
DB2 Information Integrator Version 8 - Lightyear Consulting€¦ · · 2014-07-28DB2 Information...
65
DB2 Information Integrator Version 8.1 Overview for DB2 User Group of Northern California Michael Lee – Oct 14 th , 2003
Transcript of DB2 Information Integrator Version 8 - Lightyear Consulting€¦ · · 2014-07-28DB2 Information...

DB2 Information Integrator Version 8.1 Overview for DB2 User Group of Northern CaliforniaMichael Lee – Oct 14th, 2003

IBM Q4 Events!
• Oct 14 - Chat with the Lab – Data Warehouses and Information Integration: Best Practices and Performance Characterization
• Oct 21-23 - DB2 Multiplatform Tools Proof of Technology• Oct 27-31 – Data Management Technical Conference• Nov 11-13 - DB2 Information Integrator Proof of Technology
• Education!– Oct 27-31 - DB2 Universal Database Performance Tuning and Montoring Workshop– Nov 17-20 - DB2 UDB Advanced Administration Workshop

AgendaIntegration - Some BackgroundDB2 and Information IntegrationDB2 Information IntegratorDB2 Information Integrator Performance TopicsDB2 Information Integrator - The Fine Print

Integration - Some Background

Integration is a strategic priority

Different Types of Integration Required
"Legacy"Apps
InformationIntegration
ProcessIntegration
UserInteraction
Consumers
Trading Partners
Service Providers
Suppliers
B2B Portal
B2C Site
Value ChainHeterogeneousEnvironments
New e-business Applications
Supply Chain Management
Customer Relationship Management
Service Provider Integration Into
ERP and HR Systems
Product Development Management
ApplicationConnectivity
Build to Integrate

What is Information Integration?Information integration refers to a category of middleware which lets applications access data as though it were in a single database, whether or not it is. It enables the integration of data and content sources to provide real-time read and write access, to transform data for business analysis and data interchange, and to manage data placement for performance, currency, and availability.
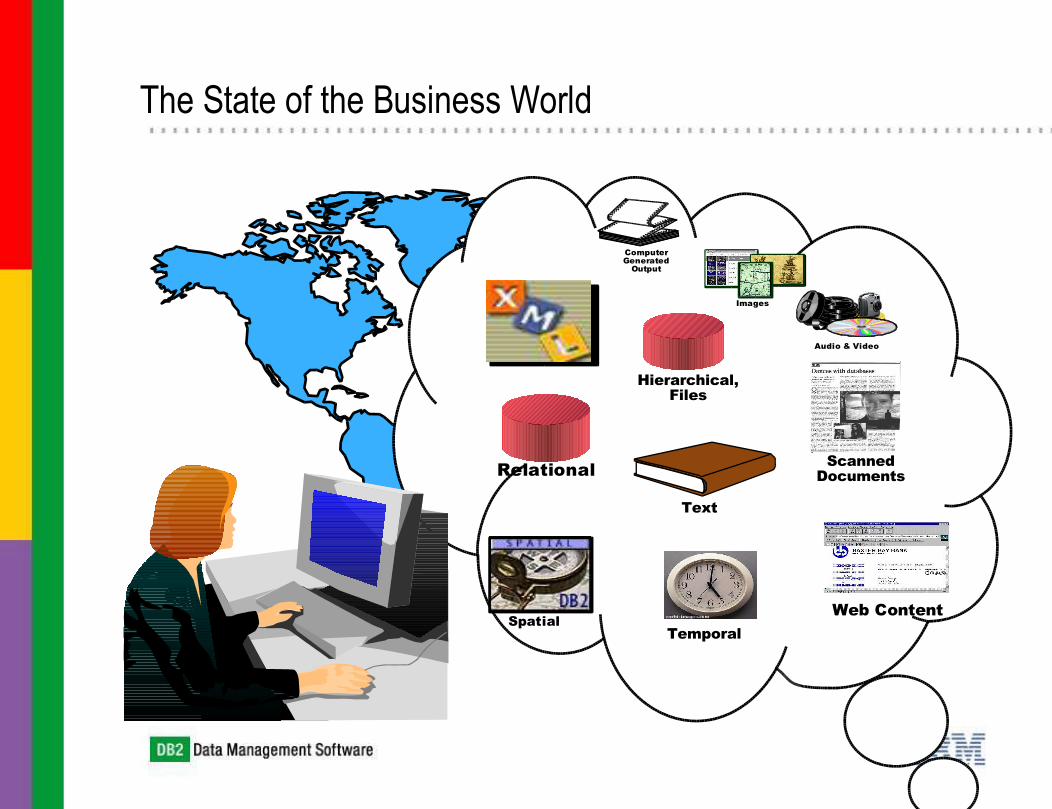
The State of the Business World
Audio & Video
ComputerGenerated
Output
Web Content
ScannedDocuments
Images
Text
Spatial
Relational
Hierarchical,Files
Temporal
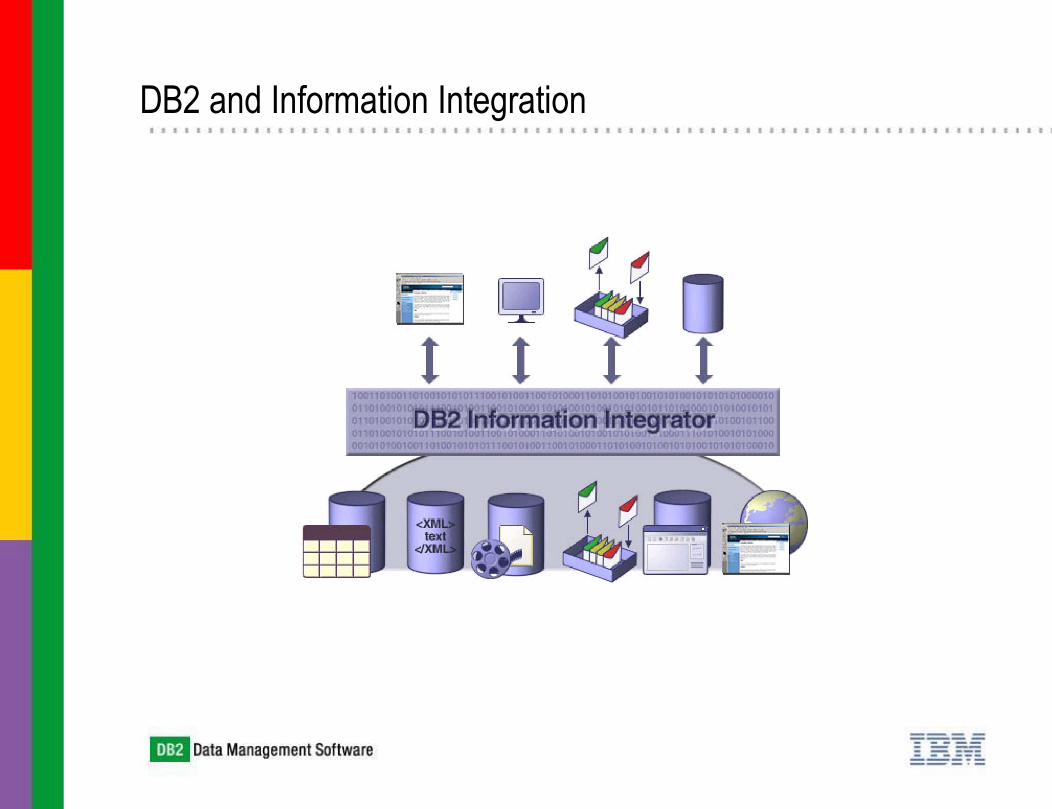
DB2 and Information Integration
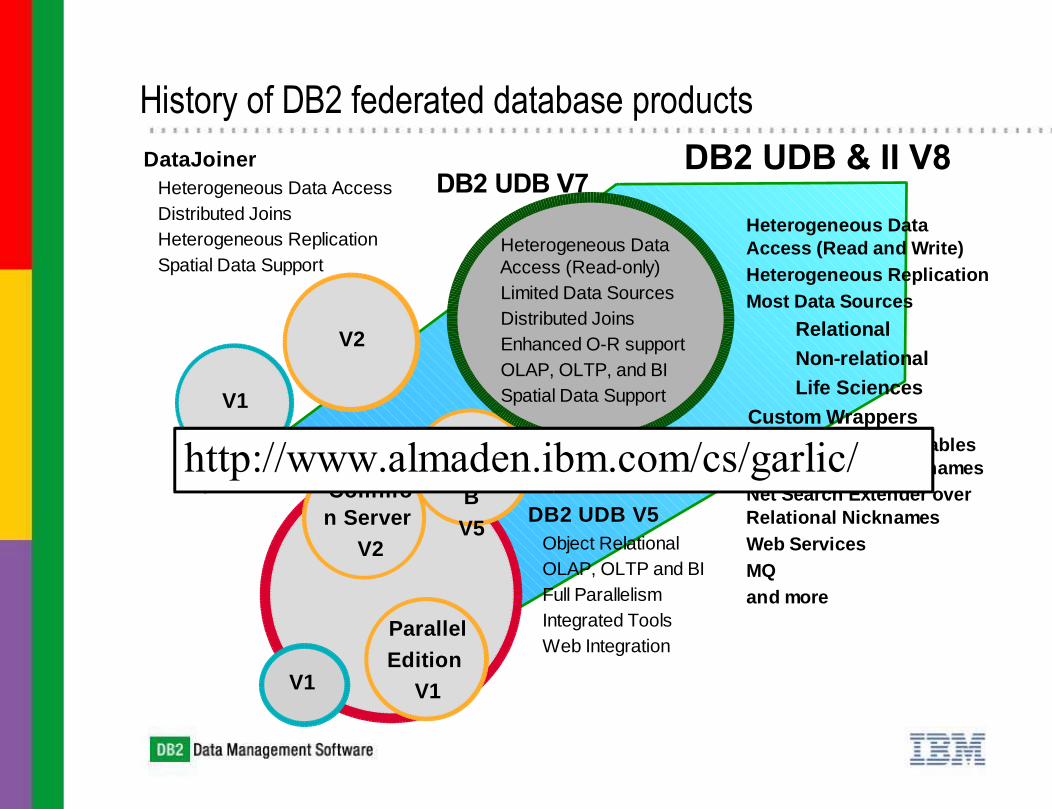
History of DB2 federated database productsDB2 UDB & II V8 DataJoiner
Heterogeneous Data AccessDistributed JoinsHeterogeneous ReplicationSpatial Data Support
V1
V2
V1
Parallel Edition
V1
DB2UDBV5
DB2 UDB V5Object RelationalOLAP, OLTP and BIFull ParallelismIntegrated ToolsWeb Integration
Parallel Edition
V1
Common Server
V2
Heterogeneous Data Access (Read-only)
Limited Data SourcesDistributed JoinsEnhanced O-R supportOLAP, OLTP, and BISpatial Data Support
Heterogeneous Data Access (Read and Write)
Heterogeneous ReplicationMost Data Sources
RelationalNon-relationalLife Sciences
Custom WrappersMaterialized Query Tables
over Relational Nicknames Net Search Extender over
Relational NicknamesWeb ServicesMQand more
DB2 UDB V7
http://www.almaden.ibm.com/cs/garlic/

