
CUNY Graduate Centeruserhome.brooklyn.cuny.edu/cbenes/F13M83100LectureNotes.pdf · 2013. 12....
95
CUNY Graduate Center Math 83100 – Probability Lecture Notes Fall 2013 Christian Beneˇ s [email protected] http://userhome.brooklyn.cuny.edu/cbenes/index.html
Transcript of CUNY Graduate Centeruserhome.brooklyn.cuny.edu/cbenes/F13M83100LectureNotes.pdf · 2013. 12....
-
CUNY Graduate Center
Math 83100 – Probability
Lecture Notes
Fall 2013
Christian Beneš
http://userhome.brooklyn.cuny.edu/cbenes/index.html
-
Math 83100 (Fall 2013) September 9, 2013Prof. Christian Beneš
Lecture #1: Introduction; Probability Spaces; Random Variables;Distributions
Reference. Sections 1.1, 1.2, 1.3
1.1 Why probability?
You probably don’t need to be convinced that probability is present everywhere in yourdaily life (the weather, results of sports competitions, the lottery are just some commonexamples). Probability also plays a major role in many of the other fields of knowledge:
• Biology: Random mutations are one of the causes of evolution and much deep research(including by the author of our textbook) in probability is done with this applicationin mind.
• Chemistry: Polymers can be modeled by certain types of random walks (see Chapter3).
• Finance and economics: Many models exist for the behavior of stocks, but none isperfect, so many probabilists are still working on this problem.
• Physics: The last decade has seen many breakthroughs by probabilists in the field ofstatistical mechanics.
• Computer science: Markov chains are widely used (for instance in Monte Carlo algo-rithms)
• etc.
1.2 Notation
Ω will always denote the set of outcomes of an “experiment” and ω will denote an elementof Ω. An outcome A (A ⊂ Ω) of the experiment will occur with a certain probability P (A),where P is a function on Ω with 0 ≤ P (·) ≤ 1.The letters X, Y, Z will usually denote random variables (functions X : Ω→ E)E[X] will denote the expectation (mean) of a random variable X.
Note 1.1. The definitions above require some care. There will be some restrictions on Pwhich will impose restrictions on the sets A for which P (A) is defined. Not every functionX : Ω→ E will be a random variable nor will E[X] be defined for every random variable.
1–1
-
1.3 Some big questions in probability
One of the big basic questions in probability is the following:
If {Xi}i≥1 are independent, identically distributed random variables (i.i.d. r.v.’s) with same
mean µ = E[Xi], and for n ≥ 1, Sn :=n∑i−1
Xi, then what can be said about Sn?(One can
ask this question about the random variable Sn, or about the sequence of random variables{Sn}n≥1, an example of a stochastic process.)
• Law of large numbers:(1/n)Sn → µ
(What does it mean for a sequence r.v.’s like Yn = (1/n)Sn to converge to a constantµ or to a random variable Y ?)
• Central Limit Theorem: If {Xi}i≥1 are i.i.d. with mean µ and finite variance σ2 =E[(Xi − µ)2], then
Zn =Sn − nµσ√n→ Z,
where Z is the standard normal distribution. (What does it mean for a sequence ofr.v.’s like Zn to converge to a random variable Y ?)
• Law of the iterated logarithm: If {Xi}i≥1 are i.i.d. with mean µ and finite varianceσ2 = E[(Xi − µ)2], then
lim supn
(Sn − nµ)/√
2σ2n log log n = 1
andlim inf
n(Sn − nµ)/
√2σ2n log log n = −1
(What is the “lim sup” of a sequence of random variables?)
1.4 Motivation for measure-theoretic approach
We would like a probability P to be a measure on a set F of subsets of Ω: For appropriatesets A, Ai, i ≥ 1, if we know P (A) and P (Ai), i ≥ 1, we should also be able to compute:
1. P (Ac)
2. P (∪∞n=1Ai).
Therefore, if A,Ai ∈ F , we will need to automatically have Ac,∪∞n=1Ai ∈ F .
1–2
-
1.5 Basic Definitions
Definition 1.1. A collection of subsets F of a set Ω is an algebra if
1. It is nonempty
2. If A ∈ F , then Ac ∈ F
3. If A1, A2, . . . , An ∈ F , then ∪ni=1Ai ∈ F .
In other words, n algebra is a nonempty collection of subsets, closed under complementationand finite unions.
A collection of subsets F of a set Ω is a σ − algebra if
1. It is nonempty
2. If A ∈ F , then Ac ∈ F
3. If A1, A2, . . . ,∈ F , then ∪∞i=1Ai ∈ F .
In other words, a sigma-algebra is a nonempty collection of subsets, closed under comple-mentation and countable unions.
Note 1.2. Since (∩∞i=1Ai)c = ∪∞i=1Aci , a sigma-algebra is also closed under countable inter-
sections. Also, since F is nonempty, Ω = A ∪ Ac ∈ F and ∅ = A ∩ Ac ∈ F .
Example 1.1. {∅,Ω} is a σ-algebra and so is the power set (the set of all subsets) 2Ω ofΩ. These are the smallest and largest σ-algebras of Ω. If A ⊂ Ω, then {∅, A,Ac,Ω} is aσ-algebra.
Note 1.3. A σ-algebra is clearly an algebra. However, the converse is not true: If Ω = Rand A is the collection of sets of the form
∪ki=1(ai, bi],−∞ ≤ ai < bi ≤ ∞, k
-
1. µ(∅) = 0
2. If {Ai}i≥1 is a countable collection of disjoint sets, µ (∪∞n=1Ai) =∞∑i=1
µ(Ai).
If µ(Ω) = 1, we write P for µ and call it a probability measure.
Note 1.4. It follows from 2. that P (Ac) = 1− P (A).
Definition 1.5. (Ω,F , P ) is called a probability space.
Example 1.2. (Finite probability space) Suppose Ω = {ω1, . . . , ωn}. Then we can always
define a probability measure on (Ω, 2Ω) by defining P ({ωi}) = pi withn∑i=1
pi = 1. Note that
this is a particular case of Example 1.1 in Durrett.
Theorem 1.1. A probability measure P on (Ω,F) satisfies the following properties: mono-tonicity, subadditivity, continuity from below and above.
Proof. This is a particular case of Theorem 1.1.1, the proof of which you should make sureyou read.
1.6 Random Variables, Distributions, and densities
Definition 1.6. Given two measurable spaces (Ω,F) and (S,S), X : Ω→ S is a measurablemap from (Ω,F) to (S,S) if
X−1(B) = {ω : X(ω) ∈ B} ∈ F ∀B ∈ S.
In particular, if X : (Ω,F) → (Rd,Rd) is measurable, X is called a random variable (ifd = 1) or a random vector (if d > 1).
Note 1.5. Every random variable X on a probability space (Ω,A, P ) induces a probabilitymeasure on R which is denoted PX and called the law (or distribution) of X. It is definedfor every B ∈ R by
PX(B) := P{ω ∈ Ω : X(ω) ∈ B} = P{X ∈ B} = P{X−1(B)}.
In other words, the random variable X transforms the probability space (Ω,A, P ) into theprobability space (R,R, PX):
(Ω,A, P ) X−→ (R,R, PX).
Definition 1.7. A function F : R→ R is called a distribution function if the following hold:
1. If x ≤ y, then F (x) ≤ F (y).
1–4
-
2. limx→−∞
F (x) = 0 and limx→∞
F (x) = 1
3. limy→x+
F (y) = F (x). In other words, F is right-continuous.
Theorem 1.2. If X is a random variable, then F (x) = FX(x) := P (X ≤ x) is a distributionfunction. It is called the distribution function of X.
Proof. The proof follows almost directly from Theorem 1.1
Thinking about the distribution function of a random variable X gives us another (moregraphical) way of thinking about the distribution of X.
Theorem 1.3. A distribution function F is the distribution function of some random vari-able X.
Proof. The key idea is to define X on ((0, 1),R(0, 1),L) by setting, for ω ∈ (0, 1), X(ω) =sup{y : F (y) < ω}. See Theorem 1.2.2 of Durrett.
Note 1.6. In addition to properties 1-3 above, the distribution function of a random variableX also satisfies the following:
4. limy→x−
F (y) = P (X < x).
5. P (X = x) = F (x)− F (x−).
Theorem 1.4. If F is a distribution function, there exists a unique probability measure Pon (R,R) such that
P ((a, b]) = F (b)− F (a)
for all −∞ ≤ a < b
-
The next theorem (Theorem A.1.3 in Durrett) is important, but technical, so in order tomove forward, I’ll let you work through it on your own.
Theorem 1.5. (Caratheodory’s Extension Theorem) Given an algebra A of subsets of Ω,consider B = σ(A), the smallest σ-algebra containingA and µ0, a countably additive measureon (Ω,A). Then there exists a unique measure µ on (Ω, σ(A)) such that µ(A) = µ0(A) forA ∈ A.
Proof of Theorem 1.4: Note that this is a somewhat different proof from Durrett’s proof.
Define A to be the algebra formed by subsets of R of the form
A = ∪nk=1(ak, bk], −∞ ≤ ak < bk
-
If there is no N such that An ⊂ [−N,N ] for all n ≥ 1, fix � > 0 and choose N such thatP0[−N,N ] > 1− �/2. Then repeat the procedure above with An ∩ [−N,N ].
�
Note 1.7. Given a probability measure P on (R,R), we can define a distribution functionby
F (x) = P ((−∞, x]).
We therefore have a one-to-one correspondence between:
• probability measures on (R,R)
• distribution functions
• random variables
1–7
-
Math 83100 (Fall 2013) September 16, 2013Prof. Christian Beneš
Lecture #2: Distributions
Reference. Sections 1.3 - 1.6
Definition 2.1. If two random variables X and Y induce the same probability measure
PX = P Y on (R,R), we say that X and Y are equal in distribution and write X d= Y .
There are essentially 3 types of probability measures:
1. Discrete measures: There exists a set of real numbers {xk}k≥1 such that
P (xk) := P ({xk}) > 0 and∑k≥1
P (xk) = 1.
2. Absolutely continuous measures: These are measures for which the corresponding dis-tribution functions can be written as
F (x) =
∫ x−∞
f(y) dy,
with some nonnegative function f , called the density of the distribution function F .
3. Singular measures: These are measures for which the corresponding distribution func-tions are continuous, but have all their points of increase on a set of Lebesgue measure0.
Theorem 2.1. (Lebesgue decomposition) Every distribution F can be written
F = c1F1 + c2F2 + c3F3,
where c1, c2, c3 ≥ 0, c1 + c2 + c3 = 1 and F1 is discrete, F2 absolutely continuous, and F3singular.
Example 2.1. 1. The pointmass at x0:
F (x) = 1 for x ≥ x0, F (x) = 0 for x < x0
is a discrete distribution.
2. The uniform distribution on the Cantor set (see Durrett, p. 11) is singular.
3. The Uniform distribution:
f(x) =1
b− a, a ≤ x ≤ b, a, b ∈ R.
2–1
-
4. The Gamma distribution:
f(x) =xα−1e−x/β
Γ(α)βα, x ≥ 0, α, β > 0.
If α = 1, this is the Exponential distribution.
5. The Cauchy distribution:
f(x) =θ
π(x2 + θ2), x ∈ R, θ > 0.
This is an example of a heavy-tailed distribution (its associated random variable X hasno mean (see definition of E[X] below)).
6. The normal distribution:
f(x) = (2πσ2)−1/2e−(x−µ)2/2σ2 .
The change of variables y = x−µσ
transforms any normal density into the standardnormal density, i.e., the density of a normal with mean 0, variance 1, usually calledφ(x).
One often comes across Φ(x) =∫ x−∞ φ(x) dx, the normal distribution function. Unfortu-
nately, there is no closed-form expression for it, so the following estimate is often useful(note that 1− Φ(x) = P (X > x)):
Lemma 2.1. If x > 0, then
(x+ x−1)−1φ(x) ≤ 1− Φ(x) ≤ x−1φ(x).
Proof. Let x > 0. Since φ′(y) = −yφ(y), we have
φ(x) =
∫ ∞x
yφ(y) dy ≥ x∫ ∞x
φ(y) dy = x(1− Φ(x)).
Also, since (y−1φ(y))′ = −(1 + y−2)φ(y),
x−1φ(x) =
∫ ∞x
(1 + y−2)φ(y) dy ≤ (1 + x−2)∫ ∞x
φ(y) dy = (1 + x−2)(1− Φ(x)).
Note 2.1. It’s worth comparing this estimate with Durrett’s, which is slightly different.
