
CS519: Lecture 6 zCommunication in tightly coupled systems (parallel computing)
57
CS519: Lecture 6 Communication in tightly coupled systems (parallel computing)
-
date post
19-Dec-2015 -
Category
Documents
-
view
217 -
download
1
Transcript of CS519: Lecture 6 zCommunication in tightly coupled systems (parallel computing)

CS519: Lecture 6
Communication in tightly coupled systems (parallel computing)
CS 519Operating System
Theory2
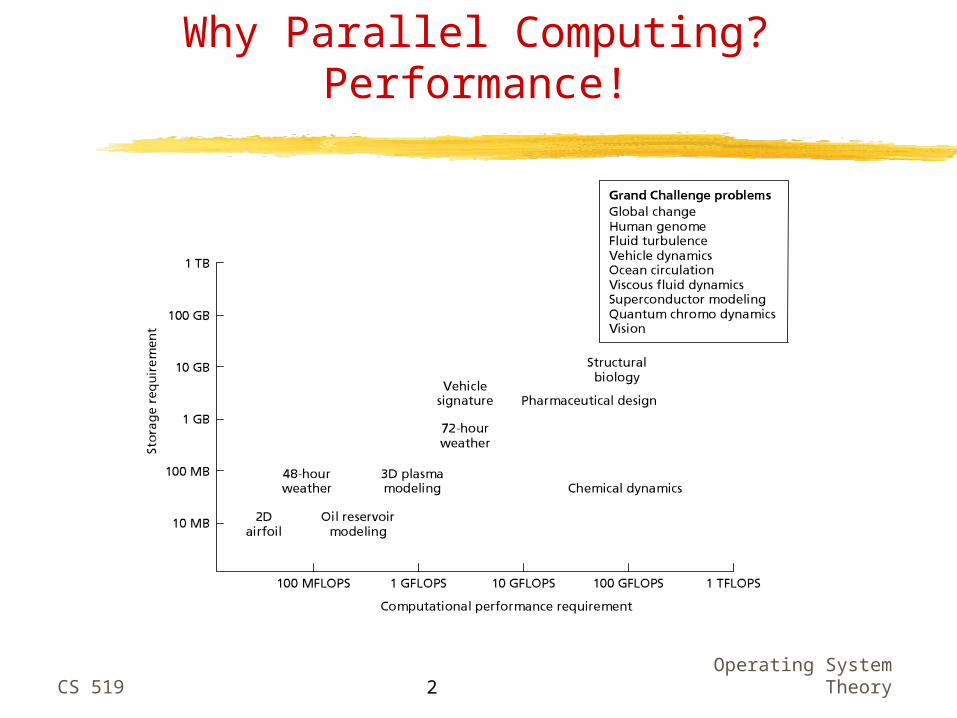
Why Parallel Computing? Performance!
CS 519Operating System
Theory3
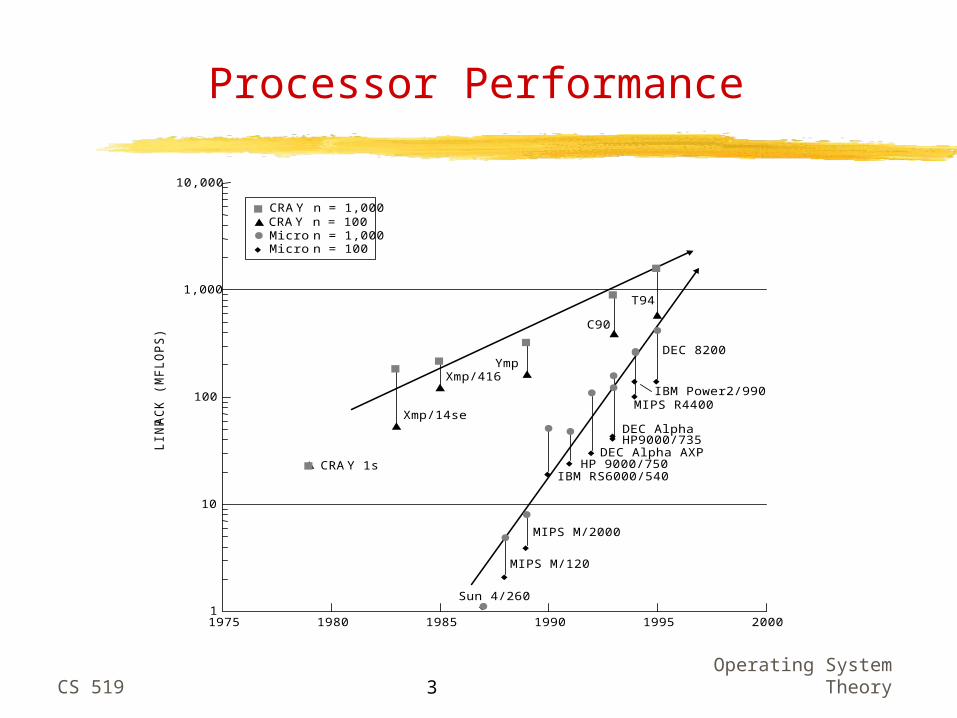
Processor Performance
LIN
PAC
K (
MF
LO
PS
)
1
10
100
1,000
10,000
1975 1980 1985 1990 1995 2000
CRAY n = 100 CRAY n = 1,000
Micro n = 100 Micro n = 1,000
CRAY 1s
Xmp/14se
Xmp/416Ymp
C90
T94
DEC 8200
IBM Power2/990MIPS R4400
HP9000/735DEC Alpha
DEC Alpha AXPHP 9000/750
IBM RS6000/540
MIPS M/2000
MIPS M/120
Sun 4/260

CS 519Operating System
Theory4
But not just Performance
At some point, we’re willing to trade some performance for: Ease of programming Portability Cost
Ease of programming & Portability Parallel programming for the masses Leverage new or faster hardware asap
Cost High-end parallel machines are expensive resources
CS 519Operating System
Theory5
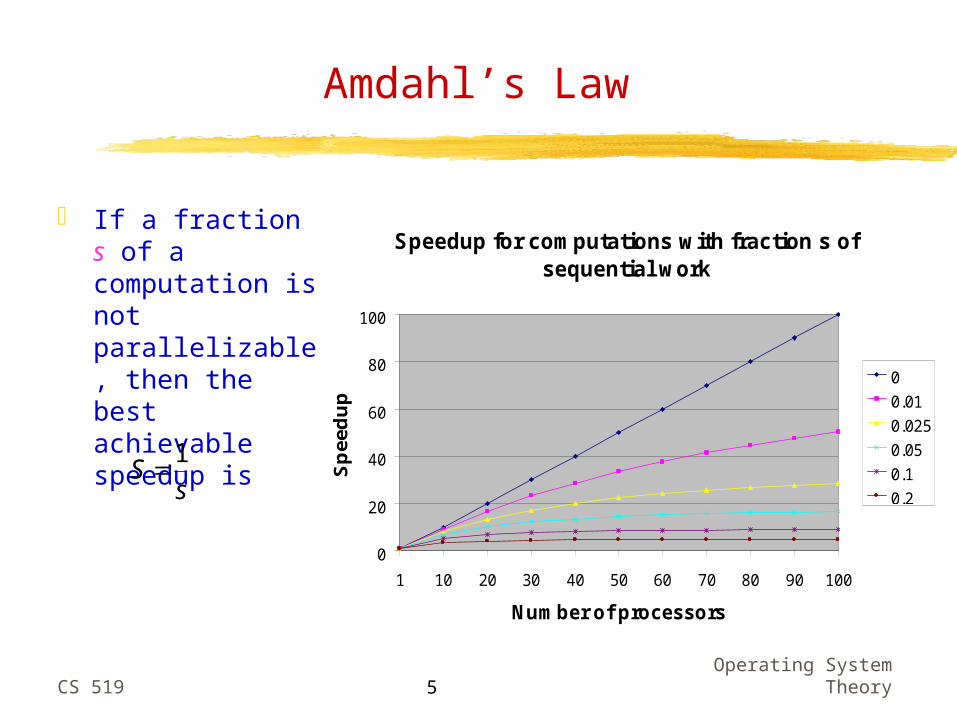
Amdahl’s Law
If a fraction s of a computation is not parallelizable, then the best achievable speedup is
sS
1
Speedup for computations with fraction s of sequential work
0
20
40
60
80
100
1 10 20 30 40 50 60 70 80 90 100
Number of processors
Sp
eed
up
0
0.01
0.025
0.05
0.1
0.2

