
Dimensions of Research - The University of … · Web viewDimensions of Research Problems Research...
84
Analysis of Data Using MR and GLM This lecture: ANOVA via MR and GLM Dimensions of Research Problems We’ll start at the top of this box and work our way through it. We’ll illustrate analysis with MR procedure and with the GLM procedure. Ideally, at the end of this, you’ll be comfortable using either procedure to perform the same analyses. ANOVA via MR and GLM 1 3/11/2022 Research Involving a mixture of qualitative Research involving only comparison of Group means – Research involving only Training Program Performance after training Gender Training Program Gender Performance Cognitive Ability Cognitive Ability
Transcript of Dimensions of Research - The University of … · Web viewDimensions of Research Problems Research...

Analysis of Data Using MR and GLMThis lecture: ANOVA via MR and GLM
Dimensions of Research Problems
We’ll start at the top of this box and work our way through it.
We’ll illustrate analysis with MR procedure and with the GLM procedure.
Ideally, at the end of this, you’ll be comfortable using either procedure to perform the same analyses.
ANOVA via MR and GLM 1 5/14/2023
Research Involving a mixture of qualitative and quantitative factors
Research involving only comparison of Group means – Qualitative Factors only
Research involving only quantitative factors
Training ProgramPerformanceafter training
Gender
Training ProgramGender PerformanceCognitive Ability
Cognitive AbilityConscientiousness GPAEmotional Stability

One Qualitative Factor: One Way ANOVAManipulation Check on Faking Data. This example is taken from the Rosetta project data. It is from Raven Worthy’s thesis, completed in 2012. Raven compared three conditions defined by different instructions regarding faking.
In each condition, participants were given a personality test (the IPIP 50-item Sample Big 5 questionnaire). Then, they were split into 3 groups.
Condition 1: Given instructions to respond honestly. Given a 2nd Big 5 questionnaire (IPIP Other 50 items)Condition 2: Given instructions to fake good. Given same 2nd Big 5 questionnaire.Condition 3: Given instructions to respond honestly but told that highest score would receive a gift certificate.
Dependent Variable: The dependent variable is a difference score . . .Mean scores on 2nd questionnaire (all 50 items) minus mean score on 1st questionnaire.
Expectation for DV values: 0 means person did not fake on 2nd administration relative to the first.Positive means person faked “good” on 2nd administration relative to first.Negative means person faked “bad” on 2nd administration relative to first.
Expectation for Conditions: Condition 1: DV ~~ 0 – Honest responseCondition 2: DV > > 0 – Instructed to fake goodCondition 3: DV > 0 – Incentive to fake good.
A snippet of the data (Dependent variable is boldfaced) . . .
b5origmean b5othmean b5meandiff ncondit
4.28 4.02 -.26 1 5.20 5.34 .14 1 4.16 3.70 -.46 1 4.68 4.16 -.52 1 5.76 5.62 -.14 1 4.54 4.40 -.14 1 4.96 4.34 -.62 1 5.16 5.06 -.10 1 4.22 3.98 -.24 1 5.36 5.16 -.20 1 5.42 5.38 -.04 1 5.06 4.65 -.41 1 4.82 5.04 .22 1 5.12 5.34 .22 1 4.58 4.46 -.12 1
ANOVA via MR and GLM 2 5/14/2023

Preliminary examination of data using dot plots . . .
It looks as if the manipulation worked. It appears that the participants in Condition 2 had more positive difference scores (more faking good) than did those in the other two conditions.
It also appears that the Incentive condition 3 resulted in more positive scores than Condition 1.
But the devil is in the p-values.
Note that the ncondit=2 scores seem more variable than the others!!!????
Various pieces of information that could/should be presented . . .
1. Means and SD’s.2. Plots of means.3. Tests of assumptions.4. Tests of significance.5. Effect sizes and observed power.6. Post hoc tests, if appropriate.
ANOVA via MR and GLM 3 5/14/2023

The data that were analyzed
Note that the dependent variable is a difference score – post instruction minus pre-instruction.
ANOVA via MR and GLM 4 5/14/2023

The analysis: Analyze -> General Linear Model -> Univariate
We will always put the name of the nominal / categorical variable defining group membership into the Fixed Factor(s) field.
(No group coding variables needed for GLM.)
We won’t be using the Random Factor(s) field in this class.
ANOVA via MR and GLM 5 5/14/2023

Descriptive Statistics.
This output was obtained by clicking on the [Options] button on the GLM dialog box and then checking Descriptive Statistics.
Note this is a quick-and-dirty way to get group means and SD’s.
The Output
Univariate Analysis of VarianceBetween-Subjects Factors
N
ncondit 1 110
2 108
3 110
Descriptive Statistics
Dependent Variable: b5meandiff
ncondit Mean Std. Deviation N
1 -.0861 .27205 110
2 .6228 .84490 108
3 .1975 .47792 110
Total .2424 .64744 328
Levene's Test of Equality of Error
Variancesa
Dependent Variable: b5meandiff
F df1 df2 Sig.
76.376 2 325 .000
Tests the null hypothesis that the error variance
of the dependent variable is equal across
groups.
a. Design: Intercept + ncondit
ANOVA via MR and GLM 6 5/14/2023
Homogeneity tests.
The variances were significantly different across groups. We’ll have to interpret the mean comparisons cautiously

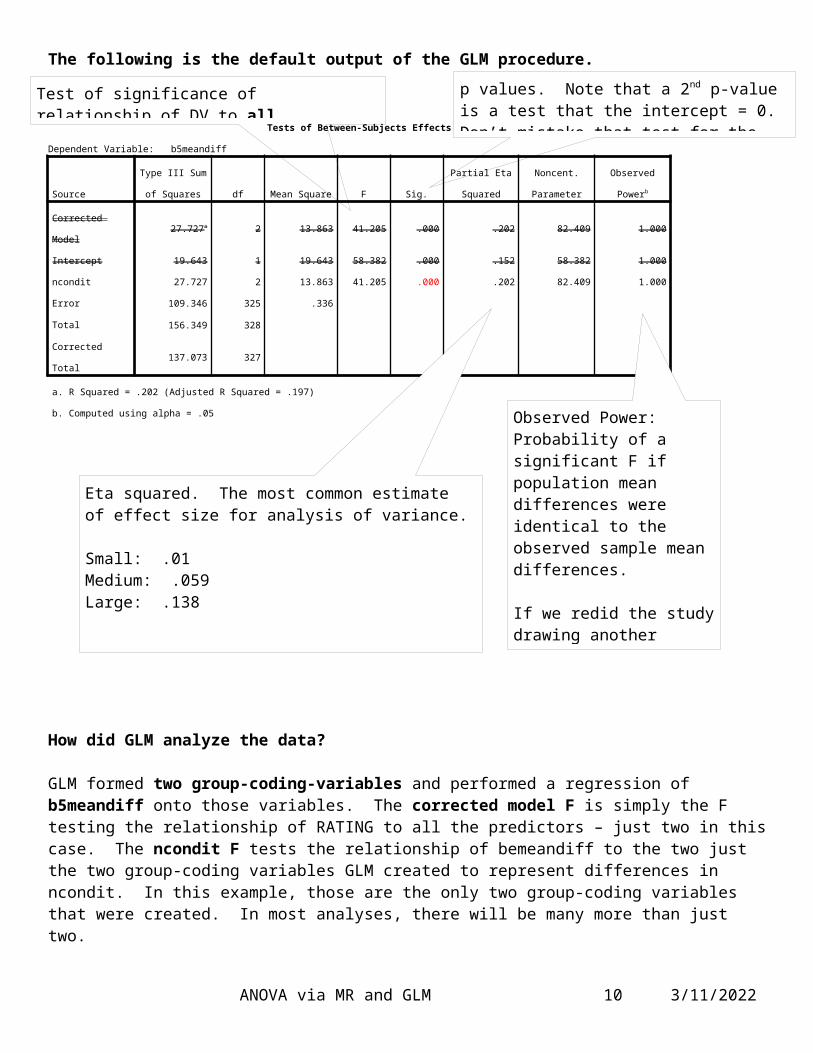
The following is the default output of the GLM procedure.
Tests of Between-Subjects Effects
Dependent Variable: b5meandiff
Source
Type III Sum of
Squares df Mean Square F Sig.
Partial Eta
Squared
Noncent.
Parameter
Observed
Powerb
Corrected Model 27.727a 2 13.863 41.205 .000 .202 82.409 1.000
Intercept 19.643 1 19.643 58.382 .000 .152 58.382 1.000
ncondit 27.727 2 13.863 41.205 .000 .202 82.409 1.000
Error 109.346 325 .336
Total 156.349 328
Corrected Total 137.073 327
a. R Squared = .202 (Adjusted R Squared = .197)
b. Computed using alpha = .05
How did GLM analyze the data?
GLM formed two group-coding-variables and performed a regression of b5meandiff onto those variables. The corrected model F is simply the F testing the relationship of RATING to all the predictors – just two in this case. The ncondit F tests the relationship of bemeandiff to the two just the two group-coding variables
ANOVA via MR and GLM 7 5/14/2023
Observed Power: Probability of a significant F if population mean differences were identical to the observed sample mean differences.
If we redid the study drawing another sample from the population and the population means were identical to the sample means obtained here, the likelihood of a significant difference would be 1.000.
Eta squared. The most common estimate of effect size for analysis of variance.
Small: .01Medium: .059Large: .138
Test of significance of relationship of DV to all predictors - MR ANOVA
p values. Note that a 2nd p-value is a test that the intercept = 0. Don’t mistake that test for the ones you’re interested in.

GLM created to represent differences in ncondit. In this example, those are the only two group-coding variables that were created. In most analyses, there will be many more than just two.
What should we conclude?
The Oneway ANOVA F is completely valid only when the population variances are all equal. The Levine’s test comparing the variances was significant, indicating that the variances are not equal. This suggests that we should interpret the differences cautiously. We could perform an additional nonparametric test, the Kruskal-Wallis nonparametric ANOVA, for example. Or we could consider transformations of the data to equalize the variances.
In this case, however, the effect size is so big that I would feel comfortable arguing that there are significant differences between the means. If the effect size had been small (close to .01) and the p-value large (nearly .05), then I would have less confidence arguing that the means are different.
ANOVA via MR and GLM 8 5/14/2023

.Post-Hoc Tests
Knowing that the variances were not equal, I went back to the analysis specification and asked for the Scheffe test, which is a quite conservative post-hoc test and four other post hoc tests designed specifically for situations in which variance are not assumed to be equal.
I got the following output . . .
ANOVA via MR and GLM 9 5/14/2023
Post Hoc TestsNonredundant comparisons p-values are red’d.
NconditMultiple Comparisons
Dependent Variable: b5meandiff
(I) ncondit (J) ncondit
Mean Difference (I-
J) Std. Error Sig.
95% Confidence Interval
Lower Bound Upper Bound
Scheffe 1 2 -.7090* .07857 .000 -.9022 -.5158
3 -.2836* .07821 .002 -.4759 -.0913
2 1 .7090* .07857 .000 .5158 .9022
3 .4254* .07857 .000 .2322 .6186
3 1 .2836* .07821 .002 .0913 .4759
2 -.4254* .07857 .000 -.6186 -.2322
Tamhane 1 2 -.7090* .08534 .000 -.9154 -.5025
3 -.2836* .05243 .000 -.4100 -.1572
2 1 .7090* .08534 .000 .5025 .9154
3 .4254* .09320 .000 .2006 .6502
3 1 .2836* .05243 .000 .1572 .4100
2 -.4254* .09320 .000 -.6502 -.2006
Dunnett T3 1 2 -.7090* .08534 .000 -.9153 -.5026
3 -.2836* .05243 .000 -.4100 -.1572
2 1 .7090* .08534 .000 .5026 .9153
3 .4254* .09320 .000 .2007 .6501
3 1 .2836* .05243 .000 .1572 .4100
2 -.4254* .09320 .000 -.6501 -.2007
Games-Howell 1 2 -.7090* .08534 .000 -.9113 -.5066
3 -.2836* .05243 .000 -.4075 -.1596
2 1 .7090* .08534 .000 .5066 .9113
3 .4254* .09320 .000 .2050 .6458
3 1 .2836* .05243 .000 .1596 .4075
2 -.4254* .09320 .000 -.6458 -.2050
Dunnett C 1 2 -.7090* .08534 -.9118 -.5062
3 -.2836* .05243 -.4082 -.1590
2 1 .7090* .08534 .5062 .9118
3 .4254* .09320 .2039 .6469
3 1 .2836* .05243 .1590 .4082
2 -.4254* .09320 -.6469 -.2039
Based on observed means.
The error term is Mean Square(Error) = .336.
*. The mean difference is significant at the .05 level.
ANOVA via MR and GLM 10 5/14/2023
The Dunnett C test gives only lower and upper bounds of a confidence interval for each pair.