2–2
-
2.1 Random Variables
Recall that a random variable is a measurable (or F -measurable) function X : (Ω,F) →(R,R). Measurability is key in allowing us to integrate a random variable and this require-ment means that not just any random function is a random variable.
Example 2.2. If A ∈ Ω is measurable, then
1A(ω) :=
{1, ω ∈ A0, ω 6∈ A
is a r.v.
Given 2 measurable spaces (Ω,F) and (S,S), it isn’t always straightforward to check if afunction
X : (Ω,F)→ (S,S)is measurable, i.e., to check if
X−1(B) ∈ F for every B ∈ S.
The following lemma and its corollary somewhat simplify this task.
Lemma 2.2. Let A be a family of sets such that σ(A) = S. Then X : Ω→ S is measurableiff
X−1(B) ∈ Ffor all B ∈ A.
Proof. Necessity is obvious: If B ∈ A, then B ∈ S, so X−1(B) ∈ F for all B ∈ S impliesX−1(B) ∈ F for all B ∈ A.To show sufficiency, define B = {B ∈ S : X−1(B) ∈ F}. (We will show that B = S.)Then if {Bi}i≥1 ∈ B (implying that for any i,X−1(Bi) ∈ F), we can use the fact that
X−1 (∪i≥1Bi) = ∪i≥1X−1(Bi) and X−1(Bc1) = (X−1(B1))c, (1)
to see that
• X−1 (∪i≥1Bi) = ∪i≥1X−1(Bi) ∈ F ⇒ ∪i≥1Bi ∈ B
• X−1(Bc1) = X−1(B1)c ∈ F ⇒ Bc1 ∈ B,
so B is a σ-algebra.Therefore,
A ⊂ B ⊂ S,implying
S = σ(A) ⊂ σ(B) = B ⊂ σ(S) = S,so that S = B. Since we assumed X−1(B) ∈ F for all B ∈ B, we now have X−1(B) ∈ F forall B ∈ S, so X is measurable.
2–3
-
Corollary 2.1. X : (Ω,F) → (R,R) is a random variable iff {ω : X(ω) ≤ x} ∈ F for allx ∈ R.
Proof. The sets {(−∞, x] : x ∈ R} generate the Borel sets.
Note 2.2. In Corollary 2.1, on can replace ≤ x by < x, > x, ≥ x.
Lemma 2.3. If X : (Ω,F)→ (S,S), then
A = {X−1(B) : B ∈ S}
is a σ-algebra. It is called the σ-algebra generated by X.
Proof. Suppose {Ai}i≥1 ∈ A. Then there exist {Bi}i≥1 ∈ S with Ai = X−1(Bi).By (1) above, the fact that ∪i≥1Bi ∈ S implies
∪ni=1Ai = ∪i≥1X−1(Bi) = X−1 (∪i≥1Bi) ∈ A
and the fact that Bc1 ∈ S implies that
Ac1 = (X−1(B1))
c = X−1(Bc1) ∈ A.
The next lemma is the general case of the fact that a Borel function (i.e., a Borel-measurablefunction) of a random variable is a random variable:
Lemma 2.4. Let X : (Ω,F) → (S,S) and f : (S,S) → (T, T ) be measurable. ThenY = f ◦X : (Ω,F)→ (T, T ) is measurable.
Proof. If Y (ω) = f(X(ω)), then for B ∈ T , we have
{ω : Y (ω) ∈ B} = {ω : X(ω) ∈ f−1(B)} ∈ F ,
since f−1(B) ∈ S.
We will now use the lemmas above to construct new random variables from collections ofrandom variables.
Theorem 2.2. If X1, . . . , Xn are random variables and f : (Rn,Rn)→ (R,R) is measurable,
then f(X1, . . . , Xn) is a random variable.
Proof. By Lemma 2.4, all we need to do is show that (X1, . . . , Xn) : (Ω,F) → (Rn,Rn)is measurable, that is, that (X1, . . . , Xn) is a random vector. Since n-dimensional Borelsare generated by n-fold products of one-dimensional Borels, Lemma 2.2 implies that we justneed to check that (X1, . . . , Xn)
−1(A1, . . . , An) ∈ F if A1, . . . , An ∈ R:
{(X1, . . . , Xn) ∈ (A1, . . . , An)} = ∩ni=1{Xi ∈ Ai} ∈ F .
2–4
-
Definition 2.2. The random variable lim supnXn is defined for every ω ∈ Ω by
lim supn
Xn(ω) = infn
supm≥n
Xm(ω).
Similarly,lim inf
nXn = sup
ninfm≥n
Xm
Corollary 2.2. Suppose X1, X2, . . . are random variables. Then the following are randomvariables as well:
1. f(X1), where f : R→ R is continuous.
2.n∑i=1
Xi
3. supnXn, infnXn
4. lim supnXn, lim infnXn
Proof. 1. This follows from Lemma 2.4, since continuous functions are measurable.
2. By Theorem 2.2, we just need to check that f(x1, . . . , xn) =n∑i=1
xi is measurable and
by Lemma 2.2 it’s enough to show that f−1(−∞, a) ∈ Rn, since intervals of the form
(−∞, a) generate the Borels. But since f−1(−∞, a) = {(x1, . . . , xn) :n∑i=1
xi < a is an
open set, it of course is a Borel set too.
3. This follows directly from
{ω : supXn(ω) > x} = ∪n{ω : Xn(ω) > x} ∈ F
and the fact thatinf Xn = − sup(−Xn).
4. This follows directly from the definitions
lim supn
Xn = infn
supm≥n
Xm,
lim infn
Xn = supn
infm≥n
Xm
and from part 3.
2–5
-
Definition 2.3. If for n ∈ N, Xn : (Ω,F)→ (R,R) is a r.v., then
Ω0 := {ω : limn→∞
Xn(ω) exists } = {ω : lim supn
Xn(ω)− lim infn
Xn(ω) = 0}
is measurable. If P (Ω0) = 1, Xn converges almost surely. Since limnXn may not be definedfor all ω, we let X∞ := lim supnXn and write
Xna.s.→ X∞.
2.2 Expectation
Definition 2.4. Let X be a random variable and let X+ := max{X, 0}, X− := −min{X, 0}.If E[X+] =
∫X+ dP < ∞ and E[X−] =
∫X− dP < ∞, we say that the expectation of X
exists. In that case, the expectation is
E[X] := E[X+]− E[X−].
Note 2.3. Being an integral, expectation is linear.
2.2.1 Inequalities
Proposition 2.1. (Markov/Chebyshev’s Inequality) Let X ≥ 0 be a random variable. Then
P (X ≥ �) ≤ E[X]�
.
Proof.
E[X] ≥ E[X · 1X−1[�,∞)] ≥ �E[1X≥�] = �∫X≥�
dP = �P (X ≥ �).
Note 2.4. There is no absolute consensus about whether to call the inequality aboveMarkov’s or Chebyshev’s. I will always refer to it as Markov’s inequality.
Although you have certainly seen the following definition before, I’ll state it here for self-containment of the notes (or at least of its probabilistic material).
Definition 2.5. If X is a random variable, its variance is defined to be (when it exists)
V ar(X) = E[(X − E[X])2](= E[X2]− E[X]2).
Proposition 2.2. (Chebyshev’s inequality) For any random variable X,
P (|X − E[X]| ≥ �) ≤ V ar(X)�2
.
Proof. By Markov’s inequality,
P (|X − E[X]| ≥ �) = P ((X − E[X])2 ≥ �2) ≤ E[(X − E[X])2]
�2=V ar(X)
�2.
2–6
-
2.3 Jensen’s Inequality
Definition 2.6. A function φ : R→ R is called convex if for x, y ∈ R, 0 ≤ p ≤ 1,
φ(px+ (1− p)y) ≤ pφ(x) + (1− p)φ(y).
Theorem 2.3 (Jensen’s inequality). Suppose φ : R→ R is convex. Suppose X is a randomvariable satisfying E[|X|] 0, limN→∞
P
(∞⋃n=N
{|Xn −X| ≥ �}
)= 0.
This implies that limN→∞ P (|XN −X| ≥ �) = 0.
2–7
-
We now turn to a number of results that tell us under what conditions, Xn → X (in somesense) implies E[Xn]→ E[X].
Theorem 2.5. (Bounded Convergence) Suppose {Xn}n≥1 and X are random variables suchthat Xn
P→ X and for some K > 0, |Xn| ≤ K for all n. Then
E[|Xn −X|]n→∞→ 0,
implyingE[Xn]
n→∞→ E[X].
Proof. First observe that P (|X| ≤ K) = 1. Indeed, for all k ∈ N,
P (|X| > K + 1k
) ≤ P (|X −Xn| >1
k∀n) = 0.
Therefore,
P (|X| > K) = P (∪k{|X| > K +1
k}) = 0,
by subadditivity. Now one of two things can happen: Either |Xn−X| is small, or it is large(remember it can’t exceed 2K), but with probability decaying to 0. Formally, fix � > 0 andchoose N so that for all n ≥ N,
P (|Xn −X| > �/3) <�
3K.
Then, for n ≥ N ,
E[|Xn −X|] = E[|Xn −X|1{|Xn−X|>�/3}] + E[|Xn −X|1{|Xn−X|≤�/3}]≤ 2KP (|Xn −X| > �/3) + �/3 ≤ �.
We give the following result without a proof.
Theorem 2.6. (Fatou’s Lemma) Suppose {Xn}n≥1 are random variables satisfying Xn ≥ 0for every n. Then
E[lim infn→∞
Xn] ≤ lim infn→∞
E[Xn].
Theorem 2.7. (Reverse Fatou’s Lemma) If {Xn}n≥1, X satisfy Xn ≤ X, ∀n, E[X] < ∞,then
E[lim supXn] ≥ lim supE[Xn].
Proof. It follows from Fatou’s Lemma that E[lim inf(X−Xn) ≤ lim inf E[Xn−X]. Therefore,
E[X]− E[lim inf(−Xn)] ≤ E[X]− lim inf E[−Xn],
implying thatE[lim inf(−Xn)] ≥ lim inf E[−Xn].
The theorem now follows from the fact that lim inf(−An) = lim supAn.
2–8
-
Theorem 2.8. (Monotone Convergence) Suppose {Xn}n≥1 and X are random variablessuch that E[Xn] < ∞ ∀n,E[X] < ∞, Xn
a.s→ X, and for all n ≥ 1, 0 ≤ Xn ≤ Xn+1. ThenE[Xn]→ E[X].
Proof. Since Xn ≤ X for every n, E[Xn] ≤ E[X] for every n. Moreover, {E[Xn]}n≥1 formsa bounded monotonic sequence, which must converge. Therefore,
limn→∞
E[Xn] ≤ E[X].
Since X = limn→∞Xn, Fatou’s Lemma gives
E[X] = E[lim infn→∞
Xn] ≤ lim infn→∞
E[Xn] = limn→∞
E[Xn].
The 2 inequalities prove the theorem.
Why is the requirement that we have an increasing or a bounded sequence necessary? Thefollowing example shows that in general, the fact that Xn
a.s→ X doesn’t necessarily implythat E[Xn] → E[X]. It is also an example showing that we may have a strict inequality inFatou’s Lemma.
Example 2.4. Consider the probability space ([0, 1],R[0, 1],L[0, 1]), where L[0, 1] denotesLebesgue measure. Then if we define
Xn(ω) =
{n, 0 ≤ ω ≤ 1/n0, otherwise
,
Xna.s→ X, but 1 = E[Xn] 6→ E[X] = 0.
The Bounded Convergence Theorem above is a particular case of the Dominated ConvergenceTheorem:
Theorem 2.9. (Dominated Convergence) Suppose {Xn}n≥1, X, and Y are random variablessuch that Xn
a.s.→ X, |Xn| ≤ Y for all n and E[Y ] < ∞. Then E[|Xn − X|] → 0, implyingE[Xn]→ E[X].
Proof. |Xn −X| ≤ 2Y , so by the Reverse Fatou’s Lemma,
0 = E[lim sup |Xn −X|] ≥ lim supE[|Xn −X|],
so E[|Xn −X|]→ 0. The second part follows from Jensen’s inequality.
2–9
-
Math 83100 (Fall 2013) September 23, 2013Prof. Christian Beneš
Lecture #3: Lp spaces
Reference. Section 1.6; see also David Williams’ “Probability With Martingales”, an ex-cellent book which should be on reserve at the library
3.1 Lp Spaces
Definition 3.1. If X : Ω→ R is a random variable, we define for all p ∈ [1,∞),
‖X‖p := (E[|X|p])1/p ,
provided that the expectation exists.
