
CS 145 Final Review - Stanford...
74
CS 145 Final Review The Best Of Collection (Master Tracks), Vol. 2 Final Review
Transcript of CS 145 Final Review - Stanford...

CS145FinalReviewTheBestOfCollection(MasterTracks),Vol.2
FinalReview

CourseSummary
• Welearned…
1. Howtodesignadatabase
2. Howtoqueryadatabase,evenwithconcurrentusersandcrashes/aborts
3. Howtooptimizetheperformanceofadatabase
• Wegotasense(astheoldjokegoes)ofthethreemostimportanttopicsinDBresearch:
• Performance,performance,andperformance
Lecture17>Section3
1.Intro
2-3.SQL
4.ERDiagrams
5-6.DBDesign
7-8.TXNs
11-12.IOCost
14-15.Joins
16.Rel.Algebra

CourseSummary
• Welearned…
1. Howtodesignadatabase
2. Howtoqueryadatabase,evenwithconcurrentusersandcrashes/aborts
3. Howtooptimizetheperformanceofadatabase
• Wegotasense(astheoldjokegoes)ofthethreemostimportanttopicsinDBresearch:
• Performance,performance,andperformance
Lecture17>Section3
1.Intro
2-3.SQL
4.ERDiagrams
5-6.DBDesign
7-8.TXNs
11-12.IOCost
14-15.Joins
16.Rel.Algebra

CourseSummary
• Welearned…
1. Howtodesignadatabase
2. Howtoqueryadatabase,evenwithconcurrentusersandcrashes/aborts
3. Howtooptimizetheperformanceofadatabase
• Wegotasense(astheoldjokegoes)ofthethreemostimportanttopicsinDBresearch:
• Performance,performance,andperformance
Lecture17>Section3
1.Intro
2-3.SQL
4.ERDiagrams
5-6.DBDesign
7-8.TXNs
11-12.IOCost
14-15.Joins
16.Rel.Algebra

CourseSummary
• Welearned…
1. Howtodesignadatabase
2. Howtoqueryadatabase,evenwithconcurrentusersandcrashes/aborts
3. Howtooptimizetheperformanceofadatabase
• Wegotasense(astheoldjokegoes)ofthethreemostimportanttopicsinDBresearch:
• Performance,performance,andperformance
Lecture17>Section3
1.Intro
2-3.SQL
4.ERDiagrams
5-6.DBDesign
7-8.TXNs
11-12.IOCost
14-15.Joins
16.Rel.Algebra
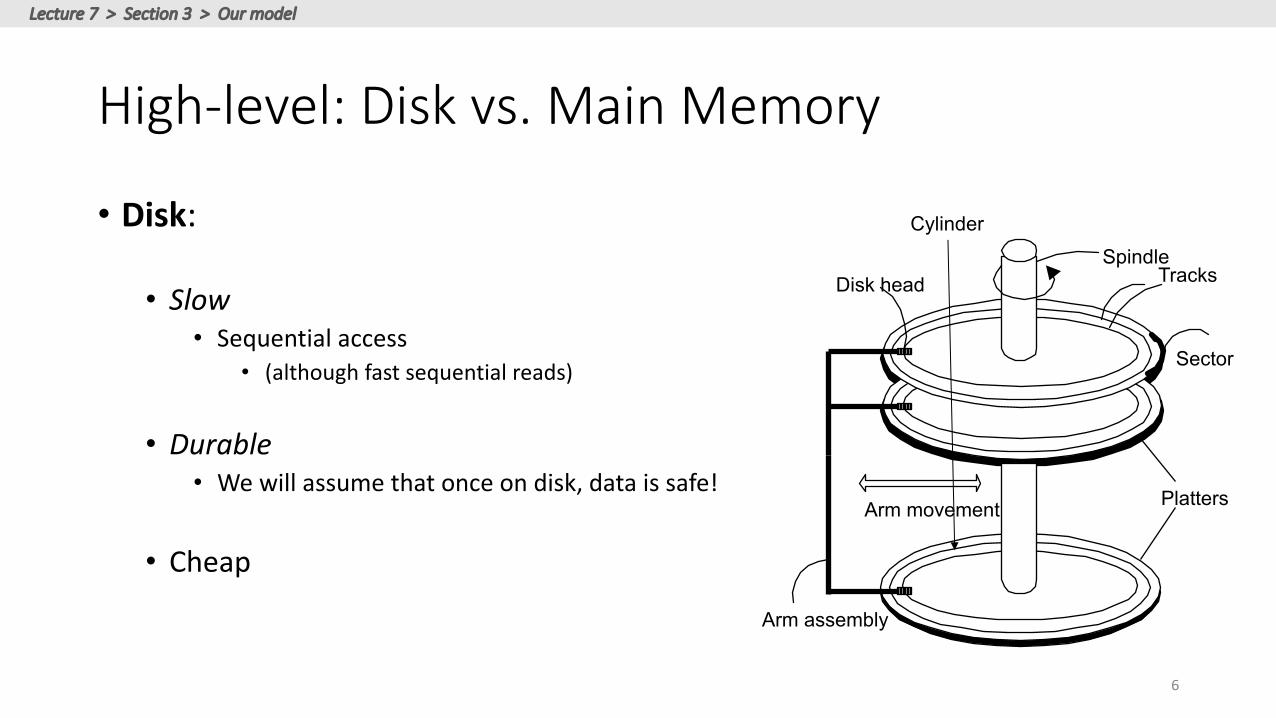
High-level:Diskvs.MainMemory
• Disk:
• Slow• Sequentialaccess
• (althoughfastsequentialreads)
• Durable• Wewillassumethatonceondisk,dataissafe!
• Cheap
6
Lecture7>Section3>Ourmodel
Platters
SpindleDisk head
Arm movement
Arm assembly
Tracks
Sector
Cylinder

• RandomAccessMemory(RAM)orMainMemory:
• Fast• Randomaccess,byteaddressable
• ~10xfasterforsequentialaccess• ~100,000xfasterforrandomaccess!
• Volatile• Datacanbelostife.g.crashoccurs,powergoesout,etc!
• Expensive• For$100,get16GBofRAMvs.2TBofdisk!
7
Lecture7>Section3>Ourmodel
High-level:Diskvs.MainMemory

Transactions:BasicDefinition
Atransaction(“TXN”)isasequenceofoneormoreoperations (readsorwrites)whichreflectsasinglereal-worldtransition.
START TRANSACTIONUPDATE ProductSET Price = Price – 1.99WHERE pname = ‘Gizmo’
COMMIT
Lecture7>Section1>TransactionsBasics
Intherealworld,aTXNeitherhappenedcompletelyornotatall

MotivationforTransactionsGroupinguseractions(reads&writes)intotransactionshelpswithtwogoals:
1. Recovery&Durability:KeepingtheDBMSdataconsistentanddurableinthefaceofcrashes,aborts,systemshutdowns,etc.
2. Concurrency: AchievingbetterperformancebyparallelizingTXNswithout creatinganomalies
Lecture7>Section1>Motivation
Thislecture!
Nextlecture

10
TransactionProperties:ACID
• Atomic• Stateshowseitheralltheeffectsoftxn,ornoneofthem
• Consistent• Txn movesfromastatewhereintegrityholds,toanotherwhereintegrityholds
• Isolated• Effectoftxns isthesameastxns runningoneafteranother(ie lookslikebatchmode)
• Durable• Onceatxn hascommitted,itseffectsremaininthedatabase
ACIDcontinuestobeasourceofgreatdebate!
Lecture7>Section2