Information Integration with DB2 Universal DatabaseWebsphere MQSeries User-Defined Functions, MQListenerWeb services deployment with DADX, Websphere SOAP Server, SOAP User-Defined FunctionsXML
ƒ XML Extenderƒ XML Publishing functions (delivered with DB2 UDB V8.1.2)
Federation to IBM Relational Sourcesƒ DB2 UDBƒ DB2 for zOS and OS/390ƒ DB2 for iSeriesƒ Informix Dynamic Server (Versions 7 & 9)ƒ Informix Extended Parallel Server (XPS)

DB2 Information Integrator

What Problems Does DB2 Information Integrator AddressData Access
ƒ Heterogeneous Data FederationData Placement
ƒ Heterogeneous Data Replicationƒ Heterogeneous Data Caching General Availability
June 13, 2003

Data Federation
Functions
Transparencyƒ Appears to be one source
Heterogeneityƒ Integrates data from diverse sourcesƒ Relational, Structured, XML, messages, Web, …
Extensibility ƒ Federate almost any data source.ƒ Development tooling provided
High Functionƒ Full query support against all dataƒ Capabilities of sources as well
Autonomyƒ Non-disruptive to data sources, existing applications, systems.
Performanceƒ Optimization of distributed queries
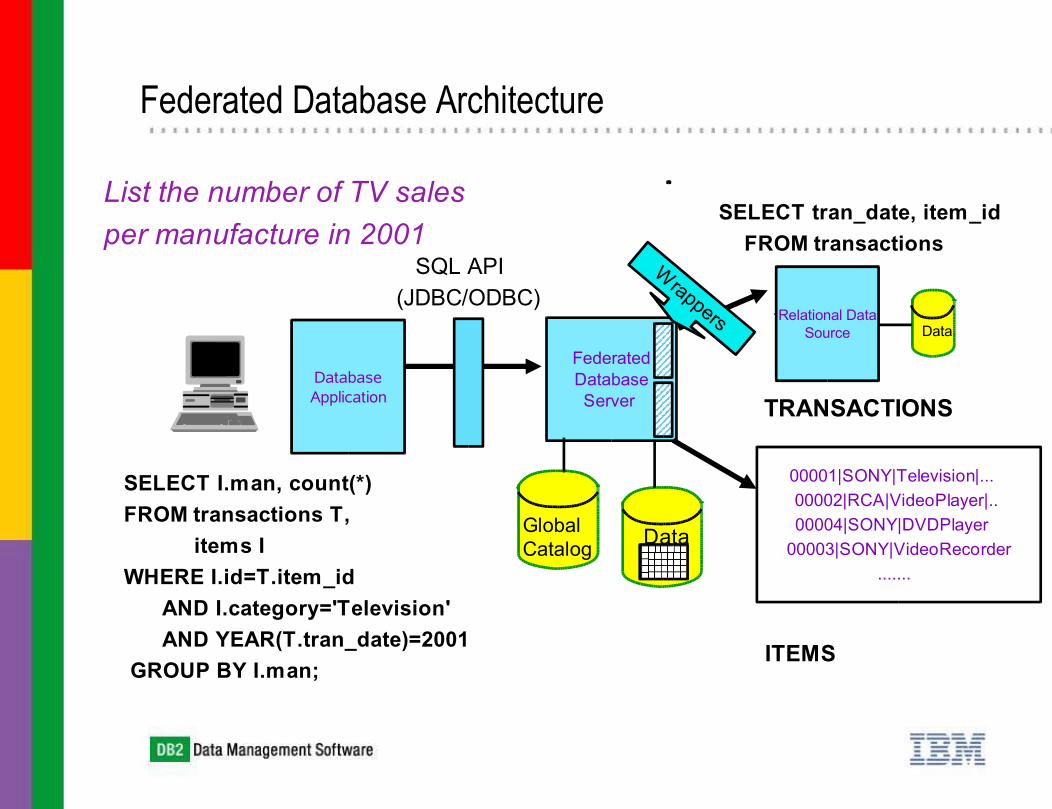
Federated Database Architecture
Federated Database Server
Data
Relational Data Source Data
Global Catalog
SQL API(JDBC/ODBC)
Wrappers
00001|SONY|Television|... 00002|RCA|VideoPlayer|.. 00004|SONY|DVDPlayer
00003|SONY|VideoRecorder.......
Database Application
SELECT I.man, count(*)FROM transactions T, items IWHERE I.id=T.item_id AND I.category='Television' AND YEAR(T.tran_date)=2001 GROUP BY I.man;
SELECT tran_date, item_id FROM transactions
ITEMS
TRANSACTIONS
List the number of TV salesper manufacture in 2001

