
Decision Trees References: "Artificial Intelligence: A Modern Approach, 3 rd ed" (Pearson) 18.3-18.4...
41
Decision Trees References: • "Artificial Intelligence: A Modern Approach, 3 rd ed" (Pearson) 18.3- 18.4 • http://onlamp.com/pub/a/python/2006/02/09/ai_decision_trees.html • http://chem-eng.utoronto.ca/~datamining/dmc/ decision_tree_overfitting.htm
-
Upload
alicia-craton -
Category
Documents
-
view
220 -
download
0
Transcript of Decision Trees References: "Artificial Intelligence: A Modern Approach, 3 rd ed" (Pearson) 18.3-18.4...

Decision Trees
References: • "Artificial Intelligence: A Modern Approach, 3rd ed" (Pearson) 18.3-18.4• http://onlamp.com/pub/a/python/2006/02/09/ai_decision_trees.html• http://chem-eng.utoronto.ca/~datamining/dmc/decision_tree_overfitting.htm

What are they?
• A "flowchart" of logic• Example:– If my health is low:• run to cover
– Else:• if an enemy is nearby:
– Shoot it
• else:– scavenge for treasure

Another Example
• Goal: Decide if we'll wait for a table at a restaurant• Factors:
– Alternate: Is there another restaurant nearby?– Bar: Does the restaurant have a bar?– Fri / Sat: Is it a Friday or Saturday?– Hungry: Are we hungry?– Patrons: How many people {None, Some, Full}– Price: Price Range {$, $$, $$$}– Raining: Is it raining?– Reservation: Do we have a reservation?– Type: {French, Italian, Thai, Burger}– Wait: {0-10, 10-30, 30-60, >60}
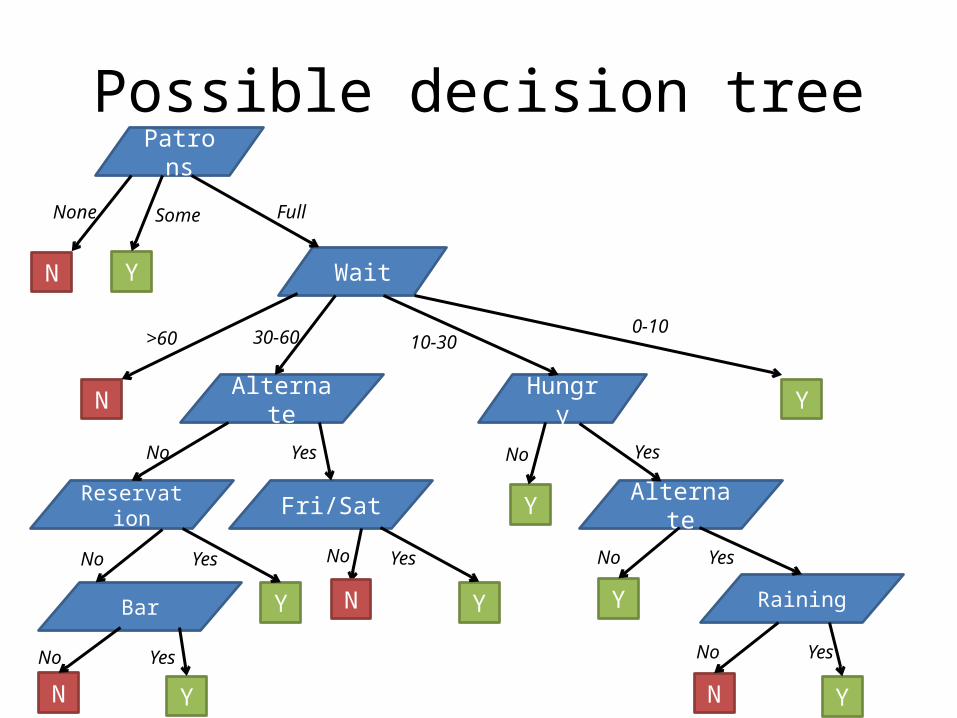
Possible decision treePatrons
Wait
Alternate Hungry
N Y
None Some Full
N Y
>60 30-60 10-300-10
Reservation Fri/Sat AlternateY
No Yes No Yes
Bar RainingY Y Y
No Yes No Yes
N
No Yes
YN YN
No Yes No Yes

Analysis
• Pluses: – Easy to traverse– Naturally expressed as if/else's
• Negatives:– how do we build an optimal tree?

