
CSE 6331 © Leonidas Fegaras XML1 Introduction to XML Leonidas Fegaras.
41
CSE 6331 © Leonidas Fegaras XML 1 Introduction to XML Leonidas Fegaras
-
Upload
eileen-davis -
Category
Documents
-
view
226 -
download
2
Transcript of CSE 6331 © Leonidas Fegaras XML1 Introduction to XML Leonidas Fegaras.

CSE 6331 © Leonidas Fegaras XML 1
Introduction to XML
Leonidas Fegaras

CSE 6331 © Leonidas Fegaras XML 2
Traditional DB Applications
• Typically business oriented
• Large amount of data
• Data is well-structured, normalized, with predefined schema
• Large number of concurrent users (transactions)
• Simple data, simple queries, and simple updates
• Typically update intensive
• Small transactions
• High performance, high availability, scalability
• Data integrity and security are of major importance
• Good administrative support, nice GUIs

CSE 6331 © Leonidas Fegaras XML 3
Document Applications
• Human friendly: what-you-see-is-what-you-get paradigm
• Focus on presentation
• Information is divided into multiple small documents
• Mostly static
• Implicit structure: section, subsection, paragraph, etc
• Meta-data: title, author, date, indexing keywords, etc
• Content structure: form/layout, inter-relationships, references
• Tagging: eg, <p> for new paragraph
• Operations: retrieving, editing, spell-checking, printing, etc
• Information retrieval: keyword queries– most successful in web search engines (eg, Google)

CSE 6331 © Leonidas Fegaras XML 4
Internet Applications
Internet applications• use heterogeneous, complex, hierarchical, fast-evolving,
unstructured/semistructured data• access mostly read-only data• need 100% availability• manage millions of users world-wide• have high-performance requirements• are concerned with security (encryption)• like to customize data in a personalized manner• expect to gain user’s trust for business-to-consumer
transactions.
Internet users choose speed and availability over correctness

CSE 6331 © Leonidas Fegaras XML 5
Electronic Commerce
• Currently, mostly business-to-business (B2B) rather than business-to-consumer (B2C) interactions
• Focus on selling and buying:– Order management
– Product catalogs
– Product configuration
• Sales and marketing
• Education and training
• Web services
• Communities

CSE 6331 © Leonidas Fegaras XML 6
Other Web Applications
• Web services– Many standards: SOAP, WSDL, UDDI
• Web integration– Heterogeneous data sources and types– Thousands of web-accessible data sources– Dynamic data– Data warehouses
• Web publishing– Access different types of content from browsers (PDF, HTML, XML)– Structured, dynamic, customized/personalized content– Integration with application– Accessible via major gateways and search engines
• Application integration– Transformation between different data formats (eg, XML, HTML)– Integration of multiple applications

CSE 6331 © Leonidas Fegaras XML 7
Current Internet Application Architectures
Architecture:
• Server-Tier: relational databases and gateways to diverse data sources, such as, files, OLE/DB etc. Use of enterprise servers
• Middle-Tier: provides data integration & distribution, query, etc. Consists of a web server and an application server
• Client-Tier: mostly a web browser, may use CGI scripts or Java
Characteristics:
• Customization is achieved at the server site (customer data in a database) with some data at the client site (cookies)
• Load balancing is typically hardware based (multiple servers, DNS routers)

CSE 6331 © Leonidas Fegaras XML 8
HTML
<html>
<head><title>My Web Page</title></head>
<body>
<h1>Introduction</h1>
Look at <a href=”http://lambda.uta.edu/index.html”>this document</a>
<img src=”image.jpg” width=100 height=50>
</body>
</html>
• It is very simple: human readable, can be edited by any editor
• It reflects document presentation, not the semantics or structure of data
• Universal: portable to any platform
• HTML pages are connected through hypertext links
• HTML pages can be located using web search engines
attribute name attribute value
opening tag
closing tag
hypertext link

CSE 6331 © Leonidas Fegaras XML 9
XML
XML (eXtensible Markup Language) is a textual language for representing and exchanging data on the web
• It is designed to improve the functionality of the Web by providing more flexible and adaptable information identification
• Based on SGML
• It was developed around 1996
• It is called extensible because– it is not a fixed format like HTML (a single, predefined markup
language)
– it is actually a metalanguage (a language for describing other languages) which lets you design your own customized markup languages for limitless different types of documents

