
Data Protection in Teradata and Teradata Utilities Overview
29
DATA PROTECTION IN TERADATA AND TERADATA UTILITIES OVERVIEW
description
data protection,terdata
Transcript of Data Protection in Teradata and Teradata Utilities Overview

DATA PROTECTION IN TERADATA AND TERADATA UTILITIES
OVERVIEW

Different data protection methods in Teradata
• Transient Journal
• RAID Protection
• Fallback
• Clusters
• Clique
• Permanent Journals
• Locking for data integrity

Transient Journal• The transient journal permits the successful rollback of
a failed transaction• In case a transaction fails, the data is returned to its
original state after transaction failure• The transient journal maintains a copy on each AMP of
before images of all rows affected by the transaction• If the transaction fails, the before images are reapplied
and rollback operation is completed and then before images are deleted from the journal
• If the transaction succeeds, the before images for the transaction are discarded.
• Transient Journal activities are automatic

Transient Journal

RAID Protection• Provides protection against the disk failure• Teradata supports the following disk protection schemes
Raid-1Raid-5
• Raid-1 is disk mirroring technique wherein a mirror copy of each physical disk is maintained. In case of a disk failure, the mirror disk becomes the primary disk for the data and performance is unchanged
• Raid-5 is parity checking technique . It stores parity information using which the data in the failed disk can be re-constructed.
• Raid-5 doesn’t store redundant data.• Teradata recommends RAID 1.

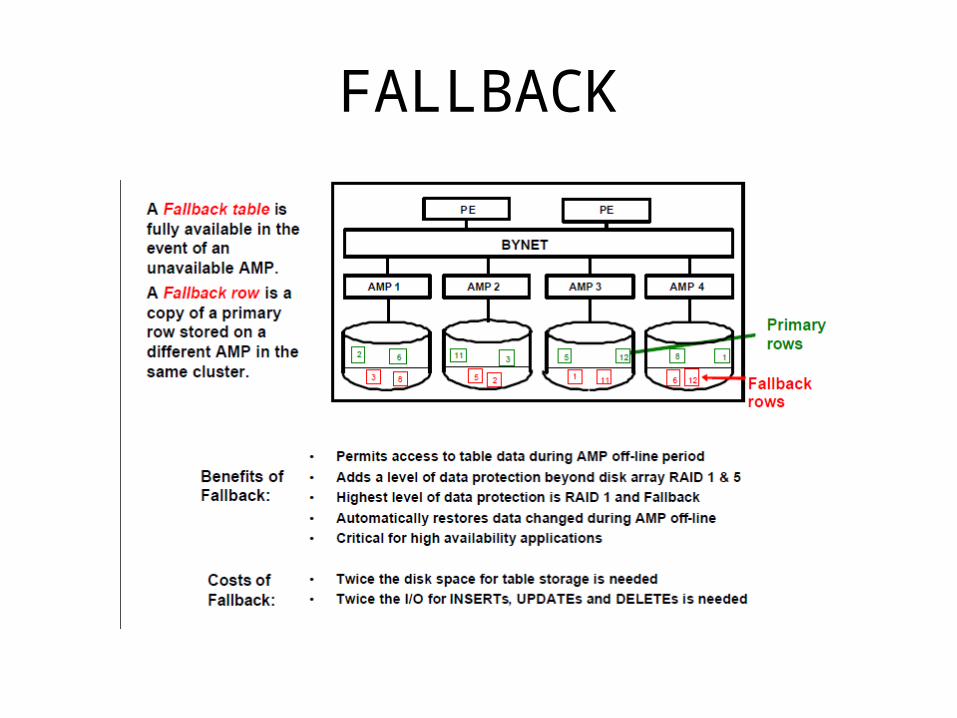
Fallback Feature• Provides data protection from AMP failure.• Stores copy of each row of the table in a separate
Fallback AMP in the same cluster.• If an AMP fails, the system accesses the Fallback
rows to meet requests• Fallback is an optional feature in Teradata which
we need to specify during table creation. If specified, it is automatic.
• Fallback guarantees that the two copies of a row will always be on different AMPs
FALLBACK

Fallback Cluster• A cluster is a group of AMPs that act as a single Fallback unit.• Clustering has no effect on primary row distribution of the table, b
ut the Fallback row will always go to another AMP in the same cluster
• Cluster size may range from 2 to 16 AMP’s• The loss of an AMP in one cluster has no effect upon other clusters.
It is possible to lose one AMP in each cluster and still have full access to all Fallback-protected table data.
• But if two AMP’s fail in the same cluster, the data access is lost.• When one AMP fails in a cluster, the other AMP’s in the cluster
should do their own work plus the work of the failed AMP,ie, the workload of the other amps will increase.

