
Decision Trees & Random Forests x Deep Neural...
42
DECISION TREES & RANDOM FORESTS X CONVOLUTIONAL NEURAL NETWORKS Meir Dalal Or Gorodissky 1 Deep Neural Decision Forests Microsoft Research Cambridge UK , ICCV 2015 Decision Forests, Convolutional Networks and the Models in-Between Microsoft Research Technical Report arXiv 3 Mar. 2016
Transcript of Decision Trees & Random Forests x Deep Neural...

DECISION TREES & RANDOM FORESTSX
CONVOLUTIONAL NEURAL NETWORKS
Meir Dalal
Or Gorodissky
1
Deep Neural Decision Forests
Microsoft Research Cambridge UK , ICCV 2015
Decision Forests, Convolutional Networks and the Models in-Between
Microsoft Research Technical Report arXiv 3 Mar. 2016

MOTIVATION
DECISION TREES
RANDOM FORESTS
DECISION TREES VS CNN
OVERVIEW OF THE PRESENTATION
2
COMBINING DECISION TREE & CNN
MOTIVATION
3
Combining CNN’s feature learning with Random Forest’s classification capacities

DECISION TREE - WHAT IS IT
4
Supervised learning algorithm used for classification
An inductive learning task - use particular facts to make more generalized conclusions
A predictive model based on a branching series of tests
These smaller tests are less complex than a one-stage classifier (Divide & Conquer)
Different way to look at : each node either predicates the answer or passes the problem to a
different node
Example…
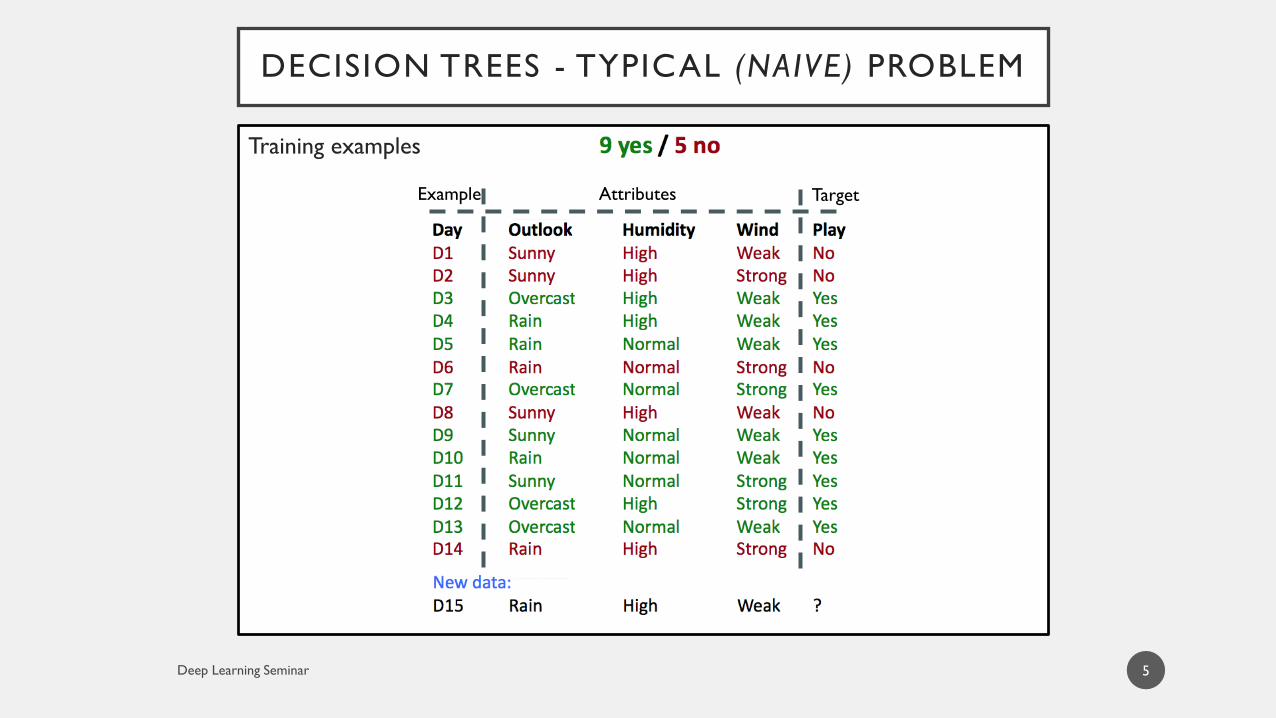
DECISION TREES - TYPICAL (NAIVE) PROBLEM
5
Training examples
Example Attributes Target
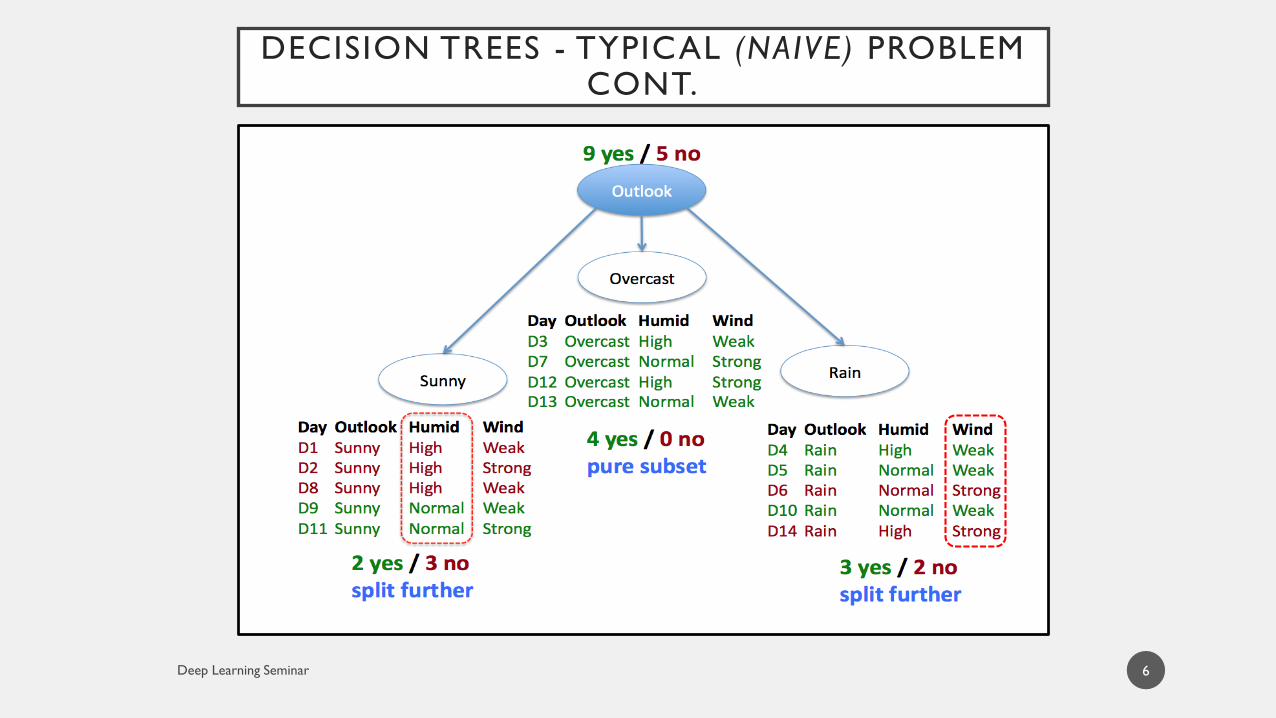
DECISION TREES - TYPICAL (NAIVE) PROBLEM CONT.
6
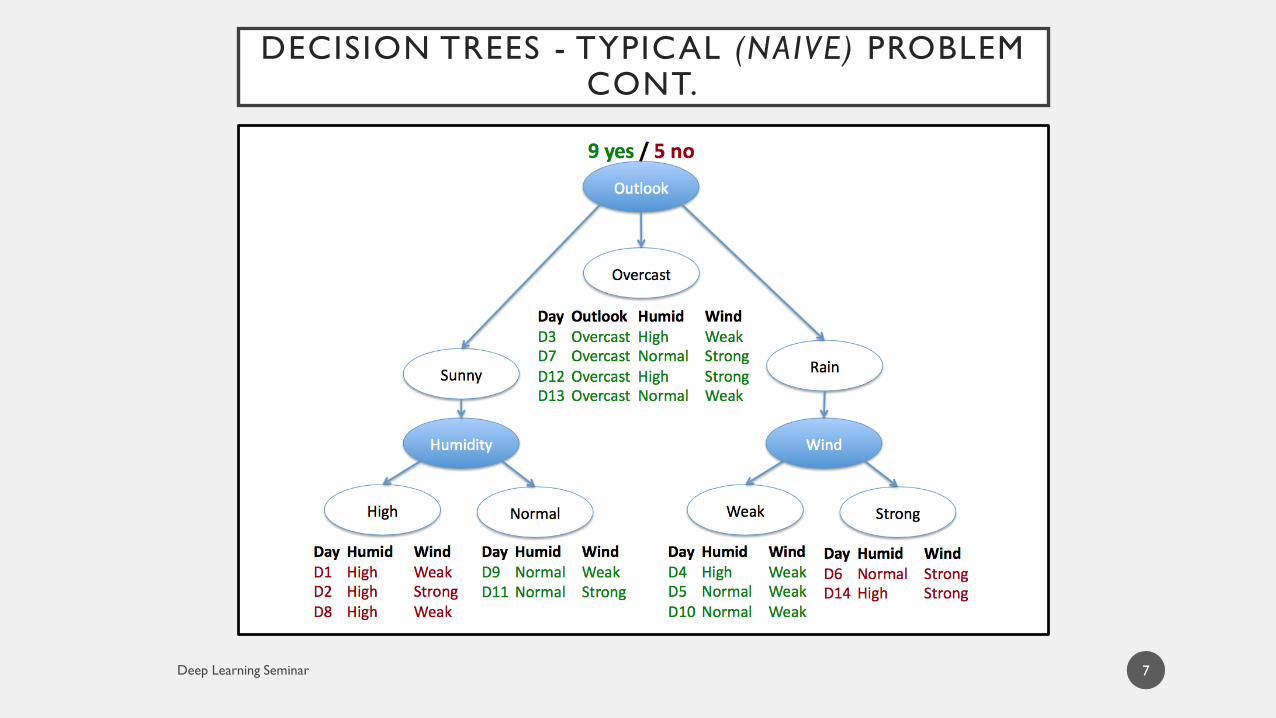
DECISION TREES - TYPICAL (NAIVE) PROBLEM CONT.
