
CS:APP Chapter 4 Computer Architecture Instruction Set ... · 16-bit processor. Basis for IBM PC &...
36
Randal E. Bryant Carnegie Mellon University CS:APP CS:APP Chapter 4 Computer Architecture Instruction Set Architecture http://csapp.cs.cmu.edu Adaptation par J.Bétréma
Transcript of CS:APP Chapter 4 Computer Architecture Instruction Set ... · 16-bit processor. Basis for IBM PC &...

Randal E. Bryant
Carnegie Mellon University
CS:APP
CS:APP Chapter 4Computer ArchitectureInstruction SetArchitecture
http://csapp.cs.cmu.edu
Ada
ptat
ion
par J
.Bét
rém
a
– 2 – CS:APP
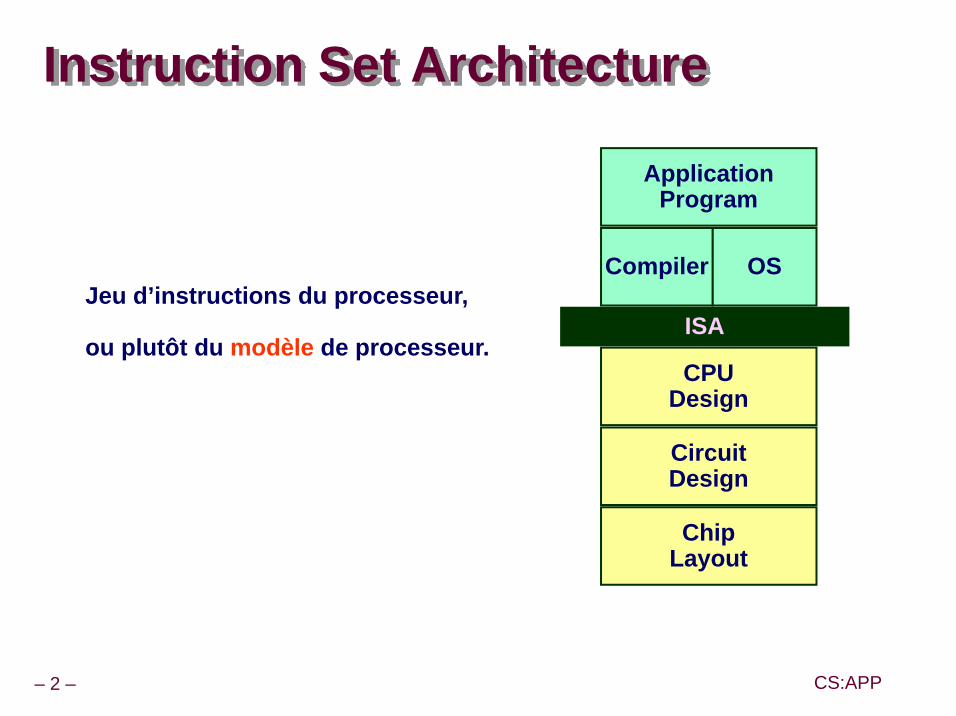
Instruction Set Architecture
ISA
Compiler OS
CPUDesign
CircuitDesign
ChipLayout
ApplicationProgram
Jeu d’instructions du processeur,
ou plutôt du modèle de processeur.

– 3 – CS:APP
X86 Evolution: Programmer’s ViewName Date Transistors
8086 1978 29K16-bit processor. Basis for IBM PC & DOSLimited to 1MB address space. DOS only gives you 640K
386 1985 275KExtended to 32 bits. Added “flat addressing”Capable of running UnixLinux/gcc uses no instructions introduced in later models
Pentium 1993 3.1M

– 4 – CS:APP
X86 Evolution: Programmer’s ViewName Date Transistors
Pentium III 1999 8.2MAdded “streaming SIMD” instructions for operating on 128-bit vectors of 1, 2, or 4 byte integer or floating point dataOur fish machines
Pentium 4 2001 42MAdded 8-byte formats and 144 new instructions for streaming SIMD mode

– 5 – CS:APP
X86 Evolution: ClonesAdvanced Micro Devices (AMD)
HistoricallyAMD has followed just behind IntelA little bit slower, a lot cheaper
RecentlyRecruited top circuit designers from Digital Equipment Corp.Exploited fact that Intel distracted by IA64Now are close competitors to Intel
Developing own extension to 64 bits