BasicIdea:(Physical)Logging• RecordUNDOinformationforeveryupdate!
• Sequentialwritestolog• Minimalinfo(diff)writtentolog
• Thelog consistsofanorderedlistofactions• Logrecordcontains:
<XID,location,olddata,newdata>
ThisissufficienttoUNDOanytransaction!
Lecture7>Section3>Motivation&basics

Whydoweneedloggingforatomicity?• Couldn’twejustwriteTXNtodiskonly oncewholeTXNcomplete?
• Then,ifabort/crashandTXNnotcomplete,ithasnoeffect- atomicity!• Withunlimitedmemoryandtime,thiscouldwork…
• However,weneedtologpartialresultsofTXNs becauseof:• Memoryconstraints(enoughspaceforfullTXN??)• Timeconstraints(whatifoneTXNtakesverylong?)
Weneedtowritepartialresultstodisk!…Andsoweneedalog tobeabletoundo thesepartialresults!
Lecture7>Section3>Motivation&basics

TransactionCommitProcess
1. FORCEWritecommit recordtolog
2. AlllogrecordsuptolastupdatefromthisTXareFORCED
3. Commit()returns
Transactioniscommittedoncecommitlogrecordisonstablestorage
Lecture7>Section3>Loggingcommitprotocol
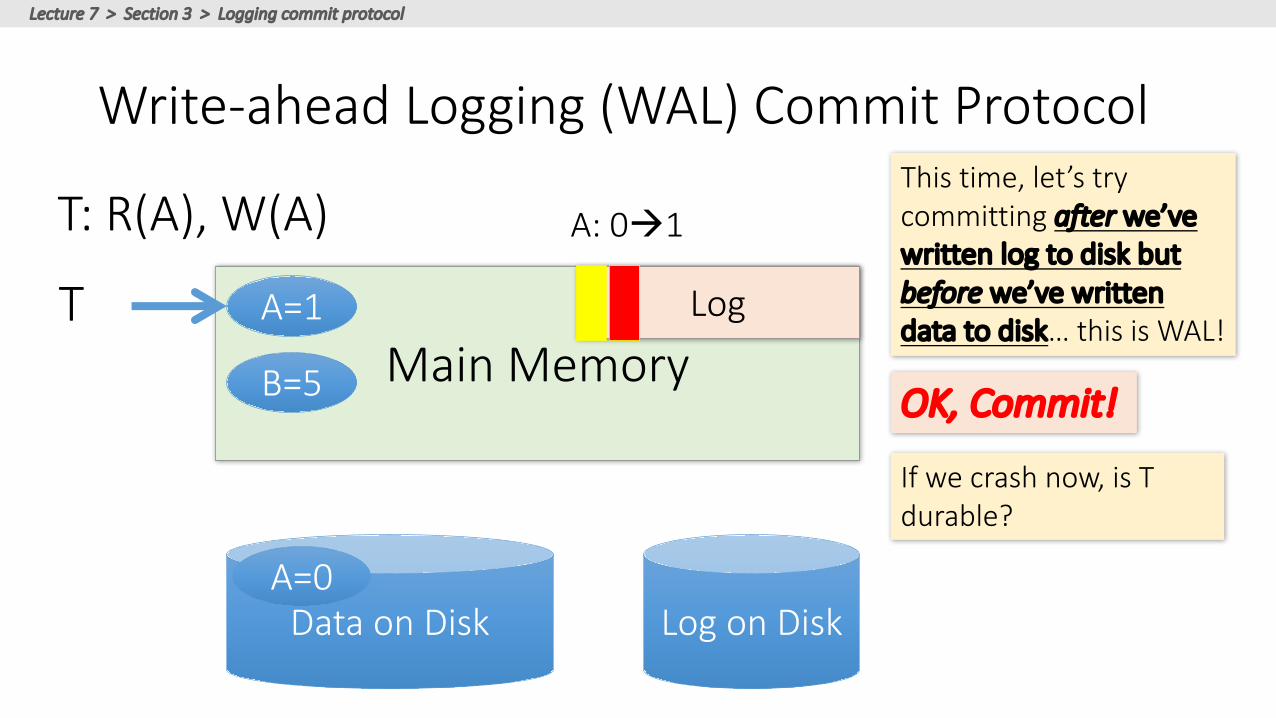
Write-aheadLogging(WAL)CommitProtocol
DataonDisk
MainMemory
LogonDisk
LogT A=1
B=5
A=0
T:R(A),W(A) A:0à1
Lecture7>Section3>Loggingcommitprotocol
Thistime,let’strycommittingafter we’vewrittenlogtodiskbutbefore we’vewrittendatatodisk…thisisWAL!
Ifwecrashnow,isTdurable?
OK,Commit!

Write-aheadLogging(WAL)CommitProtocol
DataonDisk
MainMemory
LogonDisk
T
A=0
T:R(A),W(A)
A:0à1
Lecture7>Section3>Loggingcommitprotocol
Thistime,let’strycommittingafter we’vewrittenlogtodiskbutbefore we’vewrittendatatodisk…thisisWAL!
Ifwecrashnow,isTdurable?
OK,Commit!
USETHELOG!A=1

Write-AheadLogging(WAL)
• DBusesWrite-AheadLogging(WAL) Protocol:
1. Mustforcelogrecord foranupdatebefore thecorrespondingdatapagegoestostorage
2. MustwritealllogrecordsforaTXbefore commit
Lecture7>Section3>Loggingcommitprotocol
Eachupdateislogged!Whynotreads?
à Atomicity
à Durability

WhyInterleaveTXNs?
• InterleavingTXNsmightleadtoanomalousoutcomes…whydoit?
• Severalimportantreasons:• IndividualTXNsmightbeslow- don’twanttoblockotherusersduring!
• Diskaccessmaybeslow- letsomeTXNsuseCPUswhileothersaccessingdisk!
17
Lecture8>Section1>Interleaving&scheduling
Allconcernlargedifferencesinperformance

Scheduling Definitions• Aserialschedule isonethatdoesnotinterleavetheactionsofdifferenttransactions
• AandBareequivalentschedules if, foranydatabasestate,theeffectonDBofexecutingAisidenticaltotheeffectofexecutingB
• Aserializableschedule isa schedulethatisequivalenttosome serialexecutionofthetransactions.
Theword“some”makesthisdefinitionpowerful& tricky!
Lecture8>Section1>Interleaving&scheduling

ConflictTypes
• Thus,therearethreetypesofconflicts:• Read-Writeconflicts(RW)• Write-Readconflicts(WR)• Write-Writeconflicts(WW)
Whyno“RRConflict”?
Lecture8>Section1>Interleaving&scheduling
Twoactionsconflict iftheyarepartofdifferentTXNs,involvethesamevariable,andatleastoneofthemisawrite
Interleavinganomaliesoccurwith/becauseoftheseconflictsbetweenTXNs (buttheseconflictscanoccurwithoutcausinganomalies!)
Seenextsectionformore!

