
Deep Dive - Amazon Elastic MapReduce (EMR)
46
Deep Dive – Amazon Elastic MapReduce Ian Meyers, Solution Architect – Amazon Web Services Guest Speakers: Ian McDonald & James Aley - Swiftkey ([email protected], [email protected])
-
Upload
amazon-web-services -
Category
Technology
-
view
581 -
download
3
Transcript of Deep Dive - Amazon Elastic MapReduce (EMR)

Deep Dive – Amazon Elastic MapReduce
Ian Meyers, Solution Architect – Amazon Web Services
Guest Speakers: Ian McDonald & James Aley - Swiftkey ([email protected], [email protected])

Agenda
Amazon Elastic MapReduce (EMR) Leverage Amazon Simple Storage Service (S3) with Amazon EMR File System (EMRFS) Design patterns and optimizations Space Ape Games

Amazon Elastic MapReduce
Why Amazon EMR?
Easy to Use Launch a cluster in minutes
Low Cost Pay an hourly rate
Elastic Easily add or remove capacity
Reliable Spend less time monitoring
Secure Manage firewalls
Flexible Control the cluster
Easy to deploy
AWS Management Console Command Line
Or use the Amazon EMR API with your favorite SDK.

Easy to monitor and debug
Integrated with Amazon CloudWatch Monitor Cluster, Node, IO, Hadoop 1 & 2 Processes
Monitor Debug
Amazon S3 and HDFS Browser
Query Editor
Job Browser
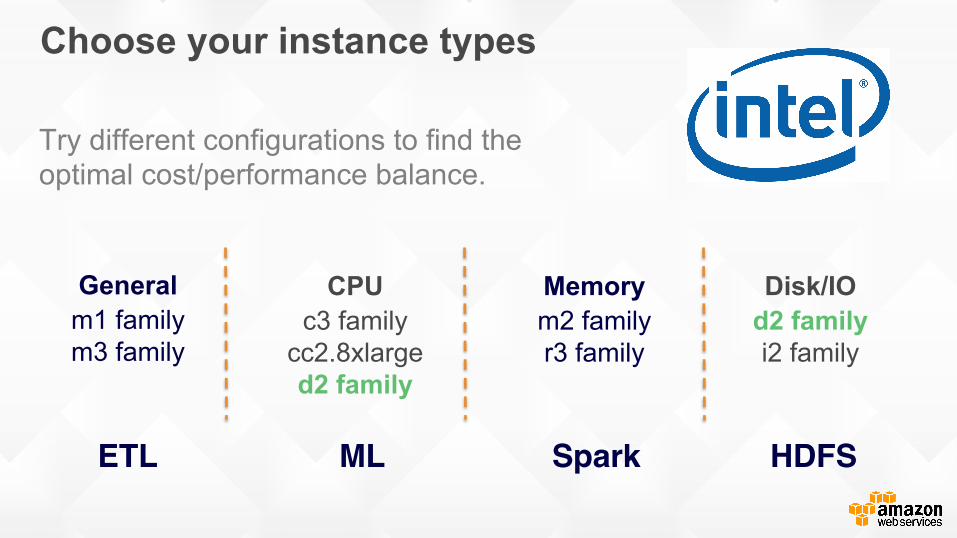
Try different configurations to find the optimal cost/performance balance.
CPU c3 family
cc2.8xlarge d2 family
Memory m2 family r3 family
Disk/IO d2 family i2 family
General m1 family m3 family
Choose your instance types
ETL ML Spark HDFS
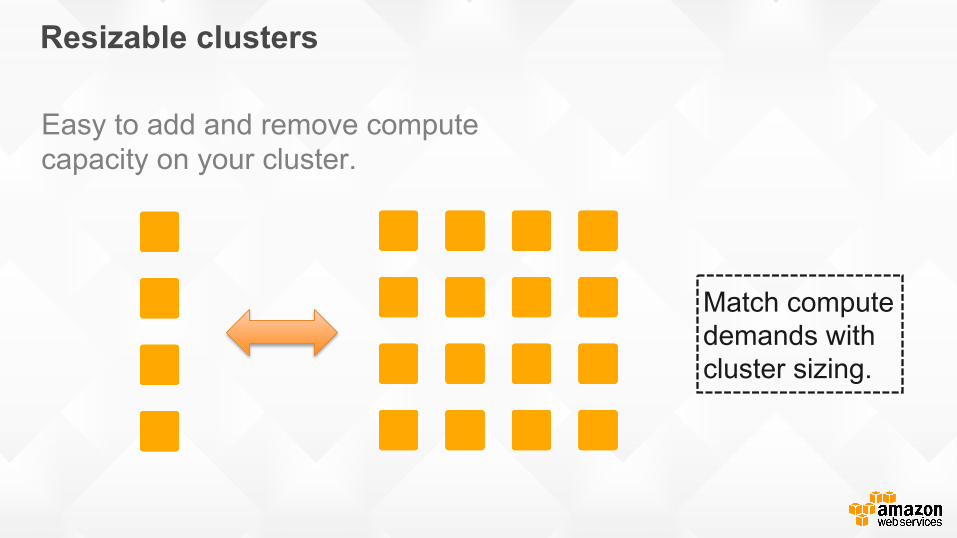
Easy to add and remove compute capacity on your cluster.
Match compute demands with cluster sizing.
Resizable clusters
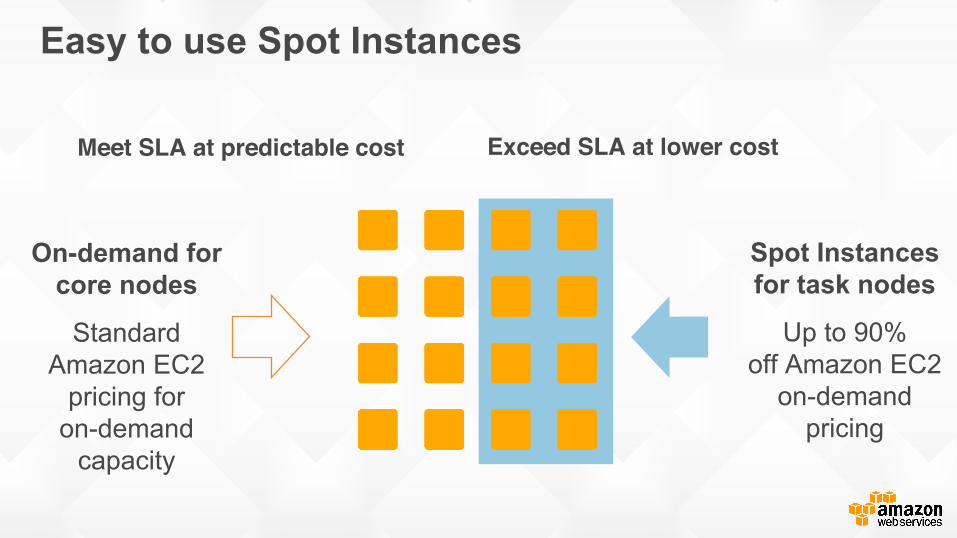
Spot Instances for task nodes
Up to 90% off Amazon EC2
on-demand pricing
On-demand for core nodes
Standard Amazon EC2
pricing for on-demand
capacity
Easy to use Spot Instances
Meet SLA at predictable cost Exceed SLA at lower cost

Use bootstrap actions to install applications…
https://github.com/awslabs/emr-bootstrap-actions