CSE 6331 © Leonidas Fegaras XML 10
XML (cont.)
• XML can be untyped (semistructured), but there are standards now for schema conformance– DTD
– XML Schema
• Without schema, an XML document is well-formed if it satisfies simple syntactic constraints:– proper nesting of start and end tags
• With a schema, an XML document is valid if its structure conforms to a DTD or an XML Schema

CSE 6331 © Leonidas Fegaras XML 11
Example
<people>
<person> <name> Leonidas Fegaras </name> <tel> (817) 272-3629 </tel> <email> [email protected] </email> </person>
<person> <name> Ramez Elmasri </name> <tel> (817) 272-2348 </tel> <email> [email protected] </email> </person></people>

CSE 6331 © Leonidas Fegaras XML 12
Why XML is so Popular?
• It looks like HTML– simple, human-readable, easy to learn, universal
• Flexible & extensible, since you can represent any kind of data– unlike HTML
• HTML describes the presentation while XML describes the content
• Precise– well-formed: properly nested XML tags
– valid: its structure may conform to a DTD or an XML Schema
• Supported by the W3C– trusted and adopted by industry
• Many standards around XML: schemas, query languages, etc

CSE 6331 © Leonidas Fegaras XML 13
What XML has to do with Databases?
• XML is an important standardization for data representation and exchange, but still needs– to store and query large repositories of XML documents
– data models and schema representations
– query languages, data indexing, query optimizers
– updates, view maintenance
– concurrency, distribution, security, etc
• Example application:– an XML data repository distributed in a peer-to-peer network
– answer queries, such as:• find all books whose author is Smith and whose title contains the word “Web”
– much like a web search engine, but for XML, ... and for more precise querying

CSE 6331 © Leonidas Fegaras XML 14
XML Syntax
• XML consists of tags and text
• XML documents conform to the following grammar:
XMLdocument ::= Pi* Element Pi*
Element ::= Stag (char | Pi | Element)* Etag
Stag ::= '<' Name Attributes '>'
Etag ::= '</' Name '>'
Pi ::= '<?' char* '?>'
Attributes ::= ( Name '=' String )*
String ::= '"' char* '"'
• Tags come in pairs <date>8/25/2004</date> and must be properly nested:
<person> <name> ... </name> ... </person> --- valid nesting
<person> <name> ... </person> ... </name> --- invalid nesting
• Text is bounded by tags. PCDATA: parsed character data. eg,
<title> The Big Sleep </title>
<year> 1935 </ year>

CSE 6331 © Leonidas Fegaras XML 15
XML Elements
• An element is a segment of an XML document between an opening and the matching closing tags
<person> <name> Ramez Elmasri </name> <tel> (817) 272-2348 </tel> <email> [email protected] </email></person>
• An element may contain a mixture of sub-elements and PCDATA
<title>An <em>element</em> is a segment</title>
• An abbreviation: for an element with empty content, we can use:
<tagname ... />
instead of:
<tagname ...></tagname>

CSE 6331 © Leonidas Fegaras XML 16
Representing Data Using XML
● Nesting tags can be used to express various structures, such as a record:
<person> <name> Ramez Elmasri </name><tel> (817) 272-2348 </tel><email> [email protected] </email>
</person>
• We can represent a list by using the same tag repeatedly:<addresses>
<person> ... </person><person> ... </person><person> ... </person>
...</addresses>

CSE 6331 © Leonidas Fegaras XML 17
XML structure
XML:<person>
<name> Ramez Elmasri </name><tel> (817) 272-2348 </tel><email> [email protected] </email>
</person>
is Lisp-like:(person (name “Ramez Elmasri”)
(tel “(817) 272-2348”)
(email “[email protected]”))
and tree-like:
person
name tel email
Ramez Elmasri (817) 272-2348 [email protected]

