agosto . Con losvilupparsi di internet e delle nuove tecnologie, sostiene l'articolo, vivremo in un mondodove tuo può essere misurato, dove il numero di informazioni di tipo quantitativo èdestinato a crescere di anno in anno. Il problema, notano, è e affiné questi dati ab-biano un senso, è necessario trasformarli in informazioni e conoscenza. Per fare questo,i dati vanno analizzati. La statistica e l'analisi dei dati sono fra gli strumenti necessariper meere in ao questa trasformazione. Dati, informazioni, conoscenza.

CAPITOLO . INTRODUZIONE ALL'ANALISI DEI DATI
L'analisi dei dati, dunque, può essere utilizzata per trasformare i dati raccolti daosservazioni empirie in informazioni e, all'interno di un contesto conoscitivo, ac-crescono la conoscenza degli individui e delle organizzazioni.
L'articolo del New York Times enfatizza principalmente la conoscenza applicativa,finalizzata ad oenere risultati pratici. L'analisi dei dati può essere utilizzata ane perfare delle previsioni.
.. Un esempio: twitter e la borsa
Recentemente, è stato pubblicato un articolo (Bollen et al., ) in cui dei ricercatorihanno analizzato il flusso di status su twier, hanno analizzato la frequenza di alcunitermini lessicali legati al tono dell'umore e allo stato emozionale. Ebbene, la ricerca haevidenziato e:
� questo tipo di analisi riesce a misurare il tono dell'umore degli utenti twier;
� questa misura ha una capacità significativa di prevedere, di due o tre giorni, l'an-damento della borsa di New York.
esto lavoro è un esempio interessante non solo dell'importanza dell'analisi dei dati, maane di alcuni aspei metodologici. I ricercatori, infai, si sono posti alcune domande:
� gli utenti twier tendono ad esprimere, nei loro post, ane il loro umore?
� è possibile analizzare l'umore di un tweet verificando la presenza di determinatitermini lessicali?
� è possibile correlare questi termini con dei costrui psicologici?
� è ipotizzabile e esista, oltre allo stato dell'umore individuale, ane uno sta-to dell'umore colleivo? Ovvero, è possibile e, in un determinato giorno o inun determinato periodo, una popolazione di individui tenda a provare le stesseemozioni?
� è possibile e -- ammesso e esista -- questo umore colleivo abbia un'influen-za su alcuni comportamenti o su alcuni indici economici? Ad esempio, l'umorecolleivo ha una relazione con l'andamento della borsa?
Per rispondere a queste domande, Bollen et al. () hanno adoato un approccioempirico. In primo luogo, hanno studiato la leeratura. Il loro articolo riporta alcunericeree indicano come l'analisi testuale dei blog sia capace di fare delle previsioni sulsuccesso dei film nelle sale cinematografie, e dall'analisi delleat si possa prevederel'andamento della vendita di libri. Inoltre, citano un lavoro e dimostra come il publicsentiment, l'opinione colleiva degli utenti dei social network relativi ad un film siacapace di prevederne il successo commerciale.
In secondo luogo vengono citati una serie di lavori e di teorie socio-cognitive edimostrano come le emozioni hanno un'influenza sui processi decisionali. Citano deilavori e mostrano come le emozioni abbiano un ruolo ane nell'ambito economico-finanziario.

.. ANALISI DEI DATI: A COSA SERVE?
Gli autori fanno dunque un'ipotesi: è ragionevole assumere, dicono,e le emozioni el'umore del pubblico possano avere un'influenza sui valori del mercato azionario. Citanouna ricerca e ha indagato proprio questo aspeo, arrivando a conclusioni a supportodi quest'ipotesi.
Il loro lavoro, dunque, si basa su alcune ipotesi verosimili, supportate da una serie diricere fae da altri ricercatori, e ne confermano la plausibilità. I ricercatori esprimo-no degli interessi, potremmo dire delle curiosità. Si pongono delle domande: esiste unumore colleivo? esto umore colleivo può avere un impao su aspei importantidella vita delle persone e delle organizzazioni? È possibile misurare questo umore?
La leeratura sull'argomento sembra rispondere positivamente a queste domande.L'umore colleivo è misurabile, ed è un indicatore interessante. Misurarlo con strumentitradizionali (ad esempio con i questionari e i sondaggi nazionali) è però molto costoso,osservano. Esiste il modo di misurare quel parametro in maniera altreando efficace mameno costosa?
Un modo alternativo per misurare il parametro, osservano, è quello di utilizzareinternet e le moderne tecnologie per raccogliere l'enorme mole di dati pubblicati dagliutenti internet sui social network, identificare degli indicatori capaci di cogliere quellamisura, e araverso opportune analisi trasformare questi indicatori in unamisura capacedi stimare il parametro.
Gli autori, dunque, fanno una seconda ipotesi: sebbene un tweet sia lungo al mas-simo caraeri, l'analisi di milioni di questi tweet può offrire una rappresentazioneaccurata dell'umore colleivo. Ane in questo caso, l'ipotesi è supportata da alcunilavori sperimentali, e vengono citati.
Bollen et al. () esprimono l'ipotesi centrale del loro lavoro:
In this paper we investigate whether public sentiment, as expressed in large-scale collections of daily Twier posts, can be used to predict the stomarket.
I ricercatori hanno fao un'indagine empirica (sebbene non sperimentale) per valu-tare la loro ipotesi. Hanno raccolto quasi milioni di tweet, di circa .. utenti.Araverso degli strumenti di analisi testuale, hanno calcolato la presenza o meno ditermini generalmente utilizzati, nella lingua inglese, per esprimere il proprio umore.Ane in questo caso, hanno utilizzato degli indicatori noti in leeratura, sebbene daloro modificati per meglio adaarsi alla loro ricerca.
Partendo da questo lavoro di data-mining (di estrazione di informazioni) Bollen et al.() hanno oenuto alcuni indicatori. Uno, relativo al tono dell'umore (positivo vs.negativo). Altri sei indicatori, correlati ai costrui psicologici di calma, allerta, sicurezza,vitalità, gentilezza e felicità. Araverso opportune trasformazioni, hanno calcolato, perognuna di queste dimensioni, l'andamento giornaliero del sentimento pubblico.
Per verificaree questi indici misurassero davvero i costruie nominalmente rap-presentano, hanno identificato duemomentie, si suppone, potevano avere un forte im-pao emotivo: l'elezione del presidente Obama e il giorno del ringraziamento. Ebbene,in concomitanza con questi due eventi, i sismografi
Utilizzando le API di twier, hanno raccolto----------

CAPITOLO . INTRODUZIONE ALL'ANALISI DEI DATI
. La ricerca
La ricerca scientifica è una aività struurata, finalizzata ad accrescere la conoscenza,teorica e applicativa, araverso un aeggiamento empirico. All'interno del processodi ricerca vi sono aività di acquisizione, analisi ed interpretazione dei dati. L'acqui-sizione è finalizzata a raccogliere i dati, l'analisi è finalizzata a trasformare i dati ininformazioni, l'interpretazione a trasformare l'informazione in conoscenza.
La ricerca usa procedure, metodi e tecnie coerenti con una specifica scelta episte-mologica e metodologica. Tali procedure, metodi e tecnie sono scelti in base alla lorovalidità e affidabilità. Infine, l'aeggiamento scientifico dovrebbe rispeare dei crite-ri di obieività, ed evitare ogni forma di manipolazione finalizzata a piegare i risultatialle ipotesi del ricercatore. Uno dei fini dell'utilizzo di procedure, metodi e tecniestandardizzate è proprio quello di rispeare dei ragionevoli criteri di obieività.
La ricerca scientifica, dunque, dovrebbe essere -- nel limite del possibile -- unaaività controllata, rigorosa, sistematica, valida, verificabile, empirica, e critica.
Attività controllata Una delle finalità del metodo sperimentale è quella di misurarela relazione fra due variabili, minimizzando gli effei di faori estranei. Il criterio dellacontrollabilità è più facile da oenere quando l'aività di ricerca avviene in un contestoil più possibile controllato, quale il laboratorio sperimentale.
Ricerca qualitativa Lo svantaggio della ricerca in laboratorio, soprauo nell'ambitodelle scienze sociali e psicologie, è e la controllabilità implica la semplificazione delseing. Per questo motivo, ad un approccio streamente sperimentale e quantitativo, èspesso necessario affiancare delle aività di ricerca di tipo più qualitativo e, sebbenemeno solide dal punto di vista inferenziale, possono permeere alla comunità scientifi-ca di avere una più completa visione d'insieme, e possono permeere di meglio conte-stualizzare ane i risultati, più particolari, delle ricere sperimentali più streamentecontrollate e quantitative.
In termini epistemologici, questo aeggiamento viene definito pluralismo metodo-logico, mentre l'idea e un solo tipo di approccio empirico e conoscitivo sia possibile èdefinito monismo metodologico.
Rigorosità Il conceo di rigorosità si riferisce ad un aeggiamento epistemologicofinalizzato ad identificare misure, strumenti e metodi e siano rilevanti, appropriati egiustificati (teoricamente ed empiricamente).
Sistematicità Indica e la procedura adoata segue una iara sequenza logica.
.. Atteggiamento critico
L'idea di aeggiamento critico, di sano sceicismo da parte del ricercatore, è la quin-tessenza del pensiero epistemologico di Popper. Secondo Popper la ricerca scientifica

.. LA RICERCA
dovrebbe vivere di due momenti: a formulazione di ipotesi; b processo di falsificazio-ne delle ipotesi. In questa prospeiva, è il ricercatore stesso e, araverso il metodosperimentale, cerca di falsificare le proprie ipotesi e le proprie teorie.
In realtà, un simile aeggiamento autocritico è difficile da mantenere, ane peré,per un ricercatore, è molto più gratificante confermare la validità delle proprie ipotesiefalsificarle. Ciononostante, questo approccio critico è considerato talmente importantee vi sono due meccanismi metodologici, fortemente consolidati, finalizzati proprio arafforzare questo aeggiamento.
Il peer reviewing Uno dei due meccanismi finalizzato a mantenere l'aeggiamen-to critico è il meccanismo del peer reviewing: prima e un lavoro scientifico vengaacceato (e dunque pubblicato su di una rivista scientifica), deve passare al vaglio dialtri ricercatori. esto esame fra colleghi avviene in forma anonima, ed è finalizzatoproprio a garantire e, prima di venir pubblicato, il lavoro sia analizzato aentamente econ ocio critico per valutarne sia il rispeo dei principi epistemologici e metodologici,di validità e la rilevanza scientifica.
Falsificazione e ipotesi nulla In secondo luogo, l'approccio falsificazionista staalla base della statistica inferenziale. Come vedremo nei prossimi paragrafi e nel corsodell'intera dispensa, la statistica inferenziale è finalizzata a valutare quanto le misureoenute siano aribuibili al caso. Nel confronto fra due (o più) variabili, ad esempio,si cerca di capire se fra le variabili vi è una relazione. Per fare questo, si identifica unastatistica, ovvero una procedura di calcolo araverso cui si oiene un valore numerico.Il fine del processo inferenziale è stabilire se quel valore numerico va aribuito al caso(all'errore di campionamento) o alla relazione fra le variabili.
Per fare questo, si formulano due ipotesi: l'ipotesi nulla (H0) assume e il valorenumerico misurato sia aribuibile al caso, e e dunque, dall'analisi faa, non si possadedurre e vi sia una relazione. L'ipotesi alternativa (HA) assume invece e il valorenumerico non sia aribuibile al caso, e dunque si possa inferire e la relazione esiste.
Ebbene, il processo inferenziale si basa sul rifiuto (ovvero, sulla falsificazione) del-l'ipotesi nulla. Se il valore numerico calcolato è superiore (o inferiore, a seconda deicasi) ad un valore critico, si rifiuta l'ipotesi nulla, ovvero si falsifica l'ipotesi e non visia relazione fra le variabili. In caso contrario, l'ipotesi nulla non viene rifiutata, ma sirifiuta l'ipotesi alternativa.
In God we trust, all others bring data. -- William Edwards Deming
Principi
Come abbiamo visto, la ricerca scientifica si basa su di una serie di principi epistemologicie metodologici.
� empiricismo (guardare ai dati);
� determinismo (assumere la presenza di relazioni causa - effeo);
� parsimonia (le spiegazioni semplici sono meglio di quelle complicate);

CAPITOLO . INTRODUZIONE ALL'ANALISI DEI DATI
� preferenza per un approccio scientifico - sperimentale;
� un sano sceicismo;
� amore per la precisione;
� indagine basata su teorie e ipotesi;
� rispeo per i paradigmi teorici;
� disponibilità a cambiare opinione (e ad ammeere di avere, talvolta, torto);
� fedeltà alla realtà, ovvero alle osservazioni empirie;
� aversione per la superstizione, e preferenza per le spiegazioni scientifie;
� sete di conoscenza, o più banalmente sana curiosità e voglia di sapere;
� capacità di sospensione del giudizio;
� consapevolezza delle proprie assunzioni, e dei limiti (teorici, metodologici, di mi-surazione);
� capacità di separare le cose importanti da quelle irrilevanti;
� rispeo - e aitudine positiva - verso i metodi quantitativi;
� conoscenza delle basi della statistica e della teoria della probabilità;
� consapevolezza e la conoscenza è sempre imperfea e in quale modo impre-cisa.
Metodo scientifico
Sebbene non esista una ricea preconfezionata, possiamo semplificare l'approccio scien-tifico come qualcosa e assomiglia al processo seguente:
. osserva un aspeo del mondo
. formula un'ipotesi su quell'aspeo
. usa la teoria per fare delle previsioni
. testa le tue previsioni, araverso delle osservazioni o, meglio, degli esperimenti
. modifica la teoria alla luce dei risultati
. ricomincia dal punto .

.. LA RICERCA
Analisi della letteratura
A month in the laboratory can oen save an hour in the library.-- F. H. Westheimer
Per trovare una risposta scientificamente plausibile ad un problema:
� studiare la leeratura: molto probabilmente il problema è già stato affrontato,sono state sviluppate delle teorie, sono stati pubblicati degli esperimenti. Primadi immaginare di iniziare una ricerca, è fondamentale analizzare la leeratura.
� se dalla leeratura emergono risposte iare, il processo può fermarsi: abbiamo larisposta e cercavamo.
Contribuire alla ricerca Se dall'analisi della leeratura non emerge una risposta ia-ra alle domande e ci siamo posti, può aver senso cercare di dare una risposta empirica,adoando il metodo scientifico.
� partire da ciò e è emerso dallo studio della leeratura;
� se opportuno, iniziare una fase di osservazione, o una raccolta dati più aperta,meno quantitativa e più qualitativa, per meglio definire il problema;
� formulare un'ipotesi, plausibilmente all'interno di una teoria;
� formulare una previsione, basata sull'ipotesi;
� procedere ad uno studio empirico, possibilmente quantitativo, possibilmente conun disegno di tipo sperimentale;
� analizzare i dati, possibilmente con l'utilizzo ane di statistie inferenziali;
� trarre delle conclusioni.
Tipologie di ricere empirie Abbiamo già accennato e l'approccio empiricopuò essere più rigoroso, quantitativo, oppure privilegiare un aspeo più qualitativo.Semplificando, possiamo elencare le seguenti tipologie di ricerca:
� osservazione non sistematica: si traa di osservare un fenomeno, prenderne nota;è utile in una fase iniziale della ricerca, per iniziare ad avere un'idea del fenomenostudiato e formulare le prime ipotesi;
� osservazione sistematica: il fenomeno non viene solo osservato, ma ane misu-rato; le dimensioni rilevanti vengono decise in anticipo;event sampling: viene registrato un dato ogni volta e ha luogo un evento; timesampling; viene faa una osservazione ad ogni intervallo di tempo;l'osservazione, in quanto tale, tende a non modificare né interferire con quello eosserva;

CAPITOLO . INTRODUZIONE ALL'ANALISI DEI DATI
� esperimento: finalizzato a verificare o falsificare un'ipotesi; implica la manipola-zione direa di una o più variabili (indipendenti), la misura di uno o più variabilidipendenti, e l'analisi dei dati araverso delle statistie inferenziali;
� si definisce quasi-esperimento una situazione empirica in cui le variabili indipen-denti non possono essere manipolate dallo sperimentatore.
� le simulazioni usano modelli fisici o matematici per riprodurre le condizioni diuna situazione o di un processo.
. ValiditàIl metodo scientifico, e più in particolare l'approccio sperimentale, si basa sull'assunzionee vi sia un legame esplicativo fra ciò e succede nel contesto sperimentale e quelloe si intende spiegare.
L'esperimento, in quanto tale, tende a replicare in un seing controllato alcuni aspeidi ciò e avviene nel mondo esterno, per poter verificare se vi è una relazione causalefra due o più variabili.
Per fare questo bisogna ricreare la situazione nel seing, testare la relazione causale,e riportare la relazione all'ambiente originale.
Presupposti di validità I presupposti sono:
� e alcuni aspei di un fenomeno si possano misurare, se non su tua la popola-zione, almeno su di un campione;
� e, a partire da queste misurazioni, si possano fare delle analisi statistie per faremergere delle relazioni o delle differenze;
� e questi risultati abbiano una significatività statistica;
� e ciò e si è misurato e e i dati oenuti abbiano un legame con il fenomenoin questione;
� e i risultati oenuti sul campione, nel contesto sperimentale, possano esseregeneralizzati.
Una ricerca è valida se rispea questi assunti.
.. Tipi di validità
In leeratura si trovano diversi tipi di validità. Ne eleniamo i più importanti.
La validità di costrutto Si preoccupa di valutare se una scala (o una variabile) misura- o correla - con il costruo scientifico teorizzato. La validità di costruo può esseresupportata dalla validità convergente, e ha luogo quando la misura correla statistica-mente con misure correlate teoricamente, e dalla validità discriminante, e ha luogoquando vi è una mancata correlazione statistica con misure e la teoria suppone nonsiano correlate.

.. L'ANALISI DEI DATI
La validità di contenuto Si preoccupa e l'esperimento (o le variabili misurate) co-prano adeguatamente il soggeo di studio, ed è fortemente legata al design sperimentale.
La validità statistica È legata alla possibilità di trarre delle inferenze dall'analisi sta-tistica, ovvero se le differenze o le associazioni e misuriamo sono statisticamentesignificative.
La validità interna Vi è validità interna se possiamo assumere e vi sia una rela-zione causale fra le variabili studiate, ovvero se una correlazione osservata può essereconsiderata una relazione causale. Può essere assunta solo all'interno di un disegnosperimentale.
La validità esterna Si preoccupa di verificare se le conclusioni valide nel seing spe-rimentale possono essere generalizzate, alla popolazione o a contesti diversi.
Validità e statistica
� L'analisi dei dati è uno degli strumenti e ci permee di valutare alcuni degliaspei della validità di un esperimento.
� L'analisi descriiva ed esplorativa ci permeono di verificare l'esistenza di unarelazione fra variabili.
� L'analisi inferenziale ci permee di verificare la validità statistica propriamentedea.
� Le tecnie di campionamento sono finalizzate a massimizzare la validità esterna.
� Il design sperimentale ha il fine di preservare la validità interna
Affidabilità
L'affidabilità si riferisce alla qualità del processo di misurazione delle variabili. È legatoagli aspei della ripetibilità della misura e di accuratezza della stessa.
. L'analisi dei dati
Scopi
L'analisi dei dati è finalizzata a molteplici scopi:
� descrivere -- numericamente e graficamente -- una misura relativa ad un campio-ne;
� fare delle stime -- puntuali e ad intervallo -- relative a dei parametri della popo-lazione;

CAPITOLO . INTRODUZIONE ALL'ANALISI DEI DATI
� calcolare delle relazioni fra due o più variabili, misurate sul campione, e fare delleinferenze in merito alla popolazione di riferimento;
� fare delle previsioni in merito al valore di una osservazione, non nota, a partireda delle osservazioni note.
Possiamo dunque distinguere fra statistie descriive-esplorative e statistie infe-renziali.
.. Statistica esplorativa
Finalità Le statistie descriive sono finalizzate a:
� avere una prima visione, qualitativa, delle variabili raccolte;
� controllare la presenza di errori, ad esempio di data-entry;
� far emergere outliers e anomalie;
� valutare qualitativamente ipotesi e assunti, determinare qualitativamente le rela-zioni fra le variabili;
� identificare l'entità e la direzione delle relazioni fra le variabili;
� selezionare i modelli statistici appropriati;
Le statistie esplorative propriamente dee (Exploratory Data Analysis, EDA) han-no ane altre funzioni:
� scoprire paern e struure implicite;
� estrarre variabili latenti, o far emergere variabili importanti;
� sviluppare modelli parsimoniosi (riduzione dello spazio delle variabili);
� determinare opportuni parametri per ulteriori analisi (es n' di faori, n' di clusters)
Tipologie di statistica esplorativa La statistica esplorativa può essere univariata omultivariata. Inoltre, può utilizzare metodi grafici e metodi non grafici.
Spesso, in leeratura, si tende ad usare sia il termine descriiva e esplorativa,ane se forse ha più senso parlare di statistica esplorativa quando valuta la relazionefra due o più variabili, e descriiva la statistica non inferenziale univariata.
Mentre l'analisi inferenziale segue la definizione dell'ipotesi di ricerca, l'analisi esplo-rativa spesso ha luogo prima della definizione del modello teorico e dell'ipotesi di ricerca.Semplificando, nell'analisi inferenziale, la sequenza teorica è problema→ definizione diun modello (ipotesi)→ raccolta dei dati→ analisi→ eventuali conclusioni
Nell'analisi esplorativa, la sequenza èproblema→ raccolta dei dati→ analisi esplorativa→ definizione di unmodello (ipotesi)→ eventuali conclusioni

.. L'ANALISI DEI DATI
.. Statistica descrittiva univariata
Nella statistica descriiva univariata (non grafica), si valutano prevalentemente tre aspet-ti (Waltenburg and McLaulan, ):
� le tendenze centrali della distribuzione
� la dispersione della distribuzione
� la forma della distribuzione
Gli strumenti e le misure della statistica descriiva univariata dipendono dalla tipologiadella variabile: categoriale-ordinale versus numerica (intervalli, rapporti).
Distribuzione
La distribuzione sintetizza la frequenza dei valori o di intervalli di valori di una varia-bile. La frequenza può essere assoluta (il numero di osservazioni e cadono in quellacategoria o e rientrano in quel valore o intervallo) o in termini percentuali.
La distribuzione può essere rappresentata in forma tabellare, oppure con un grafico(tipicamente, un istogramma). Nella forma tabellare, rappresenta una distribuzione difrequenza. Possiamo distinguere
� frequenze assolute: si contano il numero di volte e un particolare valore èoenuto nel campione;
� frequenze relative, proporzioni: frequenze assolute divise per il numero di osser-vazioni;
� frequenze percentuali: proporzioni moltiplicate per .
Le frequenze sono rappresentate in tabelle di contingenza.
Tendenze centrali
La tendenza centrale di una distribuzione è una stima del centro di una distribuzione divalori.
Vi sono tre principali tipologie di stima della tendenza centrale:
� la moda: il valore (o la categoria) più frequente. Per calcolare la moda, è sufficienteordinare i punteggi in base alla frequenza, e selezionare il primo.
� la mediana: il valore e sta a metà quando le osservazioni sono ordinate in basealla variabile. Se il numero di osservazioni è dispari, si calcola la media fra i duevalori centrali.
� la media aritmetica, si calcola sommando i valori e dividendo la somma per ilnumero di osservazioni.

CAPITOLO . INTRODUZIONE ALL'ANALISI DEI DATI
Indici di dispersione
La dispersione si riferisce alla diffusione dei valori intorno alla tendenza centrale. Ledue misure più importanti sono
� il range, ovvero la distanza fra il valore massimo ed il minimo.
� la deviazione standard misura la variabilità aorno alla media.
� la distanza interquartilica: corrisponde al range fra il primo e il terzo quartile.Meno soggeo agli outliers.
Non tui questi indici possono essere applicati a tue le variabili, e dunque il primopassaggio nella statistica descriiva è dunque quello di definire le tipologie di variabilistudiate.
Tipologie di variabili
Possiamo distinguere tipologie di variabili:
� nominali
� ordinali
� ad intervalli
� a rapporti
Nel definire le tipologie di statistie applicabili, la distinzione più importante è fravariabili categoriali e quantitative (intervalli, rapporti).
Scale nominali Le variabili nominali creano delle categorie, e permeono di classifi-care le osservazioni all'interno di quelle categorie.
Alle varie categorie non può essere aribuito un ordine, e tantomeno è possibile faredelle operazioni matematie sulle variabili nominali.
Una variabile dicotomica è un caso speciale di variabile nominale, in cui vi sonosoltanto due categorie.
A partire da una variabile nominale è possibile calcolare la frequenza (ovvero ilnumero di osservazioni classificate in ogni gruppo) e la moda (ovvero il gruppo piùnumeroso).
Scale ordinali Le variabili ordinali permeono di stabilire un ordine fra gli elementi.Soo certi aspei, costituiscono una estensione delle variabili nominali. Essendo
possibile stabilire un ordine, permeono di identificare la posizione di un elemento nelrapporto con gli altri elementi.
Data una variabile ordinale, oltre alla moda, è possibile calcolare i percentili, i quar-tili, la mediana.

.. L'ANALISI DEI DATI
Scale ad intervalli Le variabili ad intervalli non solo possono essere ordinate, ma èpossibile fare delle assunzioni in merito alla distanza fra i valori, in quanto la distanzafra ogni valore intero è costante.
È possibile misurare non soltanto la moda e la mediana, ma ane la media aritme-tica fra le tendenze centrali; fra le misure di dispersione, possiamo misurare il range, ladistanza interquartilica e la deviazione standard.
Le scale a rapporto sono variabili ad intervalli; la loro particolarità è dovuta al faoe il valore e corrisponde allo zero non è arbitrario, ma assoluto. Ciononostante,generalmente si applicano alle variabili a rapporto le stesse statistie delle variabili adintervalli.
Variabili e statistie
Statistica descrittiva univariata categoriale Nel caso di variabile categoriale, la rap-presentazione non grafica più appropriata è in forma tabellare: si costruisce una tabella,con tante colonne quanti i livelli della variabile. I valori delle celle rappresentano la fre-quenza delle osservazioni per ogni livello. La frequenza può essere assoluta (il numerodi osservazioni) o relativa. Per oenere la tabella della frequenza relativa si dividono leosservazioni di ogni livello per il numero di osservazioni totale.
L'unica misura della tendenza centrale appropriata per le scale nominali è la moda,ovvero il livello con frequenza più alta.
Graficamente, una variabile categoriale può essere rappresentata araverso un gra-fico a barre.
Se il numero di livelli è basso, può essere utile ane la rappresentazione del graficoa torta.
Statistica descrittiva univariata, variabili ordinali Nel caso di variabili ordinali,oltre alla moda e al numero di livelli, possiamo calcolare:
� l'indice di centralità della mediana;
� indici di dispersione quali il range e i percentili; di particolare interesse i quartilie la distanza interquartilica.
� ane nel caso di variabili ordinali, se il numero di livelli è relativamente basso,può essere utile creare la tabella delle frequenze, assolute o relative.
� La rappresentazione grafica più appropriata è il grafico a barre, a paoe l'ordinedegli elementi grafici rispei l'ordine delle categorie.
Statistica descrittiva univariata, variabili numerie
� nelle variabili ad intervalli (o a rapporti), oltre alla moda e alla mediana si calcolal'indice di centralità della media.
� oltre al range, ai percentili ed ai quartili, si calcola l'indice di dispersione dellavarianza (e della deviazione standard).

CAPITOLO . INTRODUZIONE ALL'ANALISI DEI DATI
� nell'analisi della forma della distribuzione, l'aspeo più importante consiste nelvalutare se la distribuzione osservata approssima una distribuzione teorica, tipi-camente la distribuzione normale. Nel caso, è possibile calcolare la simmetria e lakurtosi della curva di distribuzione.
Statistica grafica univariata, variabili numerie
� per rappresentare graficamente la distribuzione, si utilizzano l'istogramma e ilgrafico della distribuzione oenuto araverso il metodo del kernel.
� araverso il boxplot è possibile rappresentare la mediana, i quartili ed il range diuna distribuzione numerica. È possibile inoltre valutare la presenza di outliers,ovvero di osservazioni collocate ai margini della distribuzione osservata.
� usando il grafico qqnorm (o qqplot) e la funzione qqline è possibile confrontare ladistribuzione osservata con la distribuzione teorica normale.
Valutazione della normalità, trasformazioni
Test di normalità Poié le statistie inferenziali parametrie assumono una distri-buzione delle osservazioni di tipo normale, è generalmente opportuno valutare la distri-buzione osservata di una variabile non soltanto araverso metodi grafici e descriivi,ma ane araverso dei test di normalità. In questa dispensa, utilizzeremo due di questitest:
� Il test diKolmogorov-Smirnov permee di confrontare due distribuzioni arbitrarie,e può essere usato per il confronto fra la distribuzione osservata e la distribuzionenormale;
� Il test di normalità Shapiro-Wilk è finalizzato a valutare la normalità della distri-buzione osservata.
Le due misure possono dare risultati differenti. Risulta pertanto necessario un pro-cesso di valutazione e tenga conto sia dei risultati dei test e dell'analisi grafica delladistribuzione.
esta regola pratica vale in ogni ambito della ricerca e dell'analisi dei dati: la me-todologia ci indica delle procedure e è opportuno seguire, per minimizzare il risiodi errori e meano a repentaglio affidabilità e validità della ricerca.
Le procedure, però, non vanno seguite pedissequamente. Conoscere i principi e gliassunti dell'analisi dei dati ci permee di fare delle inferenze ragionevolmente robusteane nei casi, e sono molti, in cui non è possibile una applicazione meccanica dellaprocedura.
.. Statistie esplorative bivariate
Le statistie esplorative multivariate hanno la finalità di meere in relazione due o piùvariabili.

.. STATISTICA INFERENZIALE
Le statistie grafie tendono a limitarsi prevalentemente al confronto di due varia-bili alla volta, in quanto questi confronti sono più facili da rappresentare e più immediatida leggere.
Variabili numerie: grafico di dispersione Nel caso di confronto fra due variabilinumerie, la rappresentazione grafica più appropriata è il grafico di dispersione, emappa le osservazioni delle due variabili sulle due dimensioni x e y.
La linea di regressione, inoltre, ci permee di visualizzare il modello di regressionelineare.
Variabili categoriali: mosaic plot Araverso il mosaic plot è possibile rappresentaregraficamente la relazione fra due variabili di tipo categoriale, nominale o ordinale.
Per rappresentare numericamente il rapporto fra due variabili categoriali si usa in-vece la tabella delle frequenze (assolute o relative). La tabella, di dimensioni r ∗ c, dover è il numero di livelli di una variabile, c il numero di livelli dell'altra.
Variabile categoriale vs variabile numerica Nel caso si debbano confrontare grafi-camente una variabile numerica su di una variabile categoriale, è possibile utilizzarenuovamente il boxplot, disegnando tanti boxplot quanti sono i gruppi della variabilecategoriale.
Una seconda possibilità è quella di un grafico a barre, dove ogni barra rappresentala media di ogni gruppo. Un'alternativa grafica consiste nel sostituire le barre con dellelinee e congiungono i punti e rappresentano le medie.
este rappresentazioni possono essere utilizzate ane quando le variabili catego-riali (indipendenti) sono due.
. Statistica inferenzialeFinalità
Il fine dell'analisi inferenziale è quello -- banalmente -- di fare delle inferenze su di unapopolazione a partire dalle osservazioni di un campione.
Il fine dell'analisi inferenziale univariata, è quello di stimare il valore di un parametrodella popolazione a partire da una statistica calcolata sul campione.
Il fine dell'analisi inferenziale bivariata è quello di stimare la significatività di unarelazione fra due variabili. Le analisi multivariate sono sostanzialmente un'estensionedell'analisi bivariata.
Nel confronto fra le variabili, possiamo determinare
� correlazioni fra variabili
� differenze fra gruppi
� determinazione di relazioni
� stima di effei
� predizioni basate su analisi della regressione.

CAPITOLO . INTRODUZIONE ALL'ANALISI DEI DATI
Analisi inferenziale univariata La finalità è quella di stimare il parametro di unapopolazione a partire dalla statistica corrispondente, calcolata sul campione. General-mente, il parametro stimato è la media della popolazione, ma si usa ane per stimarnela varianza o la mediana.
Poié queste statistie sono soggee all'errore di campionamento, nell'analisi in-ferenziale si calcola ane l'intervallo di confidenza, ovvero la forbice entro cui si stimae il parametro oggeo di indagine si colloi.
Analisi inferenziale bivariata Lo scopo di questo tipo di analisi è quello di verificaree vi sia una relazione statisticamente significativa fra le due variabili.
L'approccio comune alle analisi bivariate è quello di identificare una statistica capacedi misurare la relazione, applicare la statistica sulle variabili in oggeo, e confrontare ilvalore con la distribuzione dell'errore di quella statistica.
Se il valore numerico della statistica cade all'interno della distribuzione di errore, siassume e quella relazione non sia statisticamente significativa.
.. Gli errori
Il fine dell'analisi inferenziale è quello di trarre delle conclusioni inmerito a dei parametridi una o più popolazioni. Per fare questo, si potrebbe voler misurare i parametri dellapopolazione di interesse, calcolarne le statistie appropriate, e trarne le debite inferenze.
Testare l'intera popolazione è però generalmente impossibile, per due ordini di mo-tivi.
� Il motivo più ovvio è di tipo pratico: se la popolazione è molto numerosa, testarlacompletamente diventa eccessivamente costoso.
� Vi è inoltre un secondo motivo: a volte, la popolazione di riferimento è teorica.Ad esempio, potremmo voler fare delle inferenze sulla depressione post partum; inquesto caso, la popolazione di riferimento sono tue le donne e hanno partoritoda meno di , mesi. Ma ane se riuscissimo a testare tue le partorienti d'Italiaper un intero anno solare, vorremmo e i risultati ci permeessero di fare delleinferenze ane sulle donne e partoriranno fra due anni. La popolazione realedi quest'anno, dunque, è un sooinsieme della popolazione teorica e include ledonne e partoriranno nei prossimi anni.
Appare dunque iaro e, tranne alcune eccezioni, testare l'intera popolazione ègeneralmente impossibile. A questo punto, diventa necessario testare soltanto un sot-toinsieme della popolazione, ovvero un campione (sample, in inglese).
Semplificando, la logica soostante l'analisi dei dati è sostanzialmente la seguente:
� si identifica un problema
� si identifica una popolazione
� si identifica una dimensione pertinente
� si estrae un campione

.. STATISTICA INFERENZIALE
� si misura la dimensione sul campione
� a partire dalla statistica sul campione, si traggono inferenze sul parametro dipopolazione
� si traggono delle inferenze sui risultati
Vi è, dunque, un passaggio logico: popolazione - campione, misura sul campione -generalizzazione alla popolazione. Abbiamo visto e, affiné questi passaggi portinoa risultati acceabili, è necessario preservare dei criteri di validità. Più in particolare, ènecessario minimizzare e gestire alcuni errori e possono influire sull'analisi.
Tipi di errore
L'analisi inferenziale si basa sulla consapevolezza e i processi di campionamento, mi-surazione ed analisi sono soggei ad errori. Il fine della metodologia è quello di minimiz-zare e, quando possibile, escludere gli errori. Il fine dell'inferenza è quello di misuraregli errori, valutare se i risultati oenuti sono da aribuire o meno agli errori, e stimareil risio e il processo decisionale dell'inferenza sia scorreo.
Conoscere le tipologie di errori e i metodi per minimizzarli ed evitarli è dunque dicentrale importanza nella metodologia e nell'analisi.
Sono numerosi gli errori e possono influire sul processo inferenziale. Ricordiamo-ne alcuni.
� Errore di campionamento: il campione non produrrà esaamente gli stessi valorie si osserverebbero misurando l'intera popolazione.
� In un esperimento, errore di assegnamento: le differenze misurate fra i gruppisperimentali (e di controllo) potrebbero essere dovute non alla condizione speri-mentale, ma a differenze pre-esistenti fra i gruppi creati
� Errore dimisurazione (affidabilità): la misurazione della variabile può essere nonaccurata, e dunque può produrre risultati parzialmente non correi.
Più in generale, si definisce errore la differenza fra una misura di un parametro edil valore reale del parametro stesso. esta differenza può essere casuale o sistematica.Per capire la differenza, è necessario pensare a numerose misure, e dunque al ripetersidell'errore. Se l'errore è casuale, la media degli errori (ovvero la media delle differenze)tende ad essere pari a zero. Viceversa, l'errore è sistematico se la media tende ad unvalore diverso da zero.
Gli errori sistematici sono i più pericolosi, in quanto possono indurre il ricercatore aconclusioni errate e sono difficili da far emergere e da correggere araverso gli strumentistatistici. Gli errori sistematici possono essere minimizzati soltanto araverso un designrigoroso ed una raccolta ed elaborazione dei dati scrupolosa.
Il problema del campionamento è e, se fao in maniera scorrea, può indurre aderrori sistematici.