– 6 – CS:APP
New Species: IA64Name Date Transistors
Itanium 2001 10MExtends to IA64, a 64-bit architectureRadically new instruction set designed for high performanceWill be able to run existing IA32 programs
On-board “x86 engine”
Joint project with Hewlett-Packard
Itanium 2 2002 221MBig performance boost
– 7 – CS:APP
%eax%ecx%edx%ebx
%esi%edi%esp%ebp
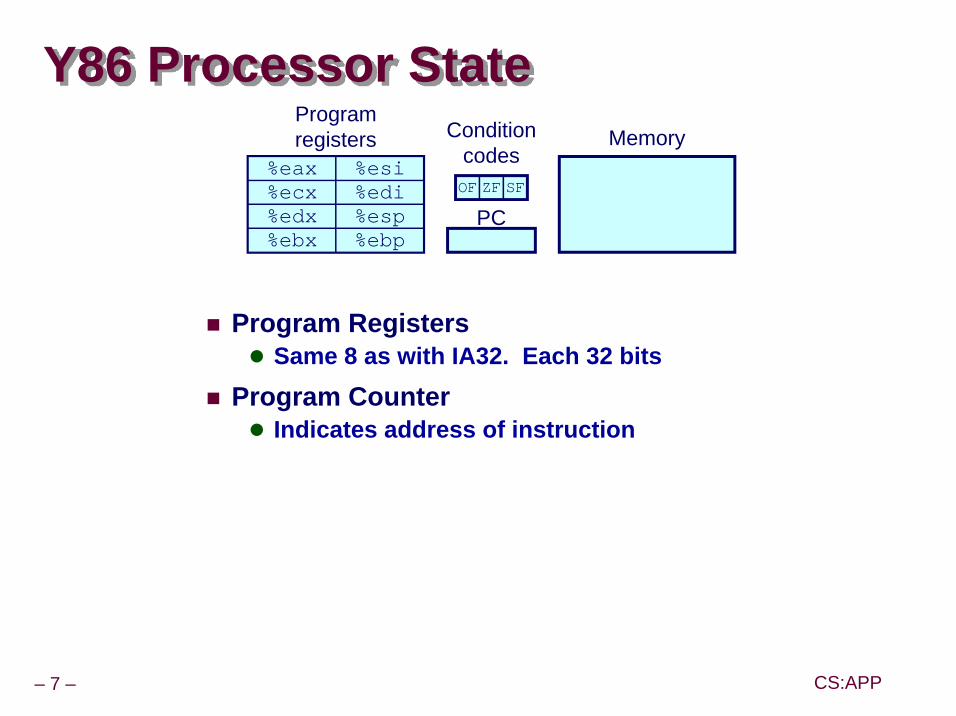
Y86 Processor State
Program RegistersSame 8 as with IA32. Each 32 bits
Program CounterIndicates address of instruction
Program registers Condition
codes
PC
Memory
OF ZF SF