CSE 6331 © Leonidas Fegaras XML 18
Attributes
• An opening tag may contain attributes– typically used to describe the content of an element<author ssn="2787901">
<name>Ramez Elmasri</name>
<email> [email protected] </email>
</author>
• It's not always clear when to use attributes<author>
<ssn>2787901</ssn>
<name>Ramez Elmasri</name> <email> [email protected] </email>
</author>
• ID attributes are special: must be unique within the document
• An IDref attribute must refer to an existing ID in the same doc

CSE 6331 © Leonidas Fegaras XML 19
Referencing Elements Using IDs/IDrefs
<family>
<person id="jane" mother="mary" father="john">
<name> Jane Doe </name>
</person>
<person id="john" children="jane jack">
<name> John Doe </name> <mother/>
</person>
<person id="mary" children="jane jack">
<name> Mary Doe </name>
</person>
<person id="jack" mother=”mary" father="john">
<name> Jack Doe </name>
</person>
</family>

CSE 6331 © Leonidas Fegaras XML 20
A Complete Example<?xml version="1.0"?><!DOCTYPE bib SYSTEM "bib.dtd"><bib> <vendor id="id0_1"> <name>Amazon</name> <email>[email protected]</email> <phone>1-800-555-9999</phone> <book> <title>Unix Network Programming</title> <publisher>Addison Wesley</publisher> <year>1995</year> <author> <firstname>Richard</firstname> <lastname>Stevens</lastname> </author> <price>38.68</price> </book> <book> <title>An Introduction to Object-Oriented Design</title> <publisher>Addison Wesley</publisher> <year>1996</year> <author> <firstname>Jo</firstname> <lastname>Levin</lastname> </author> <author> <firstname>Harold</firstname> <lastname>Perry</lastname> </author> <price>11.55</price> </book> </vendor></bib>
CSE 6331 © Leonidas Fegaras XML 21
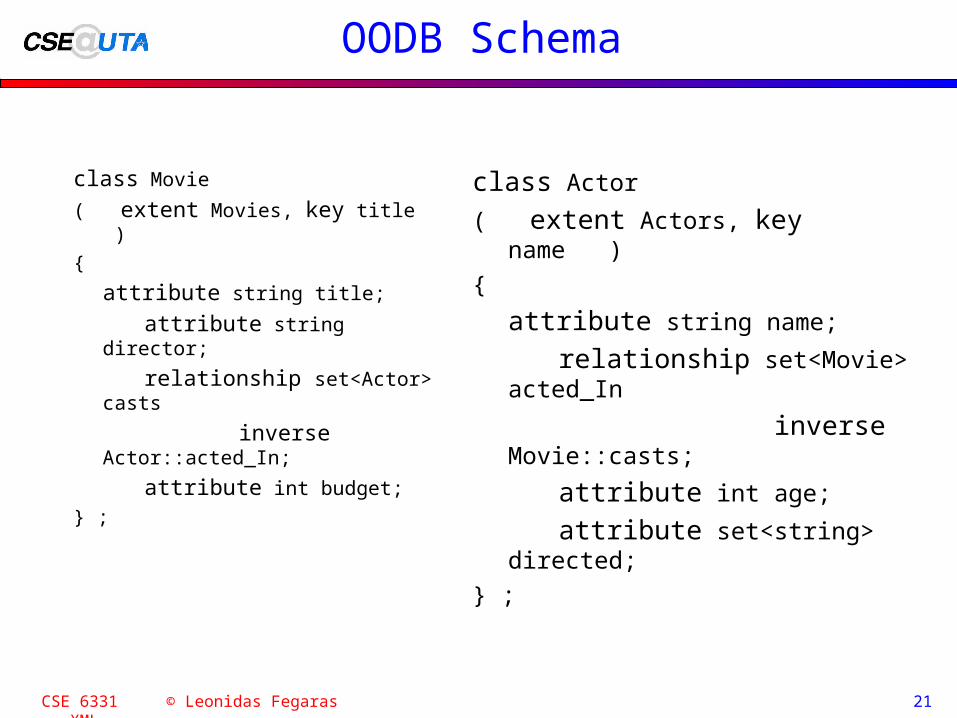
OODB Schema
class Movie
( extent Movies, key title )
{
attribute string title;
attribute string director;
relationship set<Actor> casts
inverse Actor::acted_In;
attribute int budget;
} ;
class Actor
( extent Actors, key name )
{
attribute string name;
relationship set<Movie> acted_In
inverse Movie::casts;
attribute int age;
attribute set<string> directed;
} ;

