
CS614: Time Instead of Timeout Ken Birman February 6, 2001.
31
CS614: Time Instead of Timeout Ken Birman February 6, 2001
-
date post
19-Dec-2015 -
Category
Documents
-
view
219 -
download
1
Transcript of CS614: Time Instead of Timeout Ken Birman February 6, 2001.

CS614: Time Instead of Timeout
Ken BirmanFebruary 6, 2001

What we’re after
A general means for distributed communication
Letting n processes coordinate an action such as resource management or even replicating a database.
Paper was first to tackle this issue Includes quite a few ideas, only some of
which are adequately elaborated

Earlier we saw… Distributed consensus impossible
with even one faulty process. Impossible to determine if failed or
merely “slow”. Solution 1: Timeouts
Can easily be added to asynchronous algorithms to provide guarantees about slowness.
Assumption: Timeout implies failure.

Asynchronous Synchronous
Start with an asynchronous algorithm that isn’t fault-tolerant
Add timeout to each message receipt Assumes bounds on the message
transmission time and processing time Exceeding the bound implies failure
Easy to “bullet-proof” a protocol. Practical if bounds are very conservative
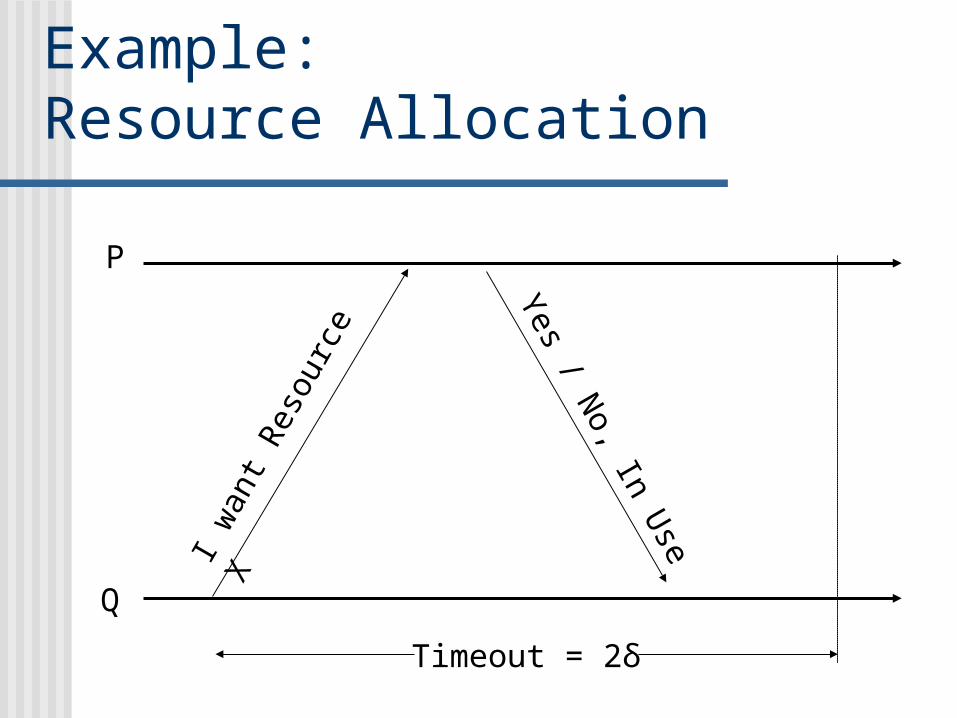
Example: Resource Allocation
I wan
t Res
ourc
e X Yes / N
o, In Use
Timeout = 2δ
P
Q

Null messages Notice that if a message doesn’t contain
real data, we can sometimes skip sending it For example: if resource isn’t in use, I could
skip sending the reply and after δ time interpret your “inaction” as a NULL message
Lamport is very excited by this option A system might send billions of NULL
messages per second! And do nothing on receiving them!! Billions and billions…

Another Synchronous System Round Based Each round characterized by time needed
to receive and process all messages.