– 8 – CS:APP
%eax%ecx%edx%ebx
%esi%edi%esp%ebp
Condition codes
Single-bit flags set by arithmetic or logical instructions» OF: Overflow ZF: Zero SF:Negative
Il manque CF : Carry (retenue). On travaille donc sur des entiers relatifs (“avec signe”).Correspondance avec la notation NZVC :
» N = SF Z = ZF V = OF
Program registers Condition
codes
PC
Memory
OF ZF SF
– 9 – CS:APP
%eax%ecx%edx%ebx
%esi%edi%esp%ebp
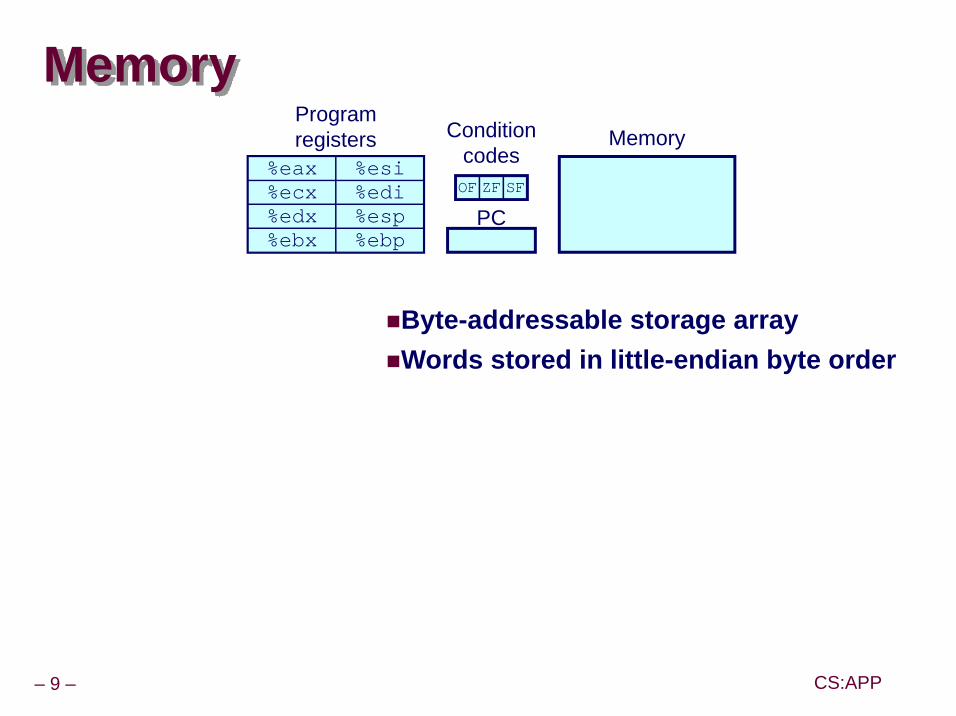
MemoryProgram registers Condition
codes
PC
Memory
OF ZF SF
Byte-addressable storage arrayWords stored in little-endian byte order

– 10 – CS:APP
Machine WordsMachine Has “Word Size”
Nominal size of integer-valued dataIncluding addresses
Most current machines are 32 bits (4 bytes)Limits addresses to 4GBBecoming too small for memory-intensive applications
High-end systems are 64 bits (8 bytes)Potentially address ≈ 1.8 X 1019 bytes
Machines support multiple data formatsFractions or multiples of word sizeAlways integral number of bytes
– 11 – CS:APP
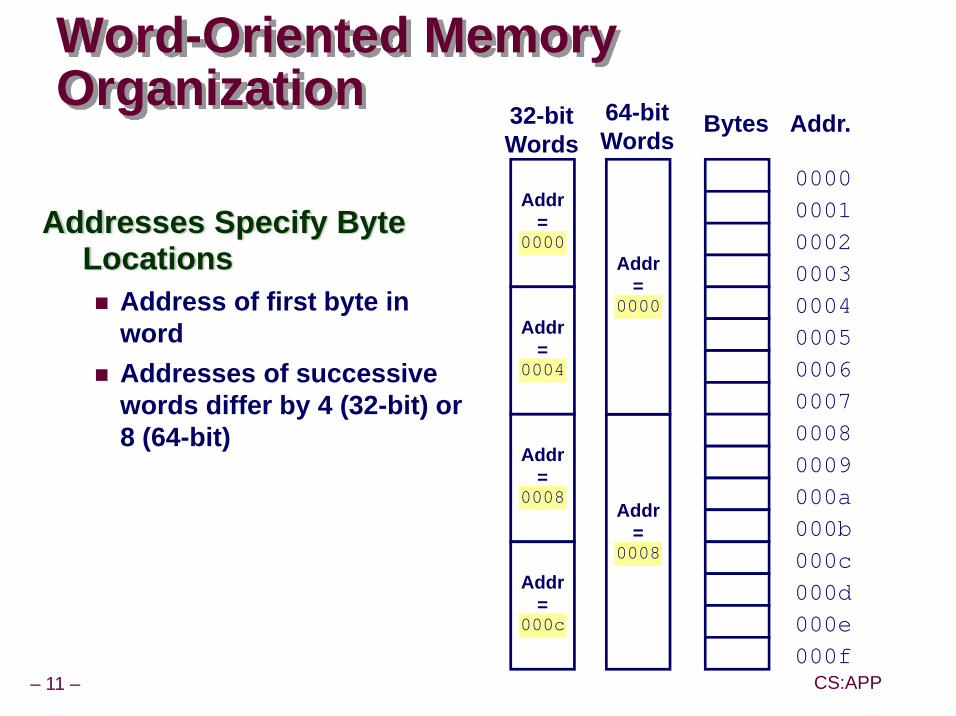
Word-Oriented Memory Organization
Addresses Specify Byte Locations
Address of first byte in wordAddresses of successive words differ by 4 (32-bit) or 8 (64-bit)
0000000100020003000400050006000700080009000a000b
32-bitWords
Bytes Addr.
000c000d000e000f
64-bitWords
Addr =
??
Addr =
??
Addr =
??
Addr =
??
Addr =
??
Addr =
??
0000
0004
0008
000c
0000
0008