Sample Input# Alt Bar Fri Hun Pat Pr Ran Res Type Wait ??
1 Y N N Y S $$$ N Y Fr 0-10 Y
2 Y N N Y F $ N N Th 30-60 N
3 N Y N N S $ N N Bu 0-10 Y
4 Y N Y Y F $ Y N Th 10-30 Y
5 Y N Y N F $$$ N Y Fr >60 N
6 N Y N Y S $$ Y Y It 0-10 Y
7 N Y N N N $ Y N Bu 0-10 N
8 N N N Y S $$ Y Y Th 0-10 Y
9 N Y Y N F $ Y N Bu >60 N
10 Y Y Y Y F $$$ N Y It 10-30 N
11 N N N N N $ N N Th 0-10 N
12 Y Y Y Y F $ N N Bu 30-60 Y

Sample Input, cont
• We can also think of these as "training data"– For a decision tree we want to model– In this context, the input:
• is that of "Experts"• exemplifies the thinking you want to encode• is raw data we want to mine• …
• Note:– Doesn't contain all possibilities– There might be noise

Building a tree
• So how do we build a decision tree from input?• A lot of possible trees:– O(2n)– Some are good, some are bad:
• good == shallowest• bad == deepest
– Intractable to find the best• Using a greedy algorithm, we can find a pretty-good
one…

ID3 algorithm
• By Ross Quinlan (RuleQuest Research)• Basic idea:
– Choose the best attribute, i– Create a tree with n children
• n is the number of values for attribute i
– Divide the training set into n sub-sets• Where all items in a subset have the same value for attribute i.• If all items in the subset have the same output value, make this a
leaf node.• If not, recursively create a new sub-tree
– Only use those training examples in this subset– Don't consider attribute i any more.

"Best" attribute
• Entropy (in information theory)– A measure of uncertainty.– Gaining info == lowering entropy
• A fair coin = 1 bit of entropy• A loaded coin (always heads) = 0 bits of entropy– No uncertainty
• A fair roll of a d4 = 2 bits of entropy• A fair roll of a d8 = 3 bits of entropy

Entropy, cont.
• Given:– V: random variable, values v1…vn
• Entropy:
• Where:– P(x) is the probability of x.

Entropy, cont.• Example:– We have a loaded 4-sided dice– We get a• {1:10%, 2:5%, 3:25%, 4:60%}
𝐻 (𝑉 )=∑𝑘=1
𝑛
𝑃 (𝑣𝑘 )∗𝑙𝑜𝑔2(1
𝑃 (𝑣𝑘 ))
¿ (0.1∗𝑙𝑜𝑔2( 10.1 ))+(0.05∗𝑙𝑜𝑔2( 1
0.05 ))+(0.25∗𝑙𝑜𝑔2( 10.25 ))+(0.6∗𝑙𝑜𝑔2( 1
0.6 ))¿ (0.1∗𝑙𝑜𝑔2 (10 ) )+(0.05∗𝑙𝑜𝑔2 (20 ) )+(0.25∗𝑙𝑜𝑔2 ( 4 ) )+(0.6∗𝑙𝑜𝑔2 (1.67 ))≈0.332+0.216+0.5+0.444≈1.492
Recall: The entropy of a fair d4 is 2.0, so this dice is slightly more predictable.

Information Gain
• The reduction in entropy• In the ID3 algorithm,– We want to split the training cases based on
attribute i– Where attribute i gives us the most information• i.e. lowers entropy the most

Information Gain, cont.• Suppose:– E is a set of p training cases– There are n "results" of each training case: r1…rn
– We're considering splitting E based on attribute i, which has m possible values: Ai1…Aim
– Ej is the subset of E which has result j, where 1 <= j <= n
– size(E) is p; size(Ej) is the size of that subset– The resulting tree would have m branches.– The gain is:
– Split on the attribute with largest gain.