CS 519Operating System
Theory6
Pictorial Depiction of Amdahl’s Law
1
p
1
Time

CS 519Operating System
Theory7
Parallel Applications
Scientific computing not the only class of parallel applications
Examples of non-scientific parallel applications: Data mining Real-time rendering Distributed servers
CS 519Operating System
Theory8
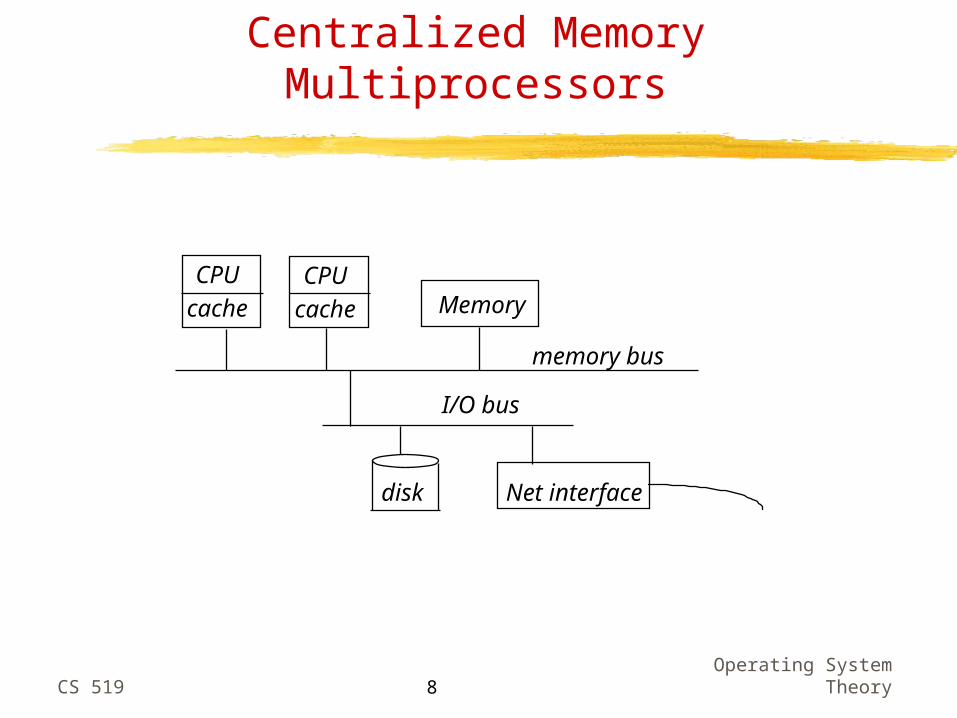
Centralized Memory Multiprocessors
CPUMemory
memory bus
I/O bus
disk Net interface
cacheCPU
cache
CS 519Operating System
Theory9
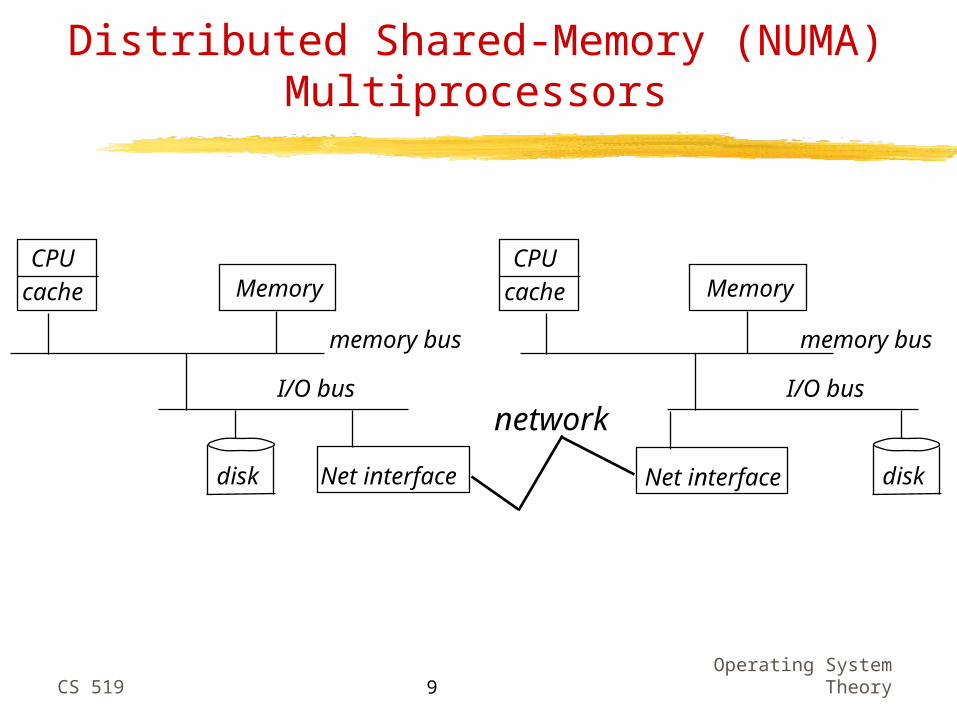
Distributed Shared-Memory (NUMA) Multiprocessors
CPUMemory
memory bus
I/O bus
disk Net interface
cache
CPUMemory
memory bus
I/O bus
diskNet interface
cache
network

CS 519Operating System
Theory10
Multicomputers
CPUMemory
memory bus
I/O bus
disk Net interface
cache
CPUMemory
memory bus
I/O bus
diskNet interface
cache
network
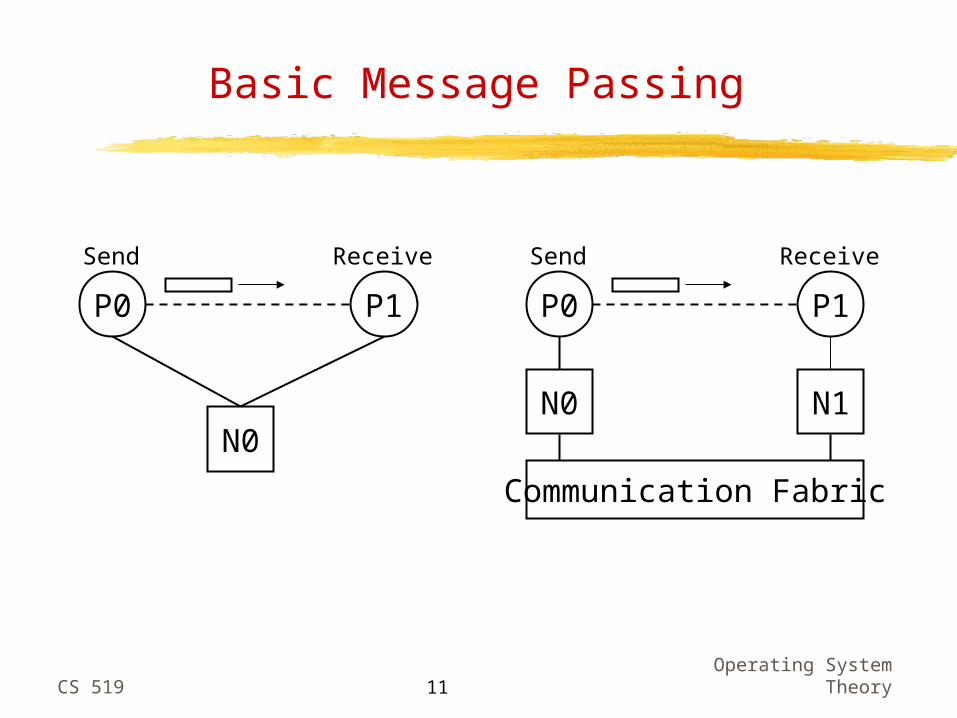
Inter-processor communication in multicomputers is effected through message passing
CS 519Operating System
Theory11
Basic Message Passing
P0 P1
N0
Send Receive
P0 P1
N0 N1
Communication Fabric
Send Receive

CS 519Operating System
Theory12
Terminology
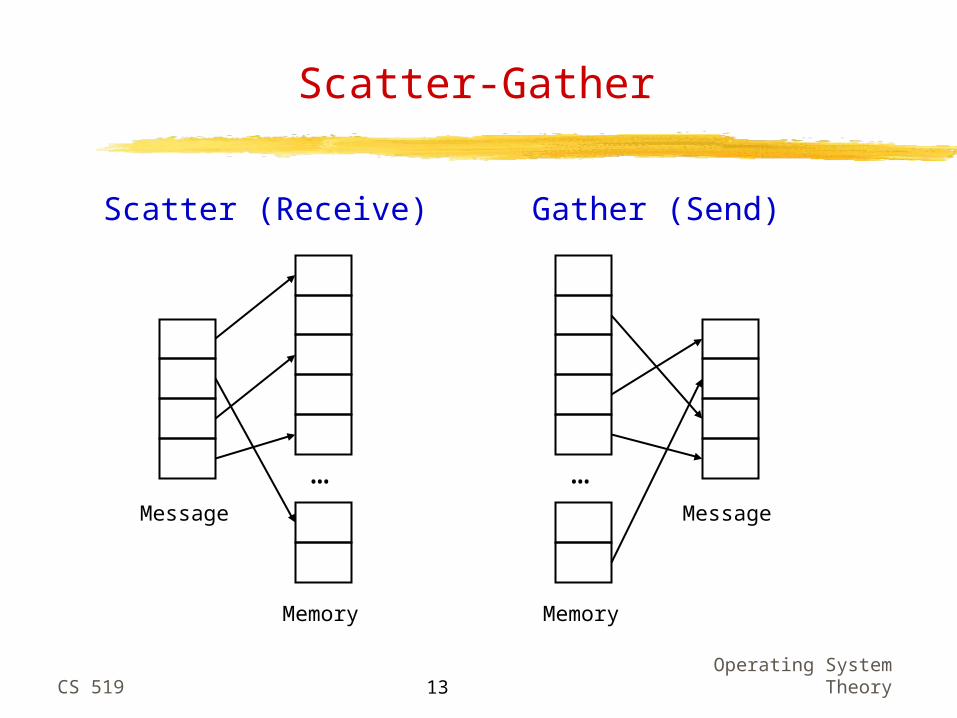
Basic Message Passing: Send: Analogous to mailing a letter Receive: Analogous to picking up a letter from the mailbox Scatter-gather: Ability to “scatter” data items in a message
into multiple memory locations and “gather” data items from multiple memory locations into one message
Network performance: Latency: The time from when a Send is initiated until the
first byte is received by a Receive. Bandwidth: The rate at which a sender is able to send data
to a receiver.
CS 519Operating System
Theory13
Scatter-Gather
… Message
Memory
Scatter (Receive)
… Message
Memory
Gather (Send)

