
Data quality/usability and population -based biobanks Paul Burton Dept of Health Sciences Dept of...
44
Data Data quality/usability and quality/usability and population population -based -based biobanks biobanks Paul Burton Dept of Health Sciences Dept of Genetics University of Leicester
-
Upload
imogen-allison -
Category
Documents
-
view
214 -
download
0
Transcript of Data quality/usability and population -based biobanks Paul Burton Dept of Health Sciences Dept of...

Data quality/usability and Data quality/usability and populationpopulation-based biobanks-based biobanks
Paul Burton
Dept of Health Sciences Dept of Genetics
University of Leicester

StructureStructure of talk of talk Why does data quality/usability matter? UK Biobank as an illustration Statistical power of nested case-control studies Expected event rates in UK Biobank Biobank harmonisation Conclusions

Why does data Why does data quality/usability quality/usability
matter?matter?

Epidemiological analysisEpidemiological analysisat its simplestat its simplest
Odds ratio (OR) = (120*240)/(200*100) = 1.44 [1.04 – 2.0] May also adjust for a confounder
• e.g. high saturated fat intake [y/n] What is the impact of error in an outcome or an
explanatory variable or in a confounder?
Outcome CAD Not CAD
Smoker 120 200 Exposure Non-smoker 100 240

Systematic errorSystematic error
Some disease free smokers deny smoking Odds ratio (OR) = (120*250)/(190*100) = 1.58
Outcome CAD Not CAD
Smoker 120 200 190 Exposure Non-smoker 100 240 250

Random errorRandom error
At random, 10% of subjects state their exposure incorrectly
Odds ratio (OR) = (118*236)/(204*102) = 1.34
Outcome CAD Not CAD
Smoker 120 118 200 204 Exposure Non-smoker 100 102 240 236

The impact of errorsThe impact of errors Systematic errors in outcome or explanatory
variables systematic bias in either direction• True OR = 2 estimated OR = e.g. 1.5 or 2.7
Random errors in binary outcomes or any explanatory variables shrinkage bias• True OR = 2 estimated OR = e.g. 1.5
Random errors in confounding variables systematic bias in either direction• True OR = 2 estimated OR = e.g. 1.5 or 2.7

Errors in biobanksErrors in biobanks
Random errors• Loss of power is primary problem• Biobank sample sizes very large, so why is there a
problem?

Errors in biobanksErrors in biobanks
Random errors• But: why are biobank sample sizes so large?
NB Biobanks very large not nested case-control studies
• Need to detect small relative risks (e.g. OR=1.3)• Power generally limited (see later)• Small error effects catastrophic
Apparent causal effects easily created or destroyed

Errors in biobanksErrors in biobanks Systematic errors
• Small real effects a major issue again• Must understand data collection protocols, and
must attempt to optimise those protocols• UK Biobank• P3G Observatory

What is UK Biobank?What is UK Biobank?

A prospective cohort study 500,000 adults across UK Middle aged (40-69 years) A population-based biobank
• Not disease or exposure based• Recruitment via electronic GP lists
“Broad spectrum” not “fully representative” Individuals not families MRC, Wellcome Trust, DH, Scottish Executive
• £61M
Basic design featuresBasic design features

Longitudinal health tracking Nested case-control studies Long time-horizon
Owned by the Nation Central Administration – Manchester
• PI: Prof Rory Collins - Oxford 6 collaborating groups (RCCs) of university
scientists
Basic design featuresBasic design features

Statistical powerStatistical powerand sample sizeand sample size

Focus on power of nestedFocus on power of nestedcase-control analysescase-control analyses
Likely to be very common analyses Power limiting

Issues that are often ignored in Issues that are often ignored in standard power calculationsstandard power calculations
Multiple testing/low prior probability of association* Interactions* Unobserved frailty Misclassification*
• Genotype• Environmental determinant• Case-control status
Subgroup analyses* Population substructure

Power calculationsPower calculations Work with least powerful setting
• Binary disease, binary genotype, binary environmental exposure
Logistic regression analysis; interactions = departure from a multiplicative model
Complexity (arbitrary but reasonable)Frailty
variance Symmetrical genotyping error rate
Symmetrical environmental
error rate
Disease to non-diseased
error rate
Non-diseased to diseased error rate
Critical P-value
Power
100 fold 1% 20% 80% 0.2% 10-4 80%