– 12 – CS:APP
Byte Ordering ExampleBig Endian
Least significant byte has highest address
Little EndianLeast significant byte has lowest address
ExampleVariable n has 4-byte representation 0x01234567Address given by &n is 0x100
0x100 0x101 0x102 0x103
01 23 45 67
0x100 0x101 0x102 0x103
67 45 23 01
Big Endian
Little Endian
01 23 45 67
67 45 23 01

– 13 – CS:APP
Y86 InstructionsFormat
1--6 bytes of information read from memoryCan determine instruction length from first byteNot as many instruction types, and simpler encoding than with IA32
Each accesses and modifies some part(s) of the program statePC incrémenté selon la longueur de l’instruction, pour pointer sur l’instruction suivante

– 14 – CS:APP
Encoding RegistersEach register has 4-bit ID
Same encoding as in IA32IA32 utilise seulement 3 bits pour coder un registre
Register ID 8 indicates “no register”Will use this in our hardware design in multiple places
%eax%ecx%edx%ebx
%esi%edi%esp%ebp
0123
6745

– 15 – CS:APP
Instruction ExampleAddition Instruction
Add value in register rA to that in register rBStore result in register rBNote that Y86 only allows addition to be applied to register data
Set condition codes based on resulte.g., addl %eax,%esi Encoding: 60 06
Two-byte encodingFirst indicates instruction typeSecond gives source and destination registers
addl rA, rB 6 0 rA rB
Encoded Representation
Generic Form

– 16 – CS:APP
Arithmetic and Logical OperationsRefer to generically as “OPl”Encodings differ only by “function code”Set condition codes as side effectManquent (entre autres) : inc (incrémentation), dec, sh (shift = décalage) …
addl rA, rB 6 0 rA rB
subl rA, rB 6 1 rA rB
andl rA, rB 6 2 rA rB
xorl rA, rB 6 3 rA rB
Add
Subtract (rA from rB)
And
Exclusive-Or
Instruction Code Function Code

– 17 – CS:APP
Arithmetic and Logical Operations (2)
Dans les architectures RISC (Reduced Instruction Set Computer) les opérations portent sur 3 registres :
• deux registres sources pour les opérandes• un registre destination pour le résultat
Attention : ici (x86 ou Y86) le second registre sert aussi de destination, et le second opérande est donc écrasé.