Lamport’s version: Use Physical Clocks
Also fault-tolerant realtime atomic broadcast Assumptions about time lead to
conclusions other than failure Passage of time can also have “positive” value
Provides generality for distributed computing problems State machines Resource acquisition and locking
Expense?

Assumptions Bounded message delay δ
Requires bandwidth guarantees. A message delayed by > δ treated as failure.
Clock Synchronization Clock times differ by less than ε. Use clock synchronization algorithms (could
be costly; revisit in next lecture). Any process can determine message
origin (e.g. using HMAC signatures) Network cannot be partitioned

An Algorithm…If send message queue not empty
Send m with timestamp Ti
If receive message queue not emptyIf queue contains exactly one message m
from j with timestamp Ti - (δ + ε)Then Received Message = mElse Received Message = NULL
Implies Δ = (δ + ε)

Example
i
j
j’M
essage M
Ti
Tj
Tj’
Ti+ Δ
Tj+ Δ
Tj’+ Δ
ε

More This can be expressed more elegantly as a
broadcast algorithm (more later). Can inductively extend definition to allow
for “routing” across path of length n Δ = (n·δ + ε) To tolerate f failstop failures, will need f + 1
disjoint paths. To tolerate f Byzantine Failures, will need 2·f
+ 1 disjoint paths. Transmitting NULL message easy: do
nothing.

Even More For good guarantees, need close
synchronization. Message arrives Tmessage- ε, …, Tmessage
+ δ + ε Thus, need to wait (δ + ε).

Synchronization required? A means to reliably broadcast to all
other processes. For process P broadcasting message M
at time Tp, every (correct) process must receive the message at time Tp + Δ
For correct j, j’, receive by Tj + Δ and Tj’ + Δ, respectively, or neither does.

= Atomic Broadcast Atomicity
All correct processors receives same message.
Same order All messages delivered in same order to
all processors. Termination
All updates delivered by T + Δ.

Lamport’s Assumption Somebody implements Atomic
Broadcast black box. Next slide summarizes options
Lamport briefly explains that previous point to point algorithm is strong enough. Only assumes ability to send along a
path correctly.

Atomic Broadcast: [CASD]*
Describes 3 atomic broadcast algorithms. All based on Diffusion (Flooding) Varying degrees of protection 1. Tolerant of omission failures
• Δ = πδ + dδ + ε 2. Works in presence of Clock Failures
• Δ = π(δ + ε )+ dδ + ε 3. Works in presence of Byzantine Failures
• Δ = π(δ + ε )+ dδ + ε• δ much larger than previous for message
authentication
* F. Cristian, H. Aghali, R. Strong and D. Dolev, "Atomic Broadcast: From Simple Message Diffusion to Byzantine Agreement", in Proc. 15th Int. Symp. on Fault-Tolerant Computing. June 1985.

State Machine General model for
computation (State Machine = Computer!)
Describe computation in terms of state + transformations on the state

State Machines Multiple replicas in lock-step
Number of replicas bounded (below) by fault-tolerance objectives
Failstop model Failover, > f + 1 replicas
Byzantine model Voting, > 2·f + 1 replicas

State Machine:Implementation Let CLOCK = current time
While ( TRUE )Execute MessageCLOCK – Δ
Execute Local Processing(CLOCK)Generate and Send MessageCLOCK
If there exist multiple messages with same time stamp, create an ordering based on sending process.

State Machine (Cont.) If we use our broadcast algorithm,
all processes will get message by Tsender + Δ
Using the sending process id to break ties ensures everyone executes messages in same order.

