
DA 592 - Term Project Presentation - Berker Kozan Can Koklu - Kaggle Contest
Upload
berker-kozanCategory
view
345download
5
Sabancı University Data Analytics M.Sc. Programme
2015-2016 Term
DA 592 - Term Project
Grupo Bimbo Inventory Demand
Kaggle Contest
Students: Berker Kozan, Can Köklü

Abstract
This data analytics project was done for a Kaggle contest where the goal was to perform
demand prediction for Grupo Bimbo company. Python language was used with Jupyter
notebooks. XGBoost library was used to perform training and predictions.
Various feature engineering features such as NLTK for text extraction, creation of lag
columns and averaging over a large number of variables were used to enhance data.
After the train table was created, XGBoost was utilized to optimize according to the
scoring function dictated by the contest, RMSLE. Hyperparameter tuning was also
leveraged after feature selection based on feature importance and correlation analysis
to determine the best parameters for the XGBoost optimizer.
The final submission to Kaggle achieved a score of 0.48666; placing our team in the top
17% of the 2000 contestants.
The biggest challenges were related to analyzing and training on a large data set. This
was overcome by forcing the data types to smaller types (unsigned integers, low
accuracy floats, etc.), using HDF5 file format for data storage and launching a
powerful Google Cloud Compute Preemptible Instance (with 208 GB RAM).
Further improvements would include attempting hyperparameter tuning across a wider
range of training tables (with different features) and also implementing a failsafe
method for running the experiment in preemptible instances. Additionally, creating
different models and averaging them to find optimal and non-overfitted models would
have yielded better results.
Keywords: data science, kaggle, demand prediction, python, jupyter, xgboost, cloud, google cloud compute, hdf5, hyperparameter tuning, feature selection
1
Table of Contents
Abstract 1
Table of Contents 2
Introduction 3
What is Kaggle? 3
What is the contest about? 3
Why this project? 4
Tools Used 4
Python 4
Platforms 5
Data Exploration 6
Definition of the Data Sets 6
Exploratory Data Analysis 7
Data Types and Sizes 7
Summary of Data 8
Correlations 9
Decreasing the Data Size 9
Models 10
Naive Prediction 10
Score 10
NLTK based Modelling 10
Feature Engineering 10
Modeling 11
Technical Problems 11
Garbage Collection 11
Data Size 11
Score 12
Conclusion 12
Final Models 12
Deeper Data Exploration 12
Demanda - Dev - Venta 12
Train - Test Difference 13
Feature Engineering 14
Agencia 14
Producto 14
Client Features 14
Demand Features 15
General Totals 15
Validation Technique 17
Xgboost 17
Training 18
Hyperparameter Tuning 18
Max Depth 18
Subsample 18
ColSample By Tree 18
Learning Rate 19
Technical Problems 19
Storing Data 19
RAM Problem 19
Code Reuse & Automatization 19
Results 20
Conclusion 21
Critical Mistakes 22
Further Exploration 22
2

Introduction
What is Kaggle?
Kaggle is a website founded in 2010 that provides data science challenges to its 1
participants. Participants compete against each other to solve data science problems.
Kaggle has unranked “practice” challenges as well as contests with monetary rewards.
Companies that have data challenges work together with Kaggle to formulate the problem
and reward the top performers.
What is the contest about?
The contest that we have taken on for our project belongs to a Mexican company named 2
Grupo Bimbo. Grupo Bimbo is a company that produces and distributes fresh bakery
products. The nature of the problem at its core is demand estimation.
Grupo Bimbo produces the products and ships them from storage facilities (agencies) to
stores (clients). The following week, a certain number of products that aren’t sold are
returned from the clients to Bimbo. To maximize their profits, Grupo Bimbo needs to
predict the demand of stores accurately to minimize these returns.
In the contest, we are provided with 9 weeks worth of data regarding these shipments
and we are asked to predict the demand for weeks 10 and 11. Participants are allowed to
submit 3 sets of predictions every day until the deadline of the project and can pick
any two of these predictions as their final submissions.
As a standard practice at Kaggle, when making initial submissions, the predictions are
ranked based on a “public” ranking which only evaluates a certain part of the
submission. This is done to prevent gaming the system by overfitting through trial &
error of submissions. For this contest, the “public” ranking is done on week 10 data;
meaning, when submitting our predictions we would only be able to see our performance
for week 10. The private performance of our predictions (i.e. weeks 11) are only shown
after the contest ends.
For this contest the evaluation metric is the Root Mean Squared Logarithmic Error of
our predictions.
1 "About | Kaggle." 2012. 10 Sep. 2016 < https://www.kaggle.com/about > 2 "Grupo Bimbo Inventory Demand | Kaggle." 2016. 10 Sep. 2016 < https://www.kaggle.com/c/grupo-bimbo-inventory-demand >
3