– 18 – CS:APP
Move Operations
Like the IA32 movl instructionSimpler format for memory addressesGive different names to keep them distinct
rrmovl rA, rB 2 0 rA rB Register --> Register
Immediate --> Registerirmovl V, rB 3 0 8 rB V
Register --> Memoryrmmovl rA, D(rB) 4 0 rA rB D
Memory --> Registermrmovl D(rB), rA 5 0 rA rB D
– 19 – CS:APP
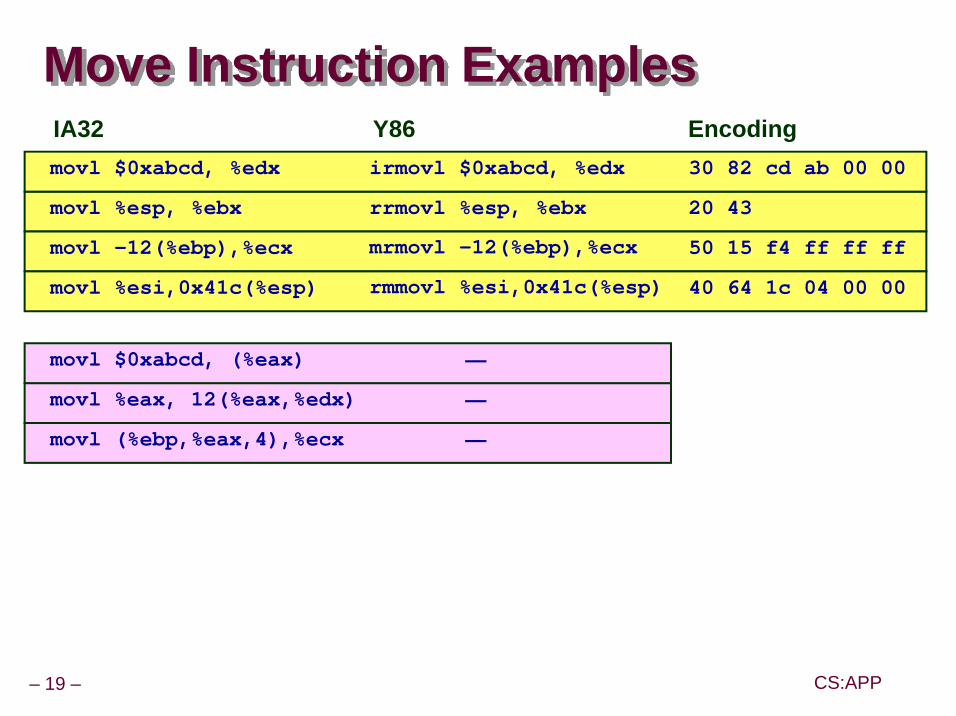
Move Instruction Examples
irmovl $0xabcd, %edx movl $0xabcd, %edx 30 82 cd ab 00 00
IA32 Y86 Encoding
rrmovl %esp, %ebx movl %esp, %ebx 20 43
mrmovl -12(%ebp),%ecxmovl -12(%ebp),%ecx 50 15 f4 ff ff ff
rmmovl %esi,0x41c(%esp)movl %esi,0x41c(%esp)
—movl $0xabcd, (%eax)
—movl %eax, 12(%eax,%edx)
—movl (%ebp,%eax,4),%ecx
40 64 1c 04 00 00

– 20 – CS:APP
Loadmrmovl 12(%ebp),%ecx
mrmovl (%ebp),%ecx
mrmovl 0x1b8,%ecx
le registre ebp sert de pointeur
adresse absolue de lecture
cas général (déplacement)
Storermmovl %esi,0x41c(%esp)
rmmovl %esi,(%esp)
rmmovl %esi,0x41c
le registre esp sert de pointeur
adresse absolue d’écriture
cas général (déplacement)
Ce sont les instructions coûteuses !

– 21 – CS:APP
Adressage par déplacementmrmovl 12(%ebp),%ecx cas général (déplacement)
rmmovl %esi,0x41c(%esp) cas général (déplacement)
On charge le mot d’adresse ebp + 12 dans le registre ecx.
Load = charger = lire .
On sauvegarde le registre esi à l’adresse esp + 0x41c .
Store = sauve(garde)r = écrire .
– 22 – CS:APP
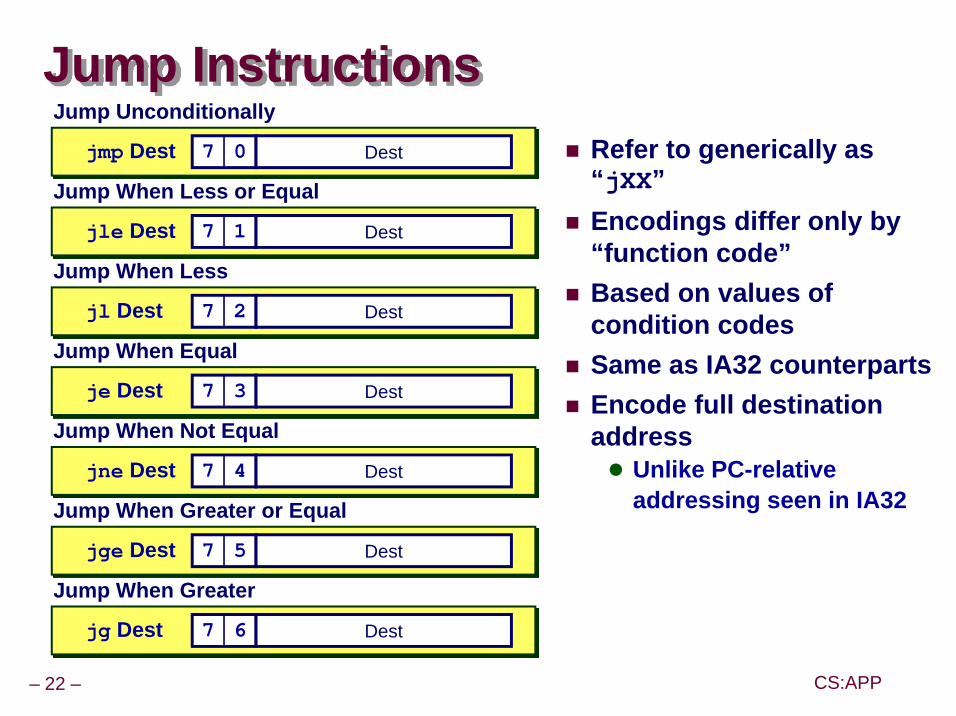
Jump InstructionsRefer to generically as “jXX”Encodings differ only by “function code”Based on values of condition codesSame as IA32 counterpartsEncode full destination address
Unlike PC-relative addressing seen in IA32
jmp Dest 7 0
Jump Unconditionally
Dest
jle Dest 7 1
Jump When Less or Equal
Dest
jl Dest 7 2
Jump When Less
Dest
je Dest 7 3
Jump When Equal
Dest
jne Dest 7 4
Jump When Not Equal
Dest
jge Dest 7 5
Jump When Greater or Equal
Dest
jg Dest 7 6
Jump When Greater
Dest