CSE 6331 © Leonidas Fegaras XML 22
In XML …
<db>
<movie id=“m1” casts=“a1 a3”>
<title>Waking Ned Divine</title>
<director>Kirk Jones III</director>
<budget>100,000</budget>
</movie>
<movie id=“m2” casts=“a2 a9 a21”>
<title>Dragonheart</title>
<director>Rob Cohen</director>
<budget>110,000</budget>
</movie>
<movie id=“m3” casts=“a1 a8”>
<title>Moondance</title>
<director>Dagmar Hirtz</director>
<budget>90,000</budget>
</movie>
<actor id=“a1” acted_in=“m1 m3 m78”> <name>David Kelly</name> <age>55</age> </actor> <actor id=“a2” acted_in=“m2 m9 m11”> <name>Sean Connery</name> <age>68</age> </actor> <actor id=“a3” acted_in=“m1 m35”> <name>Ian Bannen</name> <age>45</age> </actor> :</db>

CSE 6331 © Leonidas Fegaras XML 23
DTD: Document Type Descriptor
• A DTD imposes a structure on an XML document
• Not quite a typing system– it is purely syntactic
– now replaced by XML Schema
• Uses regular expressions to specify structure– firstname an element with tag name firstname
– book* zero or more books
– year? an optional year
– firstname,lastname a firstname followed by lastname
– book | journal either a book or a journal

CSE 6331 © Leonidas Fegaras XML 24
Example of XML Data
<bib>
<vendor id="id0_1">
<name>Amazon</name>
<email>[email protected]</email>
<phone>1-800-555-9999</phone>
<book>
<title>Unix Network Programming</title>
<publisher>Addison Wesley</publisher>
<year>1995</year>
<author>
<firstname>Richard</firstname>
<lastname>Stevens</lastname>
</author>
<price>38.68</price>
</book>
...
</vendor>
</bib>

CSE 6331 © Leonidas Fegaras XML 25
DTD Example
<?xml encoding="ISO-8859-1"?>
<!ELEMENT bib (vendor)*>
<!ELEMENT vendor (name, email, book*)>
<!ATTLIST vendor id ID #REQUIRED>
<!ELEMENT book (title, publisher?, year?, author+, price)>
<!ELEMENT author (firstname?, lastname)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT email (#PCDATA)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT publisher (#PCDATA)>
<!ELEMENT year (#PCDATA)>
<!ELEMENT firstname (#PCDATA)>
<!ELEMENT lastname (#PCDATA)>
<!ELEMENT price (#PCDATA)>

CSE 6331 © Leonidas Fegaras XML 26
Summary of the DTD Syntax
• A tagged element in a DTD is defined by<!ELEMENT name e>
where e is a DTD expression
• If e, e1, e2 are DTD expressions, then so are:– EMPTY empty content
– #PCDATA any text
– A an element with tag name A
– e1,e2 e1 followed by e2
– e1 | e2 either e1 or e2
– e* zero or more occurrences of e
– e+ one or more occurrences of e
– e? optional e (zero or one occurrences)
– (e)
• Note: tagged elements are global– must be defined once in a DTD

