
Delivering Performant, Reliable, and Scalable Apps with Anypoint Platform
30
2 Building Performant, Reliable and Scalable Integrations Rupesh Ramachandran Wai Ip
-
Upload
mulesoft -
Category
Technology
-
view
203 -
download
0
Transcript of Delivering Performant, Reliable, and Scalable Apps with Anypoint Platform

2
Building Performant, Reliable and Scalable Integrations
Rupesh RamachandranWai Ip

3
Non-Functional Requirements
• A Contract?
• Requirements?
• When are they defined?

4
Performance
• Response Time
• Throughput
• Capacity

5
• Throughput
• Concurrency
• Message Size
Scalability
6
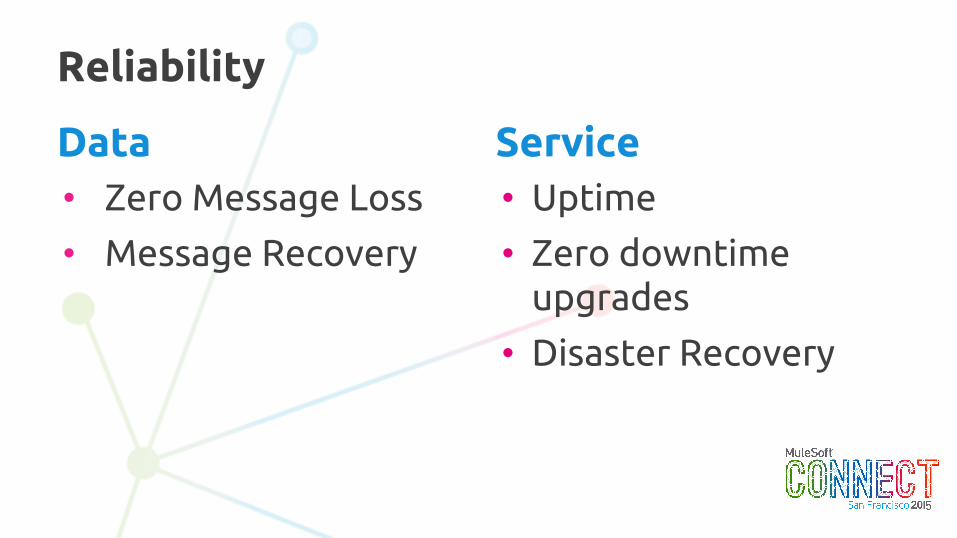
Reliability
• Uptime
• Zero downtime upgrades
• Disaster Recovery
Data Service• Zero Message Loss
• Message Recovery
7
Trade-offs

8
Best Practices

9
1) Take it seriously, plan for it.
• First class non-functional requirements
• Define early
• Be Quantitative
• Consider Growth Scenarios
10
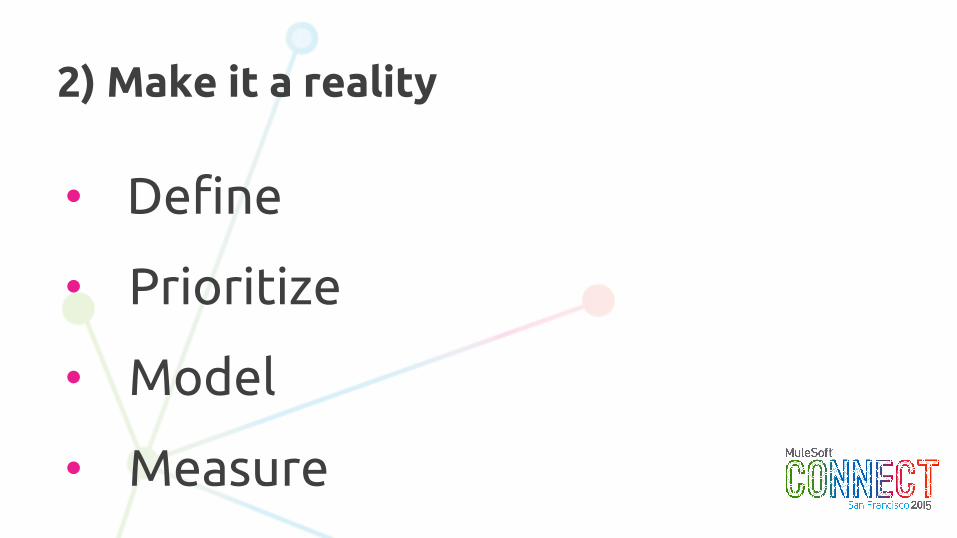
2) Make it a reality
• Define
• Prioritize
• Model
• Measure