‖X‖∞ = inf{M ∈ R : P (|X| > M) = 0}.
The space Lp = Lp(Ω,F , P ) is the space of all random variables X : Ω → R such that‖X‖p
-
3.2 Two Important Inequalities
Lemma 3.1. If X ≥ 0 is a random variable satisfying E[X] = 0, then X = 0, almost surely.
Proof. Define A = {ω : X(ω) > 0} and An = {ω : X(ω) ≥ 1/n}. Clearly, An ↑ A and
0 ≤ X1An ≤ X1A ≤ X,
so0 ≤ E[X1An ] ≤ E[X1A] ≤ E[X] = 0.
Therefore (since X ≥ 1/n over An),
1
nP (An) ≤ E[X1An ] = 0,
so P (An) = 0. But since An ↑ A,P (An)→ P (A). Therefore, P (A) = 0.
Theorem 3.1. (Hölder’s inequality) Suppose p ∈ [1,∞], 1/q = 1−1/p and X ∈ Lp, Y ∈ Lq.Then XY ∈ L1 and
E[|XY |] ≤ ‖X‖p‖Y ‖q.
Proof. The case p = 1 is left as an easy homework exercise. Assume 1 < p < ∞. Sincefor a ≥ 1, |X|a is a random variable when X is, Lemma 3.1 implies that |XY | = 0 a.s. if‖X‖p = 0 or ‖Y ‖q = 0, so the theorem is true in that case. Suppose now that ‖X‖p > 0and ‖Y ‖q > 0 and define the normalized r.v.’s
X̃ =X
‖X‖pand Ỹ =
Y
‖Y ‖q.
Since φ(x) = ln x is concave, we have, for x, y > 0,
ln(x1/py1/q) =1
plnx+
1
qln y ≤ ln(x/p+ y/q),
which, since φ is increasing, implies
x1/py1/q ≤ x/p+ y/q.
Therefore, it follows from monotonicity of expectations that
E[|X̃Ỹ |
]= E
[(|X̃|p)1/p(|Ỹ |q)1/q
]≤ E
[1
p|X̃|p + 1
q|Ỹ |q
]=
1
p+
1
q= 1.
3–2
-
Note 3.1. If p = q(= 12), Hölder’s inequality is known as the Cauchy-Bunyakovski-Schwarz
inequality: If X, Y ∈ L2,E[|XY |]2 ≤ E[X2]E[Y 2],
or equivalently, as we’ll see later,
〈X, Y 〉 ≤ ‖X‖2‖Y ‖2,
where 〈·, ·〉 denotes inner product.
Theorem 3.2. (Minkowski’s inequality) If p ∈ [1,∞] and X, Y ∈ Lp, then
‖X + Y ‖p ≤ ‖X‖p + ‖Y ‖p.
Proof. The proof is straightforward if p = 1 and p = ∞, so suppose 1 < p < ∞. Note that‖|X + Y |p−1‖q is well-defined, since (|X + Y |p−1)q = (|X + Y |p−1)
pp−1 = |X + Y |p.
The vector space property of Lp and Hölder’s inequality give
E[|X + Y |p] ≤ (E[|X||X + Y |p−1] + E[|Y ||X + Y |p−1])≤ (‖X‖p + ‖Y ‖p)‖|X + Y |p−1‖q = (‖X‖p + ‖Y ‖p)E[|X + Y |p]1/q,
so E[|X + Y |p]1−1/q ≤ ‖X‖p + ‖Y ‖p, implying that
E[|X + Y |p]1/p ≤ ‖X‖p + ‖Y ‖p.
3.3 More on Lp spaces
Definition 3.2. For 0 < p �) = P (|Xn −X|p > �p) ≤E[|Xn −X|p]
�p→ 0.
In all that follows, p ∈ [1,∞).We now know that Lp is a vector space and Minkowski’s inequality tells us it is equippedwith a semi-norm ‖ · ‖p. If it were a norm under which the space is complete, we’d have aBanach space. So we need to check that ‖X‖p = 0 ⇐⇒ X = 0. Unfortunately, it is easy to
3–3
-
construct nonzero random variables X such that ‖X‖p = 0. However, it is true (see Lemma3.1) that
‖X‖p = 0 ⇐⇒ X = 0 a.s.We can therefore define for every X ∈ Lp an equivalence class [X] by saying X ∼ Y ifX = Y a.s. If we define [Lp] to be the collection of equivalence classes [X] for X ∈ Lp, andimmediately revert to the previous notation, Lp is a normed vector space.
Now to completeness:
Definition 3.3. A sequence of random variables {Xn} ∈ Lp is a Cauchy sequence in Lp if
sups,t≥n‖Xs −Xt‖p → 0 as n→∞.
Theorem 3.3. For every Cauchy sequence {Xn} ∈ Lp, there exists a random variableX ∈ Lp such that
XnLp→ X.
Proof. Consider an increasing sequence {nk}k≥1 in N such that if sk, tk ≥ nk, ‖Xsk−Xtk‖p <2−k. Then by monotonicity of Lp norms,
E[|Xsk −Xtk |] = ‖Xsk −Xtk‖1 ≤ ‖Xsk −Xtk‖p < 2−k,
which implies that
E[∑k≥1
|Xsk −Xtk |]
-
3.4 L2 is a Hilbert space
The case p = 2 is particularly important, since Hölder’s inequality tells us we can constructan inner product on the space as follows:
Proposition 3.6. Suppose X, Y ∈ L2. Then
〈X, Y 〉 := E[XY ]
is an inner product on L2.
Proof. If X, Y, U ∈ L2, the proposition follows from the fact that for a, b ∈ R,
• 〈aX + bY, U〉 = a〈X,U〉+ b〈Y, U〉
• 〈X,X〉 ≥ 0
• 〈X,X〉 = 0 ⇐⇒ X = 0 (this holds by Lemma 3.1)
Definition 3.4. If X, Y ∈ L2, we define
Cov(X, Y ) := 〈X − E[X], Y − E[Y ]〉
andV ar(X) := Cov(X,X) = ‖X − E[X]‖22.
The angle θ between X and Y is defined by
cos θ =〈X, Y 〉‖X‖2‖Y ‖2
.
(Note that | cos θ| ≤ 1 by C-S-B.) The correlation between X and Y is
ρ(X, Y ) =Cov(X, Y )√
V ar(X)√V ar(Y )
.
If 〈X, Y 〉 = 0, we say X and Y are orthogonal.
Proposition 3.7. If Cov(X, Y ) = 0, then V ar(X + Y ) = V ar(X) + V ar(Y ).
Proof.
V ar(X + Y ) = 〈X + Y − (E[X] + E[Y ]), X + Y − (E[X] + E[Y ])〉= 〈X − E[X], X − E[X]〉+ 〈Y − E[Y ], Y − E[Y ]〉 − 2〈X − E[X], Y − E[Y ]〉= 〈X − E[X], X − E[X]〉+ 〈Y − E[Y ], Y − E[Y ]〉 = V ar(X) + V ar(Y )
3–5
-
3.5 Computing Expectations
Theorem 3.4. (Change of variables formula) Let X : (Ω,F) → (S,S) be a measurablefunction (with distribution PX defined by the relation PX(A) = P (X ∈ A)). If f : (S,S)→(R,R) is measurable and f ∈ L1(S,S, PX), then
E[f(X)] =
∫S
f(y)PX(dy).
Proof. By definition, the result is true for indicator functions. Linearity implies it’s truefor simple functions. The monotone convergence theorem implies it holds for nonnegativefunctions and linearity again shows it holds for integrable functions.
Definition 3.5. E[Xk] is called the kth moment of X.
Definition 3.6. The moment generating function of a random variable X is
MX(t) = E[eXt] =
∫R
extPX(dx) =
∫R
extdF (x).
Note 3.2. This is defined for every t, since eXt is a positive random variable. However, itmay be infinite.
Regardless of X, MX(t) is finite at t = 0, where its value is 1. However, as the followingexample shows, this may be the only point at which MX(t) is finite.
Example 3.1. Suppose PX{n} = PX{−n} = Cn2, n ∈ N. Then∫
R
extPX(dx) =∑n≥1
etnC
n2+∑n≥1
e−tnC
n2.
If t > 0, the first sum is infinite, while if t < 0, the second is. So MX(t) 0. Then
E[Xn] = M(n)X (0).
Proof. Suppose MX(t) is finite on (−t0, t0), t0 > 0 and choose t ∈ (−t0, t0). Then e|xt| ≤ext + e−xt, so since by assumption ext + e−xt is PX-integrable,
∫Re|xt|PX(dx) < ∞, so∫
R
∑k≥0
|xt|k
k!PX(dx) is defined. The dominated convergence theorem allows us to interchange
the integral and sum, so
MX(t) =∑k≥0
tk
k!
∫R
xkPX(dx) =∑k≥1
tk
k!E[Xk].
By uniqueness of Taylor expansions,
E[Xk] = M(k)X (0).
3–6
-
Example 3.2. Let Z have the standard normal distribution with density φ(x) = 1√2πe−x
2/2.Then the moment generating function of Z can be found as follows:
MZ(t) = E[etZ] =
1√2π
∫R
e−x2−2tx
2 dx =1√2π
∫R
e−(x−t)2−t2
2 dx = et2/2.
This allows us to find all even moments of Z (the odd moments are all obviously 0):
E[Z2n] = M2nZ (0) =n∏k=1
(2k − 1) = (2n)!2nn!
.
3–7
-
Math 83100 (Fall 2013) September 30, 2013Prof. Christian Beneš
Lecture #4: Independence; Laws of Large Numbers
Reference. Section 1.3
4.1 Independence
As is often the case with concepts that have definitions both in English and Mathematics,it’s easy to mis-interpret the meaning of independence in the context of probability. Here’swhat it means in probability:
Definition 4.1. If A,B ∈ F and P (A) 6= 0, we define the conditional probability of B givenA by
P (B|A) = P (AB)P (A)
.
We say that A and B are independent if
P (AB) = P (A)P (B).
Note 4.1. Our definitions mean that if A and B are independent,
P (B|A) = P (B).
In other words, the occurrence of A has no influence on the probability of B. This is tobe contrasted with the statement “the occurrence of A has no influence on the occurrenceof B”, which is how one generally thinks of independence and does not correspond to theprobabilistic meaning of the word. For example, in the experiment of the toss of two dice,the events A = {the outcome of the first die is 3} and B = {the sum of the outcomes of thedice is 7} are independent, which can be counterintuitive if one thinks of independence innon-probabilistic terms.
Definition 4.2. A collection of events {Eα}α∈I ⊂ F is independent if for all {ij}1≤j≤n ∈ I,
P (n⋂j=1
Eij) =n∏j=1
P (Eij).
A collection of random variables {Xα}α∈I is independent if for all {ij}1≤j≤n ∈ I, {Bij}1≤j≤n ∈R,
P (n⋂j=1
X−1ij (Bij)) =n∏j=1
P (X−1ij (Bij)).
A collection of classes of events {Cα}α∈I ⊂ F is independent if for all {ij}1≤j≤n ∈ I, Cij ∈ Cij ,
P (n⋂j=1
Cij) =n∏j=1
P (Cij).
Pairwise independence in a collection of events, r.v.’s, or sigma-algebras refers to indepen-dence between any two elements of the collection.
4–1
-
Note 4.2. Pairwise independence doesn’t necessarily imply independence. See Example2.1.1 in Durrett.
Definition 4.3. A collection P of sets is a π-system if whenever A,B ∈ P , we also haveA ∩B ∈ P .A collection L of sets is a λ-system if
1. Ω ∈ L,
2. If A,B ∈ L and A ⊂ B, then B \ A ∈ L,
3. If An ∈ L and An ↑ A, then A ∈ L.
Theorem 4.1. (Dynkin’s π − λ theorem) If P is a π-system, L is a λ-system, and P ⊂ L,then
σ(P) ⊂ L.
Theorem 4.2. Suppose classes of π-systems {Pα}α∈I ⊂ F are independent. Then {σ(Pα)}α∈Iare independent too.
Proof. See Durrett, p. 39.
Corollary 4.1. If for all x1, . . . , xn ∈ (−∞,∞],
P (X1 ≤ x1, . . . , Xn ≤ xn) =n∏i=1
P (Xi ≤ xi),
then X1, . . . , Xn are independent.