Homogeneous Subsetsb5meandiff
ncondit N
Subset
1 2 3
Scheffea,b,c 1 110 -.0861
3 110 .1975
2 108 .6228
Sig. 1.000 1.000 1.000
Means for groups in homogeneous subsets are displayed.
Based on observed means.
The error term is Mean Square(Error) = .336.
a. Uses Harmonic Mean Sample Size = 109.325.
b. The group sizes are unequal. The harmonic mean of the group sizes is used. Type I error levels are
not guaranteed.
c. Alpha = .05.
All of the post-hoc tests agreed that all three means were different from each other.
1 vs 2: Significant
1 vs 3: Significant
2 vs 3: Significant
So, it appears that the manipulation was successful.
When participants were told to respond honestly, they changed their responses the least from pre-instruction to post-instruction (mean diff = -.09).
When they were instructed to fake good, they did (mean diff = 0.62).
When they were given a mild incentive to fake good, they did, a little (mean diff = 0.20).
Wonderful. The manipulation worked!!
ANOVA via MR and GLM 11 5/14/2023

Profile Plots
Note: SPSS’s plotting algorithm adjusts the scale values so the graph fills as much of the rectangular space as possible.
This can make nonsignificant differences look bigger than they really are.
It’s important to note that the means that are plotted are estimated means – means estimated assuming all participants had the same value on any covariates.
In this case, there were no covariates, so the estimated means are the same as the observed means.
But in analyses involving covariates (quantitative predictors), the estimated means and observed means are not equal.
ANOVA via MR and GLM 12 5/14/2023

GLM’s Group Coding Variables in Oneway ANOVA I said above that GLM forms Group Coding Variables to conduct the ANOVA. What information on them is available? For example, what coding scheme does SPSS use?
This example was taken from Aron and Aron, p. 318. Persons in 3 groups rated guilt of a defendant after having read a background sheet on the defendant. For those in Group 1, the background sheet mentioned a criminal record. For those in Group 2, the sheet mentioned a clean record. For those in Group 3, the background sheet gave no information on the defendant's background. Question: Are the differences in guilt ratings significant? Each case is a jury, created just for this experiment.
ANOVA via MR and GLM 13 5/14/2023

Getting GLM to display Regression information.
Information on regression analyses performed in GLM including group coding variables is displayed by requesting the “Parameter Estimates” table. It is shown being requested in the dialog box shown on the right
ANOVA via MR and GLM 14 5/14/2023
Case Sum m ar i esa
10. 00 1. 00 Cr im inal Recor d G r oup 1 0 1 0
7. 00 1. 00 Cr im inal Recor d G r oup 1 0 1 0
5. 00 1. 00 Cr im inal Recor d G r oup 1 0 1 0
10. 00 1. 00 Cr im inal Recor d G r oup 1 0 1 0
8. 00 1. 00 Cr im inal Recor d G r oup 1 0 1 0
5. 00 2. 00 Clean Recor d G r oup 0 1 0 1
1. 00 2. 00 Clean Recor d G r oup 0 1 0 1
3. 00 2. 00 Clean Recor d G r oup 0 1 0 1
7. 00 2. 00 Clean Recor d G r oup 0 1 0 1
4. 00 2. 00 Clean Recor d G r oup 0 1 0 1
4. 00 3. 00 No I nf or m at ion G r oup 0 0 - 1 - 1
6. 00 3. 00 No I nf or m at ion G r oup 0 0 - 1 - 1
9. 00 3. 00 No I nf or m at ion G r oup 0 0 - 1 - 1
3. 00 3. 00 No I nf or m at ion G r oup 0 0 - 1 - 1
3. 00 3. 00 No I nf or m at ion G r oup 0 0 - 1 - 1
15 15 15 15 15 15
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
NTot al
RATI NG Rat ing of G uilt .
10 = m ax. G RO UP DC1 DC2 EC1 EC2
Lim it ed t o f ir st 100 cases.a.

Analysis Illustrating Default GLM group coding variables.
Univariate Analysis of Variance
Output from the REGRESSION procedure using the default dummy codes
So, the default group coding variables estimated in GLM are dummy codes.
ANOVA via MR and GLM 15 5/14/2023
I used the REGRESSION procedure to determine what the GLM procedure’s Parameter Estimates table was giving.
Note that the output of the Parameter Estimates box is the same as the regression analysis of dummy codes.
This is new information – the Parameter Estimates Table requested above. The codes are Dummy Codes with the last group as the comparison group. I figured this out by doing a regression analysis with various codes until I found a match.
Since I did not request Eta-squared and Power for this analysis, they are not displayed here.
Be twe e n-Subje c ts Fa c tors
Cri min a l Re c o rd Gro u p 5
Cle a n Re c o rd Gro u p 5
No In fo rma ti o n Gro u p 5
1 .0 0
2 .0 0
3 .0 0
GROUPVa lu e L a b e l N
De s c riptiv e Sta tis tic s
De p e n d en t Va ri a b le : RATING Ra ti n g o f Gu i l t. 1 0 = ma x .
8 .0 0 0 0 2 .1 2 1 3 5
4 .0 0 0 0 2 .2 3 6 1 5
5 .0 0 0 0 2 .5 4 9 5 5
5 .6 6 6 7 2 .7 6 8 9 1 5
GROUP1 .0 0 Crimin a l Re c o rd Gro u p
2 .0 0 Cl ea n Re c o rd Gro up
3 .0 0 No In fo rma ti o n Gro u p
To ta l
Me a n Std . De v ia tio n N
Tests of Between-Subjects Effects
Dependent Variable: RATING Rat ing of Guilt . 10 = max.
43. 333a 2 21. 667 4. 063 .045
481. 667 1 481. 667 90. 312 .000
43. 333 2 21. 667 4. 062 .045
64. 000 12 5. 333
589. 000 15
107. 333 14
SourceCorrect ed Model
Int ercept
GROUP
Error
Tot al
Correct ed Tot al
Type I I I Sumof Squares df Mean Square F Sig.
R Squared = . 404 (Adjust ed R Squared = . 304)a.
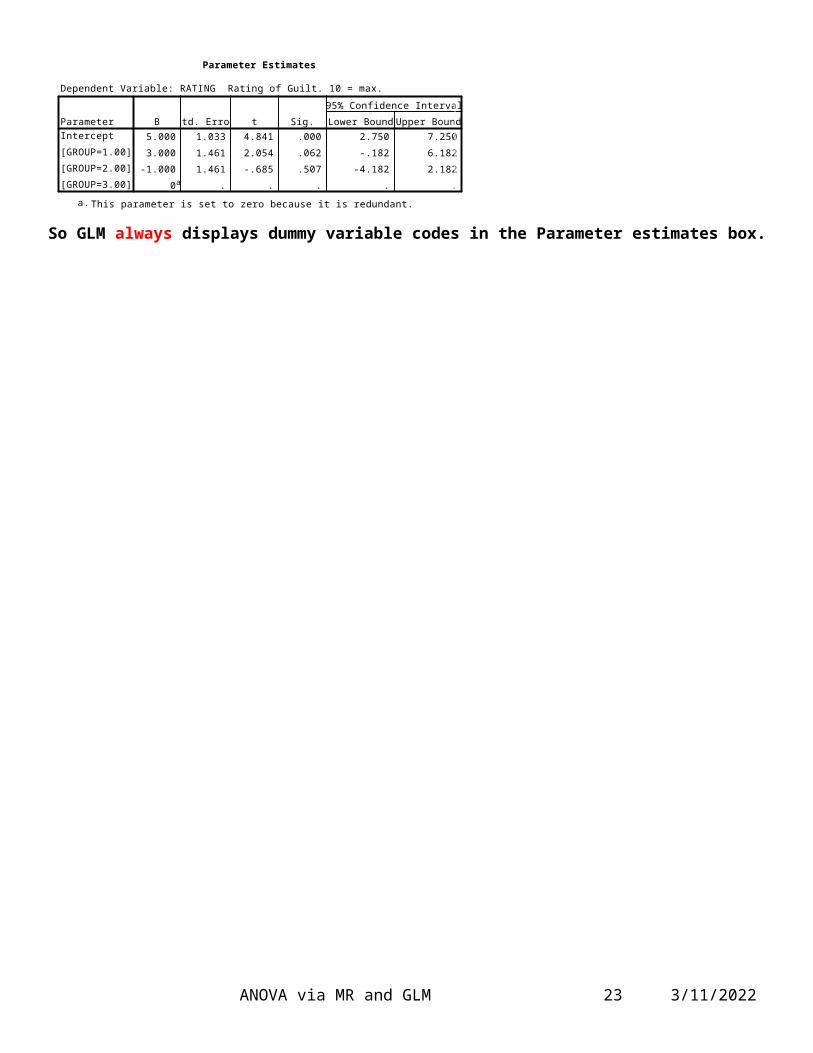
Parameter Est i mates
Dependent Var iable: RATI NG Rat ing of Guilt . 10 = max.
5. 000 1. 033 4. 841 . 000 2. 750 7. 250
3. 000 1. 461 2. 054 . 062 - . 182 6. 182
-1. 000 1. 461 - . 685 . 507 -4. 182 2. 182
0a . . . . .
Paramet erI nt ercept
[ G RO UP=1. 00]
[ G RO UP=2. 00]
[ G RO UP=3. 00]
B St d. Er ror t Sig. Lower Bound Upper Bound
95% Conf idence I nt erval
This paramet er is set t o zero because it is redundant .a.
Co e ffic ie n tsa
5 .0 0 0 1 .0 3 3 4 .8 4 1 .0 0 0
3 .0 0 0 1 .4 6 1 .5 2 9 2 .0 5 4 .0 6 2
-1 .0 0 0 1 .4 6 1 -.1 7 6 -.6 8 5 .5 0 7
(Co n s ta n t )
DC1
DC2
Mo d e l1
B Std . Erro r
Un s ta n d a rd i z e dCo e f f i c i e n ts
Be ta
Sta n d a rdi z e d
Co e f f i c i en ts
t S i g .
De p e n d e n t Va ri a b l e : RAT ING Ra t i n g o f Gu i l t . 1 0 = ma x .a .