CSE 6331 © Leonidas Fegaras XML 27
DTD Syntax (cont.)
• Attribute specification:<!ATTLIST name (attribute-name type accuracy?)+>
type is:• ID must be unique within the document
• IDREF a reference to an existing ID
• IDREFS multiple IDREFs
• CDATA any string
accuracy is #REQUIRED, #IMPLIED, #FIXED 'value', value 'v1 ... vn'
• ID, IDref, and IDrefs attributes are not typed!
• Example:<!ELEMENT person (#PCDATA)>
<!ATTLIST person
id ID #REQUIRED
children IDrefs #IMPLIED >
the id attribute is required while the children attribute is optional
CSE 6331 © Leonidas Fegaras XML 28
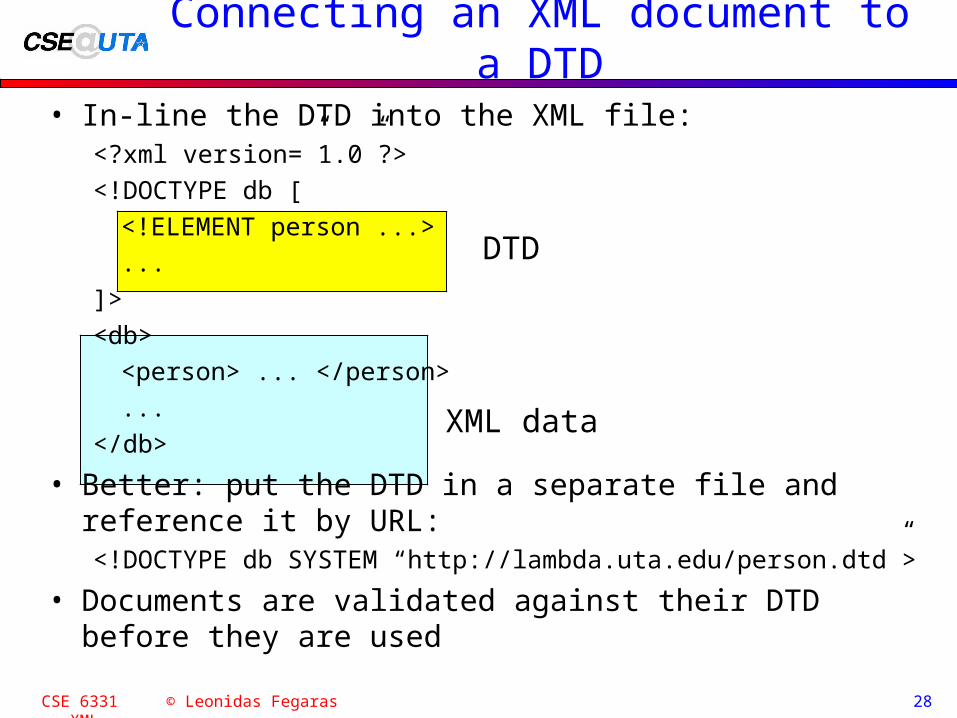
Connecting an XML document to a DTD
• In-line the DTD into the XML file:<?xml version=”1.0”?>
<!DOCTYPE db [
<!ELEMENT person ...>
...
]>
<db>
<person> ... </person>
...
</db>
• Better: put the DTD in a separate file and reference it by URL:<!DOCTYPE db SYSTEM “http://lambda.uta.edu/person.dtd”>
• Documents are validated against their DTD before they are used
XML data
DTD

CSE 6331 © Leonidas Fegaras XML 29
Recursive DTDs
We want to capture a person with a mother and a father
• First attempt:<!ELEMENT person (name, address, person, person)>
where the first person is the mother while the second is the father
• Second attempt:<!ELEMENT person (name, address, person?, person?)>
• Third attempt:<!ELEMENT person (name, address)>
<!ATTLIST person
id ID #REQUIRED
mother IDREF #IMPLIED
father IDREF #IMPLIED>
CSE 6331 © Leonidas Fegaras XML 30
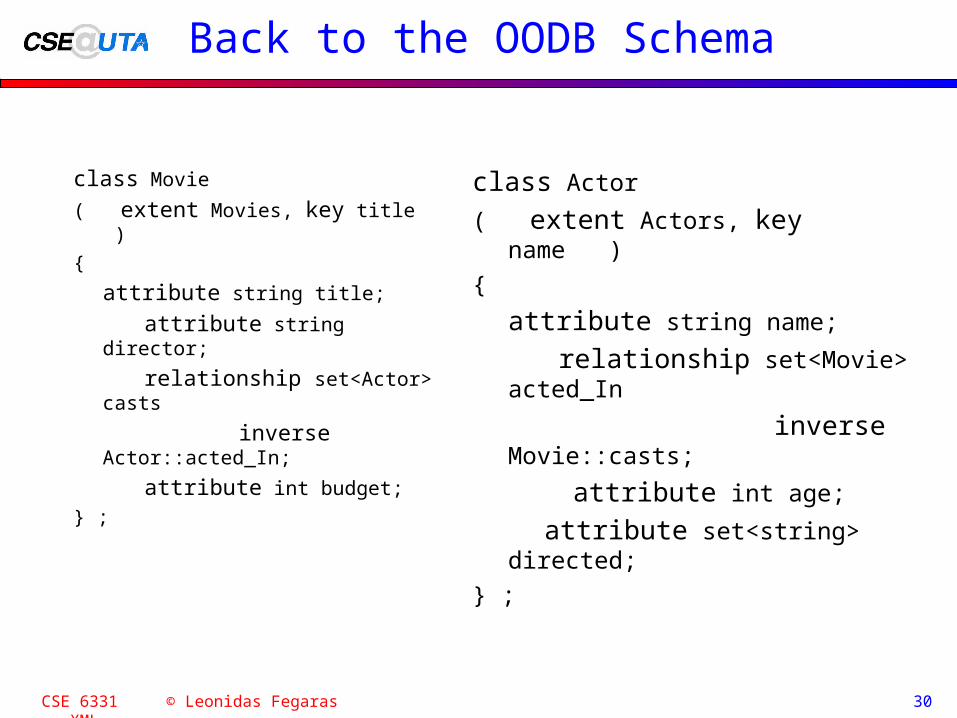
Back to the OODB Schema
class Movie
( extent Movies, key title )
{
attribute string title;
attribute string director;
relationship set<Actor> casts
inverse Actor::acted_In;
attribute int budget;
} ;
class Actor
( extent Actors, key name )
{
attribute string name;
relationship set<Movie> acted_In
inverse Movie::casts;
attribute int age;
attribute set<string> directed;
} ;