Conflicts
Twoactionsconflict iftheyarepartofdifferentTXNs,involvethesamevariable,andatleastoneofthemisawrite
T1
T2
R(A) R(B)W(A) W(B)
R(A) R(B)W(A) W(B)W-RConflict
W-WConflict
Lecture8>Section2>ConflictSerializability

Conflicts
Twoactionsconflict iftheyarepartofdifferentTXNs,involvethesamevariable,andatleastoneofthemisawrite
T1
T2
R(A) R(B)W(A) W(B)
R(A) R(B)W(A) W(B)
All“conflicts”!
Lecture8>Section2>ConflictSerializability

Conflicts
Twoactionsconflict iftheyarepartofdifferentTXNs,involvethesamevariable,andatleastoneofthemisawrite
T1
T2
W(A) W(B)
W(A) W(B)
All“conflicts”!
Lecture8>Section2>ConflictSerializability

23
SerialSchedule:
X
InterleavedSchedules:
Whatcanwesayabout“good”vs.“bad”conflictgraphs?
T1 T2 T1 T2
T1 T2
Theorem:Scheduleisconflictserializable ifandonlyifitsconflictgraphisacyclic
Simple!
Lecture8>Section2>ConflictSerializability

DAGs&TopologicalOrderings
• Ex:Whatisonepossibletopologicalorderinghere?
1
32
0
Thereisnone!
Lecture8>Section2>Topologicalorderings

StrictTwo-phaseLocking(Strict2PL)Protocol:
TXNsobtain:
• AnX(exclusive)lockonobjectbeforewriting.
• IfaTXNholds,nootherTXNcangeta lock(SorX)onthatobject.
• AnS(shared)lockonobjectbeforereading
• IfaTXNholds,nootherTXNcangetanXlock onthatobject
• AlllocksheldbyaTXNarereleasedwhenTXNcompletes.
Note:Terminologyhere- “exclusive”,“shared”- meanttobeintuitive- notricks!
Lecture8>Section2>Strict2PL

Pictureof2-PhaseLocking(2PL)
TimeStrict2PL
0locks
#LockstheTXNhas
LockAcquisition
LockReleaseOnTXNcommit!
Lecture8>Section2>Strict2PL

Deadlocks
• Deadlock:Cycleoftransactionswaitingforlockstobereleasedbyeachother.
• Twowaysofdealingwithdeadlocks:
1. Deadlockprevention
2. Deadlockdetection
Lecture8>Section2>Deadlocks

High-Level:Lecture11
• Thebuffer &simplifiedfilesystemmodel
• ShifttoIOAwarealgorithms
• Theexternalmergealgorithm
FinalReview>Lecture11

High-level:Diskvs.MainMemory
Disk:
• Slow: Sequentialblock access• Readablocks(notbyte)atatime,sosequentialaccessischeaper
thanrandom• Diskread/writesareexpensive!
• Durable:Wewillassumethatonceondisk,dataissafe!
• Cheap 29
Platters
SpindleDisk head
Arm movement
Arm assembly
Tracks
Sector
Cylinder
RandomAccessMemory(RAM)orMainMemory:
• Fast: Randomaccess,byteaddressable• ~10xfasterforsequentialaccess• ~100,000xfasterforrandomaccess!
• Volatile: Datacanbelostife.g.crashoccurs,powergoesout,etc!
• Expensive: For$100,get16GBofRAMvs.2TBofdisk!
FinalReview>Lecture11

TheBuffer
Disk
MainMemory
Buffer• Abuffer isaregionofphysicalmemoryusedtostoretemporarydata
• KeyIdea:Reading/writingtodiskisSLOW,needtocachedatainmainmemory
• Canread intobuffer,flush backtodisk,release frombuffer
• DBMSmanagesitsownbufferforvariousreasons(bettercontrolofevictionpolicy,force-writelog,etc.)
• Weuseasimplifiedmodel:• Apage isafixed-lengtharrayofmemory;pagesaretheunitthatisreadfrom/writtentodisk
• Afileisavariable-lengthlistofpagesondisk
1,0,3 1,0,3File
Page
FinalReview>Lecture11
1,0,3

IOAware
• Keyidea:Readingfrom/writingtodisk- e.g.IOoperations- isthousandsoftimesslowerthananyoperationinmemory
• àWeconsideraclassofalgorithmswhichtrytominimizeIO,andeffectivelyignorecostofoperationsinmainmemory
FinalReview>Lecture11
“IOaware”algorithms!

ExternalMergeAlgorithm
• Goal:Mergesortedfilesthataremuchbiggerthanbuffer
• Keyidea:Sincetheinputfilesaresorted,wealwaysknowwhichfiletoreadfromnext!
• Details:
FinalReview>Lecture11
Given: B+1 bufferpagesInput: B sortedfiles,F1,…,FB,whereFi hasP(Fi)pagesOutput: OnemergedsortedfileIOCOST: 𝟐 ∗ ∑ 𝑷(𝑭𝒊)𝑩
𝒊*𝟏 (Eachpageisread&writtenonce)

High-Level:Lecture12
• ExternalMergeSortAlgorithm
• Basicalgorithm(including(B+1)-lengthinitialruns&B-waymerging)
• Repackingoptimizationforlongerinitialruns
• IndexesPartI:Basics
FinalReview>Lecture12
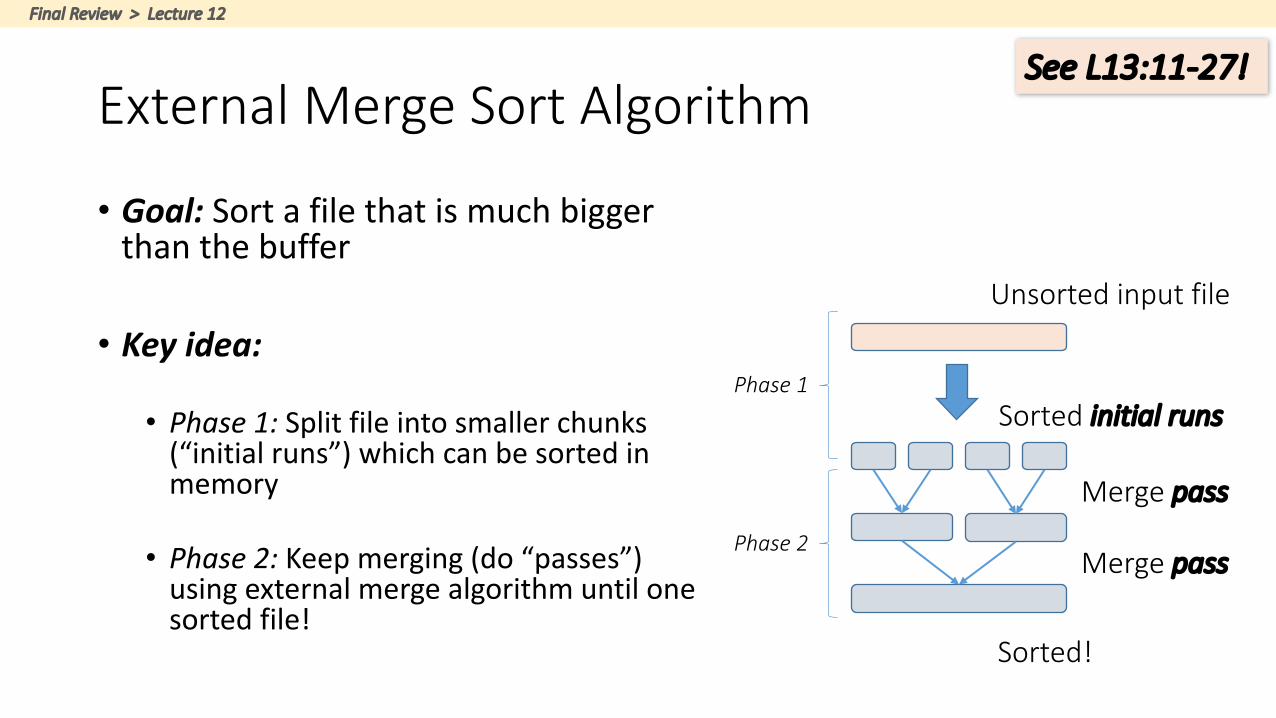
ExternalMergeSortAlgorithm
• Goal:Sortafilethatismuchbiggerthanthebuffer
• Keyidea:
• Phase1:Splitfileintosmallerchunks(“initialruns”)whichcanbesortedinmemory
• Phase2:Keepmerging(do“passes”)usingexternalmergealgorithmuntilonesortedfile!
FinalReview>Lecture12
Unsortedinputfile
SortedinitialrunsPhase1
Mergepass
Mergepass
Sorted!
Phase2
SeeL13:11-27!