Analysis Illustrating Requesting your own GLM Contrasts
UNIANOVA rating BY group /CONTRAST (group)=Deviation /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /PRINT = DESCRIPTIVE PARAMETER /CRITERIA = ALPHA(.05) /DESIGN = group .
Univariate Analysis of Variance
So GLM always displays dummy variable codes in the Parameter estimates box.
ANOVA via MR and GLM 16 5/14/2023
Same data analyzed. This time, I clicked on the [Contrasts...] button and requested Deviation Contrasts. Deviation contrasts are the same as Effects contrasts.
What is displayed in the Parameter Estimates Box is unaffected by the fact that Deviation Contrasts were chosen. What is (always) displayed here is Dummy Codes with the last group as the comparison group.
Syntax, if you’re interested.
Same output as in the above two examples.
No effect sizes or power values displayed because I did not ask for them. I did ask for Parameter Estimates.
Between-Subjects Factors
CriminalRecordGroup
5
CleanRecordGroup
5
NoInformationGroup
5
1.00
2.00
3.00
GROUPValue Label N
De s c riptiv e Sta tis tic s
De p e n d en t Va ri a b le : RATING Ra ti n g o f Gu i l t. 1 0 = ma x .
8 .0 0 0 0 2 .1 2 1 3 5
4 .0 0 0 0 2 .2 3 6 1 5
5 .0 0 0 0 2 .5 4 9 5 5
5 .6 6 6 7 2 .7 6 8 9 1 5
GROUP1 .0 0 Crimin a l Re c o rd Gro u p
2 .0 0 Cl ea n Re c o rd Gro up
3 .0 0 No In fo rma ti o n Gro u p
To ta l
Me a n Std . De v ia tio n N
Tests of Between-Subjects Effects
Dependent Variable: RATING Rat ing of Guilt . 10 = max.
43. 333a 2 21. 667 4. 063 .045
481. 667 1 481. 667 90. 312 .000
43. 333 2 21. 667 4. 062 .045
64. 000 12 5. 333
589. 000 15
107. 333 14
SourceCorrect ed Model
Int ercept
GROUP
Error
Tot al
Correct ed Tot al
Type I I I Sumof Squares df Mean Square F Sig.
R Squared = . 404 (Adjust ed R Squared = . 304)a.
Parameter Est i mates
Dependent Var iable: RATI NG Rat ing of Guilt . 10 = max.
5. 000 1. 033 4. 841 . 000 2. 750 7. 250
3. 000 1. 461 2. 054 . 062 - . 182 6. 182
-1. 000 1. 461 - . 685 . 507 -4. 182 2. 182
0a . . . . .
Paramet erI nt ercept
[ G RO UP=1. 00]
[ G RO UP=2. 00]
[ G RO UP=3. 00]
B St d. Er ror t Sig. Lower Bound Upper Bound
95% Conf idence I nt erval
This paramet er is set t o zero because it is redundant .a.

Analysis Illustrating Requesting your own contrasts continued.
Results of user-requested contrasts are presented in the Custom Hypothesis Section.
Results from REGRESSION, for comparison.
The bottom line is that the Parameter Estimates box is pretty useless for ANOVA applications unless you're interested in dummy coding. It is most useful for displaying REGRESSION-like information on quantitative variables.
On the other hand, the Contrast Results box gives you a lot of information about your contrasts, although it omits the t-statistic values (???!!!). (But we only look at the p-values anyway, right?)
ANOVA via MR and GLM 17 5/14/2023
The Regression Procedure Coefficients box using Effects Coding.
Note that the significance values for EC1 and EC2 are identical to the above significance values for
This box is the result of the specification of a contrast other than the “None” default.
“Deviation” coding was specified. This is the same as what we have called Effects coding.
Cont rast Resul t s ( K M at r i x)
2. 333
0
2. 333
. 843
. 017
. 496
4. 171
- 1. 667
0
- 1. 667
. 843
. 072
- 3. 504
. 171
Cont r ast Est imat e
Hypot hesized Value
Dif f er ence ( Est im at e - Hypot hesized)
St d. Er r or
Sig.
Lower Bound
Upper Bound
95% Conf idence I nt er valf or Dif f er ence
Cont r ast Est imat e
Hypot hesized Value
Dif f er ence ( Est im at e - Hypot hesized)
St d. Er r or
Sig.
Lower Bound
Upper Bound
95% Conf idence I nt er valf or Dif f er ence
G RO UP Deviat ion Cont r asta
Level 1 vs. M ean
Level 2 vs. M ean
RATI NG Rat ing of G uilt .
10 = m ax.
DependentVar iable
O m it t ed cat egor y = 3a.
Te s t Re s ults
De p e n d e n t Va ri a b le : RATING Ra ti n g o f Gu i l t. 1 0 = ma x .
4 3 .3 3 3 2 2 1 .6 6 7 4 .0 6 3 .0 4 5
6 4 .0 0 0 1 2 5 .3 3 3
So u rc eCo n tra s t
Erro r
Su m o fSq u a re s d f Me a n Sq u a re F Sig .
Co e ffic ie n tsa
5 .6 6 7 .5 9 6 9 .5 0 3 .0 0 0
2 .3 3 3 .8 4 3 .7 1 2 2 .7 6 7 .0 1 7
-1 .6 6 7 .8 4 3 -.5 0 9 -1 .9 7 6 .0 7 2
(Co n s ta n t )
EC1
EC2
Mo d e l1
B Std . Erro r
Un s ta n d a rd i z e dCo e f f i c i e n ts
Be ta
Sta n d a rdi z e d
Co e f f i c i en ts
t S i g .
De p e n d e n t Va ri a b l e : RAT ING Ra t i n g o f Gu i l t . 1 0 = ma x .a .

Analysis of Between-Subjects Factorial DesignsIssues
Factorial Designs – a review
Definition
Research with 2 or more factors in which data have been gathered at all combinations of levels of all factors.
Typical representation is as a Two Way Table.
Rows of the table represent one factor – i.e., the Row FactorColumns of the table represent the Column Factor.Cells represent individual groups of persons observed at each combination of factor levels.
Factor 1
Level 1 Level 2Level 1
Factor 2
Level 2
Note - each factor varies completely within each level of the other.All levels of each factor appear at all levels of the other(s).
Called a completely crossed design because the variation in each variable completely crosses the other variable.
Three Way factorial designs are often represented by separate layers of two way tables
Example: Factor 1 = Type of Training Program, say Lecture vs. ComputerizedFactor 2 = Gender; Factor 3 = Job level – 1st line managers vs. middle managers
ANOVA via MR and GLM 18 5/14/2023
Lecture CompMale
Female
Lecture CompMale
Female1st line Managers
Middle Managers

Analyses of 2x2 Factorial Designs using GLM
The data
The data are from a study by a surgeon at Erlanger on the effect of helmet use on injuries from ATV accidents. The factors investigated here areHELMET: Whether the driver was wearing a helmet or not, with 2 levels.ROLLVER: Whether the ATV rolled over or not, with 2 levels.
The dependent variable is log of the Injury Severity Score (ISS). The larger the ISS value, the more severe the injury. The logarithm was used to make the distribution of the dependent variable more nearly symmetric and less positively skewed.
FYI - Here’s a comparison of the distribution of raw ISS vs. log ISS scores.
ANOVA via MR and GLM 19 5/14/2023
Skewness values areStatistics
iss lgiss
NValid 500 500
Missing 0 0
Skewness 2.263 -.624
Std. Error of Skewness .109 .109
So, the ISS values are clearly more positively skewed than are the log ISS values which are actually slightly negatively skewed.
We’ll analyze the logs of the ISS values.
Original ISS
Log10 ISS

Expectations:
I would expect higher log ISS scores for those not wearing helmets.
I would expect higher ISS scores for those who did not roll over assuming no rollover represents collision.That is, they’re in the hospital for a reason. If they didn’t roll over, they must have hit something.
I would expect the effect of helmet use to be greater among those who did roll (bigger difference between no helmet and helmet) and less among those who did not (smaller difference between no helmet and helmet) – that is, I would expect an interaction of HELMET and ROLLOVER. I could be wrong.
Here’s a small part of the data matrix . . .
ANOVA via MR and GLM 20 5/14/2023

GLM Analysis
ANOVA via MR and GLM 21 5/14/2023
The syntax, if you’re interested . . .
GLM lgiss BY helmet rollover /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /PLOT = PROFILE( helmet*rollover rollover*helmet ) /PRINT = DESCRIPTIVE ETASQ OPOWER HOMOGENEITY /EMMEANS = TABLES(helmet*rollover) /CRITERIA = ALPHA(.05) /DESIGN = helmet rollover helmet*rollover

Univariate Analysis of Variance [DataSet3] G:\MdbT\InClassDatasets\ATVDataForClass050906.sav
Manually produced Two-way Table
Only the main effect of helmet usage was significant.There was no main effect of rollover – persons who rolled over did not have significantly different mean log ISS scores.There was no interaction of HELMET and ROLLOVER. The effect of wearing a helmet was the not significantly different among those who rolled over vs among those who crashed into something. Note, however, that the there was a large numeric difference - .08 vs .20 – between the two pairs of means. It was large numerically, but not large enough to be statistically significant.
ANOVA via MR and GLM 22 5/14/2023
No Helmet
Helmet
Roll .90 .82 .89No Ro .98 .78 .95
.93 .80 .91
.08
.20
Tests significance of interaction: Difference between effect of Helmet in Rollover group vs. effect of Helmet in No R group: .08 vs. .20.
Between-Subjects Factors
no 320
yes 61
no 137
yes 244
0
1
helmet helmetuse
0
1
rollover rollover
Value Label N
Descriptive Statistics
Dependent Variable: lgiss
.9835 .36049 115
.9033 .35490 205
.9321 .35843 320
.7763 .27251 22
.8194 .32152 39
.8039 .30315 61
.9503 .35529 137
.8899 .35050 244
.9116 .35296 381
rollover rollover0 no
1 yes
Total
0 no
1 yes
Total
0 no
1 yes
Total
helmet helmetuse0 no
1 yes
Total
Mean Std. Deviation N
Levene's Test of Equality of Error Variances a
Dependent Variable: lgiss
.820 3 377 .483F df1 df2 Sig.
Tests the null hypothesis that the error variance of thedependent variable is equal across groups.
Design: Intercept+helmet+rollover+helmet * rollovera.
Tests of Between-Subjects Effects
Dependent Variable: lgiss
1.343b 3 .448 3.670 .012 .028 11.009 .800
143.244 1 143.244 1174.063 .000 .757 1174.063 1.000
1.001 1 1.001 8.202 .004 .021 8.202 .815
.016 1 .016 .133 .715 .000 .133 .065
.180 1 .180 1.474 .225 .004 1.474 .228
45.997 377 .122
363.955 381
47.340 380
SourceCorrected Model
Intercept
helmet
rollover
helmet * rollover
Error
Total
Corrected Total
Type III Sumof Squares df Mean Square F Sig.
Partial EtaSquared
Noncent.Parameter Observed Power
a
Computed using alpha = .05a.
R Squared = .028 (Adjusted R Squared = .021)b.
Profile Plots
Which factor should be the horizontal axis? Both.
Both plots give the same information in different ways. One might be more useful than the other.
Plot 1: Horizontal axis is defined by helmet use.
Different heights of the lines (white ellipses are the marginal means) represent the Rollover effect. You can see that they’re not terribly or consistently different.
Comparison of left side points with right side points (red ellipses are the marginal means) represent the Helmet effect. Larger mean log ISS scores for no helmet group.
Lack of parallelness of lines represent the interaction. They’re crossed, but not so nonparallel as to represent a significant interaction.
helmet use * rollover
Dependent Variable: lgiss
helmet use rollover Mean Std. Error 95% Confidence Interval
Lower Bound Upper Bound
ANOVA via MR and GLM 23 5/14/2023
The marginal means are identical to the observed means because there are no covariates or other factors to control for.