7

DECISION TREES - HOW TO CONSTRUCT
8
When to stop
All the instances have the same target class
There are no more instances
There are no more attributes
Reach to pre-defined max depth
How to split? constructing a decision trees usually work top-down
Gini impurity
Information gain
…
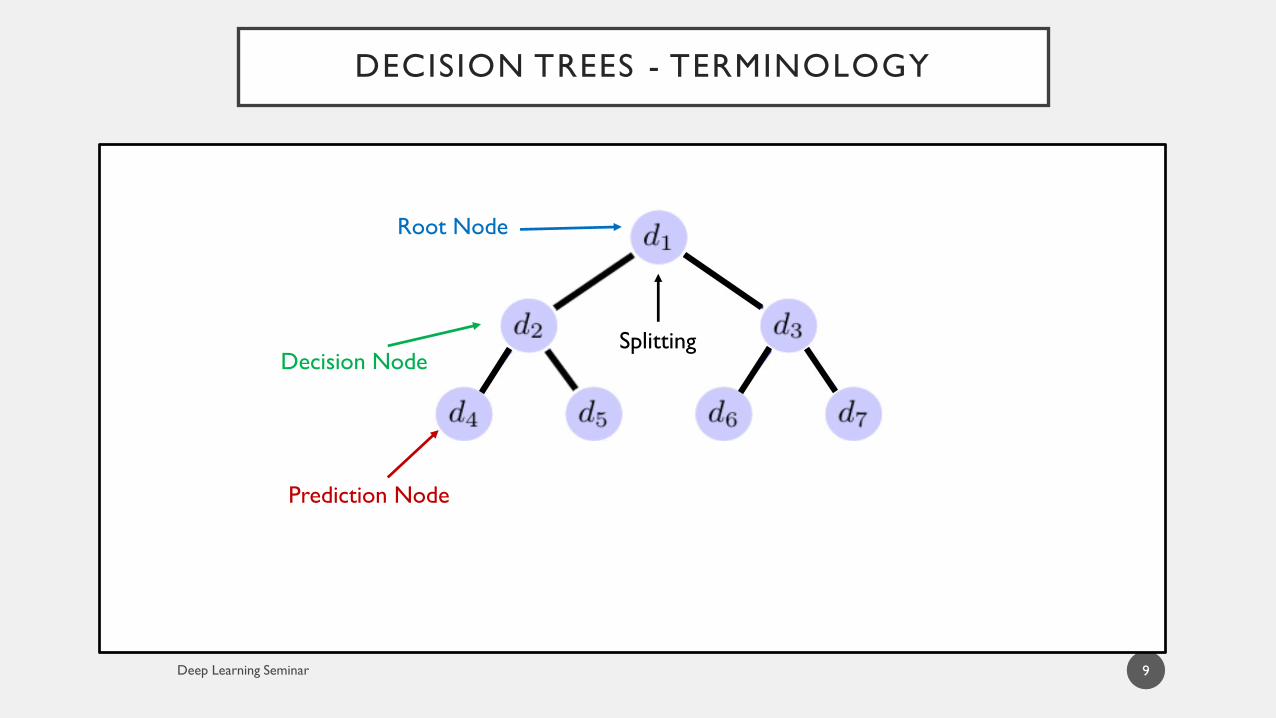
DECISION TREES - TERMINOLOGY
9
Prediction Node
Decision Node
Root Node
Splitting
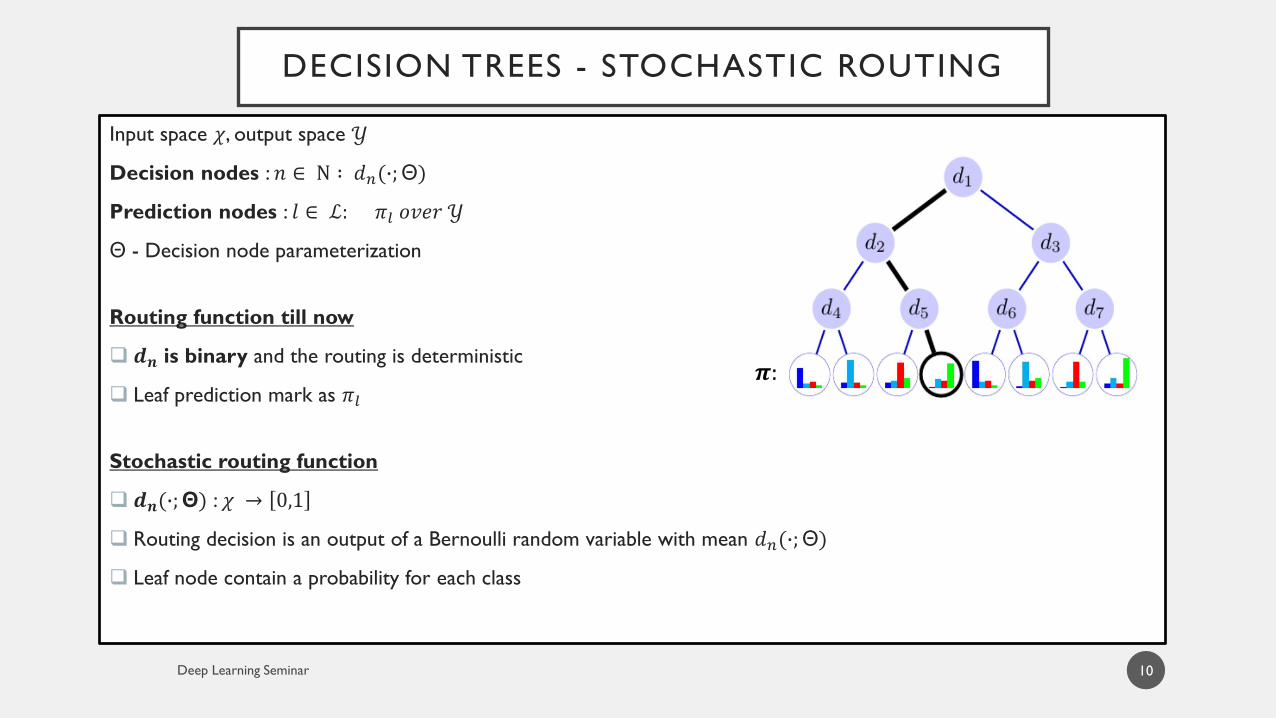
DECISION TREES - STOCHASTIC ROUTING
10
Input space 𝜒, output space 𝒴
Decision nodes : 𝑛 ∈ Ν ∶ 𝑑𝑛(∙;Θ)
Prediction nodes : 𝑙 ∈ ℒ: 𝜋𝑙 𝑜𝑣𝑒𝑟 𝒴
Θ - Decision node parameterization
Routing function till now
𝒅𝒏 is binary and the routing is deterministic
Leaf prediction mark as 𝜋𝑙
Stochastic routing function
𝒅𝒏(∙;Θ) : 𝜒 → 0,1
Routing decision is an output of a Bernoulli random variable with mean 𝑑𝑛(∙;Θ)
Leaf node contain a probability for each class
𝝅:

DECISION TREE - ENSEMBLE METHODS
11
If a decision tree is fully grown, it may lose some generalization capability
→Overfitting
How to solve it?
Ensemble methods
Involve group of predictive models to achieve a better accuracy and model stability
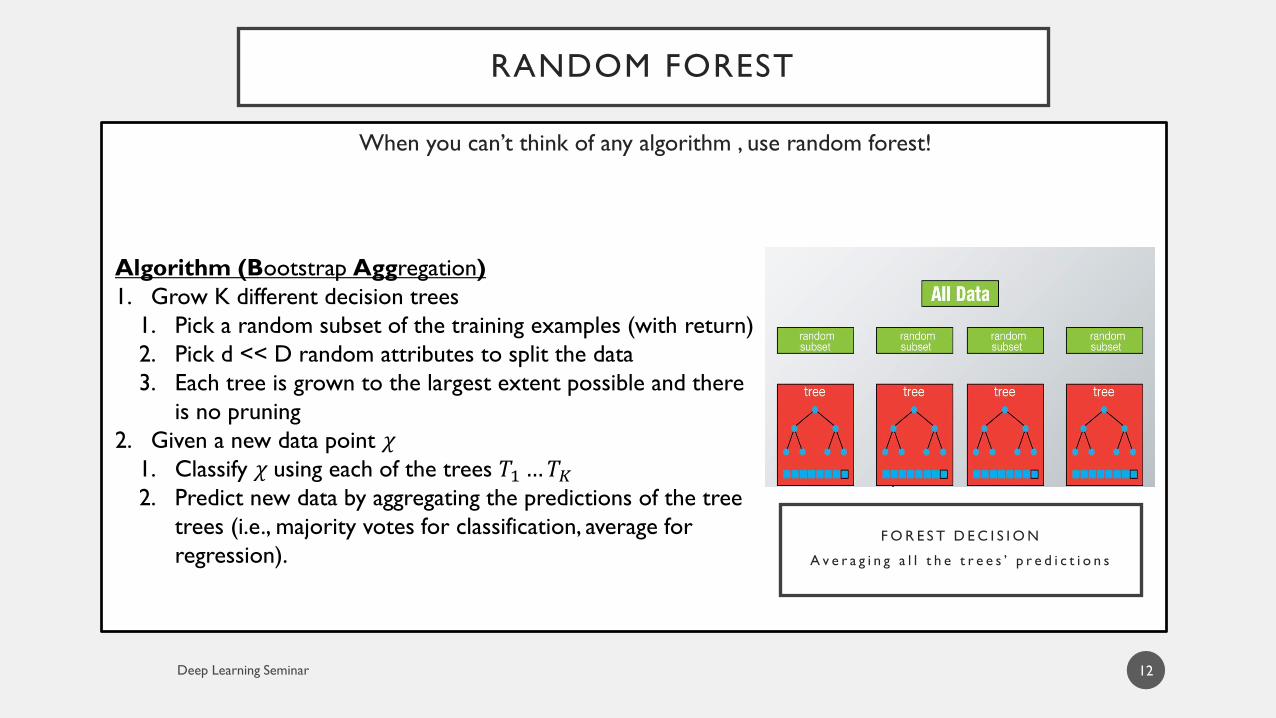
RANDOM FOREST
12
When you can’t think of any algorithm , use random forest!
Algorithm (Bootstrap Aggregation)
1. Grow K different decision trees
1. Pick a random subset of the training examples (with return)
2. Pick d << D random attributes to split the data
3. Each tree is grown to the largest extent possible and there
is no pruning
2. Given a new data point 𝜒1. Classify 𝜒 using each of the trees 𝑇1…𝑇𝐾2. Predict new data by aggregating the predictions of the tree
trees (i.e., majority votes for classification, average for
regression).F O R E S T D E C I S I O N
A v e r a g i n g a l l t h e t r e e s ’ p r e d i c t i o n s

DT
Levels
Divide & Conquer
Only log2 𝑁 parameters used in test time
No feature learned (at most)
Training is done layer wise
High efficiency
Layers
High dimensionality
Use all the parameters in test time!
Feature learning integrated classification
Training E2E with S/GD
State of the art accuracy
CNN
DECISION TREES X CONV NEURAL NETS
13
How to efficiently combine DT/RF with CNN?