CSE 6331 © Leonidas Fegaras XML 31
DTD
<!ELEMENT db (movie+, actor+)>
<!ELEMENT movie (title, director, budget)>
<!ATTLIST movie id ID #REQUIRED
casts IDREFS #REQUIRED>
<!ELEMENT title (#PCDATA)>
<!ELEMENT director (#PCDATA)>
<!ELEMENT budget (#PCDATA)>
<!ELEMENT actor (name, age, directed*)>
<!ATTLIST actor id ID #REQUIRED
acted_in IDREFS #REQUIRED>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT directed (#PCDATA)>

CSE 6331 © Leonidas Fegaras XML 32
XML Namespaces
• When merging multiple docs together, name collisions may occur• A namespace is a mechanism for uniquely naming tagnames and
attribute names to avoid name conflicts• Tag/attribute names are now qualified names (QNames)
(namespace ':')? localname
example: bib:author
• A document may use multiple namespaces• A DTD has its own namespace in which all names are unique• A namespace in an XML doc is defined as an attribute:
xmlns:bib=“http://lambda.uta.edu/biblio.dtd”
where bib is the namespace name and the URL is the location of the DTD
• The default namespace is defined asxmlns=“URL”
If not defined, it is the global namespace

CSE 6331 © Leonidas Fegaras XML 33
Example
<item xmlns=“http://www.acme.com/jp#supplies” xmlns:toy= “http://www.acme.com/jp#toys”><name>backpack</name><feature> <toy:item> <toy:name>cyberpet</toy:name> </toy:item></feature></item>

CSE 6331 © Leonidas Fegaras XML 34
Query Languages for XML
• Need a language for XML data for– extracting fragments (querying)
– restructuring (data transformation)
– integrating (eg, combining multiple XML documents)
– browsing
– presentation (eg, from XML to HTML)
• We will first learn XPath– used in extracting fragments from a single document
– many XML query languages are based on XPath
• We will briefly discuss XSLT– for extracting, restructuring, and presentation over a single document
• We will focus later on XQuery– a full-fledged query language
– much like OQL