0 no0 no .984 .033 .919 1.048
1 yes .903 .024 .855 .951
1 yes0 no .776 .074 .630 .923
1 yes .819 .056 .709 .929
Plot 2: Horizontal axis defined by Rollover
This plot is probably easier to understand.
Different heights of the lines (red ellipses are the marginal means) represent the helmet effect. They’re quite different in height, reflecting the significant effect.
Heights of the left points vs. the right side points (white ellipses are the marginal meas) represent the rollover effect. Average height above “No” is about the same as average height above “Yes”.
Lack of parallelness represents the interaction. Lines are not parallel but not so different in slope as to represent an interaction although the difference between helmet use and nonuse is numerically (but not significantly) greater for nonrollover accidents. (The opposite of my expectation. OK – I really expected the Rollover accidents to have a greater effect than the NonRoller accidents. Example of post hoc hypothesizing – Monday morning hypotheses.)
ANOVA via MR and GLM 24 5/14/2023

ANOVA via MR and GLM 25 5/14/2023

Analysis of a 2 x 3 Factorial Design using GLM Myers & Well, p. 127
Table 5.1 presents the data for 48 subjects run in a text recall experiment. The scores are percentages of idea units recalled. The data were presented at three different rates - 300, 450, or 600 words per minute. The text was either intact or scrambled.
Rate
Text G1 G2 G3G4 G5 G6
Cell scram rateG1 1 1G2 1 2G3 1 3G4 2 1G5 2 2G6 2 3
ANOVA via MR and GLM 26 5/14/2023
How the data should be entered into SPSSRecall rate scram
72 1 163 1 157 1 152 1 169 1 175 1 168 1 174 1 149 2 171 2 163 2 148 2 168 2 165 2 152 2 163 2 140 3 149 3 136 3 150 3 154 3 146 3 146 3 126 3 165 1 245 1 2
_
Analysis of the 2x3 Equal N Meyers/Well data using GLMGET FILE='E:\MdbT\P595\ANOVAviaMR\Meyers_well p.127.sav'.UNIANOVA dv BY row col /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /PLOT = PROFILE( col*row ) /EMMEANS = TABLES(row) /EMMEANS = TABLES(col) /EMMEANS = TABLES(row*col) /PRINT = DESCRIPTIVE ETASQ OPOWER HOMOGENEITY /PLOT = SPREADLEVEL /CRITERIA = ALPHA(.05) /DESIGN = row col row*col .
Menu Sequence: Analyze -> GLM -> Univariate
Univariate Analysis of Variance
ANOVA via MR and GLM 27 5/14/2023
Col 1 Col 2 Col 3 MarginRow 1 66.25 59.87 43.38 56.50Row 2 54.38 49.75 45.88 50.00Margin: 60.31 54.81 44.63 53.25
Manually created Two-way table of means.
Between-Subjects Factors
24
24
16
16
16
1
2
ROW
1
2
3
COL
N
Descriptive Statistics
Dependent Variable: DV
66.25 8.28 8
59.87 8.92 8
43.38 9.02 8
56.50 12.91 24
54.38 5.83 8
49.75 7.23 8
45.88 7.43 8
50.00 7.46 24
60.31 9.24 16
54.81 9.42 16
44.63 8.09 16
53.25 10.94 48
COL1
2
3
Total
1
2
3
Total
1
2
3
Total
ROW1
2
Total
Mean Std. Dev iation N
Levene's Test of Equality of Error Variances a
Dependent Variable: DV
.774 5 42 .574F df1 df2 Sig.
Tests the null hypothesis that the error variance ofthe dependent variable is equal across groups.
Design: Intercept+ROW+COL+ROW * COLa.

The F associated with the "Corrected Model" above is the same as the F in the REGRESSION ANOVA box when all variables are in the equation. It's simply the significance of the relationship of Y to all of the variables coding main effects and interactions.
The F in the “Intercept” row is the square of the t for the Intercept in the MR. Don’t interpret it.
Observed Power: If the population means were equal to this sample’s means, observed power is the probability you would reject if you took a new sample.
Estimated Marginal Means
ANOVA via MR and GLM 28 5/14/2023
Estimated marginal mean: An estimate of what the mean would be if all scores were equal on all the other factors.
Equal to observed marginal means if 1) cell sizes are equal or 2) if there are no other factors.
These are "estimated" means for each row, column, and cell. Since sample sizes are equal, and there are no other factors, in this case the marginal means are equal to the observed means.
When the interaction is significant, you must use caution in reporting the main effects – because they’re not “main” anymore – each is conditional on the value of the other factor.
Test s of Bet w een- Subj ect s Ef f ect s
Dependent Var iab le: DV
3026. 500b
5 605. 300 9. 791 . 000 . 538 48. 956 1. 000
136107. 000 1 136107. 000 2201. 615 . 000 . 981 2201. 615 1. 000
507. 000 1 507. 000 8. 201 . 007 . 163 8. 201 . 799
2027. 375 2 1013. 688 16. 397 . 000 . 438 32. 794 . 999
492. 125 2 246. 062 3. 980 . 026 . 159 7. 960 . 682
2596. 500 42 61. 821
141730. 000 48
5623. 000 47
Sour c eCor r ec t edM odel
I nt e r c ept
RO W
CO L
RO W * CO L
Er r or
Tot a l
Cor r ec t ed Tot al
Ty pe I I I Sumof Squar es df M ean Squar e F Sig. Et a Squar ed
Nonc ent .Par am et erO bs er v ed Power
a
Com put ed us ing alpha = . 05a.
R Squar ed = . 538 ( Adjus t ed R Squar ed = . 483)b.
1. ROW
Dependent Variable: DV
56.500 1.605 53.261 59.739
50.000 1.605 46.761 53.239
ROW1
2
Mean Std. Error Lower Bound Upper Bound
95% Confidenc e Interv al
2. COL
Dependent Variable: DV
60.313 1.966 56.346 64.279
54.813 1.966 50.846 58.779
44.625 1.966 40.658 48.592
COL1
2
3
Mean Std. Error Lower Bound Upper Bound
95% Confidenc e Interv al
3 . ROW * COL
De p e n d e n t Va ri a b l e : DV
6 6 .2 5 0 2 .7 8 0 6 0 .6 4 0 7 1 .8 6 0
5 9 .8 7 5 2 .7 8 0 5 4 .2 6 5 6 5 .4 8 5
4 3 .3 7 5 2 .7 8 0 3 7 .7 6 5 4 8 .9 8 5
5 4 .3 7 5 2 .7 8 0 4 8 .7 6 5 5 9 .9 8 5
4 9 .7 5 0 2 .7 8 0 4 4 .1 4 0 5 5 .3 6 0
4 5 .8 7 5 2 .7 8 0 4 0 .2 6 5 5 1 .4 8 5
COL1
2
3
1
2
3
ROW1
2
Me a n Std . Erro rL o we r Bo u n dUp p e r Bo u n d
9 5 % Co n f i d e n c e In te rv a l
Spread-versus-Level Plots
Profile Plots
So, words forming text (Row 1) were recalled at a higher rate than words which were scrambled (Row 2) until the rate got so high that neither was recalled well.
ANOVA via MR and GLM 29 5/14/2023
Used to help decide whether variability within each cell increases as mean of a cell increases. If so, a transformation would be recommended.
I see no trend here, so no transformation will be made.
This is a plot of the "estimated" cell means printed in the above table. Since there are no covariates, they're equal to the observed means displayed in the table at the beginning of the output for this analysis.
This plot is the plot recommended for 2-way factorial designs to show in graphical fashion the form of main effects and interactions.
It shows that there was an interaction of the row and col effects: the difference between rows (red minus green) changed across columns - with a large difference favoring Row 1 (red) in columns 1 and 2, and a small or perhaps insignificant difference favoring Row 2 (green) in column 3.
These differences of differences are the interaction. If the differences were all equal, i.e., there were no differences of differences, the interaction would not be significant.
Rate
Spread vs. Level Plot of DV
Groups: ROW * CO L
L e v e l (Me a n )
70605040
Sp
rea
d (
Sta
nd
ard
De
via
tio
n)
9. 5
9. 0
8. 5
8. 0
7. 5
7. 0
6. 5
6. 0
5. 5
Spread vs. Level Plot of DV
Groups: ROW * CO L
L e v e l (Me a n )
70605040
Sp
rea
d (
Va
ria
nc
e)
90
80
70
60
50
40
30
Estimated Marginal Means of DV
COL
321
Es
tim
ate
d M
arg
ina
l M
ea
ns
70
60
50
40
ROW
1
2

Rcmdr Analysis of Myers/Well 2 x 3 Factorial Data – Start 10/2/17Data Import Data From SPSS Dataset . . .
Change independent variables to factors in RcmdrBefore performing an ANOVA using Rcmdr, make sure that all factors (qualitative independent variables) are recognized as “factors” by Rcmdr.
If you’re not sure, simply do the following.
Data Manage Variables in Active Dataset Convert Numeric Variables to Factor . . .
If a variable is already a factor, it will either have (Factor) after its name or it will not appear in the list of variables.
If you see a variable that you wish to be a factor in an ANOVA in the list, select it. Then click on [OK].
If you check [Supply level names], you’ll be asked for a value label for each level. Otherwise, Rcmdr will simply use the values of the variable as the labels.
ANOVA via MR and GLM 30 5/14/2023

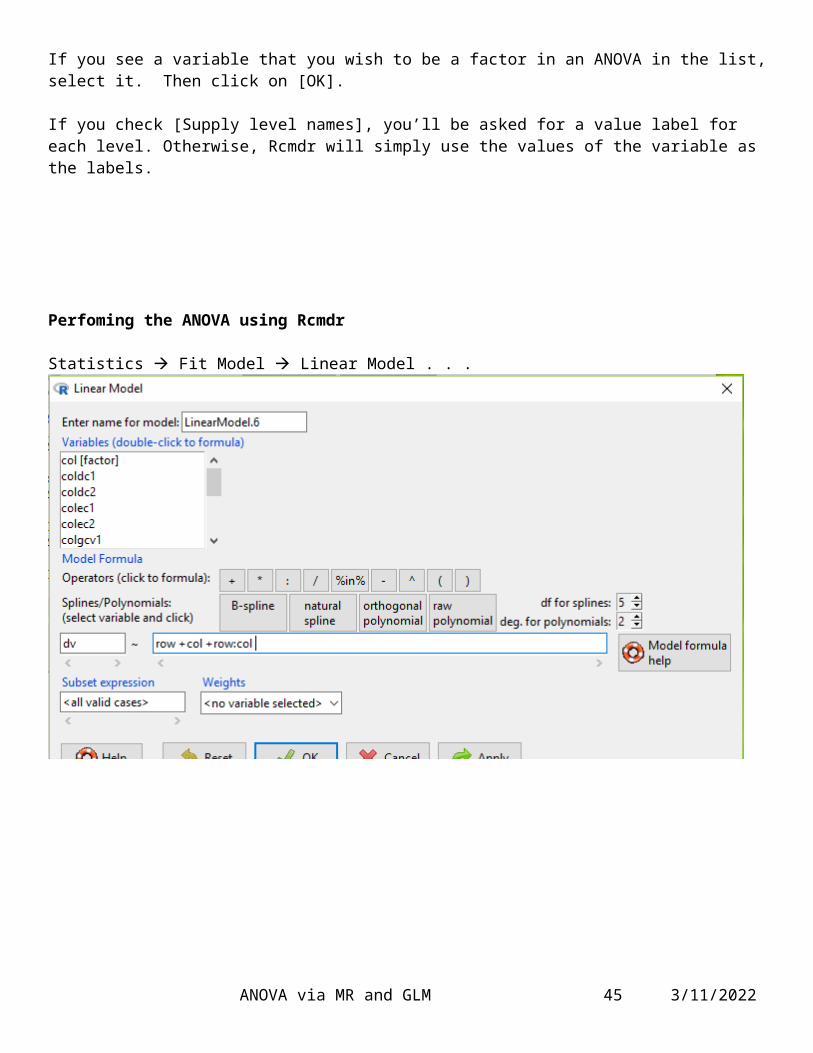
Perfoming the ANOVA using Rcmdr
Statistics Fit Model Linear Model . . .
ANOVA via MR and GLM 31 5/14/2023
I double-clicked on the names in the scrolling field to put them into the Model formula line.
You can simply type them in, if you wish.
R uses A:B to represent the interaction term.

The Rcmdr output, after clicking OK . . .> LinearModel.6 <- lm(dv ~ row +col +row:col, data=MyersWell)
> summary(LinearModel.6)
Call:lm(formula = dv ~ row + col + row:col, data = MyersWell)
Residuals: Min 1Q Median 3Q Max -17.375 -4.781 2.188 5.844 11.125
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 66.250 2.780 23.832 < 2e-16 ***row[T.2] -11.875 3.931 -3.021 0.00428 ** col[T.2] -6.375 3.931 -1.622 0.11238 col[T.3] -22.875 3.931 -5.819 7.24e-07 ***row[T.2]:col[T.2] 1.750 5.560 0.315 0.75450 row[T.2]:col[T.3] 14.375 5.560 2.586 0.01328 * ---Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 7.863 on 42 degrees of freedomMultiple R-squared: 0.5382, Adjusted R-squared: 0.4833 F-statistic: 9.791 on 5 and 42 DF, p-value: 2.963e-06
Argh!! This is not like the GLM “Tests of Between Subjects Effects” output.
Getting Rcmdr to print an ANOVA summary table . . .
The output of the anova command . . .> anova(LinearModel.6)
Analysis of Variance Table
Response: dv Df Sum Sq Mean Sq F value Pr(>F) row 1 507.00 507.00 8.2010 0.006508 ** col 2 2027.38 1013.69 16.3970 5.458e-06 ***row:col 2 492.13 246.06 3.9802 0.026127 * Residuals 42 2596.50 61.82 ---Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Bingo!! – Same values as the GLM table. (page 24)
ANOVA via MR and GLM 32 5/14/2023
I typed anova(LinearModel.6) and then pressed the [Submit] button.
This table is like the Parameters table in SPSS. Each line represents a group coding variable.