11
3) Measure/Tune iteratively
• Measure
• Generate load
• Compare with baseline, SLA
• Identify hot spots
• Tune and profile
12
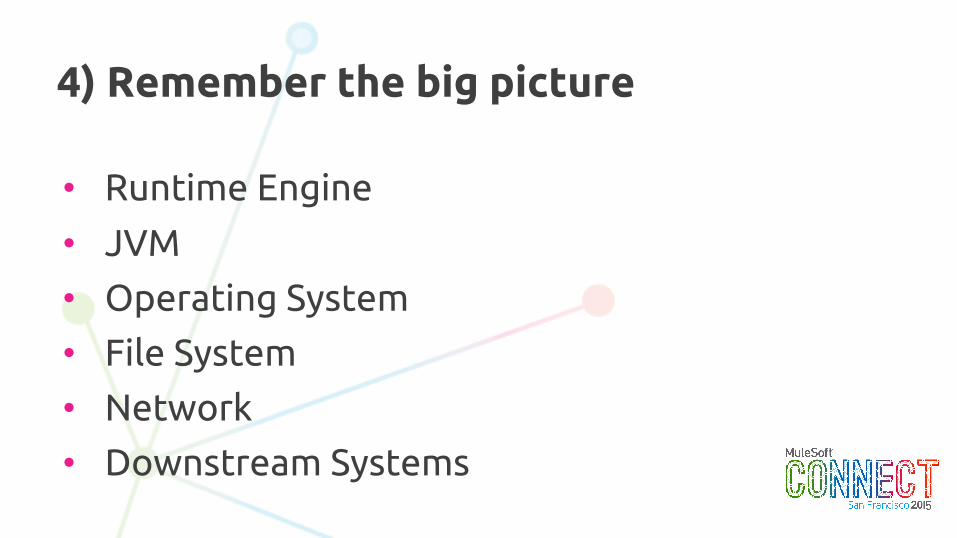
4) Remember the big picture
• Runtime Engine
• JVM
• Operating System
• File System
• Network
• Downstream Systems

13
Performance
14
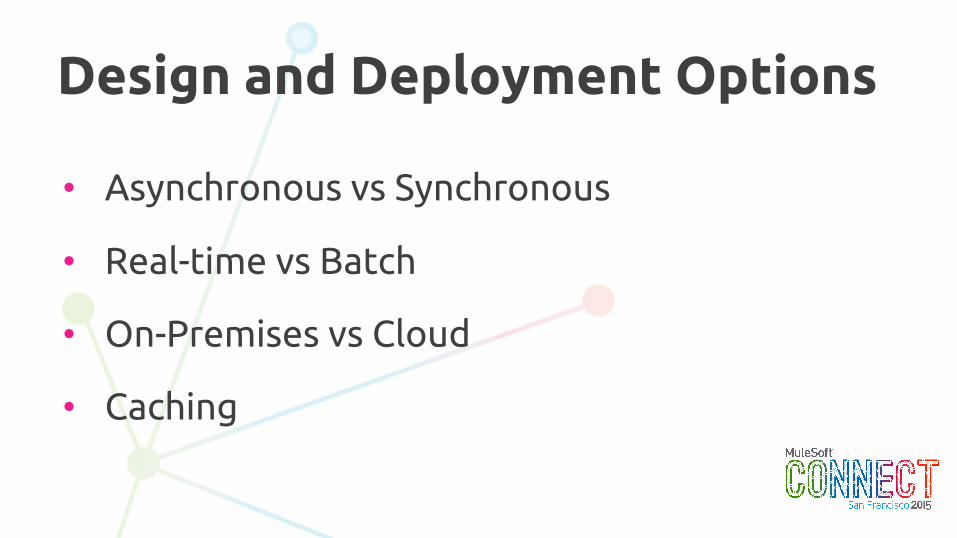
• Asynchronous vs Synchronous
• Real-time vs Batch
• On-Premises vs Cloud
• Caching
Design and Deployment Options
15
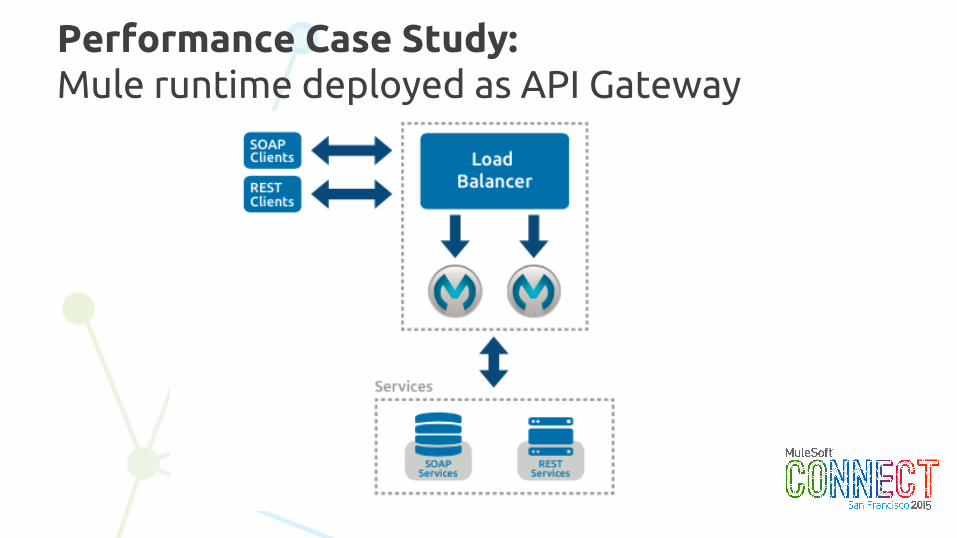
Performance Case Study:Mule runtime deployed as API Gateway