CS 519Operating System
Theory14
Basic Message Passing Issues
Issues include: Naming: How to specify the receiver? Buffering: What if the out port is not available? What if
the receiver is not ready to receive the message? Reliability: What if the message is lost in transit? What if
the message is corrupted in transit? Blocking: What if the receiver is ready to receive before
the sender is ready to send?
CS 519Operating System
Theory15
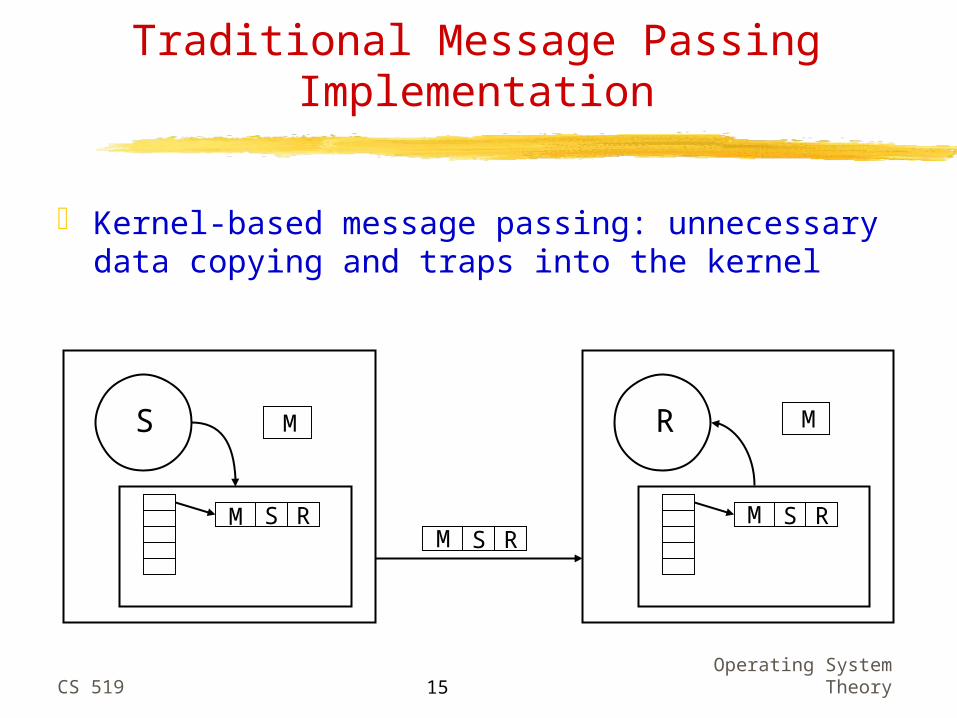
Traditional Message Passing Implementation
Kernel-based message passing: unnecessary data copying and traps into the kernel
S RM
RSMRSM
M
RSM

CS 519Operating System
Theory16
Reliability
Reliability problems: Message loss
Most common approach: If don’t get a reply/ack msg within some time interval, resend
Message corruption Most common approach: Send additional information (e.g.,
error correction code) so receiver can reconstruct data or simply detect corruption, if part of msg is lost or damaged. If reconstruction is not possible, throw away corrupted msg and pretend it was lost
Lack of buffer space Most common approach: Control the flow and size of
messages to avoid running out of buffer space

CS 519Operating System
Theory17
Reliability
Reliability is indeed a very hard problem in large-scale networks such as the Internet Network is unreliable Message loss can greatly impact performance Mechanisms to address reliability can be costly even when
there’s no message loss
Reliability is not as hard for parallel machines Underlying network hardware is much more reliable Less prone to buffer overflow, cause often have hardware
flow-control
Address reliability later, for loosely coupled systems

CS 519Operating System
Theory18
Computation vs. Communication Cost
200 MHz clock 5 ns instruction cycle Memory access:
L1: ~2-4 cycles 10-20 ns L2: ~5-10 cycles 25-50 ns Memory: ~50-200 cycles 250-1000 ns
Message roundtrip latency: ~20 s Suppose 75% hit ratio in L1, no L2, 10 ns L1 access
time, 500 ns memory access time average memory access time 132.5 ns
1 message roundtrip latency = 151 memory accesses

CS 519Operating System
Theory19
Performance … Always Performance!
So … obviously, when we talk about message passing, we want to know how to optimize for performance
But … which aspects of message passing should we optimize? We could try to optimize everything
Optimizing the wrong thing wastes precious resources, e.g., optimizing leaving mail for the mail-person does not increase overall “speed” of mail delivery significantly
Subject of Martin et al., “Effects of Communication Latency, Overhead, and Bandwidth in a Cluster Architecture,” ISCA 1997.
CS 519Operating System
Theory20
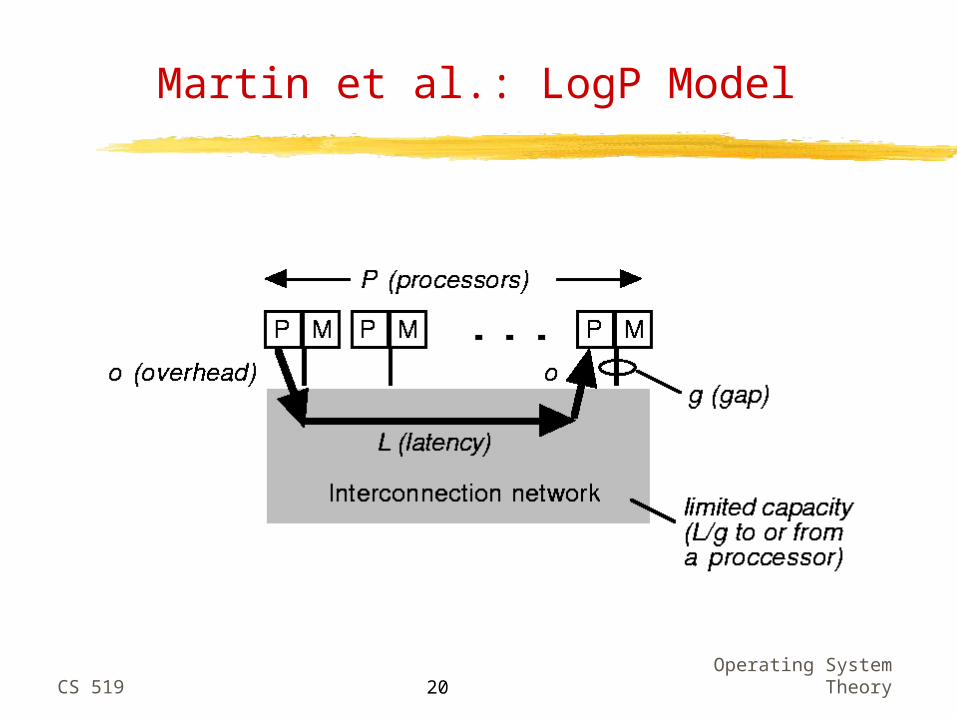
Martin et al.: LogP Model

CS 519Operating System
Theory21
Sensitivity to LogGP Parameters
LogGP parameters:L = delay incurred in passing a short msg from source to
desto = processor overhead involved in sending or receiving a
msgg = min time between msg transmissions or receptions
(msg bandwidth)G = bulk gap = time per byte transferred for long
transfers (byte bandwidth)
Workstations connected with Myrinet network and Generic Active Messages layer
Delay insertion technique Applications written in Split-C but perform their
own data caching
CS 519Operating System
Theory22
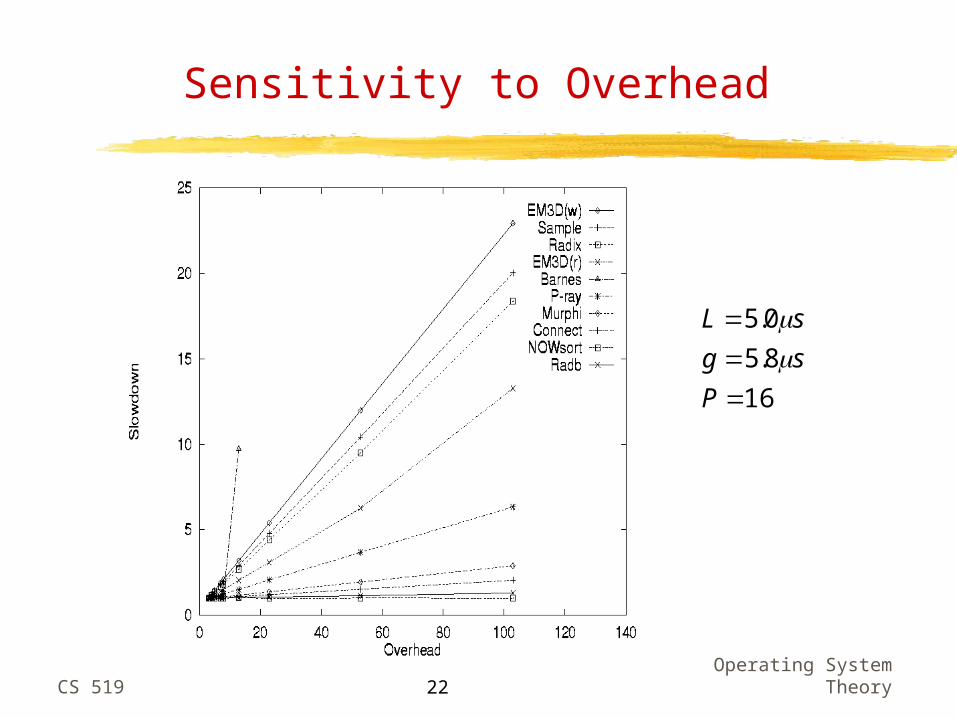
Sensitivity to Overhead
16
8.5
0.5
P
sg
sL