Using REGRESSION to perform analyses of Factorial Designs - SkipTo assess each factor, Fs with the following form must be computed
R2All Factors – R2
All except factor of interest, i.e. R2 for just the factor of interest----------------------------------------------------------------------------------Number of GCV’s for factor of interest
FFactor of interest = --------------------------------------------------------------------------------------1 – R2
All Factors
---------------------------------------------------N – Number of GCV’s for all factors – 1
These analyses can be conducted using only the REGRESSION procedure.
To get SPSS REGRESSION to create this F, 0) Request SPSS to print F for R2 change.1) Enter ALL GCV’s, but ignore the output associated with this step.
2) Remove the GCVs for the 1st factor being tested, again ignoring the output associated w. this step.3) Re-enter them. The significance of F change assesses significance of the 1st factor.
4) Remove the GCVs for the 2nd factor.5) Re-enter them. The significance of F change assesses significance of the 2nd factor.
6) Remove the GCVs for the interaction.7) Re-enter them. The significance of F change assesses significance of the interaction.
ANOVA via MR and GLM 33 5/14/2023
Problem – how to get REGRESSION to use this as the denominator

Analysis of the 2x2 Factorial using REGRESSION -skip
The 2x2 coding.
Factor 2: Helmet
Factor 1: Rollover G1 G2G3 G4
Factor 1 (Rollover) compares G1+G2 with G3+G4.Factor 2 (Helmet) compares G1+G3 with G2+G4.Interaction compares G1-G2 with G3-G4, i.e., the contrast is (G1-G2)-(G3-G4).
To make the REGRESSION output identical to the GLM output, you must use contrast codes - no dummy variables or effect coding variables.
Factor 1 Factor 2 InteractionGCV1 GCV2 GCV3
G1 +.5 +.5 +.25G2 +.5 -.5 -.25G3 -.5 +.5 -.25G4 -.5 -.5 +.25
Creating the Contrast coding variables using syntax
recode rollover (0=-.5)(1=+.5) into gcv1.recode helmet (0=-.5)(1=+.5) into gcv2.compute gcv3 = gcv1*gcv2.
variable labels gcv1 "GCV representing ROLLOVER " gcv2 "GCV representing whether HELMET was used" gcv3 "GCV representing interaction of ROLLOVER and HELMET".
Specifying the regression using syntax
The increase in R2 associated with each factor must be tested controlling for all other factors.
This means that each factor must be added to the equation containing all the other factors.Usually this means that a sequential procedure described below must be followed.
The red’d terms below represent the addition of each comparison to the equation containing all the other comparisons.
regression variables = lgiss gcv1 gcv2 gcv3 /descriptives = default corr /statistics = default cha /dep=lgiss /enter gcv1 gcv2 gcv3 /remove gcv3 /enter gcv3/remove gcv2 /enter gcv2 /remove gcv1 /enter gcv1.
Note – each effect – the Row Main Effect, the Col Main Effect, and the Interaction Effect – is represent by a collection of gcvs. In this example, however, each collection has just 1 contrast code.
ANOVA via MR and GLM 34 5/14/2023
Note that I entered gcv3 first. Some analysts will enter the interaction comparison first. If it’s not significant, they’ll leave the gcv for that comparison out of the equation. I chose to leave it in.

The regression output -skip
In the following, the red’d lines represent the entry of each factor into the equation containing all the other factors.
So the significance of the R2 change is assessed for Model 3, 5, and 7.
Variables Entered/Removeda
Model Variables Entered Variables Removed Method
1 gcv3, gcv1, gcv2b . Enter
2 .b gcv3c Remove
3 gcv3b . Enter
4 .b gcv2c Remove
5 gcv2b . Enter
6 .b gcv1c Remove
7 gcv1b . Enter
a. Dependent Variable: lgiss
b. All requested variables entered.
c. All requested variables removed.
ANOVA via MR and GLM 35 5/14/2023
RolloverHELMET
Rollover
HELMET
Descriptive Statistics
.9116 .35296 381
-.3399 .36719 381
.1404 .48051 381
-.0479 .24569 381
lgiss
gcv1 GCV representing HELMET usage
gcv2 GCV representing whether accident involved rollover
gcv3 GCV representing interaction of HELMET and ROLLOVER
Mean Std. Deviation N
Correlations
1.000 -.133 -.082 .071
-.133 1.000 -.001 .209
-.082 -.001 1.000 -.665
.071 .209 -.665 1.000
lgiss
gcv1 GCV representing HELMET usage
gcv2 GCV representing whether accident involved rollover
gcv3 GCV representing interaction of HELMET and ROLLOVER
PearsonCorrelation
lgiss
gcv1 GCVrepresenting
HELMET usage
gcv2 GCVrepresenting
whether accidentinvolved rollover
gcv3 GCVrepresentinginteraction ofHELMET andROLLOVER

-skipModel Summary
Model R R Square Adjusted R
Square
Std. Error of the
Estimate
Change Statistics
R Square
Change
F Change df1 df2 Sig. F Change
1 .168a .028 .021 .34930 .028 3.670 3 377 .012
2 .157b .025 .019 .34951 -.004 1.474 1 377 .225
3 .168c .028 .021 .34930 .004 1.474 1 377 .225
4 .167d .028 .023 .34890 .000 .133 1 377 .715
5 .168e .028 .021 .34930 .000 .133 1 377 .715
6 .085f .007 .002 .35261 -.021 8.202 1 377 .004
7 .168g .028 .021 .34930 .021 8.202 1 377 .004
a. Predictors: (Constant), gcv3, gcv1, gcv2
b. Predictors: (Constant), gcv1, gcv2
c. Predictors: (Constant), gcv1, gcv2, gcv3
d. Predictors: (Constant), gcv1, gcv3
e. Predictors: (Constant), gcv1, gcv3, gcv2
f. Predictors: (Constant), gcv3, gcv2
g. Predictors: (Constant), gcv3, gcv2, gcv1
ANOVAa
Model Sum of Squares df Mean Square F Sig.
ANOVA via MR and GLM 36 5/14/2023
Note that each red p-value is the same as the corresponding p-value in the GLM output above.

1
Regression 1.343 3 .448 3.670 .012b
Residual 45.997 377 .122
Total 47.340 380
2
Regression 1.163 2 .582 4.762 .009c
Residual 46.177 378 .122
Total 47.340 380
3
Regression 1.343 3 .448 3.670 .012d
Residual 45.997 377 .122
Total 47.340 380
4
Regression 1.327 2 .663 5.451 .005e
Residual 46.013 378 .122
Total 47.340 380
5
Regression 1.343 3 .448 3.670 .012f
Residual 45.997 377 .122
Total 47.340 380
6
Regression .343 2 .171 1.378 .253g
Residual 46.998 378 .124
Total 47.340 380
7
Regression 1.343 3 .448 3.670 .012h
Residual 45.997 377 .122
Total 47.340 380
a. Dependent Variable: lgissb. Predictors: (Constant), gcv3, gcv1, gcv2c. Predictors: (Constant), gcv1, gcv2d. Predictors: (Constant), gcv1, gcv2, gcv3e. Predictors: (Constant), gcv1, gcv3f. Predictors: (Constant), gcv1, gcv3, gcv2g. Predictors: (Constant), gcv3, gcv2h. Predictors: (Constant), gcv3, gcv2, gcv1
ANOVA via MR and GLM 37 5/14/2023

-skipIf we’re only interested in the significance of the effects of the two factors and their interaction, then the coefficients box is of little interest to us.
Since each comparison involved on 1 group-coding variable, this analysis could have been done with one equation: an equation with all three GCVs in it, as illustrated by the circled p-values above..
But, the use of only one equation only works for 2 x 2 factorial designs. Any designs with more than 2 levels in a factor would require the sequential projess that I followed above.
The example below illustrates the need to perform the analysis of more complex designs sequentially.
ANOVA via MR and GLM 38 5/14/2023
Note that each time all three GCVs were in the equation, the collection of p-values at the right was the same as the collection of p-values obtained with GLM.
This is because in this particular example, a regression analysis with all 3 GCVs includes the same tests – row main effect, column main effect, and interaction effect - as the GLM analysis.

Analysis of a 2 x 3 Factorial design using REGRESSION -skip
Factorial Designs in which one or more factors has more than 2 levels.
When a one or more of the main effects has more than 2 levels, the analysis using MR gets a little more complicated. This is because the factor with more than 2 levels must be represented by more than 2 or more group-coding variables. And that means that the interaction will also be represented by more than 1 group-coding variable. The result is that the coefficients box will generally NOT give information on the significance of factors in such an analysis.
Example of a 2x3 Factorial
The 2x3 Table
Factor 2
Factor 1 G1 G2 G3G4 G5 G6
The Data Editor
Group Factor 1 Factor 2 InteractionF1GCV F2GCV1 F2GCV2 IntGCV1 IntCGV2
G1 .5 .6667 0 .3333 0G2 .5 -.3333 .5 -.1667 .25G3 .5 -.3333 -.5 -.1667 -.25G4 -.5 .6667 0 -.3333 0G5 -.5 -.3333 .5 .1667 -.25G6 -.5 -.3333 -.5 .1667 .25
Main Effect of Factor 1: Average of G1,G2,G3) vs. Average of G4,G5,G6
Main Effect of Factor 2- 1st Contrast: Average of G1G4 vs Average of G2,G3,G5,G6 - 2nd Contrast: Average of G2,G5 vs. Average of G3,G6
Interaction: 1st Contrast: (G1 – Av of G2,G3) vs. (G4 – Av of G5,G6)
(G1-G2,G3) - (G4-G5,G6)
Is the difference between Col 1 and Col’s 2&3 the same across rows?
2nd Contrast: G2 – G3 vs. G5 – G6
(G2 – G3) – (G5 – G6)
Is the difference between Col 2 and Col3 the same across rows?
Coefficients can be easily gotten by multiplying the main effect coefficients.
ANOVA via MR and GLM 39 5/14/2023