Proof. Let Ai be the family of sets of the form {X−1i (−∞, x]}, which is a π-system, sinceX−1i (−∞, x] ∩ X−1i (−∞, y] = X−1i (−∞, x ∧ y]. Since the sets (−∞, x] generate R, the Aigenerate σ(Xi) (see Exercise 1.3.1), so σ(Ai) = σ(Xi). So if we assume that the Ai areindependent, by Theorem 4.2, so are the σ(Xi) and thus, by definition of independence ofrandom variables, so are the Xi.
4.2 Product Spaces
Definition 4.4. Suppose (Ωi,Fi, Pi) are probability spaces. Then
Ω := Ω1 × · · · × Ωn = {(ω1, . . . , ωn) : ω1 ∈ Ω1, . . . , ωn ∈ Ωn},
F := F1 × · · · × Fnis the sigma-algebra generated by the collection of rectangles {A1 × · · · × An : A1 ∈F1, . . . , An ∈ Fn}.
4–2
-
Theorem 4.3. Given probability spaces (Ωi,Fi, Pi), there is a unique probability measure
P = P1 × · · · × Pn
on (Ω,F) such that if Ai ∈ Fi, 1 ≤ i ≤ n, then
P1 × · · · × Pn(A1 × · · · × An) = P1(A1) · · ·Pn(An).
Proof. See proof of Theorem 1.7.1 in Durrett
This probability measure is a particularly important one (one of many, of course) on (Ω,F)since, as we will now see, it generates the joint measure of an n-tuple of independent randomvariables.
Of course, in order for the notion of independence to make sense, we need the randomvariables to live on the same space. On the other hand, two given random variables don’tneed a priori to live on the same probability space (think, for instance, of X1 as recording thevalue of a 6-sided die and X2 as counting the number of heads in a flip (independent of thedie throw) of a coin. Therefore, we may need to embed our probability spaces into a largerone (and thus use projections when we only care about a subset of the random variables).
Now in order to be able to talk about the independence of the Xi, we need to put them ona same space. We do this by embedding them in Ω: We define X̃i : (Ω,F , P )→ (R,R, PXi)by
X̃i(ω1, . . . , ωn) = Xi(ωi).
Note, in particular that if Bi ∈ R and X−1i (Bi) = Ai, then X̃−1i (Bi) = Ω1 × . . .Ωi−1 × Ai ×Ωi+1 × . . .× Ωn.Since Xi and X̃i coincide on Ωi and are thus essentially the same, we drop the ˜ and revert towriting Xi, being aware that it is now defined on Ω, not just Ωi (though for ease of notationwe will use Xi both for the original r.v. and its embedded version in everything that follows).
Let (Ω,F , P ) be as above and define (X1, . . . , Xn) : (Ω,F , P )→ (Rn,Rn, P (X1,...,Xn)) by
(X1, . . . , Xn)(ω1, . . . , ωn) = (X1(ω1), . . . , Xn(ωn)).
(Note that on the right of this last equality, Xi has its original meaning.) Then it is easy tocheck that (X1, . . . , Xn) is a random vector, i.e. a measurable function.
Theorem 4.4. Suppose {Xi}1≤i≤n are independent random variables and that Xi hasdistribution PXi . Then (X1, . . . , Xn) : (Ω,F , P ) → (Rn,Rn, P (X1,...,Xn)) has distributionPX1 × · · · × PXn . That is,
P (X1,...,Xn) = PX1 × · · · × PXn .
Before proving this theorem, we state a consequence of the π−λ theorem without proof (forthe proof see Theorem A.1.5 in Durrett):
Theorem 4.5. Suppose P is a π-system and P1, P2 are probability measures that agree onP . Then P1 and P2 agree on σ(P).
4–3
-
Proof of Theorem 7.2 We show that P (X1,...,Xn) and PX1 × · · · × PXn agree on the π-systemof sets of the form A1 × . . .× An, where the Ai are Borel sets. Using Theorem 4.5, we thenare done.
P (X1,...,Xn)(A1× . . .×An) = P ((X1, . . . , Xn) ∈ (A1× . . .×An)) = P (X1 ∈ A1, . . . , Xn ∈ An).
Using independence, the definition of PXi and PX1 × · · · × PXn , we see that this last termis equal to
n∏i=1
P (Xi ∈ Ai) =n∏i=1
PXi(Ai) = PX1 × · · · × PXn(A1 × . . .× An).
�
4.3 Convolution
Definition 4.5. The convolution of two distribution functions F and G is
F ∗G(z) =∫F (z − y)dG(y),
where dG(y) is the measure P Y associated with the distribution function G.
Theorem 4.6. If X and Y have distribution functions F and G, respectively, then
P (X + Y ≤ z) = F ∗G(z).
Moreover, if X has density f , X + Y has density
fX+Y (z) =
∫f(z − y)dG(y).
If Y also has a density g,
fX+Y (z) =
∫f(z − y)g(y) dy.
Proof.
P (X+Y ≤ z) =∫∫
1{x+y≤z}PX(dx)P Y (dy) =
∫P (X ≤ z−y)P Y (dy) =
∫F (z−y)dG(y).
If X has a density, F (x) =∫ x−∞ f(y) dy, so
P (X + Y ≤ z) =∫ ∫ z
−∞f(x− y) dx dG(y) =
∫ z−∞
∫f(x− y) dG(y) dx.
To deal with the case where Y has a density, see Exercise 1.6.8 in Durrett.
4–4
-
Example 4.1. One can use convolution to show for instance:
• If X, Y are independent normal random variables with means µX , µY and standarddeviations σX , σY , then X + Y is normal with mean µX + µY and variance σ
2X + σ
2Y
• If X, Y are independent and uniform on [0, 1],
fX+Y (a) =
a, 0 ≤ a ≤ 12− a, 1 ≤ a ≤ 20, otherwise
.
4–5
-
Math 83100 (Fall 2013) September 17, 2008Prof. Christian Beneš
Lecture #5: Independence, Laws of Large Numbers,Borel-Cantelli Lemmas
Reference. Sections 2.1, 2.2
5.1 Independence Revisited
We now summarize the results of the previous section.
Definition 5.1. If (X1, . . . , Xn) is an n-dimensional random vector, recall that its distribu-tion P (X1,...,Xn) is defined by
P (X1,...,Xn)(A) = P ((X1, . . . , Xn) ∈ A), A ∈ Rn.
Its distribution function F is defined by
F (x1, . . . , xn) = P (X1 ≤ x1, . . . , Xn ≤ xn) = P (X1,...,Xn)({y ∈ Rn : y1 ≤ x1, . . . , yn ≤ xn}).
X1, . . . , Xn are independent if
P (X1 ∈ A1, . . . , Xn ∈ An) = P (X1 ∈ A1) · · ·P (Xn ∈ An)
for all A1, . . . , An ∈ R.The previous section shows that X1, . . . , Xn are independent if and only if one of the followingis satisfied:
•F (x1, . . . , xn) = F (x1) · · ·F (xn).
•P (X1,...,Xn) = P1 × · · · × Pn.
• If for 1 ≤ i ≤ n, Pi has density fi and P (X1,...,Xn) has density f ,
f(x1, . . . , xn) = f1(x1) · · · fn(xn).
5.2 Fubini and Consequences
Recall
Theorem 5.1. (Fubini’s theorem) If (Ω, F, P ) = (Ω1,F1, P1)× (Ω2,F2, P2), X is a randomvariable on (Ω, F, P ) such that X ≥ 0 or
∫|X| dP
-
Theorem 5.2. Suppose X and Y are independent random variables with distributions PX
and P Y . If h : R2 → R is measurable with h ≥ 0 or E[|h(X, Y )|]
-
5.4 Weak Laws of Large Numbers
One of the big objectives in probability is that of understanding∑n
i=1(Xi − µi) if Xi arerandom variables with E[Xi] = µi. A quick first glance indicates that
∑ni=1(Xi − µi) has
mean zero and should be more and more spread out as n increases. It is then natural to askif we can normalize it to get a nontrivial random variable
1
na
n∑i=1
(Xi − µi),
where a > 0 is some adequately chosen constant. We will answer this question in severalsteps and will start by focusing on the distribution of the sample mean (1/n)
∑ni=1 Xi. We
begin with a lemma giving two basic properties of variance, which will be useful when provinga weak version of the weak law of large numbers (WLLN).
Lemma 5.1. Let X1, . . . , Xn have finite second moments and be pairwise uncorrelated.Then
1.
V ar(n∑i=1
Xi) =n∑i=1
V ar(Xi).
2.V ar(cX1) = c
2V ar(X1).
Proof. We write µi for E[Xi].
1.
V ar(n∑i=1
Xi) = E
[(n∑i=1
(Xi − µi))2]
= E
[n∑i=1
n∑j=1
(Xi − µi)(Xj − µj)
]
= E
[n∑i=1
(Xi − µi)2]
+ 2E
[n∑i=1
i−1∑j−1
(Xi − µi)(Xj − µj)
]=
n∑i=1
V ar(Xi),
since if i 6= j, E[(Xi − µi)(Xj − µj)] = E[XiXj]− µiE[Xj]− µjE[Xi] + µiµj = 0.
2.V ar(cX1) = E[(cX1 − cµ1)2] = c2E[(X1 − µ1)2] = c2V ar(X1).
Standard Notation. In probability, Sn is almost always used to denote a sum of randomvariables: If X1, . . . , Xn are random variables,
Sn =n∑i=1
Xi.
In particular, if the Xi are i.i.d., Sn is called a random walk.
5–3
-
Theorem 5.5. (L2 weak law) Let X1, . . . , Xn be pairwise uncorrelated random variableswith E[Xi] = µ and V ar(Xi) ≤ C �) = 1− 2π arctan(�) 6→ 0.
Theorem 5.6. (Weak Law of Large Numbers) Suppose X1, . . . , Xn are i.i.d and that
xP (|X1| > x)→ 0 as x→∞.
Then if µn = E[X11{|X1|≤n}],Snn− µn
P→ 0.
5–4
-
Note 5.2. : It turns out that the Cauchy distribution example is a borderline case. Itbehaves like 1/x2 as x → ∞. Suppose a random variable X has density function behavinglike 1/x2+� for some � > 0, as x → ∞. Then P (|X1| > x) ≤ Cx−�−1, so xP (|X1| > x) →0 as x → ∞. This suggests that having one moment is almost sufficent for a weak law oflarge numbers to hold.
Note 5.3. Theorem 5.6 doesn’t apply to random variables whose density decays like 1/x2,but it does to those that decay like 1
x2 lnx, which are not L1. This is why truncation is needed
(since µ is not defined for such random variables).
Lemma 5.2. If Y ≥ 0 and p > 0, then
E[Y p] =
∫ ∞0
pyp−1P (Y > y) dy.
Proof. This is just Fubini’s theorem. See proof of Lemma 2.2.8 in Durrett (it’s probablymore natural to go from right to left in his sequence of equalities).
Proof of Theorem 5.6
For n ≥ 1, 1 ≤ k ≤ n, let X̄n,k = Xk1{|Xk|≤n} and S̄n =n∑k=1
X̄n,k. Then E[S̄n] = nµn. Our
goal is to show that
P
(∣∣∣∣Sn − E[S̄n]n∣∣∣∣ > �)→ 0, as n→∞.
We have
P
(∣∣∣∣Sn − E[S̄n]n∣∣∣∣ > �) ≤ P (Sn 6= S̄n) + P (∣∣∣∣ S̄n − E[S̄n]n
∣∣∣∣ > �) .We will estimate both terms and show that they go to 0.
P (Sn 6= S̄n) ≤ P (∪nk=1{X̄n,k 6= Xk}) ≤ nP (X̄n,1 6= X1) = nP (X1 > n)→ 0,
by hypothesis.
Now Chebyshev’s inequality implies that
P
(∣∣∣∣ S̄n − E[S̄n]n∣∣∣∣ > �) ≤ ( 1�n
)2V ar(S̄n) ≤
(1
�n
)2 n∑k=1
E[X̄2n,k] =
(1
�n
)2nE[X̄2n,1].
So all that is left is show that n−1E[X̄2n,1]→ 0, as n→∞. Lemma (5.2) implies that
E[X̄2n,1] = 2
∫ ∞0
yP (|X̄n,1| > y) dy = 2∫ n
0
yP (|X̄n,1| > y) dy
= 2
∫ n0
y (P (|X1| > y)− P (|X1| > n)) dy ≤ 2∫ n
0
yP (|X1| > y) dy.
5–5
-
Now 0 ≤ 2yP (|X1| > y) ≤ 2y and yP (|X1| > y) → 0 as y → ∞, so supy yP (|X1| > y) =M y) : y ≥ n1/2}. Then∫ n
0
yP (|X1| > y) dy =∫ √n
0
yP (|X1| > y) dy +∫ n√n
yP (|X1| > y) dy ≤M√n+ n�n.