Why this project?
We decided to do a Kaggle contest for our project for various reasons:
1.It would allow us to benchmark our data science abilities in an international
field.
2.Kaggle has very active forums for each individual contest and these would provide
us with great new methods and insights in solving problems.
3.Since the data provided is clean, we could spend more time in feature and model
building rather than data cleaning.
4.We could work towards a clear goal and not be distracted.
5.From the number of contest in Kaggle, we picked the Grupo Bimbo project because:
a.It deals with text data which is considerably easier to work with for
beginners.
b.The data was very large and provided a learning opportunity in working
with large data sets.
c.The deadline of the project (August 30) was in line with the deadline of
our term project.
Tools Used
Python
We decided to use Python (version 2.7) as the our scripting language. This is the 3
language we worked with most in our programme and also one of the most popular data
science languages. We built our systems on the Anaconda package by Continuum as it 4
offers a large number of libraries that help us face the challenges.
We mainly ran Jupyter (IPython) notebooks on various systems to code and report 5
results.
A few of the specific tools/packages that we used were:
● NLTK: NLTK is the most popular Natural Language Processing Toolkit for Python. 6
It offers great features like stemming, tokenizing and chunking in multiple
languages. This was critical since the product names were in Spanish.
● XGBoost: XGBoost is a library that can be used in conjunction with various scripting languages (including R and Python) that is designed for gradient
boosting trees. It is much faster than regular scripting tools since the
computational parts are written and precompiled in C++. We picked this solution
based simply on its fame, as many of the winners have used this tool in Kaggle
contests. 7
● Pickle: The pickle module implements binary protocols for serializing and 8
de-serializing a Python object structure.
3 "Python 2.7.0 Release | Python.org." 2014. 10 Sep. 2016 < https://www.python.org/download/releases/2.7/ > 4 "Download Anaconda Now! | Continuum - Continuum Analytics." 2015. 10 Sep. 2016 < https://www.continuum.io/downloads > 5 "Project Jupyter | Home." 2014. 10 Sep. 2016 < http://jupyter.org/ > 6 "Natural Language Toolkit — NLTK 3.0 documentation." 2005. 10 Sep. 2016 < http://www.nltk.org/ > 7 "xgboost/demo at master · dmlc/xgboost · GitHub." 2015. 10 Sep. 2016 < https://github.com/dmlc/xgboost/tree/master/demo > 8 "12.1. pickle — Python object serialization — Python 3.5.2 documentation." 2014. 20 Sep. 2016 < https://docs.python.org/3/library/pickle.html >
4

● HDF5 File Format: HDF is self-describing, allowing an application to interpret 9
the structure and contents of a file with no outside information, a
general-purpose, machine-independent standard for storing scientific data in
files, developed by the National Center for Supercomputing Applications (NCSA).
● Scikit-Learn: Scikit-Learn is a simple and efficient tool for data mining and 10
machine learning beside that it’s free and build on numpy, matplotlib and scipy.
We used it on feature extraction phase.
● NumPy: NumPy is an open source extension module for Python, which provides fast 11
precompiled functions for mathematical and numerical routines. Furthermore, NumPy
enriches the programming language Python with powerful data structures for
efficient computation of multidimensional arrays and matrices.
● SciPy: SciPy is a Python-based ecosystem of open-source software for 12
mathematics, science, and engineering. We used it for sparse matrices.
● Garbage Collector: The gc module was used in order to free up memory 13
periodically to optimize performance.
Platforms
For coding and performing our computations, we initially attempted to use our laptops
(a Macbook Pro and an Ubuntu Machine each with 16GB of RAM). However, after getting
numerous Memory Errors, we gradually came to realize that our computers would not be
able to run the computations that we need (at least not in an efficient and timely
manner). To solve our problem we turned to cloud services.
We first set up an EC2 instance on Amazon Web Services with about 100GB of RAM and 16
virtual CPU cores, using a public tutorial. However, running such a powerful instance 14
continuously proved costly; a two day attempt to build and run models cost over 150USD.
(An important side note, one should make sure that all items that relate to the
instance created are removed completely to avoid incurring charges. In the case of one
of the authors of this paper, an extra 50USD was later charged because backup copies of
the instances were not deleted.)
We then decided to switch to Google Cloud Compute service; building a system with
similar specs, again following a publicly available tutorial. Although slightly 15
cheaper, having a dedicated machine run for an entire day again proved costly,
incurring about 50USD. At this point we decided to find a cheaper solution and decided
to look at Amazon’s Spot Instances and Google’s Preemptible Instances.
Both Amazon Spot Instances and Google Preemptible Instances operate on the principle
that they offer the company's surplus computing power at a discount. The caveat being
that if there are other consumers that want to use this computing power, the instances
9 "Importing HDF5 Files - MATLAB & Simulink - MathWorks." 2012. 20 Sep. 2016 < http://www.mathworks.com/help/matlab/import_export/importing-hierarchical-data-format-hdf5-files.html > 10 "scikit-learn: machine learning in Python — scikit-learn 0.17.1 ..." 2011. 20 Sep. 2016 < http://scikit-learn.org/ > 11 "What is NumPy? - Numpy and Scipy Documentation." 2009. 20 Sep. 2016 < http://docs.scipy.org/doc/numpy/user/whatisnumpy.html > 12 "SciPy.org — SciPy.org." 2002. 21 Sep. 2016 < http://www.scipy.org/ > 13 "28.12. gc — Garbage Collector interface — Python 2.7.12 ..." 2014. 21 Sep. 2016 < https://docs.python.org/2/library/gc.html > 14 "Setting up AWS for Kaggle Part 1 – Creating a first Instance – grants ..." 2016. 10 Sep. 2016 < http://www.grant-mckinnon.com/?p=6 > 15 "Set up Anaconda + IPython + Tensorflow + Julia on a Google ..." 2016. 10 Sep. 2016 < https://haroldsoh.com/2016/04/28/set-up-anaconda-ipython-tensorflow-julia-on-a-google-compute-engine-vm/ >
5