ExternalMergeSortAlgorithm
FinalReview>Lecture12
Given: B+1 bufferpagesInput: UnsortedfileoflengthN
pagesOutput: ThesortedfileIOCOST:
𝟐𝑵( log𝑩𝑵
𝑩 + 𝟏+ 𝟏)
Phase 1: InitialrunsoflengthB+1arecreated• Thereare 𝑵
𝑩1𝟏ofthese
• TheIOcostis2N
Phase2:We dopassesofB-waymergeuntilfullymerged
• Need log𝑩𝑵𝑩1𝟏
passes• TheIOcostis2Nperpass

Indexes• Anindex onafilespeedsupselectionsonthesearchkey fieldsfortheindex.
• Wherethesearchkeycouldbeanysubsetoffields,anddoes not needtobethesameaskeyofarelation
BID Title Author Published Full_text
001 WarandPeace Tolstoy 1869 …
002 CrimeandPunishment Dostoyevsky 1866 …
003 AnnaKarenina Tolstoy 1877 …
Published BID
1866 002
1869 001
1877 003
Russian_NovelsBy_Yr_Index
Author Title BID
Dostoyevsky Crime andPunishment 002
Tolstoy AnnaKarenina 003
Tolstoy War andPeace 001
By_Author_Title_Index
FinalReview>Lecture12
Anindexiscovering foraspecificquery iftheindexcontainsalltheneededattributes
Notethisisthelogicalsetup,nothowdataisactuallystored!

High-Level:Lectures14-15
• IndexesPt.2:• B+Trees
• Clusteredvs.unclustered
• JoinAlgorithms:• NestedLoopJoinVariants:NLJ,BNLJ,INLJ
• SMJ
• HashJoin
FinalReview>Lectures14-15
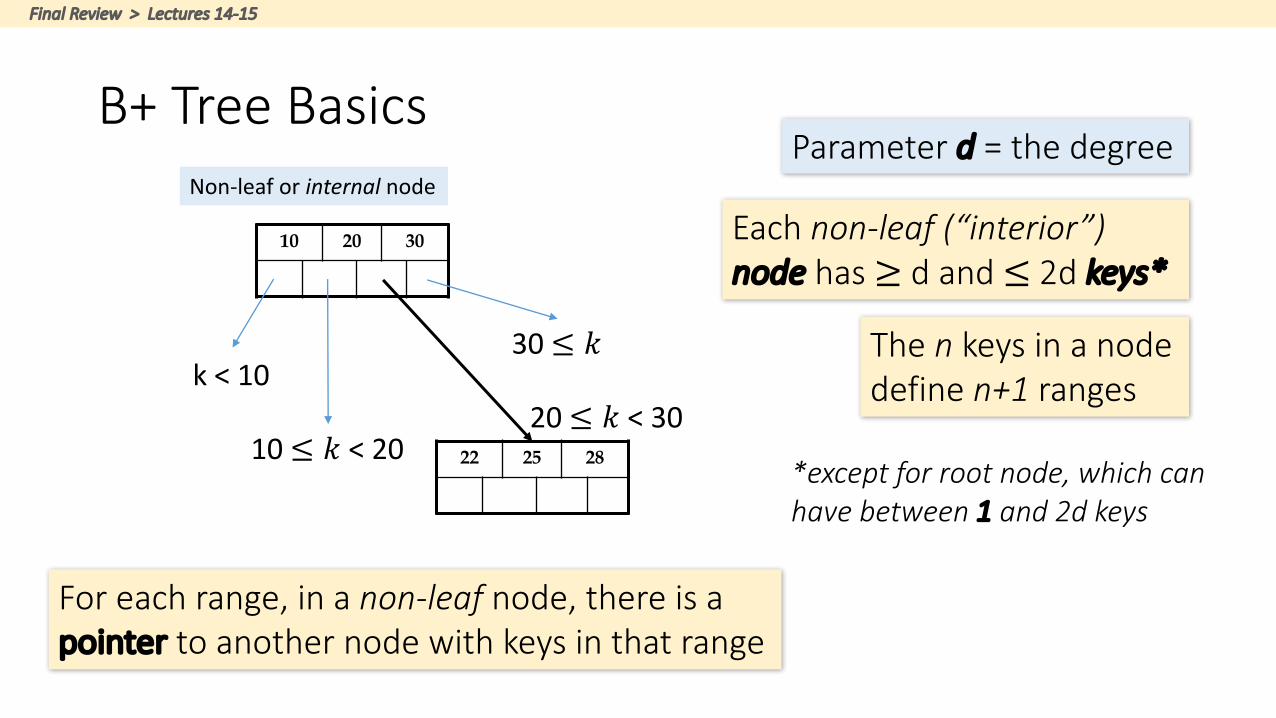
B+TreeBasics
10 20 30 Eachnon-leaf(“interior”)node has≥ dand≤2dkeys*
*exceptforrootnode,whichcanhavebetween1 and2dkeys
Parameterd =thedegree
FinalReview>Lectures14-15
k<10
10≤ 𝑘<2020≤ 𝑘<30
30≤ 𝑘 Thenkeysinanodedefinen+1ranges
Non-leaforinternalnode
22 25 28
Foreachrange,inanon-leafnode,thereisapointer toanothernodewithkeysinthatrange

B+TreeBasics
10 20 30
22 25 28 29
Leaf nodes
32 34 37 38
Non-leaforinternalnode
12 17
Name:JohnAge:21
Name:JakeAge:15
Name:BobAge:27
Name:SallyAge:28
Name:SueAge:33
Name:JessAge:35
Name:AlfAge:37Name:Joe
Age:11
Name:BessAge:22
Name:SalAge:30
FinalReview>Lectures14-15
Leafnodesalsohavebetweendand2dkeys,andaredifferentinthat:
Theirkeyslotscontainpointerstodatarecords
Theycontainapointertothenextleafnodeaswell,forfastersequentialtraversal

SearchingaB+Tree
10 20 30
22 25 28 29 32 34 37 3812 17
Name:JohnAge:21
Name:JakeAge:15
Name:BobAge:27
Name:SallyAge:28
Name:SueAge:33
Name:JessAge:35
Name:AlfAge:37Name:Joe
Age:11
Name:BessAge:22
Name:SalAge:30
FinalReview>Lectures14-15
SELECT nameFROM peopleWHERE age = 27
SELECT nameFROM peopleWHERE 27 <= ageAND age <= 35
SeeL14-15:17-18!

