
Space-for-Time Tradeoffs Design & Analysis of Algorithms CS315 1.
Upload
madeleine-harveyCategory
view
224download
3
CS315 – Link AnalysisThree generations of Search EnginesAnchor textLink analysis for ranking Pagerank HITS

1st Generation: Content Similarity
Content Similarity Ranking:The more rare words two documents share, the more similar they are
Documents are treated as “bags of words”(no effort to “understand” the contents)
Similarity is measured by vector angles
Query Results are rankedby sorting the anglesbetween query and documents
t 1
d
2d 1
t 3
t 2
θ

But we also have links (los links!)
Assumption 1: A hyperlink from a page denotes vote of confidence to second page (quality signal)
Assumption 2: The anchor text of the hyperlink describes the target page (textual context)
hyperlinkAnchor text
Page A Page B

2nd Generation: Add Popularity
A hyperlink from a page in site A to some page in site Bis considered a popularity vote from site A to site B
Score of a page = number of in-links
Query Processing First retrieve all pages meeting
the text query (say venture capital).
Order these by the link popularity (of the page or the site)
www.aa.com1
www.bb.com2
www.cc.com1 www.dd.com
2
www.zz.com0

3rd Generation: Add Reputation
Each page starts with some basic “reputation” (e.g., =1)and repeatedly distributes equal fractions to its links(while receiving from them)until some “equilibrium”
The reputation “PageRank” of a page P = the sum of a fair fraction of the reputations of all pages Pj that point to P
Beautiful Math behind itPR = principal eigenvector of the web’s link matrixPR equivalent to the chance of randomly surfing to the page
Idea similar to academic co-citations
€
PR(W ) =PR(W1)
O(W1)+PR(W2)
O(W2)+...+
PR(Wn )
O(Wn )

Roots of PR: Citation Analysis
Citation frequency The kind of background work Deans are doing at tenure time
Co-citation coupling frequency Co-citations with a given author measures “impact” Are you co-cited with influential publications?
Bibliographic coupling frequency Articles that co-cite the same articles are related
Citation indexing Who is author cited by?
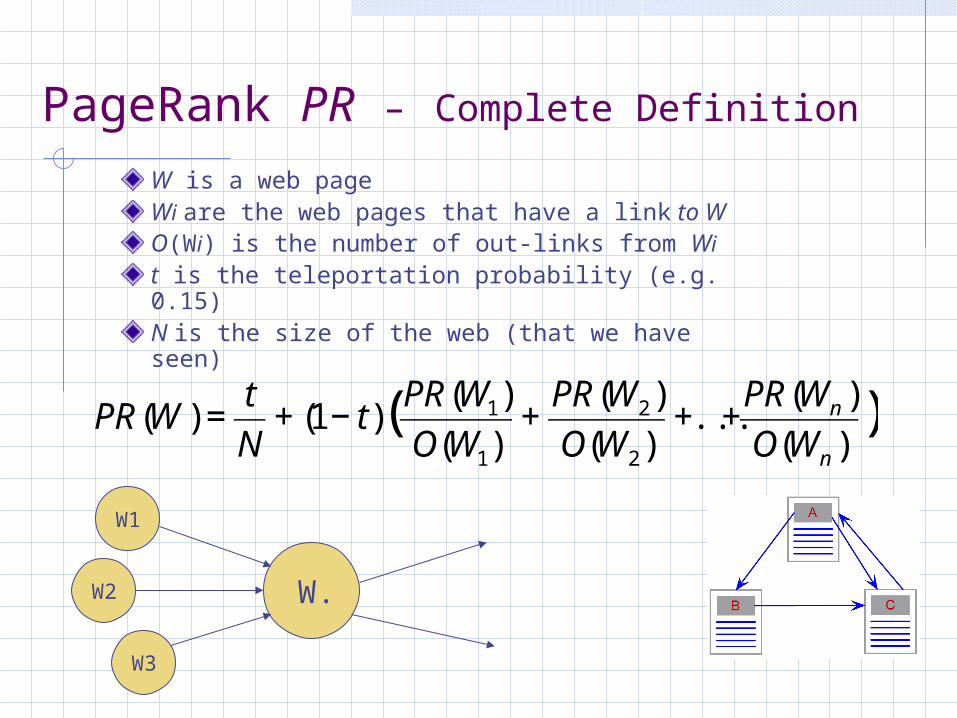
PageRank PR – Complete Definition
W is a web pageWi are the web pages that have a link to WO(Wi) is the number of out-links from Wit is the teleportation probability (e.g. 0.15)N is the size of the web (that we have seen)
€
PR(W ) =t
N+ (1− t)(PR(W1)
O(W1)+PR(W2)
O(W2)+...+
PR(Wn )
O(Wn ))
W.
W1
W2
W3
W1
W2
W3

PageRank: Iterative Computation
t is normally set to 0.15, but for this example, for simplicity let’s set it to 0.5Set initial PR values to 1Solve the following equations iteratively:
€
PR(A) = 0.5 /3 + 0.5PR(C)
PR(B) = 0.5 /3 + 0.5(PR(A) /2)
PR(C) = 0.5 /3 + 0.5(PR(A) /2 + PR(B))
€
PR(W ) =t
N+ (1− t)(PR(W1)
O(W1)+PR(W2)
O(W2)+...+
PR(Wn )
O(Wn ))

Example Computation of PRin Excel

Pagerank – Matrix Multiplication Equivalent Def.
Imagine a browser doing a random walk on web pages: Start at a random page P At each step,
walk with equal probability out of the current page along one of the links on that page,
Continue doing this randomwalk for a long time
“In the steady state” each page has a long-term visit rate:
Use this rate as the page’s score.
P1/31/31/3

Not quite enough
The web is full of dead-ends. Random walk can get stuck in dead-ends. Makes no sense to talk about long-term visit rates.
??