The Myers/Wells data Matrix for Regression analysis with contrast coding -skip
DV ROW COL ROWGCV COLGCV1 COLGCV2 INTGCV1 INTGCV2
72 1 1 .50 .67 .00 .33 .00 63 1 1 .50 .67 .00 .33 .00 57 1 1 .50 .67 .00 .33 .00 52 1 1 .50 .67 .00 .33 .00 69 1 1 .50 .67 .00 .33 .00 75 1 1 .50 .67 .00 .33 .00 68 1 1 .50 .67 .00 .33 .00 74 1 1 .50 .67 .00 .33 .00 49 1 2 .50 -.33 .50 -.17 .25 71 1 2 .50 -.33 .50 -.17 .25 63 1 2 .50 -.33 .50 -.17 .25 48 1 2 .50 -.33 .50 -.17 .25 68 1 2 .50 -.33 .50 -.17 .25 65 1 2 .50 -.33 .50 -.17 .25 52 1 2 .50 -.33 .50 -.17 .25 63 1 2 .50 -.33 .50 -.17 .25 40 1 3 .50 -.33 -.50 -.17 -.25 49 1 3 .50 -.33 -.50 -.17 -.25 36 1 3 .50 -.33 -.50 -.17 -.25 50 1 3 .50 -.33 -.50 -.17 -.25 54 1 3 .50 -.33 -.50 -.17 -.25 46 1 3 .50 -.33 -.50 -.17 -.25 46 1 3 .50 -.33 -.50 -.17 -.25 26 1 3 .50 -.33 -.50 -.17 -.25 65 2 1 -.50 .67 .00 -.33 .00 45 2 1 -.50 .67 .00 -.33 .00 53 2 1 -.50 .67 .00 -.33 .00 53 2 1 -.50 .67 .00 -.33 .00 51 2 1 -.50 .67 .00 -.33 .00 58 2 1 -.50 .67 .00 -.33 .00 53 2 1 -.50 .67 .00 -.33 .00 57 2 1 -.50 .67 .00 -.33 .00 56 2 2 -.50 -.33 .50 .17 -.25 55 2 2 -.50 -.33 .50 .17 -.25 49 2 2 -.50 -.33 .50 .17 -.25 52 2 2 -.50 -.33 .50 .17 -.25 35 2 2 -.50 -.33 .50 .17 -.25 57 2 2 -.50 -.33 .50 .17 -.25 45 2 2 -.50 -.33 .50 .17 -.25 49 2 2 -.50 -.33 .50 .17 -.25 41 2 3 -.50 -.33 -.50 .17 .25 42 2 3 -.50 -.33 -.50 .17 .25 57 2 3 -.50 -.33 -.50 .17 .25 39 2 3 -.50 -.33 -.50 .17 .25 36 2 3 -.50 -.33 -.50 .17 .25 52 2 3 -.50 -.33 -.50 .17 .25 52 2 3 -.50 -.33 -.50 .17 .25 48 2 3 -.50 -.33 -.50 .17 .25_Number of cases read: 48 Number of cases listed: 48
ANOVA via MR and GLM 40 5/14/2023
Used for GLM
Used for Regression
analysis

The regression analysis of the Myers/Well data -skip
regression variables = dv rowgcv colgcv1 colgcv2 intgcv1 intgcv2 /descriptives = default /statistics = default cha /dep=dv /enter rowgcv colgcv1 colgcv2 intgcv1 intgcv2 /remove rowgcv /enter rowgcv /remove colgcv1 colgcv2 /enter colgcv1 colgcv2 /remove intgcv1 intgcv2 /enter intgcv1 intgcv2.
Regression
ANOVA via MR and GLM 41 5/14/2023
Enters all the variables.
The "/descriptives = " subcommand above causes these two boxes of output to be printed.
Descr iptive S tatistics
53.25 10.94 48
.0000 .5053 48
6.939E -18 .4764 48
.0000 .4126 48
-3.4694E -18 .2382 48
.0000 .2063 48
DV
ROW GCV
COLGCV 1
COLGCV 2
INTGCV 1
INTGCV 2
Mean S td. Deviation N
Cor rel at i ons
1. 000 . 300 . 461 . 384 . 176 . 238
. 300 1. 000 . 000 . 000 . 000 . 000
. 461 . 000 1. 000 . 000 . 000 . 000
. 384 . 000 . 000 1. 000 . 000 . 000
. 176 . 000 . 000 . 000 1. 000 . 000
. 238 . 000 . 000 . 000 . 000 1. 000
DV
RO WG CV
CO LG CV1
CO LG CV2
I NTG CV1
I NTG CV2
Pear son Cor r elat ionDV RO WG CV CO LG CV1 CO LG CV2 I NTG CV1 I NTG CV2
Var iables Entered/Removed c
INTGCV2,INTGCV1,COLGCV2,COLGCV1,ROWGCV
a
. Enter
.a ROWGCVb Remove
ROWGCVa . Enter
.a COLGCV2,
COLGCV1b Remove
COLGCV2,COLGCV1
a . Enter
.a INTGCV2,
INTGCV1b Remove
INTGCV2,INTGCV1
a . Enter
Model1
2
3
4
5
6
7
VariablesEntered
VariablesRemoved Method
All requested variables entered.a.
All requested variables removed.b.
Dependent Variable: DVc.

-skip
ANOVA via MR and GLM 42 5/14/2023
Row main effect
Col main effect
Interaction effect
Not of any use in this analysis.
Overall ANOVA
ANOVA g
3026. 500 5 605. 300 9. 791 . 000a
2596. 500 42 61. 821
5623. 000 47
2519. 500 4 629. 875 8. 727 . 000b
3103. 500 43 72. 174
5623. 000 47
3026. 500 5 605. 300 9. 791 . 000a
2596. 500 42 61. 821
5623. 000 47
999. 125 3 333. 042 3. 169 . 034c
4623. 875 44 105. 088
5623. 000 47
3026. 500 5 605. 300 9. 791 . 000d
2596. 500 42 61. 821
5623. 000 47
2534. 375 3 844. 792 12. 035 . 000e
3088. 625 44 70. 196
5623. 000 47
3026. 500 5 605. 300 9. 791 . 000f
2596. 500 42 61. 821
5623. 000 47
Regression
Residual
Tot al
Regression
Residual
Tot al
Regression
Residual
Tot al
Regression
Residual
Tot al
Regression
Residual
Tot al
Regression
Residual
Tot al
Regression
Residual
Tot al
Model1
2
3
4
5
6
7
Sum ofSquares df Mean Square F Sig.
Predict ors: (Const ant ) , I NTGCV2, I NTGCV1, COLGCV2, COLGCV1,ROWGCV
a.
Predict ors: (Const ant ) , I NTGCV2, I NTGCV1, COLGCV2, COLGCV1b.
Predict ors: (Const ant ) , I NTGCV2, I NTGCV1, ROWGCVc.
Predict ors: (Const ant ) , I NTGCV2, I NTGCV1, ROWGCV, COLGCV2,COLGCV1
d.
Predict ors: (Const ant ) , ROWGCV, COLGCV2, COLGCV1e.
Predict ors: (Const ant ) , ROWGCV, COLGCV2, COLGCV1, I NTGCV2,I NTGCV1
f .
Dependent Variable: DVg.

-skip
Models 3,5, and 7 are all identical. Each has all variables in the equation. The change in R2 when going from Model 2 to 3, or Model 4 to 5, or Model 6 to 7, tests the significance of one of the effects in the factorial design - either a main effect or the interaction effect. If your only interest is in those effects, then the coefficients box won't be of interest to you. You might be interested in the significance of one or more of the individual GCV's presented here, though.
ANOVA via MR and GLM 43 5/14/2023WHEW!!
Not of much use in this analysis.
Co e ffic ie n tsa
5 3 .2 5 0 1 .1 3 5 4 6 .9 2 1 .0 0 0
6 .5 0 0 2 .2 7 0 .3 0 0 2 .8 6 4 .0 0 7
1 4 .1 2 5 3 .2 1 0 .4 6 1 4 .4 0 0 .0 0 0
1 0 .1 8 8 2 .7 8 0 .3 8 4 3 .6 6 5 .0 0 1
1 0 .7 5 0 6 .4 2 0 .1 7 6 1 .6 7 4 .1 0 1
1 2 .6 2 5 5 .5 6 0 .2 3 8 2 .2 7 1 .0 2 8
5 3 .2 5 0 1 .2 2 6 4 3 .4 2 6 .0 0 0
1 4 .1 2 5 3 .4 6 8 .4 6 1 4 .0 7 3 .0 0 0
1 0 .1 8 8 3 .0 0 4 .3 8 4 3 .3 9 2 .0 0 2
1 0 .7 5 0 6 .9 3 7 .1 7 6 1 .5 5 0 .1 2 9
1 2 .6 2 5 6 .0 0 7 .2 3 8 2 .1 0 2 .0 4 1
5 3 .2 5 0 1 .1 3 5 4 6 .9 2 1 .0 0 0
6 .5 0 0 2 .2 7 0 .3 0 0 2 .8 6 4 .0 0 7
1 4 .1 2 5 3 .2 1 0 .4 6 1 4 .4 0 0 .0 0 0
1 0 .1 8 8 2 .7 8 0 .3 8 4 3 .6 6 5 .0 0 1
1 0 .7 5 0 6 .4 2 0 .1 7 6 1 .6 7 4 .1 0 1
1 2 .6 2 5 5 .5 6 0 .2 3 8 2 .2 7 1 .0 2 8
5 3 .2 5 0 1 .4 8 0 3 5 .9 8 8 .0 0 0
6 .5 0 0 2 .9 5 9 .3 0 0 2 .1 9 6 .0 3 3
1 0 .7 5 0 8 .3 7 0 .1 7 6 1 .2 8 4 .2 0 6
1 2 .6 2 5 7 .2 4 9 .2 3 8 1 .7 4 2 .0 8 9
5 3 .2 5 0 1 .1 3 5 4 6 .9 2 1 .0 0 0
6 .5 0 0 2 .2 7 0 .3 0 0 2 .8 6 4 .0 0 7
1 4 .1 2 5 3 .2 1 0 .4 6 1 4 .4 0 0 .0 0 0
1 0 .1 8 8 2 .7 8 0 .3 8 4 3 .6 6 5 .0 0 1
1 0 .7 5 0 6 .4 2 0 .1 7 6 1 .6 7 4 .1 0 1
1 2 .6 2 5 5 .5 6 0 .2 3 8 2 .2 7 1 .0 2 8
5 3 .2 5 0 1 .2 0 9 4 4 .0 3 4 .0 0 0
6 .5 0 0 2 .4 1 9 .3 0 0 2 .6 8 7 .0 1 0
1 4 .1 2 5 3 .4 2 0 .4 6 1 4 .1 3 0 .0 0 0
1 0 .1 8 8 2 .9 6 2 .3 8 4 3 .4 3 9 .0 0 1
5 3 .2 5 0 1 .1 3 5 4 6 .9 2 1 .0 0 0
6 .5 0 0 2 .2 7 0 .3 0 0 2 .8 6 4 .0 0 7
1 4 .1 2 5 3 .2 1 0 .4 6 1 4 .4 0 0 .0 0 0
1 0 .1 8 8 2 .7 8 0 .3 8 4 3 .6 6 5 .0 0 1
1 0 .7 5 0 6 .4 2 0 .1 7 6 1 .6 7 4 .1 0 1
1 2 .6 2 5 5 .5 6 0 .2 3 8 2 .2 7 1 .0 2 8
(Co n s ta n t )
ROW GCV
COL GCV1
COL GCV2
INT GCV1
INT GCV2
(Co n s ta n t )
ROW GCV
COL GCV1
COL GCV2
INT GCV1
INT GCV2
(Co n s ta n t )
ROW GCV
COL GCV1
COL GCV2
INT GCV1
INT GCV2
(Co n s ta n t )
ROW GCV
COL GCV1
COL GCV2
INT GCV1
INT GCV2
(Co n s ta n t )
ROW GCV
COL GCV1
COL GCV2
INT GCV1
INT GCV2
(Co n s ta n t )
ROW GCV
COL GCV1
COL GCV2
INT GCV1
INT GCV2
(Co n s ta n t )
ROW GCV
COL GCV1
COL GCV2
INT GCV1
INT GCV2
Mo d e l1
2
3
4
5
6
7
B Std . E rro r
Un s ta n d a rd i z e dCo e f f i c i e n t s
Be ta
Sta n d a rdi z e d
Co e f f i c i en ts
t S i g .
De p e n d e n t Va ri a b l e : DVa .