Staging tablesStaging tables
Combined with the federation engine -> a powerful integration tool!
IMS
DB2/zOS
DB2/iSeries
DB2/UDB
Sybase
SQL Server
IBM Informix
Oracle
ANY source
LOG based
Trigger based
DB2/zOS
DB2/iSeries
Sybase
SQL Server
IBM Informix
Oracle
DB2/UDB
External application
Replication architecture for integrating information
Teradata
Federated Engine

Multi-tiered Caching with Materialized Query TablesImprove query performance and availability Administrator defines Materialized Query Table
ƒ Precomputed or frequently used valuesƒ Any data from the federated systemƒ Application indicates ability to use cacheƒ Implicit or explicit use
Developer enables cache useƒ If enabled, reads are handled from the cache, writes
passed through to the sourceƒ If not, reads and writes passed through to source
Cache refresh managed:ƒ Manuallyƒ By replicationƒ Various refresh strategies under design
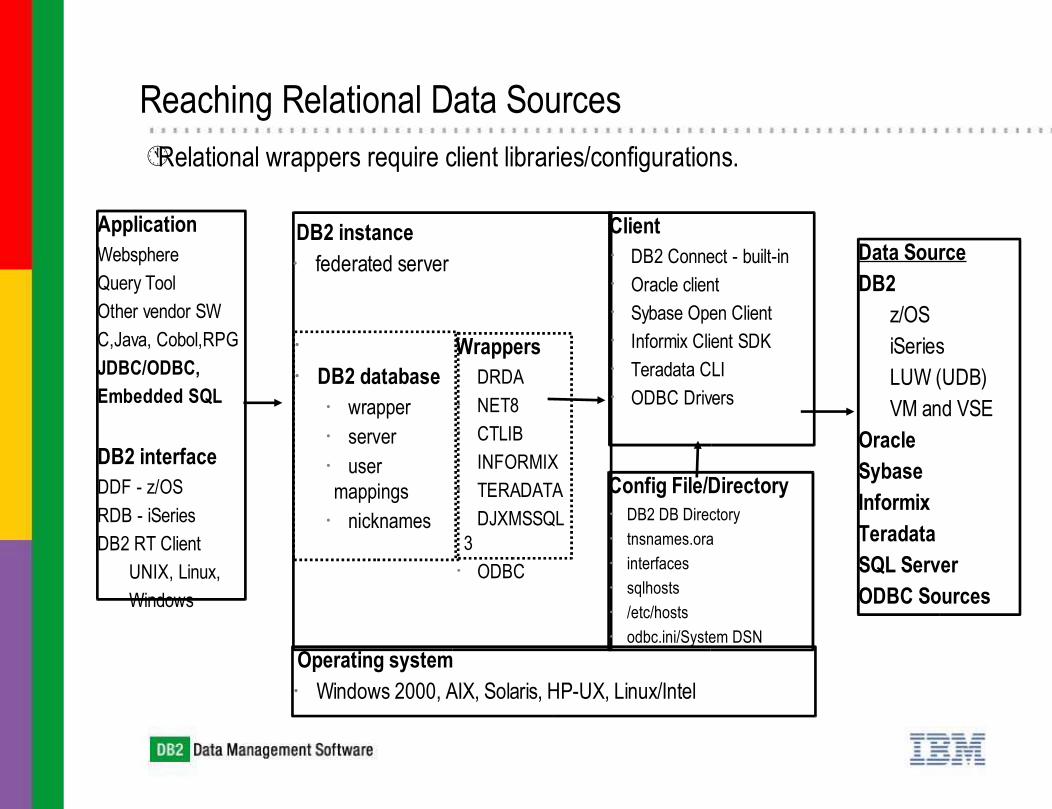
Reaching Relational Data Sources
ApplicationWebsphereQuery ToolOther vendor SWC,Java, Cobol,RPGJDBC/ODBC,Embedded SQL
DB2 interfaceDDF - z/OSRDB - iSeriesDB2 RT Client
UNIX, Linux,Windows
Data SourceDB2
z/OSiSeriesLUW (UDB)VM and VSE
OracleSybaseInformixTeradataSQL ServerODBC Sources
DB2 instance federated server
Wrappers DRDA NET8 CTLIB INFORMIX TERADATA DJXMSSQL3 ODBC
Client DB2 Connect - built-in Oracle client Sybase Open Client Informix Client SDK Teradata CLI ODBC Drivers
Operating system Windows 2000, AIX, Solaris, HP-UX, Linux/Intel
DB2 database
wrapper server user mappings nicknames
Config File/Directory DB2 DB Directory tnsnames.ora interfaces sqlhosts /etc/hosts odbc.ini/System DSN
Relational wrappers require client libraries/configurations.