CSE 6331 © Leonidas Fegaras XML 35
XPath
• Describes a single navigation path in an XML document• Selects a sequence of nodes reachable by the path
– the order of nodes is the document order (which is the preorder of the XML tree: every node occurs before its children)
• Main construct: axis navigation• Consists of one or more navigation steps separated by /• A navigation step is a triplet
axis :: node-test predicate*
• Each navigation path is evaluated relative to a context node• Examples:
– child::bib /descendant::author– descendant::book [ child::author/child::name = “Smith” ] /child::title
• Most people use shorthands– bib//author– //book[author/name=“Smith”]/title
CSE 6331 © Leonidas Fegaras XML 36
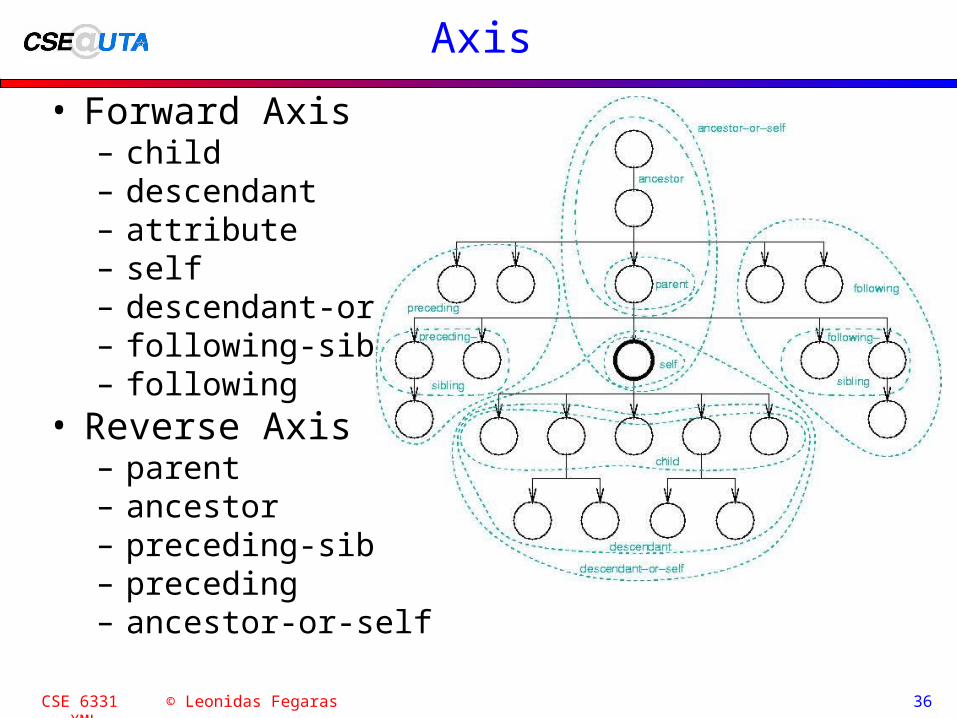
Axis
• Forward Axis– child– descendant– attribute– self– descendant-or-self– following-sibling– following
• Reverse Axis– parent– ancestor– preceding-sibling– preceding– ancestor-or-self

CSE 6331 © Leonidas Fegaras XML 37
Node Test
• person any element node whose name is person• * any element node regardless of its name• @price any attribute whose name is price• @* any attribute, regardless of its name• node() any node• text() any text node• element() any element node• element(person) any element node whose name is person• element(person, surgeon) any element node whose name is person, and
whose type annotation is surgeon• element(*, surgeon) any element node whose type annotation is
surgeon, regardless of its name• attribute() any attribute node• attribute(price) any attribute whose name is price• attribute(*, xs:decimal) any attribute whose type annotation is
xs:decimal, regardless of its name.

CSE 6331 © Leonidas Fegaras XML 38
Abbreviated Syntax
• The attribute axis child:: can be omitted– section/para is an abbreviation for child::section/child::para,
– section/@id is an abbreviation for child::section/attribute::id
• … unless the axis step contains an attribute test, … then the default axis is attribute– section/attribute(id) is short for child::section/attribute::attribute(id)
• The attribute axis attribute:: can be abbreviated by @– para[@type="warning"] is short for child::para[attribute::type="warning"]
• // is replaced by /descendant-or-self::node()/– div//para is short for child::div/descendant-or-self::node()/child::para
• .. is short for parent::node()– ../title is short for parent::node()/child::title