CAPITOLO . INTRODUZIONE ALL'ANALISI DEI DATI
.. Campionamento
Viene definito campionamento il processo di selezione del sooinsieme di unità dellapopolazione da studiare, per misurarne le caraeristie di interesse.
La notizia positiva è e, se il campionamento viene effeuato in maniera correa,le caraeristie misurate sul campione tendono ad assomigliare alle caraeristie (pa-rametri) della popolazione.La notizia negativa è e, nonostante la somiglianza, le statistie sul campione sono inquale modo diverse dai parametri della popolazione. esta differenza va aribuitaalla variabilità campionaria: se noi selezioniamo due campioni distinti da una stessa po-polazione, oeniamo statistie diverse. este differenze sono definite ane errore dicampionamento.
Campionamento rappresentativo Per evitare errori sistematici dovuti al campione,è necessario e il campione sia rappresentativo della popolazione.
La tipologia di campionamentoemeglio garantisce la rappresentatività della popo-lazione è il campionamento casuale: le unità del campione vengono scelte casualmentedalla popolazione. In alcuni casi si utilizza una forma di campionamento stratificata,nelle circostanze in cui si voglia garantire la rappresentatività di piccoli soogruppi dipopolazione.
Viceversa, metodi di campionamento non casuali (come i campionamenti di conve-nienza) risiano di introdurre degli errori sistematici nella statistica Akritas ().
Missing Un problema di non facile soluzione emerge quando una parte non trascurabi-le del campione selezionato non si presta alla misurazione. Se i missing si distribuisconoin maniera uniforme fra il campione, l'impao di questi dati mancanti risulta abbastanzacircoscrio.
Se, al contrario, i missing sono più frequenti in alcuni strati della popolazione piut-tosto e in altri, è forte il risio di incorrere in un errore sistematico.
Errori casuali Una parte di errore, però, non può essere evitata. Se questi errori nonsono sistematici, ma distribuiti casualmente, i metodi statistici ci permeono di misu-rarli, di valutarne l'impao, e di calcolare la probabilità e i risultati da noi oenutisiano o meno aribuibili al caso.
La funzione della statistica inferenziale è di fare delle stime, relative ai parametridella popolazione, partendo dalle statistie dei campioni, e tengano conto della va-riabilità campionaria. L'analisi inferenziale offre una serie di strumenti e permeanodi:
� fare delle stime sui parametri di una popolazione
� determinare se i parametri di due o più popolazioni sono significativamente diversi
� valutare se due o più parametri relativi ad una popolazione sono fra loro legati
� fare delle previsioni

.. STATISTICA INFERENZIALE
L'analisi inferenziale fa delle stime, di tipo puntuale e intervallare, su determinati para-metri della popolazione, testa delle ipotesi, valuta l'accuratezza delle proprie previsionie determina il risio e le stime, le ipotesi acceate e le previsioni risultino errate.
.. Intervalli di confidenza
Un correo campionamento minimizza l'incidenza degli errori sistematici, ma non eli-mina l'errore casuale.
Il valore della statistica sul campione, infai, è una approssimazione del valore delparametro della popolazione. Più precisamente, la media del campione costituisce unastima puntuale della media della popolazione. Sappiamo, però, e questa stima sarà --quasi sicuramente -- leggermente sbagliata. Conoscendo soltanto la stima puntuale, nonsappiamo quanto questa stima sia affidabile, e quale sia il probabile range di errore.
Il calcolo dell'intervallo di confidenza è finalizzato proprio a calcolare il range entrocui il valore del parametro di popolazione dovrebbe cadere.
Un intervallo di confidenza si basa su una percentuale - prestabilita - di confidenza.Generalmente, si considera acceabile una percentuale del %.
Per meglio capire la percentuale dell'intervallo di confidenza, partiamo da una osser-vazione. Se estraiamo campioni diversi dalla stessa popolazione, e misuriamo la stessavariabile sui due campioni, oerremo valori (più o meno) diversi.
Immaginiamo ora di estrarre campioni dalla popolazione. Usiamo il primo cam-pione per misurare il parametro della popolazione, e l'intervallo di confidenza. Un in-tervallo di confidenza del % significa e, se misuriamo la stessa statistica sugli altri campioni, ci aspeiamo e -- approssimativamente -- di loro cadano entrol'intervallo di confidenza.
Più streo l'intervallo di confidenza, più alta la precisione.Un intervallo di confidenza molto largo lascia intendere e le dimensioni del campionesono inadeguate. L'intervallo di confidenza verrà descrio più deagliatamente nellasezione .
.. Testare un'ipotesi
Nel test di ipotesi, si identificano un'ipotesi nulla e un'ipotesi alternativa; si fanno dellemisurazioni e si calcola una statistica; se la statistica cade all'interno della regione diacceazione (basata sulla distribuzione dell'errore campionario), l'ipotesi nulla non vienerifiutata. In caso contrario, l'ipotesi nulla viene rifiutata, e si accea l'ipotesi alternativa.
Il test di ipotesi si pone la questione: ``i risultatie abbiamo oenuto possono esserearibuiti al caso?'' Il primo passo, è quello di tradurre il problema scientificoe ci siamoposti nei termini delle due ipotesi: l'ipotesi nulla e l'ipotesi alternativa.
� L'ipotesi nulla,H0, assume e il risultato non sia significativo, ovvero e sia daaribuire al caso.
� L'ipotesi alternativa H1 o HA, sostiene e il risultato della statistica non pos-sa essere aribuito al caso, ma e sia da aribuire ad una relazione inerente lapopolazione, sia questa una differenza o una relazione.

CAPITOLO . INTRODUZIONE ALL'ANALISI DEI DATI
Il secondo passo, è identificare una statistica e sia capace di misurare la differenza(o la relazione) all'interno del campione, ed applicarla ai dati raccolti.
Il terzo passo è confrontare il valore della statistica con la corrispondente distribu-zione di errore. Informalmente, possiamo dire e più il valore della statistica si collocaai margini della distribuzione di errore, meno è probabile e la differenza (o la relazio-ne) misurata siano aribuibili al caso. esta probabilità può essere stimata in base alladistribuzione dell'errore, e costituisce il p-value, valore su cui si basa la decisione fina-le: se il p-value risulta inferiore ad un livello di soglia acceabile, definito α, si rifiutal'ipotesi nulla, e si accea l'ipotesi alternativa. In caso contrario, non si rifiuta l'ipotesinulla.
L'ipotesi nulla
Poié i concei di ipotesi nulla, ipotesi alternativa e p-value sonomolto importanti nellastatistica inferenziale ma sono spesso difficili da comprendere, ci soffermiamo ancora suquesti concei.
L'ipotesi nulla e l'ipotesi alternativa sono alla base del test di ipotesi, e costituisceil fine della statistica inferenziale, e si propone di capire (e di decidere) se i risultatioenuti siano da aribuire, o meno, al caso.
L'esempio più tipico è il disegno sperimentale dove i partecipanti sono assegnaticasualmente a due gruppi, il gruppo sperimentale e quello di controllo. Al gruppo spe-rimentale viene somministrato un traamento, al gruppo di controllo no (oppure, vienesomministrato il placebo). Viene definita una misura, capace di valutare l'outcome, il ri-sultato del traamento. Si calcola l'appropriata statistica (ad esempio la media) dei duegruppi sperimentali, e si calcola la differenza fra le due medie.
Se la metodologia sperimentale è stata seguita correamente, la differenza fra le duemedie può essere aribuita soltanto a due possibili cause: il traamento, o il caso.L'ipotesi nulla assume e la statistica misurata (in questo caso, la differenza) sia ari-buibile al caso, ovvero e la vera differenza fra la media dei due gruppi sia pari a zero.L'ipotesi alternativa assume e la differenza non possa essere aribuita al caso e, peresclusione, sia aribuibile al traamento.
L'ipotesi nulla viene rifiutata se la differenza fra le medie dei due gruppi è tale da nonpoter essere aribuita al caso, ovvero se si discosta significativamente dalla distribuzionedell'errore di campionamento.
Formalmente, si parla di rifiuto e non rifiuto dell'ipotesi nulla. Non è formalmentecorreo parlare di acceazione dell'ipotesi nulla. Ceriamo di capire il peré.L'ipotesi nulla assume e il valore della statistica sia da aribuire al caso. Se il valoreè esterno alla regione di acceazione non possiamo aribuire il risultato al caso, e dun-que dobbiamo rifiutare l'ipotesi nulla, ed acceare l'ipotesi alternativa (il risultato non èaribuibile al caso).
Se il valore della statistica cade all'interno della regione di acceazione, non pos-siamo escludere e il risultato sia aribuibile al caso. esto però non dimostra ela vera misura sia pari a zero. Per quanto ne sappiamo, la vera misura potrebbe esserecomunque differente da zero. Poié, però, la differenza misurata potrebbe essere ari-buita al caso, tuo quello e possiamo dire è e non si può escludere e la differenzasia dovuta al caso. L'ipotesi nulla non è falsificata (e dunque non viene rifiutata) ma

.. STATISTICA INFERENZIALE
nemmeno verificata (in quanto non sappiamo se la vera differenza sia davvero pari azero.
Il test di ipotesi, dunque, si basa su quell'aeggiamento di tipo falsificazionista in-trodoo quale paragrafo sopra.
Il p-value
Il p-value è la risposta alla domanda ``assumendo e l'ipotesi nulla sia vera, qual'è laprobabilità di osservare un valore altreanto o più estremo di quello oenuto?''
Il p-value è una misura dell'evidenza contraria all'ipotesi nulla: più basso il p-value,maggiore l'evidenza contraria all'ipotesi nulla. Un p-value basso indica una maggioresicurezza nel rigeare l'ipotesi nulla.
Il p-value è la probabilità e l'errore campionario possa assumere un valore superio-re al valore osservato. Deo in altri termini, il p-value ci dice la probabilità di compiereun errore di tipo I rifiutando l'ipotesi nulla.
Coerentemente con l'aeggiamento falsificazionista, il p-value può essere usato solocome evidenza contro l'ipotesi nulla, non a favore di un'ipotesi. Un p-value alto non cipermee di trarre alcuna conclusione: Absence of evidence is not the evidence of absence.
In ambito applicativo, non è deo e una significatività statistica abbia reali impli-cazioni pratie. In clinica, ad esempio, una differenza statisticamente significativa puònon essere clinicamente significativa. Inoltre, il p-value non dice nulla sull'entità delladifferenza (o dell'effeo)
P-value e α La decisione sul rifiuto o meno dell'ipotesi nulla si basa sul confronto frail p-value e la soglia α: se p < α si rifiuta l'ipotesi nulla, altrimenti no.
α è ane il livello di significatività del test. Generalmente, i valori più comunementeutilizzati sono α = . e α = ..
L'ipotesi alternativa L'ipotesi alternativa può essere ad una o a due code (mono- obidirezionale). Nell'ipotesi a due code assume l'esistenza di un effeo o una differenza,ma senza specificare la direzione.Nell'ipotesi ad una coda, viene specificata ane la direzione aesa della differenza.
Processo decisionale
Possiamo dunque riassumere il processo decisionale del test d'ipotesi.
� Si parte, conceualmente, dall'ipotesi nulla;
� si definisce l'ipotesi alternativa -- generalmente, l'ipotesi a supporto della teoria;
� si definisce e si calcola la statistica test opportuna sulla variabile, misurata sulcampione;
� si definisce l'errore di tipo I e si ritiene acceabile (ovvero, il valore α);
� si calcola la regione di rifiuto dell'ipotesi nulla o, alternativamente, il p-value;

CAPITOLO . INTRODUZIONE ALL'ANALISI DEI DATI
� la decisione finale si basa valutando se la misura della statistica cade all'interno oall'esterno della regione di acceazione dell'ipotesi; se all'esterno, si rifiuta l'ipotesinulla, e si accea l'ipotesi alternativa; se all'interno, non si rifiuta l'ipotesi nulla,ma quella alternativa;
� lo stesso risultato può essere oenuto confrontando il p-value con α: se p < α sirifiuta l'ipotesi nulla, altrimenti no.
.. Scegliere la statistica appropriata
Per decidere quale tipo di statistica può essere applicata, è necessario definire:
� il numero di variabili in gioco (una, due, più di due)
� la tipologia delle variabili (nominale o numerica)
� il tipo di ipotesi testata: ceriamo una relazione, una differenza, una previsione
Numero di variabili
� Statistie uni-variate
� Statistie bi-variate
� Statistie multi-variate
Tipi di variabili e statistica La tipologia di statistica inferenziale da applicare si ba-sa sulla tipologia di variabili. Come abbiamo visto, possiamo distinguere fra variabilicategoriali, ordinali, ad intervalli e a rapporti.
este quaro tipologie possono essere raggruppate in variabili nominali (catego-riali e, generalmente, ordinali) e variabili numerie (a intervalli, a rapporti).
La tipologia di statistica e può essere applicata si basa sulla tipologia delle variabiliindipendenti e dipendenti.
Statistie bivariate
dipendente numerica dipendente categorialeindipendentenumerica
correlazione, regressione analisi discriminante, regres-sione logistica
indipendentecategoriale
t-test, ANOVA i quadro
. EserciziGenere e retribuzione Domanda: vi è una differenza di retribuzione fra masi efemmine?
� qual'è la variabile indipendente? Di e tipo è?

.. ESERCIZI
� qual'è la variabile dipendente? Di e tipo è?
� e tipo di statistica si applica?
Spettatori e pubblicità Domanda: C'è relazione fra il numero di persone e vanno avedere un film ed i soldi spesi per pubblicizzare la pellicola?
� qual'è la variabile indipendente? Di e tipo è?
� qual'è la variabile dipendente? Di e tipo è?
� e tipo di statistica si applica?
Antidepressivi e stato depressivo Domanda: La somministrazione di un antidepres-sivo è efficace nel curare la depressione?
� qual'è la variabile indipendente? Di e tipo è?
� qual'è la variabile dipendente? Di e tipo è?
� e tipo di statistica si applica?
Genere e facoltà Domanda: c'è un rapporto fra la scelta di un tipo di facoltà (umani-stica, scientifica) di uno studente ed il suo genere?
� qual'è la variabile indipendente? Di e tipo è?
� qual'è la variabile dipendente? Di e tipo è?
� e tipo di statistica si applica?
Nazionalità e caffè Domanda: c'è un rapporto fra la nazionalità delle persone ed illoro consumo di caffè?
� qual'è la variabile indipendente? Di e tipo è?
� qual'è la variabile dipendente? Di e tipo è?
� e tipo di statistica si applica?
Stato civile e genitorialità Domanda: c'è un rapporto fra lo stato civile di una personaed il fao e abbia o non abbia figli?
� qual'è la variabile indipendente? Di e tipo è?
� qual'è la variabile dipendente? Di e tipo è?
� e tipo di statistica si applica?

CAPITOLO . INTRODUZIONE ALL'ANALISI DEI DATI

Capitolo
L'approccio simulativo
Indice. Gli errori di campionamento . . . . . . . . . . . . . . . . . . . .
.. Distribuzione degli errori . . . . . . . . . . . . . . . . . . . Introduzione all'approccio simulativo . . . . . . . . . . . . . . .
.. Generare popolazione e campioni . . . . . . . . . . . . . . .. Campioni di numerosità . . . . . . . . . . . . . . . . .
. Intervallo di confidenza . . . . . . . . . . . . . . . . . . . . . . . Bootstrapping . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. Generare molti campioni da un campione . . . . . . . . . .. Confronto fra le distribuzioni . . . . . . . . . . . . . . . . .. Usare l'approccio parametrico . . . . . . . . . . . . . . . .
. Gli errori di campionamento
L'analisi dei dati deve confrontarsi con la gestione degli errori. Se una buona metodo-logia ed un correo campionamento possono minimizzare l'impao degli errori siste-matici, gli errori casuali non possono essere eliminati. L'analisi inferenziale permee alricercatore di stimare l'entità di questi errori, e di capire quanto le misure e le relazioniemerse siano da imputare a tali errori.
L'analisi si basa sul calcolo di alcune statistie. Nell'analisi univariata si calcola-no gli indici di centralità e di dispersione, nelle statistie bivariate si calcolano dellestatistie capaci di misurare le relazioni fra variabili.
Sia le statistie uni e bivariate devono tener conto dell'errore di campionamento.Facciamo alcuni esempi.
La media del campione costituisce la migliore stima della media della popolazione (lamedia è una stima unbiased); se dalla stessa popolazione, però, estraggo dieci campionidiversi, oerrò dieci stime differenti.
Un tipico disegno sperimentale consiste nel dividere il campione in gruppi, som-ministrare un traamento ad un gruppo (sperimentale), somministrare un diverso trat-

CAPITOLO . L'APPROCCIO SIMULATIVO
tamento (o un placebo) all'altro gruppo, e misurare l'effeo araverso una variabile nu-merica; per valutare l'effeo del traamento, si misura la differenza fra le medie dei duegruppi. Di nuovo: questa differenza va aribuita al traamento, o al caso (alla variabili-tà campionaria)? Infai, in maniera del tuo paragonabile all'esempio precedente, cosasuccederebbe se applicassimo lo stesso traamento (o nessun traamento) ai due grup-pi? Ci aspeiamo e le medie dei due gruppi siano perfeamente uguali? La risposta ènaturalmente no: le medie saranno probabilmente simili, ma non uguali.
Facciamo un terzo esempio: immaginiamo di voler capire se vi è una relazione fradue variabili numerie. Decidiamo di adoare la statistica della correlazione di Pear-son, una misura e si muove nel range −1 < r < +1 e dove significa assenzadi correlazione. Ane in questo caso, però, nella circostanza di due variabili fra loroindipendenti, non possiamo aspearci una correlazione esaamente pari a .
.. Distribuzione degli errori
Approccio parametrico
Fortunatamente, gli errori dovuti al caso (e alla varianza campionaria) sono soggei adelle distribuzioni note (quantomeno per quanto riguarda le statistie più comuni). Lacosiddea statistica parametrica si basa proprio sul fao e, se alcuni assunti sono ri-speati, la distribuzione dell'errore delle statistie usate approssima, previo opportunatrasformazione, delle distribuzioni teorie. Il processo inferenziale utilizza questa pro-prietà; si calcola la statistica, si opera la trasformazione, e si confronta il risultato con ladistribuzione teorica.
Statistie non parametrie
Lo svantaggio dell'approccio parametrico è e fa delle assunzioni sulle variabili; vi so-no delle circostanze in cui queste assunzioni non vengono rispeate. In questi casi, lestatistie parametrie possono essere inaffidabili; a questo punto, diventa opportunoaffidarsi a delle famiglie di statistie non parametrie, il cui vantaggio è quello di fareun minore numero di assunzioni.
Generalmente, l'approccio delle statistie non parametrie consiste nel trasformarela variabile dipendente, numerica, in una variabile ordinale. La trasformazione consistenel calcolare il rank, ovvero il valore ordinale della misura.
Approccio simulativo (resampling)
Esiste poi un'altra possibilità: utilizzare il calcolatore per generare la distribuzione del-l'errore, e basare il processo inferenziale non sulla distribuzione teorica, ma sulla distri-buzione generata.
esto approccio è relativamente recente, in quanto è computazionalmente oneroso,e dunque può essere applicato soltanto con degli strumenti di calcolo potenti. Oggi, però,possono essere applicati agevolmente ane con i comuni computer, e dunque stannoguadagnando crescente popolarità.
L'approccio simulativo ha alcuni vantaggi, il principale dei quali è e fa poissimeassunzioni, e dunque può essere applicato ane nel caso, ad esempio, di distribuzioni

.. INTRODUZIONE ALL'APPROCCIO SIMULATIVO
e non possono essere ricondoe alle distribuzioni teorie.Un secondo vantaggio è e l'approccio simulativo è e può essere applicato ane astatistie non comuni, per le quali non esiste -- o non è nota -- una distribuzione teorica.
L'approccio simulativo ha infine il vantaggio di essere particolarmente intuitivo, inquanto permee di mostrare l'errore di campionamento, la sua distribuzione, e i ri-speivi parametri. esta caraeristica rende l'approccio simulativo particolarmenteindicato ai fini didaici, in quanto è possibile simulare la varianza di campionamento,generare la distribuzione campionaria, e confrontarla con la distribuzione teorica. L'ap-proccio computazionale è inoltre un oimo modo per giocare con strumenti come R,prendere confidenza con il linguaggio, e capire cosa succede dietro alle quinte quandosi utilizzano le funzioni di testing -- parametrici e non parametrici.
. Introduzione all'approccio simulativo
Per introdurre l'approccio simulativo, utilizziamo R per fare delle simulazioni e cipermeano di riprodurre, in laboratorio, l'errore di campionamento.
Araverso la simulazione possiamo creare delle circostanze difficilmente riprodu-cibili nella realtà: possiamo generare una popolazione, generare un numero molto al-to di campioni, e valutare qualitativamente (graficamente) e quantitativamente l'errorestocastico di campionamento¹.
.. Generare popolazione e campioni
Generare la popolazione Nel contesto della simulazione, generare una popolazionesignifica generare un veore di valori casuali. Se si assume e la distribuzione dellapopolazione sia normale, è possibile utilizzare la funzione rnorm per generare un veoredi numeri distribuiti normalmente intorno ad una media e con una deviazione standardpredefinita.
La lunghezza del veore corrisponde alla numerosità della nostra popolazione vir-tuale.
Nel nostro esempio, genereremo una popolazione con media teorica e deviazionestandard teorica (la scelta di media e deviazione standard è arbitraria).
Generare dei campioni A partire dal veore popolazione, è possibile estrarre un vet-tore campione (di numerosità m < n). Per fare questo, R mee a disposizione la fun-zione sample(x,m,replace=FALSE), dove x è la popolazione e m è la numerosità delcampione.
In realtà, potremmo oenere lo stesso risultato generando un campione di m os-servazioni con rnorm. Però, per un effeo più realistico, usiamo il sampling dellapopolazione.
Per visualizzare la distribuzione dell'errore di campionamento, utilizzeremo una po-polazione di valori, e genereremo campioni di numerosità .
¹Un approccio simile è adoato in Molenaar and Kiers () e in Vasishth ()

CAPITOLO . L'APPROCCIO SIMULATIVO
Dunque n = (numerosità della popolazione simulata), k = (numero di cam-pioni), m = (osservazioni per campione). Poi, genereremo ane una serie di campionida osservazioni.
Analisi descrittiva Una volta generati questi dati, possiamo utilizzare alcune tecniedi analisi univariata per fare delle misurazioni.
In primo luogo possiamo calcolare la media e la deviazione standard della popola-zione. Ci aspeeremo e la prima sia prossima a e la seconda a . Poi, possiamovisualizzare un istogramma con la distribuzione della popolazione, e ci aspeiamo siadi tipo normale. Per verificarlo, possiamo usare le funzioni qqnorm e qqline.
> n <- 10000> m50 <- 50> K <- 200> media_teorica <- 20> sd_teorica <- 2> popolazione <- rnorm(n, media_teorica, sd_teorica)> mean(popolazione)
[1] 20.00628
> sd(popolazione)
[1] 2.015178
> hist(popolazione)
Utilizzando qqnorm, valutiamo la normalità della distribuzione
> qqnorm(popolazione)> qqline(popolazione, col = 2)
Ora, creiamo una matrice *. Ogni riga rappresenta un campione di osser-vazioni. Popoliamo le righe con la funzione sample, e campiona osservazioni dallapopolazione.
Media e deviazione standard della distribuzione campionaria
Con medie campioni50 <- apply(campioni50, 1, mean), calcoliamo la mediadi ogni campione e la salviamo nel veore (di lunghezza ) medie campioni. Suquesto veore calcoliamo la media e la deviazione standard (e rappresentano la mediadelle medie e la deviazione standard delle medie, ovvero l'errore standard.
> campioni50 <- matrix(nrow = K, ncol = m50)> for (k in 1:K) {+ campioni50[k, ] <- sample(popolazione, m50)+ }> medie_campioni50 <- apply(campioni50, 1, mean)> mean(medie_campioni50)

.. INTRODUZIONE ALL'APPROCCIO SIMULATIVO
Histogram of popolazione
popolazione
Fre
quen
cy
15 20 25
050
010
0015
00
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●●
●●
●
●●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●●●
●
●
●
●●
●●
●
●
●
●
●
●
●●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●●●●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●●
●●
●
●●
●
●
●●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●●
●●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●●●●●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●●
●●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●●
●●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●●●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●●
●●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
−4 −2 0 2 4
1520
25
Normal Q−Q Plot
Theoretical QuantilesS
ampl
e Q
uant
iles
Figura .: A sinistra, l'istogramma della popolazione: hist(popolazione). A destra,qqnorm(popolazione).
[1] 19.96062
> sd(medie_campioni50)
[1] 0.2813077
L'istogramma della distribuzione campionaria
> hist(medie_campioni50)
La normalità della distribuzione
> qqnorm(medie_campioni50)> qqline(medie_campioni50, col = 2)
Testiamo la normalità della distribuzione dellemedie campionarie, usando lo Shapiro-Wilk normality test.
> shapiro.test(medie_campioni50)
Shapiro-Wilk normality test
data: medie_campioni50W = 0.9958, p-value = 0.854
Leggere i risultati La funzione shapiro.test restituisce un p − value = 0.854 >α0.05. esto significa e non è rifiutata l'ipotesi di normalità. Dunque, non vi èviolazione della normalità della distribuzione.
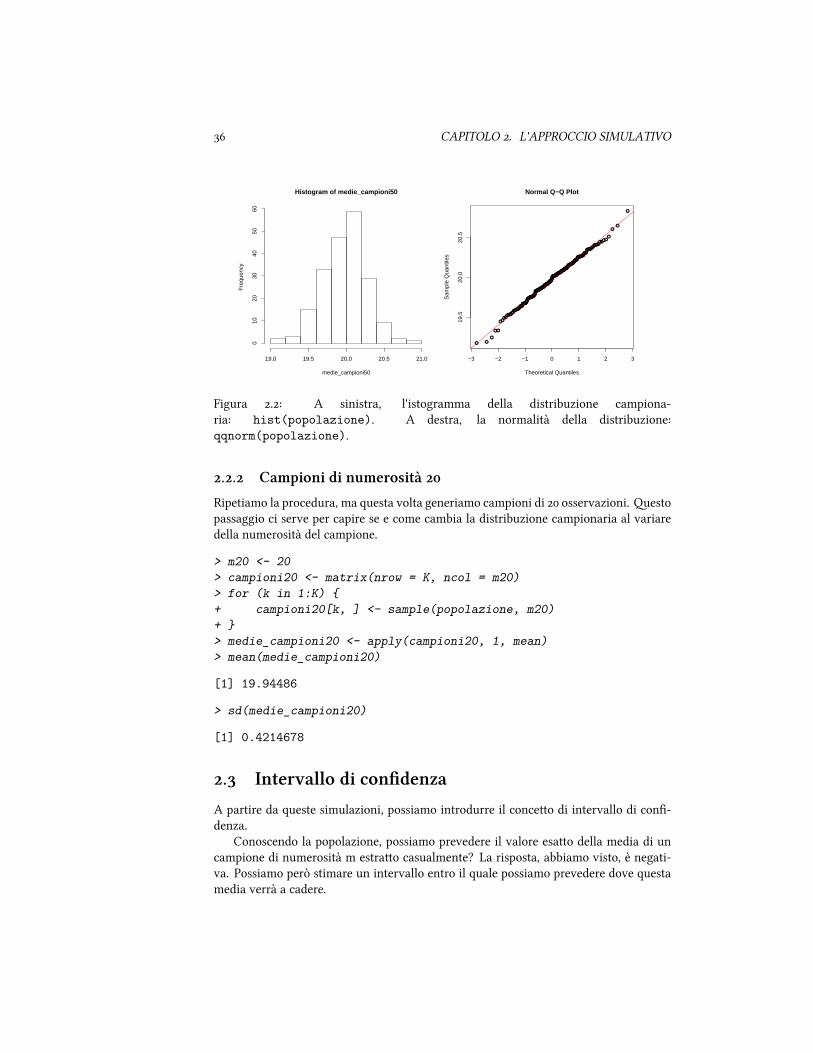
CAPITOLO . L'APPROCCIO SIMULATIVO
Histogram of medie_campioni50
medie_campioni50
Fre
quen
cy
19.0 19.5 20.0 20.5 21.0
010
2030
4050
60
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
−3 −2 −1 0 1 2 3
19.5
20.0
20.5
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Figura .: A sinistra, l'istogramma della distribuzione campiona-ria: hist(popolazione). A destra, la normalità della distribuzione:qqnorm(popolazione).
.. Campioni di numerosità
Ripetiamo la procedura, ma questa volta generiamo campioni di osservazioni. estopassaggio ci serve per capire se e come cambia la distribuzione campionaria al variaredella numerosità del campione.
> m20 <- 20> campioni20 <- matrix(nrow = K, ncol = m20)> for (k in 1:K) {+ campioni20[k, ] <- sample(popolazione, m20)+ }> medie_campioni20 <- apply(campioni20, 1, mean)> mean(medie_campioni20)
[1] 19.94486
> sd(medie_campioni20)
[1] 0.4214678
. Intervallo di confidenzaA partire da queste simulazioni, possiamo introdurre il conceo di intervallo di confi-denza.
Conoscendo la popolazione, possiamo prevedere il valore esao della media di uncampione di numerosità m estrao casualmente? La risposta, abbiamo visto, è negati-va. Possiamo però stimare un intervallo entro il quale possiamo prevedere dove questamedia verrà a cadere.

.. INTERVALLO DI CONFIDENZA
Nemmeno l'intervallo, però, può garantirci la sicurezza al %, in quanto non pos-siamo escludere di incorrere in campionamenti particolarmente sbilanciati da una parteo dall'altra.
La cosa più ragionevole da fare è quella di stabilire un livello di risio percentualeacceabile, e di calcolare l'intervallo in base a questo risio.
Calcolare il range Deo in altri termini, possiamo calcolare i valori minimo e mas-simo, e dunque il range, entro il quale, probabilmente, il (-risio)% delle medie deicampioni andrà a cadere.
Se, ad esempio, consideriamo acceabile un risio del %, calcoleremo il range entroil quale si collocano le medie del % dei campioni estrai. esto ci permee di tagliarele code estreme, a destra e a sinistra, della distribuzione.
Per fare questo, tagliamo il .% di campioni conmedia più bassa e il .% di campionicon media più alta.
La media del campione con media più bassa rimanente, e la media del campionecon media più alta rimanente, costituiscono il range e cercavamo, ovvero l'intervallodi confidenza. Per calcolare questi valori, sarà sufficiente estrarre i percentili . e .dalla distribuzione delle medie dei campioni.
> confidenza_campioni50 <- quantile(medie_campioni50, probs = c(0.025,+ 0.975))> confidenza_campioni20 <- quantile(medie_campioni20, probs = c(0.025,+ 0.975))> confidenza_campioni50
2.5% 97.5%19.44196 20.46475
> confidenza_campioni20
2.5% 97.5%19.08546 20.79953
Come possiamo notare, l'intervallo di confidenza della distribuzione campionaria èdiverso, cambiando la numerosità dei campioni. Nel caso di campioni di numerosità, il range è approssimativamente di ., mentre per i campioni di numerosità , èapprossimativamente di ..
Confrontare le due distribuzioni
Ora, usiamo la funzione density per confrontare le due distribuzioni, quella dei campionidi osservazioni, e quella dei campioni di . Abbiamo disegnato ane le due medie(le righe verticali) e gli intervalli di confidenza (le righe orizzontali).
> density20 <- density(medie_campioni20)> density50 <- density(medie_campioni50)> plot(density20, ylim = c(0, max(density50$y)), col = 2, lty = 2)
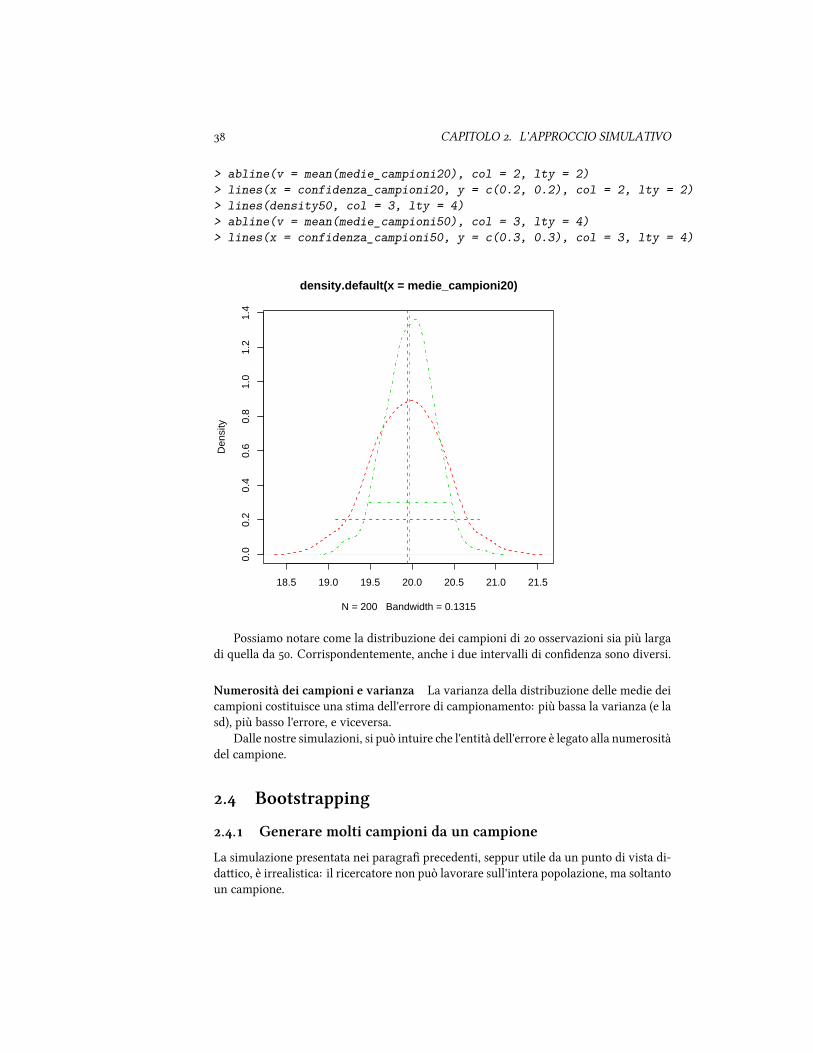
CAPITOLO . L'APPROCCIO SIMULATIVO
> abline(v = mean(medie_campioni20), col = 2, lty = 2)> lines(x = confidenza_campioni20, y = c(0.2, 0.2), col = 2, lty = 2)> lines(density50, col = 3, lty = 4)> abline(v = mean(medie_campioni50), col = 3, lty = 4)> lines(x = confidenza_campioni50, y = c(0.3, 0.3), col = 3, lty = 4)
18.5 19.0 19.5 20.0 20.5 21.0 21.5
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
density.default(x = medie_campioni20)
N = 200 Bandwidth = 0.1315
Den
sity
Possiamo notare come la distribuzione dei campioni di osservazioni sia più largadi quella da . Corrispondentemente, ane i due intervalli di confidenza sono diversi.
Numerosità dei campioni e varianza La varianza della distribuzione delle medie deicampioni costituisce una stima dell'errore di campionamento: più bassa la varianza (e lasd), più basso l'errore, e viceversa.
Dalle nostre simulazioni, si può intuiree l'entità dell'errore è legato alla numerositàdel campione.
. Bootstrapping
.. Generare molti campioni da un campione
La simulazione presentata nei paragrafi precedenti, seppur utile da un punto di vista di-daico, è irrealistica: il ricercatore non può lavorare sull'intera popolazione, ma soltantoun campione.

