
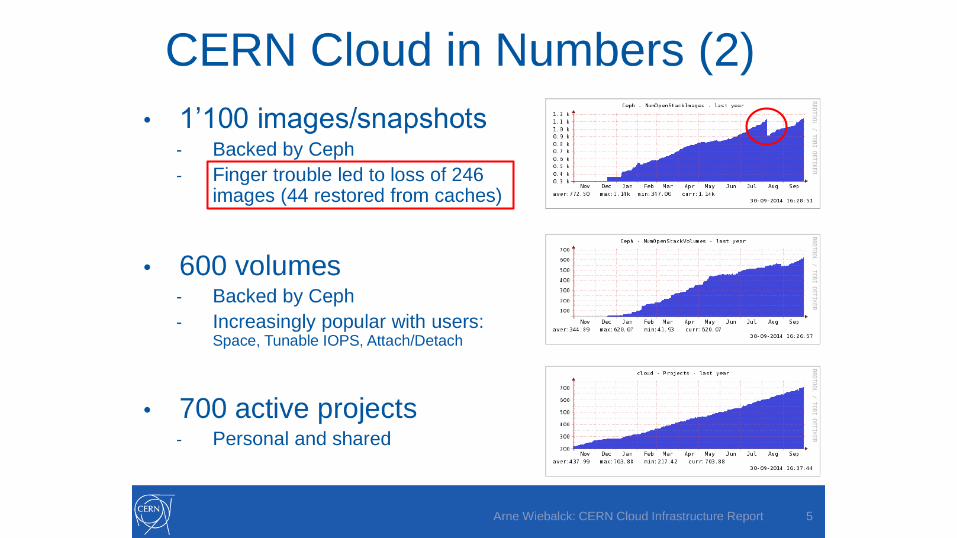
Disaster recovery with open nebula
58
Disaster recovery with OpenNebula Carlo Daffara
-
Upload
carlo-daffara -
Category
Software
-
view
116 -
download
1
Transcript of Disaster recovery with open nebula

Disaster recovery with OpenNebulaCarlo Daffara

First, let me get some coffee.




“Disaster recovery (DR) involves a set of policies and procedures to enable the recovery or continuation of vital technology infrastructure and systems following a natural or human-induced disaster. Disaster recovery focuses on the IT or technology systems supporting critical business functions, as opposed to business continuity, which involves keeping all essential aspects of a business functioning despite significant disruptive events. Disaster recovery is therefore a subset of business continuity.”

80% of businesses affected by a major incident either never re-open or close within 18 months (Source: Axa)

From “Understanding the Cost of Data Center Downtime: An Analysis of the Financial Impact on Infrastructure Vulnerability”, Ponemon Research

“Let’s begin with one very interesting fact. According to a survey completed in 2010, human error is responsible for 40% of all data loss, as compared to just 29% for hardware or system failures. An earlier IBM study determined data loss due to human error was as high as 80%” (From: Business continuity and disaster recovery planning for IT professionals”, Elsevier press, 2014)



The recovery time objective (RTO) is the targeted duration of time and a service level within which a business process must be restored after a disaster (or disruption) in order to avoid unacceptable consequences associated with a break in business continuity.
The recovery point objective (RPO), is the maximum tolerable period in which data might be lost from an IT service due to a major incident.

“Alternative storage-based replication solutions cost a minimum of $10,000 per terabyte of data covered plus ongoing maintenance. For the composite organization’s 225 protected VMs with an average size of 100 gigabytes (GB), the three year costs for licenses and maintenance are estimated at $328,500” (Forrester research, “The Total Economic Impact of VMware vCenter Site Recovery Manager”, 2013)

3 simple rules to make a working DR:

Rule 1: never put all eggs in one basket (be it hardware, software, cloud)


Customer buys full DR and snapshot capability from local data center; data center updates SAN firmware and loses everything. Customer discovers that snapshots and backups were kept in the same SAN with everything else.


In electronics, an opto-isolator, also called an optocoupler, photocoupler, or optical isolator, is a component that transfers electrical signals between two isolated circuits by using light. Opto-isolators prevent high voltages from affecting the system receiving the signal.


