
Data flow vs. procedural programming: How to put your algorithms into Flink
22
June 23, 2015 Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 1 Flink Meetup #8 Data flow vs. procedural programming: How to put your algorithms into Flink June 23, 2015 Mikio L. Braun @mikiobraun
-
Upload
mikio-braun -
Category
Software
-
view
712 -
download
0
Transcript of Data flow vs. procedural programming: How to put your algorithms into Flink

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 1
Flink Meetup #8
Data flow vs. procedural programming: How to put your
algorithms into Flink
June 23, 2015
Mikio L. Braun@mikiobraun

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 2
Programming how we're used to
● Computing a sum
● Tools at our disposal:– variables
– control flow (loops, if)
– function calls as basic piece of abstraction
def computeSum(a):sum = 0for i in range(len(a))
sum += a[i]return sum

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 3
Data Analysis Algorithms
Let's consider centering
becomes
or even just
def centerPoints(xs): sum = xs[0].copy() for i in range(1, len(xs)): sum += xs[i] mean = sum / len(xs) for i in range(len(xs)): xs[i] -= mean return xs
xs - xs.mean(axis=0)

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 4
Don't use for-loops
● Put your data into a matrix● Don't use for loops

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 5
Least Squares Regression
● Compute
● Becomes
What you learn is thinking in matrices, breaking down computations in terms of matrix algebra
def lsr(X, y, lam): d = X.shape[1] C = X.T.dot(X) + lam * pl.eye(d) w = np.linalg.solve(C, X.T.dot(y)) return w

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 6
Basic tools
Advantage– very familiar
– close to math
Disadvantage– hard to scale
● Basic procedural programming paradigm● Variables● Ordered arrays and efficient functions on those

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 7
Parallel Data Flow
Often you have stuff like
Which is inherently easy to scale
for i in someSet:map x[i] to y[i]

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 8
New Paradigm
● Basic building block is an (unordered) set.● Basic operations inherently parallel

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 9
Computing, Data Flow Style
Computing a sum
Computing a mean
sum(x) = xs.reduce((x,y) => x + y)
mean(x) = xs.map(x => (x,1)) .reduce((xc, yc) => (xc._1 + yc._1, xc._2 + yc._2))
.map(xc => xc._1 / xc._2)

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 10
Apache Flink
● Data Flow system● Basic building block is a DataSet[X]● For execution, sets up all computing nodes,
streams through data

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 11
Apache Flink: Getting Started
● Use Scala API● Minimal project with Maven (build tool) or
Gradle● Use an IDE like IntelliJ
● Always import org.apache.flink.api.scala._

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 12
Centering (First Try)
def computeMeans(xs: DataSet[DenseVector]) =xs.map(x => (x,1))
.reduce((xc, yc) => (xc._1 + yc._1, xc._2 + yc._2)) .map(xc => xc._1 / xc._2)
def centerPoints(xs: DataSet[DenseVector]) = {val mean = computeMean(xs)
xs.map(x => x – mean)}
You cannot nest DataSet operations!

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 13
Sorry, restrictions apply.
● Variables hold (lazy) computations● You can't work with sets within the operations● Even if result is just a single element, it's a
DataSet[Elem].● So what to do?
– cross joins
– broadcast variables

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 14
Centering (Second Try)
Works, but seems excessive because the mean is copied to each data element.
def computeMeans(xs: DataSet[DenseVector]) =xs.map(x => (x,1))
.reduce((xc, yc) => (xc._1 + yc._1, xc._2 + yc._2)) .map(xc => xc._1 / xc._2)
def centerPoints(xs: DataSet[DenseVector]) = { val mean = computeMean(xs) xs.crossWithTiny(mean).map(xm => xm._1 – xm._2)}

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 15
Broadcast Variables
● Side information sent to all worker nodes● Can be a DataSet● Gets accessed as a Java collection

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 16
class BroadcastSingleElementMapper[T, B, O](fun: (T, B) => O) extends RichMapFunction[T, O] { var broadcastVariable: B = _
@throws(classOf[Exception]) override def open(configuration: Configuration): Unit = { broadcastVariable = getRuntimeContext .getBroadcastVariable[B]("broadcastVariable") .get(0) }
override def map(value: T): O = { fun(value, broadcastVariable) } }
Broadcast Variables

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 17
Centering (Third Try)def computeMeans(xs: DataSet[DenseVector]) =
xs.map(x => (x,1)) .reduce((xc, yc) => (xc._1 + yc._1, xc._2 + yc._2)) .map(xc => xc._1 / xc._2)
def centerPoints(xs: DataSet[DenseVector]) = {val mean = computeMean(xs)
xs.mapWithBcVar(mean).map((x, m) => x – m)}