19961997
19981999
20002001
year
300275250225200175
part 1 scores
-The MEDRES Dataset – A 2x6 Factorial Design Example Included because it illustrates use of built-in orthogonal polynomialsThis example concerns the issue of quality of surgery residents over the years. There was talk that quality of surgical residents has been decreasing. To address this issue, a doctor at a local hospital conducted a survey of resident programs throughout the nation. The survey requested information on residents’ academic credentials. Of interest here are PART1 scores, scores on the major part of a GRE-like exam taken by all residents, and AOA member qualification, whether the resident was in the top 10% of his/her class.
Six years’ worth of data were collected from the survey responses. The distributions of PART1 scores for all six years is given below. Be sure to understand that each year represents a different group of residents.
The distributions of AOA scores (1=In top 10%, 0=Not) is below.
The interest of the investigators was in changes, if any, across years. There was also an interest in any differences that might exist between small programs and large programs.
Thus, this is a 6 (Year) x 2 (Progsize) factorial design problem with two dependent variables – PART1 scores and AOA.
ANOVA via MR and GLM 44 5/14/2023
aoa aoa * year Crosstabulation
% within year
70.1% 71.4% 71.6% 77.5% 84.4% 84.4% 76.7%
29.9% 28.6% 28.4% 22.5% 15.6% 15.6% 23.3%
100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0%
0 no
1 yes
aoa aoa
Total
1996 1997 1998 1999 2000 2001
year
Total
Specifying the GLM Analysis of PART1 scores from the MEDRES Data
ANOVA via MR and GLM 45 5/14/2023
The main dialog box.
Tells GLM that PART1 is the dependent variable.
YEAR and PROGSIZE are the two independent variables, i.e., factors.
These are fixed factors. That is, all of their values are included in the data.
The Options dialog box.
Have GLM compute estimated marginal means for each factor and for each cell if possible.
I checked the “Compare main effects” box to see what GLM output will result.
Have GLM display descriptive statistics and effect size and power estimates.

The GLM Output
First, the syntax resulting from all the above pulldowns.
UNIANOVA part1 BY year progsize /CONTRAST (year)=Polynomial /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /POSTHOC = year ( BTUKEY ) /PLOT = PROFILE( year*progsize ) /EMMEANS = TABLES(year) COMPARE ADJ(LSD) /EMMEANS = TABLES(progsize) COMPARE ADJ(LSD) /EMMEANS = TABLES(year*progsize) /PRINT = DESCRIPTIVE ETASQ OPOWER /CRITERIA = ALPHA(.05) /DESIGN = year progsize year*progsize .
ANOVA via MR and GLM 46 5/14/2023
The Post Hoc dialog box.
Since PROGSIZE is a dichotomy, it makes no sense to ask for post hoc comparisons for it.
But YEAR is 6-valued, so we can, although we’ll be focusing on the components of trend requested below.
The Contrasts dialog box.
I’ve requested that GLM test for linear, quadratic, cubic, etc. trends across the six years. The method will be that of orthogonal polynomials. Thankfully, we don’t have to look up and enter the coefficients – they’re built into the program. All we do is ask for Polynomial contrasts.

Univariate Analysis of Variance
ANOVA via MR and GLM 47 5/14/2023
The descriptive statistics requested by clicking on Options and checking the Descriptive Statistics box.
Examination of means doesn’t suggest a clear trend over years. There is, however, a large numeric difference between small and large programs.
Between-Subjects Factors
196
206
204
212
212
211
4 or fewerresidents
502
5 or moreresidents
739
1996
1997
1998
1999
2000
2001
year
0
1
progsize
Value Label N
Descriptive Statistics
Dependent Variable: part1 part 1 scores
209.35 17.515 80
222.02 14.435 116
216.85 16.915 196
211.37 13.107 83
220.59 17.330 123
216.88 16.371 206
214.38 16.420 85
222.39 17.567 119
219.05 17.512 204
212.58 15.282 84
221.88 15.804 128
218.20 16.217 212
219.26 16.777 88
225.80 16.415 124
223.08 16.839 212
214.79 17.689 82
224.41 17.542 129
220.67 18.175 211
213.70 16.422 502
222.87 16.606 739
219.16 17.127 1241
progsize0 4 or fewer residents
1 5 or more residents
Total
0 4 or fewer residents
1 5 or more residents
Total
0 4 or fewer residents
1 5 or more residents
Total
0 4 or fewer residents
1 5 or more residents
Total
0 4 or fewer residents
1 5 or more residents
Total
0 4 or fewer residents
1 5 or more residents
Total
0 4 or fewer residents
1 5 or more residents
Total
year1996
1997
1998
1999
2000
2001
Total
Mean Std. Deviation N

What follows is the basic output of GLM – the tests of differences associated with the between-subjects factors.
Starting at the top . . .
Corrected Model: This is the overall ANOVA in that we’ve seen in REGRESSION output. It’s a test of the significance of the relationship of the DV to ALL the group-coding variables created internally by GLM to represent the two factors and their interaction – all 5+1+5 = 11 of them. The conclusion is that PART1 scores are related to the factors.
Intercept. This is a test of the null hypothesis that in the population the intercept of the regression of the DV onto the group-coding variables representing the factors is 0.
Year. The Year line tests the significance of the relationship of the DV to the 5 group-coding variables created to represent the YEAR factor. There are significant differences in mean PART1 scores across years. (Use Tests of Contrasts below to see in which direction.)
Progsize The Progsize line tests the significance of the relationship of the DV to the 1 group-coding variable created to represent the PROGSIZE factor. There is a significant difference in mean PART1 scores between small and large programs. (Looking at the graphs below shows that larger programs have higher mean.)
Year * Progsize This line tests the significance of the relationship of the DV to the 5 product variables created to represent the interaction of YEAR and PROGSIZE. Its nonsignificance means that the change across years is the same for small and large programs.
Error. The Error line represents the denominator of the F ratio used to test all the hypotheses.
Partial Eta squared column. The entries in this column are estimates of effect size. See 510/511 notes for explanations. It can be reported if a journal wants effect sizes. .020 is small. .071 is medium to large.
Noncent Parameter The noncentrality parameter is a quantity that is used to compute power. It is not reported.
Observed Power. The entries in this column give the probability of rejecting the null with a new sample if the population values were equal to those found in this sample.
ANOVA via MR and GLM 48 5/14/2023
Tests of Between-Subjects Effects
Dependent Variable: part1 part 1 scores
32289.485b 11 2935.408 10.884 .000 .089 119.724 1.000
56887237.743 1 56887237.743 210928.054 .000 .994 210928.054 1.000
6615.688 5 1323.138 4.906 .000 .020 24.530 .983
25421.258 1 25421.258 94.258 .000 .071 94.258 1.000
1012.640 5 202.528 .751 .585 .003 3.755 .273
331460.960 1229 269.700
59971422.000 1241
363750.445 1240
SourceCorrected Model
Intercept
year
progsize
year * progsize
Error
Total
Corrected Total
Type III Sum ofSquares df Mean Square F Sig.
Partial EtaSquared
Noncent.Parameter Observed Power
a
Computed using alpha = .05a.
R Squared = .089 (Adjusted R Squared = .081)b.

Custom Hypothesis Tests – Results for the orthogonal polynomials
ANOVA via MR and GLM 49 5/14/2023
The Custom Hypothesis Tests box gives the results of contrasts you have specified by clicking on the Contrasts button in the main dialog box.
Here the linear trend is significant and the contrast estimate is positive, suggesting that mean PART1 scores increased over the 6-year period.
The 5th order contrast is also marginally significant. I would ignore it as a chance result.
Contrast Results (K Matrix)
4.551
0
4.551
1.171
.000
2.254
6.848
-.498
0
-.498
1.170
.671
-2.792
1.797
-1.612
0
-1.612
1.162
.166
-3.892
.668
-1.704
0
-1.704
1.158
.141
-3.976
.568
-2.541
0
-2.541
1.159
.029
-4.815
-.268
Contrast Estimate
Hypothesized Value
Difference (Estimate - Hypothesized)
Std. Error
Sig.
Lower Bound
Upper Bound
95% Confidence Intervalfor Difference
Contrast Estimate
Hypothesized Value
Difference (Estimate - Hypothesized)
Std. Error
Sig.
Lower Bound
Upper Bound
95% Confidence Intervalfor Difference
Contrast Estimate
Hypothesized Value
Difference (Estimate - Hypothesized)
Std. Error
Sig.
Lower Bound
Upper Bound
95% Confidence Intervalfor Difference
Contrast Estimate
Hypothesized Value
Difference (Estimate - Hypothesized)
Std. Error
Sig.
Lower Bound
Upper Bound
95% Confidence Intervalfor Difference
Contrast Estimate
Hypothesized Value
Difference (Estimate - Hypothesized)
Std. Error
Sig.
Lower Bound
Upper Bound
95% Confidence Intervalfor Difference
year PolynomialContrast
a
Linear
Quadratic
Cubic
Order 4
Order 5
part1 part 1 scores
DependentVariable
Metric = 1.000, 2.000, 3.000, 4.000, 5.000, 6.000a.
Test Results
Dependent Variable: part1 part 1 scores
6615.688 5 1323.138 4.906 .000 .020 24.530 .983
331460.960 1229 269.700
SourceContrast
Error
Sum of Squares df Mean Square F Sig.Partial EtaSquared
Noncent.Parameter Observed Power
a
Computed using alpha = .05a.

Estimated Marginal Means 1. year
ANOVA via MR and GLM 50 5/14/2023
The estimated marginal means are computed controlling for the other factor, PROGSIZE.
They’re computed assuming that each YEAR has the same mix of small and large programs.
So these Estimated Marginal Means will be different than the Obtained means printed in the Descriptives output section.
This output is the result of checking the “Compare Main Effects” box.
Mean at each level is compared with the mean at every other level.
Don’t request this output unless you know what you’re doing.
Obligatory aggregation of the above specific comparisons into a single overall test.
Estimates
Dependent Variable: part1 part 1 scores
215.684 1.193 213.342 218.025
215.983 1.166 213.695 218.272
218.386 1.166 216.098 220.674
217.233 1.153 214.971 219.495
222.530 1.145 220.284 224.775
219.602 1.160 217.327 221.877
year1996
1997
1998
1999
2000
2001
Mean Std. Error Lower Bound Upper Bound
95% Confidence Interval
Pairwise Comparisons
Dependent Variable: part1 part 1 scores
-.300 1.669 .857 -3.574 2.974
-2.702 1.668 .106 -5.976 .571
-1.549 1.659 .351 -4.805 1.706
-6.846* 1.653 .000 -10.090 -3.602
-3.918* 1.664 .019 -7.183 -.653
.300 1.669 .857 -2.974 3.574
-2.402 1.649 .146 -5.638 .834
-1.250 1.640 .446 -4.467 1.968
-6.546* 1.634 .000 -9.752 -3.340
-3.618* 1.645 .028 -6.845 -.391
2.702 1.668 .106 -.571 5.976
2.402 1.649 .146 -.834 5.638
1.153 1.640 .482 -2.065 4.370
-4.144* 1.634 .011 -7.350 -.939
-1.216 1.645 .460 -4.443 2.011
1.549 1.659 .351 -1.706 4.805
1.250 1.640 .446 -1.968 4.467
-1.153 1.640 .482 -4.370 2.065
-5.297* 1.625 .001 -8.484 -2.109
-2.369 1.635 .148 -5.577 .840
6.846* 1.653 .000 3.602 10.090
6.546* 1.634 .000 3.340 9.752
4.144* 1.634 .011 .939 7.350
5.297* 1.625 .001 2.109 8.484
2.928 1.629 .073 -.269 6.125
3.918* 1.664 .019 .653 7.183
3.618* 1.645 .028 .391 6.845
1.216 1.645 .460 -2.011 4.443
2.369 1.635 .148 -.840 5.577
-2.928 1.629 .073 -6.125 .269
(J) year1997
1998
1999
2000
2001
1996
1998
1999
2000
2001
1996
1997
1999
2000
2001
1996
1997
1998
2000
2001
1996
1997
1998
1999
2001
1996
1997
1998
1999
2000
(I) year1996
1997
1998
1999
2000
2001
MeanDifference (I-J) Std. Error Sig.
aLower Bound Upper Bound
95% Confidence Interval forDifference
a
Based on estimated marginal means
The mean difference is significant at the .05 level.*.
Adjustment for multiple comparisons: Least Significant Difference(equivalent to no adjustments).
a.
Univariate Tests
Dependent Variable: part1 part 1 scores
6615.688 5 1323.138 4.906 .000 .020 24.530 .983
331460.960 1229 269.700
Contrast
Error
Sum of Squares df Mean Square F Sig.Partial EtaSquared
Noncent.Parameter Observed Power
a
The F tests the effect of year. This test is based on the linearly independent pairwise comparisons among theestimated marginal means.
Computed using alpha = .05a.