Original Example
• Let's take two potential attributes: Wait & Pat. Which is best to split on?
• StepA1: Calculate H(E)– 6 Yes, 6 No

Original Example, cont.• StepA2: Calculate H(Ewait)– 4 possible values, so we'd end up with 4 branches
• "0-10": {1, 3, 6, 7, 8, 11}; 4 Yes, 2 No • "10-30": {4, 10}; 1 Yes, 1 No• "30-60": {2, 12}; 1 Yes, 1 No• ">60": {5, 9}; 2 No
– Calculate the entropy of this split group𝐻 ( 0−10 )=( 4
6 )∗𝑙𝑜𝑔2( 1
(46))+( 2
6 )∗𝑙𝑜𝑔2( 1
(26))≈0.918
𝐻 ( 10−30 )=𝐻 ( 30−60 )=( 12 )∗𝑙𝑜𝑔2( 1
(12) )+( 1
2 )∗𝑙𝑜𝑔2( 1
(12))=1.0
𝐻 ( >60 )=0.0
𝐻 (𝐸𝑤𝑎𝑖𝑡 )=612
𝐻 ( 0−10 )+ 212
𝐻 ( 10−30 )+ 212
𝐻 ( 30−60 )+ 212
𝐻 ( >60 )=𝟎 .𝟕𝟗
Gain (E ,𝑤𝑎𝑖𝑡 )=H (E )−H (𝐸𝑤𝑎𝑖𝑡 )=1.0−0.79=𝟎 .𝟐𝟏

Original Example, cont.• StepA3: Calculate H(Epat)– 3 possible values, so we'd end up with 3 branches• "Some": {1,3,6,8}; 4 Yes • "Full": {2,4,5,9,10,12}; 2 Yes, 4 No• "None": {7,11}; 2 No
– Calculate the entropy of this split group0.0
𝐻 ( Full )=( 26 )∗𝑙𝑜𝑔2( 1
(26) )+( 4
6 )∗𝑙𝑜𝑔2( 1
(46))≈0.918
𝐻 (𝐸𝑝𝑎𝑡 )=412
𝐻 ( Some )+ 612
𝐻 ( Full )+ 212
𝐻 ( ¿ )=𝟎 .𝟒𝟓𝟗
Gain (E , pat )=H (E )−H (𝐸𝑝𝑎𝑡 )=1.0−0.459=𝟎.𝟓𝟒𝟏
So…which is better: splitting on wait, or pat?

Original Example, cont.
• Pat is much better (0.541 gain vs. 0.21 gain)• Here is the tree so far:
• Now we need a subtree to handle the case where Patrons==Full– Note: The training set is smaller now (6 vs. 12)
NY
Patrons
Some Full None
{1,3,6,8} {7,11}{2,4,5,9,10,12}

Original Example, cont.
• Look at two alternatives: Alt & Type• Calculate entropy of remaining group:– We actually already calculated it (H("Full") in
StepA3)– The value becomes H(E) for this recursive
application of ID3.– H(E)≈0.918

Original Example, cont.
• Calculate entropy if we split on Alt– Two possible values: "Yes" and "No"• "Yes“ (Alt): {2,4,5,10,12}; 2 Yes, 3 No (Result)• "No“ (Alt): {9}; 1 No (Result)
𝐻 ( Yes )=25∗𝑙𝑜𝑔2( 1
( 25 ) )+
35∗𝑙𝑜𝑔2(
1
( 35 )
)≈0.971
𝐻 ( No )=0.0
𝐻 (𝐸𝑎𝑙𝑡 )=56𝐻 ( Yes )+ 1
6𝐻 ( No )≈0.809
𝐺𝑎𝑖𝑛 (𝐸 ,𝑎𝑙𝑡 )≈0.918−0.809≈0.109

Original Example, cont.• Calculate entropy if we split on Type– 4 possible values: "French", "Thai", "Burger", and
"Italian"• "French": {5}; 1 No• "Thai": {2,4}; 1 Yes, 1 No• "Burger": {9,12}; 1 Yes, 1 No• "Italian": {10}; 1 No
𝐻 ( French )=𝐻 ( Italian )=0.0
𝐻 ( Burger )=𝐻 ( Thai )=12∗𝑙𝑜𝑔2( 1
(12))+ 1
2∗𝑙𝑜𝑔2( 1
(12) )=1.0
𝐻 (𝐸 𝑡𝑦𝑝𝑒 )= 16𝐻 ( French )+ 2
6𝐻 ( Thai )+ 2
6𝐻 ( Burger )+ 1
6𝐻 ( Italian )≈0.667
𝐺𝑎𝑖𝑛 (𝐸 , 𝑡𝑦𝑜𝑒)≈0.918−0.667≈0.251Which is better: alt or type?