Teleporting
At a dead end, jump to a random web page.
At any non-dead end, With probability, say, 15%,
jump to a random web page. With remaining probability (85%),
go out on a random link. t=0.15 is the “teleporting” parameter.

Result of teleporting
Now cannot get stuck locally. There exists a computable long-term rate
at which any page is visited This not obvious, but it has been proven!
How do we compute this visit rate?

Markov chains: abstractions of random walks
A Markov chain consists of n states, and an nn transition probability matrix P.At each step, we are in exactly one of the states.For 1 i,j n, the matrix entry Pij tells us the probability of j being the next state, given we are currently in state i. Clearly, for all i,
i jPij
.11
ij
n
j
P
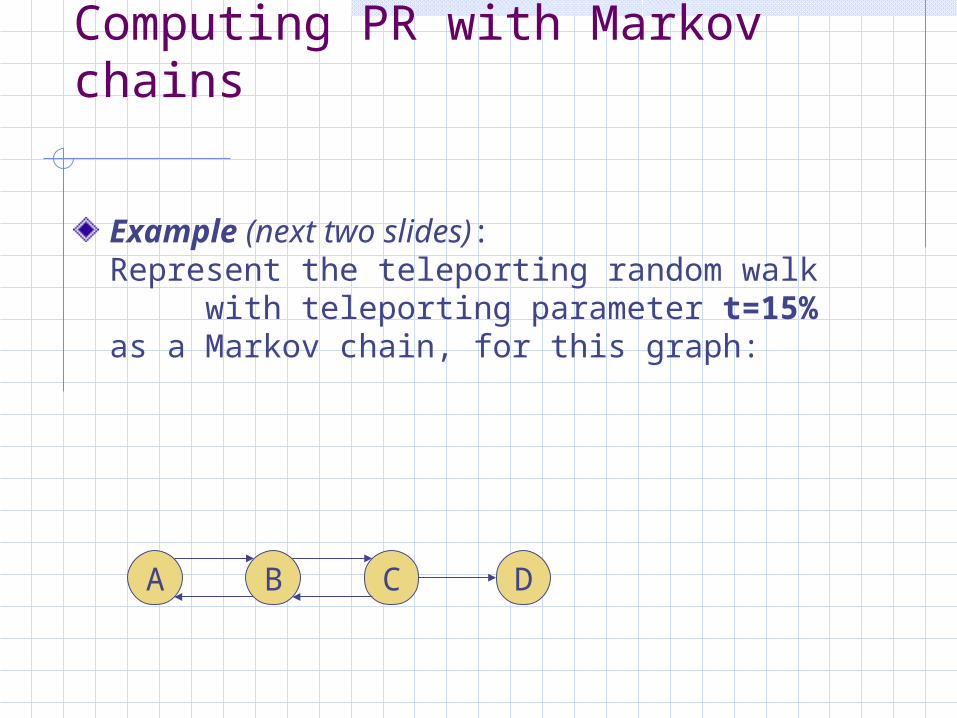
Computing PR with Markov chains
Example (next two slides): Represent the teleporting random walk
with teleporting parameter t=15% as a Markov chain, for this graph:
A B C D

Computing P with Matrix Multiplication
Start with Adjacency matrix A of the Web Graph If there is hyperlink from i to j, Aij = 1, else Aij = 0
If a row has all 0’s,
replace each element by 1/N
Else divide each 1 by the number of 1’s in the row Multiply the matrix by 1-t Add t/N to every entry of the resulting matrix
A B C D P=

Computing all Pageranks
Theorem: Regardless of where we start, we eventually reach the steady state a.Start with any distribution (say x=(1 0 … 0)). After one step, we’re at xP; after two steps at xP2 , then xP3 and so on. “Eventually” means for “large” k, xPk = a.
Algorithm: multiply x by increasing powers of P until the product looks stable.
A B C D
P=

Pagerank summary
Preprocessing: Given graph of links, build matrix P. From it compute a. The entry ai is a number between 0 and 1: the pagerank of page i.
Query processing: Retrieve pages meeting query. Rank them by their pagerank. Order is query-independent If PR(A) > PR(B) for some query, it beats it in every query

How is Pagerank used?
PageRank Technology:
PageRank reflects our view of the importance of web pages by considering more than 500 million variables and 2 billion terms. Pages that we believe are important pages receive a higher PageRank and are more likely to appear at the top of the search results.
This claim has recently changed:“Today we use more than 200 signals, including PageRank, to order websites, and we update these algorithms on a weekly basis”
Pagerank is dead, long live Pagerank!
http://www.google.com/corporate/tech.html




![PageRank . PageRank . PageRank Googleceit.aut.ac.ir/~meybodi/paper/Forsati-IKT2007.pdf · PageRank PageRank. PageRank Google ([6,7] [8-10] [11] HITS [12] Site Rank 1 Content mining](https://static.fdocuments.us/doc/165x107/5ad6ca0c7f8b9af9068b6a17/pagerank-pagerank-pagerank-meybodipaperforsati-ikt2007pdfpagerank-pagerank.jpg)













