DGXDeep Dive GTC DC 2017 - GPU Technology...
20
DGX Deep Dive GTC DC 2017
Transcript of DGXDeep Dive GTC DC 2017 - GPU Technology...

DGX Deep DiveGTC DC 2017

2
DGX-1 launch
OpenAI
THE FIRST YEAR IN REVIEW: DGX-1Barriers Toppled, the Unsolvable Solved – a Sampling of DGX-1 Impact
April2016
April2017
UC Berkley CSIRO MIT CMU Fidelity Skymind RIKEN
NYU Mass. General Hosp. DFK
IDSIA
Microsoft Nimbix
Noodle.ai
SAP NVIDIASATURNV launch
3
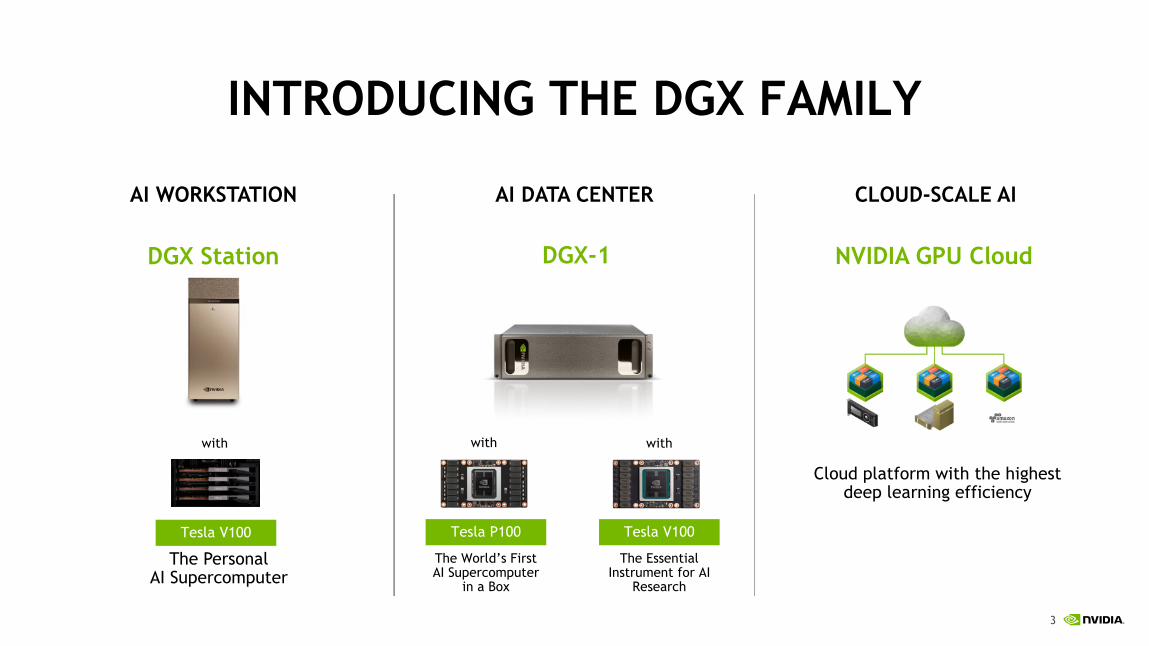
INTRODUCING THE DGX FAMILY
AI WORKSTATION
The Personal AI Supercomputer
CLOUD-SCALE AIAI DATA CENTER
The World’s First AI Supercomputer
in a Box
The Essential Instrument for AI
Research
Cloud platform with the highest deep learning efficiency
DGX Station DGX-1 NVIDIA GPU Cloud
with
Tesla P100
with
Tesla V100Tesla V100
with

4
TO GET BENEFITS OF 17.09 CONTAINERS, UPDATE YOUR DGX OS SERVER VERSIONS
• Update to DGX OS Server v2.1.1- For Pascal based DGX-1- Based on Ubuntu 14.04
• Update to DGX OS Server v3.1.2- For Pascal and Volta based DGX-1- Based on Ubuntu 16.04
4

5NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.October 2017ResNet-50 uses total batch size=64 for all frameworks except for MXNet batch size=192 for mixed precision, batch size = 96 for FP32; PyTorch bs = 256 for mixed precision, bs = 64 for FP32
Speedup
Img/sec1829
1879
1953
1952
DGX-1 V100 FOR FASTEST TRAININGFP16 Training, 8 GPU Node
2.2x2.5x
3.05x
2019
2.9x
3.0x

6
INTRODUCING NVIDIA DGX STATIONGroundbreaking AI – at your desk
The Fastest Personal Supercomputer for Researchers and Data Scientists
Revolutionary form factor -designed for the desk, whisper-quiet
Start experimenting in hours, not weeks, powered by DGX Stack
Productivity that goes from desk to data center to cloud
Breakthrough performance and precision – powered by Volta
6

7
INTRODUCING NVIDIA DGX STATIONGroundbreaking AI – at your desk
The Personal AI Supercomputer for Researchers and Data Scientists
7
Key Features
1. 4 x NVIDIA Tesla V100 GPU
2. 2nd-gen NVLink (4-way)
3. Water-cooled design
4. 3 x DisplayPort (4K resolution)
5. Intel Xeon E5-2698 20-core
6. 256GB DDR4 RAM
2
1
5
4
3
6

8NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
DGX STATION: VOLTA PERFORMANCE
Caffe Caffe2 MXNet
- DGX Station with 4x Tesla V100. ResNet-50 Training, Volta with Tensor Core, 17.09 DGX optimized container.- 4x Tesla P100 PCIe. ResNet-50 Training, FP32, 17.09 DGX Optimized container.Score: Images per Second
DGX Station4x P100 DGX
Station4x P100 DGX Station4x P100
3,000
2,000
1,000