Summarise power using “Minimum Summarise power using “Minimum Detectable Odds Ratios” (MDORs) Detectable Odds Ratios” (MDORs) calculated by ‘iterative simulation’calculated by ‘iterative simulation’
Estimate minimum ORs detectable with 80% power at stated level of statistical significance under specified scenario

Genetic main effectsGenetic main effectsNumber of cases
1,000 2,500 5,000 10,000 20,000
0.05 2.64 1.99 1.67 1.48 1.32 0.1 2.08 1.65 1.46 1.31 1.22 0.2 1.79 1.47 1.32 1.24 1.16
0.33 1.68 1.39 1.28 1.19 1.14
Prevalence of
genotypic exposure
0.5 1.65 1.39 1.27 1.19 1.13

Whole genome scanWhole genome scan Genetic main effect, p<10-7
Number of cases
2,500 5,000 10,000 20,000
0.05 2.30 1.86 1.65 1.41 0.1 1.87 1.60 1.42 1.27 0.2 1.63 1.44 1.30 1.21
0.33 1.54 1.39 1.24 1.18
Prevalence of genotypic exposure
0.5 1.52 1.35 1.24 1.16
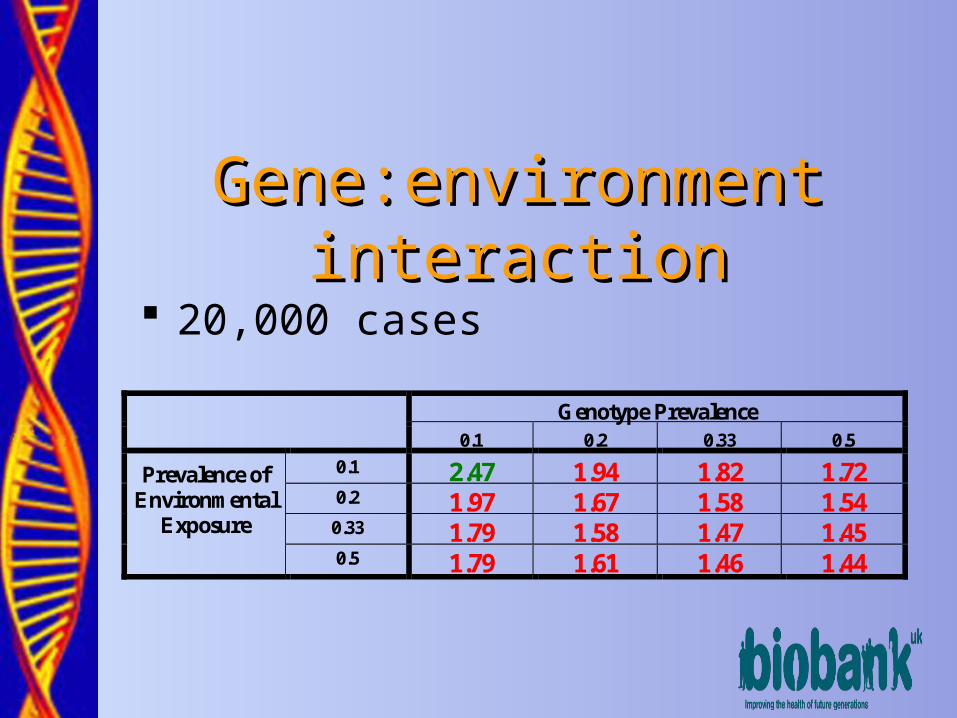
Gene:environment interactionGene:environment interaction 20,000 cases
Genotype Prevalence
0.1 0.2 0.33 0.5
0.1 2.47 1.94 1.82 1.72 0.2 1.97 1.67 1.58 1.54
0.33 1.79 1.58 1.47 1.45
Prevalence of Environmental
Exposure
0.5 1.79 1.61 1.46 1.44

Summary – rule of thumbSummary – rule of thumb 80% power for genotype frequency = 0.1, (allele
frequency 0.05 under dominant model) • Genetic main effect 1.5, p=10-4 5,000 cases• Genetic main effect 1.3, p=10-4 10,000 cases• Genetic main effect 1.2, p=10-4 20,000 cases• Genetic main effect 1.4, p=10-7 10,000 cases• Genetic main effect 1.3, p=10-7 20,000 cases• G:E interaction with environmental exposure prevalance = 0.2 2.0, p=10-4 20,000 cases

Effect of realistic data errorsEffect of realistic data errorsScenario Genetic MDOR Environmental MDOR No error 1.20 1.20
Explanatory error only 1.25 1.48 Outcome error only 1.31 1.31 Both types of error 1.40 1.72

Expected event ratesExpected event ratesin UK Biobankin UK Biobank

Taking account ofTaking account of Age range at recruitment 40-69 years Recruitment over 5 years All cause mortality Disease incidence (“healthy cohort effect”) Migration overseas Comprehensive withdrawal (max 1/500 p.a.)