…or to configure Hadoop
--bootstrap-action s3://elasticmapreduce/bootstrap-actions/configure-hadoop
--keyword-config-file (Merge values in new config to existing) --keyword-key-value (Override values provided)
Configuration File Name
Configuration File Keyword
File Name Shortcut
Key-Value Pair Shortcut
core-site.xml core C chdfs-site.xml hdfs H hmapred-site.xml mapred M myarn-site.xml yarn Y y
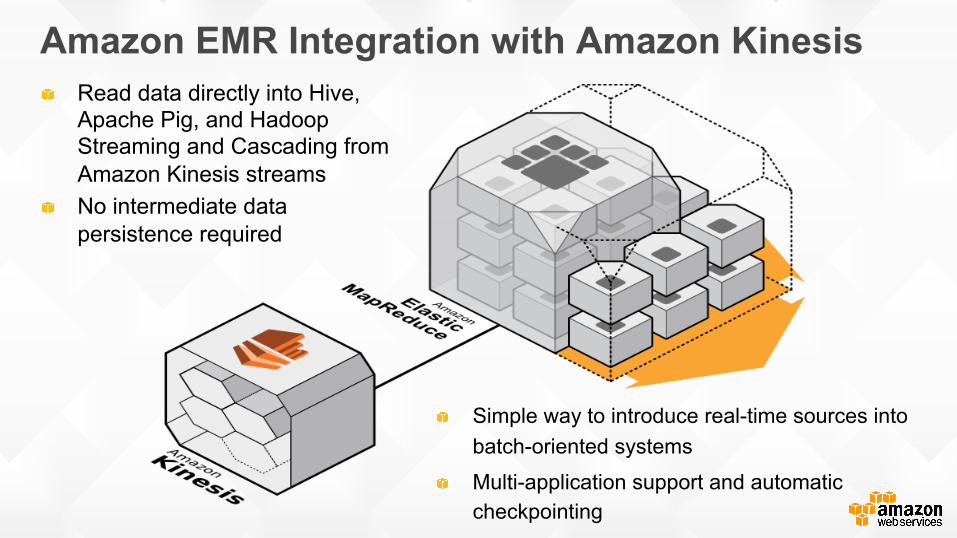
Read data directly into Hive, Apache Pig, and Hadoop Streaming and Cascading from Amazon Kinesis streams
No intermediate data persistence required
Simple way to introduce real-time sources into batch-oriented systems
Multi-application support and automatic checkpointing
Amazon EMR Integration with Amazon Kinesis

Leverage Amazon S3
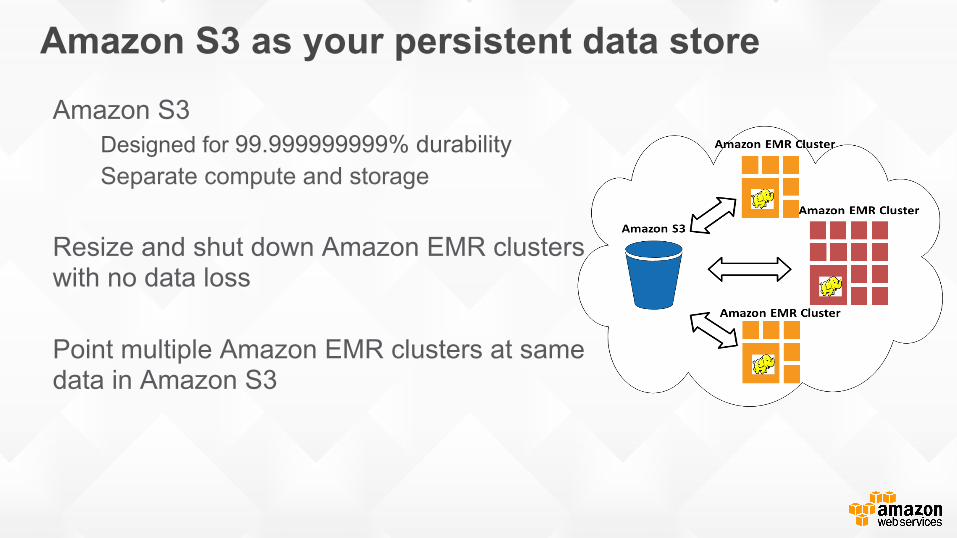
Amazon S3 as your persistent data store
Amazon S3 Designed for 99.999999999% durability Separate compute and storage
Resize and shut down Amazon EMR clusters with no data loss Point multiple Amazon EMR clusters at same data in Amazon S3