Fallback Cluster

Recovery Journal for Down AMPs• After the loss of any AMP, a down-AMP recovery
journal is started automatically to log any changes to rows which reside on the down AMP
• Any I/U/D operations to the rows on the down amp are applied to the fallback copy within the cluster.
• Once the down AMP is active again, the recovery journal is read and the changes are applied to the recovered AMP.
• The recovery journal is then discarded and the AMP is brought back online again.

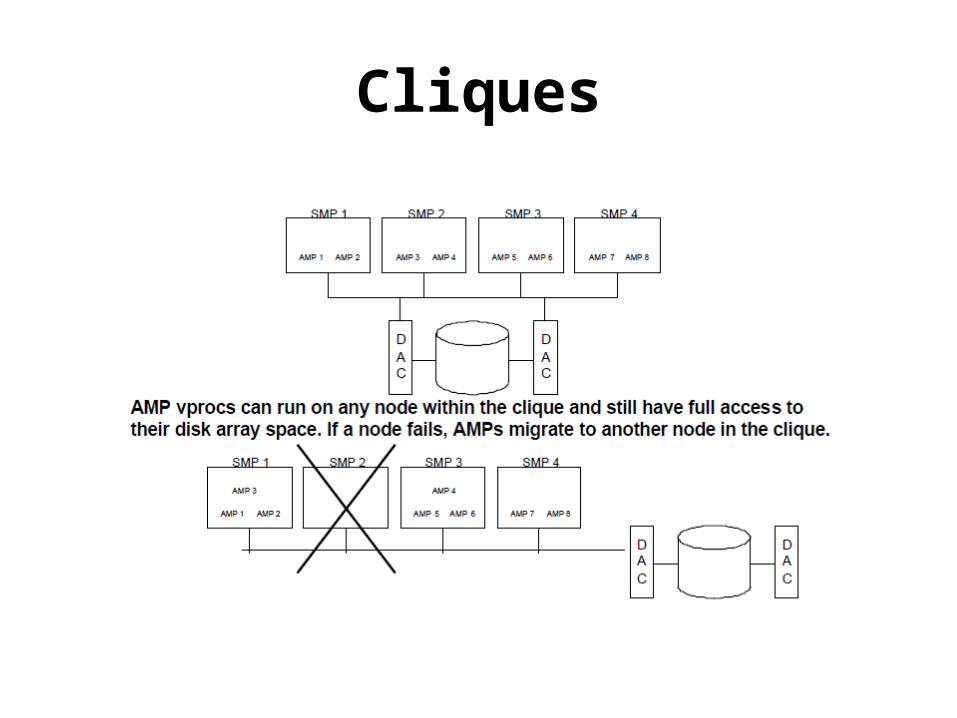
Cliques• A Collection of Teradata nodes which share a common
set of disks.
• Provides fault tolerance from Node failures
• In case of a node failure, the vprocs from the failed node can migrate to other available nodes in the clique thereby keeping the system operational
• When the failed node is returned back to operation,the vprocs will be brought back to the actual node
Cliques

Permanent Journal• Permanent Journals are optional, which we can define during table
creation.• It provides database recovery upto a specified point of time.• We can specify to capture before images(for roll back) or after
images(for roll forward) or both for all the rows which are getting changed(I/U/D operation).
• Additionally, the user must specify if single images (default) or dual images (for fault-tolerance) are to be captured
• Multiple tables or multiple databases may share a permanent journal
• It reduces the need for full table back-up’s which is very costly • The journal can be periodically dumped to external media.