B+TreeRangeSearch
• Goal:Gettheresultssetofarange(orexact)querywithminimalIO
• Keyidea:• AB+Treehashighfanout (d~=102-103),whichmeansitisveryshallowà wecangettotherightrootnodewithinafewsteps!
• Thenjusttraversetheleafnodesusingthehorizontalpointers
• Details:• Onenodeperpage(thuspagesizedeterminesd)• Fillonlysomeofeachnode’sslots(thefill-factor)toleaveroomforinsertions
• WecankeepsomelevelsoftheB+Treeinmemory!
FinalReview>Lectures14-15
Notethatexactsearchisjustaspecialcaseofrangesearch(R=1)
Thefanout f isthenumberofpointerscomingoutofanode.Thus:
𝑑 + 1 ≤ 𝑓 ≤ 2𝑑 + 1
Notethatwewilloftenapproximatefasconstantacrossnodes!
Wedefinetheheight ofthetreeascountingtherootnode.Thus,givenconstantfanout f,atreeofheighth canindexfhpagesandhasfh-1 leafnodes

B+TreeRangeSearch
FinalReview>Lectures14-15
Given: • Parameter d• Fill-factorF• Bavailable pagesinbuffer• AB+TreeoverN pages• f isthefanout [d+1,2d+1]
Input: Aarangequery.
Output: TheRvaluesthatmatch
IOCOST:
log:𝑁𝐹− 𝐿𝐵 + 𝐂𝐨𝐬𝐭(𝑂𝑢𝑡)
where 𝐵 ≥ ∑ 𝑓𝑙HIJKL*M
DepthoftheB+Tree: ForeachleveloftheB+Treewereadinonenode=onepage
#oflevelswecanfitinmemory: Thesedon’tcostanyIO!
ThisequationisjustsayingthatthesumofallthenodesforLB levelsmustfitinbuffer
SeeL14-15:22-24!
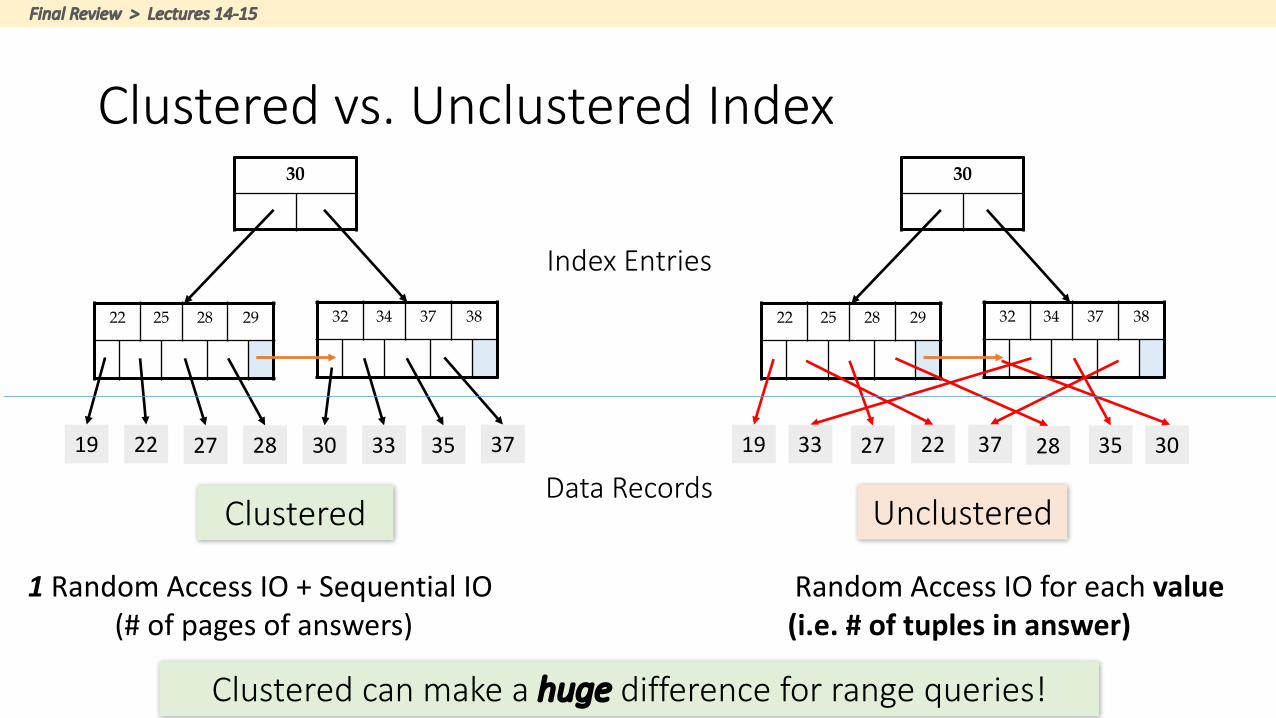
Clusteredvs.Unclustered Index30
22 25 28 29 32 34 37 38
19 22 27 28 30 33 35 37
30
22 25 28 29 32 34 37 38
19 2227 28 3033 3537
Clustered Unclustered
IndexEntries
DataRecords
FinalReview>Lectures14-15
1 RandomAccessIO+SequentialIO(#ofpagesofanswers)
RandomAccessIOforeachvalue(i.e.#oftuplesinanswer)
Clusteredcanmakeahuge differenceforrangequeries!
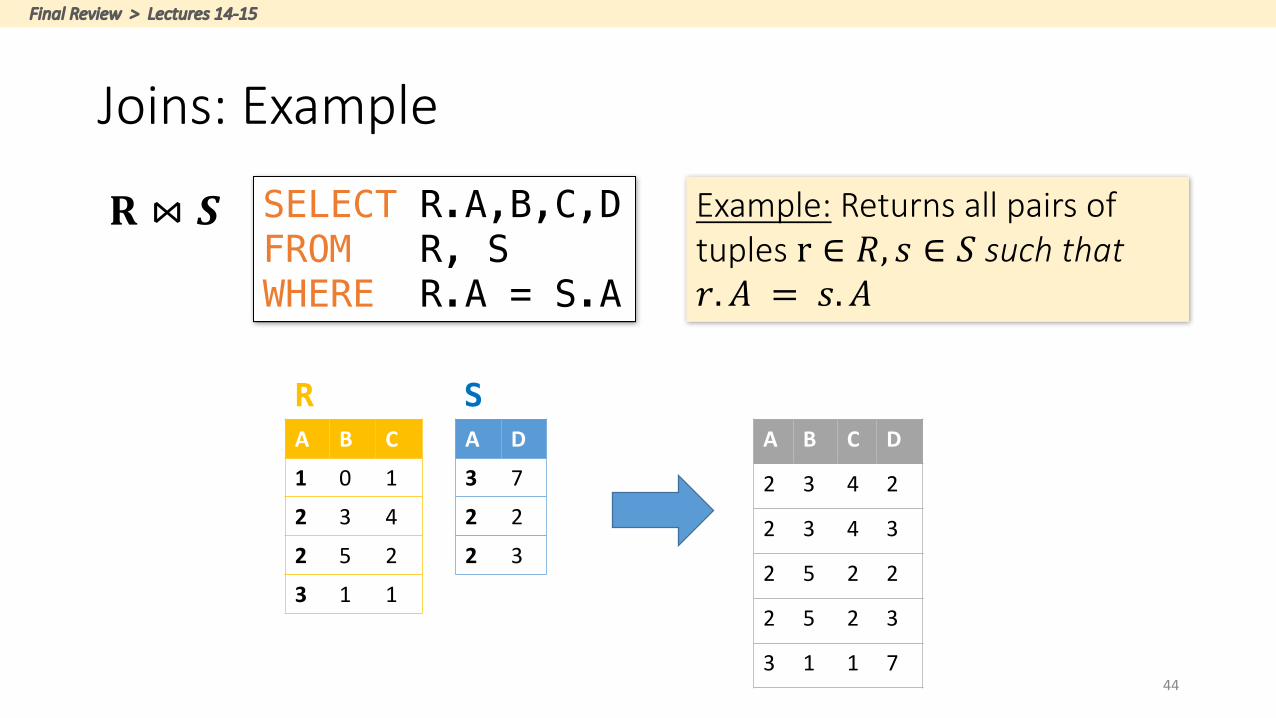
44
Joins:Example
Example: Returnsallpairsoftuplesr ∈ 𝑅, 𝑠 ∈ 𝑆suchthat𝑟. 𝐴 = 𝑠. 𝐴
A D
3 7
2 2
2 3
A B C
1 0 1
2 3 4
2 5 2
3 1 1
R SA B C D
2 3 4 2
2 3 4 3
2 5 2 2
2 5 2 3
3 1 1 7
𝐑 ⋈ 𝑺 SELECT R.A,B,C,DFROM R, SWHERE R.A = S.A
FinalReview>Lectures14-15