Original Example, cont.• Type is better (0.251 gain vs. 0.109 gain)– Hungry, Price, Reservation, Est would give you same gain.
• Here is the tree so far:
• Recursively make two more sub-trees…
Type NY
Patrons
Some Full None
{1,3,6,8} {7,11}{2,4,5,9,10,12}
French Thai ItalianBurger
N N{5} {10}{2,4} {9,12}

Original Example, cont.• Here's one possibility (skipping the details):
N NFri
Type NY
Patrons
Some Full None
{1,3,6,8} {7,11}{2,4,5,9,10,12}
French Thai ItalianBurger
{5} {10}{2,4} Alt {9,12}
Yes No Yes No
{4} {2} {12} {9}N NY Y

Using a decision tree
• This algorithm will perfectly match all training cases.
• The hope is that this will generalize to novel cases.
• Let's take a new case (not found in training)– Alt="No", Bar="Yes", Fri="No", Pat="Full"– Hungry="Yes", Price="$$", Rain=Yes– Reservation="Yes", Type="Italian", Est="30-60"
• Will we wait?
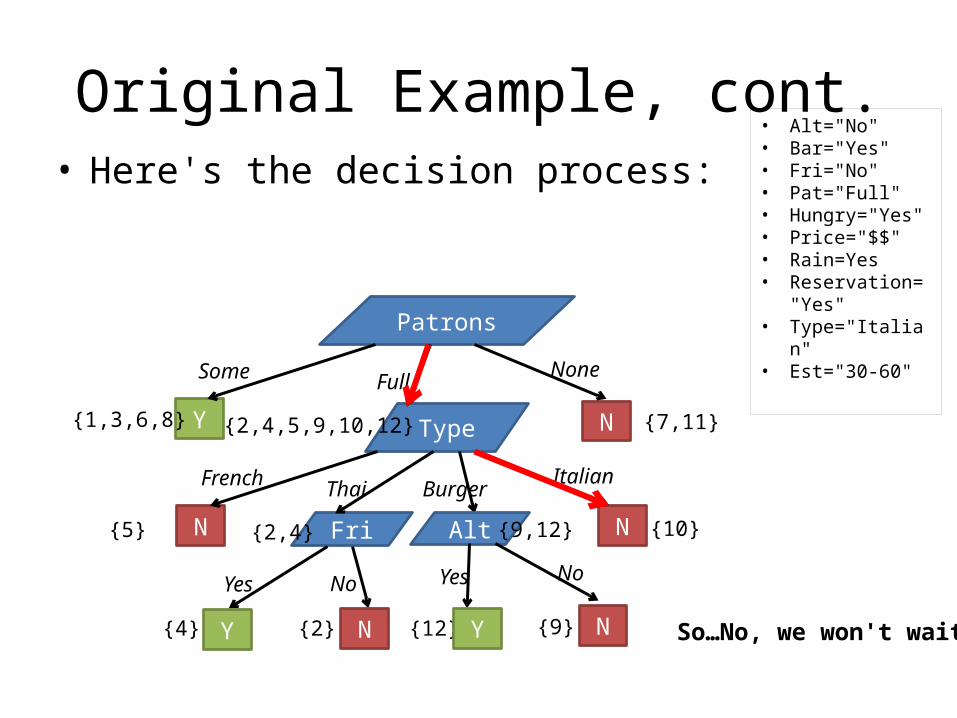
N NFri
Type NY
Original Example, cont.• Here's the decision process:
Patrons
Some Full None
{1,3,6,8} {7,11}{2,4,5,9,10,12}
French Thai ItalianBurger
{5} {10}{2,4} Alt {9,12}
Yes No Yes No
{4} {2} {12} {9}N NY Y
• Alt="No"• Bar="Yes"• Fri="No"• Pat="Full"• Hungry="Yes"• Price="$$"• Rain=Yes• Reservation="Yes"• Type="Italian"• Est="30-60"
So…No, we won't wait.

