
Data Structures – p.1/38 - Gabriel Istrate -...
38
Organizational • Last time: linked list. • Today: doubly linked list, stack, queue, circular linked list. Lists in STL. Start advanced topic: skip list. • Also: First project. • Not given today, no Monday/Tuesday deadlines (so that you can attend class). • posted Wednesday evening on the webpage. • Due two weeks from Wednesday (Thursday morning at 10AM) Data Structures – p.1/38
Transcript of Data Structures – p.1/38 - Gabriel Istrate -...

Organizational
• Last time: linked list.
• Today: doubly linked list, stack, queue, circular linked list. Lists in STL. Startadvanced topic: skip list.
• Also: First project.
• Not given today, no Monday/Tuesday deadlines (so that you can attend class).
• posted Wednesday evening on the webpage.
• Due two weeks from Wednesday (Thursday morning at 10AM)
Data Structures – p.1/38

Last time: Deleting from head of the list
int List::deletefromHead() throw (string) {
if(isEmpty())
throw string("Empty");
node *tmp = head;
int info = head->getInfo();
if (head==tail)
head = tail=0;
else
head = head->getNextNode();
delete tmp;
return info;
}
Data Structures – p.2/38

Catching exceptions
void f()
{
. . . . . .
try{
n= list.deleteFromHead();
// do something with n;
}catch(char *s){
cerr << "Error: "<< s << endl;
}
. . . . . .
}
Data Structures – p.3/38

Deleting the successor of a node pointed to
by pointer r
• Have to test whether pointer in 0.
• Also: if the successor is 0.
• simply modify the value of the field next;
• want to reclaim the memory allocated for the successor node;
• C++: delete;
• in the absence of deallocation: memory leaks.
• Program size grows continuously. Eventually will result in blocking your computer.
Data Structures – p.4/38

Deleting the successor of a node pointed to
by pointer r
void List::deleteNextNode(Node *r) throw(string){
if (!r)
throw string("Null pointer in deleteNextNode");
if (r->getNextNode()== 0)
throw string("attempt to delete nonexisting node");
Node *s = r->getNextNode();
r->setNextNode(s->getNextNode());
delete s;
}
Data Structures – p.5/38

Better solution for throwing exceptions
• Can throw complex objects as exceptions.
• Allows much better recovery (e.g. examining what went wrong).
• Solution: Define your own exception types(classes)
• Multiple catch blocks, multiple object types.
• String (char *): last one/default exception type.
Data Structures – p.6/38

Doubly linked lists
• Functions PredecessorNode() and deleteFromTail() expose a problem: no efficientway to go "backwards" in a singly linked list.
• Solution: doubly linked list. Nodes hold two pointers: one to predecessor node,one to successor node.
• Update schemes change slightly.
Data Structures – p.7/38

Doubly linked list: implementation
class Dllnode{
public:
Dllnode(){
next = prev=0;
}
Dllnode(int i, Dllnode *n=0, Dllnode *p=0){
info = i;
next = n;
prev = p;
}
. . . . . .
int getInfo(){return info;};
Dllnode *getNextNode(){return next;};
Dllnode *getPrevNode(){return prev;};
private:
int info;
Dllnode* next,prev;
};Data Structures – p.8/38

Doubly linked list: implementation (II)
class Dllist{
public:
Dllist();
∼Dllist();
. . .
void addToDllTail(int);
int deleteFromDllTail();
bool isEmpty();
private:
Dllnode* head;
Dllnode* tail;
}
Data Structures – p.9/38

Adding to the Tail of a Doubly Linked List
void DllList::addToDllTail(int info){
if (tail != 0){
tail = new Dllnode(info, 0, tail);
(tail-> getPrevNode())->setNextNode(tail); // step *}
else head = tail = new Dllnode (info);
}
Data Structures – p.10/38

Deleting from the tail of a Doubly Linked List
int DllList::deleteFromDllTail(){
assert(!isEmpty());
int i = tail->info;
if (head == tail){ // only one element in the list
delete head;
head = tail = 0;
}
else { // more than one element in the list
tail = tail-> getPrevNode();
delete tail-> getNextNode();
tail-> setNextNode(0);
}
return i;
}
Data Structures – p.11/38

Correctness
• Why is step * in function addtoDllTail correct ?
• Code executed when parameter tail ! =0.
• Newly created node has parameter prev set to this value of tail.
• Thus tail− > prev points to a nonempty node, thus pointer next can beaccessed.
• Deletion: special case is single node list. In this case by deletion it becomes empty.
• Otherwise: store last value in the list. Move parameter tail to previous node(directly accessed). Delete the last node (now accessed through tail->next). Alsoset the next pointer of the last node to zero.
Data Structures – p.12/38