.. BOOTSTRAPPING
Inoltre, il compito del ricercatore è quello di stimare la media della popolazionepartendo dal campione, e non il contrario.
Partiamo da due osservazioni
� Se abbiamo a disposizione soltanto il nostro campione, lamiglior stima dellamediadella popolazione è la media del campione stesso.
� La distribuzione del campione dovrebbe assomigliare (al neo dell'errore statisti-co) alla distribuzione della popolazione. E, dunque, la distribuzione del campioneè la miglior stima e abbiamo della distribuzione della popolazione.
Se assumiamo e la media della popolazione è pari a quella del campione, e e anela distribuzione sia paragonabile, possiamo immaginare di generare numerosi campionifiizzi a partire dal campione noto.
Bootstrapping esta tecnica è nota come bootstrapping, e permee di calcolarel'intervallo di confidenza di un parametro (quale, ad esempio, la media).
Per generare un nuovo campione dal campione esistente, basta estrarre a caso mosservazioni dal campione originale.
Naturalmente, l'estrazione dev'essere con ripetizione. In caso contrario, il nuovocampione sarebbe identico. Dunque, alcuni elementi verranno estrai più di una volta,altri nessuna.
Percentili e intervallo di confidenza In questo modo, possiamo generare dei nuovicampioni dal campione esistente. Ane in questo caso possiamo calcolare la media perogni nuovo campione, e calcolare la distribuzione delle medie.
A partire da questa distribuzione, possiamo calcolare l'intervallo di confidenza, par-tendo dai percentili. Useremo i percentili . e . per un intervallo di confidenza del% (e un errore del %).
Per iniziare, prendiamo ora il primo dei campioni generati, ed usiamolo per ilbootstrapping. Calcoliamo il veore delle medie dei bootstrap. Calcoliamo la mediadelle medie.
> campioneA <- campioni50[1, ]> mean(campioneA)
[1] 19.96079
> bootstraps <- matrix(sample(campioneA, size = 10000, replace = TRUE),+ nrow = k, ncol = m50, byrow = TRUE)> medie_bootstraps <- apply(bootstraps, 1, mean)> confidenza_bootstraps <- quantile(medie_bootstraps, probs = c(0.025,+ 0.975))> mean(medie_bootstraps)
[1] 19.99533
> confidenza_bootstraps
2.5% 97.5%19.56849 20.50061

CAPITOLO . L'APPROCCIO SIMULATIVO
.. Confronto fra le distribuzioni
Nella sezione precedente, abbiamo visto la situazione ideale ma improbabile: conoscerel'intera popolazione, estrarre k campioni, calcolare la media per ognuno dei campioni;in questo modo abbiamo la vera distribuzione campionaria, di cui possiamo calcolaremedia e varianza.
In questa sezione, vediamo una situazione più realistica: abbiamo un campione, elavoriamo su quello. Araverso il bootstrapping, generiamo k campioni virtuali, e cal-coliamo la distribuzione campionaria virtuale. Per capire se il secondo algoritmo, reali-stico ma virtuale, produce risultati robusti, confrontiamo le due medie, i due intervallidi confidenza e le due distribuzioni nel grafico ..
> densityboot <- density(medie_bootstraps)> plot(density50, ylim = c(0, max(c(density50$y, densityboot$y))),+ col = 2, lty = 2)> abline(v = mean(medie_campioni50), col = 2, lty = 2)> lines(x = confidenza_campioni50, y = c(0.2, 0.2), col = 2, lty = 2)> lines(densityboot, col = 3, lty = 4)> abline(v = mean(medie_bootstraps), col = 3, lty = 4)> lines(x = confidenza_bootstraps, y = c(0.3, 0.3), col = 3, lty = 4)> abline(v = mean(popolazione))
19.0 19.5 20.0 20.5 21.0
0.0
0.5
1.0
1.5
density.default(x = medie_campioni50)
N = 200 Bandwidth = 0.08785
Den
sity
Figura .: Confronto fra la distribuzione bootstrap e la distrbuzione campionaria. Comepossiamo vedere, le due distribuzioni sono molto simili.
Le due distribuzioni, seppure non identie, sono molto simili.Ane gli intervalli di confidenza sono paragonabili: gli intervalli calcolati sui cam-pioni sono pari a . e .; gli intervalli calcolati araverso il bootstrappingsono . e ..
Possiamo dunque intuitivamente affermare e il metodo del bootstrapping riesce asimulare, in maniera piuosto precisa, la distribuzione campionaria.

.. BOOTSTRAPPING
.. Usare l'approccio parametrico
Il calcolo parametrico dell'intervallo di confidenza è l'argomento del prossimo capitolo.i, ci limitiamo ad anticipare i risultati del test parametrico t.test.
> t_campioneA <- t.test(campioneA)> t_campioneA$conf.int
[1] 19.47571 20.44586attr(,"conf.level")[1] 0.95
> confidenza_campioni50
2.5\% 97.5\%19.44196 20.46475
Il calcolo parametrico, resitiuisce un intervallo di confidenza di . e .. Co-me vediamo, il metodo parametrico e il metodo e usa il bootstrap non restituisconorisultati uguali, ma molto simili.

CAPITOLO . L'APPROCCIO SIMULATIVO

Capitolo
Intervallo di confidenza, calcoloparametrico
Indice. L'intervallo di confidenza . . . . . . . . . . . . . . . . . . . . .
.. La simulazione . . . . . . . . . . . . . . . . . . . . . . . . .. Dalla simulazione alla stima . . . . . . . . . . . . . . . . . .. La distribuzione t di Student . . . . . . . . . . . . . . . . .
. Confronto fra un campione ed una popolazione . . . . . . . . . .. Il p-value . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Primo esempio . . . . . . . . . . . . . . . . . . . . . . . . .. Secondo esempio . . . . . . . . . . . . . . . . . . . . . . .
. L'intervallo di confidenza
I concetti di base Riprendiamo alcuni dei concei alla base del calcolo dell'intervallodi confidenza: Spostare al capitolo ?
� il fine del calcolo è di stimare il parametro di una popolazione, partendo da uncampione
� la statistica calcolata sul campione viene usata come stima del parametro dellapopolazione: è una stima puntuale
� le metodologie e stimano l'errore sono finalizzati a stimare l'accuratezza dellastima
� l'intervallo di confidenza è il range entro il quale si prevede si colloi il parametrodella popolazione

CAPITOLO . INTERVALLO DI CONFIDENZA, CALCOLO PARAMETRICO
Bias e errori non sistematici Nella definizione di errore, dobbiamo distinguere fra glierrori sistematici e gli errori non sistematici
� l'errore sistematico è definito ane bias: una inaccuratezza dovuta ad un erroree sistematicamente alza o abbassa la stima.
� l'errore non sistematico, al contrario, tende ad aumentare la varianza delle osser-vazioni.
L'accuratezza di un processo di stima è influenzata sia dal bias e dalla varianza
Accuratezza, efficienza
� Per aumentare l'accuratezza, è necessario tentare di ridurre sia il bias e la va-rianza.
� A parità di bias, minore è la varianza dovuta all'errore e maggiore l'efficienza.
� Un buon processo di stima ha bias nullo e varianza bassa.
La media di un campione, ad esempio, è una stima unbiased, in quanto la distribuzionedelle medie si distribuisce normalmente intorno alla media della popolazione.
L'intervallo di confidenza La percentuale di confidenza si riferisce alla probabilitàe il valore del parametro della popolazione cada nell'intervallo identificato in base allanostra stima.
L'intervallo di confidenza copre, con una determinata probabilità, il parametro dellapopolazione, non noto.
Come abbiamo visto, l'intervallo può essere calcolato con un metodo non parame-trico, il bootstrapping.
L'intervallo di confidenza può essere calcolato ane con dei metodi parametrici.
Assunto di normalità
Poié questi metodi fanno delle assunzioni sulla distribuzione della popolazione (e delcampione), prima di applicarle è necessario verificare questa assunzione.
Deo in altri termini, prima di calcolare l'intervallo di confidenza è necessario veri-ficare e la distribuzione del campione non si discosti dalla distribuzione normale.
Una volta stabilita la normalità del campione e assunta la normalità della popolazio-ne, possiamo procedere con il calcolo.
.. La simulazione
Riprendiamo la distribuzione di campioni di numerosità , generata nel capitoloprecedente. Abbiamo visto e la distribuzione ha una forma e si approssima a quel-la normale, con media e si approssima alla media della popolazione. Formalmente:µX ≈ µ

.. L'INTERVALLO DI CONFIDENZA
Varianza della distribuzione delle medie Come abbiamo osservato, la varianza delladistribuzione delle medie dei campioni cambia a seconda della numerosità del campione.Più in particolare, la varianza della distribuzione delle medie tende ad essere pari allavarianza della popolazione / la numerosità delle osservazioni dei campioni:
σ2X =
σ2
m,σX =
σ√m
(.)
esta misura viene definita errore standard.Proviamo a verificare . con le nostre simulazioni.
> var(popolazione)/var(medie_campioni50)
[1] 50.50856
> var(popolazione)/var(medie_campioni20)
[1] 22.5553
Possiamo notare e il rapporto fra la varianza della popolazione e la varianza cam-pionaria è ≈ 50 nel primo gruppo (campioni con numerosità ), e ≈ 20 nel secondo,dove i campioni sono di numerosità .
.. Dalla simulazione alla stima
Nella circostanza della simulazione, conosciamo la popolazione, ne conosciamo la distri-buzione, la media, la varianza. Grazie all'equazione . possiamo stimare la distribuzionecampionaria. Il passaggio logico dei prossimi paragrafi sarà il seguente:
. stimiamo la distribuzione campionaria conoscendo media e varianza della popo-lazione;
. stimiamo la distribuzione campionaria stimando la media, conoscendo la varian-za;
. infine, la situazione più realistica: stimiamo la distribuzione campionaria stiman-do media e varianza.
Media e varianza nota
Assumiamo, per ora, di conoscere media e varianza della popolazione.Conoscendo la media della popolazione e la sua varianza, possiamo ricostruire la
distribuzione delle medie dei campioni, e sarà una distribuzione (teorica) normale conmedia µX = µ e deviazione standard σX = σ√
m(errore standard)
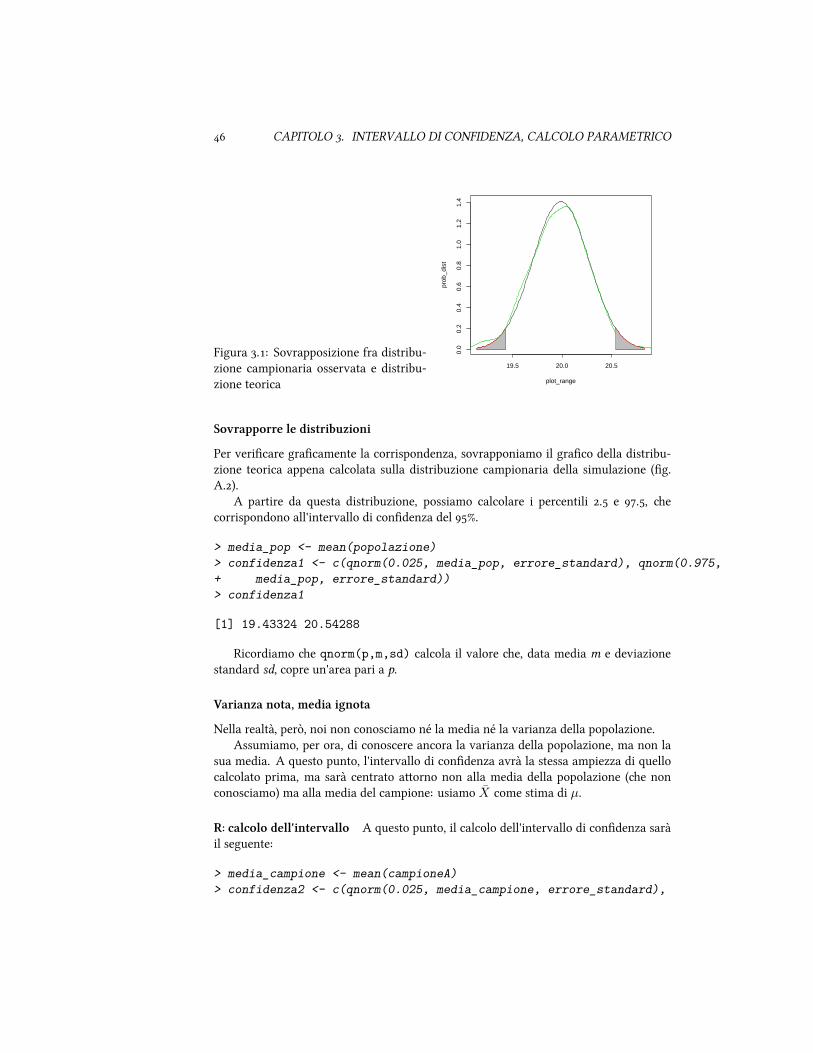
CAPITOLO . INTERVALLO DI CONFIDENZA, CALCOLO PARAMETRICO
Figura .: Sovrapposizione fra distribu-zione campionaria osservata e distribu-zione teorica
19.5 20.0 20.5
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
plot_range
prob
_dis
t
Sovrapporre le distribuzioni
Per verificare graficamente la corrispondenza, sovrapponiamo il grafico della distribu-zione teorica appena calcolata sulla distribuzione campionaria della simulazione (fig.A.).
A partire da questa distribuzione, possiamo calcolare i percentili . e ., ecorrispondono all'intervallo di confidenza del %.
> media_pop <- mean(popolazione)> confidenza1 <- c(qnorm(0.025, media_pop, errore_standard), qnorm(0.975,+ media_pop, errore_standard))> confidenza1
[1] 19.43324 20.54288
Ricordiamo e qnorm(p,m,sd) calcola il valore e, data media m e deviazionestandard sd, copre un'area pari a p.
Varianza nota, media ignota
Nella realtà, però, noi non conosciamo né la media né la varianza della popolazione.Assumiamo, per ora, di conoscere ancora la varianza della popolazione, ma non la
sua media. A questo punto, l'intervallo di confidenza avrà la stessa ampiezza di quellocalcolato prima, ma sarà centrato aorno non alla media della popolazione (e nonconosciamo) ma alla media del campione: usiamo X come stima di µ.
R: calcolo dell'intervallo A questo punto, il calcolo dell'intervallo di confidenza saràil seguente:
> media_campione <- mean(campioneA)> confidenza2 <- c(qnorm(0.025, media_campione, errore_standard),

.. CONFRONTO FRA UN CAMPIONE ED UNA POPOLAZIONE
+ qnorm(0.975, media_campione, errore_standard))> confidenza2
[1] 19.40597 20.51561
Varianza e media ignota
Arriviamo, ora, all'ipotesi più realistica: conosciamo media e deviazione standard delcampione, ma non quelle della popolazione.
Il passaggio più logico parrebbe quello di usare sX , la deviazione standard del cam-pione, come stima di σ, la deviazione standard della popolazione. In realtà, la deviazionestandard del campione è più bassa di quella della popolazione: se utilizziamo la primaal posto della seconda oeniamo un range irrealisticamente troppo streo.
Per correggere questo bias (è un errore sistematico) si utilizza, al posto della distri-buzione normale, la distribuzione t di Student.
.. La distribuzione t di Student
La t di Student è una classe di distribuzioni, e si basano sui gradi di libertà. Nel casodel nostro intervallo di confidenza, i gradi di libertà sono pari a m-. ¹
R: calcolo dal t di Student Calcoliamo l'errore standard stimato a partire dalla devia-zione standard del campione. Usiamo poi la funzione qt per calcolare i quantili .e . della distribuzione t con - gradi di libertà. Il risultato, sarà l'intervallo diconfidenza.
> errore_standard_stimato <- sd(campioneA)/sqrt(m50)> confidenza3 <- c(qt(0.025, df = 49) * errore_standard_stimato ++ mean(campioneA), qt(0.975, df = 49) * errore_standard_stimato ++ mean(campioneA))> confidenza3
[1] 19.47571 20.44586
L'uso della funzione t.test era stato anticipato in ... Il risultato -- in termini diintervallo di confidenza -- del test è quello calcolato con il codice appena mostrato.
. Confronto fra un campione ed una popolazione
Abbiamo appena visto la statistica parametrica per calcolare l'intervallo di confidenzadella stima del parametro della media di una popolazione, a partire da un campione. Nelcapitolo precedente abbiamo usato il bootstrapping, in questo il t test. Il test t di Student,però, può essere usato ane per stimare se un campione appartiene ad una popolazionela cui media è nota.
¹quando df>, la distribuzione t di Student tende ad approssimarsi alla distribuzione normale.

CAPITOLO . INTERVALLO DI CONFIDENZA, CALCOLO PARAMETRICO
In questo caso, si traa di stimare se il campione è stato estrao da una popolazionecon media µ oppure no.
In termini inferenziali, abbiamo le due ipotesi:
� ipotesi nulla,H0: non vi è differenza significativa fra la media del campione, X ela media della popolazione, µ;
� ipotesi alternativa, HA: la differenza fra le due medie è significativa, e dunque ilcampione non appartiene alla popolazione.
Per giungere alla nostra decisione inferenziale, ci viene in soccorso proprio l'inter-vallo di confidenza: se la media della popolazione cade all'interno dell'intervallo, nonpossiamo rifiutare l'ipotesi nulla. In caso contrario, rifiutiamo l'ipotesi nulla e acceiamol'ipotesi alternativa.
.. Il p-value
Vi è una possibilità complementare: calcolare il p-value. In termini inferenziali, il p-value ci dice la probabilità di incorrere in un errore di tipo I nel caso di rifiuto dell'ipotesinulla.
Di fao, quello e calcoliamo è la probabilità e il nostro campione possa esserestato estrao da una popolazione la cui media è pari ad un valore predefinito.
Decidiamo per un errore di I tipo pari ad α = 0.05 e, nella nostra simulazione,assumiamo un'ipotesi a due code.
Il primo passaggio, è quello di calcolare la differenza, in termini assoluti, fra la mediadel campione e quella della popolazione. Il secondo passaggio è di trasformare questadistanza in punti t, araverso la formula distanza / errore standard.
Infine, confrontiamo questo punteggio con la distribuzione t di Student, con gradi dilibertà pari a m-.
.. Primo esempio
Come primo esempio, calcoliamo il p-value della differenza fra la media della popo-lazione e quella del campione campioneA. Poié il campione è stato estrao dallapopolazione, ci aspeiamo e il p-value sia alto (superiore ad α).
Calcolo con R
> distanza1 <- abs(mean(campioneA) - mean(popolazione))> t1 <- distanza1/errore_standard_stimato> p_value1 <- (1 - pt(t1, df = 49)) * 2> t1
[1] 0.1129748
> p_value1
[1] 0.910512

.. CONFRONTO FRA UN CAMPIONE ED UNA POPOLAZIONE
R: uso del t.test Dopo aver calcolato manualmente il p-value, ci affidiamo alla funzio-ne t.test.
> t.test(campioneA, mu = mean(popolazione))
One Sample t-test
data: campioneAt = -0.113, df = 49, p-value = 0.9105alternative hypothesis: true mean is not equal to 19.9880695 percent confidence interval:19.47571 20.44586sample estimates:mean of x19.96079
L'algoritmo usato dalla funzione t.test è leggermente diverso: non viene usato il valo-re assoluto della differenza, e il punteggio t in questo caso è negativo. Il principio rimanecomunque lo stesso -- e il risutato ane.
Leggere l'output La funzione t.test ci restituisce tue le informazioni di cui abbia-mo bisogno: la statistica calcolata: One Sample t-test ; i gradi di libertà: df = 49; ilp-value: p-value = 0.9105; l'intervallo di confidenza al %. Poié p > α = 0.05,non rifiutiamo l'ipotesiH0.
.. Secondo esempio
Proviamo ora a confrontare il nostro campione con una media più alta: .. In questocaso, sapendo e . è esterno all'intervallo di confidenza, ci aspeiamo un p-valueinferiore ad α = 0.05.
R: p-value, media=
> distanza2 <- abs(mean(campioneA) - 20.8)> t2 <- distanza2/errore_standard_stimato> p_value2 <- (1 - pt(t2, df = 49)) * 2> t2
[1] 3.476694
> p_value2
[1] 0.001073598

CAPITOLO . INTERVALLO DI CONFIDENZA, CALCOLO PARAMETRICO
R: uso del t.test Dopo aver calcolato manualmente il p-value, ci affidiamo alla funzio-ne t.test.
> t.test(campioneA, mu = 20.8)
One Sample t-test
data: campioneAt = -3.4767, df = 49, p-value = 0.001074alternative hypothesis: true mean is not equal to 20.895 percent confidence interval:19.47571 20.44586sample estimates:mean of x19.96079
Poié, in questo caso, p − value = 0.001 < α = 0.05, rifiutiamo l'ipotesi H0 eacceiamo l'ipotesi alternativaHA.

Capitolo
Confronto fra variabilicategoriali: χ2
Indice. Variabili nominali . . . . . . . . . . . . . . . . . . . . . . . . . . Confronto di una distribuzione campionaria con una distribu-
zione teorica . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Un esempio: distribuzione occupati . . . . . . . . . . . . .
. Stima dell'errore . . . . . . . . . . . . . . . . . . . . . . . . . . . La simulazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . La distribuzione χ2 . . . . . . . . . . . . . . . . . . . . . . . . .
.. La funzioneisq.test . . . . . . . . . . . . . . . . . . . . . Confronto fra due variabili nominali . . . . . . . . . . . . . . .
.. Calcolare le frequenze aese . . . . . . . . . . . . . . . .
. Variabili nominali
Statistie sulle variabili nominali A partire da una variabile nominale è possibileoenere un numero limitato di statistie descriive, univariate. ello e è possibilefare, in pratica, è creare una tabella di contingenza unidimensionale, ovvero un veorela cui lunghezza è pari al numero di livelli, e dove il valore di ogni cella è pari al numerodi osservazioni e appartengono alla corrispondente categoria.
A partire da questa rappresentazione, è possibile calcolare l'indice centrale dellamoda.
Distribuzioni categoriali Da un punto di vista inferenziale, è possibile utilizzare la di-stribuzione delle osservazioni del campione come stima della frequenza di ogni categorianella popolazione.

CAPITOLO . CONFRONTO FRA VARIABILI CATEGORIALI: χ2
. Confronto di una distribuzione campionaria con unadistribuzione teorica
Vi sono circostanze, in cui l'ipotesi di ricerca è finalizzata a confrontare la distribuzio-ne categoriale di un campione, rispeo ad una distribuzione teorica riguardante unapopolazione.
.. Un esempio: distribuzione occupati
Facciamo un esempio. Assumiamo e, in Italia, il % della popolazione occupata la-vori nell'agricoltura, il % nell'industria, e il rimanente % nel terziario (le cifre sonoassolutamente inventate).
Potremmo iederci se, in una determinata provincia, la distribuzione categoriale sidiscosta o meno dalla distribuzione ipotizzata.
Per fare questo, possiamo estrarre un campione dalla popolazione provinciale de-gli occupati, creare la relativa tabella di contingenza, e capire se la distribuzione delcampione rispea le cosiddee frequenze aese.
Calcolo frequenze attese Il calcolo delle frequenze aese è semplice: basta moltipli-care la probabilità aesa (ovvero la probabilità e, data la popolazione di riferimen-to, venga estraa una osservazione appartenente ad una determinata categoria) per lanumerosità del campione.
Se immaginiamo di utilizzare un campione di persone, la frequenza aesa saràdi persone e lavorano nell'agricoltura, nell'industria, nel terziario.
. Stima dell'errore
Errore di campionamento A causa dell'errore non sistematico di campionamento,però, difficilmente le frequenze osservate saranno uguali alle frequenze aese.
Il compito della statistica inferenziale, in questo caso, sarà quello di stabilire se la dif-ferenza fra le frequenze osservate e quelle aese sono da aribuire o meno al caso. Nellaprima ipotesi, non si rifiuta l'ipotesi nulla, secondo cui non vi è differenza significativafra le frequenze osservate e quelle aese, e dunque si assume e non vi sia differenzafra la distribuzione della provincia in esame e quella nazionale, di riferimento.
Nella seconda ipotesi, si rifiuterà l'ipotesi nulla, e di conseguenza si assumerà evi è una differenza significativa fra la distribuzione di frequenza del campione e quelladella popolazione.
Nel nostro esempio, si assumerà e una differenza fra il nostro campione e la po-polazione nazionale di riferimento, e pertanto e la distribuzione di frequenza nelle trecategorie è, nella popolazione provinciale, diversa da quella nazionale.
La statistica
Stimare la differenza fra le fequenze Per fare questo, abbiamo bisogno di una misurae ci permea di calcolare la differenza fra due tabelle.

.. LA SIMULAZIONE
Informalmente, abbiamo bisogno di una misura e stimi la distanza fra due tabelle,e dunquee sia pari a zero se le due tabelle sono uguali, e sia positiva se le due tabellesono differenti, e e cresca al crescere delle differenze.
In leeratura, vengono citate tre possibili misure.
� il χ2 di Pearson :
χ2 =r∑i
c∑j
(Oij − Eij)2
Eij(.)
� Il likelihood ratio i square :
G2 = 2r∑i
c∑j
(Oij × log(Oij
Eij)) (.)
� il test di Fisher.
La misura più nota, e utilizzeremo, è il χ2 di Pearson ..
Numerosità delle frequenze attese Com'è intuibile, sia l'equazione . e la . sonopoco adae a circostanze in cui la frequenza aesa di una delle celle è molto bassa(generalmente, si assume e sia la frequenza aesa minima).
. La simulazionePer introdurre la stima della probabilità e la distribuzione di frequenze di un campionesia significativamente diverso dalla distribuzione aesa, useremo di nuovo il metododella simulazione.
Più in particolare, andiamo a generare k campioni di una variabile categoriale conuna determinata frequenza aesa, e per ogni campione misuriamo, utilizzando l'equa-zione ., la distanza fra la distribuzione osservata e quella aesa.
La distribuzione delle distanze dei k campioni ci permee di stimare la distribuzionedell'errore di campionamento, di stabilire i valori critici e corrispondono ad un erroreα, e al calcolo del p-value di una distribuzione.
Generiamo un'urna Generiamo un'urna, di valori, da cui estrarre i campioni.
> atteso <- c(rep(1, 17), rep(2, 51), rep(3, 32))> t_atteso <- table(atteso)> prob_attesa <- t_atteso/length(atteso)
Di fao, in questa simulazione utilizziamo il metodo delle permutazioni .
Generiamo i campioni Generiamo . tabelle da elementi, estrai (con ripe-tizione) dall'urna sopra creata. Per ogni tabella, calcoliamo la distanza dalla tabella diriferimento (t aeso) usando la formula del χ2, e la salviamo in un veore, distanza oss(distenza osservata).

CAPITOLO . CONFRONTO FRA VARIABILI CATEGORIALI: χ2
R: generazione dei campioni
> distanza_oss <- vector(mode="numeric",+ length=10000)> for (ciclo in 1:length(distanza_oss)) {+ campione <- sample(atteso, 100,+ replace = TRUE)+ t_campione <- table(campione)+ chi_quadro <-+ sum(((t_campione - t_atteso)^2)/t_atteso)+ distanza_oss[ciclo] <- chi_quadro+ }
Figura .: L'istogramma della distribu-zione dell'errore. Come possiamo no-tare (e come potevamo aspearci) ladistribuzione è asimmetrica.
Histogram of distanza_oss
distanza_oss
Den
sity
0 5 10 15 20
0.0
0.1
0.2
0.3
R: Valori critici calcoliamo i valori critici per α = 0.05 e ., ovvero il 95o ed il 99o
percentile.
> quantile(distanza_oss, probs = c(0.95, 0.99))
95% 99%5.884191 9.477457
Valori critici e inferenza esto calcolo ci permee di inferire e possiamo rifiutarel'ipotesi nulla quando la distanza della tabella osservata da quella aesa (misurata conla formula .) è > . (con α = 0.05) o > . (con α = 0.01)
Possiamo dunque generare un nuovo campione, calcolare la distanza dalla distribu-zione aesa, e confrontarla con i valori critici.
R: Generazione di un nuovo campione Generiamo un nuovo campione, calcoliamola tabella di contingenza, e calcoliamo il χ2. Poié il campione è generato a partiredall'urna, ci aspeiamo e la statistica calcolata non sia significativa.

.. LA SIMULAZIONE
> campione <- sample(atteso, 100, replace = TRUE)> t_campione <- table(campione)> chi_quadro <-+ sum(((t_campione - t_atteso)^2)/t_atteso)> chi_quadro
[1] 0.09007353
Stima del p-value Inoltre, possiamo stimare il p-value, ovvero la probabilità di com-piere un errore di tipo I rifiutando l'ipotesi nulla. Per fare questo, basta aggiungere ladistanza del nuovo campione al veore delle . distanze, e calcolare la posizionedella distanza rispeo a tue le altre (usando la funzione rank()).
Calcolo della posizione
> posizione <-+ rank(c(chi_quadro, distanza_oss))[1]> p_value <- 1 - posizione/length(distanza_oss)> p_value
[1] 0.94675
Non rifiuto dell'ipotesi nulla In questo caso, dunque, non rifiutiamo l'ipotesi nulla,in quanto
� il valore del χ2 è inferiore al valore critico con α = 0.05: . < .
� il p-value è pari a ., ovvero ben sopra ad α = 0.05.
Calcolo su nuovo campione Proviamo ora a fare la stessa verifica, ma questa voltapartendo da un campione da noi generato, in cui le frequenze osservate sono pari a ,, .
È facile intuire e questa distribuzione è molto diversa da quella aesa: .Il calcolo inferenziale, però, ci permee una stima più precisa.
R: Calcolo su nuovo campione
> t_campione2 <- c(22, 35, 43)> chi_quadro <-+ sum(((t_campione2 - t_atteso)^2)/t_atteso)> chi_quadro
[1] 10.27145
> posizione <-+ rank(c(chi_quadro, distanza_oss))[1]> p_value <- 1 - posizione/length(distanza_oss)> p_value

CAPITOLO . CONFRONTO FRA VARIABILI CATEGORIALI: χ2
[1] 0.00705
Rifiuto dell'ipotesi nulla In questo caso, dunque, rifiutiamo l'ipotesi nulla, in quanto
� il valore del χ2 è superiore ad entrambi i valori critici: con α = 0.01: . > .
� conseguentemente, il p-value (pari a .), è inferiore ad α = 0.01.
. La distribuzione χ2
La distribuzione χ2 Nella sezione precedente, abbiamo calcolato valori critici e p-value basandoci sulla distribuzione dell'errore di campionamento generata dalla simu-lazione.
La distribuzione e abbiamo oenuto, applicando la formula del χ2, è una distri-buzione nota con il nome distribuzione χ2.
L'ambiente R mee a disposizione delle funzioni e, similmente alle distribuzioninormale e t di Student, permee di calcolare alcuni valori legati alla distribuzione χ2.
χ2: funzioni in R Con risq è possibile generare dei valori casuali, con distribuzioneχ2. Con disq possiamo oenere la densità della distribuzione per un determinatovalore.
Così come per la distribuzione t di Student, ane la χ2 è una famiglia di distribu-zioni, e differiscono fra loro in base ai gradi di libertà (df, degree of freedom).
Pertanto, le funzioni legate al χ2 si aendono, fra gli argomenti, ane i gradi dilibertà.
Gradi di libertà Nell'esempio precedente, la tabella delle distribuzioni aveva un rangopari a (ovvero, avevamo categorie: agricoltura, industria, terziario).
In una tabella unidimensionale, i gradi di libertà sono pari a r-. Nel nostro caso,dunque df=.
Nel prossimo grafico, visualizziamo nuovamente l'istogramma delle distribuzionidella distanza dai campioni generati alle frequenze aese (figura .). All'istogrammasovrapponiamo la distribuzione χ2 con gradi di libertà.
Sovrapposizione fra distribuzione osservata e teorica
> plot_range <- seq(0, 15, by = 0.25)> prob_dist <- dchisq(plot_range, 2)> hist(distanza_oss, freq = FALSE, breaks = 20)> lines(plot_range, prob_dist, type = "l", col = 2)
Utilizzo della distribuzione Come vediamo, la distribuzione della nostra simulazionesi sovrappone quasi perfeamente alla distribuzione χ2. Appurata questa sovrapposi-zione, possiamo sfruare la distribuzione χ2 per calcolare valori critici e p-value.
Ad esempio, grazie alla funzione pisq possiamo calcolare il p-value dei due cam-pioni e abbiamo utilizzato negli esperimenti precedenti.

.. LA DISTRIBUZIONE χ2
Histogram of distanza_oss
distanza_oss
Den
sity
0 5 10 15 20
0.0
0.1
0.2
0.3
Figura .:Sovrappo-sizione fradistribuzioneosservata edistribuzioneteorica chi2
con gradi dilibertà.
R: Calcolo del p-value usando pisq la funzione pisq, analogamente a pnorm, cipermee di calcolare l'area della distribuzione a destra di un determinato valore. Con - pisq calcoliamo l'area rimanente, e corrisponde al p-value.
> 1 - pchisq(0.09007353, df = 2)
[1] 0.9559623
> 1 - pchisq(10.27145, df = 2)
[1] 0.005882785
Approssimazione dei risultati Come possiamo notare, i p-value non sono identicia quelli oenuti partendo dalla simulazione, in quanto la sovrapposizione fra la di-stribuzione oenuta dalla simulazione non è perfeamente identica alla distribuzioneteorica.
Ciononostante, i valori sono molto simili, e ci portano a trarre le stesse conclusioni:non rifiuto diH0 nel primo caso, rifiuto nel secondo.

CAPITOLO . CONFRONTO FRA VARIABILI CATEGORIALI: χ2
.. La funzioneisq.test
Il nostro excursus ha, naturalmente, una finalità esclusivamente didaica. In pratica, percalcolare il test del χ2, R ci mee a disposizione la funzioneisq.test, e ci restituisceil calcolo del χ2, i gradi di libertà, e il p-value.
Appliiamo la funzione al primo gruppo.
> chisq.test(x = t_campione, p = prob_attesa)
Chi-squared test for given probabilities
data: t_campioneX-squared = 0.0901, df = 2, p-value = 0.956
La funzione ci restituisce il calcolo del χ2, i gradi di libertà (df), il p-value.
isq.test, secondo gruppo Appliiamo la stessa funzione al secondo gruppo.
> chisq.test(x = t_campione2, p = prob_attesa)
Chi-squared test for given probabilities
data: t_campione2X-squared = 10.2714, df = 2, p-value = 0.005883
. Confronto fra due variabili nominali
Statistica bivariata Nella sezione precedente abbiamo analizzato il caso di del con-fronto fra una distribuzione osservata ed una aesa.
La procedura, però, può essere utilizzata ane per valutare delle ipotesi relative alrapporto e intercorre fra due variabili nominali, ovvero nel contesto di una statisticabivariata.
Esempio: categoria lavorativa e genere Per introdurre questa statistica, modifiia-mo l'esempio precedente. Immaginiamo di voler capire se, nella distribuzione della forzalavoro fra agricoltura, industria e terziario, vi sono differenze di genere.
Per fare questo, raccogliamo un campione di persone aive, e per ognuno di loroidentifiiamo il genere e la categoria lavorativa (agricoltura, industria, terziario).
Il processo
� A partire da questi dati, possiamo creare una tabella di contingenza a doppia en-trata, di dimensione r * c, dove r è pari al rango della prima variabile, e c a quellodella seconda.
� In secondo luogo, calcoliamo la tabella delle frequenze aese.