JoinAlgorithms:Overview
• NLJ:Anexampleofanon-IOawarejoinalgorithm
• BNLJ:BiggainsjustbybeingIOaware&readinginchunksofpages!
• SMJ:SortRandS,thenscanovertojoin!
• HJ:PartitionRandSintobucketsusingahashfunction,thenjointhe(muchsmaller)matchingbuckets
FinalReview>Lectures14-15
ForR ⋈ 𝑆𝑜𝑛𝐴
Quadratic inP(R),P(S)I.e.O(P(R)*P(S))
Givensufficientbufferspace,linearinP(R),P(S)I.e.~O(P(R)+P(S))
Byonlysupportingequijoins&takingadvantageofthisstructure!

NestedLoopJoin(NLJ)
Compute R ⋈ 𝑆𝑜𝑛𝐴:for r in R:for s in S:if r[A] == s[A]:yield (r,s)
P(R)+T(R)*P(S)+OUT
1. LoopoverthetuplesinR
2. ForeverytupleinR,loopoverallthetuplesinS
3. Checkagainstjoinconditions
4. Writeout(topage,thenwhenpagefull,todisk)
Cost:
NotethatIOcostbasedonnumberofpages loaded,notnumberoftuples!
HavetoreadallofSfromdiskforeverytupleinR!
FinalReview>Lectures14-15

BlockNestedLoopJoin(BNLJ)
Compute R ⋈ 𝑆𝑜𝑛𝐴:for each B-1 pages pr of R:
for page ps of S:for each tuple r in pr:
for each tuple s in ps:if r[A] == s[A]:
yield (r,s)
P 𝑅 +_ `IJK
𝑃(𝑆) +OUT
GivenB+1pagesofmemory
1. LoadinB-1pagesofRatatime(leaving1pageeachfreeforS&output)
2. Foreach(B-1)-pagesegmentofR,loadeachpageofS
3. Checkagainstthejoinconditions
4. Writeout
Cost:
Again,OUT couldbebiggerthanP(R)*P(S)…butusuallynotthatbad
FinalReview>Lectures14-15

SortMergeJoin(SMJ)
• Goal:ExecuteR⋈ SonA
• KeyIdea:WecansortRandS,thenjustscanoverthem!
• IOCost:• Sortphase:Sort(R)+Sort(S)• Merge/joinphase:~P(R)+P(S)+OUT
• Canbeworsethough- seenextslide!
FinalReview>Lectures14-15
SR
Unsortedinputrelations
Split&sort
Merge
SRMerge
SeeL14-15:63-69!

Merge/JoinPhase
SortPhase(Ext.MergeSort)
SimpleSMJOptimization
SR
Split&sortSplit&sort
MergeMerge
GivenB+1bufferpages
Thisallowsusto“skip”thelastsort&save2(P(R)+P(S))!
Unsortedinputrelations
<=Btotalruns
B-WayMerge/Join
FinalReview>Lectures14-15
SeeL14-15:78-81!

HashJoin
SR
Unsortedinputrelations
FinalReview>Lectures14-15
Joinmatchingbuckets
1 2 3 41 2 3 4
1 21 2
Partition
Partition
h h
h' h'
• Goal:ExecuteR⋈ SonA
• KeyIdea:WecanpartitionRandSintobucketsbyhashingthejoinattribute-thenjustjointhepairsof(small)matchingbuckets!
• IOCost:• Partitionphase:2(P(R)+P(S))eachpass• Joinphase:Dependsonsizeofthebuckets…canbe~P(R)+P(S)+OUTiftheyaresmallenough!
• Canbeworsethough- seenextslide!
SeeL14-15:88-!

HJ:Skew
• Ideally,ourhashfunctionswillpartitionthetuplesuniformly
• However,hashcollisionsandduplicatejoinkeyattributes cancauseskew
• Forhashcollisions,wecanjustpartitionagainwithanewhashfunction
• Duplicatesarejustaproblem…(SimilartoinSMJ!)
FinalReview>Lectures14-15
R
1
2
3
4
R
1
2
3
4
SeeL14-15:109-112!

Overview:SMJvs.HJ
FinalReview>Lectures14-15
SMJ HJ
• Wecreateinitialsortedruns
• WekeepmergingtheserunsuntilwehaveonesortedmergedrunforR,S
• WescanoverRandStocompletethejoin
• Wekeeppartitioning RandSintoprogressivelysmallerbucketsusinghashfunctionsh,h’,h’’…
• Wejoinmatchingpairsofbuckets(usingBNLJ)
Note:Ext.MergeSort!
Howmanyofthesepassesdoweneedtodo?
R⋈ SonA

Howmanypassesdoweneed?
#ofpasses
Lengthofruns
#of runs
0 1 N
1 B+1 𝑁𝐵 + 1
2 B(B+1) 1𝐵
𝑁𝐵 + 1
… … …
k+1 Bk(B+1) 1𝐵b
𝑁𝐵 + 1
#ofpasses
Avg. bucketsize
#of buckets
0 N 1
1𝑁𝐵
B
21𝐵𝑁𝐵
B2
… … …
k+11𝐵b
𝑁𝐵
Bk+1
FinalReview>Lectures14-15
SMJ HJ
Fewer,longerrunsbyafactorofB More, smallerbucketsbyafactorofBEachpass,weget:
R⋈ SonA
Initialsortedruns
Eachpasscosts2(𝑃 𝑅 + 𝑃 𝑆 )

Howmanypassesdoweneed?
#ofpasses
Lengthofruns
#of runs
k+1 Bk(B+1)1𝐵b
𝑁(𝐵 + 1)
#ofpasses
Avg. bucketsize
#of buckets
k+11𝐵b
𝑁𝐵
Bk+1
FinalReview>Lectures14-15
SMJ HJ
R⋈ SonA
If(#ofrunsofR)+(#ofrunsofS)≤ 𝐵,thenwearereadytocompletethejoininonepass*:
B ≥P R
Bk B + 1+
P SBk B + 1
𝐵b1K(𝐵 + 1) ≥ P R + P(S)
*Usingthe‘optimization’onslide25
Ifoneof therelationshasbucketsize≤ 𝐵 − 1,thenwehavepartitionedenoughtocompletethejoinwithsingle-passBNLJ:
B − 1 ≥min{P R , 𝑃 𝑆 }
𝐵b1K
𝐵b1K(B − 1) ≥ min{P R , 𝑃 𝑆 }