Pruning
• Sometimes an exact fit is not necessary– The tree is too big (deep)– The tree isn't generalizing well to new cases
(overfitting)– We don't have a lot of training cases:
• We would get close to the same results removing the attr node, and labeling it as a leaf (r1)
Attr
r1 r2 r1{47}
{98}{11, 41}
v1 v2 v3

Chi-Squared Test• The chi-squared test can be used to determine
if a decision node is statistically significant.• Example1:
• Is there a strong significance between hair color and eye color?
RAW DATA
Hair Color
Light Dark
Brown 32 12
Eye Color Green/Blue 14 22
Other 6 9

Chi-Squared Test• Example2:
• Is there a strong significance between console preference and passing etgg1803?
RAW DATA
Console PreferencePS3 PC XBox360 Wii None
Pass 5 12 6 4 15
Pass ETGG1803?
Fail 4 2 5 4 2

Chi-Squared Test• Steps:• 1) Calculate row, column, and overall totals
Hair Color
Light Dark
Black 32 12
Eye Color Green/Blue 14 22
Other 6 9
Hair Color
Light Dark
Black 32 12 44
Eye Color Green/Blue
14 22 36
Other 6 9 15
52 43 95
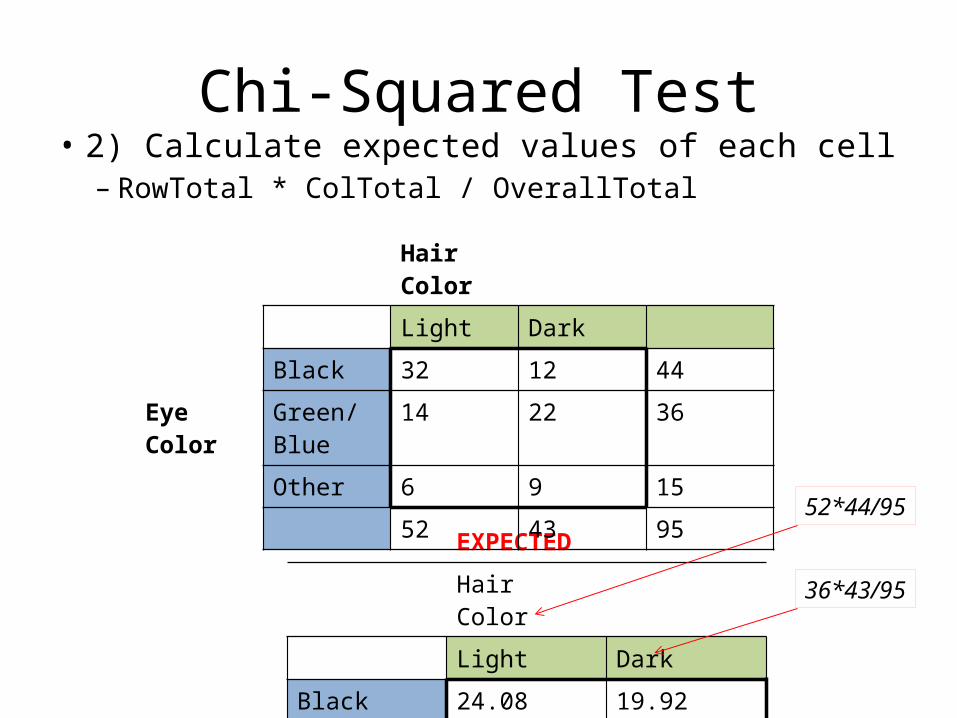
Chi-Squared Test• 2) Calculate expected values of each cell– RowTotal * ColTotal / OverallTotal
EXPECTED
Hair Color
Light Dark
Black 24.08 19.92
Eye Color Green/Blue 19.7 16.3
Other 8.21 6.8
Hair Color
Light Dark
Black 32 12 44
Eye Color Green/Blue
14 22 36
Other 6 9 15
52 43 95
52*44/95
36*43/95
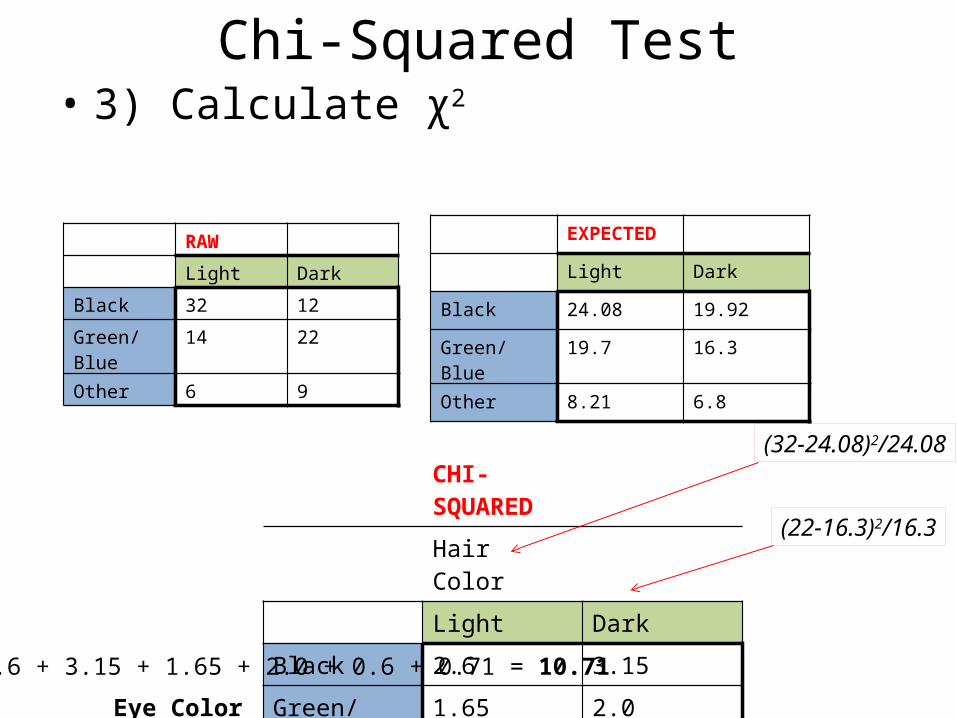
Chi-Squared Test• 3) Calculate χ2
CHI-SQUARED
Hair Color
Light Dark
Black 2.6 3.15
Eye Color Green/Blue 1.65 2.0
Other 0.6 0.71
(32-24.08)2/24.08
(22-16.3)2/16.3
EXPECTED
Light Dark
Black 24.08 19.92
Green/Blue 19.7 16.3
Other 8.21 6.8
RAW
Light Dark
Black 32 12
Green/Blue 14 22
Other 6 9
χ2 = 2.6 + 3.15 + 1.65 + 2.0 + 0.6 + 0.71 = 10.71