Rule 2: RTO and RPO are usually different from VM to VM



Needs to be replicated constantly
No one cares if this dies



Rule 3: design a reliable oracle



Oracle of Delphi

How the others do it:



How we do it:


Our approach takes advantage of three individual factors:● LizardFS’ thinly-provisioned snapshots● online replication of chunks & tiering● OpenNebula’s datastores



# An example of configuration of goals. It contains the default values.
1 1 : _2 2 : _ _3 3 : _ _ _4 4 : _ _ _ _5 5 : _ _ _ _ _
# (...)
20 20 : _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
# But you don't have to specify all of them -- defaults will be assumed.
# You can define your own custom goals using labels if you use them, e.g.:# 14 min_two_locations: _ locationA locationB # one copy in A, one in B, third anywhere# 15 fast_access : ssd _ _ # one copy on ssd, two additional on any drives# 16 two_manufacturers: WD HT # one on WD disk, one on HT disk

● Most disasters are “local”, for example a fire in the server room or a flood
● Two different DR sites, one near (eg. next building/other side of the building) and one far (external datacenter)
● near DR receives a copy of the chunks that are part of the marked datastores


● Remote snapshots are handled in the same way: we take a full snapshot of the datastore, and differentially replicate it
● We use the “snapshot of snapshot” approach to avoid the cost of deduplication
● This way we can prioritize sync queues, and in the receiving end we got a complete and decoupled + working OpenNebula
For example, average dedup cost for ZFS: 5 to 30 GB of dedup table data for every TB of pool data, assuming an average block size of 64K.

/var/lib/one/datastore↓
DRSNAP12H
/var/lib/one/snapshots↓
<yyyymmddhh>↓
DRSNAP12H
LocalVM changes only in
snapshots
/var/lib/one/datastore↓
DRSNAP12H
/var/lib/one/snapshots↓
<yyyymmddhh>↓
DRSNAP12H
Remoteno chunk changes
in snapshots
inplace rsync
(25x speedup)


virsh# domblkstat instance-0012 --device vda
vda rd_req 128vda rd_bytes 2344448vda wr_req 234vda wr_bytes 618496vda flush_operations 2vda rd_total_times 106512819vda wr_total_times 960359872vda flush_total_times 1741727

Our “pilot light” approach: a running OpenNebula on two nodes, with its own LizardFS store. Running only two VMs: the Oracle and the TesterThe Oracle checks if DR is needed, and may need a human confirmation for execution of the DR failover. If confirmation is given, it takes the latest valid snapshotted datastore, softlinks it and import the VMs (through snapshots, so it’s instantaneous)The Tester makes a snapshot of the current stable snapshot, import the VMs and runs them into a separate, non-routed vnet, then executes a test to see if everything works (workload dependent), then deletes the intermediate snapshots

Only critical VMs are executed this way, if RTO<30 minsFor the VMs with higher RTO, buy one week of hardware on demand, auto-install a node with Puppet or Ansible, and make it join the OpenNebula cloud
Deployed usually in 30 mins. Other vendor guarantee <15 minutes.



Ideal for harsh indoor environments that require protection from falling dirt or liquid, dust, light splashing, oil or coolant seepage. Its NEMA Zone 4 rating also makes it perfect for facilities located in earthquake-prone seismic zones or any environment prone to extreme vibration such as factories, power stations, construction areas, shipping facilities, warehouses, processing plants, railroads, airports and military installations.



● Have a “big red button” to stop DR if needed. Sometimes you are already fighting fire here, and you know it’s better not to move everything in flight.
● Have two people that are competent as DR firefighters, and give them a second phone with a rechargeable card. And make sure both don’t go on vacation together. (Hint: don’t choose two married people)

● Use a gateway machine to provide a consistent internal IP scheme, and two different configurations for the gateway router to provide unmodified routing for the remaining VMs
● Aggregate functionality in a single VM (for example, one that manages logs) to optimize writes

● I favor consistency, so I tend to avoid application-level replication, unless it’s native to the app (eg. NoSQL). Otherwise you have different solutions for different machines (eg. quorum group in MS replication with same UUID…)
● Try to reduce write amplification for databases, especially MySQL. Eg. TokuDB and its fractal tree


Thank you!
Carlo Daffara@cdaffara
linkedin.com/in/cdaffara



![Disaster Recovery Center (Disaster Assistance … Library/Disaster Recovery Center...Disaster Recovery Center (Disaster Assistance Center) Standard Operating Guide [Appendix to: ]](https://static.fdocuments.us/doc/165x107/5b0334ba7f8b9a2d518bd9d9/disaster-recovery-center-disaster-assistance-librarydisaster-recovery-centerdisaster.jpg)