can be stopped by the company at any point. The biggest difference between the two is
that Amazon offers a more bidding model where the prices for the computing power
fluctuates; if the bid that the buyer is higher than the current market price, the
instance remains active; however if the market price raises above the bid, it is shut
down. Google on the other hand offers a specific price for the instance. 16
We eventually settled down on using a Google Preemptible instance with 32 virtual CPUs
and 208 GB of RAM. We had to deal with a premature shutdown only once while running the
instance over the course of three days. The total cost of the preemptible instances and
backups etc came to about 60 USD.
The key interface to the Google Cloud interface was a command prompt terminal, where
the Jupyter notebook was initiated and data files were uploaded and submission files
were downloaded via SSH.
Github 17
GitHub is a code hosting platform for version control and collaboration which lets
people work together on projects from anywhere. We used this to work on our codes in
parallel while easily merging our developments.
Data Exploration
Definition of the Data Sets
The data sets that we were provided with was as follows:
● train.csv — the training set, total Demand data from clients and products per week for weeks 3-9; containing the following fields:
○ Semana - The week
○ Agencia_ID - ID of the storage facility from which the order is
dispatched.
○ Canal_ID - The channel through which the order is placed.
○ Ruta_SAK - The route ID of the delivery route.
○ Cliente_ID - The Client ID
○ Producto_ID - The Product ID
○ Venta_uni_hoy - The number of items that were ordered
○ Venta_hoy - The total cost of the items that were ordered
○ Dev_uni_proxima - The number of items that were returned.
○ Dev_proxima - The total cost of the items that were returned.
○ Demanda_uni_equil - Actual demand (the stock that was actually sold), this is the label that we need to predict for weeks 10 and 11.
● test.csv — the test set, data from clients and products for weeks 10 and 11 containing the fields:
○ Id
○ Semana
○ Agencia_ID
○ Canal_ID
○ Ruta_SAK
○ Cliente_ID
16 "What are the key differences between AWS Spot Instances ... - Quora." 2015. 10 Sep. 2016 < https://www.quora.com/What-are-the-key-differences-between-AWS-Spot-Instances-and-Googles-Preemptive-Instances > 17 "Hello World · GitHub Guides." 2014. 20 Sep. 2016 < https://guides.github.com/activities/hello-world/ >
6

○ Producto_ID
● cliente_tabla.csv — client names (can be joined with train/test on Cliente_ID) ● producto_tabla.csv — product names (can be joined with train/test on Producto_ID)
● town_state.csv — town and state (can be joined with train/test on Agencia_ID) ● sample_submission.csv — a sample submission file in the correct format
Image 1: Data Structure
None of the numeric variables existing in train data are in the test set of the data,
so the problem here is predicting the demand with only 6 categorical features.
Exploratory Data Analysis
Data Types and Sizes
The sizes of the data files were as follows:
● town_state.csv 0.03MB
● train.csv 3199.36MB
● cliente_tabla.csv 21.25MB
● test.csv 251.11MB
● producto_tabla.csv 0.11MB
● sample_submission.csv 68.88MB
7