CS 519Operating System
Theory23
Sensitivity to Gap
16
9.2
0.5
P
so
sL
CS 519Operating System
Theory24
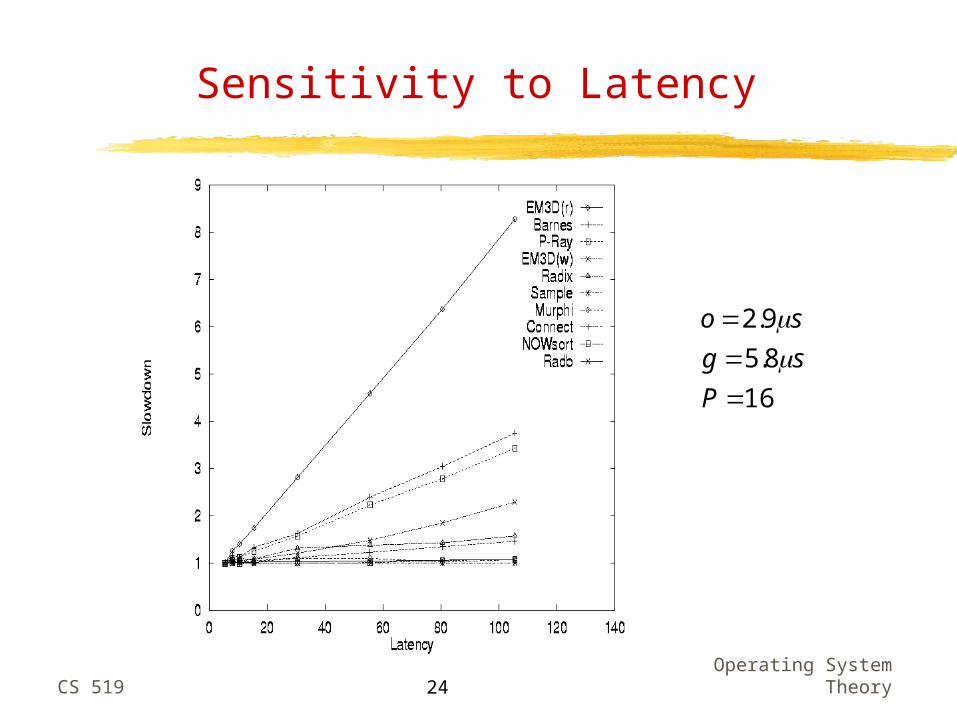
Sensitivity to Latency
16
8.5
9.2
P
sg
so
CS 519Operating System
Theory25
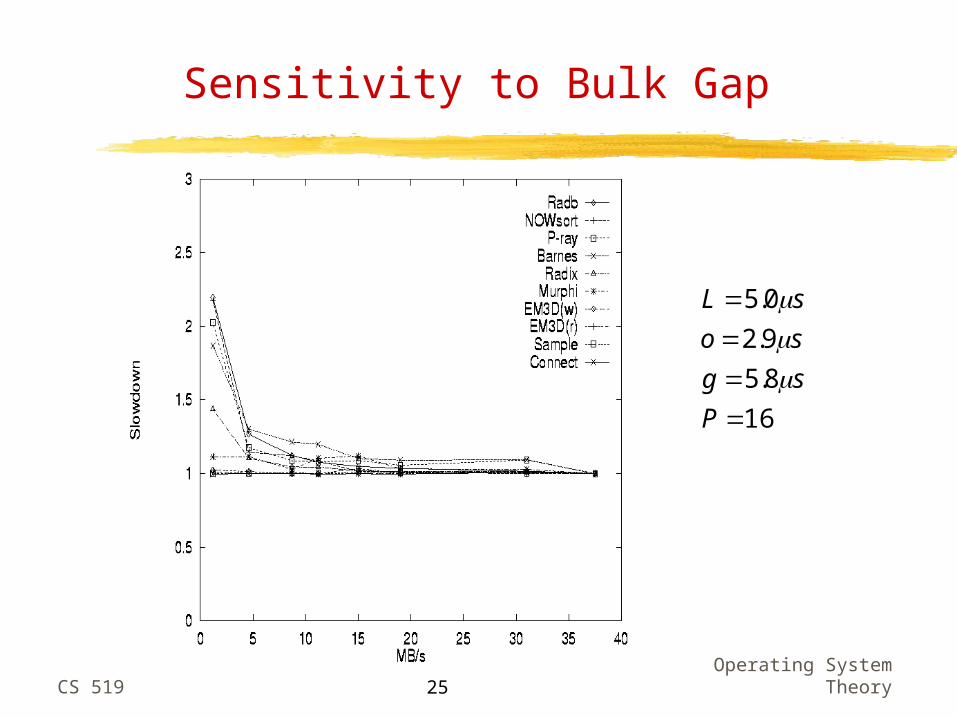
Sensitivity to Bulk Gap
16
8.5
9.2
0.5
P
sg
so
sL

CS 519Operating System
Theory26
Summary
Runtime strongly dependent on overhead and gap
Strong dependence on gap because of burstiness of communication
Not so sensitive to latency can effectively overlap computation and communication with non-blocking reads (writes usually do not stall the processor)
Not sensitive to bulk gap got more bandwidth than we know what to do with

CS 519Operating System
Theory27
What’s the Point?
What can we take away from Martin et al.’s study? It’s extremely important to reduce overhead because it
may affect both “o” and “g” All the “action” is currently in the OS and the Network
Interface Card (NIC)
Subject of von Eicken et al., “Active Message: a Mechanism for Integrated Communication and Computation,” ISCA 1992.

An Efficient Low-Level Message Passing Interface
von Eicken et al., “Active Messages: a Mechanism for Integrated Communication and Computation,” ISCA 1992
von Eicken et al., “U-Net: A User-Level Network Interface for Parallel and Distributed Computing,” SOSP 1995
Santos, Bianchini, and Amorim, “A Survey of Messaging Software Issues and Systems for Myrinet-Based Clusters”, PDCP 1999

CS 519Operating System
Theory29
von Eicken et al.: Active Messages
Design challenge for large-scale multiprocessor: Minimize communication overhead Allow computation to overlap communication Coordinate the above two without sacrificing processor
cost/performance Problems with traditional message passing:
Send/receive are usually synchronous; no overlap between communication and computation
If not synchronous, needs buffering (inside the kernel) on the receive side
Active Messages approach: Asynchronous communication model (send and continue) Message specifies handler that integrates msg into on-going
computation on the receiving side

CS 519Operating System
Theory30
Buffering
Remember buffering problem: what to do if receiver not ready to receive? Drop the message
This is typically very costly because of recovery costs Leave the message in the NIC
Reduce network utilization Can result in deadlocks
Wait until receiver is ready – synchronous or 3-phase protocol
Copy to OS buffer and later copy to user buffer
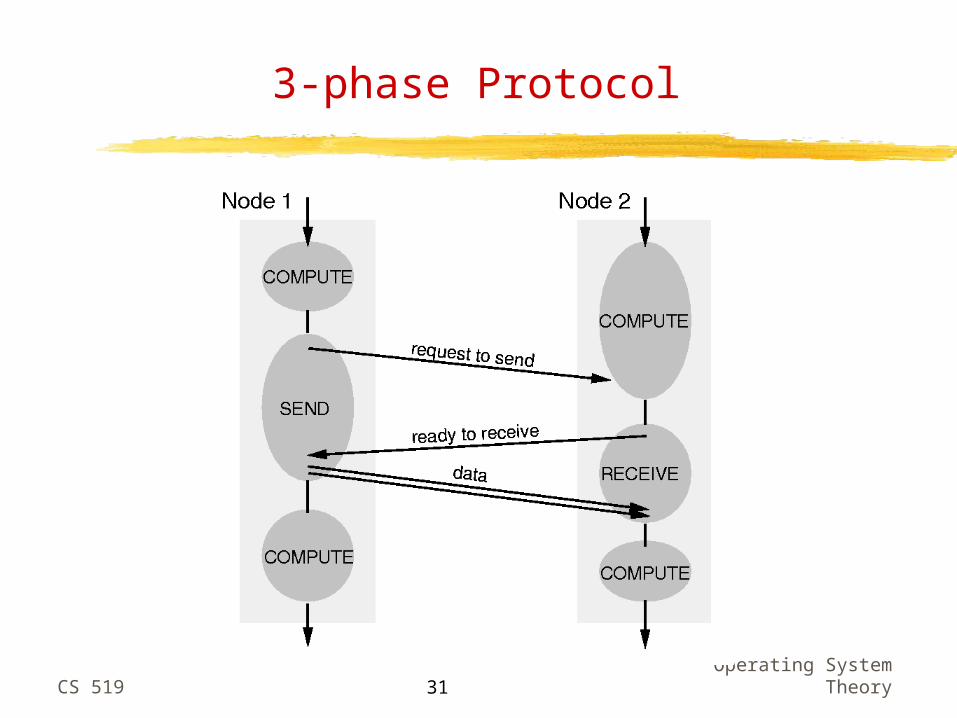
CS 519Operating System
Theory31
3-phase Protocol
CS 519Operating System
Theory32
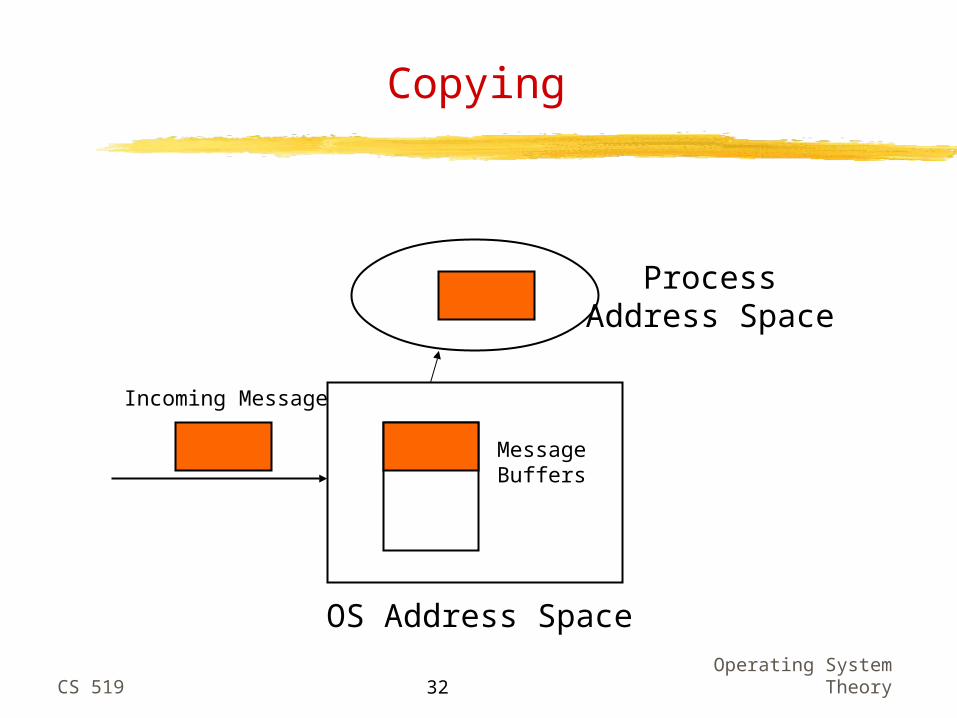
Copying
MessageBuffers
OS Address Space
ProcessAddress Space
Incoming Message
CS 519Operating System
Theory33
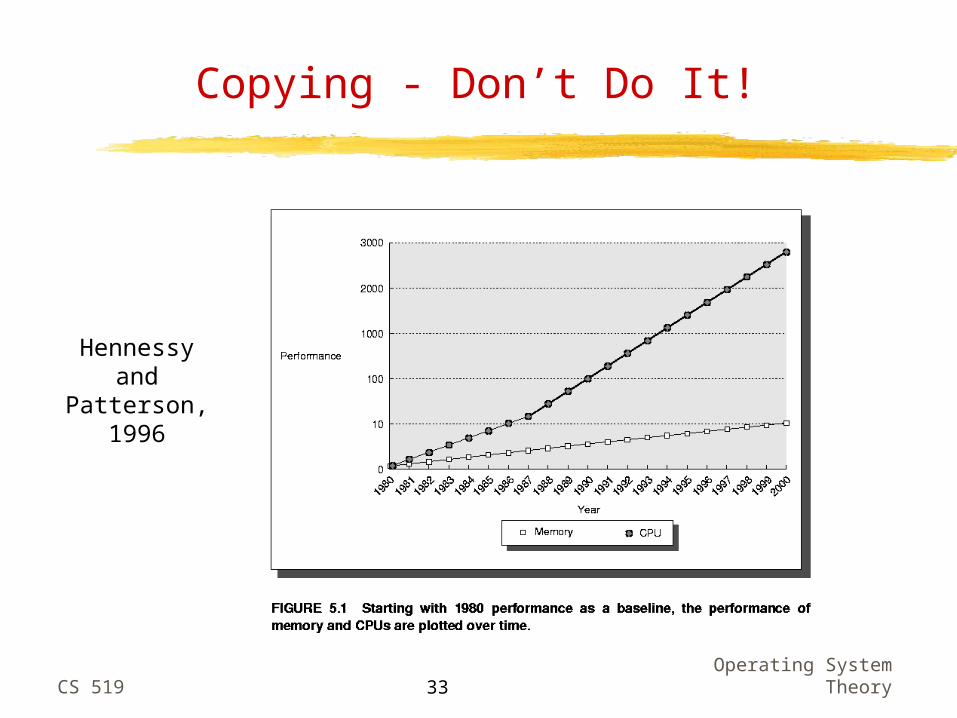
Copying - Don’t Do It!
Hennessyand
Patterson,1996