So
n−1∫ n
0
yP (|X1| > y) dy ≤M√n
+ �n → 0 as n→∞,
implying that for every � > 0,(
1�n
)2nE[X̄2n,1]→ 0. This proves the theorem. �
We obtain from this a slightly weaker corollary which has the advantage of having nicerlooking assumptions:
Theorem 5.7. (WLLN - Standard Form) If X1, . . . , Xn are i.i.d. with E[X1] = µ, then
Snn
P→ µ.
Proof. We need to show that if E[|X1|] x)→ 0 as x→∞ and that ifµn is as in Theorem 5.6, then µn → µ as n→∞.|X1|1{|X1|>x} → 0 almost surely since for every ω,X1(ω) is bounded and |X1|1{|X1|>x} ≤|X1| ∈ L1, so by the dominated convergence theorem, xP (|X1| > x) = xE[1{|X1|>x}] ≤E[|X1|1{|X1|>x}]→ 0, as x→∞.Also, X11{|X1|≤n} → X1 almost surely and |X11{|X1|≤n}| ≤ |X1| ∈ L1. So by the dominatedconvergence theorem, µn = E[X11{|X1|≤n}]→ µ as n→∞. Therefore,
P
(∣∣∣∣Snn − µ∣∣∣∣ > �) ≤ P (∣∣∣∣Snn − µn
∣∣∣∣ > �2)
+ 1{|µn−µ|>�/2} → 0.
Note 5.4. Why is independence necessary? Suppose {Xi}i≥1 satisfy Xi(ω) = Xj(ω) for alli, j and P (X1 = 0) = 0, E[X] = 0. Then P (|Sn/n| > �) = P (|X1| > �)→ 1 as �→ 0.
Note 5.5. The WLLN tells us that
Sn = nµ+ φ(n), whereφ(n)
n
P→ 0.
Though this is a useful result, it is rather imprecise, as it tells us almost nothing about φ(n).Our goal in what follows will be to find a such that
φ(n)
na→ nontrivial distribution ,
and of course, to find the distribution as well.
5–6
-
5.5 Borel-Cantelli Lemmas
Definition 5.2. Let (Ω,A, P ) be a probability space and let (An)n≥1 be a sequence of eventsin A.
lim supn→∞
An :=∞⋂n=1
⋃m≥n
Am = {ω : ∀m ≥ 1 ∃ n(ω) ≥ m such that ω ∈ An(ω)},
which can be interpreted probabilistically as
{An occur infinitely often} =: {An i.o.}.
lim infn→∞
An :=∞⋃n=1
⋂m≥n
Am = {ω : ∃ m(ω) ≥ 1 such that ∀ n ≥ m(ω), ω ∈ An}
= {ω : ω ∈ An for large enough n}.
The probabilistic meaning of the liminf is
{An occur eventually } =: {An, ev.}.
Note that{An, ev.}c = {Acn, i.o.}.
Theorem 5.8 (First Borel-Cantelli Lemma). Let An be a sequence of events in (Ω,A, P ).If
∞∑n=1
P (An)
-
Math 83100 (Fall 2013) October 15, 2013Prof. Christian Beneš
Lecture #6: Borel-Cantelli Lemmas and Applications; Zero-OneLaws
Reference. Sections 1.3, 1.4
Theorem 6.1 (First Borel-Cantelli Lemma). Let An be a sequence of events in (Ω,A, P ).If
∞∑n=1
P (An)
-
If we write pn = P (An) and use the fact that the An are independent, we get
P
(⋂n≥m
Acn
)=∏n≥m
(1− pn).
The Taylor expansion of e−x shows that if x ≥ 0, 1− x ≤ e−x, so that
∏n≥m
(1− pn) ≤ exp
(−∑n≥m
pn
)= 0,
since∑n≥1
pn =∞. Therefore, P (lim supAn) = 1.
Example 6.1. (B-C 2 doesn’t hold without the assumption of independence) Suppose thatΩ = [0, 1] and P is the uniform probability measure on [0, 1]. For n = 1, 2, . . ., let
An =[0, 1
n
]Then
{An i.o.} =∞⋂m=1
⋃n≥m
An =∞⋂m=1
[0, 1
n
]= {0}
so P (An i.o.) = 0. The An are not independent since if 1 < k < j, then Ak ∩ Aj = Aj,implying that
1
k
1
j= P (Ak)P (Aj) 6= P (Ak ∩ Aj) = P (Aj) =
1
j.
However,∞∑n=1
P (An) =∞∑n=1
1
n=∞
Therefore,∑∞
n=1 P (An) =∞ does not generally imply P{An i.o.} = 1.
Example 6.2. (lim sup of a sequence of independent random variables) Suppose {Xn}n≥1are independent and exponentially distributed: If x ≥ 0, P (X1 > x) = e−x. Then if α >0, P (Xn > α log n) = n
−α. It then follows from the two Borel-Cantelli lemmas that
P (Xn > α log n, i.o) =
{0 if α > 1
1 if α ≤ 1.
Now define L = lim sup Xnlogn
(here, the lim sup is for sequences of real numbers and should
be thought of as a random variable, defined omega by omega). We will show that L = 1,a.s. by showing that P (L ≥ 1) = 1 and P (L > 1) = 0.If Xn > log n, i.o., then L ≥ 1, so
1 = P (Xn > log n, i.o.) ≤ P (L ≥ 1).
6–2
-
On the other hand, if k ∈ N,
P (L > 1) = P
(⋃k≥1
{L > 1 + 2k}
)≤∑k≥1
P
(L > 1 +
2
k
)≤∑k≥1
P
(Xn
log n> 1 +
1
k, i.o.
)= 0.
If {Xn}n≥1 are independent and normally distributed with density f(x) = 1√2πe−x2/2, one
might expect a smaller lim sup than in the exponential case, since the density decays fasterand large values are therefore less likely for the Xn. This is indeed the case. On can showas above that
lim supXn√
2 log n= 1.
We will see this method again later when looking for lim supSn, where Sn =n∑i=1
Xi.
6.1 Pólya’s Theorem
Example 6.3 (Recurrence/Transience of Simple random walk). If {e1, . . . , ed} is the canon-ical basis of Rd, {Xi}i≥1 are independent random vectors with distribution
P (Xi = ±ej) =1
2d,
for all j ∈ {1, . . . , d}, S(0) = 0, and for n ≥ 1, S(n) =∑n
i=1Xi, then {S(n)}n≥0 is called ad-dimensional simple random walk (SRW).
0 10 20 30 40 50 60 70 80 90 100−14
−12
−10
−8
−6
−4
−2
0
2
4
6
Number of Steps
Po
sitio
n o
f W
alk
er
−35 −30 −25 −20 −15 −10 −5 0 5 10−60
−50
−40
−30
−20
−10
0
10
20
−50
510
1520
−20
−15
−10
−5
0
5−5
0
5
10
15
20
25
Figure 1: Simple random walks in 1, 2, and 3 dimensions
A random walk is called recurrent if has probability one of returning to the origin andtransient otherwise. A natural question is: Is d-dimensional simple random walk transientor recurrent? You should be able to quickly convince yourself that
• If SRW is recurrent in dimension dr, then it is recurrent in dimension d with 1 ≤ d ≤ dr.
6–3
-
• If SRW is transient in dimension dt, then it is transient in dimension d with d ≥ dt.
Lemma 6.1. Simple random walk {S(n)} is recurrent if and only if∞∑n=0
P (S(n) = 0) =∞.
Proof. Letr(n) = P (S(1) 6= 0, . . . , S(n− 1) 6= 0, S(n) = 0)
be the probability of a first return to 0 at time n and let
r = P (⋃n≥1
{S(n) = 0}) =∑n≥1
r(n)
be the probability of eventually returning to 0. Then if 1 ≤ n1 < . . . < nk, using the factthat P (S(n) = 0|S(k) = 0) = P (S(n− k) = 0) and defining
A(n1, . . . , nk) = {S(ni) = 0 for 1 ≤ i ≤ k;S(l) 6= 0 for l ≤ nk, l 6∈ {ni}1≤i≤k},
we getP (A(n1, . . . , nk)) = r
(n1) · · · r(nk−nk−1)
and for all k ≥ 1,
P (S returns to 0 k times ) = P (S(n) = 0 for k different values of n 6= 0)
=∑
{n1,...,nk∈Nk:1≤n1
-
So we’ve shown that∑n≥1
P (S(n) = 0)
-
Since∑n≥1
P (A12n) =∞, Lemma 6.1 tells us that 1-dimensional SRW is recurrent.
• d = 2:
P (A22n) = =n∑k=0
(2n)!
k!k!(n− k)!(n− k)!(1
4)2n
= (1
4)2n
(2n)!
n!n!
n∑k=0
n!n!
k!k!(n− k)!(n− k)!
= (1
4)2n(
2n
n
) n∑k=0
(n
k
)2=
((1
2)2n(
2n
n
))2.
This is the square of the 1-d case, and so
P (A22n) ∼1
πn,
Again, there exists C > 0 such that for all n ≥ 1,
P (A22n) ≤C
n
and again,∑n≥1
P (A22n) = ∞, so Lemma 6.1 tells us that 2-dimensional SRW is recur-
rent.
• d = 3: We denote by Hk = Hk(n) the event that 2k steps of S3[0, 2n] are taken in adirection parallel to e1 or e2. Then
P (A32n) =n∑k=0
P (A32n;Hk) =n∑k=0
P (A32n|Hk)P (Hk)
=n∑k=0
P (A22k)P (A12n−2k)
(2n
2k
)(2
3
)2k (1
3
)2(n−k)≤ 2
(2
3
)n+ C3−2n
n−1∑k=1
1√k
1
n− k
(2n
2k
)22k.
There are many ways to attack such a sum. Here’s one not so elegant but intuitiveversion:
There are two essential components to this sum. On one hand, we can note that
C1n−3/2 ≤ 1√
k
1
n− k≤ C2n−1/2
and that 1√k
1n−k is minimal when k is close to n/2 (in which case it’s bounded above
by Cn−3/2. On the other hand,(
2n2k
) (23
)2k (13
)2(n−k)is minimal when k is close to 0 or
to n (in which case it’s very small).
Using this heuristic argument, you can show
6–6
-
Exercise 6.1. There exists a constant C > 0 such that for all n ≥ 1,
P (A32n) ≤ Cn−3/2.
This and Lemma 6.1 is all that is needed to show that 3-dimensional SRW is transient.
• d ≥ 4: The process obtained from Sdn by considering only the times at which one of thefirst 3 components changes is a 3-dimensional random walk. Since this is transient, sois Sdn. This can easily be made perfectly precise (see pp. 185-186 in Durrett).
We just proved
Theorem 6.3. Simple random walk is recurrent in dimensions d ≤ 2 and transient indimensions d ≥ 3.
6–7
-
Math 83100 (Fall 2013) October 21, 2013Prof. Christian Beneš
Lecture #7: Strong Law of Large Numbers
Reference. Sections 2.3-2.5
There are a number of different versions of laws of large numbers. We start with one thathas relatively loose hypothesis and is easy to prove. Stronger hypotheses will lead to a muchmore involved proof based on generalities about random series later.
7.1 A Weak Strong Law of Large Numbers
Theorem 7.1 (Cantelli). Suppose that X1, X2, . . . are independent and identically dis-tributed L4 random variables with common mean E(X1) = µ. Then
Snn→ µ a.s.,
as n→∞.
Proof. [Note that this proof is essentially the same as that of Theorem 2.3.5 in Durrett,except for the last step which bypasses the use of Borel-Cantelli.] We write σ2 for thecommon variance of the Xj and let
S̃n = X1 + · · ·+Xn − nµ.
Our goal now is to estimate E(S̃4n) and show thatE(S̃4n)n4�4
is summable in n.
If we write Yi = Xi − µ, then
S̃4n = (Y1 + Y2 + · · ·+ Yn)4
=n∑j=1
Y 4j + C1∑i 6=j
Y 3i Yj +
(4
2
)∑i
-
This gives
E(S̃4n) =n∑j=1
E(Y 4j ) +
(4
2
)∑i
-
Example 7.1. The event {∞∑n=1
Xnn
converges
}is a tail-event, since for every k,{
∞∑n=1
Xnn
converges
}=
{∞∑n=k
Xnn
converges
}∈ Tk,
implying that {∞∑n=1
Xnn
converges
}∈⋂k≥1
Tk = T .