EMRFS makes it easier to leverage Amazon S3
Better performance and error handling options Transparent to applications – just read/write to “s3://” Consistent view
For consistent list and read-after-write for new puts Support for Amazon S3 server-side and client-side encryption Faster listing of large prefixes via EMRFS metadata
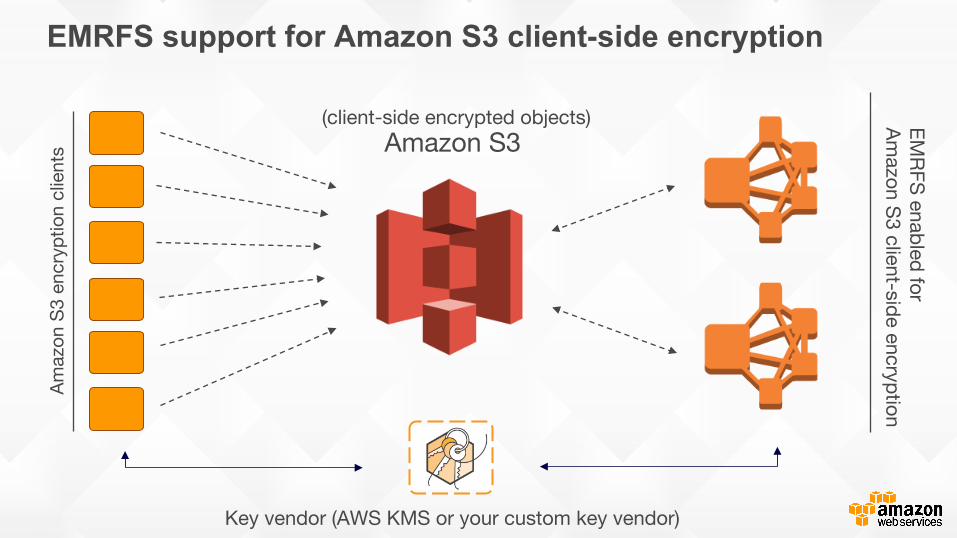
EMRFS support for Amazon S3 client-side encryption
Amazon S3
Amaz
on S
3 en
cryp
tion
clie
nts
EMRFS enabled for
Amazon S3 client-side encryption
Key vendor (AWS KMS or your custom key vendor)
(client-side encrypted objects)

Amazon S3 EMRFS metadata in Amazon DynamoDB
List and read-after-write consistency Faster list operations
Number of objects
Without Consistent View
With Consistent View
1,000,000 147.72 29.70
100,000 12.70 3.69
Fast listing of Amazon S3 objects using EMRFS metadata
*Tested using a single node cluster with a m3.xlarge instance.

Optimize to leverage HDFS
Iterative workloads If you’re processing the same dataset more than once
Disk I/O intensive workloads
Persist data on Amazon S3 and use S3DistCp to copy to HDFS for processing.