CS 519Operating System
Theory34
Overhead of Many Native MIs Too High
Recall that overhead is critical to appl performance Asynchronous send and receive overheads on
many platforms (back in 1991): Ts = time to start a message; Tb = time/byte; Tfb = time/flop (for comparison)
CS 519Operating System
Theory35
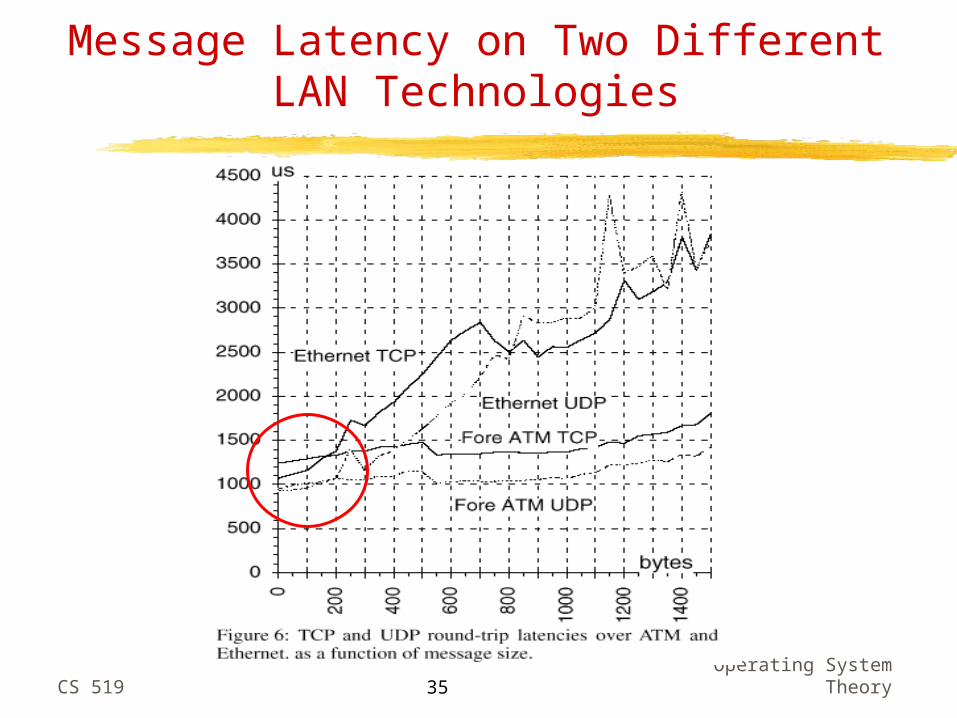
Message Latency on Two Different LAN Technologies
CS 519Operating System
Theory36
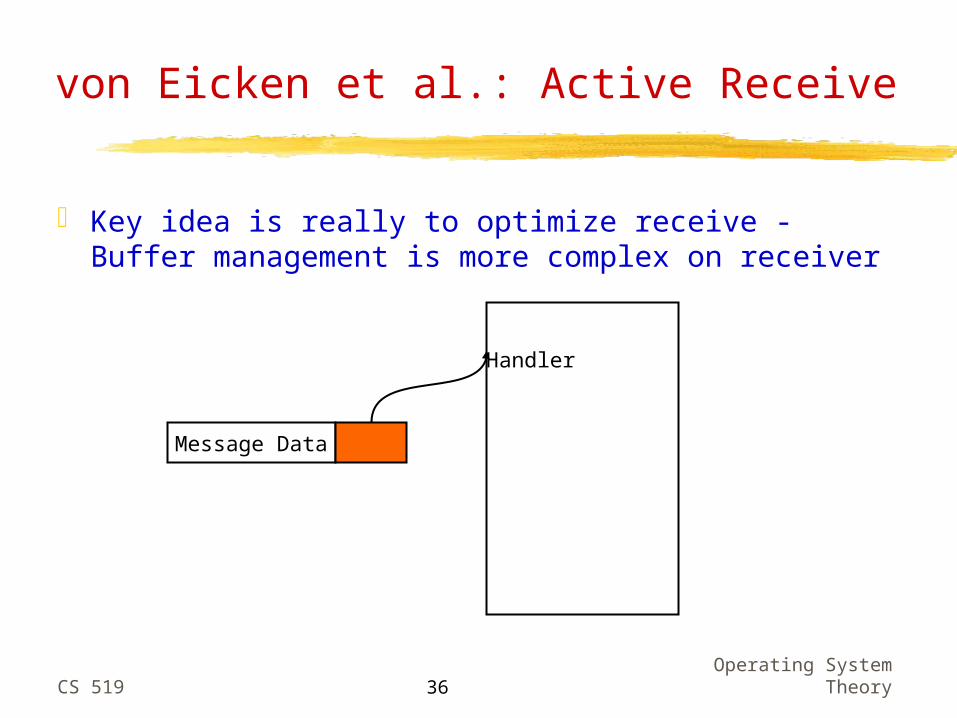
von Eicken et al.: Active Receive
Key idea is really to optimize receive - Buffer management is more complex on receiver
Message Data
Handler
CS 519Operating System
Theory37
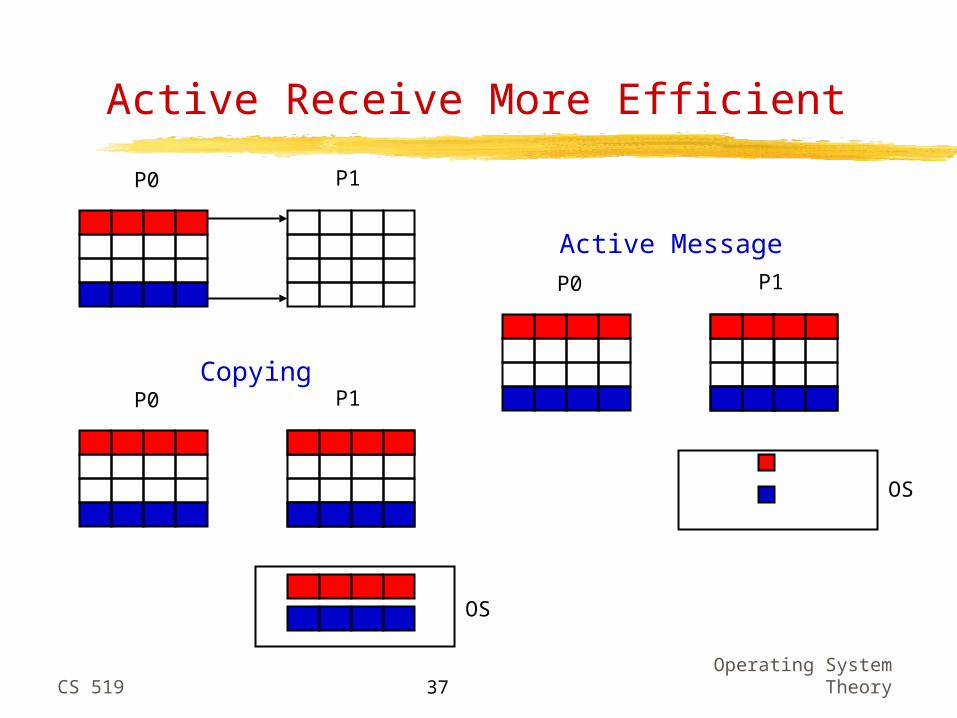
Active Receive More Efficient
P0 P1
P0 P1
P0 P1
OS
OS
Copying
Active Message

CS 519Operating System
Theory38
Active Message Performance
Send ReceiveInstructions Time (s) Instructions Time (s)
NCUBE2 21 11.0 34 15.0
CM-5 1.6 1.7
Main difference between these AM implementations is that the CM-5 allows direct, user-level access to the network interface.More on this in a minute!