.. CONFRONTO FRA DUE VARIABILI NOMINALI
� Calcoliamo, araverso la formula ., la distanza fra le frequenze aese e quelleosservate.
� Calcoliamo il p-value, araverso la funzione 1−pchisq(χ2, df = (r−1)(c−1))
.. Calcolare le frequenze attese
L'unica novità di rilievo, rispeo all'algoritmo relativo ad una sola variabile, è il calcolodelle frequenze aese è più complicato (ma non troppo)
Nuovamente, le frequenze aese si basano sull'ipotesi nulla, ovvero e non vi siaalcun legame fra le due variabili.
In termini di probabilità condizionale, si assume e la probabilità e un indivi-duo appartenga ad una delle categorie della seconda variabile non cambi a seconda el'individuo appartenga ad una categoria della prima, e viceversa.
L'ipotesi di indipendenza Nel nostro esempio, l'ipotesi di indipendenza assume eil fao di essere masio (o femmina) non influisca sulla probabilità di essere occupatonell'agricoltura, nell'industria o nel terziario, e viceversa: il fao di essere impiegato nelterziario non incide sulla probabilità di essere masio o femmina. Formalizzare l'ipotesi di indi-
pendenzaIn base a questa assunzione, la frequenza aesa, nella categoria agricoltura, masioè pari alla probabilità associata alla categoria agricoltura, moltiplicata per la probabilitàassociata alla categoria masio, moltiplicata per la numerosità del campione.
Frequenze attese Continuiamo ad assumere probabilità pari a ., . e . per la va-riabile tipo di occupazione, e assumiamoe la popolazione aiva sia per il % masilee per il % femminile (di nuovo, sono percentuali inventate). Decidendo per un cam-pione di persone, la frequenza aesa, per la casella agricoltore masio, sarà pari a. * . * = .
fe[i,j] =fifjn
(.)
fe[i,j] = pipjn (.)
R: Generare il data-frame Creiamo un data.frame con due colonne: il genere e l'oc-cupazione. In primo luogo creiamo un'urna, con probabilità . e ., da cui estrarreil genere. Poi, usando l'urna precedente (relativa all'occupazione), creiamo un veoredi osservazioni. Creiamo un secondo veore, nuovamente di osservazioni, re-lative al genere. Creiamo infine il data.frame con i due veori, campione genere ecampione occupazione.
> genere_atteso <- c(rep(1, 54), rep(2, 46))> t_genere_atteso <- table(genere_atteso)> prob_genere_attesa <-* t_genere_atteso/length(genere_atteso)> campione_occupazione <-* sample(atteso, 100, replace = FALSE)> campione_genere <-

CAPITOLO . CONFRONTO FRA VARIABILI CATEGORIALI: χ2
* sample(genere_atteso, 100, replace = FALSE)> campione <-* data.frame(campione_genere, campione_occupazione)> t_campione <- table(campione)
R: calcolo delle probabilità attese Calcoliamo le probabilità aese. Calcoliamo lasomma marginale delle righe e delle colonne. Calcoliamo le probabilità aese, pari a(marginale riga/numerosità campione) * (marginale colonna/numerositàcampione).
> marginali_riga <- apply(t_campione, 1, sum)> marginali_colonna <- apply(t_campione, 2, sum)> prob_att <-+ (marginali_riga/100) \%*\%+ t(marginali_colonna/100)
Frequenze attese e osservate Le frequenze aese sono pari alle probabilità aese,moltiplicate per il numero di osservazioni.
> t_atteso <- prob_att * 100> t_atteso
1 2 3[1,] 9.18 27.54 17.28[2,] 7.82 23.46 14.72
> t_campione
campione_occupazionecampione_genere 1 2 3
1 12 27 152 5 24 17
R: calcolo di χ2 e p-value Calcoliamo il valore della statistica χ2. Calcoliamo poi ilp-value, utilizzando la funzione pchisq.
> chi_quadro <-+ sum(((t_campione - t_atteso)^2)/t_atteso)> p_value <- 1 - pchisq(chi_quadro, df = 2)> chi_quadro
[1] 2.560209
> p_value
[1] 0.2780083

.. CONFRONTO FRA DUE VARIABILI NOMINALI
R: uso diisq.test Naturalmente, lo stesso calcolo può essere eseguito -- più agevol-mente -- usando la funzione chisq.test.
> chisq.test(t_campione)
Pearson's Chi-squared test
data: t_campioneX-squared = 2.5602, df = 2, p-value = 0.278
Leggere l'output La funzione chisq.test ci restituisce il nome del test: Pearson'sChi-squared test ; il valore della statistica: X-squared = .; i gradi di libertà: df = ;il p-value = ..
Non rifiuto dell'ipotesi nulla Come prevedibile -- considerata la modalità con cuiabbiamo generato il campione -- dal calcolo del χ2 non possiamo rifiutare l'ipotesi nulla,in quanto p− value = 0.278 > α = 0.05.
Le frequenze osservate nel data frame generato scegliendo le due variabili in manieraindipendente non si discostano significativamente dalle frequenze aese.

CAPITOLO . CONFRONTO FRA VARIABILI CATEGORIALI: χ2

Capitolo
T test: confronto fra medie didue campioni
Indice. Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Calcolo non parametrico . . . . . . . . . . . . . . . . . . . . . .
.. La simulazione . . . . . . . . . . . . . . . . . . . . . . . . .. La distribuzione U Mann-Whitney-Wilcoxon . . . . . . . .
. Approccio parametrico . . . . . . . . . . . . . . . . . . . . . . . .. Assunzioni . . . . . . . . . . . . . . . . . . . . . . . . . . .. R: p-value usando la distribuzione . . . . . . . . . . . . . . .. Uso della funzione t.test . . . . . . . . . . . . . . . . . .. Conclusioni . . . . . . . . . . . . . . . . . . . . . . . . .
. Introduzione
Confronto fra due medie Nel capitolo , abbiamo introdoo il confronto fra variabilidi tipo categoriale. In questo capitolo, affronteremo la statistica e permee di valutarela relazione fra una variabile di tipo categoriale ed una numerica (ad intervalli o rap-porti). Nel caso specifico, ci limitiamo alla circostanza in cui la variabile indipendente,categoriale, ha due sole categorie.
In questa circostanza, le osservazioni sulla variabile dipendente, numerica, vengonodivise in due insiemi. Il questito inferenziale e ci si pone è di valutare se i valori dellavariabile dipendente, di tipo numerico, differiscono significativamente da un gruppoall'altro.
Nel confronto fra due campioni si può adoare l'approccio parametrico, utilizzan-do il t-test, oppure un approccio non parametrico. In questo capitolo, verrà introdooprima l'approccio non parametrico, in quanto più intuitivo, e dopo l'approccio parame-trico. In entrambi i casi, l'argomento verrà affrontato prima con un approccio simula-

CAPITOLO . T TEST: CONFRONTO FRA MEDIE DI DUE CAMPIONI
tivo, e poi utilizzando la distribuzione teorica di riferimento. Infine, verrà utilizzata lacorrispondente funzione di R e ne verranno lei i risultati.
. Calcolo non parametrico
Approccio intuitivo Intuitivamente, possiamo dire e i due gruppi differiscono se lemisurazioni di un gruppo sono, in genere, sistematicamente più alte (o più basse) dellemisurazioni sull'altro gruppo.
Se tue le osservazioni di un gruppo (iamiamolo gruppo B) sono più elevate di tuele osservazioni dell'altro (gruppo A), possiamo inferire e, relativamente alla variabilemisurata, vi è una differenza significativa fra il gruppo B ed il gruppo A.
Seguendo questa intuizione, un metodo per valutare se la variabile indipendente, ca-tegoriale, ha una relazione sulla variabile dipendente (numerica), è quello di confrontareogni elemento del gruppo A con ogni elemento del gruppo B.
Confronto fra elementi Sempre facendo ricorso all'intuizione, appare iaro e se ilnumero di confronti vinti da un gruppo è molto superiore al numero di confronti vintidall'altro, la differenza è significativa.
In questo conteggio, possiamo arrivare a due condizioni estreme: nella prima, glielementi di A vincono tui i confronti nei confronti di tui gli elementi di B; nellaseconda, sono gli elementi di B a vincere tui i confronti.
L'ipotesi nulla, H0, assume la parità fra il numero di confronti vinti da A e vinti daB.
.. La simulazione
Errore di campionamento Sappiamo però e è molto improbabile e il confrontofra i due gruppi sia perfeamente pari. Come sappiamo, infai, ane nella circostanzain cui i due campioni sono estrai dalla stessa popolazione ed assegnati ad una o all'altracategoria a caso, emergeranno delle differenze dovute all'errore di campionamento.
Generare la distribuzione dell'errore Per stimare l'entità di questo errore, e misurarela probabilità e una differenza sia aribuibile o meno ad esso, possiamo usare la stessametodologia vista nei capitoli precedenti:
� generare k coppie di campioni, estrae ed assegnate casualmente;
� calcolare il numero di confronti vinti dall'uno e dall'altro gruppo;
� salvare questi valori in un veore, e costituisce la distribuzione dell'errore dicampionamento.
Confrontare una coppia di campioni Potendo disporre della distribuzione dell'erroredi campionamento, data una coppia di campioni possiamo calcolare il numero di vioriedell'uno e dell'altro gruppo, e valutare dove si collocano nella distribuzione.

.. CALCOLO NON PARAMETRICO
Se il risultato di questi confronti si colloca sulle code della distribuzione, possiamorifiutare l'ipotesi nulla ed acceare l'ipotesi alternativa, ovvero e vi è una differenzasignificativa fra i due gruppi.
In caso contrario, non si rifiuta l'ipotesi nulla.
R: genero la popolazione, due campioni Generiamo una popolazione di . unità,con media , sd e distribuzione normale, usando rnorm.
> n <- 10000> m <- 100> k <- 10000> media_teorica <- 20> sd_teorica <- 2> popolazione <- rnorm(n, media_teorica, sd_teorica)
R: calcoliamo i confronti fra i due campioni Estraiamo ora campioni dalla popola-zione. Instanziamo due contatori, sumA e sumB. Con un ciclo for annidato, confrontiamoogni valore del campione con ogni valore del campione ¹. Incrementiamo il contato-re sumA quando a vincere è l'unità del campione, incrementiamo sumB quando vincecampione.
> campione1 <- sample(popolazione, m, replace = FALSE)> campione2 <- sample(popolazione, m, replace = FALSE)> sumA <- 0> sumB <- 0> for (x in 1:m) {+ oss1 <- campione1[x]+ for (y in 1:m) {+ oss2 <- campione2[y]+ if (oss2 > oss1) {+ sumA <- sumA + 1+ }+ else {+ sumB <- sumB + 1+ }+ }+ }
R: risultati Non dovrebbe sorprenderci il fao e la somma dei due valori è pari am*m, ovvero il numero dei confronti.
> c(sumA, sumB)
[1] 4793 5207
esta statistica viene iamata Mann-Whitney-Wilcoxon U
¹Per semplicità, ssumiamo e non vi siano pareggi fra i confronti.

CAPITOLO . T TEST: CONFRONTO FRA MEDIE DI DUE CAMPIONI
Calcolo della posizione ordinale È però possibile oenere lo stesso risultato con uncalcolo diverso: l'insieme di tue le osservazioni viene ordinato, e ad ogni osservazioneviene assegnato un punteggio pari alla sua posizione;
� per ognuno dei due gruppi, si somma il punteggio di ogni osservazione;
� a questi valori, si sorae quelloe è il minimo valore possibile, ovverom*(m+)/.
Il vantaggio di questo algoritmo è e può essere esteso a confronti fra più di due gruppi.
R: il calcolo del ranking
> due_rank <- matrix(rank(c(campione1, campione2)),+ nrow = 2, ncol = m, byrow = TRUE)> due_somma_rank <- apply(due_rank, 1, sum)> rank_atteso <- m * (m + 1)/2> wilcoxon <- due_somma_rank - rank_atteso> wilcoxon
[1] 5207 4793
La simulazione Introdoa la statistica, usiamo la simulazione. Generiamo veori.Nel primo, distribuzione, inseriremo le coppie di valori e calcoleremo usando lastatistica di Wilcoxon. Nel secondo, differenze, salviamo una seconda statistica: ladifferenza delle medie fra i due campioni. La prima distribuzione ci serve in questasezione, la seconda nella sezione dedicata al calcolo parametrico.
> distribuzione <- vector(mode = "numeric", length = k*2)> differenze <- vector(mode = "numeric", length = k)
A questo punto, usando un ciclo for, possiamo generare k= coppie di campioni,calcolare per ognuno le due statistie, e salvarla nei due veori.
R: la generazione delle coppie di campioni
> for (i in 1:length(distribuzione)/2) {+ due_campioni <- matrix(sample(popolazione, 2 * m, replace = FALSE),+ nrow = 2, ncol = m, byrow = TRUE)+ campione1 <- due_campioni[1, ]+ campione2 <- due_campioni[2, ]+ due_rank <- matrix(rank(c(campione1, campione2)),+ nrow = 2, ncol = m, byrow = TRUE)+ due_somma_rank <- apply(due_rank, 1, sum)+ rank_atteso <- m * (m + 1)/2+ wilcoxon <- due_somma_rank - rank_atteso+ distribuzione[i * 2 - 1] <- wilcoxon[1]+ distribuzione[i * 2] <- wilcoxon[2]+ differenze[i] <- mean(campione1) - mean(campione2)+ }

.. CALCOLO NON PARAMETRICO
R: la distribuzione U
> par(mfrow = c(1, 2))> hist(distribuzione)> qqnorm(distribuzione)> qqline(distribuzione)
Histogram of distribuzione
distribuzione
Fre
quen
cy
3500 5000 6500
010
0020
0030
00
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●●
●●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●●●●●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●●
●●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●●
●●
●
●●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●●
●●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●●
●
●●
●
●●
●●
●
●●●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●●
●
●
●
●
●●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●●●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●●
●
●●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●●
●
●●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●●●
●
●
●
●
●●
●●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●●
●●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●●
●
●●
●●
●
●
●●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●●
●●
●●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●●
●
●
●●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●●●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●●
●
●●
●
●●
●●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●●●●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●●
●●
●●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●●●
●
●
●
●
●●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●●
●
●
●
●●●
●
●●
●
●●●
●●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●●●
●
●
●●●
●●
●
●
●
●●●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●●
●●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●●
●
●●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●●
●
●
●●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●●
●
●●
●
●●
●
●●●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●●
●
●●
●
●
●
●
●●
●
●
●●
●
●●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●●●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●●
●
●
●●
●●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●●
●●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●●●
●
●
●
●
●
●
●
●●●
●
●
●●●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●●
●
●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●●
●
●●●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●●●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●●●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
−4 −2 0 2 4
3500
4000
4500
5000
5500
6000
6500
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
R: valori critici Possiamo calcolare i valori critici, ad esempio per α = . e .bidirezionale
> quantile(distribuzione,+ probs = c(0.005, 0.025, 0.975, 0.995))
0.5% 2.5% 97.5% 99.5%3943.00 4187.00 5785.05 6034.02

CAPITOLO . T TEST: CONFRONTO FRA MEDIE DI DUE CAMPIONI
Calcolare il p-value dalla distribuzione Ora, generiamo due nuovi campioni, calco-liamo la statistica U, e vediamo dove si colloca rispeo alla distribuzione.
> due_campioni <- matrix(+ sample(popolazione, 2 * m, replace = FALSE),+ nrow = 2, ncol = m, byrow = TRUE)> campione1 <- due_campioni[1, ]> campione2 <- due_campioni[2, ]> due_rank <- matrix(rank(c(campione1, campione2)),+ nrow = 2, ncol = m, byrow = TRUE)> due_somma_rank <- apply(due_rank, 1, sum)> rank_atteso <- m * (m + 1)/2> wilcoxon <- due_somma_rank - rank_atteso
Calcolare il p-value dalla distribuzione
> wilcoxon
[1] 4608 5392
> p_value_simulazione <-+ rank(c(wilcoxon, distribuzione))[1:2]/length(distribuzione)> p_value_simulazione
[1] 0.165925 0.830875
.. La distribuzione U Mann-Whitney-Wilcoxon
La distribuzione di errore e abbiamo oenuto grazie al confronto di coppiedi campioni, è nota come distribuzione U Mann-Whitney-Wilcoxon Whitley and Ball().
Rmee a disposizione il gruppo di funzioni per calcolare la densità, la probabilità, pergenerare dei numeri secondo la distribuzione. Inoltre, mee a disposizione la funzionewilcox.test per calcolare, automaticamente, la statistica ed il p-value.
R: le funzioni per la distribuzione U R mee a disposizione le consuete funzioni percalcolare densità, probabilità, generare numeri casuali e calcolare il test.
� dwilcox(x, m, n) calcola la densità di x
� pwilcox(q, m, n) calcola la probabilità
� rwilcox(nn, m, n) genera nn numeri casuali.
� wilcox.test(gruppoA,gruppoB) calcola il test corrispondente
m e n sono la numerosità del primo e del secondo campione (e, nel nostro esempio,sono uguali -- m)

.. APPROCCIO PARAMETRICO
R: calcolo del p-value con pwilcox Utilizzando pwilcox calcoliamo i due p-value.Il valore interessante è quello più basso. Se, come nell'esempio, l'ipotesi è a due vie,dobbiamo raddoppiare il p-value
> p_value_Wilcoxon <- pwilcox(wilcoxon, 100, 100)
[1] 0.1697679 0.8308490
> p_value_Wilcoxon * 2
[1] 0.3395358 1.6616981
> p_value_simulazione * 2
[1] 0.33185 1.66175
Come sempre, i risultati della distribuzione generata non sono uguali, ma simili, aquelli della distribuzione teorica.
R: uso di wilcox.test
Vediamo ora il calcolo effeuando la funzione di R wilcox.test
> wilcox.test(campione1, campione2, exact = TRUE)
Wilcoxon rank sum test
data: campione1 and campione2W = 4608, p-value = 0.3395alternative hypothesis:
true location shift is not equal to 0
La funzione calcola la statistica, W = 4608, e il p-value.
. Approccio parametrico
La differenza delle medie L'algoritmo utilizzato nelle sezioni precedenti costituiscel'approccio non parametrico al confronto fra due campioni.
Come abbiamo visto, il calcolo non parametrico non prende in considerazione né lamedia né la deviazione standard e nemmeno la distribuzione dei campioni.
Il vantaggio del calcolo non parametrico è e fa poissime assunzioni:
� le m+n osservazioni devono essere indipendenti;
� m e n devono avere una numerosità di almeno elementi.

CAPITOLO . T TEST: CONFRONTO FRA MEDIE DI DUE CAMPIONI
.. Assunzioni
Per applicare il test parametrico, al contrario, è necessario non solo e le osservazionisiano indipendenti (e la numerosità adeguata). È altresì necesario e:
� la distribuzione dei due campioni sia normale;
� la varianza dei due gruppi non sia diversa.
R permee il calcolo del t test ane in caso di varianze differenti (araverso l'approssi-mazione di Wel).
La differenza fra le medie Il test parametrico si basa sulla differenza fra le medie deidue campioni. esto spiega l'assunto di normalità dei campioni.
In pratica, il test calcola il valore assoluto della differenza fra le due medie, e laconfronta con la distribuzione t di Student.
Naturalmente, ane in questo caso possiamo calcolare il p-value ignorando la distri-buzione teorica, ma basandoci sulla distribuzione dell'errore di campionamento generatadal confronto delle nostre . coppie di campioni.
Nel ciclo for e usammo per generare la statistica U, popolammo ane un veore,differenze, con il codice differenze[i]<-mean(campione1)-mean(campione2).Possiamo ora usare quel veore di distribuzioni dell'errore.
.. R: p-value usando la distribuzione
Calcoliamo il p-value confrontando la distanza delle due medie con la distribuzionedell'errore.
> distanza <- abs(mean(campione1)-mean(campione2))> (p_value_differenze_simulazione <- 1 -+ rank(c(distanza, differenze))[1]/length(differenze))
[1] 0.2067
> p_value_differenze_simulazione * 2
[1] 0.4134
Distribuzione dell'errore
Usiamo la funzione density per visualizzare la distribuzione dell'errore, e qqnorm-qqline per testarne la normalità.
> par(mfrow = c(1, 2))> plot(density(differenze))> qqnorm(differenze)> qqline(differenze, col = "red")

.. APPROCCIO PARAMETRICO
−1.0 0.0 1.0
0.0
0.5
1.0
1.5
density.default(x = differenze)
N = 10000 Bandwidth = 0.04036
Den
sity
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●●
●
●●
●
●
●
●
●●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●●
●
●●●
●
●
●
●●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●●
●
●●●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●●●
●
●●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●●●●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●●
●
●●
●
●●
●●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●●
●●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●●
●
●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●●
●
●●●
●●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●●
●●
●
●
●
●
●●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●●
●
●
●
●
●
●
●●
●●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●●
●●
●
●●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●●●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●●
●
●
●
●●●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●●●
●
●
●
●●●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●●●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●●●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
−4 −2 0 2 4
−1.
0−
0.5
0.0
0.5
1.0
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Varianza dell'errore Possiamo osservare dal grafico qqnorm e la distribuzione ap-prossima la distribuzione normale.
In realtà, la varianza della distribuzione dell'errore è legata alla numerosità dei duecampioni. Più precisamente, la varianza stimata è pari a
S2x1−x2
=s21(m− 1) + s22(n− 1)
m+ n− 2(1
m+
1
n) (.)
Dunque, l'errore standard della differenza fra le medie può essere calcolato, con R,usando
> errore_standard <- sqrt((var(campione1)*(m-1)+var(campione2)*(m-1))/> + (m-1+m-1)*(1/m+1/m))
Calcolo di t Calcoliamo t, e calcoliamo il p-value (e raddoppiamo, se l'ipotesi èbidirezionale).
> errore_standard <-+ sqrt((var(campione1) * (m - 1) + var(campione2) *+ (m - 1))/(m - 1 + m - 1) * (1/m + 1/m))> t <- distanza/errore_standard> p_value_differenze_t <- (1 - pt(t, df = (m - 1 + m - 1)))> p_value_differenze_t

CAPITOLO . T TEST: CONFRONTO FRA MEDIE DI DUE CAMPIONI
[1] 0.1921828
> p_value_differenze_t * 2 # bidirezionale
[1] 0.3843657
.. Uso della funzione t.testInfine, utilizziamo la funzione t.test
> t.test(campione1, campione2)
Welch Two Sample t-test
data: campione1 and campione2t = -0.8718, df = 192.257, p-value = 0.3844alternative hypothesis: true difference in means is not equal to 095 percent confidence interval:-0.7671013 0.2968312sample estimates:mean of x mean of y20.04375 20.27888
Leggere l'output La funzione t.test(campione1, campione2) restituisce t =-0.8718, i gradi di libertà stimati df = 192.257, il p-value = 0.3844, e l'in-tervallo di confidenza della differenza fra le medie: -0.7671013 0.2968312. an-do i due termini dell'intervallo di confidenza hanno segni opposti, la differenza non èsignificativa.
.. ConclusioniDa fare

Capitolo
Correlazione e regressionelineare
Indice. Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. La rea di regressione . . . . . . . . . . . . . . . . . . . . . Analisi inferenziale . . . . . . . . . . . . . . . . . . . . . . . . .
.. Correlazione e causazione . . . . . . . . . . . . . . . . . . .. Modelli Lineari Generalizzati . . . . . . . . . . . . . . . .
. Approccio intuitivo . . . . . . . . . . . . . . . . . . . . . . . . . .. La simulazione . . . . . . . . . . . . . . . . . . . . . . . . .. Alcuni esempi . . . . . . . . . . . . . . . . . . . . . . . . .. Uso della distribuzione teorica . . . . . . . . . . . . . . . .
. Regressione lineare . . . . . . . . . . . . . . . . . . . . . . . . . .. Regressione lineare: il modello . . . . . . . . . . . . . . . .. Assunti della regressione lineare . . . . . . . . . . . . . . .. R: la funzione lm () . . . . . . . . . . . . . . . . . . . . . .. Varianza dei residui, R2 . . . . . . . . . . . . . . . . . . .
. Violazione degli assunti . . . . . . . . . . . . . . . . . . . . . . . Coefficiente di Spearman . . . . . . . . . . . . . . . . . . . . . .
.. arto esempio, sigmoide . . . . . . . . . . . . . . . . . . . Conclusioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. Introduzione
Confronto fra variabili quantitative Dopo aver visto il confronto fra due variabilicategoriali ed il confronto fra una variabile categoriale ed una variabile a intervalli (li-mitatamente al caso del confronto fra due soli gruppi), analizziamo ora il confronto fradue variabili quantitative.
Ane in questo caso, la statistica inferenziale si propone di valutare se esiste unarelazione fra le variabili, e se questa relazione è significativa.

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
Andamento congiunto Nei casi visti in precedenza, nei capitoli e , ci si iedeva sel'appartenenza di una osservazione ad una categoria od un'altra della variabile A influivasulla distribuzione della variabile B.
Sia nel caso del test del χ2 e del test t di Student, e (come vedremo) nell'analisidella varianza, ci si concentra sulla significatività delle differenze.
Nel caso della relazione fra due variabili numerie, invece, ci si iede se le duevariabili si muovono assieme: se al crescere di una cresce ane l'altra (correlazionepositiva), o se al crescere di una l'altra cala (correlazione negativa), e ci si iede sequesto andamento congiunto sia significativo o sia dovuto al caso.
Ipotesi nulla e ipotesi estrema Ane in questo caso, è opportuno partire dall'ipotesinulla, ovvero dall'ipotesi e non vi sia alcun legame fra le due variabili.
Ane in questo caso, è necessario identificare una statistica, ovvero una misuradell'aspeo rilevante.
Da un punto di vista didaico, però, può essere utile focalizzarci sulla situazioneestrema di una totale correlazione fra le due variabili.
Nell'esempioe segue, ci limiteremo ad analizzare la circostanza di una correlazionepositiva, ma il principio può essere generalizzato alle correlazioni negative.
Esempio: misurare le precipitazioni Immaginiamo e un osservatorio metereologi-co debba misurare le precipitazioni atmosferie (pioggia) nel corso dell'anno. Per farlo,viene raccolto in un bacino di un metro quadrato l'acqua piovana, e ad ogni pioggial'acqua raccolta viene misurata.
Immaginiamo e il responsabile della misurazione sia molto pignolo, e e decidadi misurare sia il volume dell'acqua in litri, e il suo peso in kilogrammi.
Figura .: Esempio di correlazione per-fea: l'esempio del rapporto fra litri ekg.
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
5 10 15 20
510
1520
Correlazione perfetta
litri
kg
La linea retta L'aspeo più saliente del grafico . è e le misure relative a peso e avolume si dispongono lungo una linea rea.

.. INTRODUZIONE
Il secondo aspeo è e, grazie alla linea, conoscendo il valore in litri, possiamodedurre il peso in kg, e viceversa.
●
●●
●
●●
●●
●
●
●
●
●
●●●●●
●
●
●
●●
●
●
●●
●●
●
●●
●
●
●●●●
●
●
●
●●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●●
●
●
●
45 50 55
4550
55
corr.= 1 p= 0
x1
y1
●
●
●
●●
●
●
● ●
●
●
● ●
●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●●
●
●
●●
●●
●
●
●
●
●
●●
●●
●●● ●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●●●
●
● ●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
44 48 52 56
4450
56
corr.= 0.847 p= 0
x1
y1 ●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
● ●
●
●
● ●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
● ●
●
●●●●
●●
●
●●
●
●●
●
●●
●
●
●●
●●
●●
44 48 52 56
4448
5256
corr.= 0.687 p= 0
x1
y1●
●●●
● ●●
●
●
●
●
●
●
●
●●
●
● ●●
●
●
●●●
●
●
●●●
●
●
●● ●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●●
●
●
●
●●●● ●
●●
●
●●
46 50 54 58
4550
55
corr.= 0.289 p= 0.004
x1
y1
●
●
●●
● ●
●
● ●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●●
● ●●
●
●●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●●●
●
●
●● ●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●●
45 50 55
4550
55
corr.= 0.349 p= 0
x1
y1 ●●●
●
●
●
●●
●
●
●
●●
●● ●●
●
●
●
●
●●●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
● ●●
● ●
●●
●
●●
●
●●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●●●
●●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
45 50 55
4448
5256
corr.= −0.001 p= 0.992
x1
y1
Figura .: Alcuni esempi di correlazione: dalla correlazione perfea alla correlazioneassente.
Diverse distribuzioni di esempio Più realistica la simulazione della figura .. Inquesto caso, la posizione dei punti sull'asse x è dato dalla somma di valori casuali,generati su una distribuzione uniforme. Nel primo grafico, in alto a sinistra, i valorisull'asse y sono dati dalla somma degli stessi valori, e dunque i punti si collocanoperfeamente sulla linea di regressione.
Nel secondo grafico, i valori y sono il risultato di dei valori casuali di x, e valoricasuali diversi. Negli altri grafici, la proporzione è di -, - e così via. Nell'ultimografico, tui e i valori di y sono indipendenti, e dunque non vi è alcuna correlazionefra le due variabili.
.. La retta di regressione
In questi grafici abbiamo implicitamente introdoo la rea di regressione, e verrà di-scussa nelle prossime slides. Per ora, ci basti saperee la rea di regressione ci permeedi fare una stima del valore di y conoscendo il valore di x.
Nel primo grafico, proprio come nell'esempio precedente, conoscere il valore di x cipermee di inferire perfeamente il valore di y, in quanto le osservazioni di y cadonoperfeamente sulla rea.
Già nel secondo grafico, però, questa previsione non è più perfea: conoscendo x,possiamo soltanto stimare il valore di y.

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
Mano a mano e il legame diventa meno importante, la pendenza della linea diregressione diminuisce, fino a quasi sovrapporsi alla linea della media di y nell'ultimografico, dove le due variabili sono indipendenti.
Ciò e questo andamento ci dice è e conoscere il valore di x contribuisce sempremeno alla nostra conoscenza di y.
Dai grafici della seconda figura possiamo notaree la linea di regressione si incrocia,in tui i casi, nella linea della media di x e nella linea della media di y nello stesso punto.
esto significa e il valore stimato di y quando x è pari a x è y.
Analisi grafica Come abbiamo visto nelle analisi univariate e nelle altre statistiebivariate, la visualizzazione dei dati e l'analisi visiva, qualitativa delle distribuzioni èparte integrante del processo descriivo e inferenziale.
Il grafico utilizzato nella visualizzazione di due variabili quantitative è il grafico didispersione, scaerplot. In R, si oiene usando la funzione plot (x,y).
Grafico di dispersione: cosa guardare
ali sono gli aspei più salienti e bisogna osservare in un grafico a dispersione?
� La forma generale della distribuzione.
� La direzione dell'associazione: è positiva o negativa?
� La forma della la relazione? È una linea rea oppure no? È una curva?
� La forza dell'associazione: i punti osservati sono vicini o lontani dalla linea diregressione?
� La presenza di outliers: vi sono osservazioni molto lontane dalla rea di regres-sione? È possibile e queste osservazioni insolite siano dovute ad errori?
� È ipotizzabile e l'andamento del grafico lasci intendere l'influenza di una varia-bile terza?
. Analisi inferenziale
Coefficiente di correlazione La correlazione è una relazione lineare fra due variabilia intervallo o a rapporti.
È importante soolineare e la correlazione non distingue fra variabile indipen-dente e dipendente, e traa le due variabili simmetricamente: la correlazione fra Y e Xequivale alla correlazione fra X e Y.
L'analisi inferenziale è finalizzata a calcolare se esiste una relazione fra le due varia-bili, e se la relazione è statisticamente significativa.

.. ANALISI INFERENZIALE
Correlazione: cautele Prima di applicare la statistica, è necessario tener conto dialcuni possibili problemi:
� La correlazione misura relazioni di tipo lineare. Se la relazione non è di tipolineare, la correlazione non è appropriata.
� Soprauo se l'insieme di osservazioni ha una bassa numerosità, è possibile edegli outliers condizionino fortemente il risultato.
� Se una terza variabile, ane categoriale, ha una influenza significativa su una oentrambe le variabili misurate, è possibile e, non tenendone conto, si calcolinodelle correlazioni non appropriate.
.. Correlazione e causazione
La correlazione non implica causazione. La correlazione, infai, può essere aribuibilea
� Causazione direa: A causa B.
� Causa comune: C causa sia A e B.
� Faore confounding: l'andamento della variabile dipendente può essere condizio-nato da un faore esternoe non ha nulla ae fare con la variabile indipendente.
� Semplice coincidenza.
Requisiti per inferire causazione Affiné si possa inferire causazione è necessarioe:
� L'associazione sia abbastanza forte.
� Vi sia la possibilità di manipolare la variabile indipendente, e e il valore dellavariabile dipendente cambi di conseguenza.
� Vi sia un iaro rapporto temporale: la causa deve precedere l'effeo.
� Le misure devono essere consistenti, e dunque replicabili.
� I risultati siano teoreticamente plausibili e coerenti con altre evidenze empirie.
� L'associazione sia specifica (e dunque non possa essere aribuita a cause comunio altri confounding).
.. Modelli Lineari Generalizzati
Sia l'analisi della varianza e la regressione lineare sono casi particolari della metodo-logia nota come Modelli Lineari Generalizzati.
La differenza più importante fra la regressione e l'ANOVA èe in un caso la variabileindipendente è a intervalli, nell'altro categoriale. Nell'ANOVA, dunque, non si fannoassuzioni sulla linearità della relazione.

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
. Approccio intuitivoPer misurare la correlazione lineare, abbiamo bisogno di una statistica e abbia alcunecaraeristie:
� sia pari a in assenza di correlazione
� sia positiva quando la correlazione è positiva, e negativa quando è negativa
� e abbia un valore assoluto massimo, e identifica la circostanza in cui la cor-relazione è perfea
� e sia standardizzata, ovvero e non dipenda dai valori assoluti delle variabili.
In termini formali:− 1 ≤ r ≤ 1 (.)
Linea di regressione e medie Come abbiamo osservato, la linea di regressione si in-crocia sempre con le due medie. Usando le linee e identificano le medie di x e di ypossiamo dividere il grafico di dispersione in quadranti. Se le osservazioni si distri-buiscono principalmente nel quadrante in alto a destra e in quello in basso a sinistra, lacorrelazione è positiva. Se sono più frequenti nei quadranti in alto a destra o in basso asinistra, la correlazione è negativa.
Per oenere una misura standardizzata del rapporto fra le due variabili, possiamodecidere di trasformare sia la variabile x e la y in punteggi zeta.
Trasformazione in punti z Con la trasformazione, oeniamo due variabili con mediapari a zero e deviazione standard pari ad uno. La rea di regressione, a questo punto,incrocia le due medie nella posizione , del grafico.
� Il quadrante in basso a sinistra raccoglie le osservazioni in cui sia x e y sononegative.
� Il quadrante in alto a destra raccoglie le osservazioni in cui sia x e y sonopositive.
� Il quadrante in basso a destra raccoglie le osservazioni in cui x è positiva e y ènegativa.
� Il quadrante in alto a sinistra raccoglie le osservazioni in cui y è positiva e x ènegativa.
A questo punto appare evidente e, moltiplicando x per y, oerrò valori positivi neidue quadranti alto sinistra e basso destra, e valori negativi nei quadranti basso destra,alto sinistra.
Cosa succede se sommo la moltiplicazione x * y di tue le osservazioni, e dividoper il numero di osservazioni (per la precisione, per n-)? Oerrò un valore e saràpositivo in caso di correlazione positiva, negativo in caso di correlazione negativa, esarà prossimo allo zero in caso di assenza di correlazione.
Inoltre, vedremo e il valore più alto e questa misura può raggiungere è pari ad, e di conseguenza il valore più basso è pari a -.