Example 7.2 (Homework problem). Of the following events, the first 2 are tail-events whilethe last two are not:
1. {lim sup Snn< c},
2. {limSn exists},
3. {∀n ≥ 1, Xn = 0}
4. {limSn exists and is < c}
We will now turn to showing that if T is a tail event for a sequence of independent randomvariables, the only possible values for P (T ) are 0 or 1. First a few lemmas:
Lemma 7.1. Suppose I is a π-system on Ω. If µ1 and µ2 are finite measures with µ1(Ω) =µ2(Ω)
-
Lemma 7.2. Suppose G ⊂ F and H ⊂ F are sigma-algebras and I,J are π-systems withG = σ(I),H = σ(J ). Then G and H are independent iff I and J are independent.
Proof. Obviously, if G and H are independent, so are I and J . Suppose I and J areindependent. Let I ∈ I. The measures µ1 and µ2 on (Ω,F) defined by µ1(H) = P (I ∩H)and µ2(H) = P (I)P (H) agree on J and have same total mass P (I). Therefore, by Lemma7.1, they agree on H = σ(J ). Thus,
P (I ∩H) = P (I)P (H), ∀I ∈ I, H ∈ H.
We use the same argument one more time: For fixed H ∈ H, the measures ν1 and ν2 on(Ω,F) defined by ν1(G) = P (G ∩ H) and ν2(G) = P (G)P (H) agree on I and have sametotal mass P (H). Therefore, they agree on G = σ(I). So
P (G ∩H) = P (G)P (H), ∀G ∈ G, H ∈ H.
Theorem 7.2 (Kolmogorov’s Zero-One Law). Suppose that {Xn}n≥1 are independent ran-dom variables and T is the tail σ-algebra generated by {Xn}n≥1. If C ∈ T , then eitherP (C) = 0 or P (C) = 1.
Proof. Define Hn = σ(X1, . . . , Xn) and H = σ({Xn}n≥1), so that Hn and Tn are independentσ-algebras. Indeed, they are generated by the independent π-systems
{ω : Xi(ω) ≤ xi : 1 ≤ i ≤ n}, xi ∈ R ∪∞
and{ω : Xj(ω) ≤ xj : n+ 1 ≤ j ≤ n+ r}, r ∈ N, xj ∈ R ∪∞,
respectively. So by Lemma 7.2, Hn and Tn are independent.Now since T ⊂ Tn, it is clear that Hn and T are independent.Since Hn ⊂ Hn+1 for all n ≥ 1, ∪nHn is a π-system which generates H. Since ∪nHn and Tare independent, Lemma 7.2 implies that T and H are.Since T ⊂ H, T is independent of T . Therefore, if F ∈ T , P (F ) = P (F ∩ F ) = P (F )P (F ).So P (F ) = 1 or P (F ) = 0.
7.3 Random Series
We now focus on random series, i.e.,
Sn =n∑k=1
Xk,
7–4
-
where {Xn}n≥1 is a sequence of independent (not necessarily identically distributed) randomvariables. The 0− 1 law (which applies, as we saw in Lecture 11) implies that P ({S(n)/n}converges) = 0 or 1. We will now look for criteria to determine when this probability is 0and when it is 1.
An important tool in deriving criteria for convergence of random series is an extension ofChebyshev’s inequality. Recall that according to Chebyshev, if Sn is a random variable withE[Sn] = 0 and E[S
2n] 0,
P (|Sn| ≥ a) ≤E[S2n]
a2.
It turns out that if we think of Sn as a random series, then the same inequality holds for themaximum of the partial sums up to n:
Lemma 7.3. (Kolmogorov’s Maximal Inequality) Let X1, . . . , Xn be independent randomvariables with E[Xi] = 0 and E[X
2i ] 0,
P ( max1≤k≤n
|Sk| ≥ a) ≤E[S2n]
a2.
Proof. Define A = {max1≤k≤n |Sk| ≥ a} and for 1 ≤ k ≤ n,
Ak = {|Si| < a, i = 1, . . . , k − 1, |Sk| ≥ a}.
ThenA =
⊔1≤k≤n
Ak,
where t denotes the disjoint union. Let Rn,k =n∑
i=k+1
Xi. Then, since Rn,k and Sk1Ak are
independent,
E[S2n1Ak ] = E[(Sk +Rn,k)21Ak ] = E[S
2k1Ak ] + E[R
2n,k1Ak ],
so E[S2n1Ak ] ≥ E[S2k1Ak ]. This gives
E[S2n] ≥ E[S2n1A] =n∑k=1
E[S2n1Ak ] ≥n∑k=1
E[S2k1Ak ] ≥ a2P (A).
Note 7.1. Of course, Chebyshev’s inequality is just a particular case of Kolmogorov’s Max-imal Inequality.
Lemma 7.4. (Cauchy Criterion for almost sure convergence) A sequence {Xn}n≥1of randomvariables converges almost surely if and only if
P (supk≥0|Xn+k −Xn| ≥ �)
n→∞→ 0
7–5
-
Proof. Homework 3.
Theorem 7.3. (Kolmogorov-Khinchine) Let {Xn}n≥0 be a sequence of random variableswith E[Xn] = 0. Then if
∑n≥1
E[X2n] 0, an ≥
1 ∀ n ≥ 1, andn∑i=1
ai ↑ ∞ as n → ∞. Then if {xn}n≥1 is a sequence of real numbers with
limn→∞ xn = x,1n∑i=1
ai
n∑i=1
aixi → x, as n→∞.
In particular,1
n
n∑i=1
xi → x, as n→∞.
Proof. Let’s write bn =n∑i=1
ai. Define n0 ∈ N to be such that |xi − x| < �/2 for all i ≥ n0
and n1 > n0 to satisfy1
bn1
n0∑i=1
a
i
|xi − x| < �/2.
7–6
-
Then, if n ≥ n1,∣∣∣∣ 1bnn∑i=1
aixi − x∣∣∣∣ ≤ 1bn
n∑i=1
ai|xi − x| =1
bn
(n0∑i=1
ai|xi − x|+n∑
i=n0+1
ai|xi − x|
)
<1
bn1
n0∑i=1
ai|xi − x|+�
2
1
bn
n∑i=n0+1
ai <�
2+�
2
bn − bn0+1bn
≤ �.
Lemma 7.6. (Kronecker) Let {bn}n≥1 be a sequence of real numbers satisfying bn > 0 andbn ↑ ∞ as n → ∞. If {xn}n≥1 be a sequence of real numbers such that
∑n≥1
xn converges,
then1
bn
n∑i=1
bixi → 0, as n→∞.
In particular, if∑n≥1
xn/n converges, then
1
n
n∑i=1
xi → 0, as n→∞.
Proof. Let b0 = s0 = 0, sn =n∑i=1
x
i
and x = limn→∞ sn. Thenn∑i=1
bixi =n∑i=1
bi(si − si−1) =
bnsn +n∑i=1
(bi−1 − bi)si−1. Therefore,
1
bn
n∑i=1
bixi = sn −1
bn
n∑i=1
(bi − bi−1)si−1 → 0,
since as n→∞ sn → x and by Toeplitz’s lemma, 1bnn∑i=1
(bi − bi−1)si−1 → x.
Lemma 7.7. Suppose X ≥ 0 is a random variable. Then∑n≥1
P (X ≥ n) ≤ E[X] ≤ 1 +∑n≥1
P (X ≥ n).
Proof. Homework 3.
Note 7.2. If X is integer-valued, the first inequality in this lemma becomes an equality.
Theorem 7.4. (Kolmogorov’s strong law of large numbers) Let {Xi}i≥1 be a sequence ofi.i.d. random variables with E[|X1|]
-
Proof. We will assume that E[X1] = 0. By Lemma 7.7 and Borel-Cantelli,
E[|X1|]
-
Theorem 7.5. Suppose {Xi}i≥1 is a sequence of i.i.d. random variables such that
Snn
a.s.→ C n, i.o.) = 0 and by Borel-Cantelli,∑n≥1
P (|X1| > n) =∑n≥1
P (|Xn| > n)
-
Math 83100 (Fall 2013) October 28, 2013Prof. Christian Beneš
Lecture #8: Law of Large Numbers; Law of the IteratedLogarithm
8.1 Another Law of Large Numbers
There is another version of the strong law of large numbers which doesn’t require the randomvariables to be identically distributed, but needs two moments:
Theorem 8.1. Let {Xi}i≥1 be a sequence of independent L2 random variables. If there isa sequence of positive real numbers {bn} such that bn ↑ ∞ and∑
n≥1
V ar(Xn)
b2n
-
8.2 Law of the Iterated Logarithm
Suppose that {Xi} is a sequence of independent mean 0, variance 1 random variables. Thenone can show that
lim supSn
n1/2−�=∞ and lim inf Sn√
n= −∞, a.s. (5)
Indeed, let N > 0 and EN = {lim sup Snn1/2−� ≤ N} Then for every δ > 0,
P (EN) ≤ P(
Snn1/2 − �
≤ N + �, eventually)
= P
(lim inf{ Sn
n1/2 − �≤ N + �}
)Fatou
≤ lim inf P(
Snn1/2 − �
≤ N + �)< 1,
where the last inequality is due to the central limit theorem (which we’ll see soon, but whichyou’ve certainly seen in an undergraduate class).
Now since EN is a tail event (see Example 2.5.2 in Durrett), this means that there are onlytwo possibilities: P (EN) = 0 or P (EN) = 1. But we just showed that P (EN) < 1. SoP (EN) = 0. Since this holds for arbitrary N , (5) follows. Note that the choice of n
1/2−�
above is fairly arbitrary. The argument works if we replace n1/2 − � by any function f(n)such that f(n)
n1/2→ 0 as n→∞.
On the other hand, by Theorem 8.1, Sn√n logn
→ 0, a.s., since∑
n≥1Var(Xn)
(√n logn)2
=∑
n≥11
n log2 n<
∞.This suggests that we might be able to find a non-trivial almost sure lim sup for the sequenceSn. Can we find a function ψ(n) such that lim sup
S(n)ψ(n)
= 1, a.s.? It turns out that we can.
First, we prove two ancillary results. The first, called the reflexion principle, is often needed,when dealing with stochastic processes:
Definition 8.1. A random variable X is said to be symmetric if for all B ∈ R, P (X ∈ B) =P (−X ∈ B).
Lemma 8.1. Let {Xi}1≤i≤n be independent symmetric random variables Then for everya ∈ R,
P ( max1≤k≤n
Sk > a) ≤ 2P (Sn > a).
Proof. The idea is that if Sk > a for some k ≤ n, then Sn has a probability of at least 1/2of being greater than a, since Sn − Sk is symmetric. For k ≥ 1, define
Ak = {Sj ≤ a for 1 ≤ j ≤ k − 1, Sk > a},
the event that S is greater than a for the first time at time k. Then
P ( max1≤k≤n
Sk > a) =n∑k=1
P (Ak)
8–2
-
and
P (Sn > a) =n∑k=1
P (Sn > a;Ak) ≥n∑k=1
P (Sn − Sk ≥ 0;Ak)
=n∑k=1
P (Sn − Sk ≥ 0)P (Ak) ≥1
2
n∑k=1
P (Ak) =1
2P ( max
1≤k≤nSk > a),
where the second equality follows from the independence of {Sn − Sk ≥ 0} and Ak.
Lemma 8.2. Suppose Sn ∼ N(0, σ2n) with σ2n ↑ ∞, as n→∞, and suppose {rn}n≥1 satisfies
limn→∞
rnσn→∞.
Then
P (Sn > rn) ∼σn√2πrn
exp
{− r
2n
2σ2n
}.
Proof. First note that Sn/σn ∼ N(0, 1). So
P (Sn > rn) = P (Snσn
>rnσn
) ∼ σn√2πrn
exp
{− r
2n
2σ2n
},
since we know from Lemma 2.1 that if Z is a standard normal random variable,
P (Z > x)x→∞∼ 1
x
1√2πe−x
2/2.
Theorem 8.2. (Law of the iterated logarithm) Let {Xi}i≥1 be a sequence of i.i.d. randomvariables. with E[X1] = 0 and E[X
21 ] = σ
2 0,
P (Sn ≥ (1− �)√
2σ2n log log n, i.o.) = P (Sn ≤ −(1− �)√
2σ2n log log n, i.o.) = 1,
P (Sn ≥ (1 + �)√
2σ2n log log n, i.o.) = P (Sn ≤ −(1 + �)√
2σ2n log log n, i.o.) = 0.