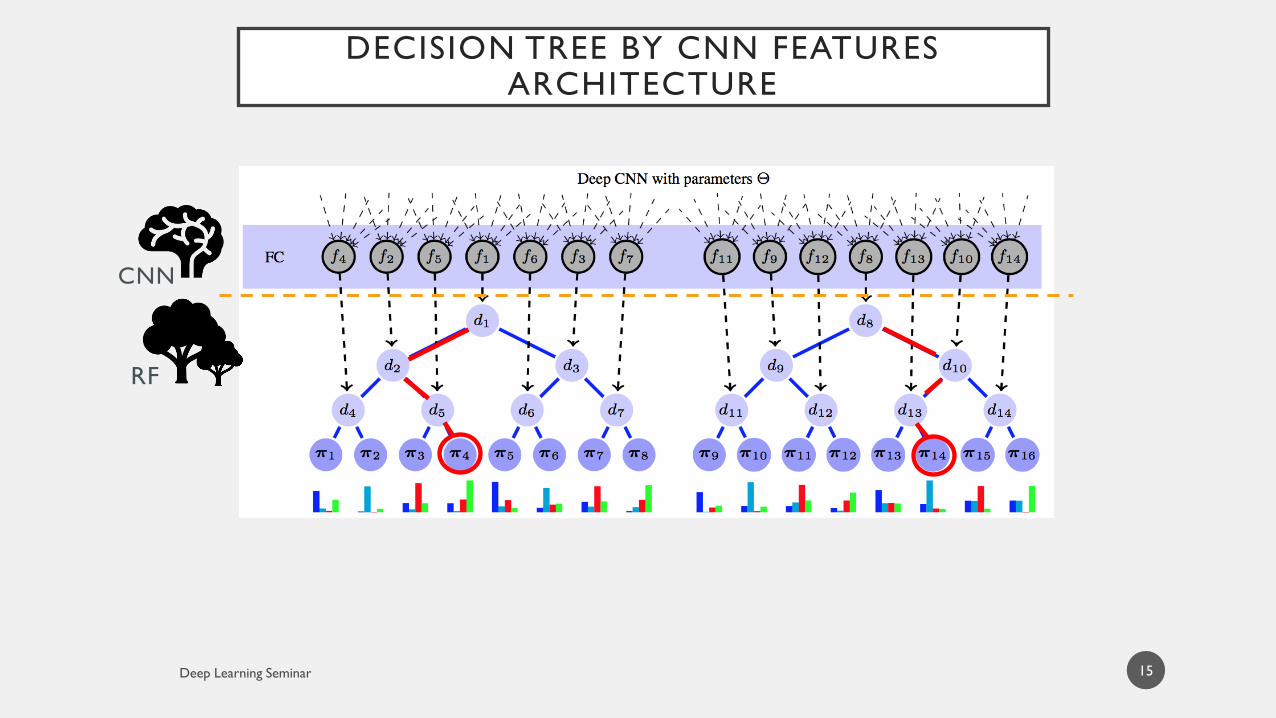
DECISION TREE BY CNN FEATURESARCHITECTURE
14
SoftmaxRF
CNN
DECISION TREE BY CNN FEATURESARCHITECTURE
15
RF
CNN
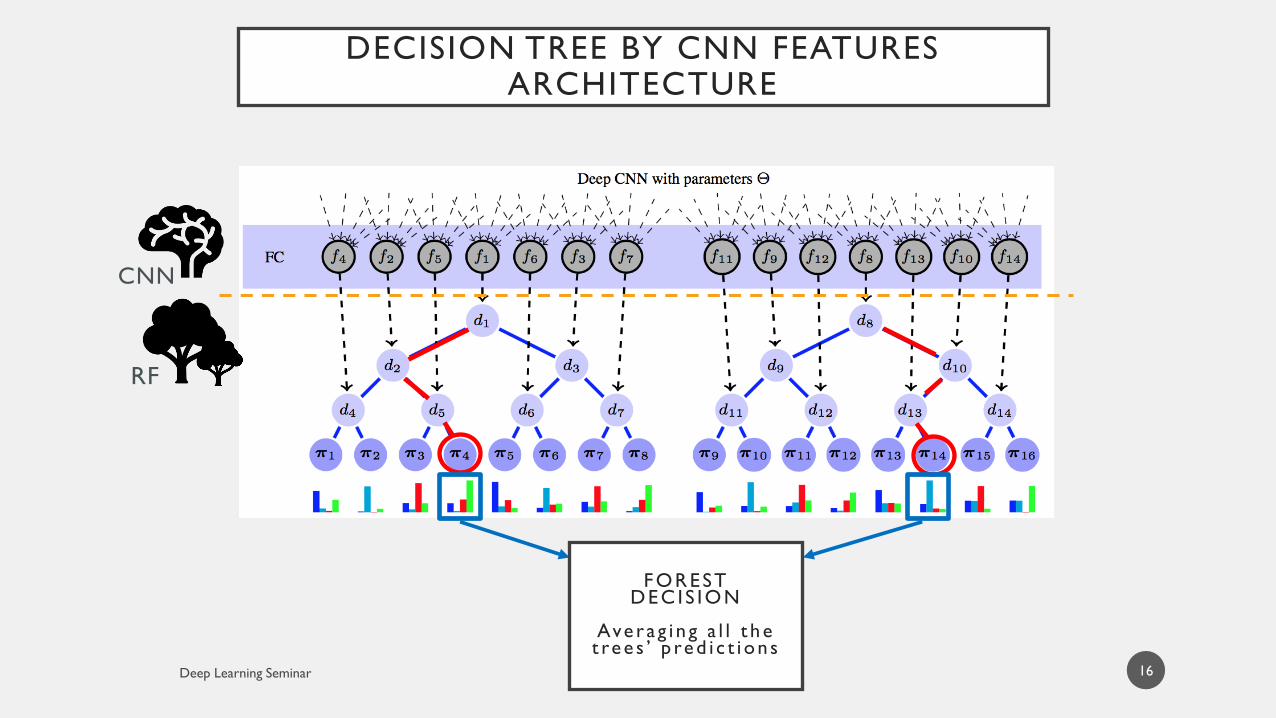
DECISION TREE BY CNN FEATURESARCHITECTURE
16
FOREST DEC IS ION
Avera g i n g a l l t h e t re e s ’ p red i c t i on s
RF
CNN

DECISION TREE BY CNN FEATURESARCHITECTURE
17
Decision Nodes
𝑑𝑛 ∙;Θ = 𝜎 𝑓𝑛 𝓍 ;Θ
𝜎 𝑥 = 1 + 𝑒−𝑥 −1 (sigmoid function)
𝑓𝑛(∙;Θ) : 𝜒 → ℝ
Prediction Probability
Prediction for sample 𝓍 ∶ 𝕡𝑇 𝓎 𝓍, Θ, 𝜋 = 𝑙∈ ℒ 𝜋𝑙𝓎𝜇𝑙(𝓍|Θ) where
𝜋𝑙𝓎 - probability of a sample reaching a leaf ℓ to take class 𝓎
𝜇𝑙(𝓍|Θ) - probability that sample 𝓍 will reach leaf ℓ 𝑙∈ ℒ 𝜇𝑙(𝓍|Θ) = 1
Forest Of Decision Trees
Deliver a prediction for a 𝓍 sample by averaging the output of each tree: ℙℱ 𝓎 𝓍 =1
𝐾 ℎ=1𝐾 ℙ𝑇ℎ 𝓎 𝓍
K - number of decision trees in the forest
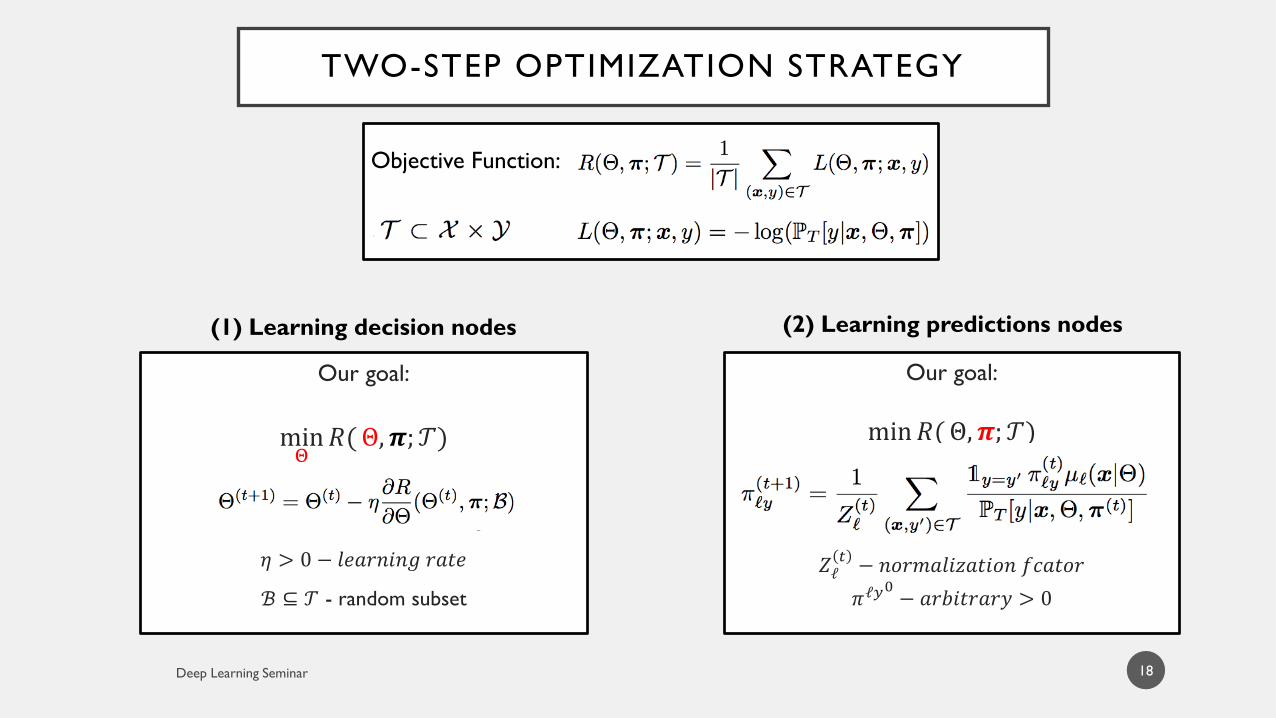
TWO-STEP OPTIMIZATION STRATEGY
18
(2) Learning predictions nodes(1) Learning decision nodes
Our goal:
min𝝅𝑅(Θ, 𝝅; 𝒯)
𝑍ℓ𝑡− 𝑛𝑜𝑟𝑚𝑎𝑙𝑖𝑧𝑎𝑡𝑖𝑜𝑛 𝑓𝑐𝑎𝑡𝑜𝑟
𝜋ℓ𝑦0− 𝑎𝑟𝑏𝑖𝑡𝑟𝑎𝑟𝑦 > 0
Our goal:
minΘ𝑅(Θ, 𝝅;𝒯)
𝜂 > 0 − 𝑙𝑒𝑎𝑟𝑛𝑖𝑛𝑔 𝑟𝑎𝑡𝑒
ℬ ⊆ 𝒯 - random subset
Objective Function:

LEARNING TREE BY BACK PROPAGATION
19
𝝅
Update the predication nodes in each tree independently since each tree has its own set of leaf predictions
𝜣
Randomly select a tree in the forest for each
mini-batch
(2)
(1)
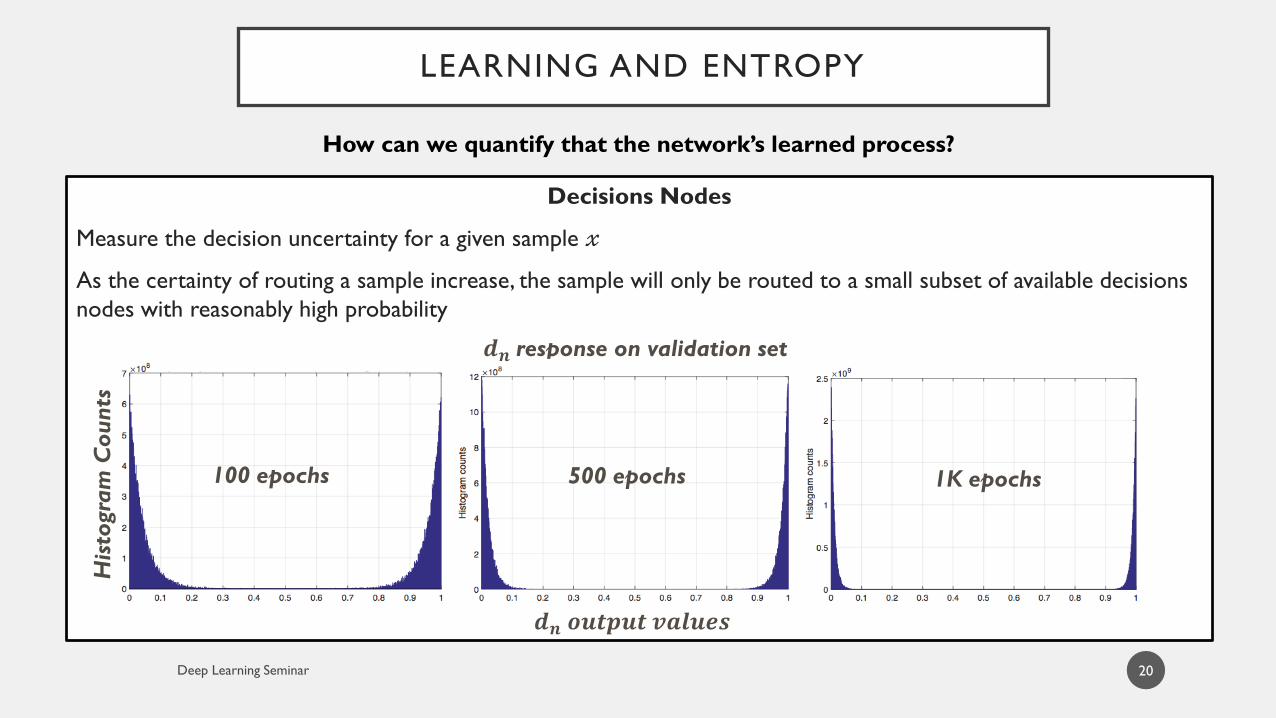
LEARNING AND ENTROPY
20
How can we quantify that the network’s learned process?