Crystal DecisionsVision
ƒ As a world-leading information infrastructure company, Crystal Decisions helps businesses make better decisions by bringing together their people and their information.
Challenge ƒ Improve response time for complex queries over distributed heterogeneous data sources
Solution ƒ Relational Connect provides transparent, globally optimized access to heterogeneous, distributed data.
Crystal Reports accesses the distributed data as if it were a single database. Response time improvement of up to 98% seen in house.
Business Valueƒ "Users can provide coherent reporting accessing non-DB2 data sources and discover new ways to meet
the information needs of their organizations. And the more information business analysts can incorporate into their views of their company's activities, the more effectively they can steer their companies in the direction of higher profits." - Janet Wood, vice president of business development, Crystal Decisions.
Competitive Valueƒ "DB2 Relational Connect provides Crystal Reports with the fastest federated querying capability on the
market today." -Trevor Smith, Program Manager, Business Development Group, Crystal Decisions

Reaching Non-Relational Data SourcesSame architecture as for Life Sciences Data Connect
ApplicationWebsphereQuery ToolOther vendor SWC,Java, Cobol,RPGJDBC/ODBC,Embedded SQL
DB2 interfaceDDF - z/OSRDB - iSeriesDB2 RT Client
UNIX, Linux,Windows
DB2 instance federated server
Wrappers Flatfile XML BLAST Excel Documentum HMMER Entrez BioRS Extended Search
Operating system (check for specific wrappers) Windows 2000, AIX, Solaris, HP-UX, Linux/Intel
DB2 database
wrapper server user mappings nicknames
Table-Structured File XML file
Excel 97/2000 Excel file
Dctm clientDocumentum
data storeHMMER data
sourceHMMERdaemon
NCBI Website
BioRS Server
ES ServerES client
BLAST data source
BLAST daemon

AventisVision
ƒ A leader in the discovery and development of innovative pharmaceutical products dedicated to improving life through the discovery and development of innovative products.
Challenge ƒ Increase drug research efficiency and encourage interdisciplinary cooperation between chemists and biologists. Scientific users require integrated view of chemical & biological information stored in distributed Oracle sources, as well as external non-relational sources.
Solution ƒ DiscoveryLink provides federated access to Oracle databases and external sources such as genomics & proteomics data across four worldwide locations.ƒ Sophisticated scientific mining algorithms
Business Valueƒ Increased research productivity leading to drug innovation and reduced time-to-market
Competitive Valueƒ " DiscoveryLink allows us to access and mine the physical data in a way never before possible,
significantly speeding up the drug discovery and development process." -- Peter Loupos, Global

Federated ConceptsWrapper: the data access code; this understands data source capabilitiesServer: a specific data source, e.g. a database on a DB2 instance.User Mapping: information needed to connect to a specific serverPassthru Session: a special mode that allows users to submit SQL statements directly to a data sourceNickname: a specific data set managed by a server, mapped to rows and columns in DB2 UDBIndex Specification: a index catalog entry for a nicknameType Mapping: a mapping between a data source type and a DB2 UDB data typeFunction Mapping: a mapping between a data source function and a DB2 UDB functionFunction Template: a virtual function definition for a data source function that cannot be executed on DB2 UDBOption: an additional attribute specific to each source to customize an object

DB2 Information Integration Features Insert/Update/Delete against relational nicknames
ƒ Used by Heterogeneous replication in DPropR.ƒ Supported operations include:
–insert with values, insert with subselect–searched updates/deletes–positioned updates/deletes
Materialized Query Tables over relational nicknamesƒ Allows previously cached query results to be used to answer queries.
Heterogeneous ReplicationEnhanced Control Center GUI for Federated SystemTransparent DDL
ƒ Allows CREATE TABLE to be issued on DB2 to create a remote table and a nickname for this remote table in one step.
Large Object Supportƒ LOB retrieval for all relational wrappersƒ LOB Insert/Update/Delete for Oracle

More DB2 Information Integration FeaturesExpand data source support
ƒ Relational Wrappers–ODBC, Teradata wrappers
ƒ Non-Relational Wrappers–Text, Excel, XML, ...–HMMER, Entrez, BioRS wrapper, ...–Lotus Extended Search wrapper
Expanded operating system supportƒ In addition to AIX ® and Windows NT, servers that use Linux, HP-UX,Solaris ™ Operating Environment,
and Windows 2000 operating systems can now be used as DB2 federated servers.–For now, Linux on Intel only
Garlic wrapper planning technologyƒ Allows non-relational wrappers to be written more "easily"ƒ 'Quirky' data sources can be modeled more accurately.ƒ Life Sciences Data Connect wrappers are all now using Garlic wrapper planning technology.
Net Search Extender: text search against relational nicknamesƒ useful for those sources that do not support text searchesƒ text indexes can be defined over relational nicknames on DB2 II
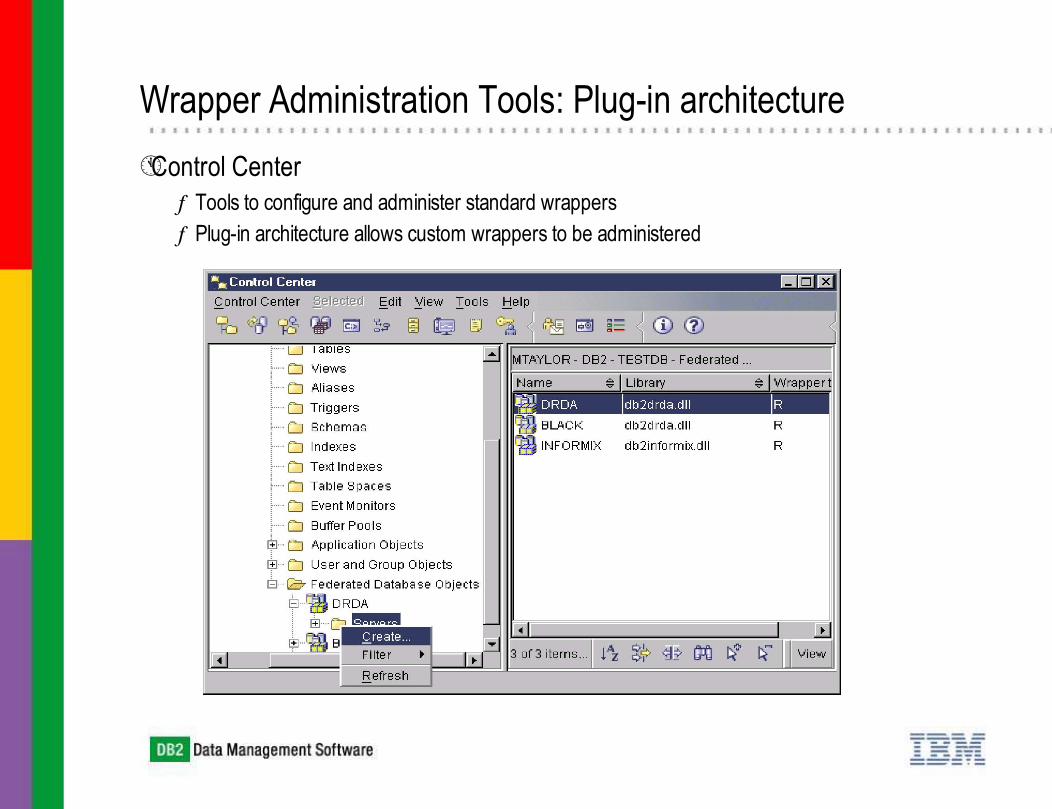
Control Centerƒ Tools to configure and administer standard wrappers ƒ Plug-in architecture allows custom wrappers to be administered
Wrapper Administration Tools: Plug-in architecture

Wrapper Administration Tools: Dynamic DiscoveryDynamic Discovery mechanism enables new data sets to be discovered and automatically configuredWrapper writer optionally provides GUI and discovery routine for custom wrappers

Wrapper Module
Shared library with specific entry pointsRepresents a class of data sourcesDynamically loaded on demand by UDB
Client Application
SQL DB2/UDB
flatfile
Teradata
create wrapper teradata library 'teradata.so' create wrapper flatfile library 'libdb2lsfile.a'