Time to achieve 1,000 cases
Time to achieve 2,500 cases
Time to achieve 5,000 cases
Time to achieve 10,000 cases
Time to achieve 20,000 cases
Bladder cancer 11 yrs 19 yrs 31 yrs - - Breast cancer (F) 4 yrs 6 yrs 10 yrs 17 yrs 40 yrs Colorectal cancer 5 yrs 9 yrs 14 yrs 22 yrs 42 yrs Prostate cancer (M) 6 yrs 9 yrs 14 yrs 22 yrs 41 yrs Lung cancer 7 yrs 12 yrs 19 yrs 34 yrs - Non-Hodgkins lymphoma 11 yrs 22 yrs - - - Ovarian cancer (F) 12 yrs 26 yrs - - - Stomach cancer 16 yrs 29 yrs - - - Stroke 5 yrs 8 yrs 12 yrs 18 yrs 28 yrs MI and coronary death 2 yrs 4 yrs 5 yrs 8 yrs 13 yrs Diabetes mellitus 2 yrs 3 yrs 4 yrs 6 yrs 10 yrs COPD 4 yrs 6 yrs 8 yrs 13 yrs 23 yrs Hip fracture 7 yrs 11 yrs 15 yrs 21 yrs 31 yrs Rheumatoid arthritis 7 yrs 14 yrs 27 yrs - - Alzheimer’s disease 7 yrs 10 yrs 13 yrs 18 yrs 23 yrs Parkinson’s disease 6 yrs 10 yrs 15 yrs 23 yrs 37 yrs
No need to contact subjectsNo need to contact subjects

Smaller sample sizesSmaller sample sizes 500K 250K 100K [1,] Bladder cancer 7500 3800 1500 [2,] Breast cancer:females only 21800 10900 4400 [3,] Colorectal cancer 21800 10900 4400 [4,] Prostate cancer:males only 22000 11000 4400 [5,] Lung cancer 12600 6300 2500 [6,] Non-Hodgkins lymphoma 4900 2400 1000 [7,] Ovarian cancer:females only 3800 1900 800 [8,] Stomach cancer 3900 1900 800 [9,] Stroke 34700 17400 6900 [10,] MI and coronary death 59200 29600 11800 [11,] Diabetes Mellitus 89300 44600 17900 [12,] COPD 35500 17700 7100 [13,] Hip fracture 37900 18900 7600 [14,] Rheumatoid.Arthritis 6800 3400 1400 [15,] Alzheimers Disease 73900 36900 14800 [16,] Parkinsons Disease 24900 12500 5000

Interim conclusionsInterim conclusions Having taken account of realistic bioclinical complexity, UK
Biobank is just large enough to be of great value as a stand-alone research infrastructure
Data quality, in particular errors in outcome or explanatory variables, or in confounders is crucial
Its value will be greatly augmented if it proves possible to set up a coherent and scientifically harmonized international network of Biobanks and large cohort studies

Harmonising Harmonising biobanks biobanks
internationallyinternationally

Why harmonise?Why harmonise?
Basic aim is to enable and promote data pooling, in a manner that recognises and takes appropriate account of systematic differences between studies.

Why harmonise?Why harmonise? Investigate less common (but not rare)
conditions• UKBB: Ca stomach 2,500 cases in 29 years
6 UKBB equivalents: 10,000 cases in 20 years Investigate smaller ORs
• GME 1.5 1.2 requires 5,000 20,000 4 UKBB equivalents
Analysis based on subsets – homogeneous classes of phenotype, or e.g. by sex

Why harmonise?Why harmonise? Earlier analyses
• UKBB: Alzheimers disease, 10,000 cases in 18 yrs 5 UKBB equivalents 9 years
Events at younger ages Broad range of environmental exposures Aim for 4-6 UKBB equivalents
• 2M – 3M recruits

Harmonisation initiativesHarmonisation initiatives Public Population Program in Genomics (P3G)
• Canada + Europe Tom Hudson, Bartha Knoppers, Leena Peltonen, Isabel Fortier …..
Population Biobanks• FP6 Co-ordination Action (PHOEBE – Promoting Harmonisation Of
Epidemiological Biobanks in Europe) Camilla Stoltenberg, Paul Burton, Leena Peltonen, George Davey Smith …..