Decisions Nodes
Measure the decision uncertainty for a given sample 𝓍
As the certainty of routing a sample increase, the sample will only be routed to a small subset of available decisions
nodes with reasonably high probability
𝒅𝒏 𝒐𝒖𝒕𝒑𝒖𝒕 𝒗𝒂𝒍𝒖𝒆𝒔
His
togra
m C
ounts
100 epochs 500 epochs 1K epochs
𝒅𝒏 response on validation set
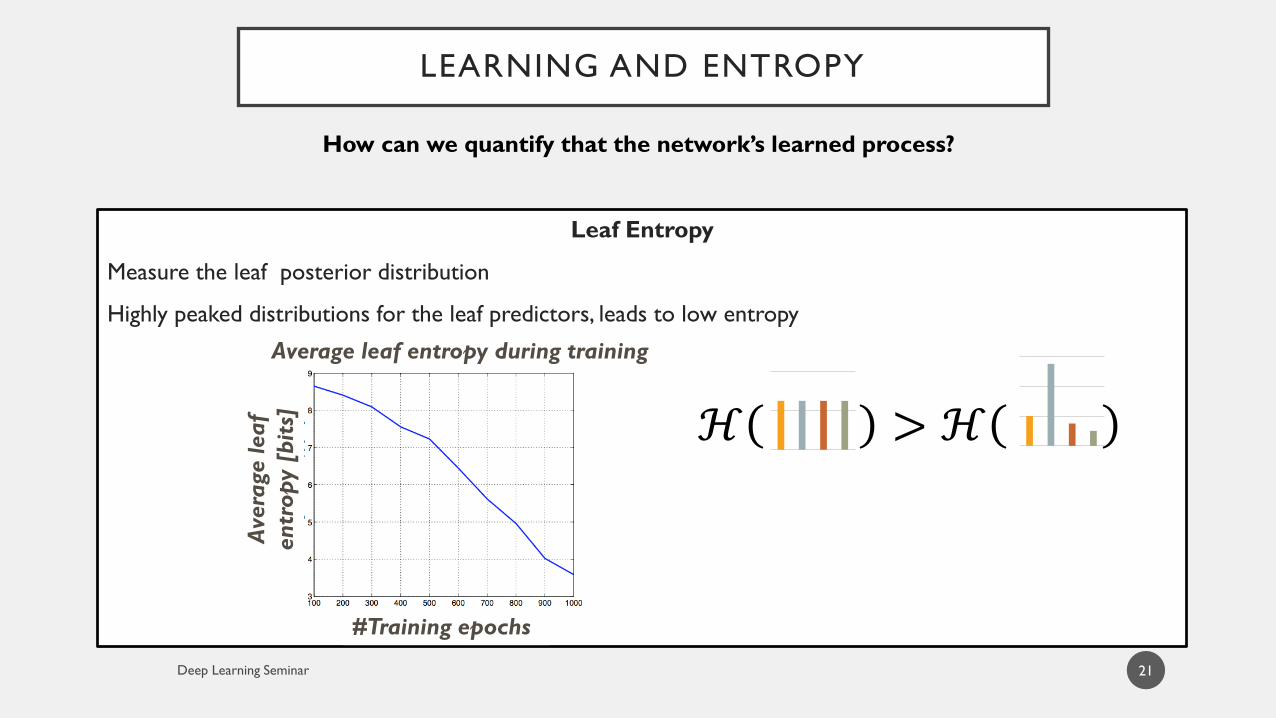
LEARNING AND ENTROPY
21
How can we quantify that the network’s learned process?
Leaf Entropy
Measure the leaf posterior distribution
Highly peaked distributions for the leaf predictors, leads to low entropy
ℋ > ℋ
Average leaf entropy during training
#Training epochs
Ave
rage leaf
entr
opy [
bit
s]
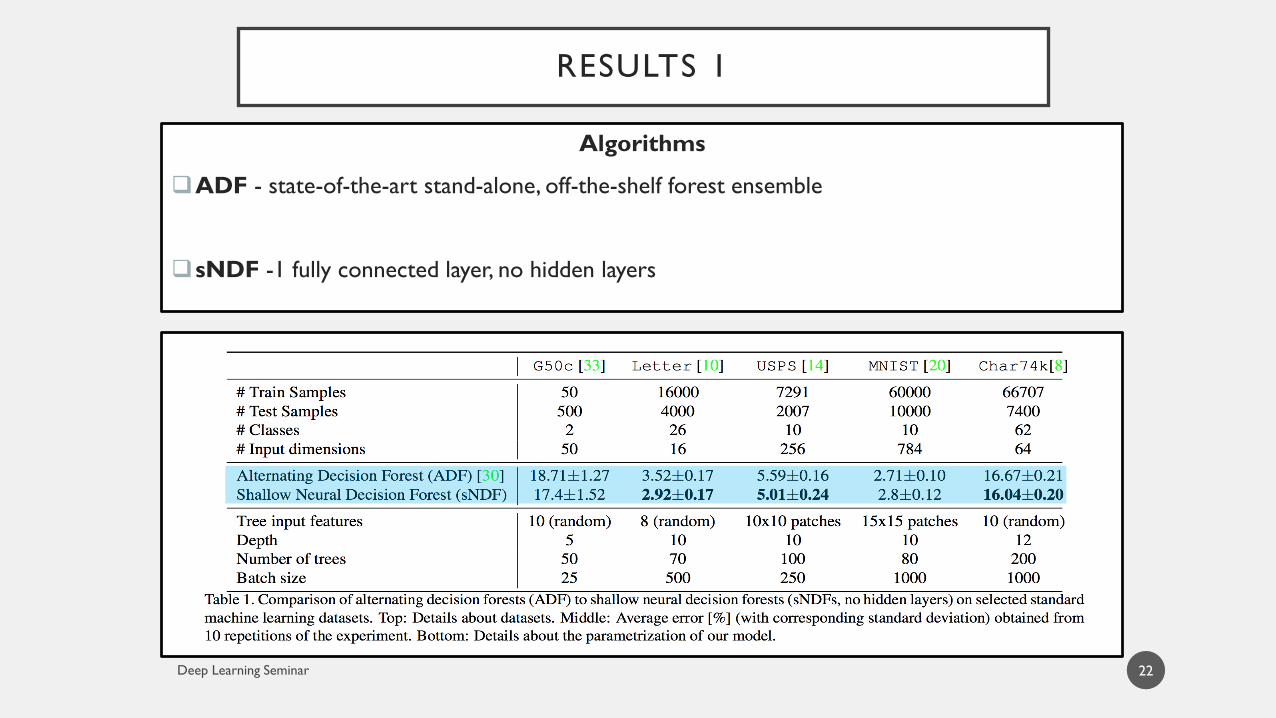
RESULTS 1
22
Algorithms
ADF - state-of-the-art stand-alone, off-the-shelf forest ensemble
sNDF -1 fully connected layer, no hidden layers
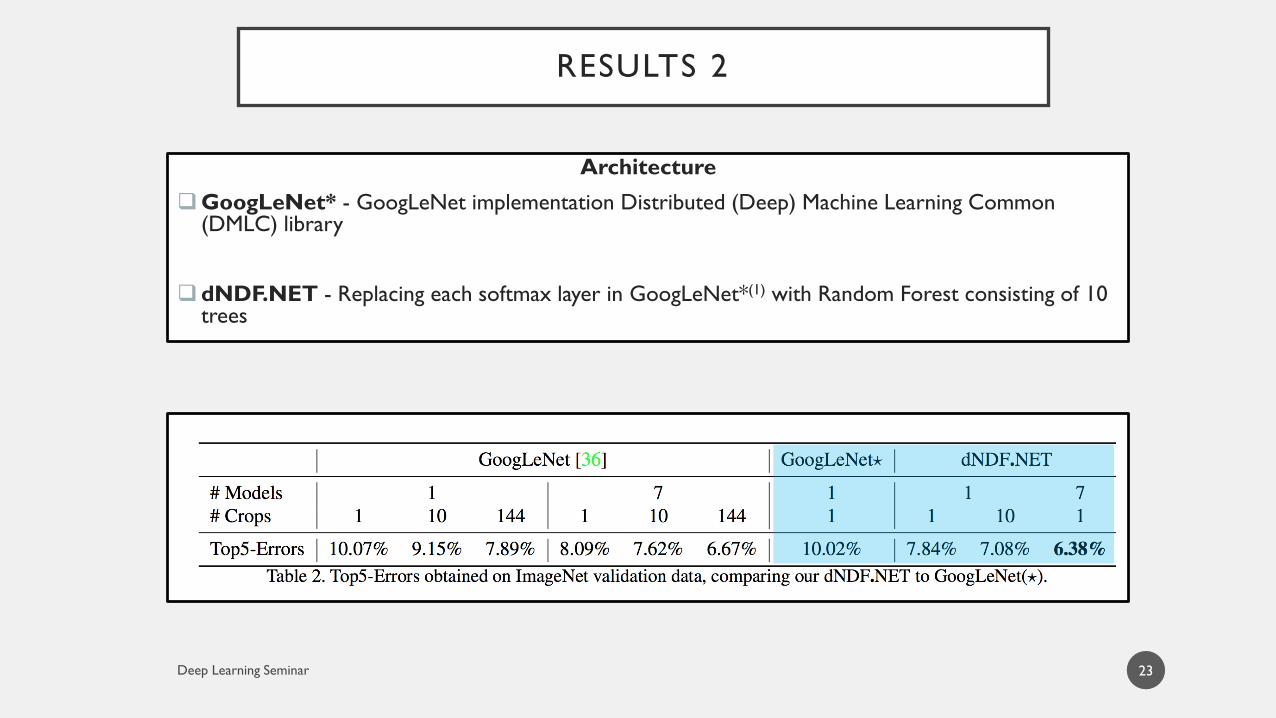
RESULTS 2
23
Architecture
GoogLeNet* - GoogLeNet implementation Distributed (Deep) Machine Learning Common (DMLC) library
dNDF.NET - Replacing each softmax layer in GoogLeNet*(1) with Random Forest consisting of 10 trees

CONCLUSIONS
24
Novel algorithm for learning Random Forest - sNDF (shallow neural decision forest)
Model unified representation learning and classifier using random forest -
dNDF.NET (deep neural decision forest)
Train dNFTs - 2 step stochastic gradient descent
Prediction function
Routing function
No dramatic improvement in accuracy comparing to regular GoogLeNet

RECAP
25
Before: Decision trees and random forests are efficient classifiers
CNNs are state of the art at feature extractions an classifiers
In “Deep Neural Decision Forests” ICCV 2015:
All softmax layers are used to deduce a random forest
GoogLeNet variation