Chi-Squared test
• 4) Look up your chi-squared value in a table– The degrees-of-freedom (dof) is (numRows-
1)*(numCols-1)– http://home.comcast.net/~
sharov/PopEcol/tables/chisq.html• If the table entry (usually for 0.05) is less than your chi-
squared, it's statistically significant.
– scipy (www.scipy.org)import scipy.stats
if 1.0 – scipy.stats.chi2.cdf(chiSquared, dof) > 0.05:# Statistically insignificant

Chi-squared test
• We have a χ2 value of 10.71 (dof = 2)• The table entry for 5% probability (0.05) is 5.99• 10.71 is bigger than 5.99, so this is statistically
significant• For the console example– χ2 = 8.16– dof = 4– table entry for 5% probability is 9.49– So…this isn't a statistically significant connection.

Chi-Squared Pruning
• Bottom-up– Do a depth-first traversal– do your test after calling the function recursively
on your children

Original Example, cont.• Look at "Burger?" first
N NFri
Type NY
Patrons
Some Full None
[4Y,0N] [0Y,2N][2Y,4N]
French Thai ItalianBurger
[0Y,1N] [0Y,1N][1Y,1N] Alt [1Y,1N]
Yes No Yes No
[1Y,0N]
[0Y,1N] [1Y,0N] [0Y,1N]N NY Y
[6Y,6N]

Original Example, cont.• Do a Chi-squared test:
Burger
Alt [1Y,1N]
Yes No
[1Y,0N] [0Y,1N]
NY
Yes No
Yes: Wait 1 0
No: Don't 0 1
Yes No
Yes: Wait 1 0 1
No: Don't 0 1 1
1 1 2
Yes No
Yes: Wait 0.5 0.5
No: Don't 0.5 0.5
Yes No
Yes: Wait 0.5 0.5
No: Don't 0.5 0.5
χ2 = 0.5 + 0.5 + 0.5 + 0.5 = 2.0 dof = (2-1)*(2-1) = 1 Table(0.05, 1) = 3.84
So…prune it!
Note: we'll have a similar case with Thai. So…prune it too!
Original
Totals
Expected
Chi's

Original Example, cont.• Here's one possibility:
N NFri
Type NY
Patrons
Some Full None
[4Y,0N] [0Y,2N][2Y,4N]
French Thai ItalianBurger[0Y,1N] [0Y,1N][1Y,1N] Alt [1Y,1N]
Yes No Yes No
[1Y,0N][0Y,1N] [1Y,0N] [0Y,1N]
N NY Y
[6Y,6N]
N N
Type NY
Patrons
Some Full None
[4Y,0N] [0Y,2N][2Y,4N]
French Thai ItalianBurger[0Y,1N] [0Y,1N][1Y,1N] [1Y,1N]Y
[6Y,6N]
Y