Server
Represents a specific data sourceProvides information about data source capabilities
Tera
data
Se
rver
Teradata
Client Application
SQL DB2/UDB
flatfile
Teradata
create server mapping from mytd to node "tdatsvr" type teradata VERSION 3.0 protocol "teradata" authid "tempx" password "xxpibm"; create server ff wrapper flatfile;
db2 identifies a specific db2 SID

Remote User
Information needed to identify end user to a particular server
Client Application
SQL DB2/UDB
teradata
Tera
dat
aSe
rver
Store Data
uid: j15user1
pwd: secret
flatfile
create user mapping from user to server mytd authid "tempx" password "xxxxxm" ;

Nickname
Represents a particular collection of data at a serverMapped to rows and columns in UDBActs like an alias
Client Application
SQL DB2/UDB
drda Tera
dat
aSe
rver Store Data
CatalogsMOLECULES
TESTS
flatfile

Nicknames
To create the DB2 nickname:create nickname td_div for mytd.dw_dss.lu_division; To create the flat file nickname: CREATE NICKNAME tests (id char(5), score smallint, type char(20)) for server ff OPTIONS(FILE_PATH '/home/etlin/sql/flattests.txt', COLUMN_DELIMITER '|');

CREATE NICKNAME O_EMP FOR DB2OS390.J15USER3.EMP
A table EMP exists on DB2 for OS/390EMPNO EMPNAME
100200300400500
Owner is J15USER3
SmithJonesAdamsMillerBennett
A table OFFICE exists on Teradata:EMPNO
100200300400500
OFFICENO
C200C202C204C206C208
Owner is J15USER1
CREATE NICKNAME TD_OFFICE FOR TERADATA.J15USER1.OFFICE
SmithJonesAdamsMillerBennett
EMPNAME OFFICENO
C200C202C204C206C208
Putting it all together...
SELECT O_EMP.EMPNAME, TD_OFFICE.OFFICENOFROM o_emp, td_officeWHERE O_EMP.EMPNO= TD_OFFICE.EMPNO

Packaging and Upgrades
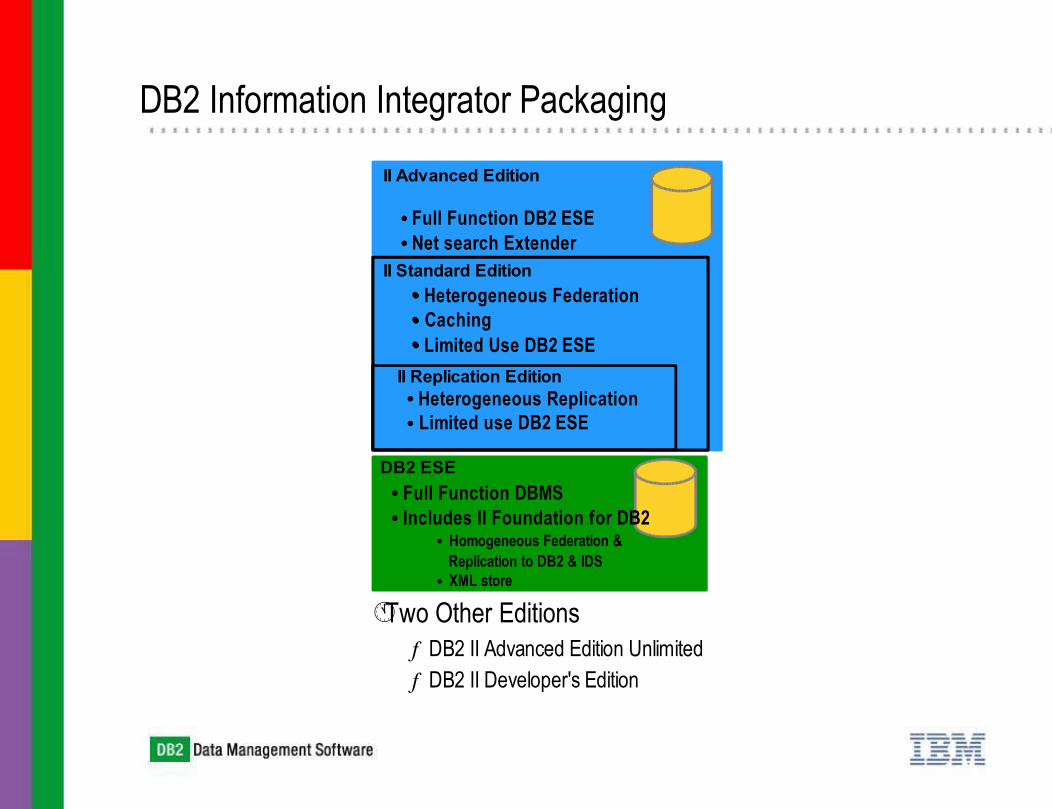
DB2 Information Integrator Packaging
II Advanced Edition
• Full Function DB2 ESE• Net search Extender
II Standard Edition• Heterogeneous Federation• Caching • Limited Use DB2 ESE
•••
•••
• Heterogeneous Replication• Limited use DB2 ESE
II Replication Edition
• Full Function DBMS• Includes II Foundation for DB2
• Homogeneous Federation & Replication to DB2 & IDS
• XML store
DB2 ESE
Two Other Editionsƒ DB2 II Advanced Edition Unlimitedƒ DB2 II Developer's Edition

Connector LicensingDB2 UDB, Informix IDS, Informix XPS, WebSphere MQ, Web services, and OLE DB - provided with base server license.
Relational databases - access only one database instance of Oracle, Microsoft SQL Server, Sybase or Teradata databases, or any one data source instance accessed using the ODBC connector.
Microsoft Excel - access to all Excel documents that reside on one or more servers. Flat files - access to all flat files that reside on one or more servers. XML - access to all XML documents that reside on one or more servers.
Documentum - access to one repository of Documentum documents.
Extended Search - access to all data sources accessible through Extended SearchBLAST - access to all data sources accessible through one BLAST daemon. Entrez - access to all supported data sources accessible through Entrez. Access to PubMed and Nucleotide databases is supported by DB2 Information Integrator. HMMER - access to all data sources accessible through one HMMER daemon. BioRS - access to all the databanks supported by a single installation of BioRS.