Two steps SGD defined for finding both the decision and prediction functions
Trained E2E achieved (slightly) better results
Now:In “Decision Forests, Convolutional Networks and the Models in-Between”
Microsoft Research Technical Report arXiv 3 Mar. 2016
Generalize DT and CNN as Conditional Networks using routers
Improve state of the art architectures compute cost while maintaining accuracyYani Ioannou
Peter
Kontschieder

SAVE THE PLANET / YOUR PHONE(MOTIVATION)
26
VGG16 single forward pass uses ~ 30G FLOPS
Top ranking efficient super computer (HPC) ~ 10G FLOPS / Watt
https://www.top500.org/green500/
100,000,000 US search for an image on their cloud ~ 300MWatt
After one hour:
Energy equivalent to a ~ 45 ton of coal
https://www.euronuclear.org/info/encyclopedia/coalequivalent.htm
NomophobiaFrom Wikipedia, the free encyclopedia
is a proposed name for the phobia of being out of mobile phone contact.[1][2] It is, however, arguable that the word
"phobia" is misused and that in the majority of cases it is another form of anxiety disorder.[3][not in citation given] Although
nomophobia does not appear in the current Diagnostic and Statistical Manual of Mental Disorders, Fifth Edition (DSM-5), it
has been proposed as a "specific phobia", based on definitions given in the DSM-IV.[4][dubious – discuss]
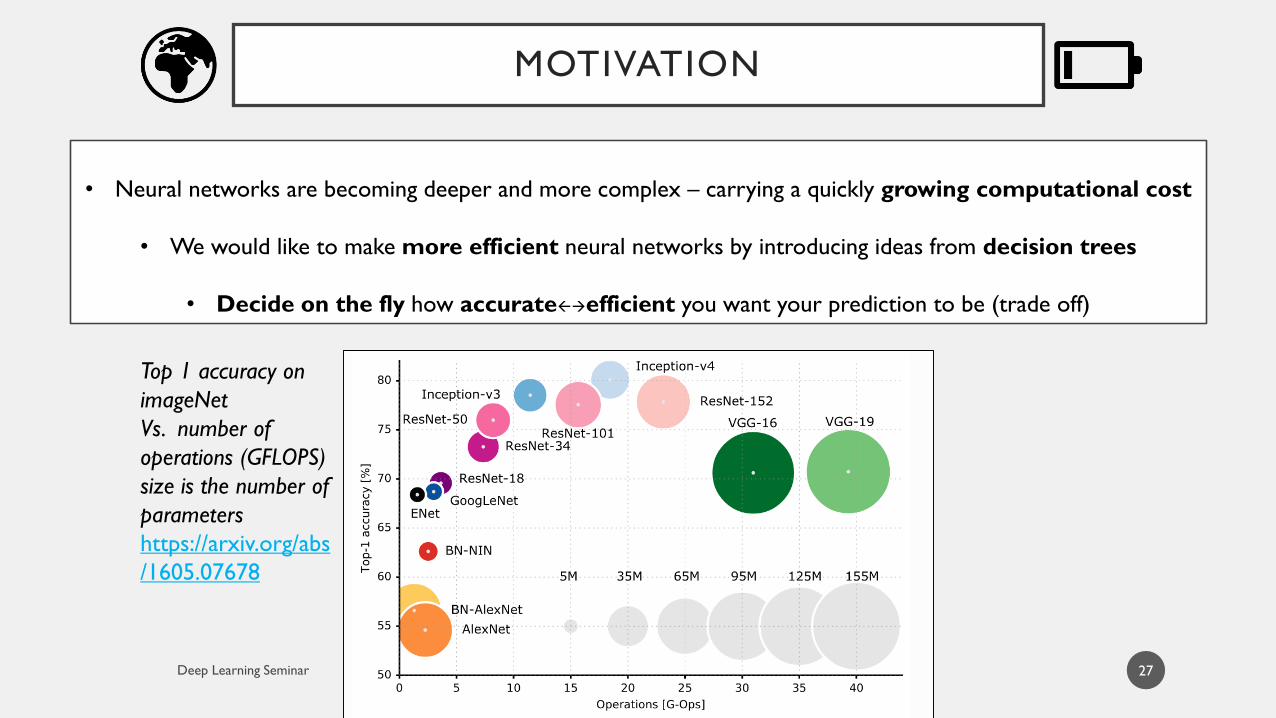
MOTIVATION
27
• Neural networks are becoming deeper and more complex – carrying a quickly growing computational cost
• We would like to make more efficient neural networks by introducing ideas from decision trees
• Decide on the fly how accurateefficient you want your prediction to be (trade off)
Top 1 accuracy on
imageNet
Vs. number of
operations (GFLOPS)
size is the number of
parameters
https://arxiv.org/abs
/1605.07678