Table definition with Fallback & Journal enabled
CREATE TABLE table_nameFALLBACK,NO BEFORE JOURNAL
AFTER JOURNAL ( field1 INTEGER,field2 INTEGER)PRIMARY INDEX field1;

Locking in Teradata• Locks are used for concurrency control,ie, Locking
prevents multiple users from changing the same data at the same time which can affect the data integrity
• Locks are automatically acquired during the processing of a request and released at the termination of the request. Users can also specify locks explicitly
• There are 3 levels of locking in teradata,ie, Database level, Table level and Row Level
• There are 4 types of locks ie, Exclusive Locks, Write Lock, Read lock and Access locks
• The type and level of locks are automatically chosen based on the type of SQL command

Locking• Exclusive locks are placed whenever there is any Database or Table
level structural changes,ie,DDL changes.This is the most restrictive of all the locks.
• Write locks enable users to modify data while locking out all other users except readers not concerned about data consistency.
• Write lock is established when there is an insert,delete or update request
• Read locks are used to ensure consistency during read operations. Read locks are established for select requests
• Several users may hold concurrent read locks on the same data• Access Locks(stale read locks.) : Users who are not concerned about
data consistency can specify access locks . This is placed in response to a user-defined LOCKING FOR ACCESS

Locking
• Teradata locks objects on a first come first serve basis. The first user to request an object is the first to lock the object. Teradata will place other users who are accessing the same object in a locking queue
• Teradata allows a user to move up the line if their lock is compatible with the lock in front of them

Compatibility between different Locks
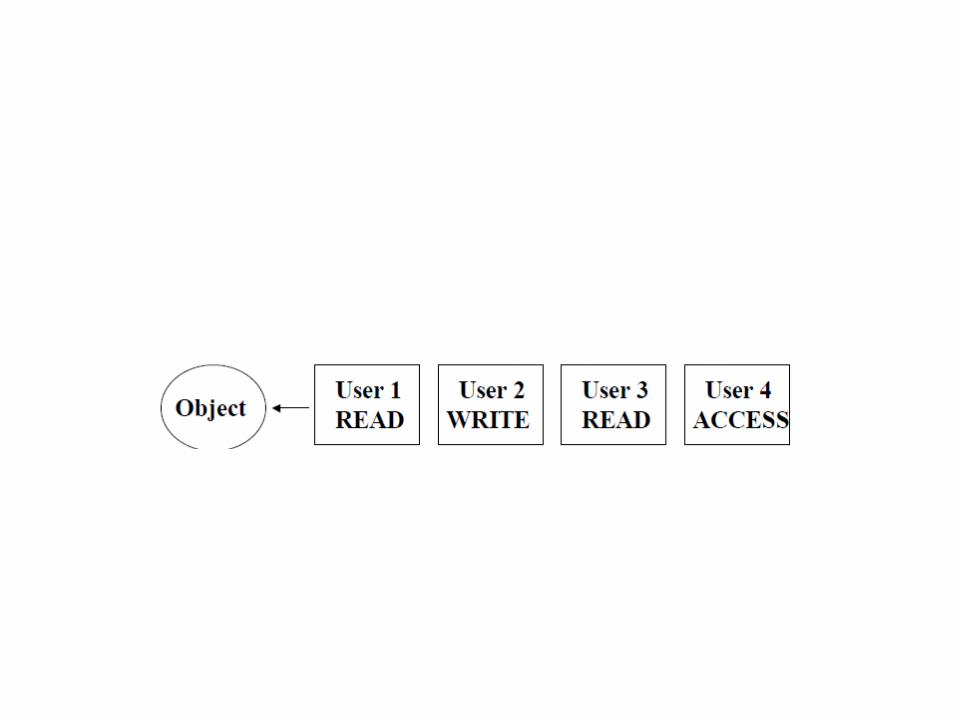

Compatibility between different Locks
• In the example in the previous slideUSER 1 is first in line and READS the objectUSER 2 must wait on USER 1USER 3 must wait on USER 2USER 4 moves past USER 3, then USER 2, and simultaneously reads the object with USER 1.
Example 2:

Compatibility between different Locks
USER 1 READS the Object immediatelyUSER 2 is compatible and WRITES on the object
alsoUSER 3 must wait on both USER 1 and USER 2USER 4 must wait until USER 3 is done. It is not
compatible with the EXCL and can’t move up.

• TERADATA UTILITIES OVERVIEW

BTEQ• BTEQ stands for Basic Teradata Query• Batch-mode utility for submitting SQL requests to the
Teradata database• Runs on every supported platform—laptop to mainframe• Can be used to export data to a client system from the
Teradata database• Reads input data and imports it to the Teradata database
as bulk INSERTs, UPDATEs, DELETEs or Upserts• A BTEQ script is a combination of BTEQ commands and SQL
commands.• Supports Conditional Logic and error handling.