Upgrades from DataJoiner and Relational Connect
These Customers: Are entitled to these upgrades:DataJoiner Server 1 DB2 II SE ProcessorDataJoiner Additional Processor 1 DB2 II SE ProcessorDataJoiner Relational Data Source 1 DB2 II ConnectorDataJoiner Spatial Extender Processor 1 DB2 Spatial Extender ProcessorRelational Connect 2 DB2 II SE Processors
2 DB2 II ConnectorsLife Sciences Data Connect 2 DB2 II SE Processors
1 DB2 II Connector
Sunsetting DB2 DataJoiner and DB2 Relational Connectƒ Withdrawal from Marketing: September 9, 2003ƒ Withdrawal from Service: September 9, 2004ƒ See IBM Announcement Letter # 903-106: Software Withdrawal: DB2 Relational Connect,
DB2 Life Sciences Data Connect, DB2 DataJoiner, DB2 DataJoiner Spatial Extender

DB2 Information Integrator – Capability Comparison
Wrapper toolkit for developers
Control Center – Discovery for nicknames
Web services consumer
Application Dev’t via standard tooling (e.g. WebSphere Studio, MS Visual Studio)
• Excel, flat file, Life Sciences wrappers (R/O)
• MQ series 1PC
• XML wrapper (R/O)
• Extended search wrapper (R/O)
(1PC)• ODBC R/W
Wrapper architecture
Heterogeneous replication
Web services provider
Caching - MQTs over nicknames
(1PC) (R/O)• Oracle, Sybase, SQL Server, Teradata R/W
(1PC) (1PC) (R/O)Federated Reach: • DB2/Informix Read/Write
II V8.1DB2 V8.1DB2 V7.2 & RC/LSDC
DataJoinerFunction

Time for a short break ...?

DB2 Information Integrator Performance Topics

DB2 Information Integrator Performance TopicsCost-based query optimizationPerformance of queries against a single federated data source Performance of queries against multiple federated data sources Application development with and without DB2 II

A Simple Join QueryShow me:
the number of TV sales per manufacture in year 2001
SQL to DB2:SELECT I.man, count(*) FROM transactions T, items I WHERE I.id=T.item_id and I.cat='Television' and YEAR(T.tran_date)=2001GROUP BY I.man;
Global Plan RETURN | GROUP BY | SORT | Hash Join / \ Relational Evaluate cat='Television' Query | SHIP Non-Relational Plan | RPD Nickname: | TRANSACTIONS Nickname: ITEMS
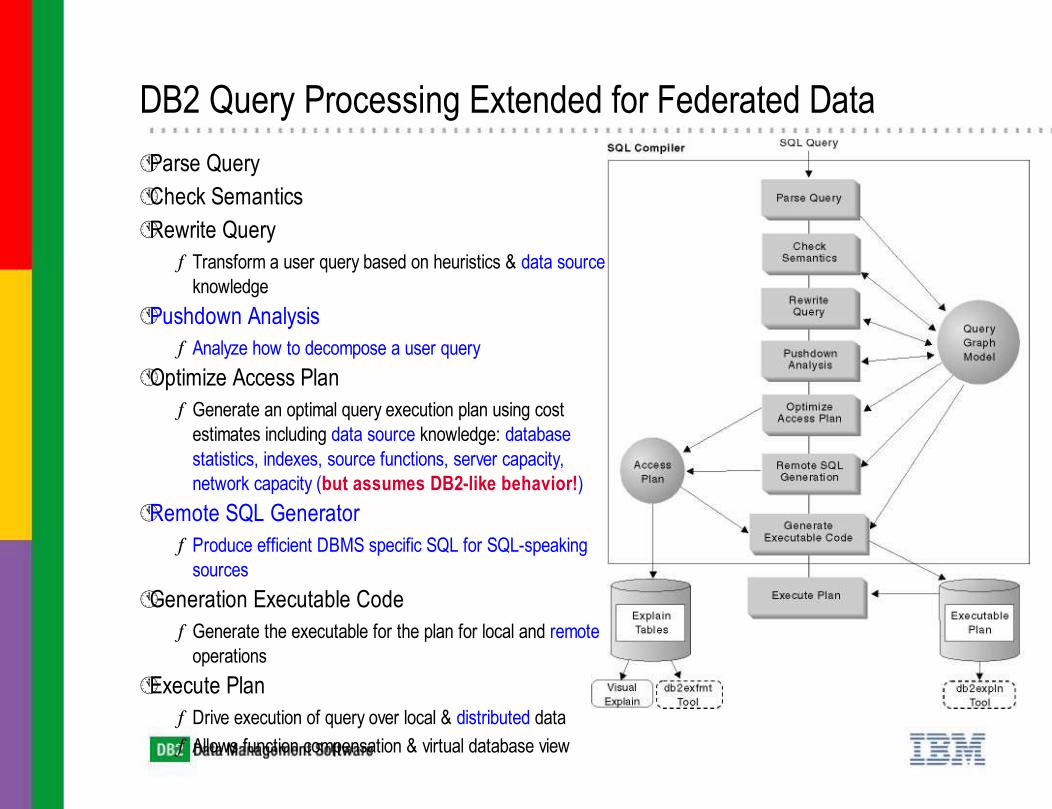
DB2 Query Processing Extended for Federated DataParse QueryCheck SemanticsRewrite Query
ƒ Transform a user query based on heuristics & data source knowledge
Pushdown Analysisƒ Analyze how to decompose a user query
Optimize Access Planƒ Generate an optimal query execution plan using cost
estimates including data source knowledge: database statistics, indexes, source functions, server capacity, network capacity (but assumes DB2-like behavior!)
Remote SQL Generatorƒ Produce efficient DBMS specific SQL for SQL-speaking
sourcesGeneration Executable Code
ƒ Generate the executable for the plan for local and remote operations
Execute Planƒ Drive execution of query over local & distributed dataƒ Allows function compensation & virtual database view

Relational Data Source Pushdown AnalysisDetermine what portion of a query can be executed outside DB2 for relational sourcesWill not dictate how much really gets pushed down to the data source in most casesWhat matters:
ƒ data source capabilities–e.g. Can it handle join operation ?
ƒ characteristics about the data–e.g. Can sorting sequence affects predicates on a column ?
ƒ function mappings–e.g. Can this source evaluate COUNT(*) ?
ƒ and more

Actual pushdown is cost-basedJust because processing can be pushed down doesn't mean it will be.Influenced by estimates of rows processed/returned. Example: two-table join with nicknames ORA.T1 and ORA.T2 to a single remote source that is "nearly" a Cartesian product. May be better to do the join at the Federated server to avoid retrieval of many rows. Example: Retrieving (10,000 + 25) rows to do a local join is faster than retrieving (10,000 * 25) = 250,000-row remote join result
SELECT .... from ORA.T1, ORA.T2 where T1.a = T2.b
ORA.T1 ORA.T2
25 rows 10,000 rows
Single remote Oracle source

Experimental results: Federated single-source query performance
What Happened Here?