Amazon EMR – Design Patterns

Amazon EMR example #1: Batch processing
GBs of logs pushed to Amazon S3 hourly Daily Amazon EMR
cluster using Hive to process data
Input and output stored in Amazon S3
250 Amazon EMR jobs per day, processing 30 TB of data
http://aws.amazon.com/solutions/case-studies/yelp/
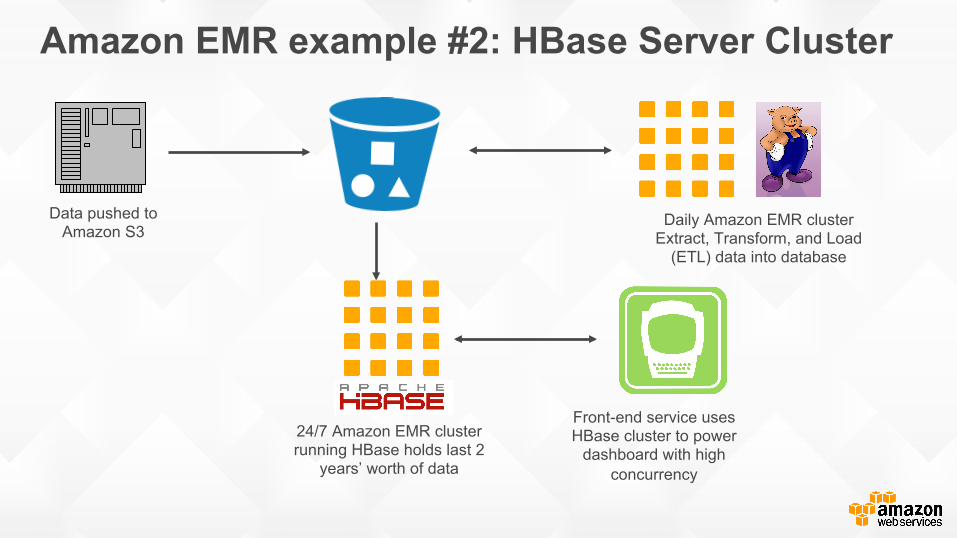
Amazon EMR example #2: HBase Server Cluster
Data pushed to Amazon S3
Daily Amazon EMR cluster Extract, Transform, and Load
(ETL) data into database
24/7 Amazon EMR cluster running HBase holds last 2
years’ worth of data
Front-end service uses HBase cluster to power
dashboard with high concurrency
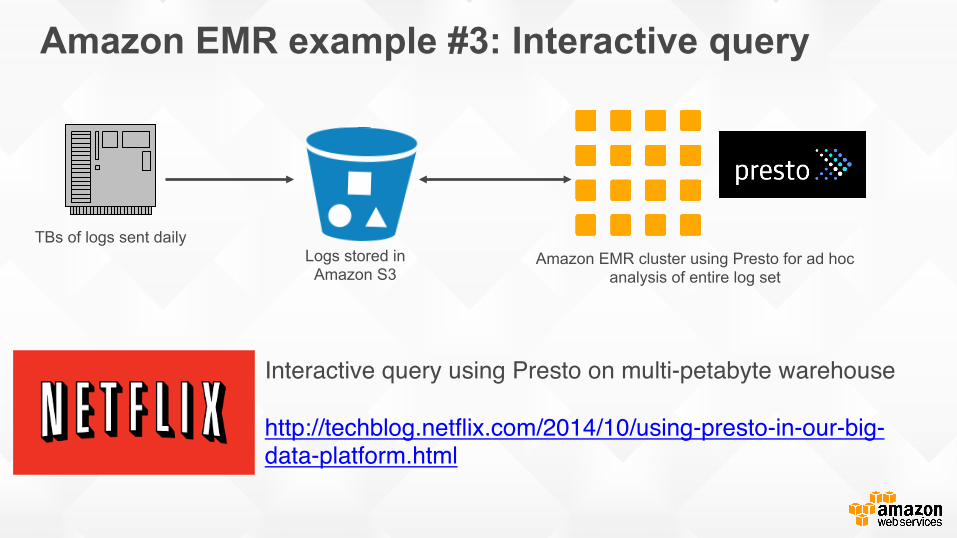
Amazon EMR example #3: Interactive query
TBs of logs sent daily Logs stored in
Amazon S3 Amazon EMR cluster using Presto for ad hoc
analysis of entire log set
Interactive query using Presto on multi-petabyte warehouse
http://techblog.netflix.com/2014/10/using-presto-in-our-big-data-platform.html

Optimizations for Storage

File formats
Row oriented Text files Sequence files
Writable object Avro data files
Described by schema
Columnar format Object Record Columnar (ORC) Parquet
Logical Table
Row oriented
Column oriented

Choosing the right file format
Processing and query tools Hive, Pig, Impala, Presto, Spark
Evolution of schema Avro for schema and Orc/Parquet for storage
File format “splittability” Avoid JSON/XML files with newlines - default Split is \n
Compression Block, File or Internal

File sizes
Avoid small files Avoid anything smaller than 100 MB
Each process is a single Java Virtual machine (JVM) CPU time is required to spawn JVMs
Fewer files, matching closely to block size Fewer calls to Amazon S3 Fewer network/HDFS requests