CS 519Operating System
Theory39
Any Drawback To Active Message?
Active message SPMD SPMD: Single Program Multiple Data
This is because sender must know address of handler on receiver
Not absolutely necessary, however Can use indirection, i.e. have a table mapping handler
Ids to addresses on receiver. Mapping has a performance cost, though.
CS 519Operating System
Theory40
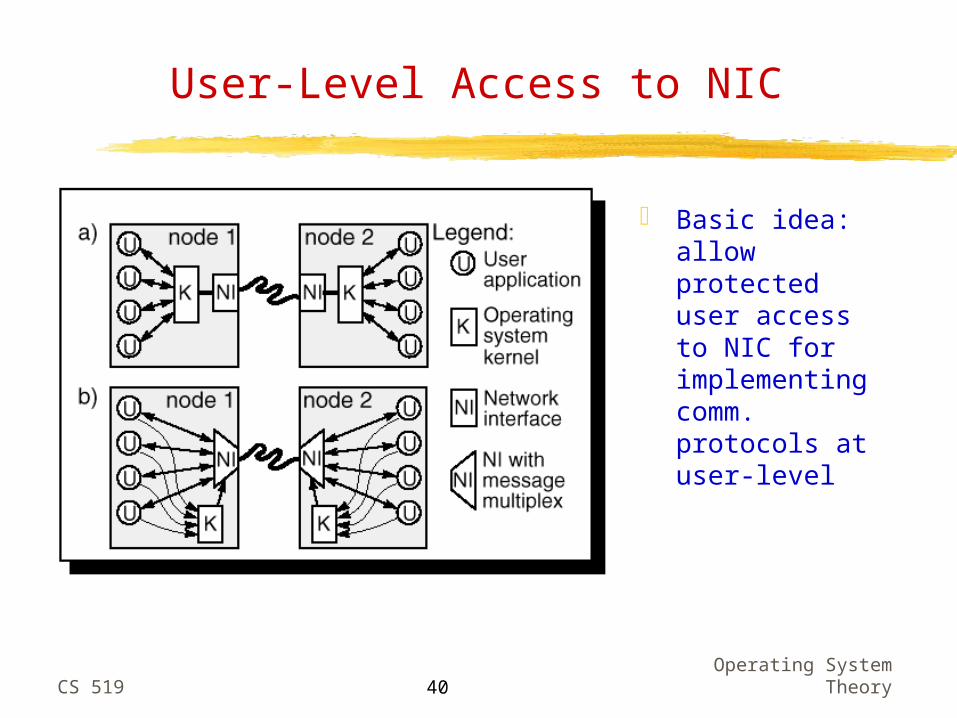
User-Level Access to NIC
Basic idea: allow protected user access to NIC for implementing comm. protocols at user-level
CS 519Operating System
Theory41
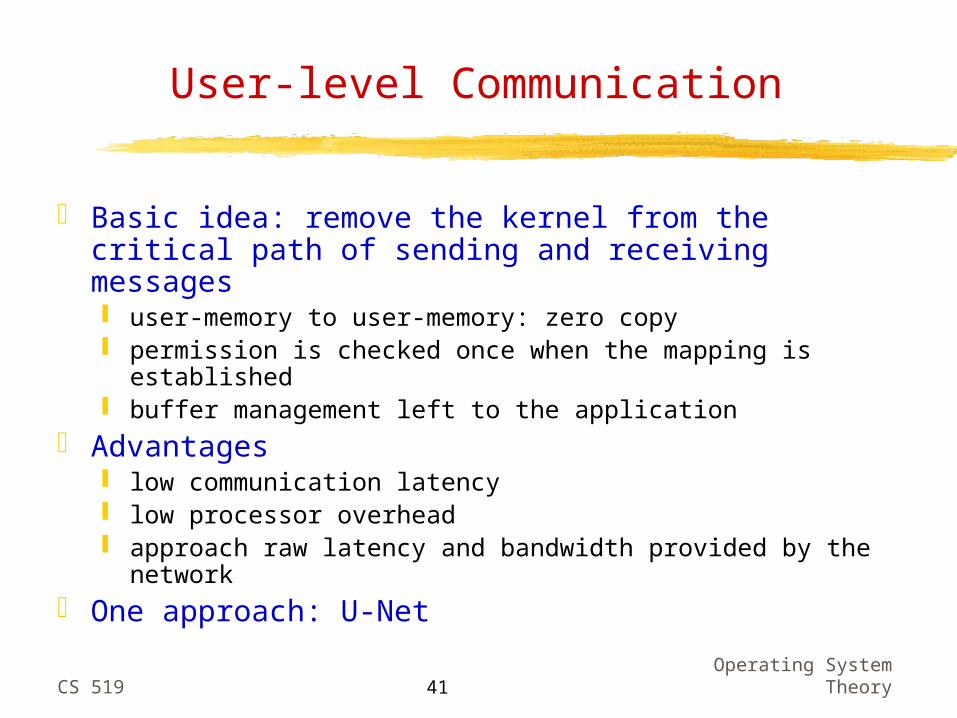
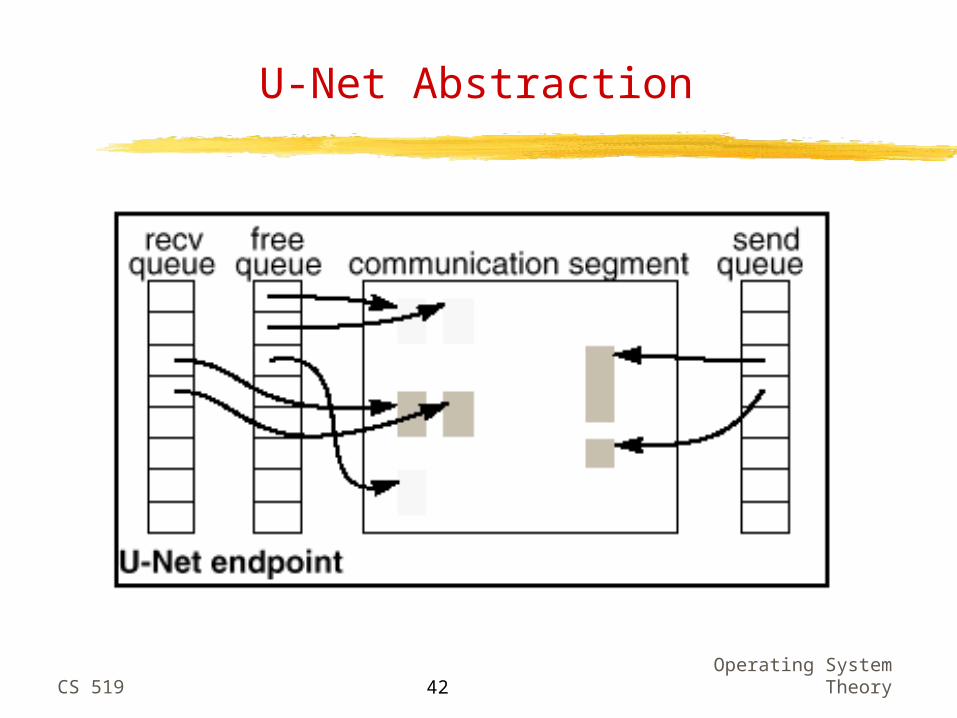
User-level Communication
Basic idea: remove the kernel from the critical path of sending and receiving messages user-memory to user-memory: zero copy permission is checked once when the mapping is
established buffer management left to the application
Advantages low communication latency low processor overhead approach raw latency and bandwidth provided by the
network One approach: U-Net
CS 519Operating System
Theory42
U-Net Abstraction
CS 519Operating System
Theory43
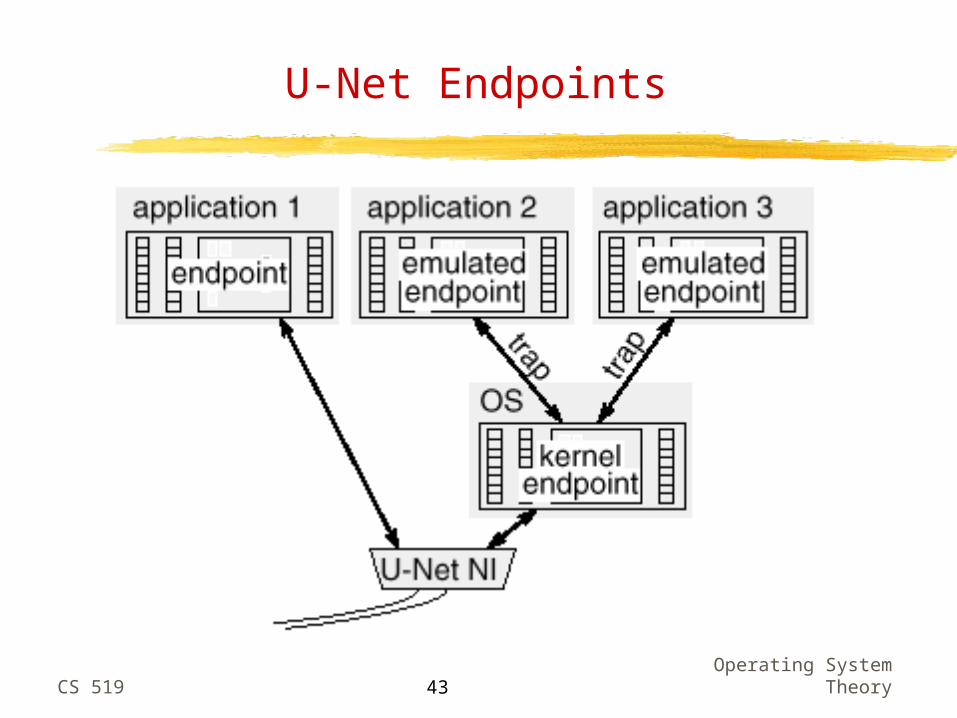
U-Net Endpoints