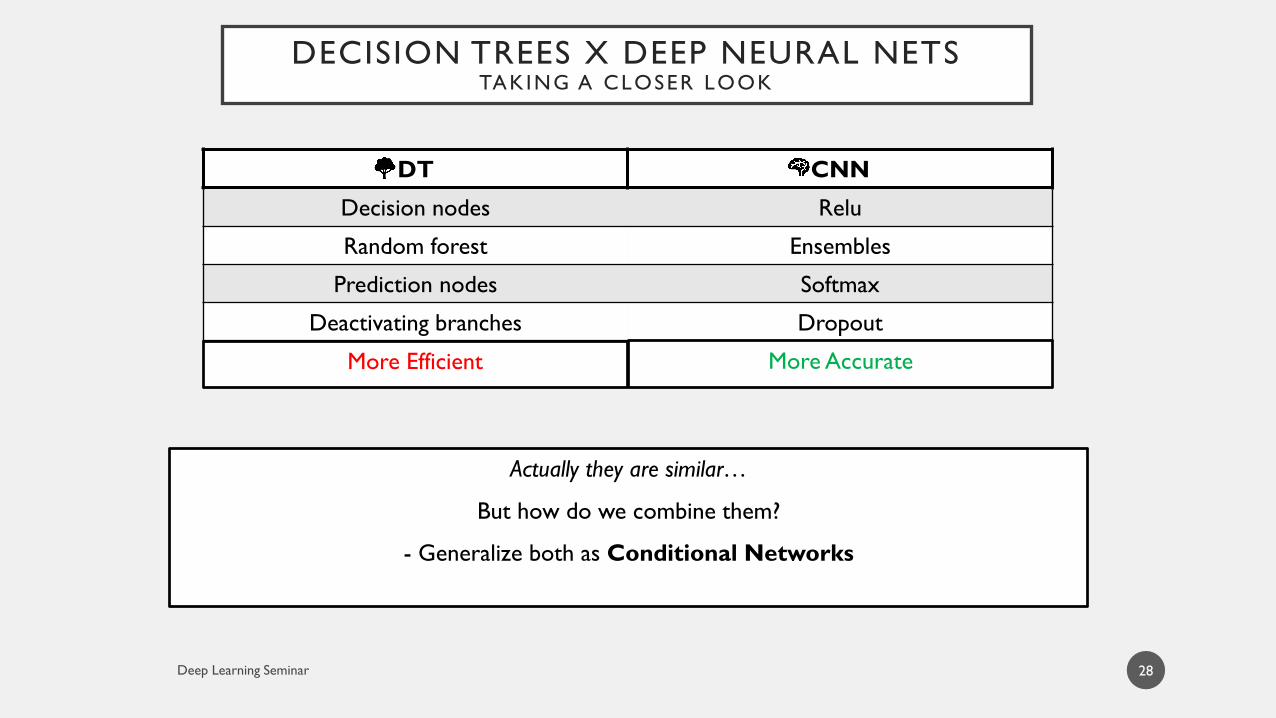
DT CNN
Decision nodes Relu
Random forest Ensembles
Prediction nodes Softmax
Deactivating branches Dropout
DECISION TREES X DEEP NEURAL NETSTAKING A CLOSER LOOK
28
Actually they are similar…
But how do we combine them?
- Generalize both as Conditional Networks
More Efficient More Accurate

POC - FROM NET TO TREE
29
Take 2 consecutive layers from
trained CNN (VGG)
Calculate the 2 layers cross-
correlation matrix of a fully
connected neural network
Rearrange as a block matrix
(higher cross-correlation values)
Decorrelate by zeroing block
off-diagonal elements
Replot the net with the
branched structure
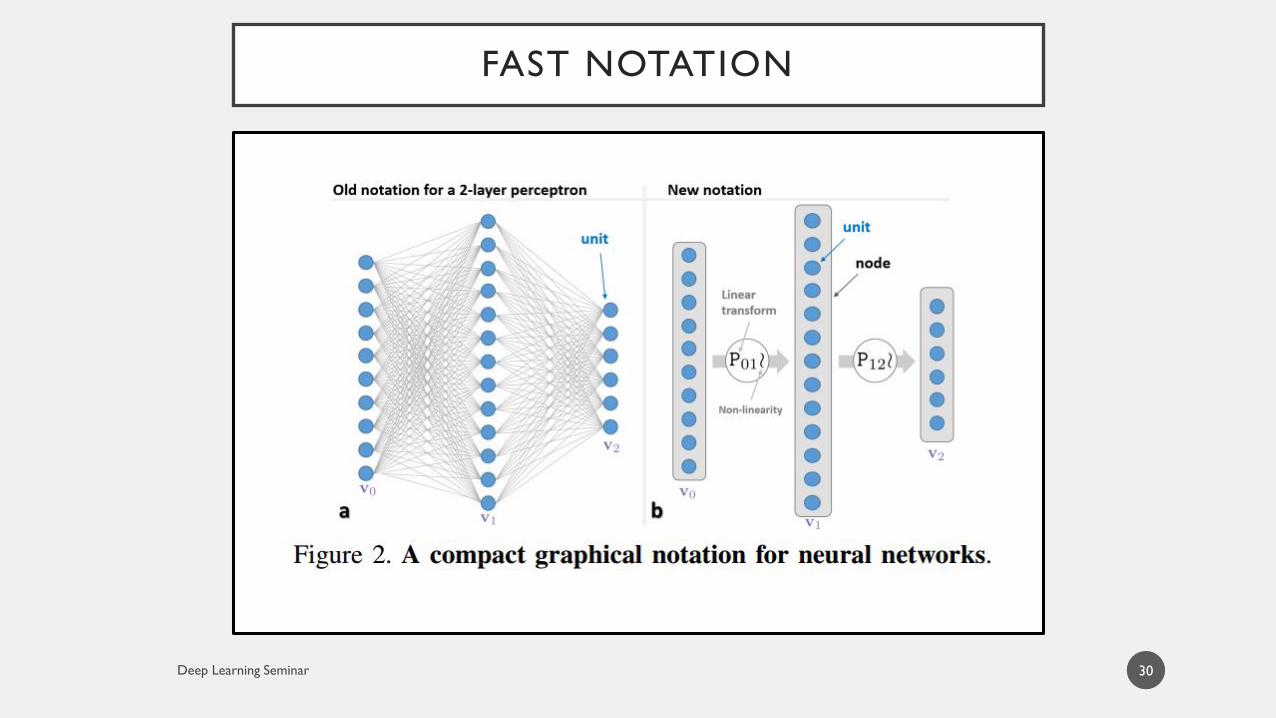
FAST NOTATION
30
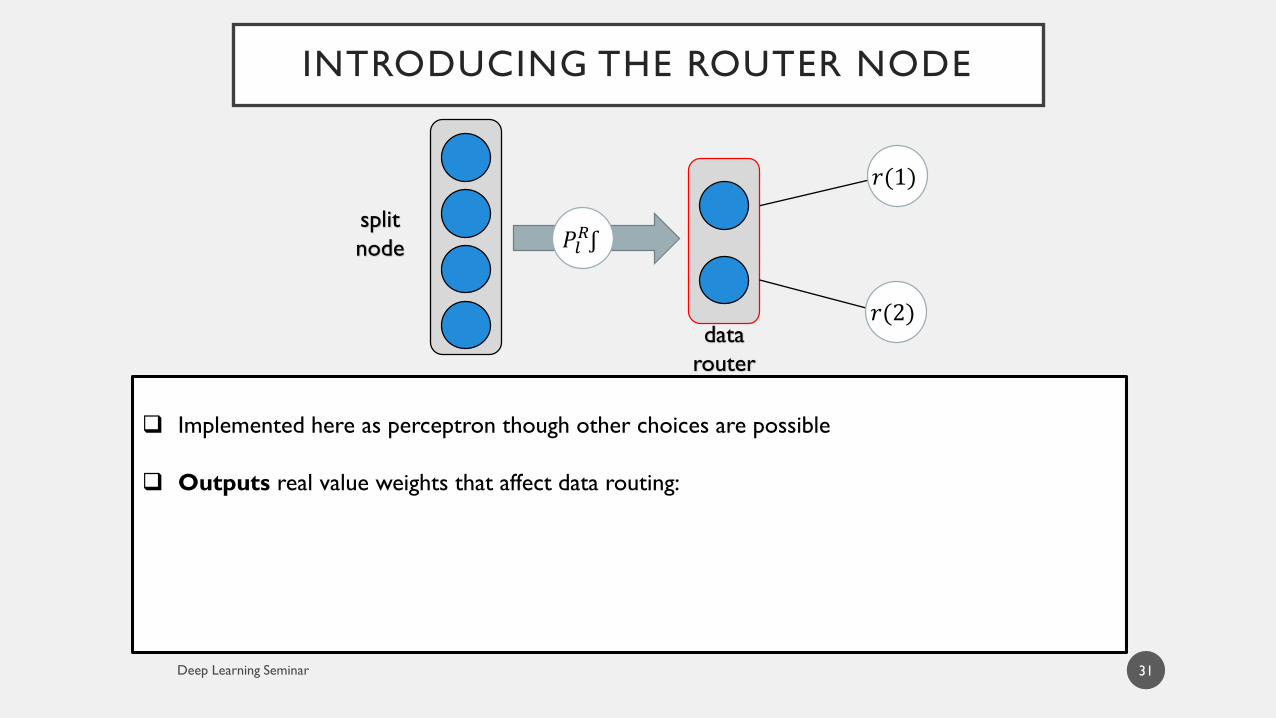
INTRODUCING THE ROUTER NODE
31
Implemented here as perceptron though other choices are possible
Outputs real value weights that affect data routing:
data
router
𝑃𝑙𝑅ʃ
split
node
𝑟(2)
𝑟(1)
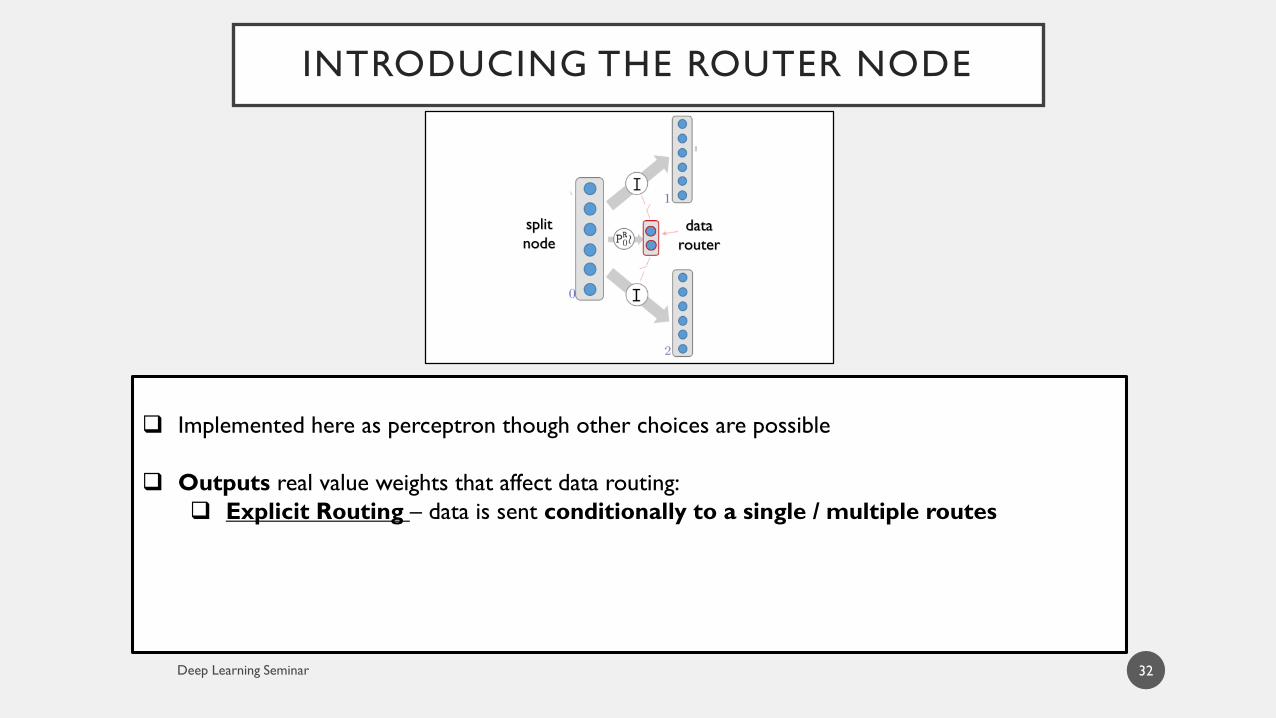
INTRODUCING THE ROUTER NODE
32
Implemented here as perceptron though other choices are possible
Outputs real value weights that affect data routing:
Explicit Routing – data is sent conditionally to a single / multiple routes
split
nodedata
router
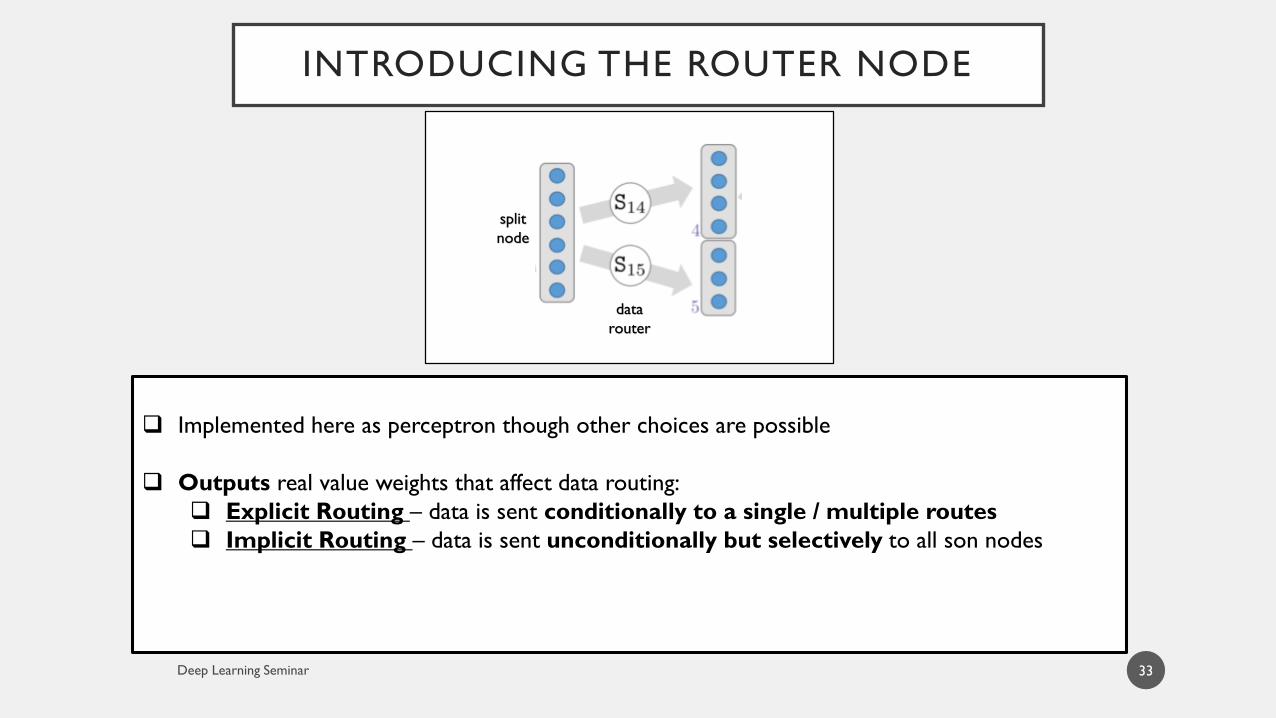
INTRODUCING THE ROUTER NODE
33
Implemented here as perceptron though other choices are possible
Outputs real value weights that affect data routing:
Explicit Routing – data is sent conditionally to a single / multiple routes
Implicit Routing – data is sent unconditionally but selectively to all son nodes
split
node
data
router
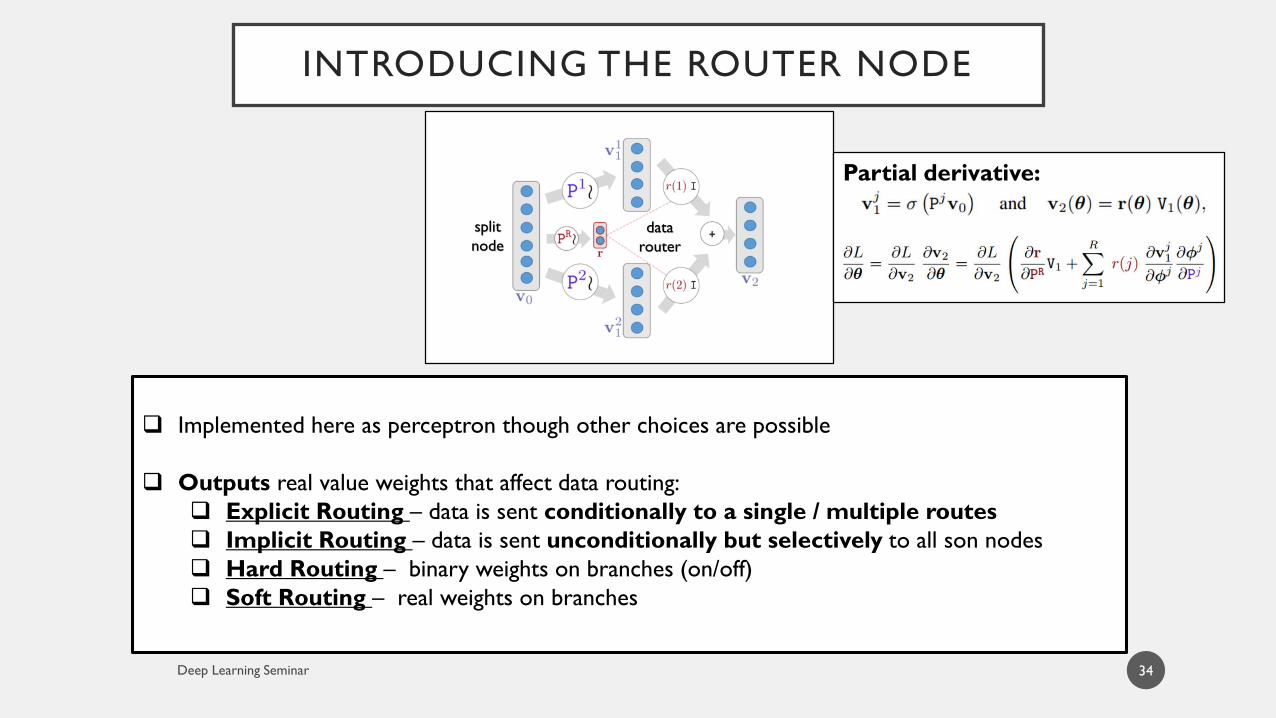
INTRODUCING THE ROUTER NODE
34
Implemented here as perceptron though other choices are possible
Outputs real value weights that affect data routing:
Explicit Routing – data is sent conditionally to a single / multiple routes
Implicit Routing – data is sent unconditionally but selectively to all son nodes
Hard Routing – binary weights on branches (on/off)
Soft Routing – real weights on branches
split
node
data
router
Partial derivative:
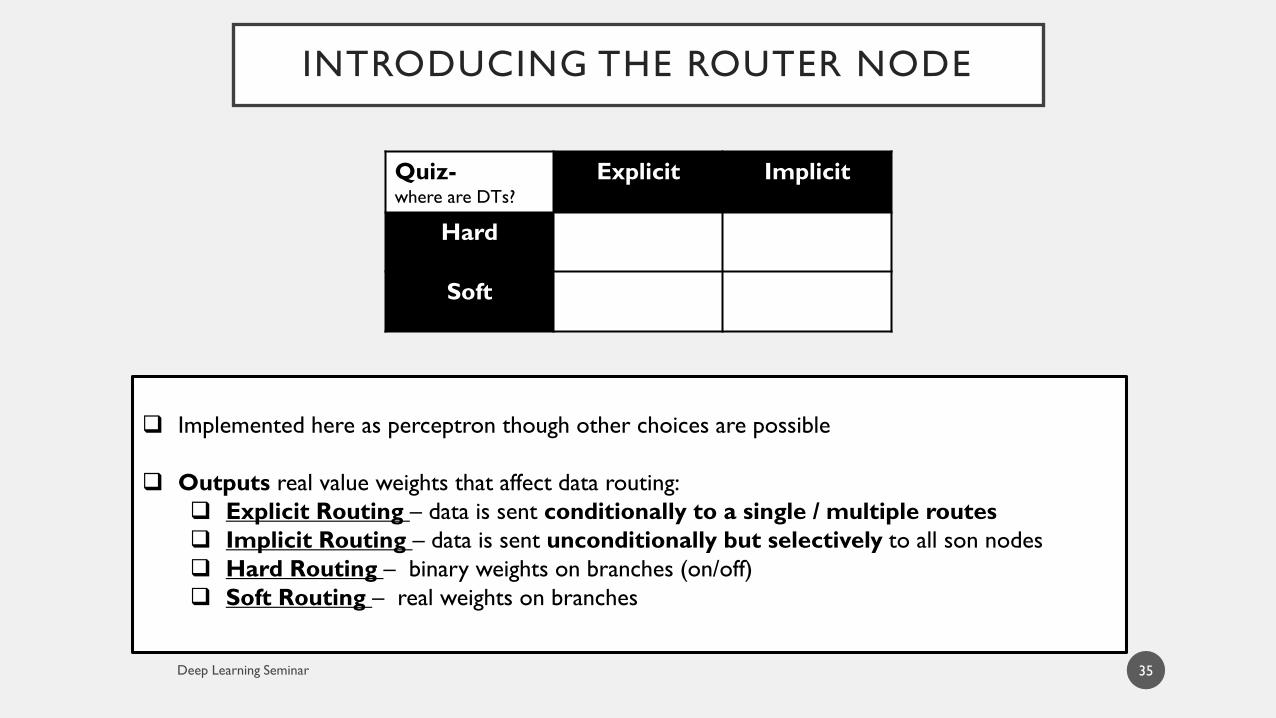
INTRODUCING THE ROUTER NODE
35
Implemented here as perceptron though other choices are possible
Outputs real value weights that affect data routing:
Explicit Routing – data is sent conditionally to a single / multiple routes
Implicit Routing – data is sent unconditionally but selectively to all son nodes
Hard Routing – binary weights on branches (on/off)
Soft Routing – real weights on branches
Quiz-where are DTs?
Explicit Implicit
Hard
Soft
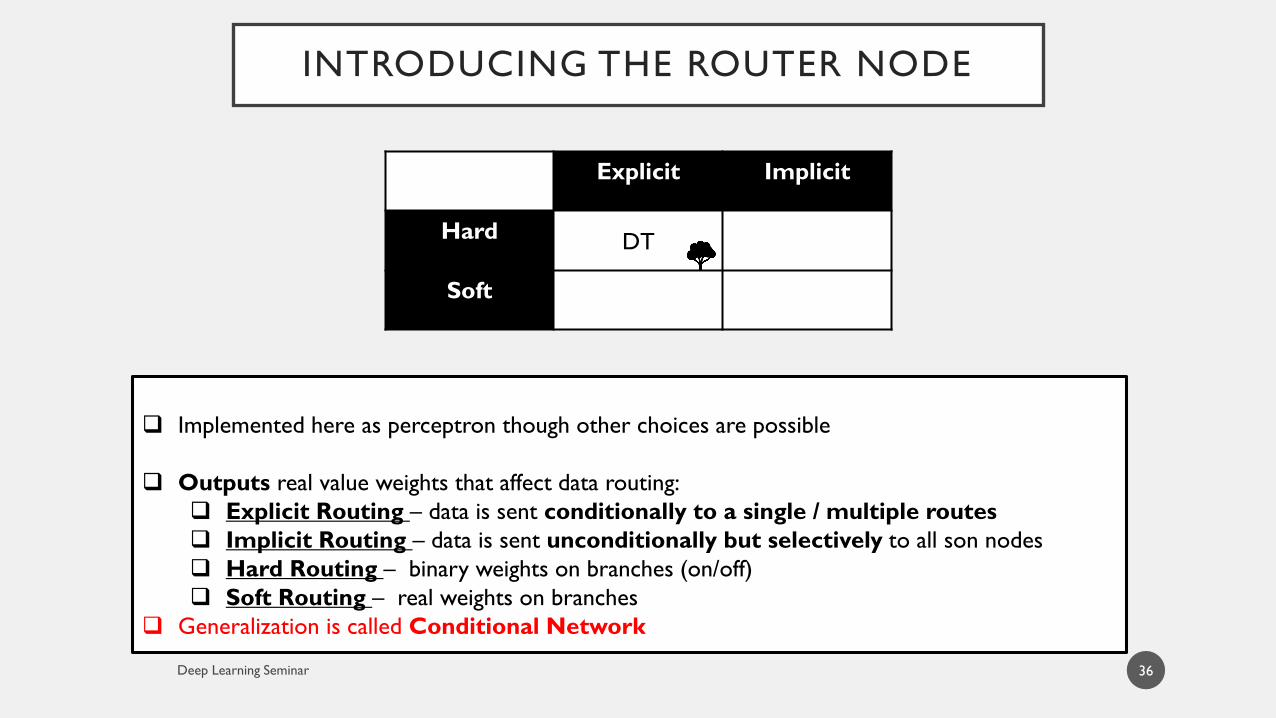
INTRODUCING THE ROUTER NODE
36
Implemented here as perceptron though other choices are possible
Outputs real value weights that affect data routing:
Explicit Routing – data is sent conditionally to a single / multiple routes
Implicit Routing – data is sent unconditionally but selectively to all son nodes
Hard Routing – binary weights on branches (on/off)
Soft Routing – real weights on branches
Generalization is called Conditional Network
Explicit Implicit
Hard DT
Soft
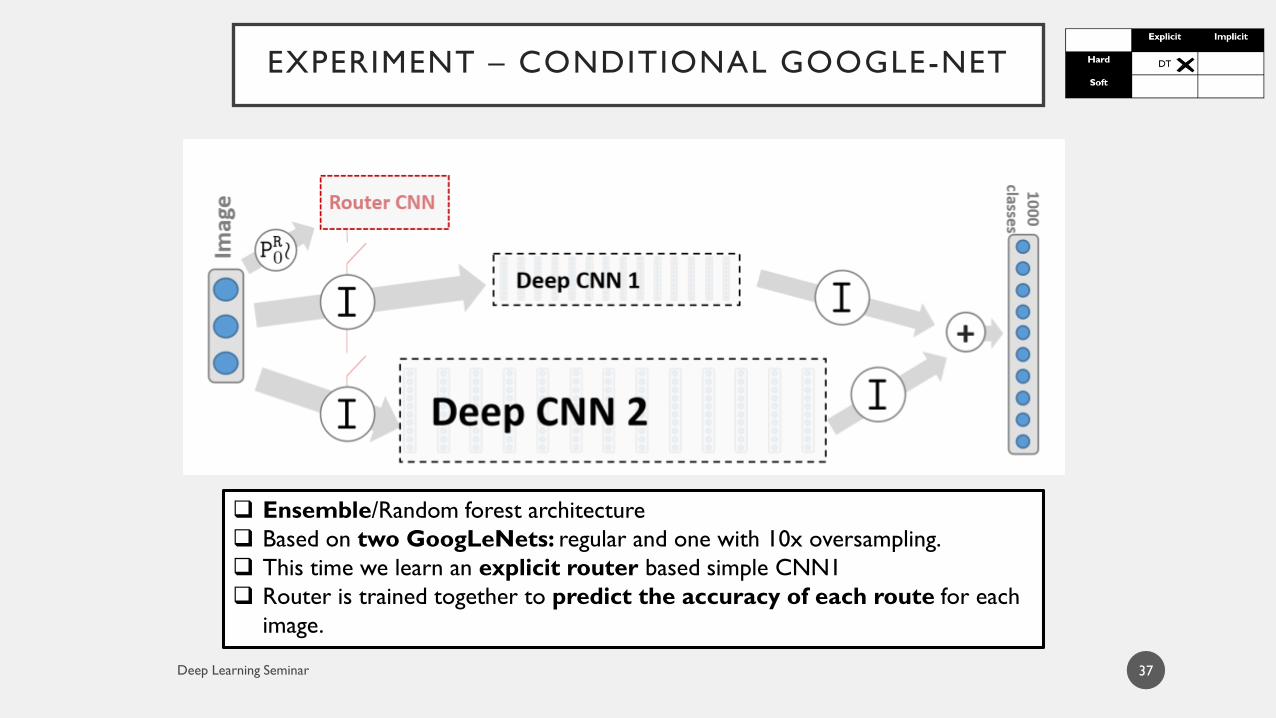
EXPERIMENT – CONDITIONAL GOOGLE-NET
37
Ensemble/Random forest architecture
Based on two GoogLeNets: regular and one with 10x oversampling.
This time we learn an explicit router based simple CNN1
Router is trained together to predict the accuracy of each route for each
image.
EXPERIMENT – CONDITIONAL GOOGLE-NET
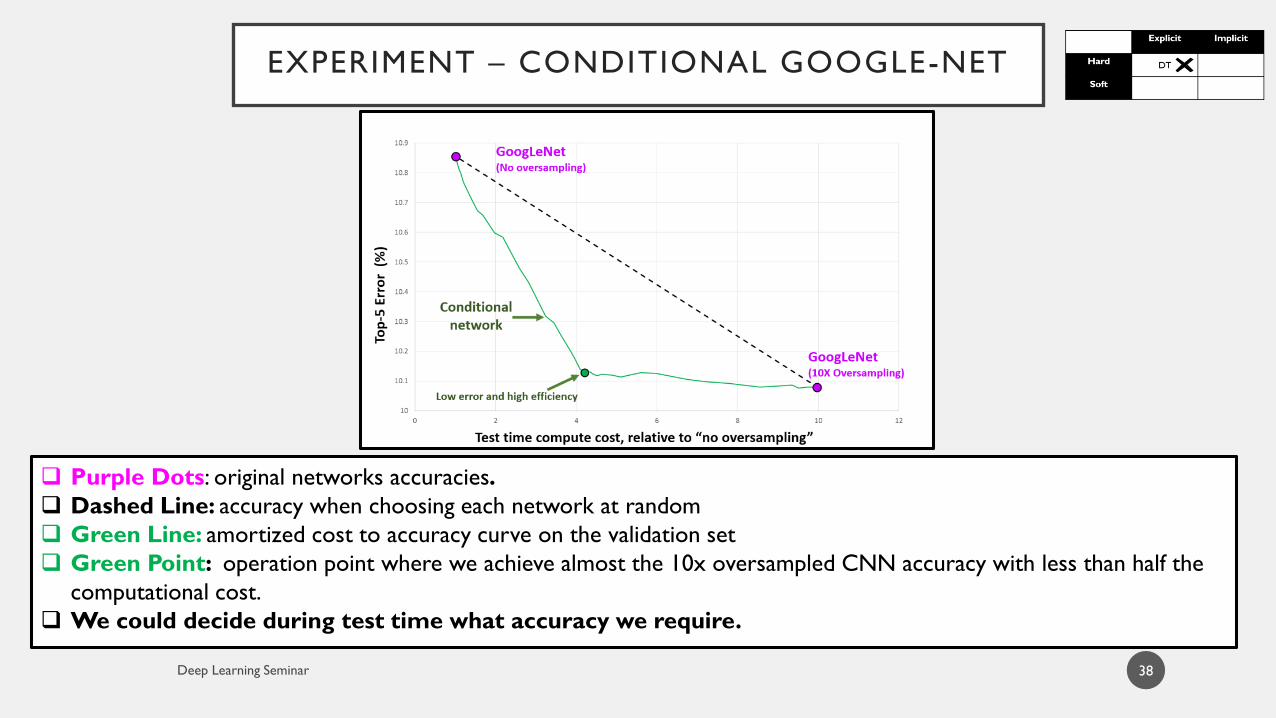
38
Purple Dots: original networks accuracies.