Dealing with small files
You *can* reduce HDFS block size (e.g., 1 MB [default is 128 MB])
--bootstrap-action s3://elasticmapreduce/bootstrap-actions/configure-hadoop --args “-m,dfs.block.size=1048576”
Instead use S3DistCp to combine small files together
S3DistCp takes a pattern and target path to combine smaller input files into larger ones Supply a target size and compression codec

Compression
Always compress data files on Amazon S3 Reduces network traffic between Amazon S3 and Amazon EMR Speeds up your job
Compress Mapper and Reducer output Amazon EMR compresses internode traffic with LZO on Hadoop 1, and Snappy on Hadoop 2.
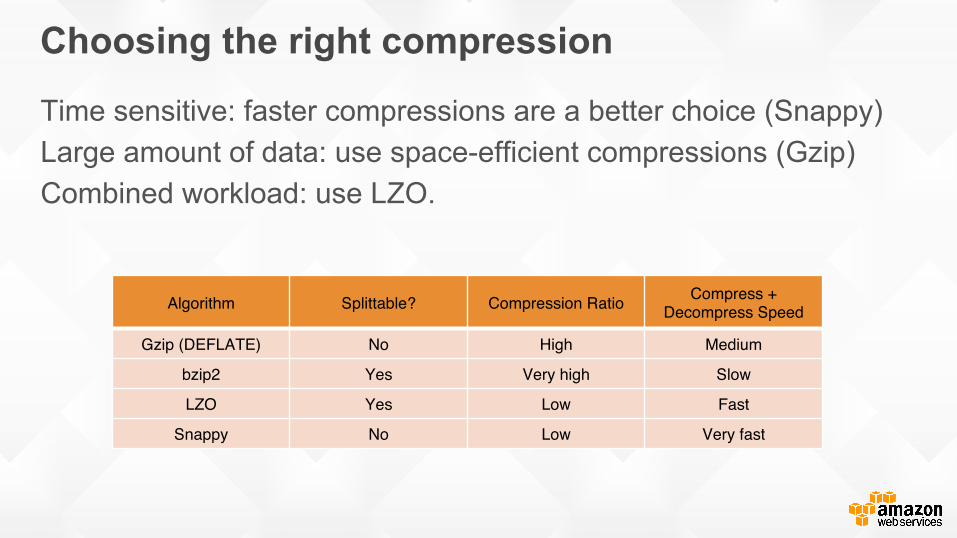
Choosing the right compression
Time sensitive: faster compressions are a better choice (Snappy) Large amount of data: use space-efficient compressions (Gzip) Combined workload: use LZO.
Algorithm Splittable? Compression Ratio Compress + Decompress Speed
Gzip (DEFLATE) No High Medium
bzip2 Yes Very high Slow
LZO Yes Low Fast
Snappy No Low Very fast

Cost-saving tips
Use Amazon S3 as your persistent data store (only pay for compute when you need it!). Use Amazon EC2 Spot Instances (especially with task nodes) to save 80 percent or more on the Amazon EC2 cost. Use Amazon EC2 Reserved Instances if you have steady workloads. Create CloudWatch alerts to notify you if a cluster is underutilized so that you can shut it down (e.g. Mappers running == 0 for more than N hours).

Cost-saving tips
Contact your account manager about custom pricing options, if you are spending more than $10K per month on Amazon EMR.

©2015, Amazon Web Services, Inc. or its affiliates. All rights reserved
Next Generation Analytics Ian McDonald, Director of IT
SwiftKey Twitter: @imcdnzl
What is SwiftKey?