16
Infrastructure 32-core Amazon EC2 RedHat Linux
Throughput 7600tps
Latency Transaction: 5msGateway: 2 ms
API Gateway performance

17
Scalability

18
Scalability: Best Practices
• Scale Up, Scale Out
• Stateful vs Stateless
• Synchronous
• Asynchronous
19
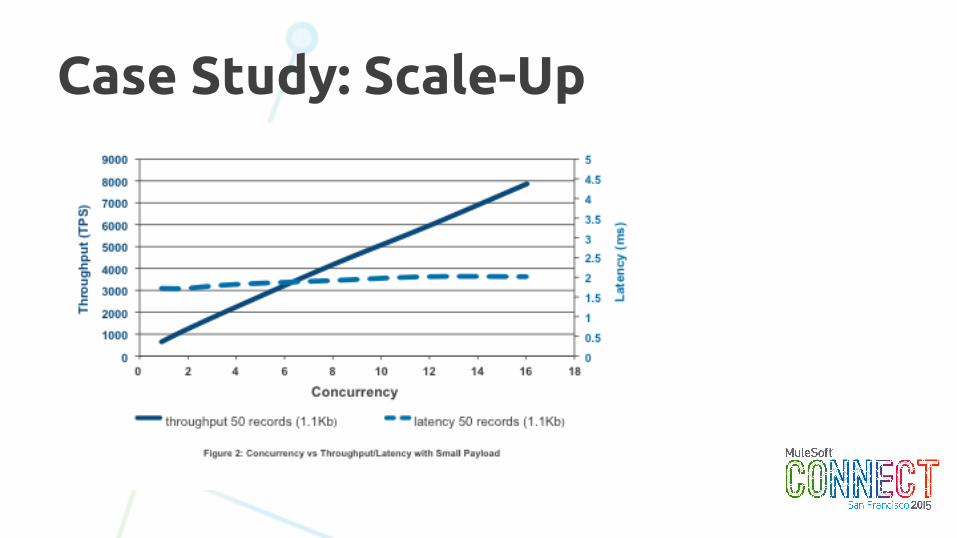
Case Study: Scale-Up

20
Reliability

21
Reliability: Best Practices
• Degrees of reliability- At least once- Once and only once {XA}
• Reliable transactions- JMS, JDBC, VM-Endpiont- Multi-resource transactions- Business vs Infrastructure Exceptions
22
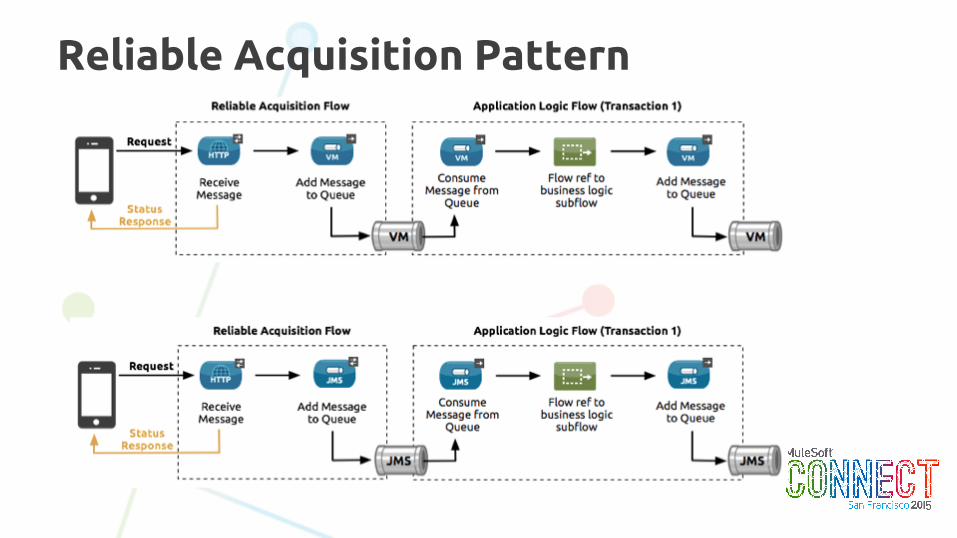
Reliable Acquisition Pattern