FASTLOAD• FastLoad is a utility that can be used to quickly load
large amounts of data to an empty table on Teradata• FastLoad uses multiple sessions to load data to the
teradata table.• One fastload job per target table.• Full Restart capability.• Error Limits may be set• Error Tables collect records that fail to load, which can
later be used for analysis• Quickly loads the data into an empty table in 64K
blocks.

Restrictions on Fastload
• Target table must initially be empty.
• Target tables must NOT have: – Secondary Indexes defined – Enabled Triggers – Referential Integrity constraints

MULTILOAD• MultiLoad is used for loading, updating or deleting data to and from
populated or empty tables• Support for up to five target tables per script• Performs block level operations against populated tables and is
good for high percentage updates. Data processing is done in 64K blocks
• Uses conditional logic for applying changes.• Ability to do INSERTs, UPDATEs, DELETEs and UPSERTs (UPDATE if
exists, else INSERT)• Supports mainframe and network-attached systems• Full Restart capability using a Logtable.• Definable error limits• Error capture and reporting via error tables
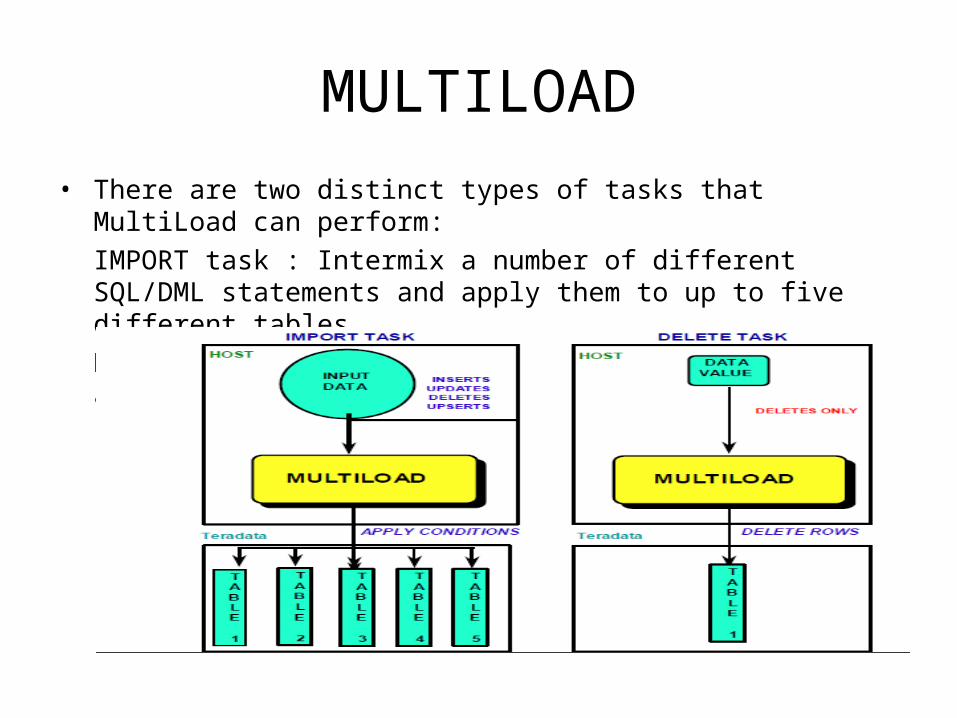
MULTILOAD• There are two distinct types of tasks that MultiLoad can perform:
IMPORT task : Intermix a number of different SQL/DML statements and apply them to up to five different tablesDELETE task: Execute a single DELETE statement on a single table

FASTEXPORT• Exports large volumes of Data from Teradata to a
file
• Can use multiple sessions with Teradata
• It can export data from multiple tables
• Fully automated restart capability
• Data export is done in 64k blocks

TPump Utility• Allows near real-time updates from transactional
systems into the warehouse• Allows constant loading of data into a table.• Performs INSERT, UPDATE, DELETE, or a combination,
to more than 60 tables at a time• Allows target tables to:
• Have secondary indexes, referential integrity constraints and enabled triggers.• Be populated or empty.
• Supports automatic restarts.• No session limit—use as many sessions as necessary









![Teradata Utilities[1]](https://static.fdocuments.us/doc/165x107/53ff9b25dab5ca61288b457a/teradata-utilities1.jpg)