Howmanybufferpagesfornicebehavior?
FinalReview>Lectures14-15
𝐵(𝐵 + 1) ≥ P R + P(S)
Ifweuserepacking,thenwecansatisfytheaboveifapproximately:
𝐵2 ≥ max{P R , P S }
R⋈ SonA
à TotalIOCost=3(P(R)+P(S))+OUT!
Let’sconsiderwhatBwe’dneedfork+1=1passes(plusthefinaljoin):
SMJ HJ
𝐵(𝐵 − 1) ≥ min{P R , P S }
Soapproximately:
𝐵2 ≥ min{P R , P S }

Overview:SMJvs.HJ
• HJ:• PROS:Nicelinearperformanceisdependentonthesmallerrelation• CONS:Skew!
• SMJ:• PROS:Greatifrelationsarealreadysorted;outputissortedeitherway!• CONS:
• Nicelinearperformanceisdependentonthelargerrelation• Backup!
FinalReview>Lectures14-15

High-Level:Lecture16
• OverallRDBMSarchitecture
• TheRelationalModel
• RelationalAlgebra
FinalReview>Lectures16
CheckouttheRelationalAlgebrapracticeexercisesnotebook!!
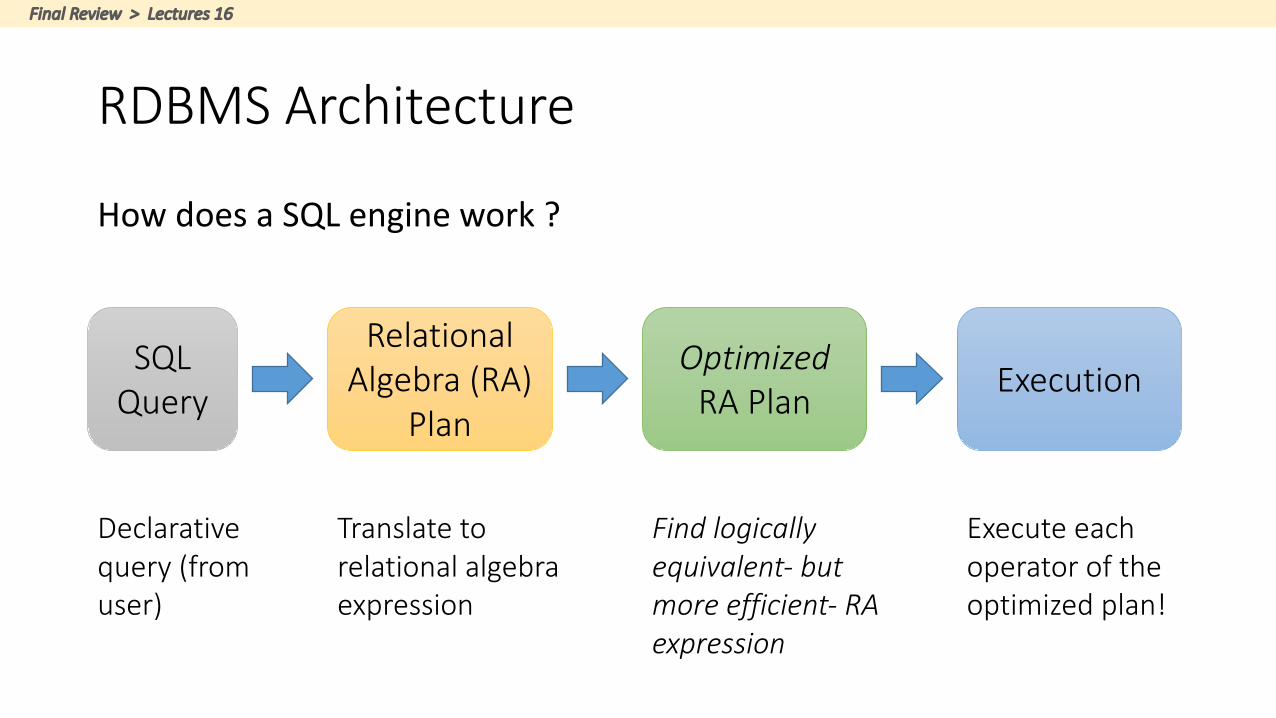
RDBMSArchitecture
HowdoesaSQLenginework?
SQLQuery
RelationalAlgebra(RA)
Plan
OptimizedRAPlan Execution
Declarativequery(fromuser)
Translatetorelationalalgebraexpression
Findlogicallyequivalent- butmoreefficient- RAexpression
Executeeachoperatoroftheoptimizedplan!
FinalReview>Lectures16

59
TheRelationalModel:Data
sid name gpa
001 Bob 3.2
002 Joe 2.8
003 Mary 3.8
004 Alice 3.5
StudentAnattribute (orcolumn)isatypeddataentrypresentineachtupleintherelation
Thenumberofattributesisthearity oftherelation
Atuple orrow (orrecord)isasingleentryinthetablehavingtheattributesspecifiedbytheschema
Thenumberoftuplesisthecardinality oftherelation
Arelationalinstance isaset oftuplesallconformingtothesameschema
FinalReview>Lectures16

• Fivebasicoperators:1. Selection: s2. Projection:P3. CartesianProduct:´4. Union:È5. Difference:-
• Derivedorauxiliaryoperators:• Intersection,complement• Joins(natural,equi-join,thetajoin,semi-join)• Renaming: r• Division
RelationalAlgebra(RA)
FinalReview>Lectures16

• Returnsalltupleswhichsatisfyacondition
• Notation: sc(R)• Theconditionccanbe=,<,>, <>
1.Selection(𝜎)
SELECT *FROM StudentsWHERE gpa > 3.5;
SQL:
RA:𝜎nopqr.s(𝑆𝑡𝑢𝑑𝑒𝑛𝑡𝑠)
Students(sid,sname,gpa)
FinalReview>Lectures16

• Eliminatescolumns,thenremovesduplicates
• Notation:P A1,…,An (R)
2.Projection(Π)
SELECT DISTINCTsname,gpa
FROM Students;
SQL:
RA:Πvwpxy,nop(𝑆𝑡𝑢𝑑𝑒𝑛𝑡𝑠)
Students(sid,sname,gpa)
FinalReview>Lectures16