CSE 6331 © Leonidas Fegaras XML 39
Most Common Steps
XPath step new context nodes/author all the children of a context node with tagname author
/* all the children of the context node
//book the context node and all its descendants with tagname book
//* the context node and all its descendants
/@ssn the attribute value of the attribute name ssn of the context node
//@ssn like /@ssn but for all descendants
/.. parent of context node
/text() the text of the context node
• Examples:– /book/chapter/section– //chapter/*– //book/author/@*
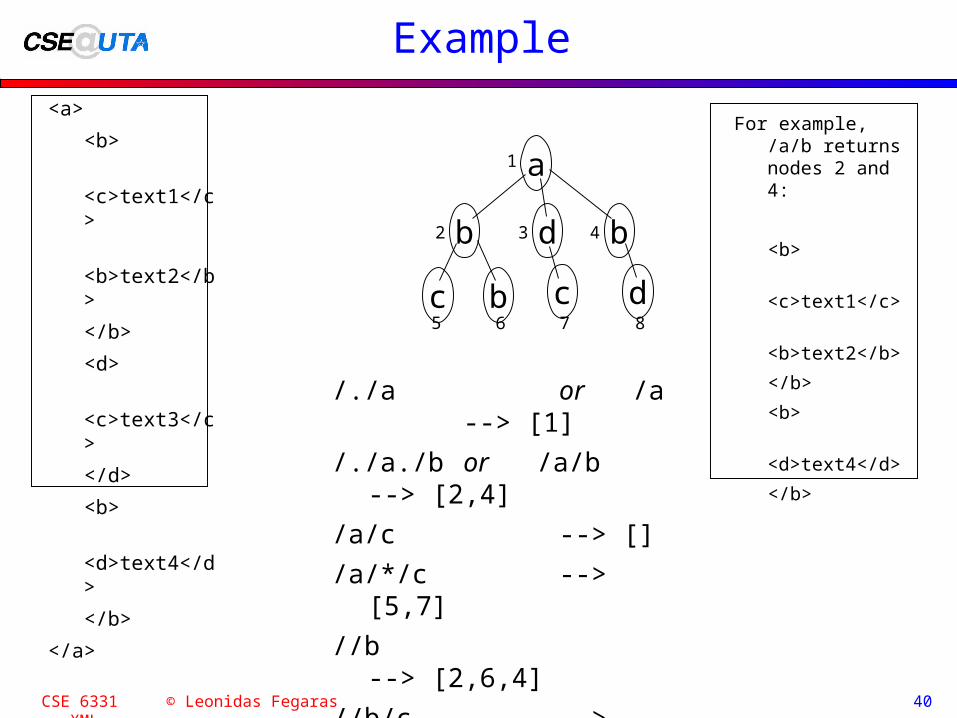
CSE 6331 © Leonidas Fegaras XML 40
Example
<a>
<b>
<c>text1</c>
<b>text2</b>
</b>
<d>
<c>text3</c>
</d>
<b>
<d>text4</d>
</b>
</a>
a
b
c b
d
c
b
d
/./a or /a --> [1]
/./a./b or /a/b --> [2,4]
/a/c --> []
/a/*/c --> [5,7]
//b --> [2,6,4]
//b/c --> [5]
/a//c --> [5,7]
1
32 4
75 6 8
For example, /a/b returns nodes 2 and 4:
<b>
<c>text1</c>
<b>text2</b>
</b>
<b>
<d>text4</d>
</b>

CSE 6331 © Leonidas Fegaras XML 41
Predicates
• Many variations– //book[10] the tenth child node of the context node (tenth
book)
– //book[last()] the last child node of the context node (last book)
– //book[author] true, if the book has at least one author
– //book[author/name] true, if there is an author/name in the book
– //book[author/name=“Smith”] true if the author name is Smith
• Examples/bib/book[@price < 100]/title
/bib/book[author/text()]
//author[name/firstname=“John”][name/lastname=“Smith”]/title
/bib/book/author[name/firstname][address[zip=1234][city]]/name/lastname













![[PPT]The Dictatorship of Rafael Leonidas Trujillo Molinawebhost.lclark.edu/woodrich/POWERPOINT/WarmuthTrujillo.ppt · Web viewThe Dictatorship of Rafael Leonidas Trujillo Molina Nicola](https://static.fdocuments.us/doc/165x107/5b197dc97f8b9a37258cc533/pptthe-dictatorship-of-rafael-leonidas-trujillo-web-viewthe-dictatorship-of.jpg)