Harmonisation in the P3G Harmonisation in the P3G ObservatoryObservatory
(from Isabel Fortier)(from Isabel Fortier) Description Comparison Harmonisation
Data quality crucial at every stage

Final conclusionsFinal conclusions
Power of individual biobanks is limited Minimisation of measurement error is crucial Harmonisation is crucial if we are to optimise
the value of biobanks internationally Harmonisation depends on a full understanding
of all aspects of data quality

Extra slidesExtra slides

Rarer genotypesRarer genotypes
Genetic main effects
Number of cases
Genotype prevalence
Environmental exposure
prevalence
Symmetrical genotyping error rate
Symmetrical environmental
error rate
Disease to non-diseased
error rate
Non-diseased to diseased error rate
Critical P-value
Minimum detectable*
OR for genetic effect
10000 0.01 0.2 1% 20% 80%1 0.2%1 10-4 2.37 20000 0.01 0.2 1% 20% 80%1 0.2%1 10-4 2.09 10000 0.002 0.2 1% 20% 80%1 0.2%1 10-4 [[8.2]] 20000 0.002 0.2 1% 20% 80%1 0.2%1 10-4 [[5.1]]

Gene:environment interactionGene:environment interaction 10,000 cases
Genotype Prevalence
0.1 0.2 0.33 0.5
0.1 3.03 2.36 2.11 2.05 0.2 2.32 1.95 1.87 1.78
0.33 2.15 1.80 1.68 1.64
Prevalence of Environmental
Exposure
0.5 2.16 1.86 1.70 1.70

Disease Gene Polymorphism Approximate frequency of the disease associated allele
Approximate odds ratio for disease associated allele
Thrombophilia F5 Leiden Arg506Gln
0.03 4
Crohn’s disease CARD15 3 SNPs 0.06(composite) 4.6
Alzheimer’s disease
APOE 2/3/4 0.15 3.3
Osteoporotic fractures
COL1A1 Sp1 restriction site
0.19 1.3
Type 2 diabetes KCNJ11 Glu23Lys 0.36 1.23
Type 1 diabetes CTLA4 Thr17Ala 0.36 1.27
Graves’ Disease CTLA4 Thr17Ala 0.36 1.6
Type 1 diabetes INS 5’ VNTR 0.67 1.2
Bladder Cancer GSTM1 Null (gene deletion)
0.70 1.28
Type 2 diabetes PPARG Pro12Ala 0.85 1.23
Hattersley AT, McCarthy MI. A question of standards: what makes a good genetic association study?Lancet 2005; in press.

Summarise power using MDORs Summarise power using MDORs calculated by ‘iterative simulation’calculated by ‘iterative simulation’ Want minimum ORs detectable with 80% power at
stated level of statistical significance• 1. Guess starting values for ORs• 2. Simulate population under specified scenario• 3. Sample required number of cases and controls• 4. Analyse resultant case-control study in standard way• 5. Repeat 2,3,4 1,000 times• 6. Use empirical statistical power results from the 1,000
analyses to update ORs to new values expected to generate a power of 80%
• Repeat 2-6 till all ORs have 80% power

Taking account ofTaking account of Age range at recruitment 40-69 years Recruitment over 5 years All cause mortality Disease incidence (“healthy cohort effect”) Migration overseas Comprehensive withdrawal (max 1/500 p.a.) Partial withdrawal (c.f. 1958 Birth Cohort)