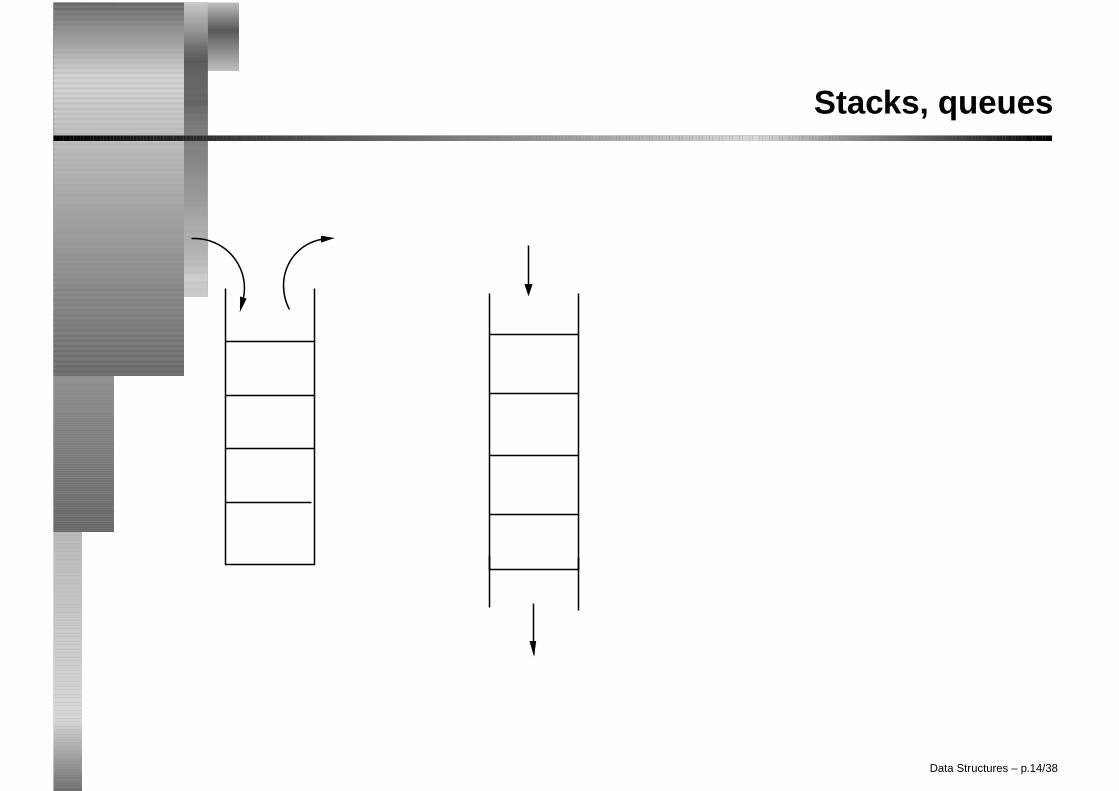
STACKS, QUEUES, DEQUEUES
• STACK: insert/delete elements at the tail.
• QUEUE: insert at the end, delete at the front.
• DEQUEUE: insert/delete both at front and back.
Data Structures – p.13/38
Stacks, queues
Data Structures – p.14/38

STACKS, QUEUES, DEQUEUES
• delete from the end of the list: deleteNextNode(predecesorNode(tail)); or youcan implement it directly as member function deleteFromTail.
• STACK: interface exposes functions addToTail and deleteFromTail (usuallycalled push and pop).
• QUEUE: interface exposes addToTail and deleteFromHead.
• DEQUEUE: both addToHead and addToTail, also deleteFromHead,deleteFromTail.
Data Structures – p.15/38

Destructor
List::∼List(){
for (node *p; !isEmpty(); ){
p = head->getNextNode();
delete head;
head = p;
}
}
• nodes: contain dynamically allocated memory. Has to be freed.
• REMEMBER: second condition in the for loop functions as a WHILE test.
• We keep a temporary pointer to the node next to the head, delete head, andadvance the head pointer.
Data Structures – p.16/38

Circular lists
• A list in which nodes form a ring: list is finite and every node has a successor.
• E.g. several processes using a shared resource for the same amount of time (timesharing), and we make processes take turn.
• Processes are put on a circular list accessed by pointer current.
• After process take its time, pointer advances to the next process.
• node class: same as the one for singly linked list from last course.
• Implementation: can use singly linked list and make the last node point to firstrather than to zero.
• Interface can be the same, functions (e.g. inserting, deleting nodes) will be different.
• Only need one pointer, tail.
Data Structures – p.17/38

Implementing insertion at the end of the
circular list
void CLList::addToTail(int el){
if (isEmpty())
{
// handle addition to an empty list separately
tail = new node(el);
tail->setNextNode(tail);
}
else
{
tail->setNextNode(new node(el, tail->getNextNode()));
}
}
Data Structures – p.18/38