Distributions and Summary of Data
Image 2: Summary of Train Data
Image 3: Summary of Train Data (cont.)
Image 4: Distribution of Target Variable
Target variable's mean is 7, median is 3, max is 5000, std is 25 and %75 of the data is
between 0-6. This is a classical right-skewed data and this explains why evaluation
metric is RMSLE. Moreover, we logged target variable (log(variable+1)) before starting
modeling and than take exponential of it before submitting (exp(variable)-1).
8
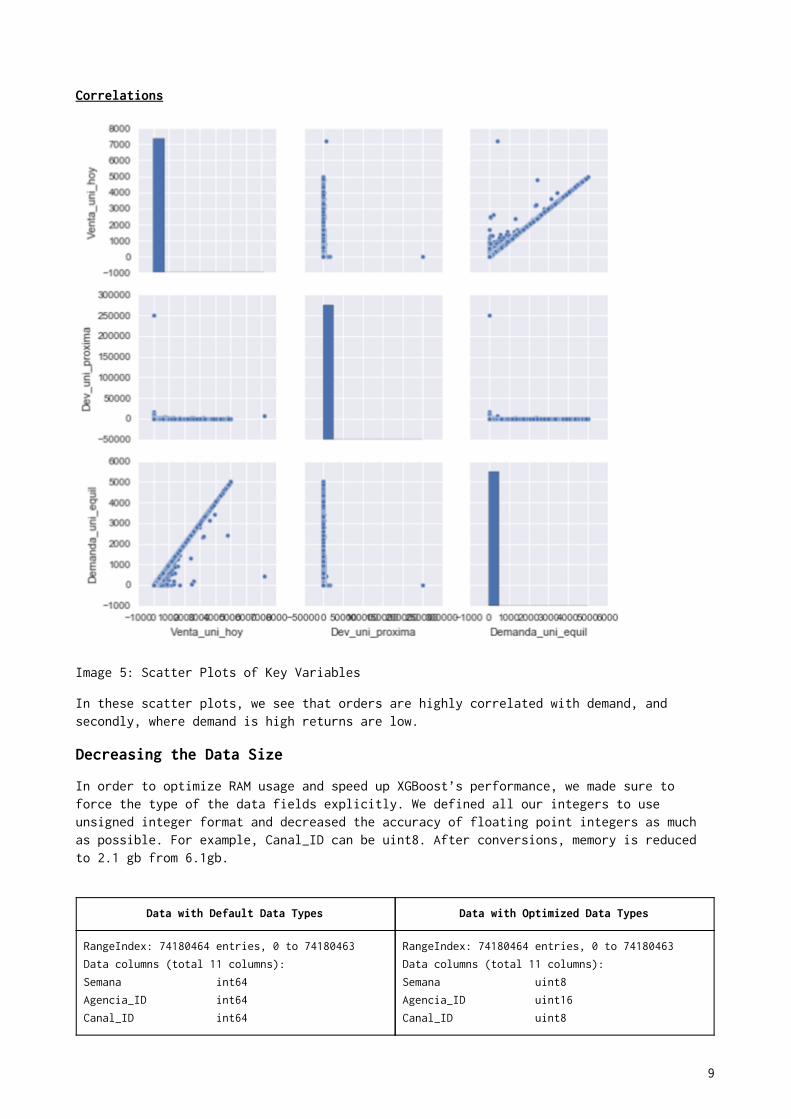
Correlations
Image 5: Scatter Plots of Key Variables
In these scatter plots, we see that orders are highly correlated with demand, and
secondly, where demand is high returns are low.
Decreasing the Data Size
In order to optimize RAM usage and speed up XGBoost’s performance, we made sure to
force the type of the data fields explicitly. We defined all our integers to use
unsigned integer format and decreased the accuracy of floating point integers as much
as possible. For example, Canal_ID can be uint8. After conversions, memory is reduced
to 2.1 gb from 6.1gb.
Data with Default Data Types Data with Optimized Data Types
RangeIndex: 74180464 entries, 0 to 74180463
Data columns (total 11 columns):
Semana int64
Agencia_ID int64
Canal_ID int64
RangeIndex: 74180464 entries, 0 to 74180463
Data columns (total 11 columns):
Semana uint8
Agencia_ID uint16
Canal_ID uint8
9

Ruta_SAK int64
Cliente_ID int64
Producto_ID int64
Venta_uni_hoy int64
Venta_hoy float64
Dev_uni_proxima int64
Dev_proxima float64
Demanda_uni_equil int64
dtypes: float64(2), int64(9)
memory usage: 6.1 GB
Ruta_SAK uint16
Cliente_ID uint32
Producto_ID uint16
Venta_uni_hoy uint16
Venta_hoy float32
Dev_uni_proxima uint32
Dev_proxima float32
Demanda_uni_equil uint32
dtypes: float32(2), uint16(4), uint32(3),
uint8(2)
memory usage: 2.1 GB
Models
Naive Prediction
We first decided to create a naive prediction; for this we grouped the training data
based on Product ID, Client ID, Agency ID and Route ID. We simply took the median of
this grouping, if this specific grouping did not exist, in the training data set, we
defaulted back to the product’s median demand and if this also did not exist, we simply
took the average of the overall demand.
Score
This method resulted in a score of 0.73 when submitted.
NLTK based Modelling
Feature Engineering
We utilized the NLTK library to extract the following information from the Producto
Tabla file (we used a slightly modified version of a code provided by Andrey Vykhodtsev
) 18
● Weight: In grams
● Pieces
● Brand Name: Extracted through a three letter acronym
● Short Name: Extracted from the Product Name field. We processed this information
using the NLTK library. We first removed the Spanish “stop words” and then used
the stemming in order to make sure only the cores of the names remained.
18 "Exploring products - Kaggle." 2016. 10 Sep. 2016 < https://www.kaggle.com/vykhand/grupo-bimbo-inventory-demand/exploring-products >
10

Image 6: Product Data Names after preprocessing
Modeling
We wanted to model text data and predict. Here are the steps that were taken:
1)Separate x and y of train data
2)Append test data to train data to align them to have same sparse product features
order (If they don’t have same column order, training gives false results).
3)Merge this data with products.
4)Use “count vectorizer” of Scikit-learn on brand and short_name columns to create
sparse count-word matrices and append them to train-test data horizontally.
5)Separate appended train and test data.
6)Train Xgboost with default parameters on train data and predict test data.
Technical Problems
1)Garbage Collection
Garbage collection was a big problem because of the size of the data. When we
stopped using a python object, we had to remove and force garbage collection
mechanism to free this memory. For this the the gc library was used. 19
2)Data Size
Before using xgboost, we had 70+ million records with 577 columns. Holding this
sparse data in memory with dataframe was impossible. We solved this issue with
sparse matrices of SciPy library.
In the example below, instead of holding all data including zeros in memory,
sparse method holds only data different than 0. There are many sparse matrices
methods. We used “CSR” and “COO” ones. 20
19 "28.12. gc — Garbage Collector interface — Python 2.7.12 ..." 2014. 21 Sep. 2016 < https://docs.python.org/2/library/gc.html > 20 "Sparse matrices (scipy.sparse) — SciPy v0.18.1 Reference Guide." 2008. 21 Sep. 2016 < http://docs.scipy.org/doc/scipy/reference/sparse.html >
11