– 23 – CS:APP
Sauts conditionnelsJump When Less : saut effectué si le résultat de la dernière opération (addl, subl, andl, xorl) est négatif; ne pas oublier l’overflow !
• ( SF = 1 et OF = 0 ) ou ( SF = 0 et OF = 1 )• en résumé SF ≠ OF
Jump When Equal : saut effectué si le résultat de la dernière opération est nul, soit ZF = 1Jump When Less or Equal : SF ≠ OF or ZF = 1
Jump When Greater or Equal : SF = OFJump When Not Equal : ZF = 0Jump When Greater : SF = OF and ZF = 0
Négations :

– 24 – CS:APP
Sauts (suite et fin)Un saut est effectué en modifiant PC .Les instructions rrmovl, irmovl, rmmovl, mrmovl ne modifient jamais les codes de condition.Opérations logiques andl, xorl : ZF et SF ajustés selon résultat de l’opération, OF = 0 (clear).
andl %eax, %eax # ne modifie pas le registre
je ... # saut effectué si eax = 0
jl ... # saut effectué si eax < 0
xorl %eax, %ebx
je ... # saut effectué si eax = ebx
(mais ce test écrase ebx)

– 25 – CS:APP
Miscellaneous Instructions
Don’t do anything
Stop executing instructionsIA32 has comparable instruction, but can’t execute it in user modeWe will use it to stop the simulator
nop 0 0
halt 1 0