.. APPROCCIO INTUITIVO
Correlazione lineare: la formula
r =1
n− 1
n∑i=1
[(xi − x
σx)(yi − y
σy)] (.)
Ricordando e x e y sono le medie di X e Y e e σX e σY sono le deviazionistandard di X e Y, e ricordando e il calcolo del punteggio z è pari a
z =xi − x
σx(.)
possiamo riscrivere r come
r =1
n− 1
n∑i=1
(z(xi)z(xi)) (.)
Correlazione lineare: assunti
� Poié il calcolo della correlazione utilizza la trasformazione dei punteggi grezziin punti zeta, si assume e entrambe le variabili siano almeno a livello di scala diintervallo e abbiano una distribuzione normale.
� Le osservazioni su entrambe le variabili devono essere stocasticamente indipen-denti (ovvero, il valore di di una osservazione non deve condizionare il valore diun'altra osservazione)
� Infine, il rapporto fra le due variabili sia di tipo lineare. Vedremo nelle prossimesezioni quali alternative esistono in caso di non linearità del rapporto.
Distribuzione dell'errore
Come consuetudine, utilizziamo la consueta sequenza logica
� identificazione di una misura della relazione
� identificazione di una popolazione virtuale
� estrazione casuale di k campioni
� calcolo del veore delle k misure
� osservazione della distribuzione delle misure
� calcolo del p-value araverso il confronto con il veore delle misure
� identificazione di una distribuzione teorica e, previo opportuna trasformaizone,mappa quella osservata
� calcolo del p-value utilizzando la probabilità della distribuzione teorica identifi-cata
� utilizzo della funzione di R

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
.. La simulazione
� La misura della relazione è il coefficiente r identificato sopra.
� Araverso la funzione rnorm () possiamo estrarre n campioni di osservazionicasuali da una popolazione con specifica media e deviazione standard. Poié sia-mo interessati a misurare la relazione fra due variabili, per ogni misura estraiamodue campioni
� Utilizziamo la funzione scale() per trasformare le osservazioni in punti z.
� Calcoliamo la statistica r, e la salviamo nel veore delle misure.
> m <- 100> k <- 10000> relazioni <- vector(mode = "numeric", length = k)> for (i in 1:length(relazioni)) {+ x1 <- rnorm(m, 20, 2)+ x2 <- rnorm(m, 50, 6)+ x1 <- scale(x1)+ x2 <- scale(x2)+ erre <- sum(x1 * x2)/(length(x1) - 1)+ relazioni[i] <- erre+ }
Grafico della distribuzione dell'errore Visualizziamo la distribuzione dell'errore di rnella figura ..
> hist(relazioni)
Figura .: La distribuzione dell'errore dir
Histogram of relazioni
relazioni
Fre
quen
cy
−0.4 −0.2 0.0 0.2 0.4
050
010
0015
00

.. APPROCCIO INTUITIVO
Rapporto fra distribuzione dell'errore e t
Poié il valore possibilie di r varia nel range −1 ≤ r ≤ 1, ane la distribuzionedell'errore varia nello stesso range, e si concentra aorno ai valori -., ..
La forma della distribuzione approssima la t di Student, previa opportuna trasfor-mazione. Per arrivare alla distribuzione t va applicata la trasformazione
t =r√1−r2
n−2
(.)
P-value calcolato sulla distribuzione t Per calcolare il p-value basandoci sulla di-stribuzione t, dovremmo dunque trasformare r in t, e poi calcolare la probabilità dit.
.. Alcuni esempi
Facciamo ora alcuni esempi, generando differenti casi di variabili bivariate.
Primo esempio: variabili indipendenti
In questo caso, generiamo due variabili casuali indipendenti. Ci aspeiamo un r prossi-mo allo .
> x1 <- rnorm(100, 20, 2)> y1 <- rnorm(100, 50, 3)> sx1 <- scale(x1)> sy1 <- scale(y1)> erre1 <- sum(sx1 * sy1)/(length(sx1) - 1)> erre1
[1] -0.0188566
La statistica r, dunque, è pari a -..
> colori <- c(2, 2, 1)> colore <- colori[sign(sx1 * sy1) + 2]> plot(sx1, sy1, col = colore)> abline(a = 0, b = erre1)> abline(v = 0)> abline(h = 0)
Calcolo p-value su simulazione Calcoliamo il p-value usando la distribuzione osser-vata. Poié la nostra ipotesi è a due code, moltipliiamo p per . Poié le due variabilisono indipendenti, la nostra previsione è e p sia superiore a ..
> p_value_simulazione1 <- rank(c(-abs(erre1), relazioni))[1]/(length(relazioni) ++ 1)> p_value_simulazione1 * 2

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
Figura .: Variabili indipendenti
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
● ●
●
●
●●
●
●
●
●
●
●
●
● ●
● ●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
−2 −1 0 1 2
−2
−1
01
2
sx1
sy1
[1] 0.8535146
Il p-value è dunque pari a ..
Secondo esempio: variabili correlate
In questo secondo esempio, la variabile y è creata in modo da correlare con x. Ciaspeiamo un r relativamente alto, e un p basso.
> y2 <- x1 + rnorm(100, 0, 2)> sy2 <- scale(y2)> erre2 <- sum(sx1 * sy2)/(length(sx1) - 1)> erre2
[1] 0.6568569
La statistica r è pari a ..Disegnamo il grafico.
> colori <- c(2, 2, 1)> colore <- colori[sign(sx1 * sy2) + 2]> plot(sx1, sy2, col = colore)> abline(a = 0, b = erre2)> abline(v = 0)> abline(h = 0)
> p_value_simulazione2 <- rank(c(-abs(erre2), relazioni))[1]/(length(relazioni) ++ 1)> p_value_simulazione2 * 2
[1] 0.00019998
Come previsto, il p-value -- calcolato sulla distribuzione osservata dalla simulazione-- è basso: ..

.. APPROCCIO INTUITIVO
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
−2 −1 0 1 2
−2
−1
01
2
sx1
sy2
Figura .: Grafico relativo al secondoesempio
.. Uso della distribuzione teorica
Dopo aver visto il calcolo del p-value usando la distribuzione della simulazione, utiliz-ziamo la probabilità calcolata a partire dalla distribuzione teorica, t.
In primo luogo confrontiamo la distribuzione generata dalla simulazione con la di-stribuzione teorica, sovrapponendo le due curve.
> relazioni_t <- relazioni/(sqrt((1 - relazioni^2)/(100 - 2)))> x <- seq.int(-4, 4, by = 0.05)> y <- dt(x, 100 - 2)> plot(density(relazioni_t), col = 4, main = "Sovrapposizione delle distribuzioni")> lines(x, y, type = "l", col = 3)
Calcoliamo il p-value usando la distribuzione t
Constatato empiricamente e le due distribuzioni sono estremamente simili, decidiamodi calcolare il punteggio t, usando la funzione .. Poi, calcoliamo il p-value usando lafunzione pt
Primo esempio Mostriamo il calcolo, ed il risultato, del primo esempio.
> t1 <- abs(erre1)/(sqrt((1 - erre1^2)/(100 - 2)))> t1
[1] 0.1867040
> p_value_t1 <- (1 - pt(t1, df = (100 - 2)))> p_value_t1 * 2
[1] 0.8522787
Dunque, t è pari a ., p= ..

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
Figura .: La distri-buzione osservata dal-la simulazione, sovrap-posta alla distribuzioneteorica
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
Sovrapposizione delle distribuzioni
N = 10000 Bandwidth = 0.1451
Den
sity
Secondo esempio Ripetiamo il calcolo, con il secondo esempio.
> t2 <- abs(erre2)/(sqrt((1 - erre2^2)/(100 - 2)))> p_value_t2 <- (1 - pt(t2, df = (100 - 2)))> p_value_t2 * 2
[1] 1.163514e-13
t è pari a ., p= .e-.
R: uso di cor.test
E come di consueto, terminiamo mostrando l'uso della funzione cor.test (x,y).Iniziamo con il primo esempio.
> correlazione1 <- cor.test(x1, y1)> correlazione1
Pearson's product-moment correlation
data: x1 and y1t = -0.1867, df = 98, p-value = 0.8523alternative hypothesis: true correlation is not equal to 095 percent confidence interval:-0.2144803 0.1782216sample estimates:

.. REGRESSIONE LINEARE
cor-0.0188566
Leggere i risultati La funzione ci ricorda e stiamo applicando la Pearson's product-moment correlation, ci restituisce t = -0.186, df = 98, p-value = 0.852. Infine,restituisce il calcolo di r: cor -0.0188.
Naturalmente, visti i risultati, non possiamo rifiutare l'ipotesi nulla.
Secondo esempio
> correlazione2 <- cor.test(x1, y2)> correlazione2
Pearson's product-moment correlation
data: x1 and y2t = 8.6239, df = 98, p-value = 1.164e-13alternative hypothesis: true correlation is not equal to 095 percent confidence interval:0.5286437 0.7557670sample estimates:
cor0.6568569
In questo caso, l'ipotesi nulla va rifiutata, in quanto p− value < 0.001.
. Regressione lineare
Precipitazioni: dal volume al peso Torniamo all'esempio, banale, delle precipitazioni.Grazie alla correlazione perfea fra volume e peso, data una osservazione, conoscendoil volume, possiamo calcolare il peso.
Se guardiamo al grafico, possiamo notare e il peso stimato incrocia il volumeproprio lungo la linea di regressione.
La linea di regressione, dunque, stima il valore di y a partire da x (e viceversa, ilvalore di x conoscendo y).
Esempio A: noleggio automobili Immaginiamo e una agenzia di noleggio autoapplii, per un modello, la seguente tariffa:
� importo fisso di euro al giorno
� . euro a km percorso
Conoscendo questi due valori, possiamo prevedere esaamente quanto spenderemo. Adesempio, se ho percorso km, spenderò + .* = . euro.

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
Esempio B: noleggio automobili Immaginiamoe un'altra agenzia applii, invece,il fisso di euro più il costo della benzina consumata. Immaginiamo e l'auto inquestione consumi, in media, . euro a km.
In questo caso, quando spenderemo, dopo aver fao km? Il calcolo è lo stesso: + .* = .. In questo caso, però, questo valore è solo una stima di quello e ciaspeiamo di spendere, in quanto non possiamo essere sicuri e la benzina consumatasia esaamente pari a . euro.
I valori di . euro a km, infai, sono una statistica, calcolata in seguito ad una seriedi osservazioni, dove si sono misurati i km effeuati e la benzina consumata.
Il numero di km fai è il miglior prediore della benzina consumata, ma non èl'unico. Il tipo di percorso e il tipo di guida, fra gli altri, influenzano il consumo.
ando pagheremo per il noleggio della seconda agenzia, noi possiamo aspearciun conto di circa euro e , ma sappiamo e in quella stima ci sarà un errore, legatoa quei faori e incidono sul consumo ma e non sono annoverati nel calcolo.
.. Regressione lineare: il modello
Generalizzando dall'esempio precedente, nel modello di regressione lineare bivariato(X,Y), la variabile Y può essere rappresentata tramite la relazione lineare
Y = β0 + β1X + ε (.)
ed il valore
yi = β0 + β1xi + εi(i = 1...n) (.)
Infine,
yi = β0 + β1xi(i = 1...n) (.)
dove yi è il valore stimato di y.Spesso si usa la forma α+ βxi.
Le componenti
� β0 rappresenta l'intercea, ovvero il valore di y quando x = .
� β1 (o, nella regressione bivariata, semplicemente β) rappresenta la pendenza dellalinea, ed è pari alla differenza fra y = f(x) e y = f(x + 1). Nell'esempio,rappresenta il costo supplementare per ogni km percorso.
� ε rappresenta la variabile di errore, ovvero quella varianza in y e non può esserespiegata da x.
Per massimizzare la prediività della regressione è dunque necessario scegliere due pa-rametri β0 e β1 capaci di minimizzare l'errore e, possibilmente, di escludere dei bias(errori sistematici).

.. REGRESSIONE LINEARE
Somma dei quadrati degli errori Nella regressione lineare semplice, la misura dell'er-rore ε si basa sulla somma dei quadrati degli errori (in inglese sum of squared residuals,SSR):
SSR =n∑
i=1
e2i =n∑
i=1
(yi − yi)2 =
n∑i=1
((β0 + β1xi)− yi)2 (.)
dove yi è il valore stimato di y.Si traa dunque di identificare i parametri β0 e β1 capaci di minimizzare SSR.
Stime di β0 e β1 Le due stime e minimizzano la somma dei quadrati degli errori(SSR) sono
β1 =
∑ni=1(xi − x)(yi − y)∑n
i=1(xi − x)2(.)
β0 = y − β1x (.)
Proporzione di varianza spiegata e residua
La varianza di Y può essere divisa fra la varianza spiegata da β0 + β1X e la varianzaresidua, o di errore. La proporzione di varianza spiegata è pari a R2 = r2.
R2 = 1− SSR/(n− 1)
var(Y )= 1−
∑ni=1 e
2i∑n
i=1(yi − y)2i(.)
0 ≤ R2 ≤ 1. R2 è pari al quadrato di r.Va notato e quanto SSR è R2 è , e quando SSR = var(Y ) R2 = 0.
.. Assunti della regressione lineare
� La relazione fra le variabili dev'essere lineare
� L'errore è una variabile casuale con media zero e distribuzione normale
� Gli errori non sono fra loro correlati
� La varianza dell'errore è costante
Distribuzione di yi
Tenuto conto eyi = β0 + β1xi + εi(i = 1...n) (.)
se εi ha distribuzione normale, media , varianza σ2, la distribuzione di yi sarà
yi ∼ N(β0 + β1xi, σ2)(∀i = 1...n) (.)
dove N() è la distribuzione normale.

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
.. R: la funzione lm ()In R, la regressione lineare si calcola utilizzando la funzione lm(). La sintassi usata èlm(y ∼ x) dove y è la variabile dipendente e x la variabile indipendente.
Per disegnare la rea di regressione, si passa il risultato di lm() alla funzione abline,e disegna una linea con parametri a e b.
> modello1 <- lm(y1 ~ x1)> summary(modello1)
Call:lm(formula = y1 ~ x1)
Residuals:Min 1Q Median 3Q Max
-7.48470 -2.03610 0.09732 1.71495 7.56805
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 50.93513 3.13521 16.246 <2e-16 ***x1 -0.02884 0.15447 -0.187 0.852---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.95 on 98 degrees of freedomMultiple R-squared: 0.0003556, Adjusted R-squared: -0.009845F-statistic: 0.03486 on 1 and 98 DF, p-value: 0.8523
summary(lm()) ci restituisce molte informazioni. Intercept, ad esempio, ci di-ce se l'intercea è significativamente diversa da (informazione generalmente pocointeressante).
Molto più importante la seconda linea, e calcola t e il p-value di β1. R-squared èR2. Il p-value è calcolato ane araverso la statistica F (e non abbiamo affrontato).Il risultato, nel caso di correlazione bivariata, è lo stesso: p-value: 0.852.
Il grafico e la retta di regressione Abbiamo già introdoo la rea di regressione,abline, e utilizza proprio il risultato del modello lineare lm().
> plot(x1, y1)> abline(modello1)
.. Varianza dei residui, R2
Nel paragrafo .. abbiamo introdoo il conceo di rapporto fra varianza spiegata evarianza residua. la funzione lm() restituisce, fra le altre cose, i residui: $residuals.Sappiamo e la varianza totale è pari alla varianza spiegata più la varianza residua.

.. REGRESSIONE LINEARE
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
● ●
●
●
●●
●
●
●
●
●
●
●
● ●
● ●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
16 18 20 22 24
4550
55
x1
y1
Figura .
Sappiamo dunque la varianza spiegata è pari a R2 = 1 − var(residui)var(Y ) . Nelle prossime
righe di R calcoliamo R2, e lo confrontiamo con il r2, per mostrare e sono uguali.
> residui1 <- modello1$residuals> R2_1 <- 1 - var(residui1)/var(y1)> R2_1
[1] 0.0003555714
> erre1^2
[1] 0.0003555714
Come vediamo,R2 è pari a ., e r2 è pari a ..
Grafico dei residui
Il grafico dei residui ci permee di visualizzare la distribuzione dell'errore. È importanteper verificare gli assunti del modello.
> plot(modello1$fitted.values, modello1$residuals)> abline(lm(modello1$residuals ~ modello1$fitted.values))
Il secondo esempio Usiamo lm() sulle variabili del secondo esempio.
> modello2 <- lm(y2 ~ x1)> summary(modello2)

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
●
●
●●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
● ●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
50.20 50.25 50.30 50.35 50.40 50.45
−5
05
modello1$fitted.values
mod
ello
1$re
sidu
als
Figura .: Il grafico dei residui
Call:lm(formula = y2 ~ x1)
Residuals:Min 1Q Median 3Q Max
-4.52502 -1.14867 -0.01355 1.20021 3.74245
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.91190 1.89024 2.070 0.0411 *x1 0.80317 0.09313 8.624 1.16e-13 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.779 on 98 degrees of freedomMultiple R-squared: 0.4315, Adjusted R-squared: 0.4257F-statistic: 74.37 on 1 and 98 DF, p-value: 1.163e-13
In questo caso, il modello è significativo, in quanto il p-value di x è < 0.001.Visualizziamo il grafico.
> plot(x1, y2)> abline(modello2)
Usiamo i residui, calcoliamo R2.
Residui, R2

.. VIOLAZIONE DEGLI ASSUNTI
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
16 18 20 22 24
1618
2022
24
x1
y2
Figura .
> residui2 <- modello2$residuals> R2_2 <- 1 - var(residui2)/var(y2)> R2_2
[1] 0.431461
> erre2^2
[1] 0.431461
Visualizziamo il grafico dei residui su x.
> plot(modello2$fitted.values, modello2$residuals)> abline(lm(modello2$residuals ~ modello2$fitted.values))> lines(smooth.spline(modello2$fitted.values, modello2$residuals),+ col = "red", lwd = 2)
In questo caso, alla linea di regressione abbiamo aggiunto ane unasmooth.spline,ovvero una curva e segue l'andamento della relazione fra punteggi stimati e residui.esta curva ci può aiutare a capire se l'assunto di linearità è violato.
. Violazione degli assuntiGli assunti della regressione lineare Ricordiamo gli assunti della regressione lineare:
� La relazione fra le variabili dev'essere lineare
� L'errore è una variabile casuale con media zero e distribuzione normale
� Gli errori non sono fra loro correlati

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
18 20 22 24
−4
−2
02
4
modello2$fitted.values
mod
ello
2$re
sidu
als
Figura .
� La varianza dell'errore è costante (omoskedasticità)
ali sono le conseguenze della violazione degli assunti?La violazione di linearità è il caso più importante, di cui discuteremo estesamente
nelle prossime slide.
Correlazione fra gli errori La correlazione fra gli errori è sintomo di non indipen-denza fra le misure.
La non indipendenza fra le misure è un problema di cui va tenuto conto nelle misureripetute.
Nel caso di misure su di un campione estrao casualmente, la non indipendenzadelle misure e dell'errore è meno probabile.
La violazione di questo assunto può essere diagnosticata araverso un test di auto-correlazione dei residui
Omoskedasticità: varianza dell'errore costante Se la varianza dell'errore non è co-stante, l'intervallo di confidenza della distribuzione di Y non sarà correamente predii-vo, in quanto sovrastimato nella parte del grafico in cui la varianza dell'errore è minore,e soostimato nelle parti dove è maggiore.
La violazione dell'omoskedasticità può essere diagnosticata ploando i residui suivalori aesi: se la dispersione degli errori non è omogenea, possiamo sospeare unaviolazione della costanza della varianza dell'errore.test di omoskedasticità
Normalità dell'errore La violazione di questo assunto comporta la compromissionedella stima sia dei coefficienti β1 e β0 e dei valori di confidenza della distribuzione diY su X.
Per verificare graficamente la normalità della distribuzione dell'errore, si può utiliz-zare il grafico qqnorm e qqline.

.. VIOLAZIONE DEGLI ASSUNTI
Per verificarla inferenzialmente, si possono usare il test di Kolmogorov-Smirnov,ks.test, o il test di normalità Shapiro-Wilk: shapiro.test
Violazione della linearità È uno degli aspei più delicati, in quanto può indurre adinferenze scorree.
La non linearità può essere diagnosticata araverso la visualizzazione del grafico didispersione delle due variabili, il grafico di dispersione dei residui sui valori aesi, o sullavariabile X.
Da un punto di vista inferenziale, è possibile applicare la statistica Harvey-Collier:harvtest (va caricata la libreria lmtest: library(lmtest::harvtest).
In alcune circostanze, è possibile applicare una trasformazione non lineare ad una oentrambe le variabili, per rendere lineare la relazione.
Secondo esempio: testiamo gli assunti
Focalizziamoci sul secondo esempio, relativo a due variabili correlate, e testiamo gliassunti di normalità e di linearità.
Verifico la normalità della distribuzione dell'errore Uso il test di Shapiro-Wilk pertestare la normalità della distribuzione dell'errore.
> st2 <- shapiro.test(modello2$residuals)> st2
Shapiro-Wilk normality test
data: modello2$residualsW = 0.9919, p-value = 0.8123
Poié p = 0.812327573851688, non rifiuto l'ipotesi nulla di normalità del modello.L'assunto, dunque, non è violato.
Valuto la linearità del modello Utilizziamo ora il test Harvey-Collier per testare lalinearità del modello. Aenzione: per usare la funzione harvtest è necessario, prima,importare la libreria lmtest, con il comando library(lmtest).
> library(lmtest)> ht2 <- harvtest(y2 ~ x1, order.by = ~x1)> ht2
Harvey-Collier test
data: y2 ~ x1HC = 0.4536, df = 97, p-value = 0.6511
Poié p = 0.651115675604489, non rifiuto l'ipotesi nulla di linearità del modello.L'assunto, dunque, non è violato.

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
Terzo esempio, non lineare
Infine, l'ultimo esempio. Come vediamo dal codice, la relazione fra y e x, al neodella varianza non spiegata, è data da x32. Appliiamo il modello lineare, e leggiamoi risultati.
> x3 <- runif(100, -2, 6)> y3 <- x3^2 + rnorm(100, 0, 1)> x3 <- x3 + 10> modello3 <- lm(y3 ~ x3)> summary(modello3)
Call:lm(formula = y3 ~ x3)
Residuals:Min 1Q Median 3Q Max
-8.132 -4.128 -1.173 4.207 11.905
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) -36.7907 2.6504 -13.88 <2e-16 ***x3 3.8919 0.2161 18.01 <2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 5.201 on 98 degrees of freedomMultiple R-squared: 0.768, Adjusted R-squared: 0.7656F-statistic: 324.4 on 1 and 98 DF, p-value: < 2.2e-16
Il grafico Analizziamo, ora, il grafico.
> par(mfrow = c(1, 2))> plot(x3, y3, main = "grafico di dispersione")> abline(modello3)> plot(modello3$fitted.values, modello3$residuals, main = "punteggi attesi vs residui",+ xlab = "attesi", ylab = "residui")> abline(lm(modello3$residuals ~ modello3$fitted.values))> lines(smooth.spline(modello3$fitted.values, modello3$residuals),+ col = "red", lwd = 2)
Risulta evidente, dal grafico a sinistra, e la relazione fra x e y non è lineare. Lanon linearità è ancor più evidente nel grafico dei residui, a destra.
Usiamo il test Harvey-Collier per valutare la linearità. --------------------------
> ht3 <- harvtest(y3 ~ x3, order.by = ~x3)> ht3

.. COEFFICIENTE DI SPEARMAN
●
●
●
●
●
●
●
●
●●
●●
●●
●●
●●
●
●
●●
●
●
●●
●
●
●●
●●●●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●● ●
●
●
●
●
● ●
●
●
●
●
●
●
●
●●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●●
8 10 12 14 16
010
30
grafico di dispersione
x3
y3
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●● ●
●
●●●
●
●●
●
●
●
● ●
●●
●
●
●
●
●●
●●●
●
●
●
●
●●
●●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●● ●●
●
●
−5 5 15 25
−5
5
punteggi attesi vs residui
attesire
sidu
i
Figura .: x, y: a sinistra il grafico di dispersione di y su x, a destra i residui suipunteggi esi.
Harvey-Collier test
data: y3 ~ x3HC = 11.0666, df = 97, p-value < 2.2e-16
p = 6.8004985975279e − 19 < 0.05, e dunque rifiuto l'ipotesi nulla di lineari-tà del modello. L'assunto di linearità del modello è violato, come previsto dall'analisiqualitativa del grafico.
I data-set di Anscombe
In leeratura, sono noti i insiemi di dati pubblicati da Anscombe (). I quaro insie-me di dati sono particolari: le quaro y hanno la stessa media (.), deviazione standard(.), correlazione (.) e linea di regressione. Com'è possibile notare dal grafico,però, i quaro insiemi sono qualitativamente molto diversi. L'esempio, è finalizzato aricordarci e calcolare il modello lineare non basta, e e una aenta analisi dei graficidi dispersione è indispensabile, per evitare di trarre conclusioni inferenziali indebite.
. Coefficiente di Spearman
Dipendenza monotona Nelle circostanze in cui la relazione fra le due variabili nonsia lineare, ma tenda ad essere comunque monotona, è possibile utilizzare il modellonon-parametrico della correlazione: ρ di Spearman.
In questo modello, il calcolo della relazione si effeua non sui valori delle due va-riabili, ma sulla loro posizione ordinale.
esta statistica, pertanto, può essere applicata ane nella circostanza in cui una oentrambe le variabili siano di tipo ordinale.
Assunti del modello di Spearman Gli assunti sono i seguenti:

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
●
●●
●●
●
●
●
●
●
●
5 10 15
46
810
12
anscombe$x1
ansc
ombe
$y1
●
●●●
●
●
●
●
●
●
●
5 10 15
46
810
12
anscombe$x2
ansc
ombe
$y2
●
●
●
●
●
●
●
●
●
●
●
5 10 15
46
810
12
anscombe$x3
ansc
ombe
$y3
●
●
●
●●
●
●
●
●
●
●
5 10 15
46
810
12
anscombe$x4
ansc
ombe
$y4
Figura .: il dataset di Anscombe
� le due variabili devono essere almeno ordinali, non necessariamente ad intervalli;
� su entrambe le variabili, le diverse osservazioni devono essere fra loro indipen-denti;
� si assume e vi sia, fra le variabili, una relazione di tipo monotono;
.. arto esempio, sigmoide
Introduciamo un quarto esempio, dove la curva fra x e y è una sigmoide.
> x4 <- rnorm(200, 0, 4)> y4 <- (1/(1 + exp(-x4))) * 10 + rnorm(200, 0, 0.3)> x4 <- x4 + 8 + rnorm(200, 0, 0.3)
Il grafico Prima di ogni calcolo, mostriamo il grafico.
> par(mfrow = c(1, 1))> plot(x4, y4)> abline(lm(y4 ~ x4))> lines(smooth.spline(x4, y4), col = "red", lwd = 2)
.. COEFFICIENTE DI SPEARMAN
●
●●
●
●
●
● ●
●
● ●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●● ●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
● ●
●
● ●
●●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
0 5 10 15
02
46
810
x4
y4
Figura .: Relazione sigmoide

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
Dal grafico appare iaro e una relazione fra x e y esiste, ma e la relazionenon è lineare. Il modello lineare riesce comunque a cogliere la relazione, ma il modelloprediivo risulta sostanzialmente scorreo.
Calcolo di r Calcoliamo, comunque, r, usando cor.test. Negli esempi precedenti,l'argomento method='pearson' era stato omesso, in quanto costituisce il default delmetodo. Adesso, al contrario, lo rendiamo esplicito.
> cor.test(x4, y4, method = "pearson")
Pearson's product-moment correlation
data: x4 and y4t = 35.4166, df = 198, p-value < 2.2e-16alternative hypothesis: true correlation is not equal to 095 percent confidence interval:0.9076226 0.9460919sample estimates:
cor0.9293373
Coefficiente di Spearman Calcoliamo, ora, a mano, il coefficiente ρ di Spearman. Co-me abbiamo deo, la statistica non parametrica utilizza, al posto dei valori numerici dix e y, le loro posizioni ordinali. Il primo passaggio, dunque, è quello di trasformare ipunteggi nei rispeivi ranking (e, nel nostro algoritmo, di scalarli). Poi, utilizziamo laconsueta formula per calcolare il coefficiente.
> rankx4 <- scale(rank(x4))> ranky4 <- scale(rank(y4))> spearman4 <- sum(rankx4 * ranky4)/(length(rankx4) - 1)> spearman4
[1] 0.9756004
> plot(rankx4, ranky4)
Per capire meglio il meccanismo, disegnamo il grafico di dispersione dei rankingdelle due variabili. Come possiamo vedere, la trasformazione rende lineare la relazionemonotona.
Coefficiente di Spearman, cor.test
Infine, come di consueto, utilizziamo la funzione di R: cor.test(x4, y4, method= spearman). Se si vuole usare la ρ di Spearman, è necessario specificare method =spearman.
> spearman4 <- cor.test(x4, y4, method = "spearman")> spearman4

.. COEFFICIENTE DI SPEARMAN
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
−1.5 −1.0 −0.5 0.0 0.5 1.0 1.5
−1.
5−
1.0
−0.
50.
00.
51.
01.
5
rankx4
rank
y4
Figura .: Grafico di disperisone dei punteggi trasformati in ranking

CAPITOLO . CORRELAZIONE E REGRESSIONE LINEARE
Spearman's rank correlation rho
data: x4 and y4S = 32532, p-value < 2.2e-16alternative hypothesis: true rho is not equal to 0sample estimates:
rho0.9756004
Leggere i risultati La funzione calcola la statistica S= ., rho=.,p= .
. Conclusioni

Capitolo
Analisi della Varianza
Indice. Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. Confronto a coppie . . . . . . . . . . . . . . . . . . . . . . . Varianze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.. Varianza spiegata e previsioni . . . . . . . . . . . . . . . . .. Un esempio: gli affii in una cià . . . . . . . . . . . . . .
. Inferenza e previsioni . . . . . . . . . . . . . . . . . . . . . . . .. L'analisi della Varianza . . . . . . . . . . . . . . . . . . .
. Distribuzione dell'errore, inferenza . . . . . . . . . . . . . . . . .. La distribuzione Fisher-Snedecor . . . . . . . . . . . . . . .. R: uso di aov . . . . . . . . . . . . . . . . . . . . . . . . .
. Anova a due vie . . . . . . . . . . . . . . . . . . . . . . . . . . .. Due variabili indipendenti . . . . . . . . . . . . . . . . . . .. Un esempio: antidepressivi e aività aerobica . . . . . . . .. Il calcolo . . . . . . . . . . . . . . . . . . . . . . . . . . . .. Modello lineare . . . . . . . . . . . . . . . . . . . . . . . .. L'esempio dei traamenti per la depressione . . . . . . . .
. Confronti multipli . . . . . . . . . . . . . . . . . . . . . . . . . .. La correzione di Bonferroni . . . . . . . . . . . . . . . . . .. Il test di Tukey . . . . . . . . . . . . . . . . . . . . . . . . .. Analisi della Varianza: assunti . . . . . . . . . . . . . . . .
. Test non parametrico . . . . . . . . . . . . . . . . . . . . . . . . .. Il test di Kruskal-Wallis . . . . . . . . . . . . . . . . . . .
. Conclusioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. Introduzione
Confronto fra variabili categoriali e a intervalli Abbiamo visto, nel capitolo , co-me il t-test ci permea di confrontare le medie di due gruppi, e di valutare se la lorodifferenza è significativa.

CAPITOLO . ANALISI DELLA VARIANZA
Il confronto su coppie di elementi è applicabile se abbiamo una variabile indipen-dente di tipo categoriale con due soli livelli. Vi sono circostanze, però, in cui il confrontodeve avvenire fra più di due gruppi. Il caso più semplice è quando la variabile indi-pendente ha tre o più livelli. Una circostanza più complessa emerge quando le variabiliindipendenti sono più di due.
In quale modo possiamo affrontare una simile eventualità?
.. Confronto a coppie
Una possibile risposta è quella di confrontare ogni possibile combinazione di coppie digruppi.
Nell'esempio semplice di una variabile indipendente a tre livelli, confrontare il grup-po con il gruppo , il gruppo con il , il con il .
Sebbene questi confronti a coppie siano non solo possibili, ma realmente utilizzatinei confronti post-hoc, l'utilizzo esclusivo di questa metodologia incorre in due limiti.
Problemi del confronto a coppie
Il primo è e, moltiplicando il numero dei confronti, si accresce la probabilità di incor-rere in un errore di tipo I.
Immaginiamo, ad esempio, di acceare un valore α pari a .. esto significaacceare la possibilità e, il % delle volte, si rifiuti indebitamente l'ipotesi nulla.
Ma se, invece di un solo confronto, ne facciamo due, qual'è la probabilità e si rifiutiindebitamente almeno una volta l'ipotesi nulla?
Ricordiamo e, se l'ipotesi e si sta valutando è se la variabile indipendente in-fluisce su quella dipendente, basta rilevare una differenza significativa fra i gruppi perinferire una influenza.
Ma se i confronti sono numerosi, la probabilità di incorrere in un errore del primotipo aumenta. Nell'esempio con tre gruppi, poié i confronti sono tre, con un α pari a. la probabilità di rifiutare erroneamente l'ipotesi nulla diventa pari a ..
Più variabili indipendenti Il secondo inconveniente emerge quando le variabili indi-pendenti sono più di una. In questo caso, dal confronto a coppie è difficile far emergerequali variabili indipendenti hanno un'influenza significativa sulla variabile dipendentee quali no, così come diventa difficile far emergere l'eventuale interazione fra le variabiliindipendenti.
esti due inconvenienti ci costringono ad identificare una metodologia capace digeneralizzare ai confronti con più variabili indipendenti e capace di mantenere soocontrollo l'errore di tipo I.
. Varianze
Nel capitolo sulla regressione lineare sono stati introdoi i concei di varianza totale,spiegata e residua.La varianza di una variabile ci offre una misura della distribuzione di quella variabile.

.. VARIANZE
Conoscendo la media e la varianza (o la deviazione standard) di una variabile, ed assu-mendo una distribuzione di tipo normale, possiamo fare delle previsioni su Y. Possiamoassumere e Y sia il valore aeso di y più probabile, e possiamo stimare la probabilitàdell'occorrenza di una osservazione y.
Naturalmente, la varianza di una variabile influisce sulla nostra capacità di fare delleprevisioni. Se la varianza è prossima allo zero, noi possiamo prevedere con certezza eil valore aeso di una osservazione y sarà molto vicino alla media Y
.. Varianza spiegata e previsioni
Se riprendiamo l'esempio banale delle precipitazioni atmosferie: La variazione del-le osservazioni può essere molto ampia: da poi millimetri a decine di centimetri.Tuavia, tua la variazione di peso, però, può essere spiegata dal volume dell'acqua(aenzione: spiegata non significa causata).
Passiamo al caso meno banale di dover stimare il consumo di carburante durantel'uso di un'auto in una giornata, conoscendo i km percorsi.
In questo caso, come abbiamo visto, la scommessa sarà meno certa, in quanto ilconsumo è legato ane al tipo di guida, al tipo di percorso, alle condizioni di trafficoe così via. Ciononostante, conoscere il numero di km percorsi mi permee una stimamolto più accurata di quanto potrei fare semplicemente tirando ad indovinare.
La varianza residua, ovvero la varianza dei residui, sarà molto più bassa della va-rianza totale. Il numero di km costituisce dunque un prediore molto utile del consumodi carburante.
Varianza residua e previsioni Il vantaggio di poter applicare la regressione lineare èe la relazione fra due variabili può essere espressa araverso due soli parametri: β0 eβ1, ovvero l'intercea e la pendenza della linea.
Nel caso di variabili indipendenti di tipo categoriale, naturalmente, non è possibileassumere alcuna linearità, e dunque non possono bastarci quei due parametri.
.. Un esempio: gli affitti in una città
Immaginiamo di voler prendere in affio un appartamento in una cià di medie di-mensioni, e vogliamo capire se, in differenti quartieri, i prezzi sono significativamentediversi.
Immaginiamo dunque di fare una ricerca sistematica, usando alcuni siti specializzati,raccogliendo le informazioni relative a appartamenti, distribuiti su quartieri: nelquartiere A, nel B, nel C.
ello e vogliamo capire è se, nei differenti quartieri, i prezzi sono significativa-mente diversi.
R: generare l'esempio Con R, possiamo generare il dataset di valori, invocandornorm.
Decidiamo di generare valori con media e sd (quartiere A), con media e sd (quartiere B), con media e sd (quartiere C).