Time to achieve 1,000 cases
Time to achieve 2,500 cases
Time to achieve 5,000 cases
Time to achieve 10,000 cases
Time to achieve 20,000 cases
Bladder cancer 12 yrs 21 yrs 39 yrs - - Breast cancer (F) 4 yrs 7 yrs 11 yrs 19 yrs - Colorectal cancer 6 yrs 10 yrs 15 yrs 25 yrs - Prostate cancer (M) 6 yrs 10 yrs 15 yrs 24 yrs - Lung cancer 7 yrs 13 yrs 22 yrs - - Non-Hodgkins lymphoma 12 yrs 26 yrs - - - Ovarian cancer (F) 13 yrs 33 yrs - - - Stomach cancer 17 yrs 36 yrs - - - Stroke 5 yrs 8 yrs 12 yrs 19 yrs 33 yrs MI and coronary death 2 yrs 4 yrs 5 yrs 8 yrs 14 yrs Diabetes mellitus 2 yrs 3 yrs 5 yrs 7 yrs 11 yrs COPD 4 yrs 6 yrs 9 yrs 14 yrs 27 yrs Hip fracture 7 yrs 12 yrs 16 yrs 24 yrs 36 yrs Rheumatoid arthritis 7 yrs 15 yrs 36 yrs - - Alzheimer’s disease 7 yrs 11 yrs 14 yrs 19 yrs 26 yrs Parkinson’s disease 7 yrs 11 yrs 17 yrs 26 yrs -
Necessary to contact subjectsNecessary to contact subjects
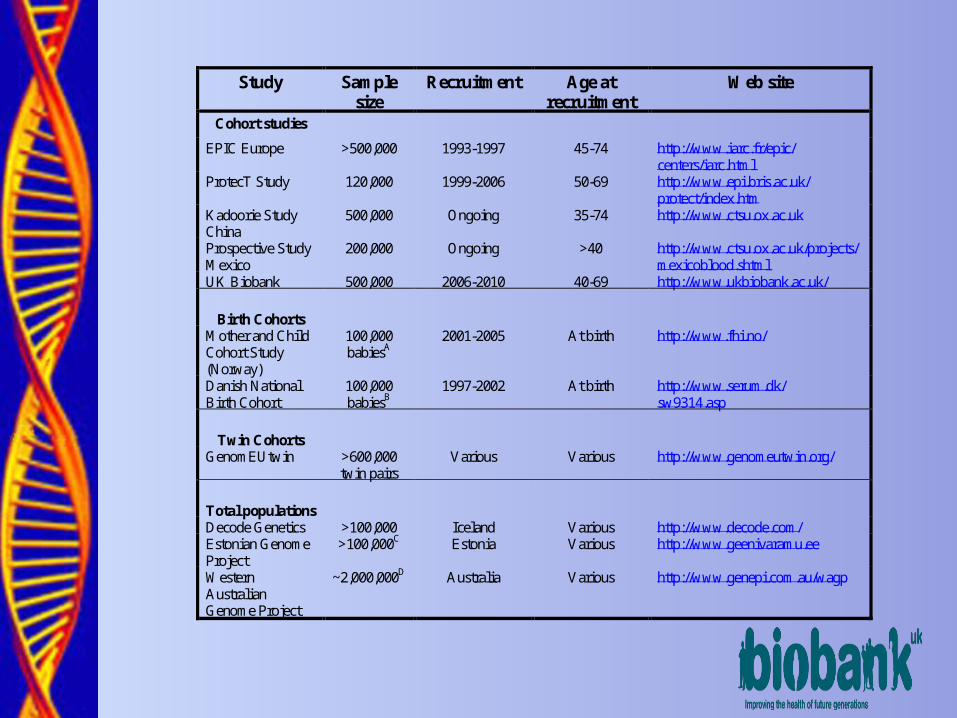
Study Sample size
Recruitment Age at recruitment
Web site
Cohort studies
EPIC Europe >500,000 1993-1997 45-74 http://www.iarc.fr/epic/ centers/iarc.html
ProtecT Study 120,000 1999-2006 50-69 http://www.epi.bris.ac.uk/ protect/index.htm
Kadoorie Study China
500,000 Ongoing 35-74 http://www.ctsu.ox.ac.uk
Prospective Study Mexico
200,000 Ongoing >40 http://www.ctsu.ox.ac.uk/projects/mexicoblood.shtml
UK Biobank 500,000 2006-2010 40-69 http://www.ukbiobank.ac.uk/
Birth Cohorts
Mother and Child Cohort Study (Norway)
100,000 babiesA
2001-2005 At birth http://www.fhi.no/
Danish National Birth Cohort
100,000 babiesB
1997-2002 At birth http://www.serum.dk/ sw9314.asp
Twin Cohorts
GenomEUtwin >600,000 twin pairs
Various Various http://www.genomeutwin.org/
Total populations
Decode Genetics >100,000 Iceland Various http://www.decode.com/ Estonian Genome Project
>100,000C Estonia Various http://www.geenivaramu.ee
Western Australian Genome Project
~2,000,000D Australia Various http://www.genepi.com.au/wagp


