Image 7: Visual explanation of how the COO sparse matrix works.
Score
The RMSLE scores obtained by using this method were as follows:
Validation Test 10 Test 11 (Private)
0.764 0.775 0.781
Conclusion
These scores are worse than the naive approach, so we started to think about a new
model.
Final Models
Digging Deeper in Data Exploration
1.Demanda - Dev - Venta Relationship
On data description page of contest, it’s said that Demanda = Venta-Dev except
some return situations.
When we query this equation, there are 615000 records which are exceptions as
shown below. It can mean that returns can be done after more than 1 week. We
flagged these products.
Image 8: Exceptional cases where the number of returns is higher than the number
of orders (lagging returns).
Secondly, we query Demanda = 0 & Dev = 0 and there are 199767 records which
includes only returns. When we find demand mean of a product, these records can
falsify our results as they only include return values.
12

Image 9: Exceptional cases where the number of orders and demand are both zero.
2.Train - Test Difference
We analyzed the missing products, clients, agencies and routes tuples which exist
in train but not in test and vice versa or in specific files.
There were 9663 clients, 34 products, 0 agencies and 1012 routes that doesn’t
exist in train data.
he important outcome of this analysis was that: we should build a general model that can handle new products, clients and routes which don’t exist in train data but in test data.
Feature Engineering
In order to provide our models with more information, we had to perform some feature
engineering.
Agencia
Agencia file shows each agency’s town id and state name. We can merge this file with
train and test data on Agencia_ID column and encode state columns into integers.
Image 10: Agencia Table after processing.
Producto
We used features from NLTK model, weights and pieces. In addition to them, we included
short names of product and brand id.
In the picture below, we can see same product with different weights and different ids.
We take the short name of this products (we will add a feature like they are the same
product) and include them to the features. Later we will see why.
Product file
2025 , Pan Blanco 460g WON 2025
2027 , Pan Blanco 567g WON 2027
13

Demand Features
This was the most critical part of our data structure. We generated 4 new columns for
our training and testing data and named them Lag0, Lag1, Lag2 and Lag3. We asked
ourselves why we hadn’t added the product’s ex demands.
Lag0 is a special case that attempts to find the average demand for a specific row.
This is done by attempting to find the average based on a large number of variables (as
specific as possible) and failing that, attempting to find the average of a fewer
number of variables (a more relaxed, less accurate and more general average).
For example,
● Average demand based on:
"Producto_ID", "Cliente_ID", "Ruta_SAK", "Agencia_ID", "Canal_ID"
● If this combination is not found, attempt to find average based on:
"Producto_ID", "Cliente_ID", "Ruta_SAK", "Agencia_ID"
● If this combination is not found, attempt to find average based on:
"Producto_ID", "Cliente_ID", "Ruta_SAK"
● And so on and so forth.
This was done in the order of finding various averages based on product id first, then
falling back on averages based on the short names of products (In Pan Blanco example above, If product 2025 can’t be found, we used “product 2027” instead, thinking that
product 2027 gives an idea about the product 2025), failing that, falling back on
averages based on the brand names (In the same example, “WON” is used).
Lag 1 through 3 were constructed in a similar fashion but were more strict and
considered only a single week’s data. In these cases, we did not want to create any
information based on Brand names as it would be too general. Only combinations with
product id and product short name were used. So for a line of training data that
pertained to week 7, Lag 1 would be the averages of that product id or product name
based on week 6 data; Lag 2 would be averages of week 5 data; and so on and so forth.
Client Features
The Client Features were more difficult to engineer. Unlike the product table, the
client table had a large number of duplicates, where clients names were misspelled in
different cases. We removed the duplicates from the client table and then used a code
snippet provided by AbderRahman Sobh (the process made use of using TF-IDF scoring of 21
the client names and then manual selection of certain keywords) in order to classify
the clients based on their types, resulting in the following categorization:
● Individual 353145
● NO IDENTIFICADO 281670
● Small Franchise 160501
● General Market/Mart 66416
● Eatery 30419
● Supermarket 16019
● Oxxo Store 9313
● Hospital/Pharmacy 5798
● School 5705
21 "Classifying Client Type using Client Names - Kaggle." 2016. 10 Sep. 2016 < https://www.kaggle.com/abbysobh/grupo-bimbo-inventory-demand/classifying-client-type-using-client-names >
14