CAPITOLO . ANALISI DELLA VARIANZA
Usando le funzioni factor, levels e data.frame creiamo il dataframe con colonne(prezzo, quartiere) e righe.
R: il codice
> zonaA <- round(rnorm(20, 55, 3)) * 10> zonaB <- round(rnorm(20, 59, 3)) * 10> zonaC <- round(rnorm(20, 62, 3)) * 10> zone <- c(zonaA, zonaB, zonaC)> fZone <- factor(c(rep("A", 20),+ rep("B", 20), rep("C", 20)))> affitti <- data.frame(prezzo = zone,+ quartiere = fZone)
0 10 20 30 40 50 60
500
550
600
650
700
Affitti per zona
Zone
Affi
tti
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
Figura .: Il grafico dell'esempio degli affii

.. INFERENZA E PREVISIONI
Grafico e varianza Nel grafico ., ploiamo le osservazioni: in rosso le venti delquartiere A, verde il quartiere B, blu il C. La linea rossa marca il valore medio di A, laverde la media di B, blu la media di C. Le due righe rosse traeggiate, l'intervallo diconfidenza al % delle osservazioni in A, le verdi in B, le blu in C. La riga continua nerarappresenta la media generale, le due righe traeggiate nere l'intervallo di confidenzagenerale, al %.
Nonostante le variazioni dovute al caso, è iaro e l'intervallo di confidenza deisingoli gruppi è minore (e diverso) dell'intervallo di confidenza totale. esto significae conoscere il quartiere dove un appartamento è collocato mi permee di fare delleprevisioni migliori in merito al prezzo e mi aspeo di pagare.
. Inferenza e previsioni
L'analisi bivariata (descriiva e inferenziale) ci permee dunque innanzituo di capirese una variabile influisce su di un'altra.
In secondo luogo, se l'influenza è statisticamente significativa, conoscere il valoredella prima variabile ci permee di fare delle previsioni più accurate sulla seconda.
Rapporto fra varianza spiegata e residua L'analisi della varianza è la statistica in-ferenziale e valuta se vi è una relazione fra una (o più) variabili indipendenti, di tipocategoriale, e una variabile quantitativa (almeno ad intervalli). Il principio su cui si ba-sa la statistica è proprio la percentuale di varianza spiegata dal modello riespeo allavarianza totale.
La misura e viene presa in considerazione in questa statistica è dunque un rappor-to: il rapporto fra varianza spiegata dal modello e varianza residua (ovvero la differenzafra la varianza totale e quella spiegata). Se il rapporto supera un determinato valore cri-tico, si rifiuta l'ipotesi nulla (secondo cui non vi è relazione fra la variabile indipendentee quella dipendente).
.. L'analisi della Varianza
elloe l'analisi della varianza ci permee di capire è se lemedie della variabile dipen-dente osservate nei diversi gruppi sono o meno statisticamente diverse. Più precisamen-te, ci permee di stabilire se esistono almeno due gruppi la cui media sia statisticamentediversa ¹.
Il vantaggio di questo approccio, rispeo al confronto fra coppie di gruppi, è duplice:
� non vi è una proliferazione dell'errore di tipo I, in quanto il confronto è unico
� nel caso di più variabili indipendenti, è possibile stimare l'influenza di ognunadelle variabili indipendenti, noné della loro interazione.
¹questo tipo di statistica viene definito omnibus

CAPITOLO . ANALISI DELLA VARIANZA
L'ipotesi nulla L'ipotesi nulla assume e la media dei gruppi non sia fra loro diversa,e dunque e le medie dei gruppi siano approssimativamente pari alla media generale.
Se lemedie dei vari gruppi sono tue perfeamente uguali allamedia generale, anela varianza dei gruppi sarà pari alla varianza generale, e dunque la varianza spiegata saràpari a zero.
Errore di campionamento A causa dell'errore di campionamento, però, sappiamoe,ane qualora l'ipotesi nulla sia vera, le medie dei gruppi potranno discostarsi dallamedia generale, e dunque la varianza spiegata misurata sarà superiore a zero.
Come nei casi già visti (t test, correlazione, i quadro), il valore del rapporto fra va-rianze va dunque confrontato con una distribuzione (teorica o generata empiricamente,ad esempio araverso una simulazione) in modo da valutare se la proporzione di va-rianza spiegata è da aribuire al caso (errore di campionamento), e dunque va acceatal'ipotesi nulla, oppure no.
Il calcolo
Somme dei quadrati Per calcolare il test dell'analisi della varianza, dobbiamo calco-lare tre valori.
� la somma dei quadrati dell'errore totale, SST ;
� la somma dei quadrati dell'errore residuo, SSR;
� la somma dei quadrati del modello, SSM ;
Per calcolare le varianze totale, residua e spiegata dobbiamo dividere gli SS per i rispeivigradi di libertà
Somma dei quadrati e varianza totale La somma dei quadrati dell'errore totale sicalcola con la formula
SST =N∑
n=1
(Yi − Y..)2 (.)
dove N è il numero totale di osservazioni e Y.. è la media totale.I gradi di libertà della varianza totale sono dfT = N − 1.La varianza totale è pari aMST = SST /dfT .
Somma dei quadrati e varianza residua La somma dei quadrati dell'errore residuo sicalcola con la formula
SSR =
I∑i=1
Ji∑j=1
(Yij − Yi.)2 (.)
dove I sono i livelli della variabile indipendente, Ji il numero di osservazioni del livelloi e Yi. la media delle osservazioni per il livello i.
I gradi di libertà della varianza residua sono dfR = N − I .La varianza residua è pari aMSR = SSR/dfR.

.. DISTRIBUZIONE DELL'ERRORE, INFERENZA
Somma dei quadrati e varianza spiegata La somma dei quadrati del modello si cal-cola con
SSM =I∑
i=1
(Yi. − Y..)2· Ji (.)
Ovvero, si calcola la differenza fra la media del gruppo i e la media totale, la si eleva alquadrato, e la si moltiplica per il numero di osservazioni di quel gruppo.I gradi di libertà della varianza del modello sono dfM = I − 1.
La varianza spiegata è pari aMSM = SSM/dfM .
Identità principale dell'ANOVA Proprio come per il modello di regressione lineare,SST = SSM + SSR. esta uguaglianza viene definita identità principale dell'ANO-VA.
La significatività del rapporto fra la variabile indipendente e quella dipendente vienemisurata meendo a rapporto la varianza spiegata dal modello con la varianza residua:F = MSM/MSR.
. Distribuzione dell'errore, inferenzaPer introdurre il calcolo dell'analisi della Varianza, usiamo la consueta sequenza logica
� identificazione di una misura della relazione
� identificazione di una popolazione virtuale
� estrazione casuale di k· I campioni; calcolo della misura per ogni estrazione, esalvataggio nel veore delle misure
� osservazione della distribuzione delle misure generate
� calcolo del p-value araverso il confronto con il veore delle misure
� identificazione di una distribuzione teorica e, previo opportuna trasformaizone,mappa quella osservata
� calcolo del p-value utilizzando la probabilità della distribuzione teorica identifi-cata
� utilizzo della funzione di R
La simulazione Per la nostra simulazione, immaginiamo un disegno sperimentalebivariato, dove la variabile indipendente ha tre livelli.
� La misura della relazione è la statistica F identificata sopra;
� generiamo per k volte tre campioni di numerositàm, con stessamedia e deviazionestandard (media e deviazione standard sono arbitrarie);
� calcoliamo SST , SSR, SSM , dfT , dfR, dfM ,MST ,MSR,MSM

CAPITOLO . ANALISI DELLA VARIANZA
� Calcoliamo la statistica F = MSM/MSR, e la salviamo nel veore delle misure.
> k <- 10000> distribuzione <- vector("numeric", k)> for (i in 1:k) {+ n <- 60+ osservazioni <- rnorm(n, 100, 6)+ osservazioniA <- osservazioni[1:20]+ osservazioniB <- osservazioni[21:40]+ osservazioniC <- osservazioni[41:60]+ meanA <- mean(osservazioniA)+ meanB <- mean(osservazioniB)+ meanC <- mean(osservazioniC)+ meanTot <- mean(osservazioni)+ SSRA <- sum((osservazioniA - meanA)^2)+ SSRB <- sum((osservazioniB - meanB)^2)+ SSRC <- sum((osservazioniC - meanC)^2)+ SSR <- SSRA + SSRB + SSRC+ SSMA <- 20 * (meanA - meanTot)^2+ SSMB <- 20 * (meanB - meanTot)^2+ SSMC <- 20 * (meanC - meanTot)^2+ SSM <- SSMA + SSMB + SSMC+ SST <- sum((osservazioni - meanTot)^2)+ MSM <- SSM/(3 - 1)+ MSR <- SSR/(60 - 3)+ Fvalue <- MSM/MSR+ distribuzione[i] <- Fvalue+ }
.. La distribuzione Fisher-Snedecor
Nella figura ., l'istogramma rappresenta la distribuzione dell'errore di campionamentooenuto con la simulazione.
La linea sovrapposta all'istogramma rappresenta la distribuzione teorica F di Fisher-Snedecor.
Similmente alla distribuzione t di Student e alla distribuzione χ2, ane la F è unafamiglia di distribuzioni, e variano a seconda dei gradi di libertà.
La distribuzione F, però, varia in base a due gradi di libertà. Nell'esempio della si-mulazione, la linea corrisponde alla distribuzione F (,), ovvero ai gradi di libertà dellavarianza spiegata e della varianza residua.
R: calcolo di F value Mostriamo il calcolo della statistica F con R, calcolando le tremedie, la media totale, SSR, SSM , SST ,MSR,MSM , ed infine F.
> osservazioniA <- zonaA

.. DISTRIBUZIONE DELL'ERRORE, INFERENZA
Histogram of distribuzione
distribuzione
Den
sity
0 2 4 6 8 10 12 14
0.0
0.1
0.2
0.3
0.4
0.5
0.6
Figura .: La distribuzione dell'errore diF di Fisher-Snedecor
> osservazioniB <- zonaB> osservazioniC <- zonaC> osservazioni <- zone> meanA <- mean(osservazioniA)> meanB <- mean(osservazioniB)> meanC <- mean(osservazioniC)> meanTot <- mean (osservazioni)> SSRA <- sum ((osservazioniA-meanA)^2)> SSRB <- sum ((osservazioniB-meanB)^2)> SSRC <- sum ((osservazioniC-meanC)^2)> SSR <- SSRA + SSRB + SSRC> SSMA <- 20 * (meanA-meanTot)^2> SSMB <- 20 * (meanB-meanTot)^2> SSMC <- 20 * (meanC-meanTot)^2> SSM <- SSMA + SSMB + SSMC> SST <- sum((osservazioni-meanTot)^2)> MSR <- SSR/(n-3)> MSM <- SSM/(3-1)> F_Affitti <- MSM/MSR> c(SSM, SSR, SST)
[1] 55090 61595 116685
> c(MSM, MSR)
[1] 27545.000 1080.614
> F_Affitti
[1] 25.49014

CAPITOLO . ANALISI DELLA VARIANZA
F è dunque pari a .. Ora, possiamo calcolare il p-value nel modo consueto,confrontando la posizione di questa statistica con la distribuzione calcolata prima.
> p_value_empirica_1 <- 1 -+ rank(c(F_Affitti, distribuzione))[1]/(k + 1)> p_value_empirica_1
[1] 0
Ora, calcoliamo il p-value usando la funzione pf.
> p_value_F_1 <- 1 - pf(F_Affitti, 2, 57)> p_value_F_1
[1] 1.236281e-08
Il risultato è sostanzialmente simile.
.. R: uso di aov
R mee a disposizione, per il calcolo dell'analisi della varianza, la funzione aov(y x),dove y è la variabile dipendente, numerica, e x è il faore.
> summary(aov(prezzo~quartiere,data=affitti))
Df Sum Sq Mean Sq F value Pr(>F)quartiere 2 55090 27545.0 25.49 1.236e-08 ***Residuals 57 61595 1080.6---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Leggere l'output utilizzando la funzione summary su aov è possibile avere il deagliodei risultati dell'analisi. Nel caso di una analisi ad una via, avremo una tabella con duerighe. La seconda riga calcola i gradi di libertà, la somma dei quadrati, e la media deiquadrati dei residui (ovvero dfR, SSR,MSR). La prima riga calcola i gradi di libertà,la somma dei quadrati, e la media dei quadrati del modello: dfM , SSM ,MSM ); Inoltre,calcola F = MSM/MSR; infine, calcola il p-value. I codici simbolici (gli asterisi) cisuggeriscono la significatività: *** significa e p− value < 0.01.
. Anova a due vie
.. Due variabili indipendenti
L'analisi della varianza e abbiamo introdoo, può essere estesa ane ai casi in cui levariabili indipendenti sono più di una.
Nell'analisi della varianza a due vie, ad esempio, si indaga la relazione fra due va-riabili indipendenti, entrambe categoriali, ed una variabile dipendente, quantitativa.
In questa sezione analizziamo la circostanza in cui le variabili indipendenti sono due,ma la logica rimane la stessa ane nelle circostanze in cui le variabili indipendenti sonopiù di due.

.. ANOVA A DUE VIE
Le ipotesi
Nell'Anova a due vie, le domande e il ricercatore si pone sono tre:
� La prima delle variabili indipendenti, influisce significativamente sulla variabiledipendente?
� La seconda delle variabili indipendenti, influisce significativamente sulla variabiledipendente?
� Vi è una interazione fra le due variabili?
.. Un esempio: antidepressivi e attività aerobica
Introduciamo l'analisi della varianza a due vie con un esempio. Dei ricercatori sono inte-ressati ad analizzare l'influenza dell'aività aerobica e di un tipo di farmaci antidepressivi(ad esempio, gli RSSI, gli inibitori del reuptake della serotonina) sul tono dell'umore dipazienti con diagnosi di depressione maggiore.
Decidono pertanto di selezionare pazienti con diagnosi di depressione, e di asse-gnarli casualmente a gruppi sperimentali, in un disegno x.
I fattori Un faore è dunque l'antidepressivo: a pazienti verrà somministrato, per giorni, una dose di RSSI, mentre agli altri verrà somministrato, per lo stesso periodo,un placebo.
L'altro faore, l'aività aerobica: a pazienti verrà iesto di fare minuti diaività aerobica due volte al giorno per giorni. Agli altri pazienti verrà iesto difare una aività non aerobica, di controllo, per lo stesso periodo di tempo.
I gruppi sperimentali Avremo dunque pazienti con placebo e aività non aerobica, con placebo e aività aerobica, con farmaco e aività non aerobica, con farmacoe aività aerobica.
Alla fine dei giorni, verrà somministrato un questionario (ad esempio il BDI, Bedepression inventory), per valutare il loro tono dell'umore alla fine del traamento.
.. Il calcolo
Somma dei quadrati totale e residua La somma dei quadrati totale è identico al casodell'anova ad una via: si somma il quadrato della differenza di ogni osservazione conla media generale. Per calcolare la varianza totale si divide il tuo per i gradi di libertàdella varianza totale, pari a n-.
Ane la somma dei quadrati residui è identico al caso dell'anova ad una via: per ognicondizione sperimentale, si sommano i quadrati delle differenze fra i valori osservati ela media di quel gruppo, si sommano i valori così oenuti da ogni gruppo. Di nuovo, lavarianza è data dalla somma dei quadrati divisa per i gradi di libertà

CAPITOLO . ANALISI DELLA VARIANZA
Somma dei quadrati dei fattori Il calcolo di SSA: per ogni livello della variabile A,si calcola la media delle osservazioni di quel livello.
Si calcola il quadrato della differenza fra questa media e la media generale.Si moltiplica questo risultato per il numero di osservazioni del livello.Alla fine, si sommano i valori oenuti per ognuno dei livelli. Si dividono per i gradi
di libertà (pari al numero di livelli meno uno) per oenere la varianzaMSA
In pratica, nel calcolare SSA si fa come se il faore B non esistesse. Lo stessoprocedimento viene usato per calcolare la varianza spiegata dal faore B.
Somma dei quadrati dell'interazione Nel caso dell'anova ad una via, la varianza tota-le era pari alla somma della varianza residua e della varianza spiegata dall'unica variabileindipendente.
Nel caso dell'anova a due vie, però, la somma di varianza residua, varianza spiegatada A e varianza spiegata da B sarà minore della varianza totale.
La differenza è data dalla varianza spiegata dall'interazione fra i due faori A e B.Più forte è l'interazione fra le due variabili indipendenti, più alta sarà la varianza spie-gata dall'interazione (e dunque maggiore sarà la differenza fra la somma delle varianzeresidue, di A, di B e la varianza totale).
L'interazione fra le variabili indipendenti
Per introdurre il calcolo della varianza spiegata dall'interazione fra A e B, può essereutile riprendere il conceo di frequenza aesa introdoa nel test del χ2. Ane in quelcaso si traava di valutare l'interazione fra due variabili categoriali. La differenza è ementre nel χ2 si misurano le frequenze, in questo caso la misura è data da una variabilequantitativa.
In maniera simile al χ2, però, è possibile, conoscendo le medie marginali dei livelli diA e B, costruire una tabella delle medie aese, e costituisce il caso perfeo di assenzadi interazione fra i due faori. esta tabella costituisce il caso oimale di acceazionedell'ipotesi nulla relativa all'interazione fra le due variabili.
L'esempio: calcolo delle somme dei quadrati
Per esemplificare, torniamo all'esempio di un disegno x. ello e vogliamo fare ècreare una tabella x delle medie aese.
Il primo passaggio, è calcolare le medie marginali per ogni livello della variabile A,e dunque la media di A e la media di A.
Il secondo passaggio, è calcolare le medie marginali per i livelli di B, e dunque lamedia di B e la media di B.
Infine, per le quaro celle [,] [,] [,] e [,], calcolare la media aesa.La media aesa della cella [,] è pari alla media generale + la differenza fra A e la
media generale e la differenza fra B e la media generale. Dunque, A + B - media.
Calcolo delle somme dell'interazione SSInt si basa sul quadrato delle differenze frala tabella delle medie aese e la tabella delle medie osservate, moltiplicata per il numerodi osservazioni per gruppo.

.. ANOVA A DUE VIE
Dunque, più la tabella delle medie osservate è simile alla tabelle delle medie aese,minore è l'interazione fra le due variabili indipendenti, e dunque minore è la varianzaspiegata dall'interazione.
Viceversa, maggiore è la differenza, maggiore l'interazione, maggiore la varianzaspiegata dall'interazione.
Il calcolo, formalizzazione
Somma dei quadrati e varianza totale La somma dei quadrati dell'errore totale sicalcola con la formula
SST =N∑
n=1
(Yi − Y...)2 (.)
dove N è il numero totale di osservazioni e Y... è la media totale.I gradi di libertà della varianza totale sono dfT = N − 1.La varianza totale è pari aMST = SST /dfT .
Somma dei quadrati e varianza residua La somma dei quadrati dell'errore residuo sicalcola con la formula
SSR =I∑
i=1
J∑j=1
K∑k=1
(Yijk − Yij.)2 (.)
dove I sono i livelli di A, J i livelli di B, K il numero di osservazioni per ogni livello e Yij.
la media delle osservazioni per il gruppo ij.I gradi di libertà della varianza residua sono dfT = N − I ∗ J .La varianza residua è pari aMSR = SSR/dfR.
Somma dei quadrati e varianza spiegata La somma dei quadrati del modello si cal-cola con
SSA = K·J ·I∑
i=1
(Yi.. − Y...)2 (.)
SSB = K· I·J∑
j=1
(Y.j. − Y...)2 (.)
I gradi di libertà della varianza del modello sono dfA = I − 1, dfB = J − 1.Le varianze spiegate sonoMSA = SSA/dfA,MSB = SSB/dfB .
Somma dei quadrati e varianza dell'interazione
SSint = K·I∑
i=1
J∑j=1
(Yij. − Yi.. − Y.j. + Y...)2 (.)
ovvero la media osservata meno la media marginale di Ai, meno la media marginale diBj , più la media totale.

CAPITOLO . ANALISI DELLA VARIANZA
I gradi di libertà della varianza dell'interazione sono dfint = (I − 1)· (J − 1).La varianza dell'interazione èMSint = SSint/dfint.
Le ipotesi inferenziali
Le ipotesi inferenziali sono tre:
� HA0 : l'influenza della variabile A sulla variabile dipendente non è significativa
� HB0 : l'influenza della variabile B sulla variabile dipendente non è significativa
� HAB0 : l'interazione fra A e B non è significativa.
Ipotesi inferenziali e F Per valutare le tre ipotesi inferenziali, vengono calcolati i trerapporti:
� FA = MSA/MSR;
� FB = MSB/MSR;
� Fint = MSint/MSR;
Ognuno dei rapporti viene confrontato con la distribuzione F di Fisher-Snedecor.
.. Modello lineare
In maniera simile alla regressione lineare, ane l'analisi della varianza (sia a una e adue vie) può essere rappresentata araverso un modello lineare. Il modello generale perl'anova a due vie è
Yijk = µ+ αi + βj + δij + εijk, i = 1...I, j = 1...J, k = 1...K (.)
dove I è il numero di livelli del faore A, J il numero di livelli del faore B, K il numerodi osservazioni per ogni gruppo.
µ corrisponde alla media totale di tue le osservazioni.αi corrisponde allo scostamento dalla media totale del livello Ai
βj corrisponde allo scostamento dalla media totale del livello Bj
δij corrisponde alla differenza fra la media del campione osservata e quella aesa inbase all'ipotesi di non interazione fra A e B.
εijk è la componente di errore, ovvero la differenza fra il valore aeso dal modelloe il valore osservato.
.. L'esempio dei trattamenti per la depressione
Torniamo all'esempio dei traamenti per la depressione, e generiamo tre diversi scenari.

.. ANOVA A DUE VIE
2530
35
expDep$farmaco
mea
n of
exp
Dep
$pun
tegg
i
placebo farmaco
expDep$aerobica
aerobiconon aerobico
Figura .: Primo scenario
Primo scenario
non aerobico aerobicoplacebo 23.17468 27.80842farmaco 29.99511 38.29113
Df Sum Sq Mean Sq F value Pr(>F)farmaco 1 2245.5 2245.49 37.2503 1.414e-08 ***aerobica 1 1253.8 1253.84 20.7999 1.273e-05 ***farm:aer 1 100.6 100.59 1.6687 0.199Resid. 116 6992.6 60.28
Dal modello dell'analisi della varianza possiamo dedurre e vi è una influenza signifi-cativa sia del primo faore (farmaco) e del secondo (aività aerobica); non vi è, però,interazione significativa fra i due faori.
L'esempio, secondo scenario
non aerobico aerobicoplacebo 23.17468 27.80842farmaco 29.99511 28.69854
Df Sum Sq Mean Sq F value Pr(>F)farmaco 1 445.9 445.89 7.4065 0.007501 **aerobica 1 83.5 83.53 1.3874 0.241257farm:aer 1 263.8 263.76 4.3812 0.038516 *Resid. 116 6983.6 60.20
In questo scenario, invece:
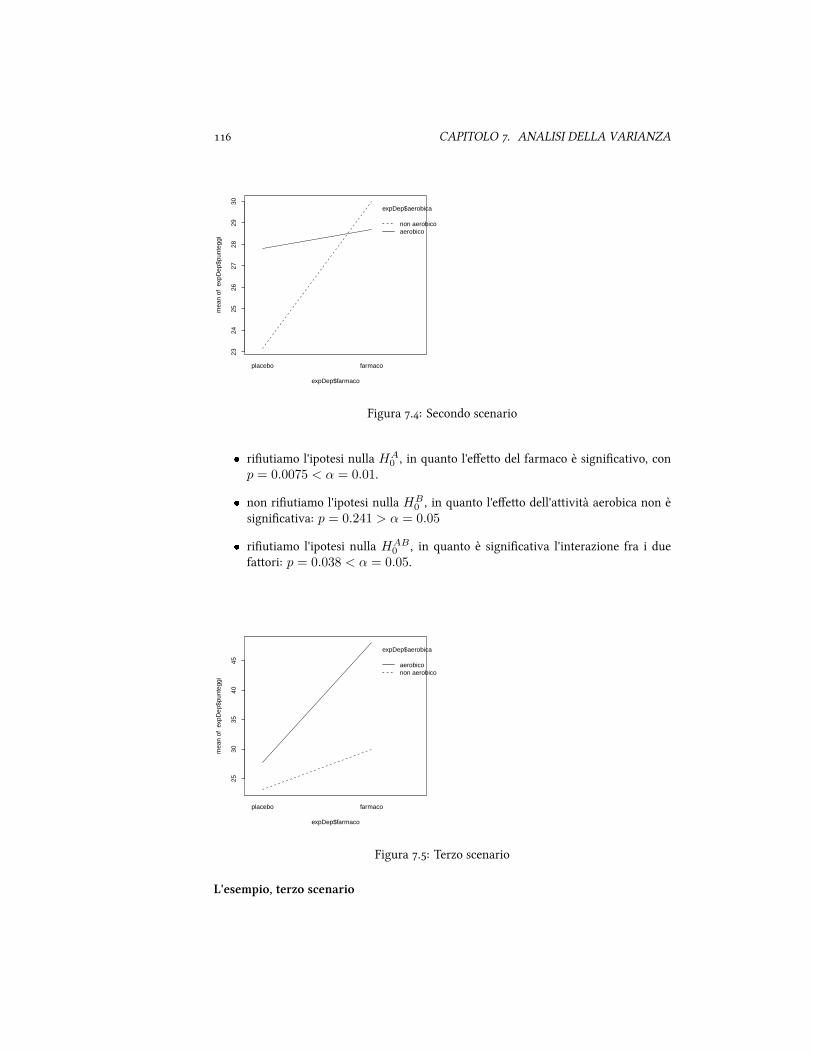
CAPITOLO . ANALISI DELLA VARIANZA
2324
2526
2728
2930
expDep$farmaco
mea
n of
exp
Dep
$pun
tegg
i
placebo farmaco
expDep$aerobica
non aerobicoaerobico
Figura .: Secondo scenario
� rifiutiamo l'ipotesi nulla HA0 , in quanto l'effeo del farmaco è significativo, con
p = 0.0075 < α = 0.01.
� non rifiutiamo l'ipotesi nulla HB0 , in quanto l'effeo dell'aività aerobica non è
significativa: p = 0.241 > α = 0.05
� rifiutiamo l'ipotesi nulla HAB0 , in quanto è significativa l'interazione fra i due
faori: p = 0.038 < α = 0.05.
2530
3540
45
expDep$farmaco
mea
n of
exp
Dep
$pun
tegg
i
placebo farmaco
expDep$aerobica
aerobiconon aerobico
Figura .: Terzo scenario
L'esempio, terzo scenario

.. CONFRONTI MULTIPLI
non aerobico aerobicoplacebo 23.17468 27.80842farmaco 29.99511 48.07014
Df Sum Sq Mean Sq F value Pr(>F)farmaco 1 5500.8 5500.8 90.080 3.701e-16 ***aerobica 1 3867.7 3867.7 63.336 1.301e-12 ***farm:aer 1 1355.0 1355.0 22.189 6.910e-06 ***Resid. 116 7083.7 61.1---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
In questo caso, si rifiutano tue le ipotesi nulle, in quanto risultano significativi sia ilfarmaco, e l'aività aerobica, e l'interazione fra i due faori. In tui i casi p < 0.001.
. Confronti multipliConfronti multipli ed errore L'analisi della varianza ci permee di verificare se ledifferenze fra le medie di tre o più campioni sono da aribuire all'errore campionario, ose sono significative.
Una volta rifiutata l'ipotesi nulla, però, resta da determinare quali differenze sonosignificative. L'analisi della varianza, infai, ci dice se vi è almeno una coppia di gruppila cui differenza è significativa, ma non ci dice quali differenze lo sono.
Per poter determinare quali differenze sono significative, diventa necessario con-frontare i gruppi a due a due.
Come abbiamo visto all'inizio del capitolo, si potrebbe decidere di utilizzare, per con-frontare a due a due i diversi gruppi, il t-test. Ma, come abbiamo già accennato, applicareripetutamente il t-test aumenta la probabilità di incorrere in un errore del primo tipo.
Diventa dunque necessario adoare dei test di confronti multipli capaci di manteneresoo controllo l'errore del I tipo.
.. La correzione di Bonferroni
Un possibile approccio, finalizzato a controllare la proliferazione dell'errore del I tipo, èquello di adoare la correzione di Bonferroni, e consiste nel dividere il valore α per ilnumero di confronti effeuati (o, in maniera corrispondente, moltiplicare il p-value peril numero di confronti).
Se, ad esempio, dobbiamo confrontare le medie di gruppi e decidiamo per un valoreα = 0.05, in base alla correzione di Bonferroni dovremo considerare significativi sol-tanto quei confronti il cui p-value sia inferiore a 0.05/6 = 0.0083 (in quanto i confrontiprevisti sono ).
Il problema di questo metodo è e tende ad essere eccessivamente conservativo.
.. Il test di Tukey
Un metodo di confronto multiplo meno conservativo è il test di Tukey.

CAPITOLO . ANALISI DELLA VARIANZA
Ane araverso il test di Tukey è possibile mantenere l'errore di tipo I entro unpredeterminato valore di α (generalmente pari a .).
Il test di Tukey permee di correggere il p-value in base al numero di confrontie vengono effeuati nel confronto multiplo, senza però penalizzare eccessivamente lastatistica.
Per correggere l'errore, il test di Tukey confronta la statistica calcolata con la distri-buzione studentized range
Il test di Tukey: calcolo Per calcolare la significatività della differenza fra due gruppicon il metodo di Tukey si utilizza il seguente algoritmo:
� si calcola l'errore standard, con la formula
SE =√(MSR/n) (.)
dove n è il numero di osservazioni per gruppo. Nel caso di gruppi con numerositàdiversa, la formula diventa
SE =
√MSR
2· ( 1
na+
1
nb) (.)
dove na e nb sono la numerosità del primo e del secondo gruppo
� si calcola la statistica Q = |Ya−Yb|SE
� si calcola il p-value, usando la funzione ptukey(Q, k,DfR) dove k è il numerodi confronti effeuati, eDfR i gradi di libertà della varianza residua. La funzioneptukey calcola la probabilità sulla distribuzione studentized range.
Affitti: confronti multipli
Torniamo all'esempio degli affii, e mostriamo il calcolo di uno dei confronti multiplicon il test di Tukey. Mostriamo le tre medie.
> medieAffitti <- tapply(affitti$prezzo, affitti$quartiere, mean)> medieAffitti
A B C560.5 579.0 632.0
Tukey: il calcolo di un confronto Calcoliamo il cononto fra le medie dei gruppi Ae B.
> confronto1 <-+ abs(medieAffitti[1] - medieAffitti[2])> SE <- sqrt(MSR/20)> Q <- confronto1/SE> p_value <- 1 - ptukey(Q, 3, 57)> c(confronto1, SE, Q, p_value)

.. CONFRONTI MULTIPLI
Differenza SE Q p-value18.5 7.350558 2.516816 0.185548
Il p-value è alto, e dunque la differenza fra i gruppi A e B non è significativa.
La funzione R TukeyHSD
La funzione di R per il calcolo del confronto con il metodo Tukey è TukeyHSD. Coe-rentemente con l'uso dei confronti multipli, la funzione si applica sul risultato dellacorrispondente analisi della varianza.
> aovAffitti <- aov(prezzo ~ quartiere, data = affitti)> TukeyHSD(aovAffitti, ordered = TRUE)
diff lwr upr p adjB-A 18.5 -6.515339 43.51534 0.185548C-A 71.5 46.484661 96.51534 0.000000C-B 53.0 27.984661 78.01534 0.000012
La funzione ritorna una tabella, con una riga per ogni confronto, dove vengonomostrate:
� la coppia confrontata (es, il confronto fra il gruppo B ed il gruppo A); l'ordine ètale e il gruppo con media più alta è davanti all'altro;
� la differenza (positiva) fra i due gruppi;
� l'intervallo di confidenza della differenza; ad esempio, nel secondo confronto (C-A), la differenza è di ., l'intervallo di confidenza va da un minimo di . adun massimo di .. p adj è il p-value aggiustato; nell'esempio, i confronti C-A eC-B sono significativi, il confronto B-A no.
.. Analisi della Varianza: assunti
Come ogni approccio parametrico, ane l'analisi della varianza fa delle assunti:
� indipendenza delle osservazioni
� distribuzione normale degli errori
� omosedasticità: la varianza dell'errore è costante
� gli errori sono fra loro indipendenti
Distribuzione degli errori Si assumee gli errori abbiano una distribuzione normale,con media pari a , e varianza costante fra i gruppi. Per testare l'ipotesi di normalità, èpossibile usare il test di Shapiro-Wilk sui residui del modello dell'analisi della varianza:
> shapiro.test(aovAffitti$residuals)
Per testare l'ipotesi di omosedasticità, si può usare il test di Bartle:
> bartlett.test(prezzo ~ quartiere, data = affitti)

CAPITOLO . ANALISI DELLA VARIANZA
. Test non parametricoVi sono circostanze in cui l'analisi della varianza non può essere applicata, in quantovengono meno alcuni assunti o condizioni:
� non si può assumere la normalità della distribuzione degli errori
� il numero di osservazioni per ogni gruppo è minore di
� la variabile dipendente non è ad intervalli, ma ordinale
In questi casi è possibile applicare il test non parametrico di Kruskal-Wallis
.. Il test di Kruskal-Wallis
il test di Kruskal-Wallis è un'estensione del test di Wilcoxon, e abbiamo visto nel ca-pitolo dedicato al t-test Chan and Walmsley (). Nel test di Kruskal-Wallis, la primaoperazione da compiere è quella di trasformare i punteggi osservati nel loro rango. Aquesto punto, si applica la formula
K = (n− 1)
∑Ii=1 ni(ri. − r)2∑I
i=1
∑ni
j=1(rij − r)2(.)
dove ni è il numero di osservazioni nel gruppo i, rij è la posizione ordinale dell'osserva-zione j del gruppo i, N è il numero totale delle osservazioni, ri. è la media dei rank delgruppo i.
Semplificazioni L'equazione . può in realtà essere semplificata, in quanto r = (N+1)/2 e denominatore è pari a (N − 1)N(N + 1)/12, e dunque oeniamo
K =12
N(N + 1)
I∑i=1
ni(ri. −N + 1
2)2 (.)
La statistica K assume una distribuzione χ2 con i- gradi di libertà.
R: la funzione kruskal.test
Appliiamo il test di Kruskal-Wallis al nostro esempio degli affii.
> kruskal.test(prezzo ~ quartiere, data = affitti)
Kruskal-Wallis rank sum test
data: prezzo by quartiereKruskal-Wallis chi-squared = 26.4763,df = 2, p-value = 1.781e-06
Leggere i risultati La funzione restituisce la statistica, Kruskal-Wallis i-squared =.; I gradi di libertà: df = ; il p-value = .e-.