Q4: Rows
RETURN
( 1)
Cost
I/O
|
5
SHIP
( 2)
4.51969e+07
1.80339e+06
/------+-----\
6e+06 2.39966e+07
NK: TPCD NK: TPCD ORDERS LINEITEM
Reading the Explain plan for Q4
Q4: join between nicknames to two tables (Orders and Lineitem) on the remote sourceOrders: 6M rows, Lineitem: ~24M rowsNo processing at the Federated server - topmost operator is SHIP. 5 rows are estimated to be returned to the Federated server What statement is SHIPped to the remote source? Look in details of the SHIP operator in EXPLAIN output

Original Query:SELECT O_ORDERPRIORITY, COUNT(*) AS ORDER_COUNT FROM TPCD.ORDERS WHERE O_ORDERDATE >= DATE('1993-07-01') AND O_ORDERDATE < DATE('1993-07-01') + 3 MONTHS AND EXISTS (SELECT * FROM TPCD.LINEITEM WHERE L_ORDERKEY = O_ORDERKEY AND L_COMMITDATE < L_RECEIPTDATE)GROUP BY O_ORDERPRIORITYORDER BY O_ORDERPRIORITY;
RED = NicknamesPINK = Remote source table names
What is shipped to the remote source:SELECT A0."O_ORDERPRIORITY", COUNT(*) FROM "TPCH"."ORDERS" A0WHERE (EXISTS (SELECT A1."L_RETURNFLAG" FROM "TPCH"."LINEITEM" A1 WHERE (A1."L_ORDERKEY" = A0."O_ORDERKEY") AND (A1."L_COMMITDATE" < A1."L_RECEIPTDATE")))AND(TO_DATE('19930701 000000','YYYYMMDD HH24MISS') <= A0."O_ORDERDATE") AND (A0."O_ORDERDATE" < TO_DATE('19931001 000000','YYYYMMDD HH24MISS'))GROUP BY A0."O_ORDERPRIORITY"ORDER BY 1 ASC;
Even for a completely pushed down query...The remote query text is not the same as the original due to
ƒ SQL differences on remote sourceƒ Federated optimization includes a rewrite phase!
Q4: What is shipped to the remote source?

Experimental results: Federated single-source query performance
Q14

Q14: What went wrong? Rows RETURN ( 1) Cost I/O | 1 (rows output) GRPBY (operator name) ( 2) (operator no.) 370486 (Cost estimate) 27108.4 (I/O estimate) | 2.39966e+06 SHIP ( 3) 369851 27108.4 /------+-----\ 800000 2.39966e+07 NK: TPCD NK: TPCD PART LINEITEM
SELECT 100.00 * SUM(CASE WHEN P_TYPE LIKE 'PROMO%' THEN L_EXTENDEDPRICE*(1-L_DISCOUNT) ELSE 0END)/SUM(L_EXTENDEDPRICE*(1-L_DISCOUNT)) AS PROMO_REVENUE FROM TPCD.LINEITEM, TPCD.PART WHERE L_PARTKEY = P_PARTKEY AND L_SHIPDATE >= DATE('1995-09-01') ANDL_SHIPDATE < DATE('1995-09-01') + 1 MONTH
Join is pushed down to the remote database, but SUM/CASE/GROUPBY is done locally. Thus *many* rows are processed locally. Why? Not all versions of the remote database can deal with a CASE expression of this type

Experimental results: Federated single-source query performance
Q20
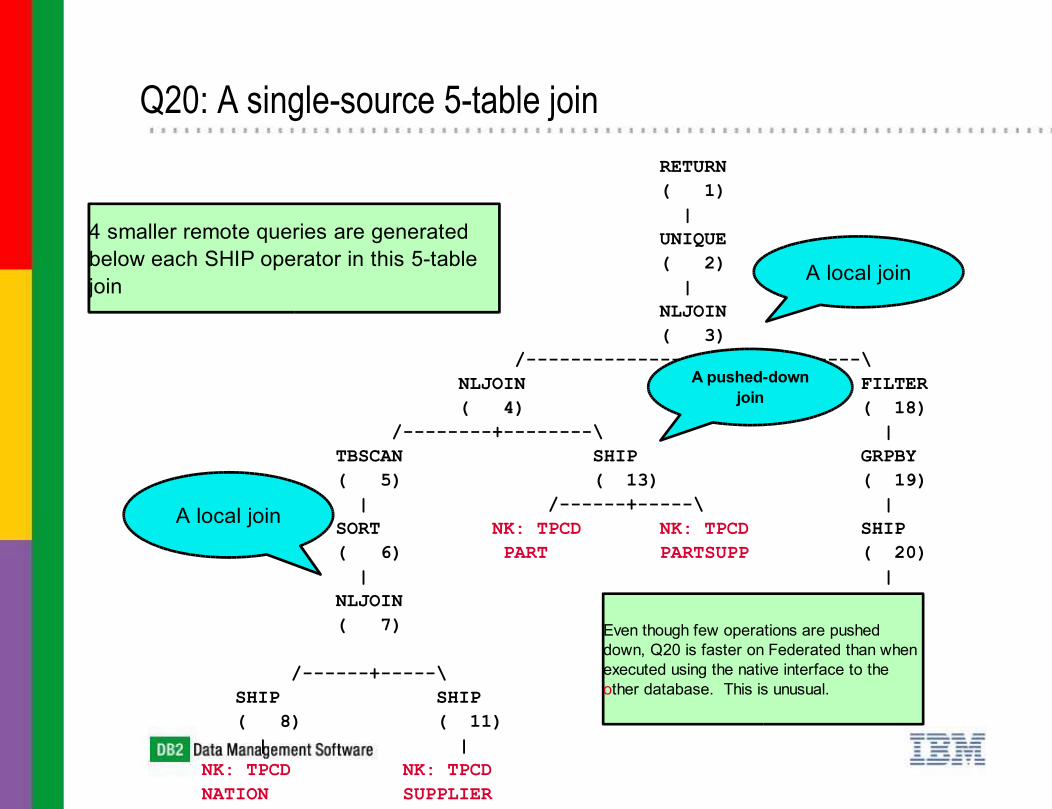
Q20: A single-source 5-table join RETURN ( 1) | UNIQUE ( 2) | NLJOIN ( 3) /---------------+--------------\ NLJOIN FILTER ( 4) ( 18) /--------+--------\ | TBSCAN SHIP GRPBY ( 5) ( 13) ( 19) | /------+-----\ | SORT NK: TPCD NK: TPCD SHIP ( 6) PART PARTSUPP ( 20) | | NLJOIN NK: TPCD ( 7) LINEITEM /------+-----\ SHIP SHIP ( 8) ( 11) | | NK: TPCD NK: TPCD NATION SUPPLIER
4 smaller remote queries are generated below each SHIP operator in this 5-table join
A local join
A pushed-down join
A local join
Even though few operations are pushed down, Q20 is faster on Federated than when executed using the native interface to the other database. This is unusual.

Understanding performance of a query to 1 remote sourceConsider a Federated query Q. Get DB2EXFMT output for Q.
ƒ Watch for portions of the query that are not pushed downFor a fully pushed-down query: Find the remote query Q' from the SHIP operatorIf you can, try executing the remote query Q' directly at the remote source to isolate any performance issues. Try executing Q' by hand with a SELECT COUNT(*) to verify the number of rows returnedCompare execution time of Q at the Federated server and Q' at the remote source. If you know how, get an EXPLAIN of Q' at the remote sourceUseful tool: db2batch -d <dbname> -f <query file> -o p 2 executes query at Federated server and measures elapsed and CPU time Technique generalizes to case with more than one Q' (query Q decomposed into two or more remote queries)
Elapsed time
QQ'

A simple distributed two-source query
SELECT P_PARTKEY, SUM (100.00 * L_EXTENDEDPRICE*(1-L_DISCOUNT)) AS PROMO_REVENUEFROM TPCD2.LINEITEM, TPCD.PARTWHERE L_PARTKEY = P_PARTKEY and P_TYPE LIKE 'PROMO%' AND L_SHIPDATE >= DATE('1995-09-01') AND L_SHIPDATE < DATE('1995-09-01') + 3 MONTHGROUP BY P_PARTKEY ORDER BY PROMO_REVENUE FETCH FIRST 20 ROWS ONLY;
DB2 Federated Server
TPCDPART
TPCD2LINEITEM
Join LINEITEM and PART tables located on sources TPCD2 and TPCDJoin predicate L_PARTKEY= P_PARTKEYPredicate on PART: consider only promotional partsPredicate on LINEITEM: consider only items shipped between certain dates