– 26 – CS:APP
Code for sum0x401040 <sum>:
0x550x890xe50x8b0x450x0c0x030x450x080x890xec0x5d0xc3
Object Code Assembler
Translates .s into .oBinary encoding of each instructionNearly-complete image of executable codeMissing linkages between code in different files
LinkerResolves references between filesCombines with static run-time libraries
E.g., code for malloc, printf
Some libraries are dynamically linkedLinking occurs when program begins execution
• Total of 13 bytes
• Each instruction 1, 2, or 3 bytes
• Starts at address 0x401040
Dans la vraie vie :
– 27 – CS:APP
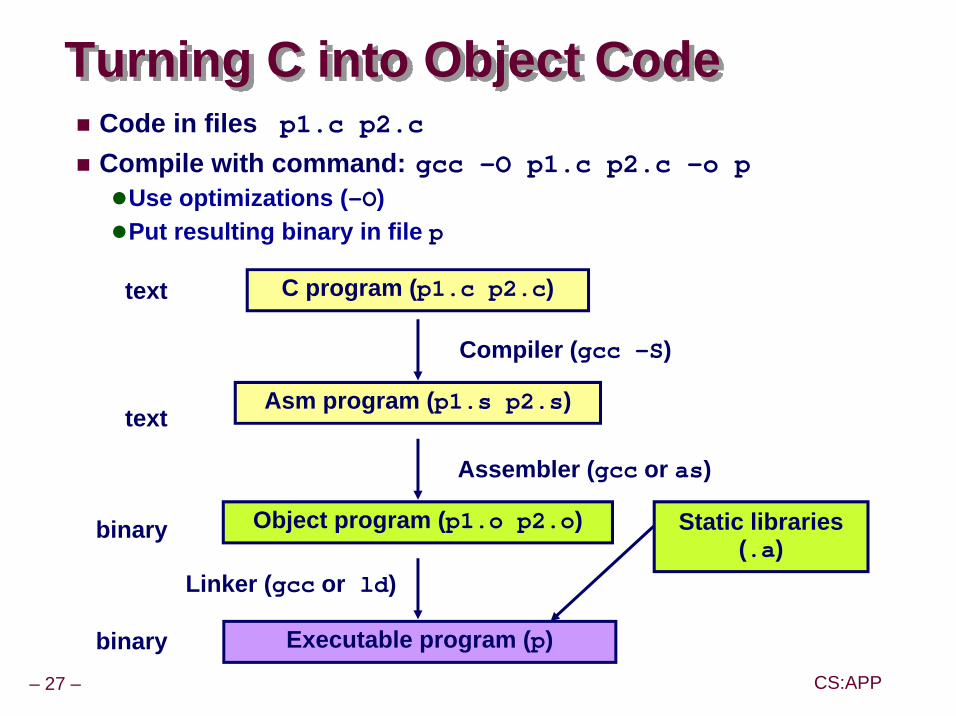
text
text
binary
binary
Compiler (gcc -S)
Assembler (gcc or as)
Linker (gcc or ld)
C program (p1.c p2.c)
Asm program (p1.s p2.s)
Object program (p1.o p2.o)
Executable program (p)
Static libraries (.a)
Turning C into Object CodeCode in files p1.c p2.c
Compile with command: gcc -O p1.c p2.c -o pUse optimizations (-O)Put resulting binary in file p

– 28 – CS:APP
Disassembled00401040 <_sum>:
0: 55 push %ebp1: 89 e5 mov %esp,%ebp3: 8b 45 0c mov 0xc(%ebp),%eax6: 03 45 08 add 0x8(%ebp),%eax9: 89 ec mov %ebp,%espb: 5d pop %ebpc: c3 ret d: 8d 76 00 lea 0x0(%esi),%esi
Disassembling Object Code
Disassemblerobjdump -d p
Useful tool for examining object codeAnalyzes bit pattern of series of instructionsProduces approximate rendition of assembly codeCan be run on either a.out (complete executable) or .o file

– 29 – CS:APP
Pseudo code objet Simulateur Y86
Loop: mrmovl (%ecx),%esi # get *Startaddl %esi,%eax # add to sumirmovl $4,%ebxaddl %ebx,%ecx # Start++irmovl $-1,%ebxaddl %ebx,%edx # Count--jne Loop # Stop when 0
Fichier source .ys
0x057: 506100000000 |Loop: mrmovl (%ecx),%esi0x05d: 6060 | addl %esi,%eax0x05f: 308304000000 | irmovl $4,%ebx 0x065: 6031 | addl %ebx,%ecx0x067: 3083ffffffff | irmovl $-1,%ebx0x06d: 6032 | addl %ebx,%edx0x06f: 7457000000 | jne Loop
Fichier .yo
Assembleur yas

– 30 – CS:APP
Fichier .yo 0x057: 506100000000 |Loop: mrmovl (%ecx),%esi0x05d: 6060 | addl %esi,%eax0x05f: 308304000000 | irmovl $4,%ebx 0x065: 6031 | addl %ebx,%ecx0x067: 3083ffffffff | irmovl $-1,%ebx0x06d: 6032 | addl %ebx,%edx0x06f: 7457000000 | jne Loop
1. Etiquette = adresse calculée par l’assembleur(vrai pour tout assembleur)
2. Fichier « exécuté » par un simulateur

– 31 – CS:APP
CISC Instruction SetsComplex Instruction Set ComputerDominant style through mid-80’s
Stack-oriented instruction setUse stack to pass arguments, save program counterExplicit push and pop instructions
Arithmetic instructions can access memoryaddl %eax, 12(%ebx,%ecx,4)
requires memory read and writeComplex address calculation
Condition codesSet as side effect of arithmetic and logical instructions
PhilosophyAdd instructions to perform “typical” programming tasks