Estimated Marginal Means 2. progsize
ANOVA via MR and GLM 51 5/14/2023
This output is the result of checking the “Compare Main Effects” box.
Mean at each level is compared with the mean at every other level.
Don’t request this output unless you know what you’re doing.
Estimates
Dependent Variable: part1 part 1 scores
213.623 .733 212.184 215.062
222.850 .605 221.664 224.036
progsize0 4 or fewerresidents
1 5 or moreresidents
Mean Std. Error Lower Bound Upper Bound
95% Confidence Interval
Pairwise Comparisons
Dependent Variable: part1 part 1 scores
-9.227* .950 .000 -11.091 -7.362
9.227* .950 .000 7.362 11.091
(J) progsize1 5 or moreresidents
0 4 or fewerresidents
(I) progsize0 4 or fewerresidents
1 5 or moreresidents
MeanDifference (I-J) Std. Error Sig.
aLower Bound Upper Bound
95% Confidence Interval forDifference
a
Based on estimated marginal means
The mean difference is significant at the .05 level.*.
Adjustment for multiple comparisons: Least Significant Difference (equivalent to no adjustments).a.
Univariate Tests
Dependent Variable: part1 part 1 scores
25421.258 1 25421.258 94.258 .000 .071 94.258 1.000
331460.960 1229 269.700
Contrast
Error
Sum of Squares df Mean Square F Sig.Partial EtaSquared
Noncent.Parameter Observed Power
a
The F tests the effect of progsize. This test is based on the linearly independent pairwise comparisons among theestimated marginal means.
Computed using alpha = .05a.
3. year * progsize
Dependent Variable: part1 part 1 scores
209.350 1.836 205.748 212.952
222.017 1.525 219.026 225.009
211.373 1.803 207.837 214.910
220.593 1.481 217.688 223.499
214.376 1.781 210.882 217.871
222.395 1.505 219.441 225.348
212.583 1.792 209.068 216.099
221.883 1.452 219.035 224.731
219.261 1.751 215.827 222.696
225.798 1.475 222.905 228.692
214.793 1.814 211.235 218.351
224.411 1.446 221.574 227.248
progsize0 4 or fewerresidents
1 5 or moreresidents
0 4 or fewerresidents
1 5 or moreresidents
0 4 or fewerresidents
1 5 or moreresidents
0 4 or fewerresidents
1 5 or moreresidents
0 4 or fewerresidents
1 5 or moreresidents
0 4 or fewerresidents
1 5 or moreresidents
year1996
1997
1998
1999
2000
2001
Mean Std. Error Lower Bound Upper Bound
95% Confidence Interval

Post Hoc Tests
year
Homogeneous Subsets
ANOVA via MR and GLM 52 5/14/2023
In view of the significant linear trend found above, the post hoc tests are kind of meaningless.
These are identical to the observed cell means.
If there had been quantitative covariates, they would not have been identical to the observed means.
part1 part 1 scores
Tukey Ba,b,c
196 216.85
206 216.88
212 218.20
204 219.05 219.05
211 220.67 220.67
212 223.08
year1996
1997
1999
1998
2001
2000
N 1 2
Subset
Means for groups in homogeneous subsets are displayed.Based on Type III Sum of SquaresThe error term is Mean Square(Error) = 269.700.
Uses Harmonic Mean Sample Size = 206.671.a.
The group sizes are unequal. The harmonic mean of thegroup sizes is used. Type I error levels are not guaranteed.
b.
Alpha = .05.c.

Analysis of AOA scores.Because the AOA scores are dichotomies, they should be analyzed using Logistic Regression. The results of the analysis using GLM will be presented here for comparison with logistic regression results when we cover it in a few weeks..UNIANOVA aoa BY year progsize /CONTRAST (year)=Polynomial /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /POSTHOC = year ( BTUKEY ) /PLOT = PROFILE( year*progsize ) /EMMEANS = TABLES(year) COMPARE ADJ(LSD) /EMMEANS = TABLES(progsize) COMPARE ADJ(LSD) /EMMEANS = TABLES(year*progsize) /PRINT = DESCRIPTIVE ETASQ OPOWER /CRITERIA = ALPHA(.05) /DESIGN = year progsize year*progsize .
Univariate Analysis of Variance
ANOVA via MR and GLM 53 5/14/2023
Skip in Fall 10, Fall 11, Fall 13, Fall 14, Fall 15, Fall 16, Fall17 Fall18
Between-Subjects Factors
201
206
204
213
211
212
4 or fewerresidents
504
5 or moreresidents
743
1996
1997
1998
1999
2000
2001
year
0
1
progsize
Value Label N
Descriptive Statistics
Dependent Variable: aoa aoa
.13 .343 82
.41 .494 119
.30 .459 201
.10 .297 83
.41 .495 123
.29 .453 206
.13 .338 85
.39 .491 119
.28 .452 204
.11 .311 84
.30 .461 129
.23 .419 213
.08 .272 88
.21 .410 123
.16 .364 211
.09 .281 82
.20 .402 130
.16 .363 212
.11 .307 504
.32 .467 743
.23 .423 1247
progsize0 4 or fewerresidents
1 5 or moreresidents
Total
0 4 or fewerresidents
1 5 or moreresidents
Total
0 4 or fewerresidents
1 5 or moreresidents
Total
0 4 or fewerresidents
1 5 or moreresidents
Total
0 4 or fewerresidents
1 5 or moreresidents
Total
0 4 or fewerresidents
1 5 or moreresidents
Total
0 4 or fewerresidents
1 5 or moreresidents
Total
year1996
1997
1998
1999
2000
2001
Total
Mean Std. Deviation N

Note that the YEAR and PROGSIZE factors are both significant, and that the YEAR*PROGSIZE interaction is nearly significant.
The “almost” interaction will appear in the plots below.
ANOVA via MR and GLM 54 5/14/2023
Tests of Between-Subjects Effects
Dependent Variable: aoa aoa
20.254b
11 1.841 11.211 .000 .091 123.316 1.000
54.923 1 54.923 334.403 .000 .213 334.403 1.000
3.480 5 .696 4.238 .001 .017 21.191 .963
14.152 1 14.152 86.165 .000 .065 86.165 1.000
1.726 5 .345 2.102 .063 .008 10.510 .701
202.839 1235 .164
291.000 1247
223.092 1246
SourceCorrectedModel
Intercept
year
progsize
year * progsize
Error
Total
Corrected Total
Type III Sumof Squares df Mean Square F Sig.
Partial EtaSquared
Noncent.Parameter Observed Power
a
Computed using alpha = .05a.
R Squared = .091 (Adjusted R Squared = .083)b.

Custom Hypothesis Tests
ANOVA via MR and GLM 55 5/14/2023
Contrast Results (K Matrix)
-.124
0
-.124
.029
.000
-.181
-.068
-.021
0
-.021
.029
.470
-.077
.036
.026
0
.026
.029
.364
-.030
.082
.028
0
.028
.029
.333
-.028
.084
-.010
0
-.010
.029
.733
-.066
.046
Contrast Estimate
Hypothesized Value
Difference (Estimate - Hypothesized)
Std. Error
Sig.
Lower Bound
Upper Bound
95% Confidence Intervalfor Difference
Contrast Estimate
Hypothesized Value
Difference (Estimate - Hypothesized)
Std. Error
Sig.
Lower Bound
Upper Bound
95% Confidence Intervalfor Difference
Contrast Estimate
Hypothesized Value
Difference (Estimate - Hypothesized)
Std. Error
Sig.
Lower Bound
Upper Bound
95% Confidence Intervalfor Difference
Contrast Estimate
Hypothesized Value
Difference (Estimate - Hypothesized)
Std. Error
Sig.
Lower Bound
Upper Bound
95% Confidence Intervalfor Difference
Contrast Estimate
Hypothesized Value
Difference (Estimate - Hypothesized)
Std. Error
Sig.
Lower Bound
Upper Bound
95% Confidence Intervalfor Difference
year PolynomialContrast
a
Linear
Quadratic
Cubic
Order 4
Order 5
aoa aoa
Dependent
Variable
Metric = 1.000, 2.000, 3.000, 4.000, 5.000, 6.000a.
Test Results
Dependent Variable: aoa aoa
3.480 5 .696 4.238 .001 .017 21.191 .963
202.839 1235 .164
SourceContrast
Error
Sum of Squares df Mean Square F Sig.Partial EtaSquared
Noncent.Parameter Observed Power
a
Computed using alpha = .05a.

Profile Plots
We won’t try this one using REGRESSION. Although the procedure is straightforward, it’s quite tedious.
ANOVA via MR and GLM 56 5/14/2023

Review of main tests conducted in Factorial Designs – skipped in 2017, 2018
The data below represent a 2 (row) by 3 (column) factorial design.
Participants were shown lists of words. Some were intact words, others were scrambled. So the row factor is “Intactness”?? The data were presented at three different rates - 300, 450, or 600 words per minute. So the column factor is Rate. The scores are percentages of idea units recalled.
Effects tested in factorial designs
When data have been gathered in a 2 way factorial design, the following questions are usually asked. (But remember, the fact that the data were gathered factorially doesn’t mean that you have to analyze them factorially.)
1. Is there a main effect of the first factor. Is the DV averaged across levels of the 2nd factor related to changes in levels of the 1st factor. This will involve comparison of 50.0 vs. 56.5 from the above example.
2. Is there a main effect of the 2nd factor? Is the DV averaged across levels of the 1st factor related to changes in levels of the 2nd factor. E.g., is the mean of Column 1 significantly different from the mean of column 2? This will involve comparisons of 60.3125, 54.8125, and 44.6250 in the above.
3 Is there an interaction of the effects of the 1st and 2nd factors. Does the relationship of the DV to the 1st factor change as levels of the 2nd factor change? Do differences between Row means change from one column to the next? If so, there is an interaction. (Alternatively, do differences between Column means change from one row to the next?) This will involve comparing the difference 66.250-54.375 with 59.875-49.75 with 43.375-45.875. If the differences are consistent, there is no interaction. If the differences are different, then there IS an interaction.
ANOVA via MR and GLM 57 5/14/2023
Is number of words recalled affected by Rate of presentation and Intactness of the words?

Higher order factorial designs.
With higher order factorial designs, even more questions involving interactions can be asked . . .
For a 3 way factorial design1. We test the main effect of Factor A2. We test the main effect of Factor B3. We test the main effect of Factor C4. We test the interaction of factors A & B. Is the effect of A the same across levels of B, or vice versa?5. We test the interaction of factors A & C. Is the effect of A the same across levels of C or vice versa?6. We test the interaction of factors B & C. Is the effect of B the same across levels of C or vice versa?7. We test the interaction of all factors: ABC Is the interaction of A and B different at different levels of C?
Significance Testing – a review
The general form of a significance test in MR
R2 Factor being tested + Factors controlled for – R2 Factors controlled for
---------------------------------------------------------------------Number of variables representing factor being tested.
F = --------------------------------------------------------------------------1 – R2
All variables
---------------------------------------------------------------------N – All variables – 1
The numerator
The numerator of the numerator:: R2 Factor being tested + Factors controlled for – R2 Factors to be controlled for
It’s the change (i.e., increase) in R2 due to the addition of the variable or variables representing the factor being tested. It’s the increase over and above R2 for another set of variables – those representing the factors being controlled for.
So, for example, if I have two factors, A and B, and I want to test the significance of Factor A, controlling for Factor B, the numerator of the F statistics will be
R2A + B – R2 B
If I have 3 factors and want to test the significance of A controlling for both B and C, then the numerator will be R2
A + B + C – R2 B + C
The significance of a variable or factor is always assessed by determining if it adds to R2 over and above a base. If we’re controlling for other variables, the R2 obtained when they’re in the equation is the base. If we’re not controlling for anything, then 0 is the base.
Note that the numerator is an increase in R2, from R2 associated with the base to R2 associated with the base PLUS the variable being tested.
The denominator
The denominator of the F statistic is 1 – R2All variables.
This quantity should represent random variability in the dependent variable. It’s the proportion of variance left over when we take out all the predictability associated with the variables we’re studying. The smaller it is, the greater the chance that the F will be significant.
ANOVA via MR and GLM 58 5/14/2023


