Dashed Line: accuracy when choosing each network at random
Green Line: amortized cost to accuracy curve on the validation set
Green Point: operation point where we achieve almost the 10x oversampled CNN accuracy with less than half the
computational cost.
We could decide during test time what accuracy we require.
EFFICIENCY BENEFITS OF IMPLICIT ROUTING
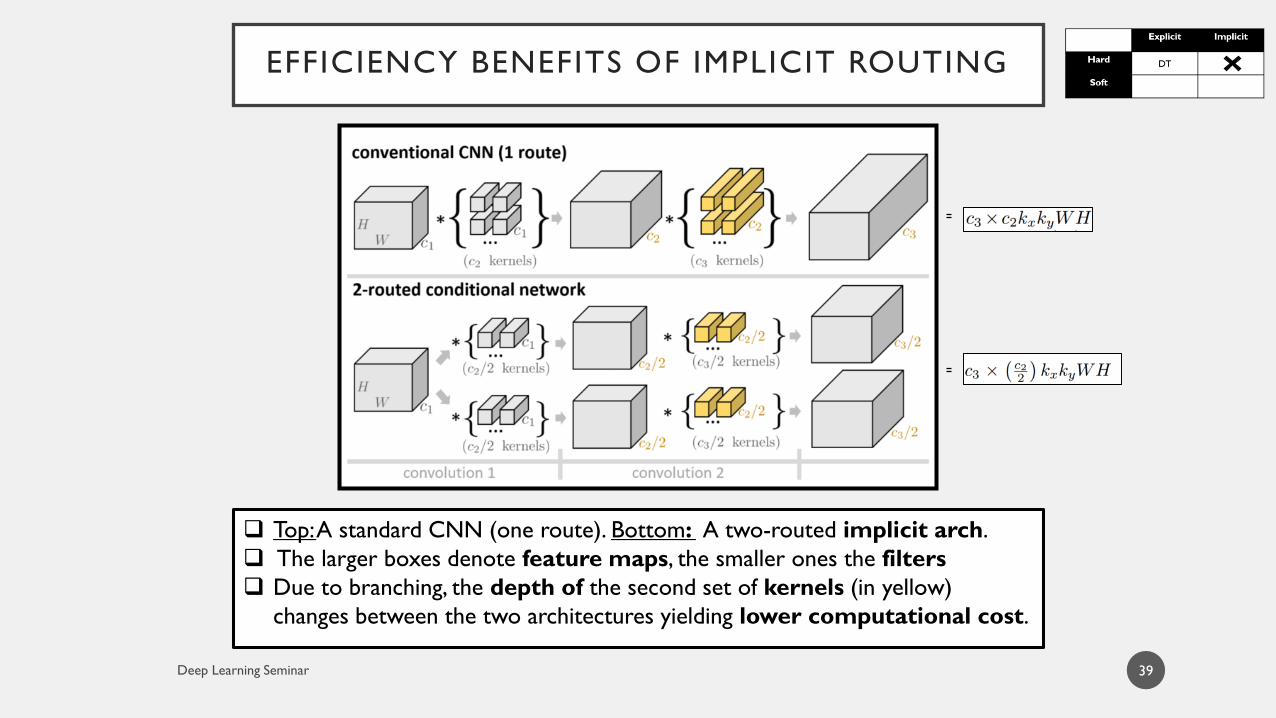
39
Top: A standard CNN (one route). Bottom: A two-routed implicit arch.
The larger boxes denote feature maps, the smaller ones the filters
Due to branching, the depth of the second set of kernels (in yellow)
changes between the two architectures yielding lower computational cost.
EXPERIMENT – CONDITIONAL VGG11
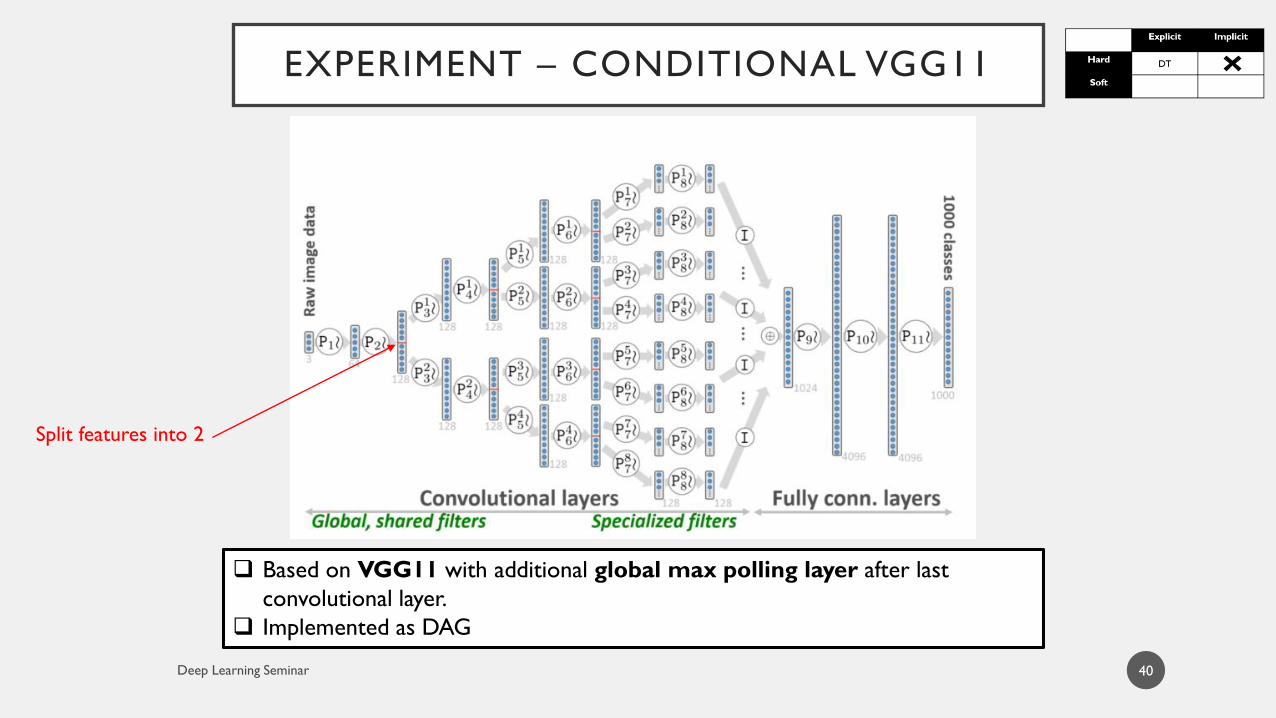
40
Based on VGG11 with additional global max polling layer after last
convolutional layer.
Implemented as DAG
Split features into 2
EXPERIMENT – CONDITIONAL VGG11
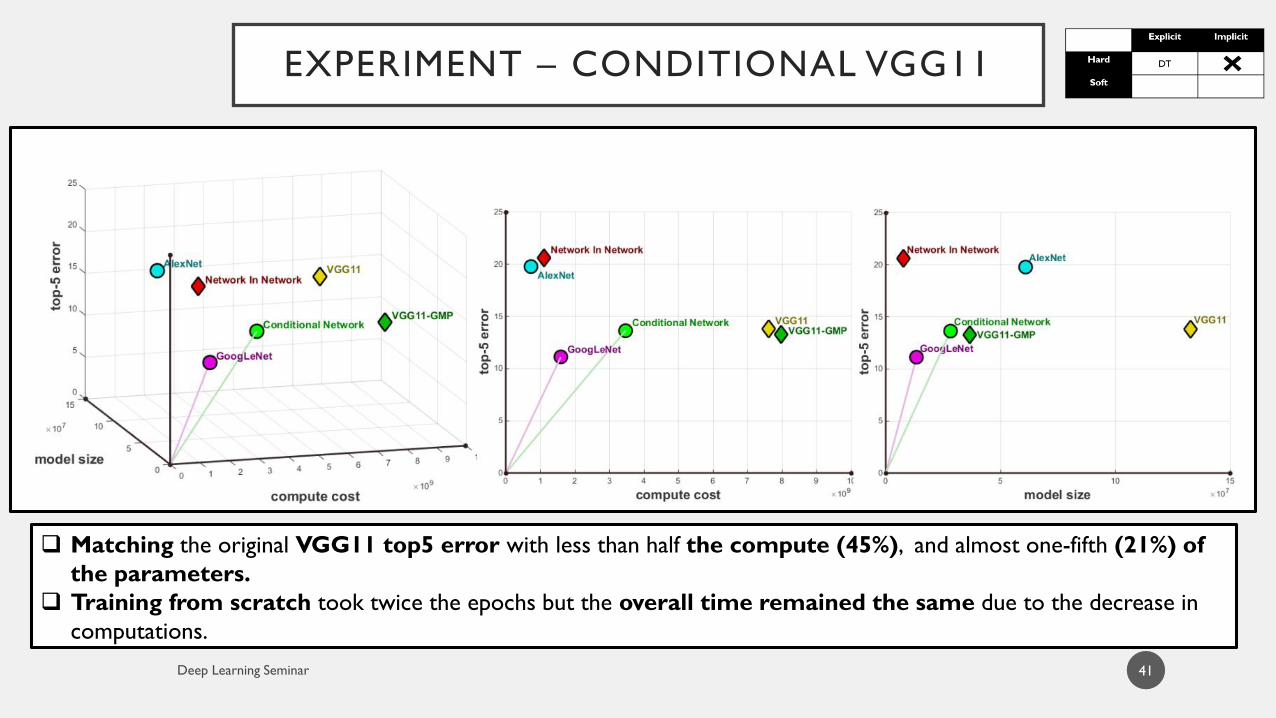
41
Matching the original VGG11 top5 error with less than half the compute (45%), and almost one-fifth (21%) of
the parameters.
Training from scratch took twice the epochs but the overall time remained the same due to the decrease in
computations.

Decision Trees are efficient and CNN are Accurate
Conditional NN are the generalization of both
Trade off - we try to find the sweet spot combining the two
By using Implicit Routing:
we could achieve 50% reduction of computational and memory cost.
By using Explicit Routing:
we could achieve 50% reduction of computational cost same accuracy
Decide on the fly how accurate-costly we want to be
*If you aren’t more accurate maybe you’re more efficient
TL;DR
42


