– 32 – CS:APP
RISC Instruction SetsReduced Instruction Set ComputerInternal project at IBM, later popularized by Hennessy (Stanford) and Patterson (Berkeley)
Fewer, simpler instructionsMight take more to get given task doneCan execute them with small and fast hardware
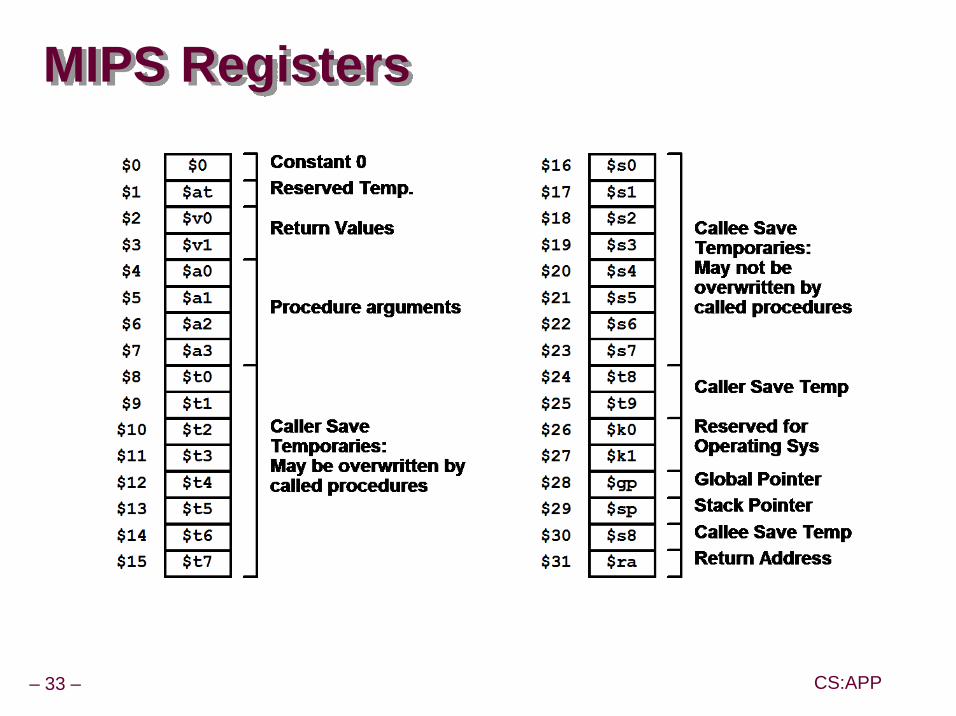
Register-oriented instruction setMany more (typically 32) registersUse for arguments, return pointer, temporaries
Only load and store instructions can access memorySimilar to Y86 mrmovl and rmmovl
No Condition codesTest instructions return 0/1 in register
– 33 – CS:APP
MIPS Registers

– 34 – CS:APP
MIPS Instruction Examples
Op Ra Rb Offset
Op Ra Rb Rd Fn00000R-R
Op Ra Rb ImmediateR-I
Load/Store
addu $3,$2,$1 # Register add: $3 = $2+$1
addu $3,$2, 3145 # Immediate add: $3 = $2+3145
sll $3,$2,2 # Shift left: $3 = $2 << 2
lw $3,16($2) # Load Word: $3 = M[$2+16]
sw $3,16($2) # Store Word: M[$2+16] = $3
Op Ra Rb OffsetBranch
beq $3,$2,dest # Branch when $3 = $2

– 35 – CS:APP
CISC vs. RISCOriginal Debate
Strong opinions!CISC proponents---easy for compiler, fewer code bytesRISC proponents---better for optimizing compilers, can make run fast with simple chip design
Current StatusFor desktop processors, choice of ISA not a technical issue
With enough hardware, can make anything run fastCode compatibility more important
For embedded processors, RISC makes senseSmaller, cheaper, less power

– 36 – CS:APP
SummaryY86 Instruction Set Architecture
Similar state and instructions as IA32Simpler encodingsSomewhere between CISC and RISC
How Important is ISA Design?Less now than before
With enough hardware, can make almost anything go fast
Intel is moving away from IA32Does not allow enough parallel executionIntroduced IA64
» 64-bit word sizes (overcome address space limitations)» Radically different style of instruction set with explicit parallelism» Requires sophisticated compilers


