.. CONCLUSIONI
. ConclusioniDa fare.

CAPITOLO . ANALISI DELLA VARIANZA

Capitolo
Casi di studio
In questo capitolo verranno presentati alcuni casi di studio: un esperimento su framingeffect, un questionario sulla depressione, un test di riconoscimento di parole e non parole.
La finalità è quella di mostrare l'uso di R ed i passaggi necessari per caricare il fi-le dei dati, filtrarli, lavorare sui valori mancanti (missing), utilizzare i metodi grafici enon grafici della statistica descriiva, applicare la statistica inferenziale e trarre delleconclusioni.
Nell'analizzare i casi di studio, vedremo e, spesso, gli assunti alla base dei me-todi parametrici tendono ad essere violati (nella peggiore delle ipotesi) o tendono adessere al limite dell'acceabilità (nella migliore). Per questo motivo, nella sezione .torneremo sul problema degli assunti, della loro violazione e delle statistie cosiddeerobuste, accennando alle trasformazioni non lineari, al trimming, alla winsorizzazione,alle permutazioni ed al bootstrapping.
Infine, il capitolo si concluderà con una coppia di esempi i cui dati verranno creatiartificialmente.
. Il framing effect nella scelta di un pacetto turistico:un esperimento on line
.. Introduzione
È noto in leeratura come i processi decisionali di un individuo possano essere significa-tivamente influenzati dalla modalità di presentazione delle alternative. Più in particolarela teoria del prospeo (Tversky and Kahneman, ) prevede e la prospeiva di unaperdita (o di un costo) abbia un impao decisionale maggiore della prospeiva di unguadagno (o di un risparmio). Abbiamo condoo un esperimento finalizzato a replicareil ``framing effect`` (Kahneman and Tversky, ) in un contesto decisionale legato allascelta di un paceo turistico. L'esperimento è stato condoo esclusivamente on-line,araverso un sito internet.

CAPITOLO . CASI DI STUDIO
.. Metodo
Nell'esperimento veniva presentata una offerta turistica alberghiera e il partecipantedoveva scegliere se acquistare il paceo “pensione completa” o il paceo “mezzapensione”. I partecipanti sono stati reclutati araverso un invito a partecipare ad unesperimento sulla psicologia della decisione, pubblicato su due differenti siti. Coloroe decidevano di partecipare all'esperimento venivano assegnati casualmente, dal ser-ver web, ad una delle due condizioni sperimentali. Hanno partecipato all'esperimento persone. Per indurre l'effeo del framing sono stati presentati due differenti scenari: unoscenario “supplemento” ed uno scenario “risparmio”. Nel primo veniva proposto comeofferta di base il paceo in mezza pensione ( giorni a euro), con la possibilità discegliere la pensione completa pagando un supplemento di euro. Nel secondo l'offertadi base era il paceo in pensione completa a euro, con la possibilità di scegliere lamezza pensione risparmiando euro.
Scenario Supplemento
Immagina di voler trascorrere alcuni giorni di vacanza in una località turistica. Sul sitoweb di un albergo e ti piace viene proposta la seguente offerta: giorni in mezzapensione a euro. Maggiorazione per la pensione completa: euro.
Scenario Risparmio
Immagina di voler trascorrere alcuni giorni di vacanza in una località turistica. Sul sitoweb di un albergo e ti piace viene proposta la seguente offerta: giorni in pensionecompleta a euro. Riduzione per la mezza pensione: euro.
Domanda (comune ai scenari)
Immagina di voler trascorrere giorni in quell'albergo. Decidi di fare pensione completao mezza pensione?Mezza PensionePensione Completa
> rm(list = ls(all = TRUE))> soggettiEsteso <- read.table("decisione1.log", header = TRUE,+ sep = "\t")> names(soggettiEsteso)
[1] "data" "ip" "referer" "navigator" "lang" "v1"[7] "v2" "v3" "i1" "scenario" "risposta"
Conservo solo le colonne scenario e risposta
> soggetti <- soggettiEsteso[, c(10, 11)]> summary(soggetti)

.. IL FRAMINGEFFECTNELLA SCELTADI UN PACCHETTOTURISTICO: UNESPERIMENTOONLINE
scenario rispostagain:243 completa:249loss:217 mezza :211
> freqScenario <- table(soggetti$risposta, soggetti$scenario)> freqScenario
gain losscompleta 152 97mezza 91 120
Disegno il grafico
> mosaicplot(freqScenario)
freqScenario
completa mezza
gain
loss
Figura .: Mosaicplot: frequenza dellerisposte in base allo scenario.
Calcolo il χ2
> chisqDecisione <- chisq.test(soggetti$risposta, soggetti$scenario)> chisqDecisione
Pearson's Chi-squared test with Yates' continuity correction
data: soggetti$risposta and soggetti$scenarioX-squared = 14.0016, df = 1, p-value = 0.0001827
Leggere l'output La statistica risulta significativa: χ2(df = 1) = 14.0, p < 0.001.Dal test del χ2 si evince e vi è un'influenza statisticamente significativa dello scenarionella scelta da parte dei partecipanti.

CAPITOLO . CASI DI STUDIO
.. Conclusioni
Viene definito ``effeo framing`` l'influenza della modalità di presentazione delle al-ternative in un compito di decisione. Nel nostro esperimento due differenti modalitàdi presentazione della stessa offerta influenzano significativamente la scelta dei parteci-panti.
I risultati confermano la solidità del framing effect nel condizionare le scelte deipartecipanti, ane nell'ambito di scelta di un paceo turistico-alberghiero.
L'esperimento soolinea inoltre l'efficacia del web come strumento per lo sviluppodi esperimenti e per la raccolta di partecipanti in ambiti di ricerca quali la psicologiadelle decisioni.
. Depressioneesto dataframe rappresenta i risultati di un questionario, somministrato on line: in-ventario di depressione neuropsy.it Ai partecipanti veniva iesto di:
� rispondere preliminarmente ad una domanda, su scala liert: quanto sei depresso,ora?
� rispondere ad una lista di sintomi della depressione, sempre su scala liert:per nulla - moltissimo
� circa metà dei partecipanti ha ane risposto al Be depression inventory.
Carico il dataframe
> rm(list = ls(all = TRUE))> soggettiTutti <- read.table("depressione.txt", header = TRUE, sep = ",")> dim(soggettiTutti)
[1] 500 8
> summary(soggettiTutti)
condizione sex age scol depressOK :452 f:307 Min. : 14.0 Min. : 5.00 Min. :0.000Prova: 48 m:187 1st Qu.: 25.0 1st Qu.:13.00 1st Qu.:2.000
x: 6 Median : 33.0 Median :13.00 Median :2.000Mean : 651.6 Mean :13.53 Mean :2.4263rd Qu.: 44.0 3rd Qu.:18.00 3rd Qu.:3.000Max. :9999.0 Max. :18.00 Max. :5.000
beck omessi sommaMin. :-1.00 Min. : 0.000 Min. : 0.01st Qu.:-1.00 1st Qu.: 0.000 1st Qu.:248.0Median :-1.00 Median : 0.000 Median :354.0Mean :11.37 Mean : 4.656 Mean :339.43rd Qu.:24.00 3rd Qu.: 1.000 3rd Qu.:442.2Max. :97.00 Max. :170.000 Max. :676.0

.. CONFRONTO FRA VARIABILI AD INTERVALLI
Filtro i partecipanti Tolgo i partecipanti con più di omissioni
> soggetti2 <- soggettiTutti[soggettiTutti$omessi < 20, ]> dim(soggetti2)
[1] 474 8
Tolgo i partecipanti non sperimentali
> soggetti3 <- soggetti2[soggetti2$condizione == "OK", ]> dim(soggetti3)
[1] 431 8
Assegno correamente i valori di missing dell'età
> soggetti3$age[soggetti3$age == 9999] <- NA> soggetti3 <- soggetti3[soggetti3$beck <= 63, ]> dim(soggetti3)
[1] 428 8
Assegno i missing del Be Inventory, e creo un nuovo dataframe, e include solo ipartecipanti e hanno fao ane il questionario di Be
> soggetti3$beck[soggetti3$beck == -1] <- NA> soggetti3$sex[soggetti3$sex == "x"] <- NA> soggetti3$sex <- factor(soggetti3$sex)> beck_fatto <- !is.na(soggetti3$beck)> soggetti_beck <- soggetti3[beck_fatto, ]> dim(soggetti_beck)
[1] 208 8
. Confronto fra variabili ad intervalli
.. Disegno i grafici delle variabili
Disegno alcuni grafici per studiare la distribuzione dei punteggi al Be inventory (be)e al questionario sulla depressione (somma).
Inoltre, araverso il test di Kolmogorov-Smirnov e il test di Shapiro-Wilk , valuto lanormalità delle distribuzioni.
> par(mfrow = c(2, 2))> boxplot(soggetti_beck$beck)> qqnorm(soggetti_beck$beck)> qqline(soggetti_beck$beck, col = 2)> boxplot(soggetti_beck$somma)

CAPITOLO . CASI DI STUDIO
> qqnorm(soggetti_beck$somma)> qqline(soggetti_beck$somma, col = 2)> ks.test(soggetti_beck$beck, "pnorm", mean = mean(soggetti_beck$beck),+ sd = sd(soggetti_beck$beck))
One-sample Kolmogorov-Smirnov test
data: soggetti_beck$beckD = 0.0588, p-value = 0.4689alternative hypothesis: two-sided
> ks.test(soggetti_beck$somma, "pnorm", mean = mean(soggetti_beck$somma),+ sd = sd(soggetti_beck$somma))
One-sample Kolmogorov-Smirnov test
data: soggetti_beck$sommaD = 0.076, p-value = 0.1808alternative hypothesis: two-sided
> shapiro.test(soggetti_beck$beck)
Shapiro-Wilk normality test
data: soggetti_beck$beckW = 0.9863, p-value = 0.04184
> shapiro.test(soggetti_beck$somma)
Shapiro-Wilk normality test
data: soggetti_beck$sommaW = 0.9777, p-value = 0.002185
Il test Kolmogorov-Smirnov risulta non significativo su entrambe le variabili (e dun-que, l'ipotesi nulla di normalità delle distribuzioni non viene rifiutata). Il test Shapiro-Wilk, però, risulta significativo su entrambe le variabili.
I due test valutano la normalità araverso algoritmi differenti, e dunque non è pur-troppo insolito oenere risultati differenti sulla stessa variabile.
.. Correlazione
Disegno il grafico della relazione fra le due variabili, e disegno la linea di regressionelineare.
Decido inoltre di usare il test Harvey-Collier per valutare la linearità del modello

.. CONFRONTO FRA VARIABILI AD INTERVALLI
010
3050
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
−3 −2 −1 0 1 2 3
010
3050
Normal Q−Q Plot
Theoretical QuantilesS
ampl
e Q
uant
iles
020
040
060
0
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
−3 −2 −1 0 1 2 3
020
040
060
0
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Figura .: ---
> par(mfrow = c(1, 2))> plot(soggetti_beck$somma, soggetti_beck$beck)> lmBeck <- lm(soggetti_beck$beck ~ soggetti_beck$somma)> abline(lmBeck)> library(lmtest)> harvtest(soggetti_beck$beck ~ soggetti_beck$somma, order.by = ~soggetti_beck$somma)
Harvey-Collier test
data: soggetti_beck$beck ~ soggetti_beck$sommaHC = 5.6503, df = 205, p-value = 5.311e-08
> cor.test(soggetti_beck$somma, soggetti_beck$beck, method = "pearson")
Pearson's product-moment correlation
data: soggetti_beck$somma and soggetti_beck$beckt = 19.2223, df = 206, p-value < 2.2e-16alternative hypothesis: true correlation is not equal to 095 percent confidence interval:0.7466245 0.8451883sample estimates:
cor0.8012785
Creo il grafico dei residui, e con lines(smooth.spline()) cerco di capire l'andamentodei residui. Apparentemente, la non linearità è dovuta ad un outlier, e identifico conla funzione whi.
> plot(lmBeck$fitted.values, lmBeck$residuals)> lines(smooth.spline(lmBeck$fitted.values, lmBeck$residuals),

CAPITOLO . CASI DI STUDIO
+ col = "red", lwd = 2)> soggetti_beck[which(soggetti_beck$somma < 5), ]
condizione sex age scol depress beck omessi somma151 OK m 52 18 0 48 0 0
Il modello dunque non è lineare. Probabilmente, eliminando l'outlier (un parteci-pante con punteggio all'inventario neuropsy e al Be Inventory), potrei correggerela non linearità della relazione.
In ogni caso, decido di calcolare il coefficiente di Spearman
> cor.test(soggetti_beck$somma, soggetti_beck$beck, method = "spearman")
Spearman's rank correlation rho
data: soggetti_beck$somma and soggetti_beck$beckS = 282990.3, p-value < 2.2e-16alternative hypothesis: true rho is not equal to 0sample estimates:
rho0.8113126
Figura .: ---
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
0 200 400 600
010
2030
4050
soggetti_beck$somma
sogg
etti_
beck
$bec
k
● ●
●
●
●
●
●●
●● ●
●
●
●
●
●
●
●
●●
●
● ● ●
●
●
●
●
●●
●
●
●
●
●
●
●
●
● ●
●
●
● ●
●
●
●
●
●
●●
●●
●●
●
●
●● ●
●
● ●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●
●
●●
●●●
●
●
●●
●●
●
●
●
●
●
●
● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
● ●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
0 10 20 30 40
−20
−10
010
2030
4050
lmBeck$fitted.values
lmB
eck$
resi
dual
s
.. Conclusioni
In questa sezione ho confrontato due variabili numerie. Il test parametrico d'elezioneè il test di correlazione di Pearson. In questo caso, però, non siamo sicuri e gli assuntisiano rispeati:
� Dal test Kolmogorov-Smirnov non appare violato l'assunto di normalità delle va-riabili. I risultati del test Shapiro-Wilk, però, sono diversi, e rifiutano l'ipotesi dinormalità delle variabili.

.. DIFFERENZA FRA MASCHI E FEMMINE
� Il test Harvey-Collier, e valuta la linearità del rapporto fra le due variabili, risultasignificativo. Va dunque rifiutata l'ipotesi nulla della linearità della relazione.
Formalmente, dunque, non sarebbe possibile applicare la correlazione di Pearson, e nem-meno il modello di correlazione lineare. Dall'analisi grafica dei grafici di dispersione edel qqplot, però, possiamo dire e né la violazione di normalità, né quella di linearitàappaiono estremamente gravi. In questi casi, una regola informale può essere quelladi applicare sia il test parametrico e quello non parametrico, e confrontare i risultati:se sono molto simili, come nel nostro caso, possiamo ragionevolmente assumere e irisultati inferenziali siano piuosto solidi.
. Differenza fra masi e femmineSono interessato a capire se il punteggio medio, nell'inventario neuropsy, è diverso frasoggei masi e femmine.
> boxplot(soggetti3$somma ~ soggetti3$sex)> tapply(X = soggetti3$somma, INDEX = soggetti3$sex, FUN = mean)
f m363.3948 325.7792
.. Test non parametrico
Come abbiamo visto, i risultati dei test sulla normalità danno pareri discordanti. An-e in questo caso potrebbe aver senso applicare sia il test parametrico e quello nonparametrico. Per motivi didaici, mostriamo l'applicazione del test non parametricoWilcoxon rank sum test
> wilcox.test(soggetti3$somma[soggetti3$sex == "m"], soggetti3$somma[soggetti3$sex ==+ "f"])
Wilcoxon rank sum test with continuity correction
data: soggetti3$somma[soggetti3$sex == "m"] and soggetti3$somma[soggetti3$sex == "f"]W = 17840, p-value = 0.0129alternative hypothesis: true location shift is not equal to 0
Poié il p-value risulta pari a ., la differenza risulta significativa per un α =0.05, ma non per un α = 0.01.
. estionario parole-non paroleIn questo questionario, somministrato on line, al partecipante venivano elencate parole, di cui parole vere, ma non comuni, e non parole legali.
adamantino affioragliare apologetico approprinquare aramenatoarduttuante aristofanio betabloccante brezzatura caldramo cardamomo
CAPITOLO . CASI DI STUDIO
Figura .: ---
f m
010
020
030
040
050
060
070
0
cariatide cariogenesi carsi cemblatore cologaria condroma cresticocretizzare cuspico elare epifita epilemma esagettato esatico fioganglio iatrogeno iconoclasta incorsarsi inflame intonso inusitatomantardica miscellaneo patofobia pianosequenza ralingare revocianterisura rogito scolta scorporo scutoso specile stuello tessurgiatrasfogenico vellizzante
.. Filtro i dati
In primo luogo, creo un dataframe con le sole colonne e mi interessano.
> rm(list = ls(all = TRUE))> soggettiEsteso <- read.table("nonparole.txt", header = TRUE,+ sep = "\t")> soggettiTutti <- soggettiEsteso[, c(1, 3, 4, 5, 6, 7, 8, 9)]> summary(soggettiTutti)
sogg sex age scolMin. : 1.0 - :188 - :188 - :1881st Qu.:458.8 femmina:210 22 : 19 13_diploma :176Median :589.5 maschio:123 24 : 19 16_laureabreve: 27Mean :581.4 null : 3 26 : 18 18_laurea :1043rd Qu.:720.2 30 : 18 5_elem : 1Max. :851.0 23 : 17 8_medie : 21
(Other):245 NA's : 7prof web risposte giuste
- :188 - :188 Min. : 0.00 Min. : 0.00XX : 92 01: 53 1st Qu.:48.00 1st Qu.:29.00studente : 33 12: 56 Median :49.00 Median :34.00studentessa: 24 35:227 Mean :45.91 Mean :32.12

.. QUESTIONARIO PAROLE-NON PAROLE
impiegata : 20 3rd Qu.:49.00 3rd Qu.:37.00impiegato : 16 Max. :49.00 Max. :48.00(Other) :151
> dim(soggettiTutti)
[1] 524 8
Escludo i partecipanti e hanno risposto a meno di domande.
> soggetti <- soggettiTutti[soggettiTutti$risposte > 40, ]> dim(soggetti)
[1] 477 8
Assegno i missing, e li filtro dal dataframe
> soggetti$web[soggetti$web == "-"] <- NA> soggetti <- soggetti[!is.na(soggetti$web), ]> dim(soggetti)
[1] 310 8
> soggetti$sex[soggetti$sex == "null"] <- NA> soggetti <- soggetti[!is.na(soggetti$sex), ]> dim(soggetti)
[1] 308 8
> soggetti$sex <- factor(soggetti$sex)> dim(soggetti)
[1] 308 8
> soggetti$scol[soggetti$scol == "-"] <- NA> soggetti$scol[soggetti$scol == "5_elem"] <- NA> soggetti <- soggetti[!is.na(soggetti$scol), ]> soggetti$scol <- factor(soggetti$scol, ordered = TRUE)> summary(soggetti)
sogg sex age scolMin. : 1.0 femmina:191 22 : 18 13_diploma :1621st Qu.:410.0 maschio:110 24 : 18 16_laureabreve: 27Median :489.0 26 : 18 18_laurea : 92Mean :478.8 23 : 17 8_medie : 203rd Qu.:574.0 25 : 16Max. :663.0 30 : 16
(Other):198prof web risposte giuste

CAPITOLO . CASI DI STUDIO
XX : 75 - : 0 Min. :41.00 Min. :19.00studente : 31 01: 44 1st Qu.:49.00 1st Qu.:32.00studentessa: 23 12: 48 Median :49.00 Median :35.00impiegata : 19 35:209 Mean :48.56 Mean :34.23impiegato : 14 3rd Qu.:49.00 3rd Qu.:38.00insegnante : 8 Max. :49.00 Max. :48.00(Other) :131
Misuro la normalità della distribuzione della variabile giuste (numero di risposte corret-te). Dal test di Shapiro-Wilk devo rifiutare l'ipotesi nulla di normalità della distribuzionedella variabile.
> shapiro.test(soggetti$giuste)
Shapiro-Wilk normality test
data: soggetti$giusteW = 0.9823, p-value = 0.00091
.. Rapporto fra scolarità e media di risposte corrette
Disegno i grafici della distribuzione
> par(mfrow = c(2, 2))> hist(soggetti$giuste)> qqnorm(soggetti$giuste)> qqline(soggetti$giuste)> boxplot(soggetti$giuste ~ soggetti$scol)> boxplot(soggetti$giuste ~ soggetti$sex)
Figura .: ---
Histogram of soggetti$giuste
soggetti$giuste
Fre
quen
cy
15 25 35 45
020
6010
0
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●●
●●
●
●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●●
●●
●●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●●
●
●●
●
●
●
●
●●
●●
●●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●●●
●●
●
●●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●●●
●
●●
●●
●
●
●●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●●●
●
●●
●●
●
●●
−3 −2 −1 0 1 2 3
2030
40
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
●
●●
●
●
13_diploma 18_laurea
2030
40
●
●●
●
●●●
femmina maschio
2030
40

.. QUESTIONARIO PAROLE-NON PAROLE
Alcune prove grafie
Proviamo a giocare con la funzione stripchart(), aggiungendo delle linee orizzontalicorrispondenti alle medie dei gruppi.
> stripchart(giuste ~ scol, method = "jitter", jitter = 0.2, main = "Giuste per scolarità",+ vertical = TRUE, log = "y", data = soggetti)> lines(c(0.7, 1.3), rep(mean(soggetti$giuste[soggetti$scol ==+ "13_diploma"]), 2), col = "red", lwd = 2)> lines(c(1.7, 2.3), rep(mean(soggetti$giuste[soggetti$scol ==+ "16_laureabreve"]), 2), col = "red", lwd = 2)> lines(c(2.7, 3.3), rep(mean(soggetti$giuste[soggetti$scol ==+ "18_laurea"]), 2), col = "red", lwd = 2)> lines(c(3.7, 4.3), rep(mean(soggetti$giuste[soggetti$scol ==+ "8_medie"]), 2), col = "red", lwd = 2)
13_diploma 16_laureabreve 18_laurea 8_medie
2025
3035
4045
Giuste per scolarità
gius
te
Figura .: ---
Confronto fra grafici diversi
Proviamo a sovrapporre tipologie di grafici diversi. Con tabulate creo una tabella con lefrequenze dei valori osservati.
> tabulate(soggetti$giuste)
[1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 4 3 1 3[26] 8 6 12 7 14 13 26 19 28 25 27 24 27 16 11 8 8 4 1 2 0 0 1
Sovrappongo l'istogramma al plot della tabella delle frequenze (in rosso) al plot dellafunzione density() (in verde).
> frequenze <- tabulate(soggetti$giuste)/length(soggetti$giuste)> hist(soggetti$giuste, probability = TRUE, ylim = c(0, max(frequenze)))> lines(frequenze, col = 2)> lines(density(soggetti$giuste), col = 3)

CAPITOLO . CASI DI STUDIO
Test non parametrico di Kruskal-Wallis
Poié la distribuzione della variabile dipendente (giuste) non è normale, e la numerositàdei campioni è differente, non è opportuno utilizzare l'analisi della varianza parametrica,ma la sua variante non parametrica.
> kruskal.test(giuste ~ scol, data = soggetti)
Kruskal-Wallis rank sum test
data: giuste by scolKruskal-Wallis chi-squared = 25.872, df = 3, p-value = 1.014e-05
Leggere l'output Abbiamo confrontato la media di punteggi correi dei partecipanti,divisi in base alla scolarità diiarata. Dalla somministrazione del test non parametri-co Kruskal-Wallis rank sum test emerge e la differenza fra le medie è significativa:Kruskal-Wallis i-squared (df = ) = ., p < 0.001. Possiamo dunque rifiutare l'i-potesi nulla (e assume e le differenze fra le medie siano da aribuire al caso, ovveroe la differenza non sia significativa) ed acceare l'ipotesi alternativa: vi è una relazionesignificativa fra la scolarità dei partecipanti ed il punteggio medio di risposte corree.
Figura .: ---
Histogram of soggetti$giuste
soggetti$giuste
Den
sity
15 20 25 30 35 40 45 50
0.00
0.02
0.04
0.06
0.08
.. Confronto per genere
Ane in questo caso, valutiamo se la media del numero di risposte corree è diversafra masi e femmine.
In primo luogo, verifiiamo e la varianza dei due gruppi non sia differente.
> var.test(soggetti$giuste[soggetti$sex == "maschio"], soggetti$giuste[soggetti$sex ==+ "femmina"])

.. QUESTIONARIO PAROLE-NON PAROLE
F test to compare two variances
data: soggetti$giuste[soggetti$sex == "maschio"] and soggetti$giuste[soggetti$sex == "femmina"]F = 0.8176, num df = 109, denom df = 190, p-value = 0.2476alternative hypothesis: true ratio of variances is not equal to 195 percent confidence interval:0.5896565 1.1511707sample estimates:ratio of variances
0.8175957
In questo caso, sebbene la distribuzione della variabile indipendente non sia normale,in leeratura si assume e possa essere utilizzato il test parametrico quando:
� la non normalità della distribuzione non sia particolarmente pronunciata
� vi sia un buon numero di osservazioni per ogni gruppo.
Appliiamo dunque il t-test.
> t.test(soggetti$giuste[soggetti$sex == "maschio"], soggetti$giuste[soggetti$sex ==+ "femmina"])
Welch Two Sample t-test
data: soggetti$giuste[soggetti$sex == "maschio"] and soggetti$giuste[soggetti$sex == "femmina"]t = 1.2965, df = 246.482, p-value = 0.1960alternative hypothesis: true difference in means is not equal to 095 percent confidence interval:-0.3805035 1.8460913sample estimates:mean of x mean of y34.69091 33.95812
L'applicazione del test non parametrico di Wilcoxon da risultati paragonabili?
> wilcox.test(soggetti$giuste[soggetti$sex == "maschio"], soggetti$giuste[soggetti$sex ==+ "femmina"])
Wilcoxon rank sum test with continuity correction
data: soggetti$giuste[soggetti$sex == "maschio"] and soggetti$giuste[soggetti$sex == "femmina"]W = 11492.5, p-value = 0.1736alternative hypothesis: true location shift is not equal to 0
In entrambi i casi, non possiamo rifiutare l'ipotesi nulla (in quanto in entrambi i casi p >0.1. La differenza di punteggio fra masi e femmine non è statisticamente significativa.

CAPITOLO . CASI DI STUDIO
. Il problema della violazione degli assunti
ello della violazione degli assunti di normalità della distribuzione e di omogeneitàdelle varianze è un problema molto delicato, soprauo nell'ambito della psicologiasperimentale.
Alcuni studi metodologici, infai, hanno rivelato come:
� l'utilizzo di test parametrici, quali il t-test, la regressione lineare e l'analisi dellavarianza, siano usati estesamente nell'ambito della psicologia sperimentale;
� ciononostante, raramente gli assunti di normalità e di omogeneità della varianzasono rispeati:
– la distribuzione tende spesso ad assumere una forma diversa da quella nor-male
– il rapporto fra varianze, e dovrebbe essere pari ad : in caso di uguaglian-za, arriva ad essere superiore ad : in molti casi.
I test parametrici, dunque, sono spesso applicati nonostante vengano violati gli assuntidi normalità della distribuzione e di omogeneità della varianza.
Il problema e emerge nell'applicare le classie statistie parametrie in viola-zione agli assunti è e il p-valuee si oiene può non essere correo, risultando a voltesovrastimato (e dunque non rifiutando l'ipotesi nulla, commeendo un errore di tipo II),altre volte soostimato (rifiutando erroneamente l'ipotesi nulla, e dunque commeendoun errore di tipo I).
Purtroppo, non è sempre iaro quando la statistica risulta robusta nonostante laviolazione degli assunti, e quando no. Vi sono, in genere, posizioni molto permissivein merito alla possibilità di applicare i test parametrici nonostante la violazione degliassunti.
In genere, ad esempio, si assume e, se la numerosità delle osservazioni per gruppoè alta, e il numero di osservazioni fra i vari gruppi è simile, la statistica rimane robustaane in violazione dell'assunto di normalità.
Un'altra regola empirica e viene spesso utilizzata recita e, se il rapporto fra la va-rianze dei gruppi non supera il rapporto :, è possibile comunque assumere l'omogeneitàdelle varianze.
Altri autori, però, tendono ad essere molto più prudenti, in quanto vi sono ricer-e e confermano e la violazione degli assunti può portare ad errori nel calcolo delp-value e degli intervalli di confidenza piuosto notevoli. Più in particolare, la con-temporanea violazione dell'assunto di normalità e di quello di uniformità della varianzatende ad avere effei deleteri sulla correezza dei risultati.
.. Possibili soluzioni
Test non parametrici
Una possibile soluzione al problema è, come abbiamo visto, quella di usare la contropar-te non parametrica dei test parametrici. esto approccio, però, non è completamente

.. IL PROBLEMA DELLA VIOLAZIONE DEGLI ASSUNTI
soddisfacente, in quanto implica la trasformazione dei punteggi grezzi in ranking, rinun-ciando pertanto a parte dell'informazione. In secondo luogo, i metodi non parametricinon sono adeguati ai disegni sperimentali faoriali (ad esempio, l'analisi della varianzaa due vie). Infine, in presenza di eterosedasticità, ane questi test tendono a perdereaffidabilità.
Trasformazione delle variabili
Un secondo approccio consiste nell'applicare alle variabili e violano l'assunto di nor-malità delle trasformazioni, di tipo non lineare, capaci di modificare la curva e renderladi nuovo normale.
Fra le trasformazioni più note, vanno ricordate la trasformazione in base al logaritmonaturale, la radice quadrata o l'elevazione a potenza.
Ane questo approccio ha però dei limiti:
� non è noto a priori quale trasformazione applicare, e con quali parametri
� non è deoe vi sia una trasformazione capace di rendre normale la distribuzioneosservata
� tendono a non aver effeo sugli outliers
� in caso di contemporanea violazione dell'assunto di normalità e di quello di omo-geneità delle variabili, la trasformazione, ane se capace di rendere normale ladistribuzione, non garantisce una miglior stima del p-value.
Ciononostante, questo approccio è utile quando non vi sia eterosedasticità (ovvero,quando vi sia omogeneità delle varianze), se dalla trasformazione si riesce ad oenereuna distribuzione di tipo normale.
Trimming e Winsorized Variance
Il Trimming e laWinsorized Variance sonometodi finalizzati a gestire gli outliers, ovveroquelle osservazioni e si discostano fortemente dalle altre Keselman et al. ().
Il trimming consiste nell'eliminare le code alte e basse delle osservazioni. Ad esem-pio, togliere il % di osservazioni più basse ed il % di osservazioni più alte.
La Winsorized Variance è una procedura simile. In questo caso, però, i valori elimi-nati vengono rimpiazzati con il valore più basso (per la coda inferiore) e quello più alto(per la coda superiore) rimanente.
este operazioni, eliminando gli outliers, tendono a rendere più robusta la tecnicaparametrica.
Permutazioni, simulazioni Monte Carlo, Bootstrapping
Infine, per calcolare parametri, stime dell'errore e intervalli di confidenza, può essereopportuno applicare delle tecniee, generando uno spazio campionario a partire dalleosservazioni disponibili, permeono una stima dei parametri a partire da questo spazio.