Issues with previous implementation
• Deleting the tail node requires looping around the tail so that the predecessor’ssuccessor node can be updated.
• Delete tail node complexity O(n).
• Processing data in reversed order not efficient: O(n2).
• Alternative: circular doubly-linked list.
Data Structures – p.19/38

Lists in the STL
#include <list>
// list class library
using namespace std;
// Create a "list" object, specifying its content as "int".
// The "list" class does not have the same "random access" capability
// as the "vector" class, but it is possible to add elements at
// the end of the list and take them off the front.
list<int> list1;
// Add some values at the end of the list, which is initially empty.
// The member function "push back" adds at item at the end of the list.
int value1 = 10;
int value2 = -3;
list1.push back (value1);
list1.push back (value2);
list1.push back (5);
list1.push back (1);
Data Structures – p.20/38

Lists in the STL (II)
// Output the list values, by repeatedly getting the item from
// the "front" of the list, outputting it, and removing it
// from the front of the list.
// cout << endl << "List values:" << endl;
// Loop as long as there are still elements in the list.
while (list1.size() > 0)
{
// Get the value of the "front" list item.
int value = list1.front();
// Output the value.
cout << value << endl;
// Remove the item from the front of the list ("pop front"
// member function).
list1.pop front();
}
Data Structures – p.21/38

Lists in the STL
Commonly used member functions:
• size_type size() const; returns number of elements in the list.
• bool empty() const; returns TRUE if list is empty, FALSE otherwise.
• void push_back(const T& x); void push_front(const T& x); insert element x at thefront (back) of the list.
• T& front(); T& back (); return references to the front/back elements;
• begin(), end(). Iterators to the beginning/end of the list.
• iterator insert(iterator position, const T& x); insert element x before the element (ifany) pointed out by the iterator.
• void clear(); clear the list.
• void remove (const T& value); remove all elements equal to value. Type T mustpermit operator==.
• void sort(); void reverse();
Data Structures – p.22/38

Lists in the STL
Other member functions:
• c.assign(n, elem): assign n copies of element elem to list.
• c.resize(num):Modifies the container so that it has exactly n elements, insertingelements at the end or erasing elements from the end if necessary. values: defaultconstructor (for integers, 0).
• c.unique() : removes duplicates of consecutive elements with the same value.
• iterator previous(iterator pos) returns an iterator to the position before that pointedby pos.
• list: Doubly-linked lists. For singly-linked lists use slist.
Data Structures – p.23/38

Iterators in STL
• "Smart" generalizations of pointers. Allow access to a data structure (list,vector,etc.).
• Input/output iterators: first only allow "dereferencing" but not change of value.Second only guarantee write access: it is possible to assign a value through anOutput Iterator, but not necessarily possible to refer to that value.
• Forward/backward iterators: allow multiple passes, but in one direction only.
• Both single-pass iterators. Bidirectional iterators: can increment and decrement.
• References: google, STL documentation (webpage), Scott Meyers "Effective STL"(available in Romanian from Teora). Also his other books on C++.
Data Structures – p.24/38

Case Study: concordance problem
• GIVEN: text (i.e. a sequence of words).
• TO DO: parse the text and discover the words. For each word examine if this itsfirst occurrence.
• If this is the case memorize it.
• Otherwise increment a counter associated to the number of occurrences of thegiven word.
• Similar issues encountered in analyzing natural language (natural languageprocessing). What is the text about ? Statistical language processing.
• Also in compilers.
• First phase in a compiler: lexical analysis.
• Identifies words. Represents program by lexical tokens.
• Example: x = 5; [IDENT "x"] [EQL] [NUMBER 5] [SEMICOLON].
• To represent x: <identifier>. Also: pointer to a list (table) of identifiers.
Data Structures – p.25/38

Solution
• Create a linked list of words.
• For each new word:
• If not found in the list add it.
• Otherwise increment a counter associated to the given word.
Data Structures – p.26/38

Implementation: interfaces
I am showing only more significant elements in the interfaces;
struct Token{
std::string word;
int count;
};
struct TokenNode{
Token info;
TokenNode * next;
};
class TokenNodeList{
public:
TokenNodeList();
void insertOrIncreaseCount (string);
private:
TokenNode *head;
TokenNode *tail;
} Data Structures – p.27/38

Comments on implementation
• C++: a struct is a class with all members public. It allows e.g. constructors.Though I don’t recommend public data members, it’s a better alternative to structs.
• Useful to maintain list in sorted order: to insert a new word we have to determineanyway that it doesn’t appear in the list.
• Order on words: lexicographic order. The way words are listed in a dictionary:compare first letter first, then second letter, etc. Prefixes are smaller.
• InsertOrIncreaseCount(): search until you find element or larger one. If foundincrease count. Reuse code insertInfoBefore(), insertInfo() (Course 3).
int compareStrings(string a, string b){
int i=0; int l1=a.length(); int l2=b.length();
for (int i=0;i<min(l1,l2);i++)
if (a[i]<b[i])
return 0;
else
if (a[i]>b[i])
return 0;
return 1;
}
Data Structures – p.28/38