CS 519Operating System
Theory44
U-Net Basics
Protection provided by endpoints and communication channels Endpoints, communication segments, and message queues are
only accessible by the owning process (all allocated in user memory)
Outgoing messages are tagged with the originating endpoint address and incoming messages are demultiplexed and only delivered to the correct endpoints
For ideal performance, firmware at NIC should implement the actual messaging and NI multiplexing (including tag checking). Protection must be implemented by the OS by validating requests for the creation of endpoints. Channel registration should also be implemented by the OS.
Message queues can be placed at different memories to optimize polling Receive queue allocated in host memory Send and free queues allocated in NIC memory
CS 519Operating System
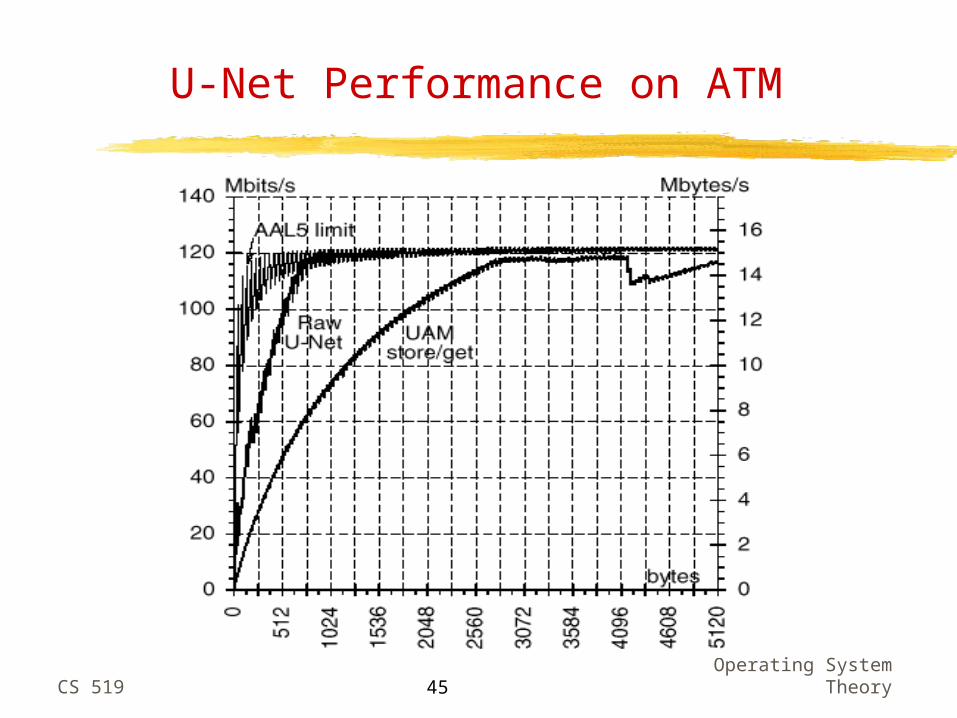
Theory45
U-Net Performance on ATM

CS 519Operating System
Theory46
U-Net UDP Performance
CS 519Operating System
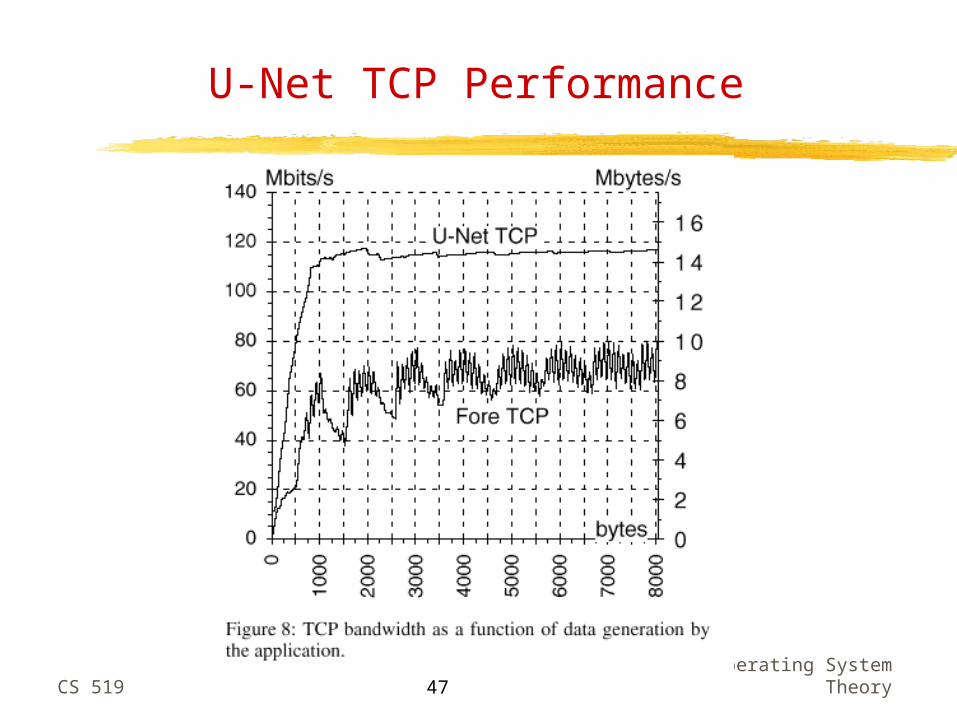
Theory47
U-Net TCP Performance
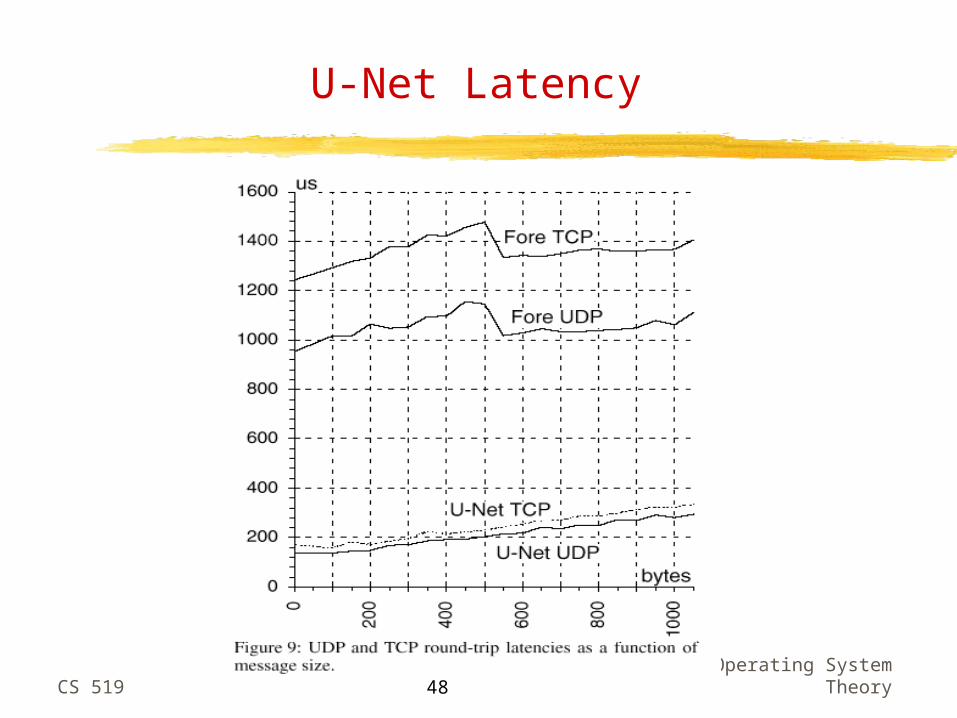
CS 519Operating System
Theory48
U-Net Latency

CS 519Operating System
Theory49
Virtual Memory-Mapped Communication
Receiver exports the receive buffers Sender must import a receive buffer before sending The permission of sender to write into the receive buffer is
checked once, when the export/import handshake is performed (usually at the beginning of the program)
Sender can directly communicate with the network interface to send data into imported buffers without kernel intervention
At the receiver, the network interface stores the received data directly into the exported receive buffer with no kernel intervention

CS 519Operating System
Theory50
Virtual-to-physical address
In order to store data directly into the application address space (exported buffers), the NI must know the virtual to physical translations
What to do?
sender receiver
int rec_buffer[1024];exp_id = export(rec_buffer, sender);
recv(exp_id);
int send_buffer[1024];recv_id = import(receiver, exp_id);
send(recv_id, send_buffer);

CS 519Operating System
Theory51
Software TLB in Network Interface
The network interface must incorporate a TLB (NI-TLB) which is kept consistent with the virtual memory system
When a message arrives, NI attempts a virtual to physical translation using the NI-TLB
If a translation is found, NI transfers the data to the physical address in the NI-TLB entry
If a translation is missing in the NI-TLB, the processor is interrupted to provide the translation. If the page is not currently in memory, the processor will bring the page in. In any case, the kernel increments the reference count for that page to avoid swapping
When a page entry is evicted from the NI-TLB, the kernel is informed to decrement the reference count
Swapping prevented while DMA in progress
CS 519Operating System
Theory52
Introduction to Collective Communication