23
Out of the Box Reliability
• Transactional Scope
• Retry Mechanisms
• Until Successful
• First Successful
• Persistent Queues• HA Clustering• In-Memory
Replication
24
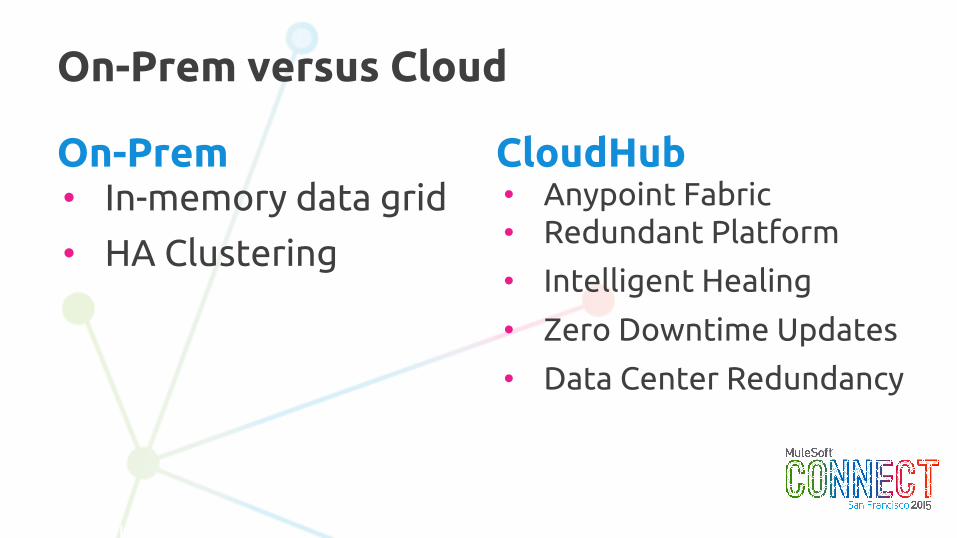
On-Prem versus Cloud
• Anypoint Fabric• Redundant Platform
• Intelligent Healing
• Zero Downtime Updates
• Data Center Redundancy
On-Prem • In-memory data grid
• HA Clustering
CloudHub
25
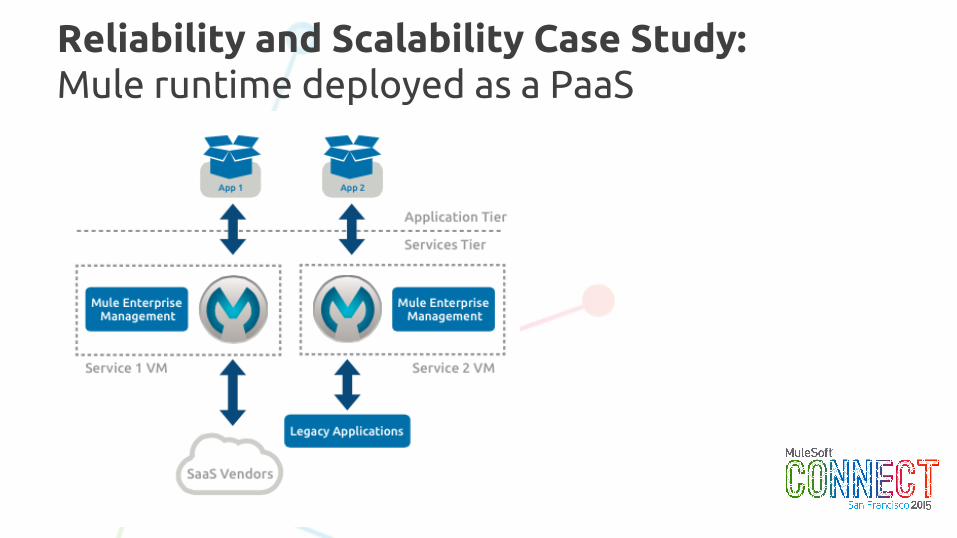
Reliability and Scalability Case Study:Mule runtime deployed as a PaaS

26
Customer PaaS performance
6,000+ Mule VMs deployed to test 500+ Mule VMs deployed in production200+ Service consumers in production200+ Service providers in production600+ Service contracts in production9.5 million messages per day850,000 messages per hour peak

27
Managing and Monitoring SLA’s
28
Out of the box API management

29
Want More?

30
Mule 3.5 & 3.6: Performance Tuning Guides
Mule 3.6 https://www.mulesoft.com/lp/whitepaper/soa/performance-tuning-guide-mule-36xMule 3.5 https://www.mulesoft.com/lp/whitepaper/soa/performance-tuning-guide

31


