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 18
Intermediate Results pattern
val x = someDataSetComputation()val y = someOtherDataSetComputation()
val z = dataSet.mapWithBcVar(x)((d, x) => …)
val result = anotherDataSet.mapWithBcVar((y,z)) { (d, yz) => val (y,z) = yz …}
x = someComputation()y = someOtherComputation()
z = someComputationOn(dataSet, x)
result = moreComputationOn(y, z)
June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 19
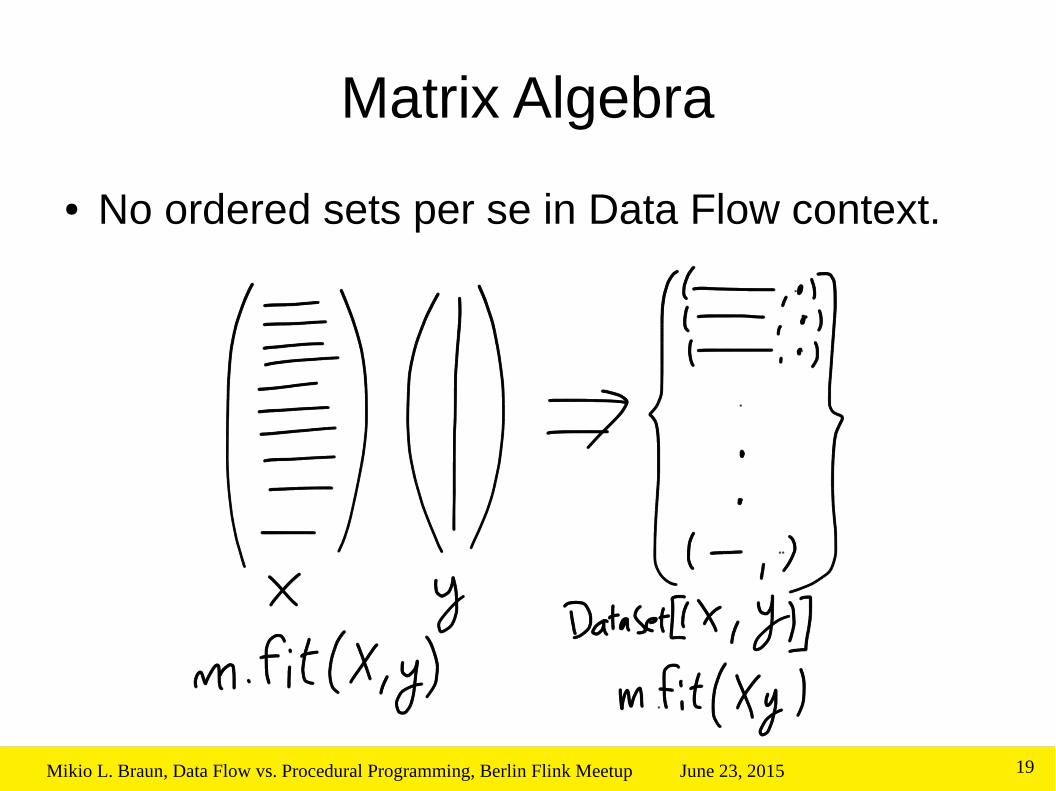
Matrix Algebra
● No ordered sets per se in Data Flow context.

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 20
Vector operations by explicit joins
● Encode vector (a1, a2, …, an) with
{(1, a1), (2, a2), … (n, an)}● Addition:
– a.join(b).where(0).equalTo(0) .map((ab) => (ab._1._1, ab._1._2 + ab._2._2))
after join: {((1, a1), (1, b1)), ((2, a1), (2, b1)), … }

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 21
Back to Least Squares Regression
Two operations: computing X'X and X'Y
def lsr(xys: DataSet[(DenseVector, Double)]) = { val XTX = xs.map(x => x.outer(x)).reduce(_ + _) val XTY = xys.map(xy => xy._1 * xy._2).reduce(_ + _)
C = XTX.mapWithBcVar(XTY) { vars => val XTX = vars._1 val XTY = var.s_2
val weight = XTX \ XTY }}

June 23, 2015Mikio L. Braun, Data Flow vs. Procedural Programming, Berlin Flink Meetup 22
Summary and Outlook
● Procedural vs. Data Flow– basic building blocks elementwise operations on
unordered sets
– can't be nested
– combine intermediate results via broadcast vars
● Iterations● Beware of TypeInformation implicits.




![Efficient Datastream Sampling on Apache Flink · For the sampling task all implemented algorithms perform as stream operators in the Apache Flink framework. Apache Flink [2] is an](https://static.fdocuments.us/doc/165x107/5ec57af17810c0214a0c2f45/efficient-datastream-sampling-on-apache-flink-for-the-sampling-task-all-implemented.jpg)