CS 519Operating System
Theory53
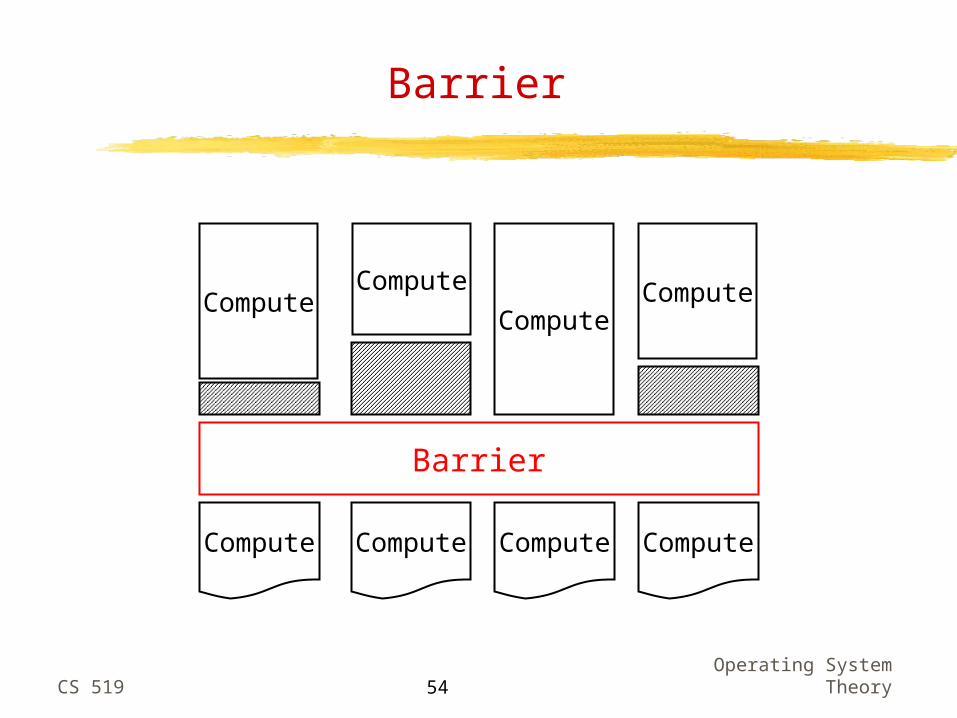
Collective Communication
More than two processes involved in communication Barrier Broadcast (one-to-all), multicast (one-to-many) All-to-all Reduction (all-to-one)
CS 519Operating System
Theory54
Barrier
Compute
Barrier
Compute
ComputeCompute
Compute Compute Compute Compute
CS 519Operating System
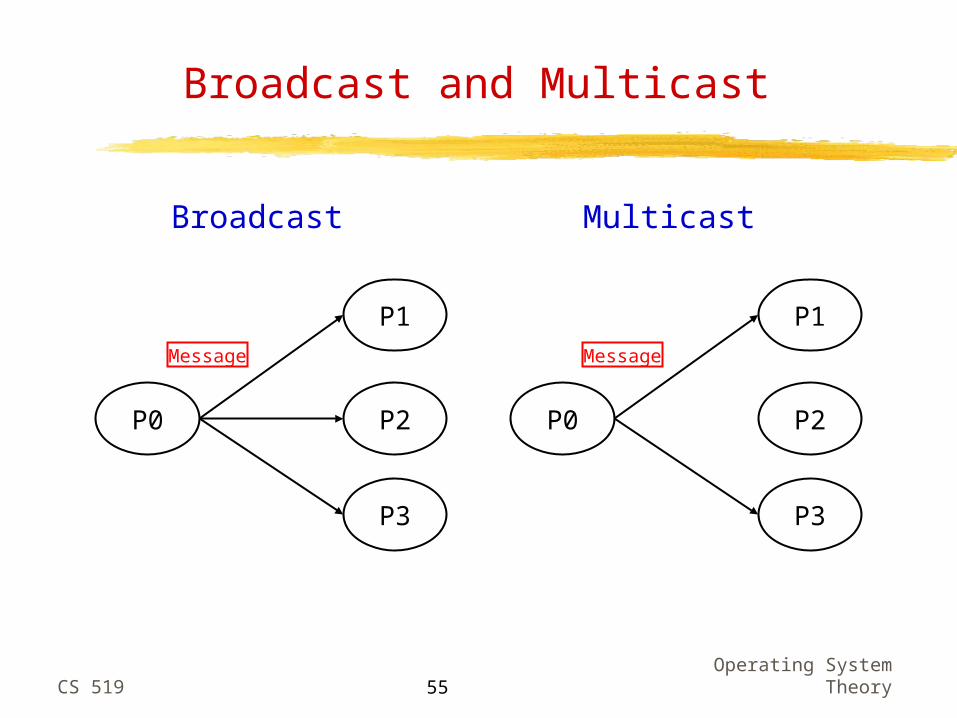
Theory55
Broadcast and Multicast
P0
P1
P2
P3
Broadcast
Message
P0
P1
P2
P3
Message
Multicast
CS 519Operating System
Theory56
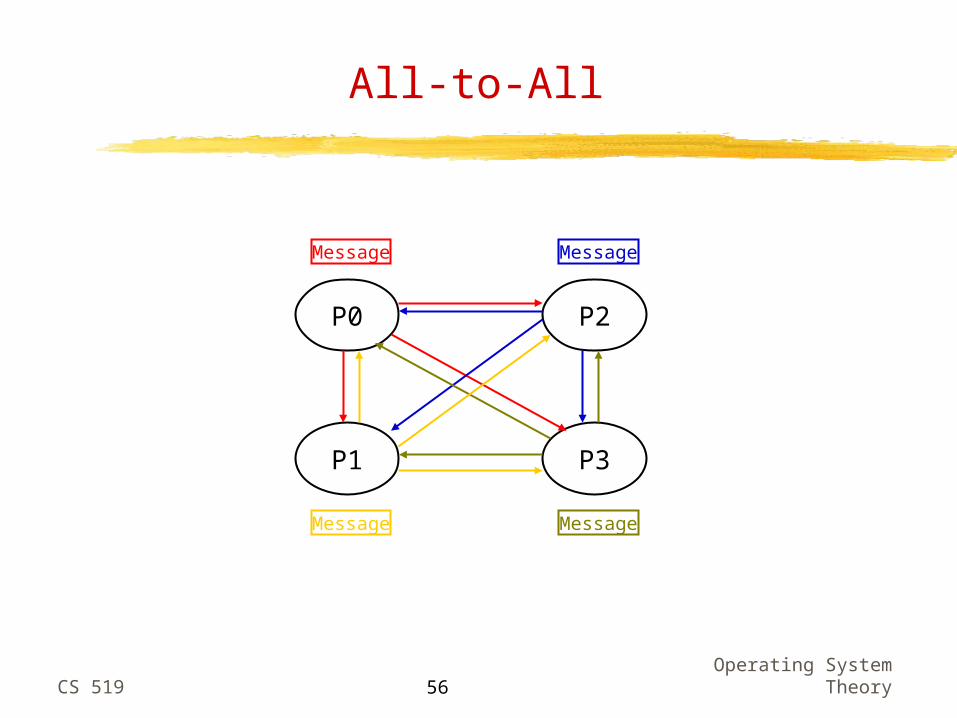
All-to-All
P0
P1
P2
P3
Message
Message Message
Message
CS 519Operating System
Theory57
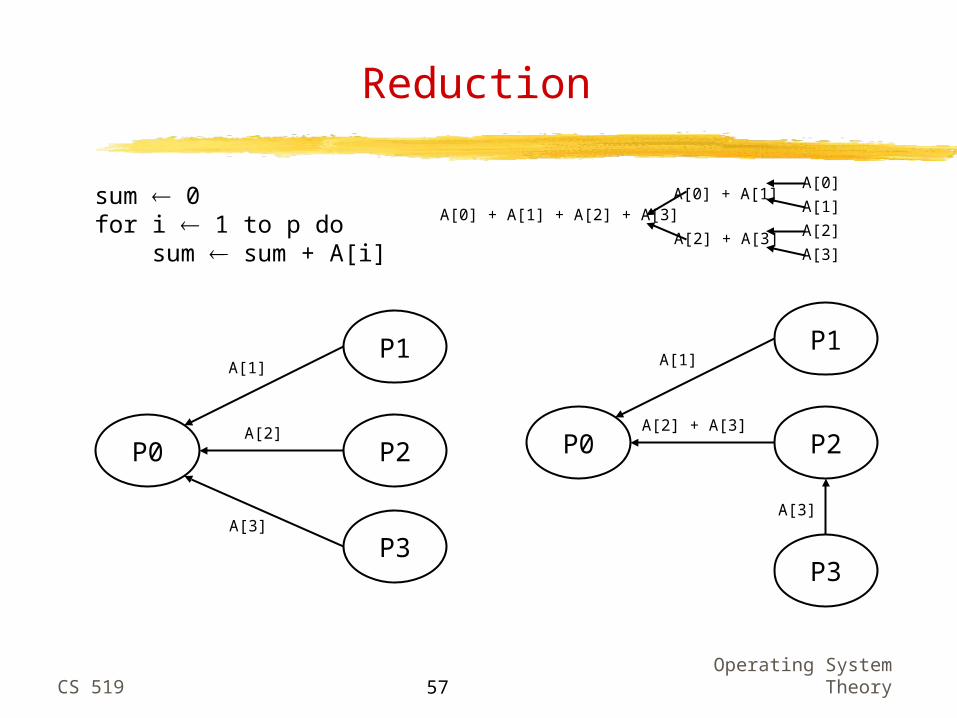
Reduction
sum 0for i 1 to p do sum sum + A[i]
P0
P1
P2
P3
A[1]
A[2]
A[3]
P0
P1
P2
P3
A[1]
A[2] + A[3]
A[3]
A[0]
A[1]
A[2]
A[3]
A[0] + A[1]
A[2] + A[3]
A[0] + A[1] + A[2] + A[3]


