8–3
-
Proof. We will prove the theorem in the case where Xi ∼ N(0, 1). Let ψ(n) =√
2n log log n.We will show that
P
(lim supn→∞
Snψ(n)
≤ 1)
= 1 (6)
and
P
(lim supn→∞
Snψ(n)
≥ 1)
= 1. (7)
Equation (6) will be somewhat more straightforward to prove than (7).
We begin by noting that{lim supn→∞
Snψ(n)
≤ 1}
=
{limn→∞
supm≥n
Smψ(m)
≤ 1}
= {∀� > 0∃m1(�)s.t.∀m ≥ m1(�), Sm ≤ (1 + �)ψ(m)}
and{lim supn→∞
Snψ(n)
≥ 1}
=
{limn→∞
supm≥n
Smψ(m)
≥ 1}
= {∀� > 0, Sm ≥ (1− �)ψ(m), i.o., } .
Therefore, we can show (6) by proving for every � > 0 that P (Sm > (1 + �)ψ(m), i.o.) = 0.We will now decompose R into intervals of exponentially increasing length and estimate theprobability that over each interval Sn > (1 + �)ψ(n) for some n. These probabilities will besummable.
Let λ = 1 + � and define Ak = {Sm > λψ(m) for some m ∈ (λk, λk+1]}. Then we can usethe fact that Sn ∼ N(0, n) and Lemmas 8.1 and 8.2 to see that
P (Ak) = P (Sm > λψ(m), some m ∈ (λk, λk+1]) ≤ P (Sm > λψ(λk), some m ≤ λk+1)
≤ 2P (Sbλk+1c > λψ(λk)) ≤ C√λk
λψ(λk)exp
−λ22(ψ(λk)√bλkc
)2≤ C exp
{−λ2 ln lnλk
}≤ C exp {−λ ln(k lnλ)} ≤ C exp {−λ ln k} = Ck−λ.
Here, we assumed k is large enough that all quantities are defined. Since λ > 1,∑k≥1
P (Ak) <
∞, implying via Borel-Cantelli that P (Ak, i.o.) = 0.We now turn to the proof of (7). The key difficulty is that the Sn are not independent,making the direct use of the second Borel-Cantelli Lemma impossible. The trick is to findindependent random variables to which B-C 2 can be applied. These independent randomvariables will be increments of Sn over certain appropriately chosen intervals.
We let λ = 1− � and will show that
P (Sm ≥ λψ(m), i.o.) = 1.
From the work above and symmetry, we know that P (Sm ≤ −2ψ(m), i.o.) = 0 (the “2” isarbitrary; anything strictly greater than 1 works too). So since if N ∈ N \ {1},
{SNk−SNk−1 > λψ(Nk)+2ψ(Nk−1), i.o.} ⊆ {SNk > λψ(Nk), i.o.}∪{SNk−1 ≤ −2ψ(Nk−1), i.o.},
8–4
-
we have
P (SNk − SNk−1 > λψ(Nk) + 2ψ(Nk−1), i.o.) ≤ P (SNk > λψ(Nk), i.o.).
The expression λψ(Nk) is not so convenient to work with. However,
λψ(Nk) + 2ψ(Nk−1) = λ√
2Nk ln lnNk + 2√
2Nk−1 ln lnNk−1 <
(λ+
2√N
)√2Nk√
ln lnNk
=
((λ+
2√N
)/
√1− 1
N
)√2(Nk −Nk−1)
√ln lnNk
< λ′√
2(Nk −Nk−1) ln lnNk,
for some λ′ with λ′ ∈ (λ, 1), for k large enough. So we’ll be done if we can show that
P (SNk − SNk−1 > λ′√
2(Nk −Nk−1) ln lnNk, i.o.) = 1. (8)
By Lemma 8.2,
P(SNk − SNk−1 > λ′
√2(Nk −Nk−1) ln lnNk
)∼ 1√
2πλ′√
2 ln lnNke−λ
′2 ln lnNk
≥ C√ln k
(k lnN)−λ′2 ≥ C
k ln k.
Since∑k≥1
1
k ln k= ∞ and the increments SNk − SNk−1 are independent, the second Borel-
Cantelli Lemma implies that (8) holds.
8–5
-
Math 83100 (Fall 2013) November 11, 2013Prof. Christian Beneš
Lecture #9: Convergence in Distribution, Weak Convergence;Characteristic Functions
Reference. Sections 3.2, 3.3
In order to derive one of the most important results of probability theory, the central limittheorem, we need to be comfortable with the notions of convergence in distribution andcharacteristic functions.
9.1 Convergence in Distribution & Weak Convergence
There is a mode of convergence of random variables which is radically different from thosewe’ve studied so far. It is convergence in distribution. Whereas the other modes we haveseen require that the random variables are all defined on the same probability space, weakconvergence concerns the laws of the random variables, so we don’t need to assume that theyare all defined on a common probability space.
Notation. We will denote by C(R) the space of bounded continuous functions f : R→ R.
Definition 9.1. A sequence {Xn}n≥1 converges in distribution to the random variable X if
E[f(Xn)]→ E[f(X)], as n→∞
for every f ∈ C(R). We writeXn
d→ X.
Proposition 9.8. If XnP→ X, then Xn
d→ X.
Proof. Consider a continuous function f with |f(x)| ≤ C for some C < ∞. For everyN 0 and let N be such that P (|X| ≥ N) < �
6c. Choose δ > 0 with δ < N such
that if |x| < N and |x − y| ≤ δ, then |f(x) − f(y)| ≤ �3. Also choose n0 such that for all
n ≥ n0, P (|Xn −X| > δ) < �6c .
E[|f(Xn)− f(X)|] ≤ E[|f(Xn)− f(X)|1{|Xn −X| ≤ δ; |X| ≤ N}]+ E[|f(Xn)− f(X)|1{|X| > N}]+ E[|f(Xn)− f(X)|1{|Xn −X| > δ}]
<�
3+ 2c
�
6c+ 2cP (|Xn −X| > δ) ≤ �.
9–1
-
Recall that if X : (Ω,A, P )→ (R,B) is a random variable, then PX , the law of X, is givenby
PX(B) = P{X ∈ B} for every B ∈ B
and defines a probability measure on (R,B). That is, if X is a random variable, then(R,B, PX) is a probability space.Suppose that for each n ≥ 1, Xn : (Ωn,An, Pn) → (R,B) and X : (Ω,A, P ) → (R,B) arerandom variables. The laws of each of these random variables induce probability measureson (R,B), say PXn , n = 1, 2, 3, . . ., and PX .
Definition 9.2. If {Pn}n≥1 and P are probability measures, we say that Pn converges weaklyto P if
limn→∞
∫R
f(x)Pn(dx) =
∫R
f(x)P (dx)
for all f ∈ C(R). We write Pn ⇒ P .Similarly, we say that the distribution functions Fn converge weakly to the distributionfunction F if
limn→∞
∫R
f(x)dFn(x) =
∫R
f(x)dF (x)
for every f ∈ C(R) and write Fn ⇒ F .We say that Xn converges weakly to X or Xn converges to X in law if P
Xn converges weaklyto PX and write Xn ⇒ X.
Note 9.1. This definition is rather unintuitive. Fortunately, we will prove a number ofcharacterizations of weak convergence which will be, in general, much easier to handle.
Weak convergence and convergence in distribution are the same thing:
Theorem 9.1. Let {Xn}n≥1 be random variables with laws PXn and let X be a randomvariable with law PX . Then Xn ⇒ X if and only if Xn
d→ X
Proof. This follows immediately from the change of variables formula (see Lecture 3): If Xnhas distribution PXn and X has distribution PX , then∫
R
f(x)PXn(dx) = E(f(Xn)) and
∫R
f(x)PX(dx) = E(f(X)).
This equivalence establishes the theorem.
Note 9.2. The reason for the name “convergence in law” should be clear. We are discussingconvergence of the laws of random variables. The reason that it is also called convergencein distribution is the following. Since the law of a random variable is characterized by itsdistribution function, one could hope that convergence of the laws of the random variablesis equivalent to convergence of the corresponding distribution functions. This is almost thecase, as we will see.
9–2
-
Note 9.3. Since f(x) = x is NOT bounded, we cannot infer whether or not Xn → X weaklyfrom the convergence/non-convergence of E(Xn) to E(X).
Although the random variables Xn and X need not be defined on the same probability spacein order for weak convergence to make sense, if they are defined on a common probabilityspace, then we can talk about implication between types of convergence.
Note 9.4. Suppose that {Xn}n≥1 , and X are random variables defined on a commonprobability space (Ω,A, P ). The facts about convergence are:
Xn → X almost surely⇓
Xn → X in probability ⇒ Xn ⇒ X⇑
Xn → X in Lp
with no other implications holding in general.
The following example shows just how weak convergence in distribution really is.
Example 9.1. Suppose that Ω = {a, b}, F = 2Ω, and P{a} = P{b} = 1/2. Define therandom variables Y and Z by setting
Y (a) = 1, Y (b) = 0, and Z = 1− Y.
ThenY 6= Z almost surely but P Y = PZ .
If n is odd, let Xn = Y , and if n is even, let Xn = Z. Since PY = PZ , it is clear that
PXn → P Y meaning that Xn → Y in distribution. (In fact, PXn = P Y meaning thatXn = Y in distribution for every n.) However, if � > 0 and n is even, then
P{|Xn − Y | > �} = P{|Z − Y | > �} = P{Z = 1, Y = 0}+ P{Z = 0, Y = 1} = 1.
Thus, it is not possible for Xn to converge in probability to Y . Of course, this exampleshould make sense. By construction, since Z = 1 − Y , the observed sequence of Xn willalternate between 1 and 0 or 0 and 1 (depending on whether a or b is first observed).
One would hope that if PXn → PX , then FXn would converge to FX . This is not quite trueas the following example shows:
Example 9.2. Suppose X has distribution F . Then if Yn = X +1n, Yn
a.s.→ X, implying thatYn ⇒ X. However,
FYn(x) = P (X +1
n≤ x) = P (X ≤ x− 1
n) = F (x− 1
n),
so limn→∞ FYn(x) = limy↑x FY (y). So FYn converges to FX only at points of continuity ofFX .
9–3
-
Definition 9.3. A sequence of distribution functions {Fn} converges in general to the dis-tribution F if Fn(x)→ F (x) for all points x of continuity of F .
Theorem 9.2.Xn ⇒ X ⇐⇒ FXn → FX in general.
Example 9.3. Let X1, X2, . . . be independent with P (Xi = 1) = P (Xi = −1) = 12 and letX be such that P (X = 0) = 1. Then
∀� > 0, P (∣∣∣∣Snn
∣∣∣∣ > �)→ 0 ⇐⇒ ∀x > 0, FSn/n(x)→ 1 and ∀x < 0, FSn/n(x)→ 0⇐⇒ FSn/n → FX in general ⇐⇒
Snn⇒ X.
So WLLN is equivalent to convergence of Snn
to X in law.
9.2 Characteristic Functions
Definition 9.4. If X is a random variable, then the characteristic function of X is given by
φX(t) = E[eitX ] = E[cos(tX)] + iE[sin(tX)], t ∈ R.
Note 9.5. The following is a list of basic properties of characteristic functions. Their proofsall hold in 2 lines, so we omit them (see Durrett, pp. 90-91 if you are unsure how to derivethem).
•φX(0) = 1.
• For all t ∈ R,φX(−t) = φX(t).
• For all t ∈ R,|φX(t)| ≤ 1.
• For all t ∈ R,φaX+b(t) = e
itbφX(at).
• For all t ∈ R,φ−X(t) = φX(t).
• φX is uniformly continuous.
9–4
-
Theorem 9.3. If X1, X2, . . . , Xn are independent random variables and
Sn = X1 +X2 + · · ·+Xn,
then
φSn(t) =n∏i=1
φXi(t).
In particular, if X1, X2, . . . , Xn are identically distributed, then
φSn(t) = [φX1(t)]n .
Proof. By definition,
φSn(t) = E[eitSn ] = E[eit(X1+···+Xn)] = E[eitX1 · · · eitXn ] = E[eitX1 ] · · ·E[eitXn ] =
n∏i=1
φXi(t)
where the second-to-last equality follows from the fact that Xi are independent.
9.3 Moments and Derivatives
Theorem 9.4. If X has a moment of order n, then∣∣∣∣φX(t)− n∑j=0
E
[(itX)j
j!
]∣∣∣∣ ≤ E [min{ |tX|n+1(n+ 1)! , 2|tX|nn!}]
.