● Post 2667
● Hotel 1127
● Fresh Market 1069
● Govt Store 959
● Bimbo Store 320
● Walmart 220
● Consignment 14
General Totals
After obtaining the above averages, we also included the following:
● Total Venta per client (giro of client)
● Total Venta_uni_hoy per client (total unit product sold by a client)
● Division of sum of venta_hoy to venta_uni_hoy (giving the approximate price per
unit).
● Division of sum of demand to sum of Venta uni (giving the ratio of goods actually
sold by the client, i.e. ability to sell inventory)
This was done for product short names and also product ids; resulting in an additional
12 more columns for our training data. Other added columns are shown below:
● Client per town
● Sum of returns of product
● Sum of returns of short name of a product
After eliminating highly correlated features (%90), the training data table was as
follows:
Int64Index: 74180464 entries, 0 to 74180463 Data columns (total 36 columns): Semana uint8 Agencia_ID uint16 Canal_ID uint8 Ruta_SAK uint16 Cliente_ID uint32 Producto_ID uint16 Venta_uni_hoy uint16 Venta_hoy �oat32 Dev_uni_proxima uint32 Dev_proxima �oat32 Demanda_uni_equil �oat64 Town_ID uint16 State_ID uint8 weight uint16 pieces uint8 Prod_name_ID uint16 Brand_ID uint8 Demanda_uni_equil_original �oat64 DemandaNotEqualTheDifferenceOfVentaUniAndDev bool Lag0 �oat64 Lag1 �oat64 Lag2 �oat64 Lag3 �oat64 weightppieces uint16 Client_Sum_Venta_hoy �oat32
15

Client_Sum_Venta_uni_hoy �oat32 Client_Sum_venta_div_venta_uni �oat32 prod_name_sum_Venta_hoy �oat32 prod_name_sum_Venta_uni_hoy �oat32 prod_name_sum_venta_div_venta_uni �oat32 Producto_sum_Venta_hoy �oat32 Producto_sum_Venta_uni_hoy �oat32 Producto_sum_venta_div_venta_uni �oat32 Producto_ID_sum_demanda_divide_sum_venta_uni �oat64 Prod_name_ID_sum_demanda_divide_sum_venta_uni �oat64 Cliente_ID_sum_demanda_divide_sum_venta_uni �oat64 memory usage: 10.6 GB
Validation Technique
Validation is the maybe the most critical part of a data science project. Top priority
was to not overfitting the data. We used different models to predict week 10 and week
11.
Image 11: Structure of training, validation and test mechanism.
We used 6th and 7th week data as training. Our validation for week 10 was 8th, our
validation for week 11 was 9th. In the latter one, we didn’t use Lag1 variable, because
it means that in order to predict week 11, we should use week 10’s demand (Lag1 of week
11 is week 10) which doesn’t exist. Or, we should predict week 10 first and with this
predicted demands, we predict week 11 but it carries error from week 10 to week 11.
After feature extraction phase and adding features to each record, we deleted first 3
weeks. Because they don’t have Lag1, Lag2 and Lag3 features.
Xgboost
Xgboost can be given 2 different datasets (train and validation). With playing with
parameters, we can make it train until the validation score stops increasing after “N”
iterations. It automatically stops and tells you the best iteration number and its
score.
Xgboost can also give feature importances according to the counts of features on trees
of model. For example:
16

Image 12: Feature importance graph of fitted training data based on XGboost
Training
We started to make models after defining validation strategy and feature extraction.
Features Validation 1 (Week 8)
Validation 2 (Week 9)
Trial 1 0.476226 0.498475
Trial 2: Removing highly correlated features 0.477067 0.493038
Trial 3: Adding lag interactions. 0.502514 N/A
Trial 4: Adding more lag interactions 0.51825 N/A
Trial 5: Lag interactions but removing more
correlated features
0.517606 N/A
Trial 6: Replacing extreme values with NAN 0.517467 0.517375
Trial 7: Removing low importance features (all
lag interactions are removed)
0.480394 0.494104
Trial 8: Adding Client Types 0.48101 0.494804
Many other variations were tried but abandoned due to poor performance.
Interestingly, the original data set (with engineered features such as averages, lags
etc.) resulted in the best performance. There is a caveat however, these attempts were
all made with a fixed setting in XGBoost, as will be seen next, the number of trees may
have been set too low in these trials to take into account the benefits of added
features such as interactions between lags or clients types etc.
Hyperparameter Tuning
After selecting the data set, we proceeded with hyperparameter tuning of the XGBoost
model.
The XGBoost library has numerous parameters, the ones that were used for tuning were:
17

Max Depth:
The maximum depth of the decision trees.
● Values tried: 10, 12, 8, 6, 14, 18, 20, 22
● Optimal Value: 22
Subsample:
The subsampling rate of rows of the data.
● Values tried: 1, 0.9, 0.8, 0.6
● Optimal Value: 0.9
ColSample By Tree:
The subsampling rate of columns of the data.
● Values tried: 0.4, 0.3, 0.5, 0.6, 0.8, 1
● Optimal Value: 0.4
Learning Rate:
The gradient descent optimization parameter (the size of each step).
● Values tried: 0.1, 0.05
● Optimal Value: 0.05
Features Validation 1 (Week 8)
Validation 2 (Week 9)
Original Training 0.476226 0.498475
Training after Parameter Tuning 0.469628 0.489799
Technical Problems
Storing Data
“CSV” file type is very slow to load and save. In addition to that, it isn’t
self-describing. When we try to load data from it, we have to do all conversions as we
did before saving it. We searched for a better file format to store that much data.
Firstly, we tried “pickle” library which we used for storing xgboost models because of
self-describing feature. But after file size gets bigger, it starts to give error.
Secondly, we tried “HDF5” which is designed for storing big data on file. It was both
very fast to load and save and also self-describing. We picked this one.
RAM Problem
Due to the size of the training and test tables, it was not possible to perform the
operations using our underpowered laptops. Attempting to join large tables or use
XGBoost to create models always resulted in memory errors. We solved this issue by
migrating our environment to Google Cloud Compute. We used linux command line prompts
to install Anaconda and related libraries and then launched Jupyter notebook to create
a development environment. At its highest level, our instance (with 32 virtual CPUs and
18