Original Example, cont.
N N
Type[2Y,4N]
French Thai ItalianBurger[0Y,1N] [0Y,1N][1Y,1N] [1Y,1N]Y Y
I got a chi-squared value of 1.52, dof=3…prune it!
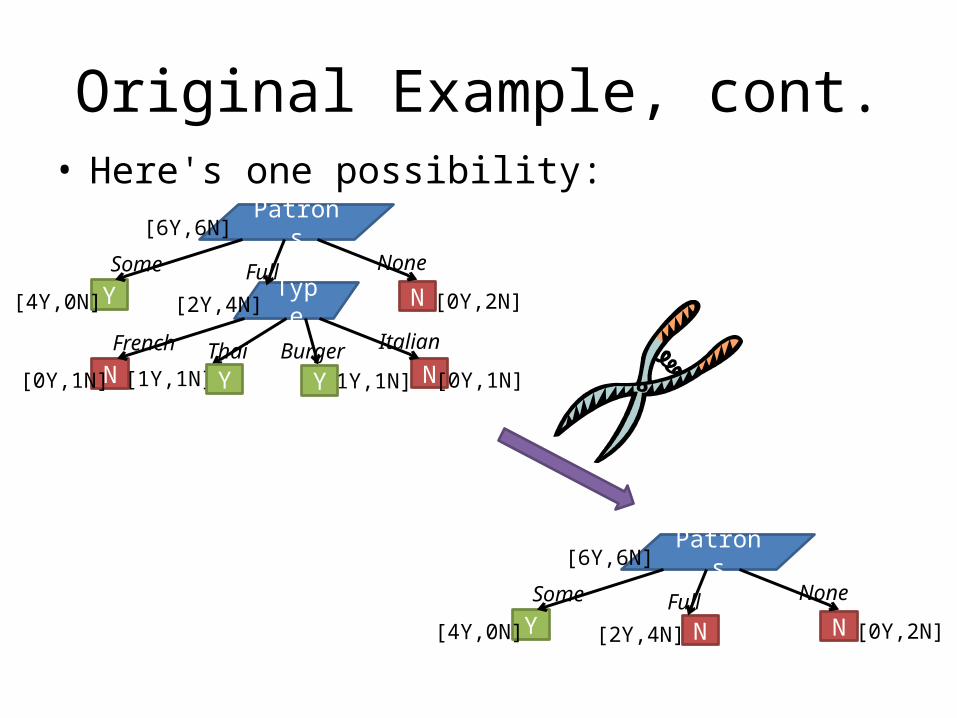
Original Example, cont.• Here's one possibility:
N NY
Patrons
Some Full None
[4Y,0N] [0Y,2N][2Y,4N]
[6Y,6N]
N N
Type NY
Patrons
Some Full None
[4Y,0N] [0Y,2N][2Y,4N]
French Thai ItalianBurger[0Y,1N] [0Y,1N][1Y,1N] [1Y,1N]Y
[6Y,6N]
Y

Pruning Example, cont.
N NY
Patrons
Some Full None
[4Y,0N] [0Y,2N][2Y,4N]
[6Y,6N]
I got a chi-squared value of 6.667, dof=2. So…keep it!
Note: if the evidence were stronger (more training cases) in the burger, thai branch, we wouldn't have pruned it

Questions?






![Braille Module 63 Special Formats: Poetry, Columns, Tables, …profitt.gatech.edu/drupal/sites/default/files/curriculum... · 2012. 9. 24. · Lesson 18.3 [BF Rule 7] Lesson 18.4](https://static.fdocuments.us/doc/165x107/6046a2830d5010642b0d440b/braille-module-63-special-formats-poetry-columns-tables-2012-9-24-lesson.jpg)









![[PPT]PowerPoint Presentation - Annual Conference on … file... · Web view18.1 CALL AND PUT OPTIONS 18.2 ONE-PERIOD OPTION PRICING MODEL 18.3 TWO-PERIOD OPTION PRICING MODEL 18.4](https://static.fdocuments.us/doc/165x107/5afe76337f8b9a814d8f1126/pptpowerpoint-presentation-annual-conference-on-fileweb-view181-call.jpg)