• EachtupleinR1witheachtupleinR2
• Notation:R1´ R2• Rareinpractice;mainlyusedtoexpressjoins
3.Cross-Product(×)
SELECT *FROM Students, People;
SQL:
RA:𝑆𝑡𝑢𝑑𝑒𝑛𝑡𝑠×𝑃𝑒𝑜𝑝𝑙𝑒
Students(sid,sname,gpa)People(ssn,pname,address)
FinalReview>Lectures16
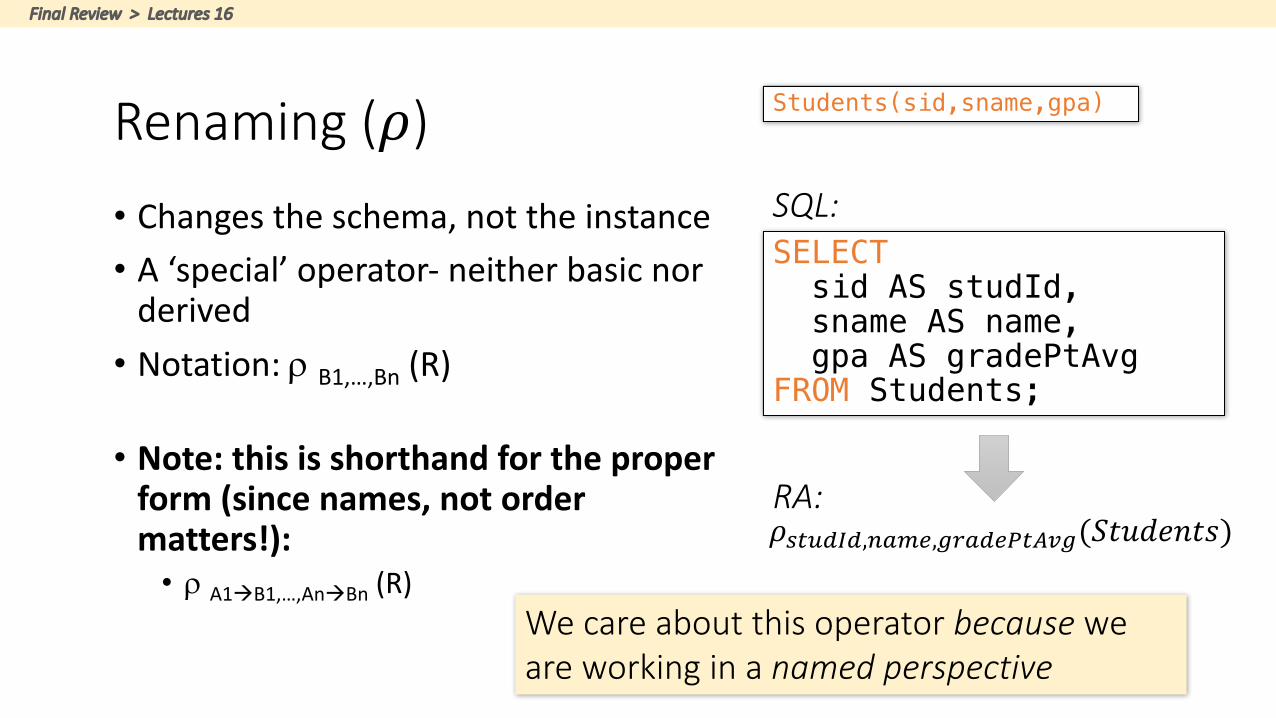
• Changestheschema,nottheinstance• A‘special’operator- neitherbasicnorderived
• Notation:r B1,…,Bn (R)
• Note:thisisshorthandfortheproperform(sincenames,notordermatters!):
• r A1àB1,…,AnàBn (R)
Renaming(𝜌)
SELECTsid AS studId,sname AS name,gpa AS gradePtAvg
FROM Students;
SQL:
RA:𝜌v}~���,wpxy,n�p�y_}��n(𝑆𝑡𝑢𝑑𝑒𝑛𝑡𝑠)
Students(sid,sname,gpa)
Wecareaboutthisoperatorbecause weareworkinginanamedperspective
FinalReview>Lectures16

• Notation:R1⋈R2
• JoinsR1 andR2 onequalityofallsharedattributes• IfR1 hasattributesetA,andR2 hasattributesetB,andtheyshareattributesA⋂B=C,canalsobewritten:R1⋈ 𝐶R2
• OurfirstexampleofaderivedRA operator:• Meaning:R1⋈ R2 =PAUB(sC=D(𝜌�→�(R1)´ R2))• Where:
• Therename𝜌�→� renamesthesharedattributesinoneoftherelations
• TheselectionsC=Dchecksequalityofthesharedattributes• TheprojectionPAUBeliminatestheduplicate
commonattributes
NaturalJoin(⋈)
SELECT DISTINCTssid, S.name, gpa,ssn, address
FROM Students S,People P
WHERE S.name = P.name;
SQL:
RA:𝑆𝑡𝑢𝑑𝑒𝑛𝑡𝑠 ⋈ 𝑃𝑒𝑜𝑝𝑙𝑒
Students(sid,name,gpa)People(ssn,name,address)
FinalReview>Lectures16

ConvertingSFWQuery->RASELECT DISTINCT A1,…,AnFROM R1,…,RmWHERE c1 AND … AND ck;
Π�K,…,�w(𝜎�K …𝜎�b(𝑅1 ⋈ ⋯ ⋈ 𝑅𝑚))
FinalReview>Lectures16
Whymusttheselections“happenbefore”theprojections?

High-Level:Lecture17
• Logicaloptimization
• Physicaloptimization
• Indexselections
• IOcostestimation
FinalReview>Lecture17

Logicalvs.PhysicalOptimization
• Logicaloptimization:• Findequivalentplansthataremoreefficient• Intuition:Minimize#oftuplesateachstepbychangingtheorderofRAoperators
• Physicaloptimization:• FindalgorithmwithlowestIOcosttoexecuteourplan
• Intuition:Calculatebasedonphysicalparameters(buffersize,etc.)andestimatesofdatasize(histograms)
Execution
SQLQuery
RelationalAlgebra(RA)Plan
OptimizedRAPlan
FinalReview>Lecture17

LogicalOptimization:“Pushingdown”projection
ΠI
R(A,B) S(B,C)
ΠI
R(A,B) S(B,C)
ΠI
Whymightwepreferthisplan?
FinalReview>Lecture17

LogicalOptimization:“Pushingdown”selection
𝜎I��
R(A,B) S(B,C)
𝜎I��
R(A,B) S(B,C)
𝜎I��
Whymightwepreferthisplan?
FinalReview>Lecture17

RAcommutators
• Thebasiccommutators:• Pushprojection through(1)selection,(2)join• Pushselectionthrough(3)selection,(4)projection,(5)join• Also:Joinscanbere-ordered!
• Notethatthisisnotanexhaustivesetofoperations• Thiscoverslocalre-writes;globalre-writespossiblebutmuchharder
ThissimplesetoftoolsallowsustogreatlyimprovetheexecutiontimeofqueriesbyoptimizingRAplans!
FinalReview>Lecture17

IndexSelectionInput:
• Schemaofthedatabase• Workloaddescription: setof(querytemplate,frequency)pairs
Goal:Selectasetofindexesthatminimizeexecutiontimeoftheworkload.
• Cost/benefitbalance:Eachadditionalindexmayhelpwithsomequeries,butrequiresupdating
Thisisanoptimizationproblem!
FinalReview>Lecture17

IOCostEstimationviaHistograms
• Forindexselection:• Whatisthecostofanindexlookup?
• Alsofordecidingwhichalgorithmtouse:• Ex:ToexecuteR ⋈ 𝑆,whichjoinalgorithmshouldDBMSuse?
• Whatifwewanttocompute𝝈𝑨q𝟏𝟎(𝐑) ⋈ 𝝈𝑩*𝟏(𝑺)?
• Ingeneral,wewillneedsomewaytoestimate intermediateresultsetsizes
Histogramsprovideawaytoefficientlystoreestimatesofthesequantities
FinalReview>Lecture17

Histogramtypes
Allbucketsroughlythesamewidth
Allbucketscontainroughlythesamenumberofitems(totalfrequency)
Equi-depth
Equi-width
FinalReview>Lecture17

