State Machines for Distributed Applications
Resource allocation All processes maintain list of which process
has resource “locked”. Lock expires after Δ’ seconds Requests for resource are broadcast to all Rules govern who is granted lock (followed by
all correct processes)• Ensure no starvation• Maintain consistency of resource locking
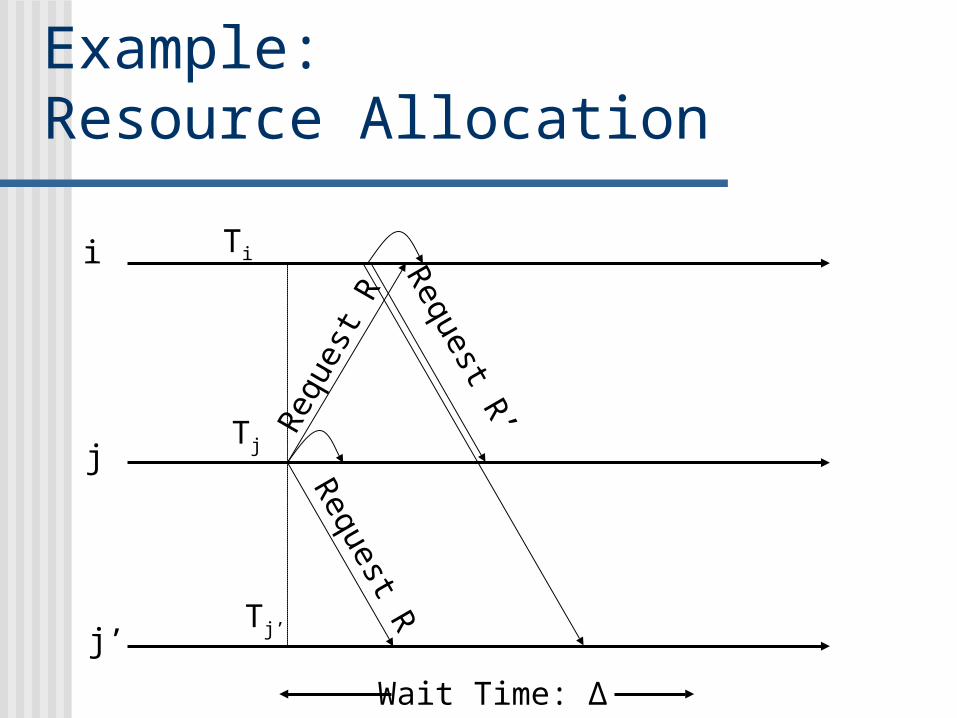
Example: Resource Allocation
Request R
’
Ti
Tj
Tj’Request R
Req
uest
R
i
j
j’
Wait Time: Δ

Comparison No explicit acknowledgement
needed Would be needed in traditional
asynchronous algorithm But here, requesting process knows
that any conflicting request would arrive within T + Δ window.

Key: Non-occurrence of event (non-request)
tells us of info: we can safely lock the resource!
Cost is the delay, as message sits in “holding pen.”
Concern about scalability in n: We always see n requests in each time
period, so will grow in n. Not addressed Must bound request processing time so that all
can be satisfied (else could starve process with higher id hence lower priority)

More on Comparison: Resource Allocation
Timeout Max Delay: 2·δ
Average Delay: 2·δexp Messages: n +
dependent on failure mode
Time [Lamport] Max Delay: Δ = δ + ε Average Delay:
Δ = δ + ε Messages:
dependent on failure mode
l But is request processing time the “real” issue?

Characterizing ε
ε proportional to δvar
Low level algorithms can achieve good clock synchronization. δvar small for low-level algorithms
δvar large for high-level algorithms• Variance added by traversing low levels of
protocol stack

Summary… Expressing application as state
machine transitions can easily be transferred to distributed algorithm.
Event based implementation can be easily created from transitions.

Other State Machine uses Distributed Semaphores Transaction Commit State Machine synchronization core
on top of distributed apps. Entire application need not be
distributed state machine.

Ideas in this paper Coordination and passing of time modeled
as synchronous execution of steps of a state machine
Absence of a message becomes NULL message after delay Δ
Notion of dynamic membership (vague) Broadcast to drive state machine (vague) State transfer for restart (vague) Scalability in n (not addressed) Fault-tol. (ignores application semantics) Δ-T behavior (real-time mechanism)

Discussion How far can we take the state
machine model? Can it be made to scale well? Extreme clock synchronization
dependence, practical? Worth it? Possibly large waiting time for each
message, dependent upon worst case message delivery latency


