208GB RAM) was performing at 100% CPU load and 40% RAM usage. Training and predicting
over our full train and test data took more than 2 hours.
Code Reuse and Automatization
There were lots of coding challenges for us as follows:
● Opening csv files with predefined data types and names
● Handling hdf5 files
● Adding configurable features (Lag0, Lag1, …) to data
● Automatically deleting first “N” lagged weeks from train data
● Appending test to train data
● Separating test and train data automatically
● Xgboost configurable hyperparameter tuning
● Handling memory issues
We solved this issues with Object Oriented Programming with Python. This is the
structure of our general class. class FeatureEngineering :
def __init__ ( self , ValidationStart, ValidationEnd, trainHdfPath, trainHdfFile,
testHdfPath1, testHdfPath2, testHdfFile, testTypes, trainTypes, trainCsvPath, testCsvPath,
maxLag =0 )
def __printDataFrameBasics__ (data)
def ReadHdf ( self , trainOrTestOrBoth)
def ReadCsv ( self , trainOrTestOrBoth)
def ConvertCsvToHdf (csvPath, HdfPath, HdfName, ColumnTypeDict)
def Preprocess ( self , trainOrTestOrBoth, columnFunctionTypeList)
def SaveDataFrameToHdf ( self ,trainOrTestOrBoth)
def AddCon�gurableFeaturesToTrain ( self , con�g)
def DeleteLaggedWeeksFromTrain ( self )
def ReadFirstNRowsOfACsv ( self , nrows, trainOrTestOrBoth)
def AppendTestToTrain ( self ,deleteTest = True )
def SplitTrainToTestUsingValidationStart ( self )
We can use this class by giving configurable parameters.
parameterDict = { "ValidationStart" : 8 , "ValidationEnd" : 9 , "maxLag" : 3 ,
"trainHdfPath" : '../../input/train_wz.h5' , "trainHdfFile" : "train" ,
"testHdfPath1" : "../../input/test1_wz.h5" , "testHdfPath2" : "../../input/test2_wz.h5" ,
"testHdfFile" : "test" ,
"trainTypes" : { 'Semana' :np . uint8, 'Demanda_uni_equil' : np . uint32}, "testTypes" :
{ 'id' :np . uint32, 'Semana' :np . uint8, 'Agencia_ID' :np . uint16},
"trainCsvPath" : '../../input/train.csv' , "testCsvPath" : '../../input/test.csv' }
FE = FeatureEngineering( ** parameterDict)
To add complex lagged feature, we build an automation system which works with a config
variable.
con�gLag0Target1DeleteColumnsFalse = Con�gElements( 0 ,[ ( "SPClRACh0_mean" ,
[ "Producto_ID, "Cliente_ID, "Ruta_SAK, "Agencia_ID, "Canal_ID], [ "mean" ]),
( "SPClRA0_mean" ,
[ "Producto_ID" , "Cliente_ID" , "Ruta_SAK" , "Agencia_ID" ], [ "mean" ]),
( "SB0_mean" ,[ "Brand_ID" ], [ "mean" ])], "Lag0" , True )
FE . AddCon�gurableFeaturesToTrain(con�gLag0Target1)
To do hyperparameter tuning automatically, we wrote a python function.
19
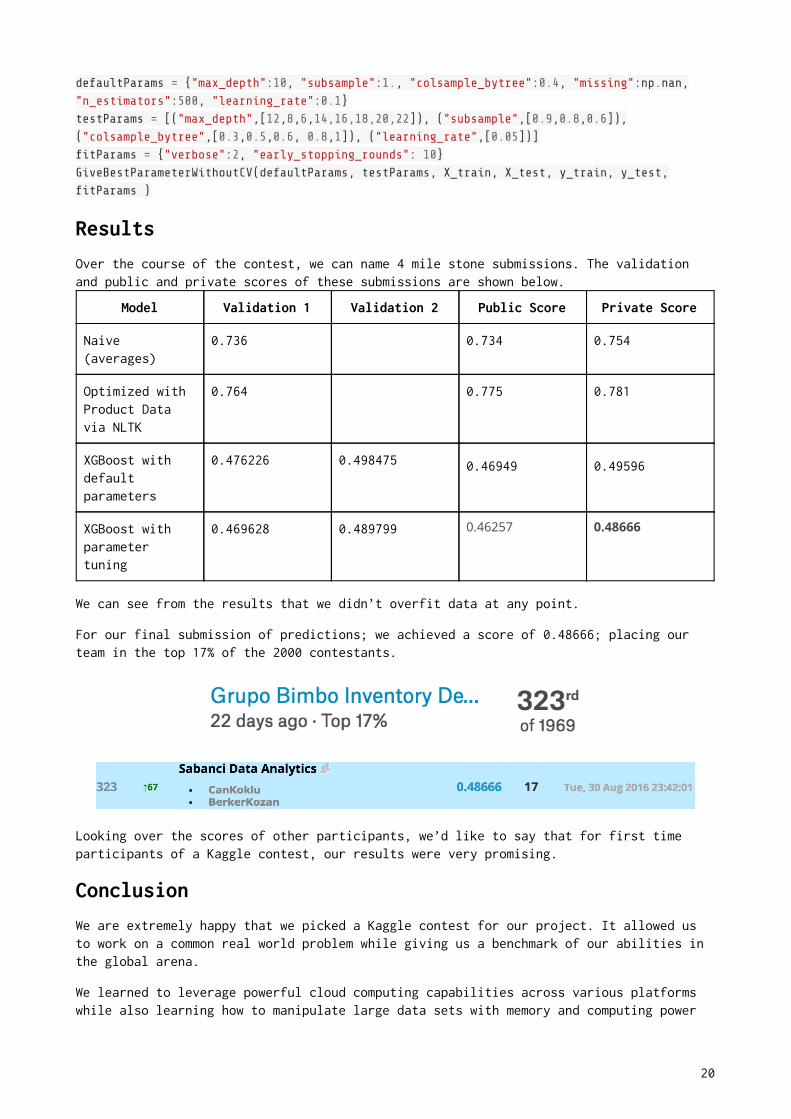
defaultParams = { "max_depth" : 10 , "subsample" : 1. , "colsample_bytree" : 0.4 , "missing" :np . nan,
"n_estimators" : 500 , "learning_rate" : 0.1 }
testParams = [( "max_depth" ,[ 12 , 8 , 6 , 14,16,18,20,22 ]), ( "subsample" ,[ 0.9 , 0.8 , 0.6 ]),
( "colsample_bytree" ,[ 0.3 , 0.5 , 0.6 , 0.8 , 1 ]), ( "learning_rate" ,[ 0.05 ])]
�tParams = { "verbose" : 2 , "early_stopping_rounds" : 10 }
GiveBestParameterWithoutCV(defaultParams, testParams, X_train, X_test, y_train, y_test,
�tParams )
Results
Over the course of the contest, we can name 4 mile stone submissions. The validation
and public and private scores of these submissions are shown below.
Model Validation 1 Validation 2 Public Score Private Score
Naive
(averages)
0.736 0.734 0.754
Optimized with
Product Data
via NLTK
0.764 0.775 0.781
XGBoost with
default
parameters
0.476226 0.498475 0.46949 0.49596
XGBoost with
parameter
tuning
0.469628 0.489799 0.46257 0.48666
We can see from the results that we didn’t overfit data at any point.
For our final submission of predictions; we achieved a score of 0.48666; placing our
team in the top 17% of the 2000 contestants.
Looking over the scores of other participants, we’d like to say that for first time
participants of a Kaggle contest, our results were very promising.
Conclusion
We are extremely happy that we picked a Kaggle contest for our project. It allowed us
to work on a common real world problem while giving us a benchmark of our abilities in
the global arena.
We learned to leverage powerful cloud computing capabilities across various platforms
while also learning how to manipulate large data sets with memory and computing power
20