Architecture
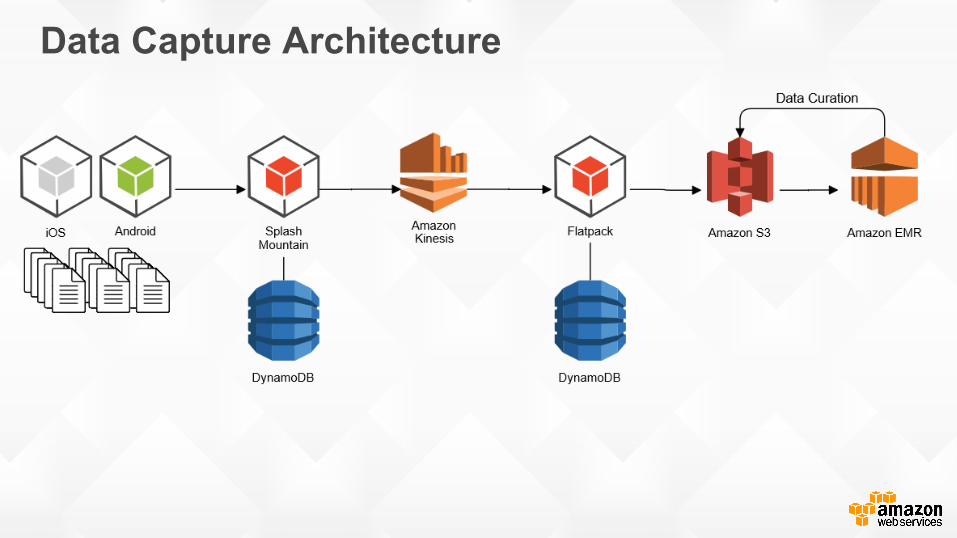
Data Capture Architecture
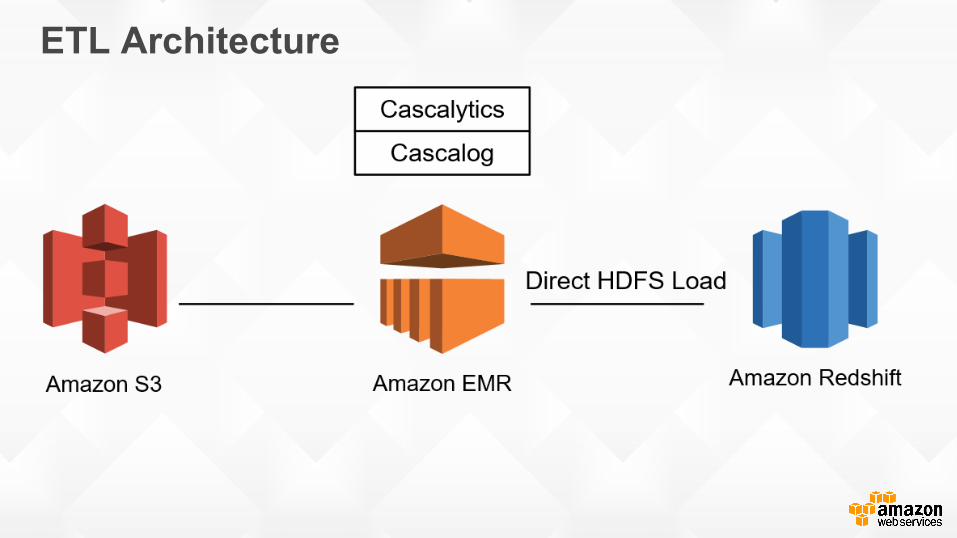
ETL Architecture

Cascalog
• Cascalog is an open source Clojure library implemented using Cascading
• Using instead of things like Hive / Pig • Write a few lines of Clojure and end up with an
EMR job

Parquet (Apache project)
• Developed by Cloudera and Twitter • Efficient compression and encoding on Hadoop /
EMR • Use for storing and processing our data

Things we’ve learnt

Lessons
• Get on top of serialisation • Don’t just stick with JSON / Gzip • Many small files in S3 painful – rebuild to fewer
bigger files • Use spot instances for EMR (except Master
node) • Experiment with different instance types to find
best speed / cost effectiveness

What’s Next

Apache Spark
• Easier / faster than Hadoop or database queries • Processes in RAM • Directly against S3 data • Available on EMR • Not necessarily great for big joins

LONDON


