9
Single, unified stack for deep learning frameworks
Predictable execution across platforms
Pervasive reach
COMMON SOFTWARE STACK ACROSS DGX FAMILY
DGX Station DGX-1 NVIDIA Cloud Service
NVIDIAGPU Cloud

10

11

12

13
DGX-1 DEEP LEARNING DATA CENTERReference Architecture

14
NETWORKING TOPOLOGY• Ingest data as fast as possible
• Pass data rapidly between nodes across cluster
• Similar to HPC networking architecture
• InfiniBand = ultra high bandwidth, low latency
• Two-tier network with root and leaf switches
• any to any connectivity with full bi-section bandwidth & minimum contention between nodes

15
SMALL CLUSTER
• Assume growth for up to 12 nodes
• 2 racks, 2 IB switches (36 ports)
• 19.2 kW per rack, but can split across racks if necessary
• Full bi-section bandwidth for each group of 6 nodes
• 2:1 oversubscription between groups of 6
up to 12 DGX-1 nodes

16NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
MEDIUM CLUSTER
• Defines a DGX-1 “pod”
• Can be replicated for greater scale, ex: large cluster configuration
• 6 racks, 6 nodes per rack
• Larger IB director switch (216 ports) with capacity for more pods via unused ports
up to 36 DGX-1 nodes

17NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
LARGE CLUSTER
• Implements 4 DGX-1 pods
• Distributed across 24 racks
• Full bi-section bandwidth within pod, 2:1 between pods
• Training jobs ideally scheduled within a pod, to minimize inter-pod traffic
up to 144 DGX-1 nodes (4 ”pods”)

18NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE.
“A-HA” MOMENTS IN DL CLUSTER DESIGNAdditional design insights to get you started
Overall Cluster Rack Design Networking Storage Facilities Software
• HPC is the closest “cousin” to deep learning (DL) re: resource demand
• Access to HPC expertise can aid in design process
• Even with HPC, the similarities are limited
• DL drives compute nodes to close to operational limits;
• Assume less headroom
• Proper airflow is crucial to maximizing per-node / cluster performance
• Like HPC, InfiniBand is networking medium of choice
• high bandwidth, low latency
• Allow for the maximum number of per-node IB connections to avoid future bottlenecks
• DGX-1 read cache critical to DL performance
• Datasets can range from 10k’s to millions objects = terabyte levels of storage
• Large variance
• GPU data center comfortably operates at near-max. power levels.
• Assume higher watts per-rack
• Dramatically higherFLOPS/watt = footprint savings while increasing compute capacity
• Scalability requires “cluster-aware” software stack
• NCCL2 provides fast routines for multi-GPU/multi-node acceleration
• automatic topology detection
• DL frameworkoptimizations
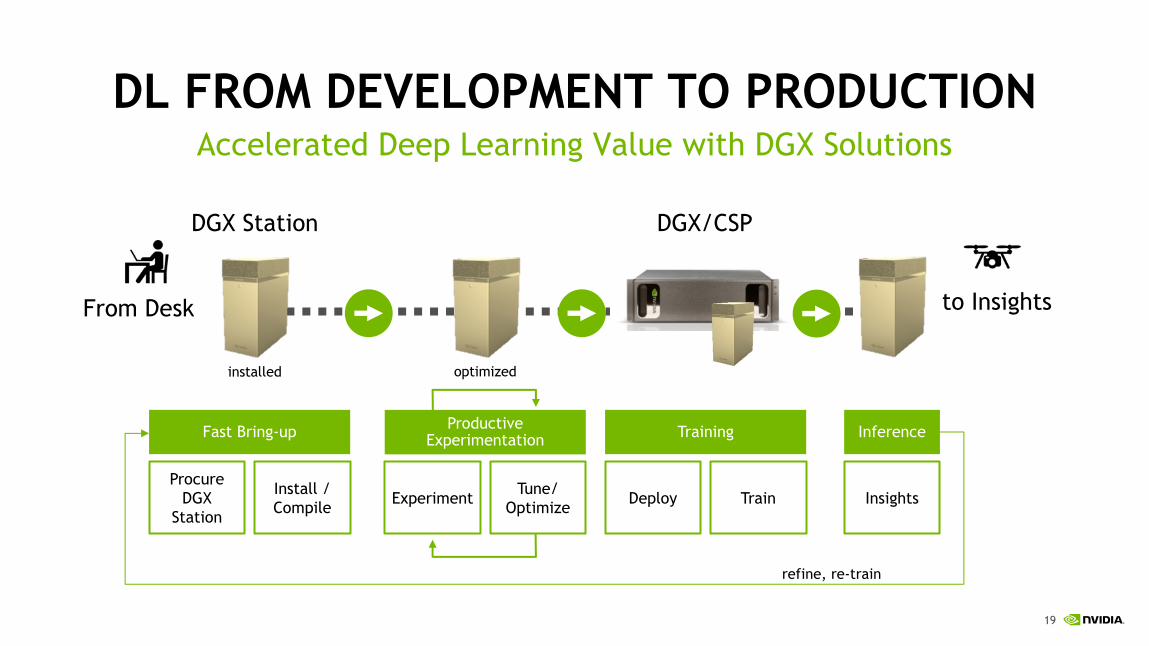
19
DL FROM DEVELOPMENT TO PRODUCTIONAccelerated Deep Learning Value with DGX Solutions
Experiment Tune/Optimize Deploy Train Insights
ProcureDGX
Station
Install / Compile
TrainingProductive ExperimentationFast Bring-up
DGX/CSPDGX Station
From Desk
installed optimized
Inference
to Insights
refine, re-train

Thank you!