CAPITOLO . CASI DI STUDIO
Ane questa tecnica si è dimostrata efficace nel rendere più robusta l'inferenza sta-tistica in caso di violazione della normalità e dell'omogeneità della varianza dei dati(Keselman et al., ).
. Calcolo su dati artificiali
Concludiamo i nostri esercizi con due esempi creati artificialmente.
.. Correlazione
> x <- rnorm(200, 25, 5)> y1 <- x[1:100] * 1.2 + rnorm(100, 0, 2) + 5> y2 <- x[101:200] * 0.7 + rnorm(100, 0, 2)> y <- c(y1, y2)> gruppo <- gl(2, 100, labels = c("neri", "rossi"))> plot(x, y, col = gruppo)> abline(lm(y[gruppo == "neri"] ~ x[gruppo == "neri"]))> abline(lm(y[gruppo == "rossi"] ~ x[gruppo == "rossi"]))
Figura .: ---
●
●
●●
●
●
●●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●●
●
●
●
●
●
● ●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
● ●
●
●
●
●●
●
●
●●
●●●
●
●
●
●●
●●
●
●
●
●●
● ●●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
● ●
● ●
●
●
●
●
●
●● ●
●
● ●
15 20 25 30 35 40
1020
3040
x
y
.. Analisi della varianza a due vie
> base <- 34> d1 <- 0> d2 <- 12> d3 <- 9> dA <- 0> dB <- 10> A1 <- rnorm(30, base + d1 + dA, 6)

.. CALCOLO SU DATI ARTIFICIALI
> A2 <- rnorm(30, base + d2 + dA, 6)> A3 <- rnorm(30, base + d3 + dA, 6)> B1 <- rnorm(30, base + d1 + dB, 6)> B2 <- rnorm(30, base + d2 + dB, 6)> B3 <- rnorm(30, base + d3 + dB - 12, 6)> ind1 <- gl(3, 30, length = 180, labels = c("uno", "due", "tre"))> ind2 <- gl(2, 90, labels = c("A", "B"))> dip <- c(A1, A2, A3, B1, B2, B3)> esempio5 <- data.frame(ind1, ind2, dip)> remove(ind1, ind2, dip)
Calcolo l'analisi della varianza a due vie.
> aovEsempio5 <- aov(dip ~ ind1 + ind2 + ind1:ind2, data = esempio5)> summary(aovEsempio5)
Df Sum Sq Mean Sq F value Pr(>F)ind1 2 4182.5 2091.25 54.254 < 2.2e-16 ***ind2 1 1191.5 1191.46 30.910 1.001e-07 ***ind1:ind2 2 2496.2 1248.10 32.380 1.110e-12 ***Residuals 174 6707.0 38.55---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Che cosa posso concludere, da questi dati? Verifico la distribuzione normale dell'errore
> shapiro.test(aovEsempio5$residuals) \index{Assunti!normalità}
Shapiro-Wilk normality test
data: aovEsempio5$residualsW = 0.988, p-value = 0.1289
Verifico l'omogeneità delle varianze
> bartlett.test(dip ~ ind1 + ind2 + ind1:ind2, data = esempio5)
Bartlett test of homogeneity of variances
data: dip by ind1 by ind2Bartlett's K-squared = 5.2645, df = 2, p-value = 0.07192
Applico i confronti multipli,
> hsdEsempio5 <- TukeyHSD(aovEsempio5, ordered = TRUE)> par(mfrow = c(1, 1))> interaction.plot(esempio5$ind1, esempio5$ind2, esempio5$dip)
hsdEsempio5

CAPITOLO . CASI DI STUDIO
Figura .: ---
3540
4550
55
esempio5$ind1
mea
n of
ese
mpi
o5$d
ip
uno due tre
esempio5$ind2
AB
Tukey multiple comparisons of means95% family-wise confidence levelfactor levels have been ordered
Fit: aov(formula = dip ~ ind1 + ind2 + ind1:ind2, data = esempio5)
$ind1diff lwr upr p adj
tre-uno 2.680070 0.09378747 5.266352 0.0403294due-uno 10.942063 8.35578071 13.528345 0.0000000due-tre 8.261993 5.67571094 10.848276 0.0000000
$ind2diff lwr upr p adj
B-A 5.389939 3.626857 7.153021 0
$`ind1:ind2`diff lwr upr p adj
tre:B-uno:A 6.331621 1.8729119 10.790329 0.0009121tre:A-uno:A 9.987382 5.5286729 14.446090 0.0000000uno:B-uno:A 10.958863 6.5001540 15.417571 0.0000000due:A-uno:A 11.988137 7.5294279 16.446845 0.0000000due:B-uno:A 20.854852 16.3961433 25.313561 0.0000000tre:A-tre:B 3.655761 -0.8029477 8.114470 0.1753317uno:B-tre:B 4.627242 0.1685333 9.085951 0.0369705due:A-tre:B 5.656516 1.1978073 10.115225 0.0045114due:B-tre:B 14.523231 10.0645227 18.981940 0.0000000uno:B-tre:A 0.971481 -3.4872277 5.430190 0.9888173due:A-tre:A 2.000755 -2.4579537 6.459464 0.7884944
.. CALCOLO SU DATI ARTIFICIALI
due:B-tre:A 10.867470 6.4087617 15.326179 0.0000000due:A-uno:B 1.029274 -3.4294347 5.487983 0.9854644due:B-uno:B 9.895989 5.4372806 14.354698 0.0000000due:B-due:A 8.866715 4.4080067 13.325424 0.0000006
> plot(hsdEsempio5)> abline(v = 0, col = "red")
0 2 4 6 8 10 12 14
due−
tre
due−
uno
tre−
uno
95% family−wise confidence level
Differences in mean levels of ind1 Figura .: ---

CAPITOLO . CASI DI STUDIO

Appendice A
Primi passi con R
Descriviamo, brevemente, alcuni concei basilari di R. Per una visione più esaustiva,rimandiamo a Muggeo and Ferrara (); Mineo ()
A. Scaricare e avviare R
A.. Scaricare R
R è un soware free ed open source, e può essere liberamente scaricato dal sitoR è disponibile per piaaforme Windows, Mac, Linux.Nel sito di R sono disponibili numerosi manuali in formato pdf. La maggior parte in
Inglese, ma vi sono alcune risorse ane in Italiano.In ambiente Windows, una volta scaricato il soware è possibile avviare l'installa-
zione guidata.Una volta installato, a partire da Start è possibile avviare l'ambiente R, e vi meerà
a disposizione la riga di comando.R è un soware a riga di comando. esto significa e ogni istruzione viene
comunicata ad R araverso il prompt della riga di comando.Il prompt è rappresentato dal simbolo >.
A.. Usare R come una calcolatrice
Per iniziare a prendere confidenza con la riga di comando di R, è possibile cominciarea giocarci, provando le funzioni più elementari. La riga di comando, ad esempio, puòessere utilizzata per calcolare alcune semplici operazioni.
Operazioni aritmetie di base
Addizione, sorazione, moltiplicazione, divisione, elevazione a potenza
> 7 + 4
[1] 11

APPENDICE A. PRIMI PASSI CON R
> 13 - 5
[1] 8
> 7 * 7
[1] 49
> 12/3
[1] 4
> 2^3
[1] 8
> 3^2 + (7 - 2) * 3
[1] 24
A.. Operazioni booleane
Finalizzate a confrontare due elementi. L'output di queste operazioni è di tipo booleano.Aenzione: == è l'operazione di confronto per valutare
> pippo <- 4> pluto <- 5> pippo == 4
[1] TRUE
> pluto == 4
[1] FALSE
> pippo < pluto
[1] TRUE
> pippo <= 4
[1] TRUE
> pippo < 4
[1] FALSE
> pippo != pluto
[1] TRUE

A.. SCARICARE E AVVIARE R
> giusto = TRUE> sbagliato = FALSE> giusto | sbagliato
[1] TRUE
> giusto & sbagliato
[1] FALSE
> (5 > 4) | (4 > 5)
[1] TRUE
> (5 > 4) & (4 > 5)
[1] FALSE
> (6 < 7) & (7 < 8)
[1] TRUE
> !sbagliato
[1] TRUE
> sbagliato & (pippo == 4)
[1] FALSE
Assegnazione di variabili
Implicitamente, abbiamo già visto come vengono assegnate le variabili. In R non è ne-cessario definire il tipo di variabile. Araverso l'assegnazione, sarà R a creare un tipoopportuno di variabile (o di oggeo).
> numero <- 5> etichetta <- "Antonio"> variabile1 <- 5.12> variabile2 <- 10/3> mode(numero)
[1] "numeric"
> mode(etichetta)
[1] "character"
> mode(variabile1)

APPENDICE A. PRIMI PASSI CON R
[1] "numeric"
> mode(variabile2)
[1] "numeric"
> variabile2
[1] 3.333333
> variabile2 <- 10 * 2> variabile2
[1] 20
> ls()
[1] "etichetta" "giusto" "numero" "pippo" "pluto"[6] "sbagliato" "variabile1" "variabile2" "x" "xm"
La funzione ls() mi permee di elencare tue le variabili (oggei) aualmente at-tivi nel framework. La funzione rm() rimuove un oggeo. Ad esempio, se iamorm(variabile) l'oggeo variabile sarà cancellato, e non più disponibile.
A. HelpSebbene sia opportuno conoscere a memoria le funzioni più importanti, è assolutamentenormale non ricordare tue le funzioni, tui i parametri.Dalla sezione documenti del sito di R si possono scaricare delle R Reference Card, ovverodelle raccolte, con breve spiegazioni, delle funzioni più importanti.
Inoltre, è opportuno imparare ad usare gli aiuti e l'ambiente R ci offre.
� help.start() # help generale
� help(nome) # help sulla funzione ``nome''
� ?nome # = a help(nome)
� apropos(nome) # elenca le funzioni e contengono ``nome''
� example(funzione) # mostra degli esempi dell'uso della funzione
� RSiteSear(kmeans) # cerca informazioni relative alla funzione ``kmeans'' suinternet.
> apropos("mean")
[1] "colMeans" "kmeans" "mean" "mean.data.frame"[5] "mean.Date" "mean.default" "mean.difftime" "mean.POSIXct"[9] "mean.POSIXlt" "rowMeans" "weighted.mean"

A.. FUNZIONI
> example(mean)
mean> x <- c(0:10, 50)
mean> xm <- mean(x)
mean> c(xm, mean(x, trim = 0.10))[1] 8.75 5.50
mean> mean(USArrests, trim = 0.2)Murder Assault UrbanPop Rape7.42 167.60 66.20 20.16
A. Funzioni
R mee a disposizione un enorme numero di funzioni. Inoltre, è possibile scaricare,installare e riiamare delle librerie esterne, e meono a disposizione altri insiemi difunzioni.
Eleniamo, di seguito, alcune funzioni e si utilizzano più spesso.
c() esta funzione permee di combinare una lista di argomenti in un veore.
> c(1, 7:9)
[1] 1 7 8 9
> c(1:5, 10, 11)
[1] 1 2 3 4 5 10 11
> c(1:5, 10.5, 11)
[1] 1.0 2.0 3.0 4.0 5.0 10.5 11.0
> c(1:5, 10.5, "next")
[1] "1" "2" "3" "4" "5" "10.5" "next"
Poié nell'ultimo comando, abbiamo mescolato numeri interi, numeri decimali e strin-ghe, R ha trasformato il veore in un veore di stringhe.
> serie1 <- c(1:10)> serie1
[1] 1 2 3 4 5 6 7 8 9 10
> serie1[4]

APPENDICE A. PRIMI PASSI CON R
[1] 4
> serie2 <- serie1 * 3 + 1> serie2
[1] 4 7 10 13 16 19 22 25 28 31
> serie2[3]
[1] 10
> serie2[5:7]
[1] 16 19 22
min, max, whi, length
> variabile1 <- c(2, 3, 6, 4, 8, 4, 1)> min(variabile1)
[1] 1
> max(variabile1)
[1] 8
> which(variabile1 == 4)
[1] 4 6
> which(variabile1 == max(variabile1))
[1] 5
> length(variabile1)
[1] 7
Generare delle sequenze
> seq(0, 1000, length = 11)
[1] 0 100 200 300 400 500 600 700 800 900 1000
> rep(2, times = 10)
[1] 2 2 2 2 2 2 2 2 2 2
> sequenza1 <- c(seq(0, 1000, length = 11), seq(1000, 0, length = 11))> sequenza1
[1] 0 100 200 300 400 500 600 700 800 900 1000 1000 900 800 700[16] 600 500 400 300 200 100 0
> plot(sequenza1)

A.. FUNZIONI
Ordinare un vettore: sort, order
> variabile1
[1] 2 3 6 4 8 4 1
> variabile2 <- c(3, 6, 7, 2, 4, 5, 1)> sort(variabile1)
[1] 1 2 3 4 4 6 8
> variabile1[order(variabile2)]
[1] 1 4 2 8 4 3 6
A.. Creare e manipolare matrici
> matrix(c(1, 2, 3, 11, 12, 13), nrow = 2, ncol = 3, byrow = TRUE)
[,1] [,2] [,3][1,] 1 2 3[2,] 11 12 13
> matrice1 <- matrix(seq(2, 20, length = 10), nrow = 2, ncol = 5,+ byrow = TRUE)> matrice1
[,1] [,2] [,3] [,4] [,5][1,] 2 4 6 8 10[2,] 12 14 16 18 20
> matrice2 <- matrix(seq(10, 55, length = 10), nrow = 2, ncol = 5,+ byrow = FALSE)> matrice2
[,1] [,2] [,3] [,4] [,5][1,] 10 20 30 40 50[2,] 15 25 35 45 55
> matrice1 + matrice2
[,1] [,2] [,3] [,4] [,5][1,] 12 24 36 48 60[2,] 27 39 51 63 75
> matrice1 - matrice2
[,1] [,2] [,3] [,4] [,5][1,] -8 -16 -24 -32 -40[2,] -3 -11 -19 -27 -35

APPENDICE A. PRIMI PASSI CON R
> matrice1/matrice2
[,1] [,2] [,3] [,4] [,5][1,] 0.2 0.20 0.2000000 0.2 0.2000000[2,] 0.8 0.56 0.4571429 0.4 0.3636364
> t(matrice1)
[,1] [,2][1,] 2 12[2,] 4 14[3,] 6 16[4,] 8 18[5,] 10 20
> matrice3 <- matrix(c(2, 3, 4, 3, 2, 6, 7, 8, 5, 9), nrow = 5,+ ncol = 2, byrow = TRUE)> matrice3
[,1] [,2][1,] 2 3[2,] 4 3[3,] 2 6[4,] 7 8[5,] 5 9
> t(matrice1) + matrice3
[,1] [,2][1,] 4 15[2,] 8 17[3,] 8 22[4,] 15 26[5,] 15 29
> matrice4 <- cbind(c(3, 3), c(4, 4), c(7, 7))> matrice4
[,1] [,2] [,3][1,] 3 4 7[2,] 3 4 7
> matrice5 <- rbind(c(3, 3), c(4, 4), c(7, 7))> matrice5
[,1] [,2][1,] 3 3[2,] 4 4[3,] 7 7

A.. FUNZIONI
> matrice4 == t(matrice5)
[,1] [,2] [,3][1,] TRUE TRUE TRUE[2,] TRUE TRUE TRUE
> dim(matrice1)
[1] 2 5
> dim(matrice4)
[1] 2 3
> matrice4[1:2, 1:2]
[,1] [,2][1,] 3 4[2,] 3 4
> matrice4[, 1:2]
[,1] [,2][1,] 3 4[2,] 3 4
> matrice1[1:2, 1:2]
[,1] [,2][1,] 2 4[2,] 12 14
> diag(matrice1[1:2, 1:2])
[1] 2 14
> diag(matrice1)
[1] 2 14
> matrice1[1:2, 3:4]
[,1] [,2][1,] 6 8[2,] 16 18
> diag(matrice1[1:2, 3:4])
[1] 6 18

APPENDICE A. PRIMI PASSI CON R
> as.vector(matrice4)
[1] 3 3 4 4 7 7
> as.vector(matrice5)
[1] 3 4 7 3 4 7
> array(1:24, dim = c(3, 4, 2))
, , 1
[,1] [,2] [,3] [,4][1,] 1 4 7 10[2,] 2 5 8 11[3,] 3 6 9 12
, , 2
[,1] [,2] [,3] [,4][1,] 13 16 19 22[2,] 14 17 20 23[3,] 15 18 21 24
A.. Filtri
> matrice1
[,1] [,2] [,3] [,4] [,5][1,] 2 4 6 8 10[2,] 12 14 16 18 20
> matrice1 > 6
[,1] [,2] [,3] [,4] [,5][1,] FALSE FALSE FALSE TRUE TRUE[2,] TRUE TRUE TRUE TRUE TRUE
> matrice4
[,1] [,2] [,3][1,] 3 4 7[2,] 3 4 7
> matrice4%%2 == 1
[,1] [,2] [,3][1,] TRUE FALSE TRUE[2,] TRUE FALSE TRUE

A.. FUNZIONI
A.. Data frames
> nome <- c("luigi", "mario", "antonella", "luca")> anno <- c(1956, 1945, 1972, 1976)> condizione <- c("exp", "controllo", "exp", "controllo")> soggetti <- data.frame(nome, anno, condizione)> soggetti
nome anno condizione1 luigi 1956 exp2 mario 1945 controllo3 antonella 1972 exp4 luca 1976 controllo
> soggetti$anno
[1] 1956 1945 1972 1976
> soggetti[, 3]
[1] exp controllo exp controlloLevels: controllo exp
> soggetti[3, ]
nome anno condizione3 antonella 1972 exp
> soggetti[3, 3]
[1] expLevels: controllo exp
A.. Liste
Le liste sono, appunto, liste di elementi o oggei fra loro differenti.
> lista1 <- list(matrix(10:18, nrow = 3), rep("ciao", 3), c("alto",+ "basso"))> lista1
[[1]][,1] [,2] [,3]
[1,] 10 13 16[2,] 11 14 17[3,] 12 15 18
[[2]][1] "ciao" "ciao" "ciao"
[[3]][1] "alto" "basso"

APPENDICE A. PRIMI PASSI CON R
> str(lista1)
List of 3$ : int [1:3, 1:3] 10 11 12 13 14 15 16 17 18$ : chr [1:3] "ciao" "ciao" "ciao"$ : chr [1:2] "alto" "basso"

A.. LE DISTRIBUZIONI TEORICHE
A. Le distribuzioni teorie
L'approccio parametrico all'analisi inferenziale si basa sul confronto delle statistie conle distribuzioni teorie. Per una panoramica completa sulle distribuzioni continue ediscrete, si vedano Seltman (); Wal ()
R mee a disposizione alcuni strumenti estremamente utili per lavorare con le piùimportanti distribuzioni. Più in particolare, data una distribuzione dist, R mee ge-neralmente a disposizione una famiglia di funzioni: rdist per generare dei numericasuali e rispeino quella distribuzione; ddist calcola la densità, pdist calcola laprobabilità, qdist calcola il quantile.
A.. La distribuzione normale
Iniziamo a giocare con la distribuzione normale. Come abbiamo visto nel corso delladispensa, per generare dei numeri casuali con distribuzione normale, si usa la funzionernorm. dnorm permee di calcolare la densità, e può essere utilizzata, ad esempio, perdisegnare il grafico della distribuzione.
> plotnorm <- function(mean = 0, sd = 1, val = NA, left = TRUE) {+ min <- mean - sd * 4+ max <- mean + sd * 4+ x <- seq(min, max, length = 200)+ y <- dnorm(x, mean = mean, sd = sd)+ plot(x, y, type = "l")+ if (!is.na(val)) {+ if (left == TRUE) {+ x <- seq(min, val, length = 200)+ }+ else {+ x <- seq(val, max, length = 200)+ }+ y <- dnorm(x, mean = mean, sd = sd)+ polygon(c(x[1], x, x[length(x)]), c(0, y, 0), col = "gray")+ if (left == TRUE) {+ prob <- round(pnorm(val, mean, sd), 3)+ }+ else {+ prob <- round(1 - pnorm(val, mean, sd), 3)+ }+ text(x[100], y[1], prob)+ }+ }> plotnorm(val = 2, left = FALSE)

APPENDICE A. PRIMI PASSI CON R
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
y
0.023
Figura A.: La distribuzione normale.L'area in grigio corrisponde all'area delladistribuzione superiore a .
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
y
0.023
Grazie alla funzione plotnorme abbiamo creato, possiamo disegnare la funzionenormale, e ritagliare l'area soostante un determinato valore. La funzione disegna lacurva, l'area, e calcola la superfice dell'area disegnata, e corrisponde alla probabilità.La funzione usa dnorm per calcolare l'altezza della curva in ogni punto, e pnorm percalcolare l'area associata al valore.
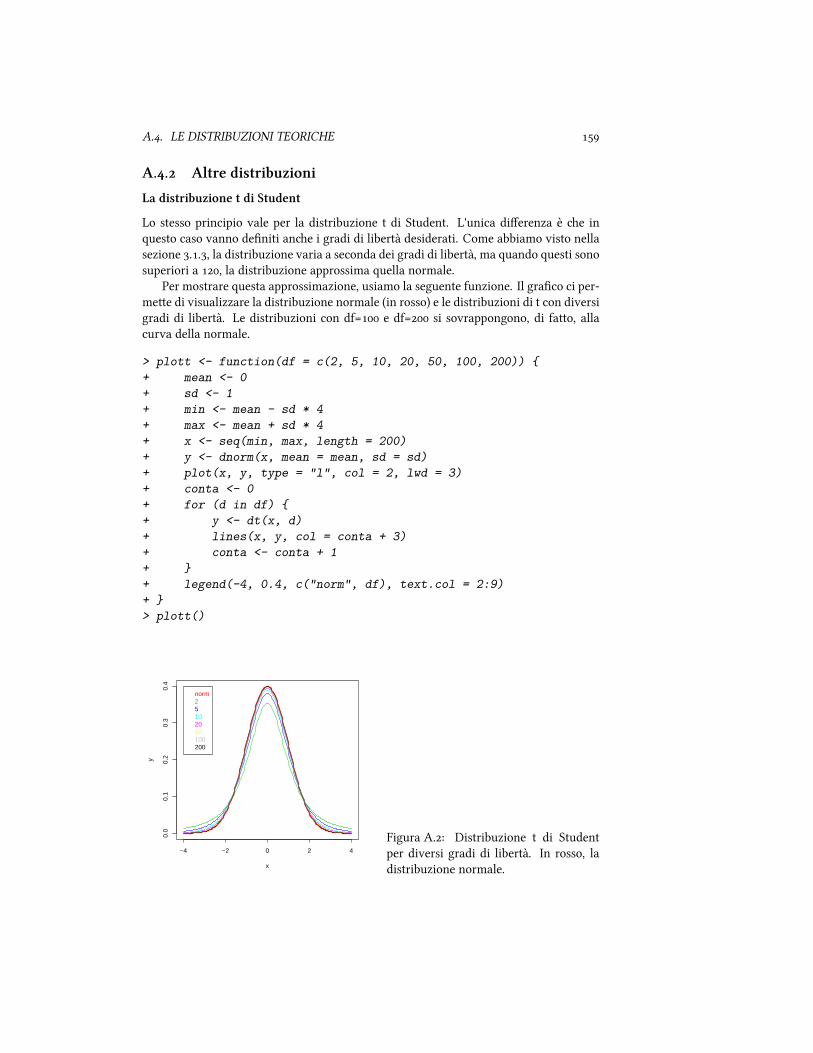
A.. LE DISTRIBUZIONI TEORICHE
A.. Altre distribuzioni
La distribuzione t di Student
Lo stesso principio vale per la distribuzione t di Student. L'unica differenza è e inquesto caso vanno definiti ane i gradi di libertà desiderati. Come abbiamo visto nellasezione .., la distribuzione varia a seconda dei gradi di libertà, ma quando questi sonosuperiori a , la distribuzione approssima quella normale.
Per mostrare questa approssimazione, usiamo la seguente funzione. Il grafico ci per-mee di visualizzare la distribuzione normale (in rosso) e le distribuzioni di t con diversigradi di libertà. Le distribuzioni con df= e df= si sovrappongono, di fao, allacurva della normale.
> plott <- function(df = c(2, 5, 10, 20, 50, 100, 200)) {+ mean <- 0+ sd <- 1+ min <- mean - sd * 4+ max <- mean + sd * 4+ x <- seq(min, max, length = 200)+ y <- dnorm(x, mean = mean, sd = sd)+ plot(x, y, type = "l", col = 2, lwd = 3)+ conta <- 0+ for (d in df) {+ y <- dt(x, d)+ lines(x, y, col = conta + 3)+ conta <- conta + 1+ }+ legend(-4, 0.4, c("norm", df), text.col = 2:9)+ }> plott()
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
y
norm25102050100200
Figura A.: Distribuzione t di Studentper diversi gradi di libertà. In rosso, ladistribuzione normale.

APPENDICE A. PRIMI PASSI CON R
La distribuzione chi2
Le funzioni standard sono disponibili ane per la distribuzione chi2: dchisq per ladensità, pchisq per la probabilità, qchisq per i quartili, rchisq per la generazione dinumeri casuali. Ane in questo caso vanno definiti i gradi di libertà. Per visualizzarel'help contestuale, digitate, come al solito, ?dchisq.
La distribuzione F
Infine, la distribuzione F: df, pf, qf, rf riiedono due valori per i gradi di libertà.

Appendice B
R: analisi descrittiva
B. Analisi descrittiveDescriviamo brevemente gli strumentie Rmee a disposizione per l'analisi descriiva,grafica e non grafica. Per una descrizione più deagliata, si vedano Frascati () eMaindonald ()
B.. Leggere un file di dati
In R, per leggere un file di dati possiamo usare la funzione read.table. Il parametro sep=�stabilisce e i valori sono separati dal tab.
> soggetti <- read.table("/home/bussolon/documenti/didattica/psicometria/R/parole_nonparole_mini.txt",+ header = TRUE, sep = "\t")
B.. Visualizzare il sommario
Il comando summary permee di visualizzare alcune informazioni di ognuna delle va-riabili della tabella (data.frame)
> summary(soggetti)
sex age scol webfemmina:210 Min. :20.00 05_elem : 1 Min. : 1.00maschio:123 1st Qu.:25.00 08_medie : 21 1st Qu.:12.00NA's : 3 Median :30.00 13_diploma :176 Median :35.00
Mean :33.48 16_laureabreve: 27 Mean :25.803rd Qu.:40.00 18_laurea :104 3rd Qu.:35.00Max. :68.00 NA's : 7 Max. :35.00
risposte giusteMin. : 4.00 Min. : 4.001st Qu.:48.00 1st Qu.:30.00Median :49.00 Median :34.00

APPENDICE B. R: ANALISI DESCRITTIVA
Mean :46.36 Mean :32.883rd Qu.:49.00 3rd Qu.:37.00Max. :49.00 Max. :48.00
B.. Variabili nominali
Genere
Possiamo calcolare la frequenza araverso la funzione table().
> freq_sex <- table(sex)> freq_sex
sexfemmina maschio
210 123
> freq_sex/sum(freq_sex)
sexfemmina maschio
0.6306306 0.3693694
> prop.table(freq_sex)
sexfemmina maschio
0.6306306 0.3693694
Grafici La funzione barplot mi permee di fare un grafico a barre.
> barplot(freq_sex)
pie è una funzione e permee di generare dei grafici a torta.
> pie(freq_sex)
> pareto.chart(freq_sex)
Pareto chart analysis for freq_sexFrequency Cum.Freq. Percentage Cum.Percent.
femmina 210 210 63.06306 63.06306maschio 123 333 36.93694 100.00000

B.. ANALISI DESCRITTIVE
femmina maschio
050
100
150
200
femmina
maschio
Calcolo della moda
> t_sex <- tabulate(sex)> mode_sex <- which(t_sex == max(t_sex))> mode_sex
[1] 1
> sex[mode_sex]
[1] femminaLevels: femmina maschio
> t_sex[mode_sex]
[1] 210
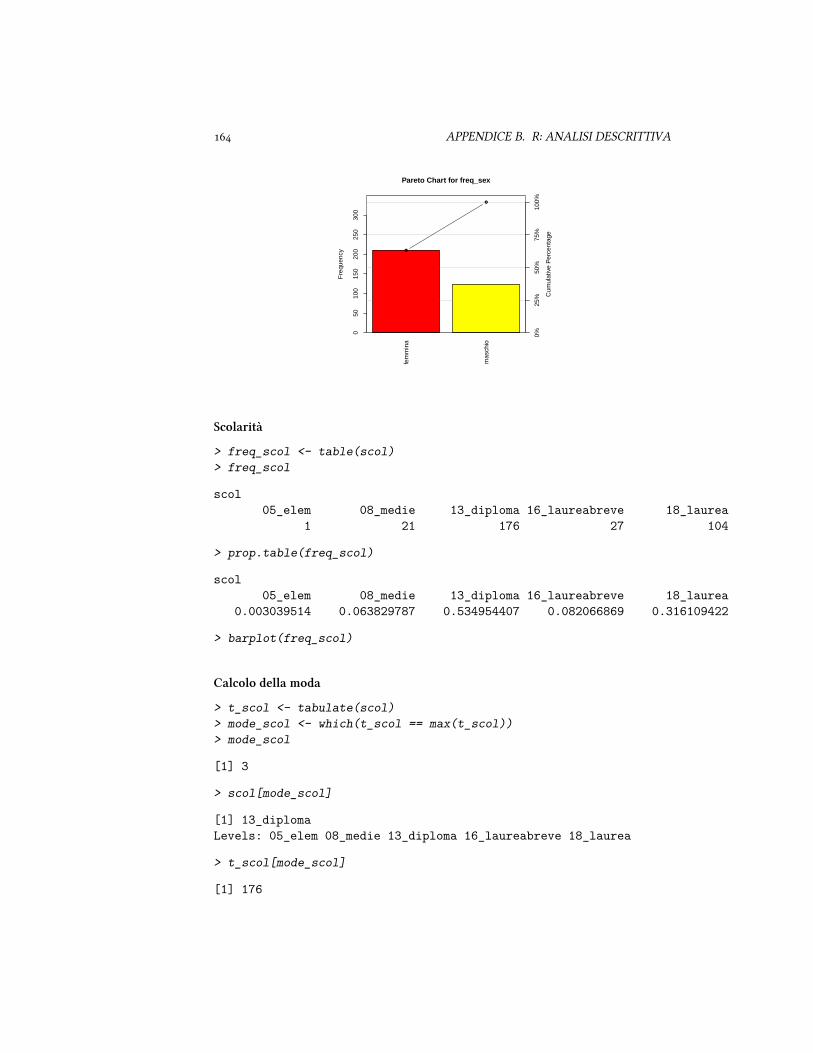
APPENDICE B. R: ANALISI DESCRITTIVA
fem
min
a
mas
chio
Pareto Chart for freq_sex
Fre
quen
cy
050
100
150
200
250
300
●
●
0%25
%50
%75
%10
0%
Cum
ulat
ive
Per
cent
age
Scolarità
> freq_scol <- table(scol)> freq_scol
scol05_elem 08_medie 13_diploma 16_laureabreve 18_laurea
1 21 176 27 104
> prop.table(freq_scol)
scol05_elem 08_medie 13_diploma 16_laureabreve 18_laurea
0.003039514 0.063829787 0.534954407 0.082066869 0.316109422
> barplot(freq_scol)
Calcolo della moda
> t_scol <- tabulate(scol)> mode_scol <- which(t_scol == max(t_scol))> mode_scol
[1] 3
> scol[mode_scol]
[1] 13_diplomaLevels: 05_elem 08_medie 13_diploma 16_laureabreve 18_laurea
> t_scol[mode_scol]
[1] 176

B.. ANALISI DESCRITTIVE
05_elem 08_medie 16_laureabreve
050
100
150
B.. Variabili a rapporti
> table(giuste)
giuste4 6 7 9 10 11 12 13 14 15 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 321 1 1 1 1 1 2 1 2 2 1 1 2 2 4 4 3 3 4 10 6 15 7 14 13 2633 34 35 36 37 38 39 40 41 42 43 44 45 4820 29 26 28 24 28 17 11 8 8 5 1 2 1
L'uso di table non è molto pratico. Dato difficile da leggere.
> hist(giuste)
Histogram of giuste
giuste
Fre
quen
cy
0 10 20 30 40 50
020
4060
8010
0
> stripchart(giuste, method = "stack", xlab = "giuste")
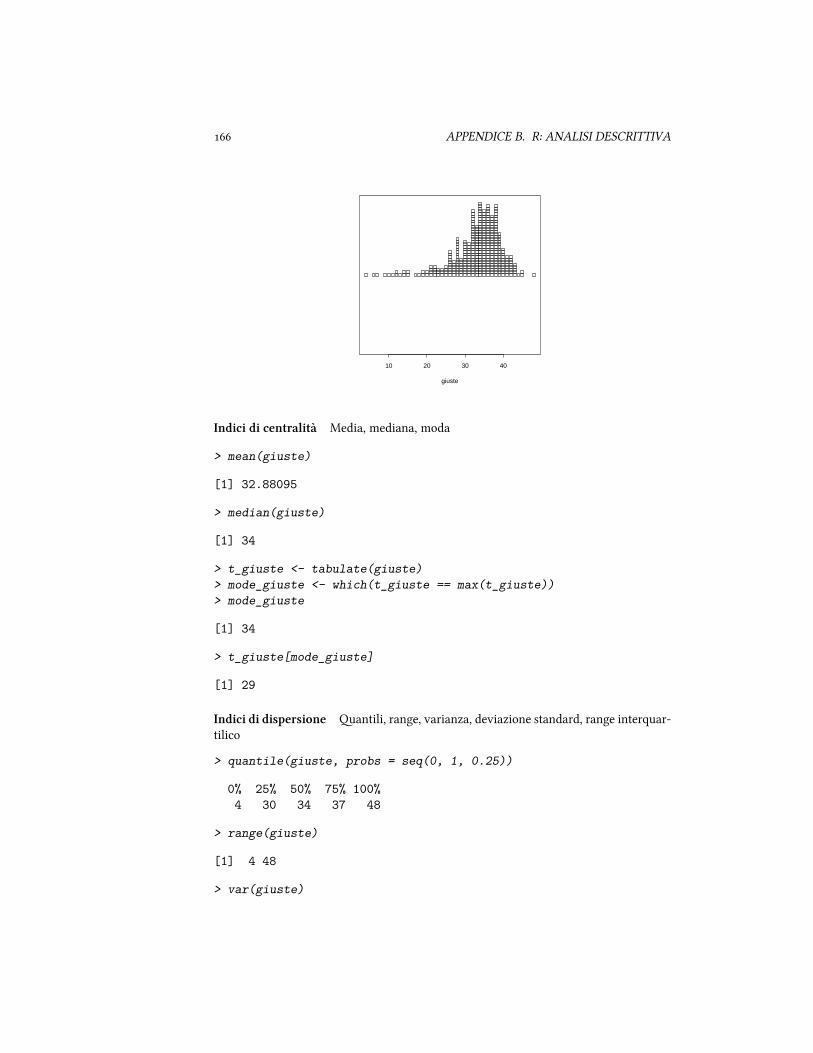
APPENDICE B. R: ANALISI DESCRITTIVA
10 20 30 40
giuste
Indici di centralità Media, mediana, moda
> mean(giuste)
[1] 32.88095
> median(giuste)
[1] 34
> t_giuste <- tabulate(giuste)> mode_giuste <- which(t_giuste == max(t_giuste))> mode_giuste
[1] 34
> t_giuste[mode_giuste]
[1] 29
Indici di dispersione antili, range, varianza, deviazione standard, range interquar-tilico
> quantile(giuste, probs = seq(0, 1, 0.25))
0% 25% 50% 75% 100%4 30 34 37 48
> range(giuste)
[1] 4 48
> var(giuste)

B.. ANALISI DESCRITTIVE
[1] 47.35295
> sd(giuste)
[1] 6.881348
> IQR(giuste)
[1] 7
Boxplot
> boxplot(giuste)
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
1020
3040
QQ plot QQ plot: quantile quantile plots
> qqnorm(giuste)> qqline(giuste, col = 2)

APPENDICE B. R: ANALISI DESCRITTIVA
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●●
●
●
●
●
●
●●
−3 −2 −1 0 1 2 3
1020
3040
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s

Bibliografia
Akritas, M. G. (). Statistics : An Introduction to Statistics for Engineers andScientists. StatPublisher.
Anscombe, F. J. (). Graphs in statistical analysis.eAmerican Statistician, ():--.
Bollen, J., Mao, H., and Zeng, X. (). Twier mood predicts the sto market. Arxivpreprint arXiv:..
Chan, Y. and Walmsley, R. P. (). Learning and understanding the kruskal-wallis one-way analysis-of-variance-by-rankstest for differences among three ormoreindependent groups. Physical erapy, ().
Frascati, F. (). Formulario di Statistica con R. GNU.
Kahneman, D. and Tversky, A. (). Choices, values, and frames. AmericanPsyologist, :--.
Keselman, H. J., Wilcox, R. R., Othman, A. R., and Fradee, K. (). Trimming,transforming statistics, and bootstrapping: Circumventing the biasing effects of he-terescedasticity and nonnormality. Journal of Modern Applied Statistical Methods,():--.
Maindonald, J. H. (). Using r for data analysis and graphics -- introduction, co-de and commentary. Tenical report, Centre for Mathematics and Its Applications,Australian National University.
Mineo, A. M. (). Una guida all'utilizzo dell'ambiente statistico r. Tenical report,Universita degli Studi di Palermo.
Molenaar, I. and Kiers, H. (). Statistics refresher course. Tenical report, HeymansInstituut Rijksuniversiteit Groningen.
Muggeo, V. M. R. and Ferrara, G. (). Il linguaggio r: concei introduivi ed esempi.Tenical report, Universita degli Studi di Palermo.
Seltman, H. J. (). Experimental design and analysis. Tenical report, College ofHumanities and Social Sciences at Carnegie Mellon University.

BIBLIOGRAFIA
Tversky, A. and Kahneman, D. (). e framing of decisions and the psyology ofoice. Science, :--.
Vasishth, S. (). e foundations of statistics: A simulation-based approa. Tenicalreport, University of Potsdam.
Wal, C. (). Hand-book on statistical distributions for experimentalists. Tenicalreport, University of Stoholm.
Waltenburg, E. and McLaulan, W. (). Exploratory data analysis: A primer forundergraduates. Tenical report, Purdue University.
Whitley, E. and Ball, J. (). Nonparametric methods. Critical Care, :--.

Indice analitico
χ2
likelihood ratio i square, Pearson, statistica, statistica bivariata,
Affidabilità, , Analisi della Varianza,
a due vie, assunti, identità principale, interazione, modello, modello lineare,
Assuntilinearità, normalità, , omoskedasticità, , , violazioni,
Campionamento, missing,
Coefficiente di Spearman, assunti,
Confronti multipli, , , correzione di Bonferroni, correzione di Tukey,
Correlazione e causazione, Correlazione lineare,
assunti, modello,
Distribuzioneχ2, Fisher-Snedecor, Normale, t di Student, , ,
Wilcoxon U,
Errore, , campionamento, , , distribuzione, , , distribuzione delle medie, errore standard, non sistematico (bias), varianza,
Faori sperimentali, Frequenze
aese, , osservate,
Funzioni Raov, bartle.test, isq.test, , , cor.test, , harvtest, kruskal.test, , ks.test, lm, pisq, shapiro.test, , , t.test, , TukeyHSD, , wilcox.test, , ,
Gradi di libertàChi2,
Intervallo di confidenza, , , Ipotesi di indipendenza, Ipotesi nulla,
Modelli Lineari,

INDICE ANALITICO
Omnibus,
P-value, confronto fra campione e popolazio-
ne, correlazione,
Regressione lineare, Assunti, modello, violazione assunti,
Rea di regressione, , Ricerca
qualitativa, scientifica,
Scaleintervalli, nominali, , ordinali, quantitative, rapporto,
Simulazioneχ2, analisi della Varianza, , bootstrapping, confronto fra due gruppi, correlazione, introduzione, permutazioni, resampling,
Somma dei quadrati degli errori, Statistica,
descriiva, , inferenziale, tendenze centrali,
t test, assunzioni,
tatisticaindici di dispersione,
Testconfronto fra medie, Kruskal-Wallis, , Mann-Whitney-Wilcoxon U, t test,
Wilcoxon, Test di ipotesi, Test non parametrici, , , Trimming,
Validità, Varianza
residua, , spiegata, , ,
Winsorizzazione,


