Note 9.6. In particular, for any t with limn→∞|t|nE[|X|n]
n!= 0, φ(t) =
∑k≥0
(it)k
k!E[Xk].
Proof. If we let An =∫ x
0(x− s)neis ds, then A0 = e
ix−1i
and by integration by parts, we get
for n ≥ 0, An = xn+1
n+1+ i
n+1An+1, implying that for n ≥ 1, An = ixn − inAn−1. By induction,
we get
eix =n∑k=0
(ix)k
k!+in+1
n!An, (9)
so
eix =n∑k=0
(ix)k
k!+in+1
n!(ixn − inAn−1) =
n∑k=0
(ix)k
k!+in+1
n!(ixn − in
∫ x0
(x− s)n−1eis ds)
=n∑k=0
(ix)k
k!− (ix)
n
n!+nin
n!
∫ x0
(x− s)n−1eis ds
=n∑k=0
(ix)k
k!+
in
(n− 1)!
(∫ x0
(x− s)n−1(eis − 1) ds), (10)
9–5
-
where we used the fact that xn = n∫ x
0(x− s)n−1 ds. Therefore, by (9) and (10),
eix −n∑k=0
(ix)k
k!=in+1
n!An =
in
(n− 1)!
∫ x0
(x− s)n−1(eis − 1) ds.
Now ∣∣∣∣in+1n! An∣∣∣∣ ≤ 1n!
∫ x0
|x− s|n ds ≤ |x|n+1
(n+ 1)!
and ∣∣∣∣ in(n− 1)!∫ x
0
(x− s)n−1(eis − 1) ds∣∣∣∣ ≤ 1(n− 1)!2
∫ x0
|x− s|n−1 ds ≤ 2|x|n
n!.
So ∣∣∣∣eix − n∑k=0
(ix)k
k!
∣∣∣∣ ≤ min{ |x|n+1(n+ 1)! , 2|x|nn!}.
The theorem follows.
9.4 The Inversion Theorem
Definition 9.5. For T ≥ 0, we define
S(T ) :=
∫ T0
sinx
xdx.
Lemma 9.1. 1. limT→∞ S(T ) =π2.
2.∫ T
0sin(θt)t
dt = sgn(θ)S(T |θ|)
Proof. 1. This is just a creative application of Fubini’s theorem (which is OK, since on[0, T ]× [0,∞), | sinxe−ux| is integrable) :∫ T
0
sinx
xdx =
∫ T0
sinx
∫ ∞0
e−ux du dx =
∫ ∞0
∫ T0
sinxe−ux dx du
=
∫ ∞0
1
1 + u2(1− e−uT (u sinT + cosT )
)du
=
∫ ∞0
1
1 + u2du−
∫ ∞0
e−uT (u sinT + cosT )
1 + u2du.
=π
2− T
∫ ∞0
e−s(s sinT/T + cosT )
s2 + T 2ds.
But ∣∣∣∣T ∫ ∞0
e−s(s sinT/T + cosT )
s2 + T 2ds
∣∣∣∣ ≤ TT 2∫ ∞
0
Cse−s ds→ 0, as T →∞.
9–6
-
2. Using the change of variables |θ|t = u, we get∫ T
0sin(θt)t
dt = |θ|θ
∫ |θ|T0
sin(u)u
dt
Theorem 9.5. If a probability measure µ has characteristic function φ(t) =∫Reitxµ(dx)
and if µ({a}) = µ({b}) = 0, then
µ(a, b] = limT→∞
1
2π
∫ T−T
e−ita − e−itb
itφ(t) dt. (11)
Proof. By Fubini’s theorem,
IT :=1
2π
∫ T−T
e−ita − e−itb
itφ(t) dt =
1
2π
∫ ∞−∞
∫ T−T
eit(x−a) − eit(x−b)
itdt µ(dx).
Using the fact that sin θtt
is even and cos θtt
is odd and that
eit(x−a) − eit(x−b)
it=
cos(t(x− a)) + i sin(t(x− a))− (cos(t(x− b)) + i sin(t(x− b)))it
= icos(t(x− b))− cos(t(x− a))
t+
sin(t(x− a))− sin(t(x− b))t
,
we get, via Lemma 9.1 2.,
IT =1
π
∫ ∞−∞
∫ T0
sin(t(x− a))− sin(t(x− b))t
dt µ(dx)
=
∫ ∞−∞
1
π(sgn(x− a)S(T |x− a|)− sgn(x− b)S(T |x− b|))µ(dx).
By Lemma 9.1 1., the integrand converges, as T →∞ to the function fa,b(x) = 1{a
-
thenφX(u) = [pe
iu + 1− p]n.
It follows from Theorem 9.3 that if X ∼ Bin(n, p) and Y ∼ Bin(m, p) are independent,then φX+Y = [pe
iu + 1 − p]n[peiu + 1 − p]m = [peiu + 1 − p]n+m. Corollary 9.1 now implies
that X + Y ∼ Bin(n + m, p). By induction, if Xj ∼ Bin(nj, p) are independent,n∑j=1
Xj ∼
Bin(n∑j=1
nj, p).
Example 9.5. If X ∼ N(µ, σ2),
φX(t) = exp{iµt−σ2t2
2}.
Therefore, if X ∼ N(µ1, σ21) and Y ∼ N(µ2, σ22) are independent,
φX+Y (t) = φX(t)φY (t) = exp{iµ1t−σ21t
2
2} exp{iµ2t−
σ22t2
2} = exp{i(µ1+µ2)t−
(σ21 + σ22)t
2
2},
implying that X+Y ∼ N(µ1 +µ2, σ21 +σ22). By induction, if Xj ∼ N(µj, σ2j ) are independent,n∑j=1
Xj ∼ N(n∑j=1
µj,n∑j=1
σ2j ).
Example 9.6. Suppose that λ > 0 and Xj are independent random variables with a Poissondistribution with parameter λj (Xj ∼ Po(λj)), that is,
P{Xj = k} =λkj e
−λj
k!, k = 0, 1, 2, 3, . . . .
ThenφXj(t) = exp{λj(eit − 1)}.
and if Sn =n∑j=1
Xj
φSn(t) = exp{n∑j=1
λj(eit − 1)},
so Sn ∼ Po(n∑j=1
λj).
9–8
-
Math 83100 (Fall 2013) November 18, 2013Prof. Christian Beneš
Lecture #10: Central Limit Theorem
Reference. Sections 3.2, 3.3
10.1 Some Basic Facts from Complex Analysis
Definition 10.1. The residue Res(f, a) of a meromorphic function f at an isolated singu-larity a, is the coefficient a−1 of (z− a)−1 in the Laurent series expansion of f around a. Ata simple pole, the residue is given by:
Res(f, a) = limz→a
(z − a)f(z).
Theorem 10.1. Suppose D is a simply connected open subset of the complex plane, anda1, . . . , an are finitely many points of D and f is a function which is defined and holomorphicon D \ {a1, . . . , an}. If γ is a rectifiable Jordan (i.e., closed, non-self-intersecting) curve inD which disconnects ak from infinity for all k ∈ {1, . . . , n} but such that γ ∩ ak = ∅ for allk ∈ {1, . . . , n}, then ∮
γ
f(z) dz = 2πin∑k=1
Res(f, ak),
where Res(f, ak) denotes the residue of f at ak.
10.2 More on Characteristic Functions
Example 10.1. If X ∼ N(µ, σ2),
φX(t) = exp
{iµt− σ
2t2
2
}.
Indeed, if X ∼ N(µ, σ2), Z = X−µσ∼ N(0, 1). Therefore, X = σZ + µ, implying that
φX(t) = eiµtφZ(σt). (12)
Now
φZ(t) = E[eitZ ] =
1√2π
∫R
eitxe−x2/2 dx =
1√2π
∫R
∑n≥0
(itx)n
n!e−x
2/2 dx
=∑n≥0
(it)n
n!
1√2π
∫R
xne−x2/2 dx =
∑n≥0
(it)2n
(2n)!
(2n)!
2nn!=∑n≥0
(−1)nt2n
2nn!
=∑n≥0
(−t
2
2
)n1
n!= e−t
2/2,
where the second equality on the second line follows from a computation from the end ofLecture 3. The expression for φX(t) now follows from (12).
10–1
-
Example 10.2. If X has the standard Cauchy distribution with density
f(x) =1
π(1 + x2),
then
φX(t) = E[eitX ] =
∫R
eitx
π(1 + x2)dx.
We evaluate this integral by computing∮γR
eitz
π(1 + z2)dz
along the curve γR composed of the line segment [−R,R] and the semi-circle CR = {z ∈ C :|z| = R, Im(z) ≥ 0}, traversed counterclockwise, where R > 1. Then∮
γR
eitz
π(1 + z2)dz =
∫ R−R
eitx
π(1 + x2)dx+
∫CR
eitz
π(1 + z2)dz. (13)
Also, by the residue theorem,∮γR
eitz
π(1 + z2)dz = 2πi lim
z→i
eitz(z − i)π(1 + z2)
= 2πi limz→i
eitz
π(z + i)= 2πi
e−t
π(2i)= e−t. (14)
Now if |z| = |x+ iy| = R, ∣∣∣∣ eitzπ(1 + z2)∣∣∣∣ ≤ e−tyπR2 ,
so since y ≥ 0, if t ≥ 0,∣∣∣∣ ∫CR
eitz
π(1 + z2)dz
∣∣∣∣ ≤ 1πR2∫CR
dz =1
R→ 0, as R→∞.
(13), (14), and continuity of Lebesgue integral now imply that∫R
eitx
π(1 + x2)dx = e−t.
If t ≤ 0, we can repeat the same argument with γ′R composed of the line segment [−R,R]and the semi-circle CR = {z ∈ C : |z| = R, Im(z) ≤ 0}. Alternatively, we can just use thefact that φX(−t) = φ̄X(t) for all t. This then gives
φX(t) = e−|t|.
Theorem 10.2. Let X be a random variable with distribution function FX . Then φX isreal-valued if and only if the measure dFX is symmetric (
∫BdFX(x) =
∫−B dFX(x)∀B ∈ R).
10–2
-
Proof. Suppose dFX is symmetric. Then∫R
sin(tx) dFX(x) = 0, so φX(t) = E[cos(tX)],which is real-valued.
Conversely, suppose φX is real-valued. Then
φ−X(t) = φX(t) = φX(t).
By the inversion theorem, the measures PX and P−X are the same, so
P (X ∈ B) = P (−X ∈ B) = P (X ∈ −B).
Corollary 10.1. If X, Y are i.i.d., then X − Y is symmetric.
Proof. Since X and Y are i.i.d.,
φX−Y (t) = φX(t)φ−Y (t) = φX(t)φX(t) = |φX(t)|2 ∈ R.
Note 10.1. It also follows immediately that if X and Y are independent, symmetric, thenX + Y is symmetric.
10.3 More on Weak Convergence
Theorem 10.3 (Helly’s Theorem). For every sequence {Fn} of distribution functions, thereexists a subsequence {Fnk} and a nondecreasing right-continuous function F such thatlimk→∞ Fnk(x) = F (x) at all continuity points of F .
Proof. The diagonal method gives a sequence {nk} ∈ N such that G(q) := limk→∞ Fnk(q)exists for every r ∈ Q.Indeed, let Q = {q1, q2, . . .}. Then since {Fn(q1)}n≥1 is a bounded sequence, it contains aconvergent subsequence {Fn(1,j)(q1)}j≥1 with {Fn(1,j)(q1)}j≥1
j→∞→ G(q1). There then is somesubsequence {n(2, j)}j≥1 of {n(1, j)}j≥1 with {Fn(2,j)(q2)}j≥1
j→∞→ G(q2), and so on. If we letfor i ∈ N, ni = n(i, i), we see that for any j ∈ N, the following is well defined:
G(qj) = limi→∞
Fni(qj).
For x ∈ R, define F (x) = inf{G(r) : r > x}. [Note that for q ∈ Q, F (q) may be differentform G(q).] Then
• F is obviously non-decreasing.
• For every x ∈ R, � > 0, there exists q ∈ Q such that x < q and G(q) <


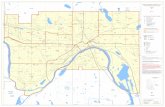












![109 w] ^ 0 [ ï}Ú}²Vóÿ ÿ ÿ ÿ ÿ ÿ ÿ ÿ - Nagasaki...n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n](https://static.fdocuments.us/doc/165x107/5f36fb8f1f26d128d06b20dc/109-w-0-v-nagasaki-n-n-n-n-n-n-n-n-n.jpg)