Implementing functions
void TokenList::insertOrIncreaseCount(string s){
assert(!isEmpty());
node *first=head;
node *second = 0;
while (lessThan(first->getInfo(),s))
{
second = first;
first = first->getNextNode();
};
if (first->getInfo() == s)
{ // string found in list;
first->count++;
}else
insertInfo(second,s);
}
Data Structures – p.29/38

Concordance: main function
#include<fstream>
int main(int argc, char *argv[]) {
std::string nextItem;
TokenNodeList tl;
fstream file op(argv[1],ios::in);
while (file op >> nextItem)
tl.insertOrIncreaseCount(nextItem);
// do something with token list
. . . . . .
return 0;
}
Data Structures – p.30/38

Advanced topic: Skip lists
• Drawback with linked list: require sequential access to locate a searched-for element.
• Ordering: can speed up searching, but sequential search still required.
• Solution: lists that allow skipping some elements to speed up search.
• Skip lists: variant of ordered linked lists that make such search possible.
• More advanced data structure (W. Pugh "Skip lists: a Probabilistic Alternative toBalanced Trees", Communication of the ACM 33(1990), pp. 668-676.)
• If anyone curious/interested in data structures/algorithms, can give paper to read; taste how a
research article looks like.
Data Structures – p.31/38

Skip lists (II)
Data Structures – p.32/38

Skip lists: implementation
• k = 1, . . . , ⌊log2(n)⌋, 1 ≤ i ≤ ⌊n/2k−1⌋ − 1.
• Item 2k−1 · i points to item 2k−1 · (i + 1).
• every second node points to positions two node ahead,
• every fourth node points to positions four nodes ahead,
• every eigth node points to positions eigth nodes ahead,
• . . . . . ., and so on.
• Different number of pointers in different nodes in the list !
• half the nodes only one pointer.
• a quarter of the nodes two pointers,
• an eigth of the nodes four pointers,
• . . . . . ., and so on.
• Approximately how many times more pointers than in a simply-linked list?.
Data Structures – p.33/38

Algorithm
• If you guessed log2(n)/2 times you guessed right:
• n/2 · 1 + n/4 · 2 + n/8 · 4 + . . ..
• Each product in the sum is n/2.
• How many terms in the sum ? ⌈log2 n⌉. Total approximately n ·log
2(n)
2.
• The number of pointers: the level of the node in the tree.
• Levels: from 1 to ⌊log2(n)⌋ + 1.
• To search: first follow pointers on the higher level until a larger element is found orthe list is exhausted.
• If a larger element is found, restart search from its predecessor, this time on alower level.
• Continue doing this until element found, or you reach the first level and a largerelement or the end of the list.
Data Structures – p.34/38

Pseudocode
find(element el){
p = the nonnull list on the highest level i;
while (el not found and i ≥ 0)
if (p->key > el)
p = a sublist that begins in the predecessor of p
on the level −− i;
else
if (p->key < el)
if p is the last element on the level i
p = a nonnull sublist that begins in p
on the highest level < i;
i = the number of this level;
else
p = p− > next;
}
Data Structures – p.35/38

Inserting and deleting nodes
• Problem: when inserting/deleting a node pointers of following nodes have to berestructured.
• Solution: rather than equal spacing, random spacing on a level.
• Number of nodes on each level approximately preserved.
• Level numbering: start with zero.
• New node inserted: probability 1/2 on first level, 1/4 second level, 1/8 third level,. . ., etc.
• Function chooseLevel: chooses the level of the new node.
• Generate random number. If in [0,1/2] level 1, [1/2,3/4] level 2, etc.
• Construct for "typical" case.
• Use randomness to simplify constructions.
Data Structures – p.36/38

Skip list node: interface
#define MAXLEVEL 4
class SkipListNode(){
public:
SkipListNode(){}
int key;
SkipListNode ** next;
};
class SkipList{
public:
SkipList();
bool isEmpty() const;
void choosePowers();
int chooseLevel();
int * SkipListSearch(int);
void SkipListInsert(int);
private:
typedef SkipListNode* nodePtr;
nodePtr root[maxlevel];
int powers[MAXLEVEL];
}Data Structures – p.37/38

Conclusions
• Next time: complete implementation of skip lists.
• Pointer jumping is nontrivial: practice !
• First homework: on webpage tonight.
Any questions ?
Data Structures – p.38/38


