Does the simple distributed query perform well?
Comparison:Elapsed Time of Federated distributed query vs. time to
ƒ Export & move qualifying PART rows from source TPCD to source TPCD2 and...
ƒ ...do a local query on source TPCD2 between LINEITEM and the "moved" PART rows stored in a temporary table
Consider:ƒ Federated moves 864K + 30K = 894K rowsƒ Manual co-location moves only 30K, but must export/insert rows.
What if we make a "mistake" and move LINEITEM to PART instead?
Qualitative criteria: Yes.ƒ Minimal Data Movementƒ Work is pushed down
Quantitative criteria: Compare Federated with temporary co-location ("move and join")
: : | 29917.6 SORT ( 6) | 32329.1 HSJOIN ( 7) /------+-----\ 864484 29917.6 SHIP SHIP ( 8) ( 10) | | 2.39966e+07 800000 NK: TPCD2 NK: TPCD LINEITEM PART DB2 Federated Server
TPCDPARTTPCD2
LINEITEM
30k Part rows

Federated Move Part to Lineitem, Local Join
Move Lineitem to Part, Local Join
19 12 48
Results of the comparison experiment
Elapsed Time, sec.
Compare "move and join" to Federated joinƒ in both directions (Part to Lineitem and vice-versa).
Results:ƒ move-and-join can be faster than a Federated join orƒ it can be slower because it is dominated by cost to export/load a large temporary table.

Federated Move Part to Lineitem, Local Join
Move Lineitem to Part, Local Join
32.5 32.3 52.4
"Move and join" is not always worth the trouble
Elapsed Time, sec.
Repeat the experiment with a modified query in which the join is not as "lopsided"ƒ Predicate on PART table changed to select much more data than beforeƒ Almost as many PART rows as LINEITEM rows participate in the distributed join
Result: Federated does as well as the best "move and join" experiment.

Comparing "move and join" with Federated Move-and-join: temporarily move data to be joined from two (or more sources) to one sourceƒ This strategy is NOT available for DB2 II today
Move-and-join may be quicker than Federated join ifƒ one side of the join is much smaller than the otherƒ you correctly choose to move the small side
Butƒ It takes considerable knowledge of the query to implement move-and-join correctly and efficientlyƒ It requires additional scripting and administration ƒ If both sides of the join are of comparable size, performance will usually be similar to Federatedƒ Need authority to create new tables, insert dataƒ Performance may be much worse than Federated if you make a mistake
Federated is a good bet in a dynamic environment!

local DB2 for "scratch" temp tables
Comparing performance of distributed queries in an application with and without DB2 Federated
DB2 Federated
Server
Oracle Excel/ODBC
DB2
Federated Application
Non-Federated Application
Connection to Federated server
Connection to all individual data sources

Comparing performance of distributed queries with and without DB2 Information IntegratorWithout DB2 Federated: Application connects to each source, issues SQL in its dialect, retrieves appropriate data from each, inserts into local temporary tables, and processes query locallyWith DB2 Federated: Application connects only to Federated server and submits queries against nicknames to several sources ƒ Federated manages the decomposition and processing of the queryƒ Can also create join and union views over nicknames to make multiple remote tables appear as one to
the applicationResults w/J2EE servlets issuing queries involving 3 remote data sources
ƒ 40 - 65% less code with DB2 IIƒ 50 - 65% less time required to develop with DB2 II
Query Time with Federated
Time without Federated
1 3.5 sec 3.4 sec2 0.24 sec 0.16 sec3 54.2 sec 170.1 sec4 6.5 sec 81.2 sec5 15.1 sec 9.9 sec

Tuning stuff ...Pay attention to pushdown
ƒ Ensure that appropriate work is being pushed down to remote sourcesƒ Affected by collating sequences, data types, null attributes
Pay attention to sorting and temporary tablespacesƒ Even with appropriate pushdown, DB2 II will be doing lots of work
–Results from remote sources become temporary tables on DB2 II–Final sorts, aggregates may need to be performed on DB2 II, especially with multiple remote data sources
ƒ Monitor sortheap, sheapthresh–ensure most sorts take place in memory
ƒ Appropriately size bufferpool for temporary tablespaces–ensure spills from sortheap have a place to land in bufferpool–ensure adequate space for temporary tables being materialized on DB2 II
ƒ Storage underlying temporary tablespaces–ensure good performance when temporary tables are forced to disk
Temporary tables aren't reusable for multiple usersƒ Consider using MQT's to persist frequently used data

DB2 Information Integrator - The Fine Print

EEE instance
Current parallelism limitations in Federated performance No SMP intra-query parallelism at the Federated server (yet)
ƒ A query involving one or more nicknames will run using only one db2 agent ƒ A single user running a distributed query can't exploit the full power of (say) an 8-way SMP
Watch out when making EEE instance Federated. Joins between local partitioned tables (EEE) and nicknames run on coordinator partition only - no parallelism!
P1P2
P3P4
JOIN
Nickname
T
This join will run on one partition only.Better... create an MQT over the nickname. The MQT is a local table that can be joined in parallel with the partitioned table

Upcoming Features...2 Phase Commit not yet supported
ƒ No triggers on nicknames that cause updates to another siteƒ Only read-only IMS, CICS Transactions to federated sources
Nicknames on remote stored procedures not yet supportedReplication with DB2 II requires DB2 DataPropagator Version 8
ƒ Version 7 tolerated, but replication subscriptions can't be changedRUNSTATS on nicknames not yet supported
ƒ Can drop and recreate, but dependent objects are dropped as wellƒ GET_STATS (IBM supplied program) is available from DB2 II support site
–http://www-3.ibm.com/software/data/integration/db2ii/support.htmlOptimizer assumes DB2 UDB behavior for relational data sourcesMay need to run db2updv8 on databases after upgrading to FixPak 2

Open infrastructure for integrating diverse and distributed data for real time access ƒ Structured, semi-structured, and unstructured data, standards-based extensibility ƒ Leverage native source capabilitiesƒ Query engine provides optimized cross-source queries
An extension of industrial-strength technologyƒ Robust, high function, high performanceƒ Benefit from R & D in relational DBMSƒ Benefit from experience in content management
Eases application developmentƒ Transparency, heterogeneity, high functionƒ APIs for modern environments (XML, J2EE, Web Services)
Application Autonomyƒ Does not disrupt existing applications
Summary: II Federated Technology

For More Information DB2 Information Integrator Home Pageƒ http://www-3.ibm.com/software/data/integration/db2ii/
DB2 Information Integrator Documentationƒ Now in DB2 UDB Documentation (with DB2 UDB Documentation FP2)
IBM Systems Journal on Information Integrationƒ http://www.research.ibm.com/journal/sj41-4.html
Information Integration White Papersƒ http://www-3.ibm.com/software/data/pubs/papers/#ii

