constraints; while also learning how to use XGBoost library for training and testing
purposes.
We also learned how to use important tools like command prompts to launch development
environments and Github for code sharing collaboration.
Critical Mistakes
Poor data exploration
We performed very little data exploration on our own. We mainly depended on the data
exploration that was done by other Kagglers. This resulted in sub-optimal solutions in
our training and testing as we did not exclude outliers etc.
Not preparing for system outages
We faced one outage while using the Google Cloud Preemptible Instance (possibly due to
high demand from other clients) which caused a key data file to become corrupted. The
re-creation of this data file cost us over 5 hours of work. In the future, it would be
preferable if the system was listening to “shut-down” signals that are sent by the
platforms and took necessary steps to prevent the corruption of this data.
Performing hyperparameter tuning too late
In our process we initially performed feature selection using a set of parameters for
XGBoost and then proceeded to hyperparameter tuning step. However, it became apparent
that some features were being given lower scores because our initial set of parameters
were not optimal for a high number of feature columns. Specifically, the depth of the
trees were set to 6 in our initial feature selection; when this was increased to 22, it
became apparent that the features that were originally dropped could have been good
predictors.
Further Exploration
If we had more time and resources, we would have liked to undertake additional actions.
Partial Fitting
When faced with the memory problem we decided to use cloud services. However, another
method would have been loading and processing the data in smaller batches. This would
be a more scalable model and could even be used to create a cluster of cloud machines
to perform operations in parallel.
Multiple Models
Although XGBoost is a very effective tool, it gives a single model (or in our case, 2
models one for each week). We would like to explore the possibility of creating a
larger number of models using different systems and seeing how they perform for
different slices of data. We would then take some sort of weighted average of these
predictions to reach our final prediction.
As an extension to this idea, we would also perform parameter tuning across these
various models to find optimal solutions for each one.
Neural Networks
We would also have like to approach this problem with a neural network solution to see
the accuracy of the predictions and also the performance of the neural network solution
vs the XGBoost tool.
21


















