
Crowdsourced query augmentation through the semantic discovery of domain specific jargon
18
Crowdsourced Query Augmentation through the Semantic Discovery of Domain-specific Jargon Khalifeh Aljadda, Mohammed Korayem, Trey Grainger, Chris Russell 2014.10.28 - 2014 IEEE International Conference on Big Data - Washington, D.C.
-
Upload
trey-grainger -
Category
Technology
-
view
1.952 -
download
2
Transcript of Crowdsourced query augmentation through the semantic discovery of domain specific jargon

Crowdsourced Query Augmentation through the Semantic Discovery of Domain-specific Jargon
Khalifeh Aljadda, Mohammed Korayem, Trey Grainger, Chris Russell
2014.10.28 - 2014 IEEE International Conference on Big Data - Washington, D.C.

Authors
• Khalifeh AlJadda– Ph.D. Candidate, University of Georgia
• Mohammed Korayem– Ph.D. Candidate, Indiana University
• Trey Grainger– Director of Engineering, Search, CareerBuilder
• Chris Russell– Engineering Lead, Relevancy & Recommendations, CareerBuilder

The problem• Traditional search engines (i.e. Lucene, Solr, Elasticsearch) tokenize text
and find documents containing those tokens and linguistic variations:– User’s Search: machine learning
Tokenization: ["machine", "learning"] => Stemming: ["machin", "learn"]Final Query: machin AND learn
This could match a document for a “machinist” who has “learned” something.
– software architect => … => software AND architect• Might identify a building architect requiring knowledge of specialized architecture software
– account manager => … => account AND manag• Will match text such as “need to manage the process and account for any variances”
• We need a way to identify and search for the meaning of keyword phrases, not just the individual text tokens– i.e. machine learning = "machine learning" OR "data scientist" OR
"mahout" OR "svm" OR "neural networks" …

Goals for the proposed system• System should be language-agnostic. We don’t want custom NLP
rules to be required for each language (we support dozens of languages).
• The output of the system should be human-readable. We want to show user’s how we enhance their queries in language they will understand so they can modify our enhancements.
• The system should be very high-precision (since end-users will be seeing and critiquing the output) and should be automatically updated based upon new data.
• The system must be fast and scalable, handling billions of search log entries (offline) and processing millions of queries an hour in real-time

Alternate Techniques• Latent Semantic Indexing
– Approach involves doing dimensionality reduction of text across your corpus to derive underlying relationships between terms:
• i.e. java => programming, c# => programming, therefore they are related.
– Pros:
• Can be run automatically against your corpus of data to discover underlying (latent) relationships between terms, which requires very little human work
– Cons:
• The latent relationships often aren’t represented as a human would express them, so it would confuse users if they saw this information.

• Manual building of taxonomies– Approach requires hiring human data analysts to manually
build, correct, and improve taxonomies
– Pros:
• high-precision relationships can be mapped depending upon the quality of your hired data analysts
– Cons:
• Requires human analysts to comb through hundreds of thousands of data points and generate lists of important phrases and relationships, which go stale
• Requires expertise in every supported spoken language to rebuild taxonomies per-language
Alternate Techniques

Example use case• User’s Query:
machine learning research and development Portland, OR software engineer AND hadoop java
• Traditional Search Engine Parsing:(machine AND learning AND research AND development AND portland) OR (software AND engineer AND hadoop AND java )
• Ideal Parsing:"machine learning" AND "research and development" AND "Portland, OR” AND "software engineer" AND hadoop AND java
• Semantically Enhanced Query: ("machine learning" OR "computer vision" OR "data mining" OR matlab) AND ("research and development" OR "r&d") AND ("Portland, OR" OR "Portland, Oregon") AND ("software engineer" OR "software developer") AND (hadoop OR "big data" OR hbase OR hive) AND (java OR j2ee)

Proposed strategy1. Mine user search logs for a list of common phrases (“jargon”)
within our domain.
2. Perform collaborative filtering on the common jargon (“user’s who searched for that phrase also search for this phrase”)
3. Remove noise through several methodologies:– Segment search phrases based upon the
classification of users– Consider shared jargon used by multiple
sides of our two-sided market (i.e. both Job Seekers and Recruiters utilize the same phrase)
– Validate that the two “related” phrases actually co-occur in real content (i.e. within the same job or resume) with some frequency

● Implementation: Map/Reduce job which finds and scores similar searches run for the same users
○ Jane searched for “registered nurse” and “r.n.” and “nurse”.○ Zeke searched for “java developer” and “scala” and “jvm” and “j2ee”
Finding and Scoring Related Jargon

Similarity Score:To do the collaborative filtering, we look at two similarity measures:
1. Search Co-occurrences - provides raw, real-world correlation2. Point-wise Mutual Information - examines probability of terms being
related by contrasting individual vs joint distributions:
Final Score:
Finding and Scoring Related Jargon

Example output
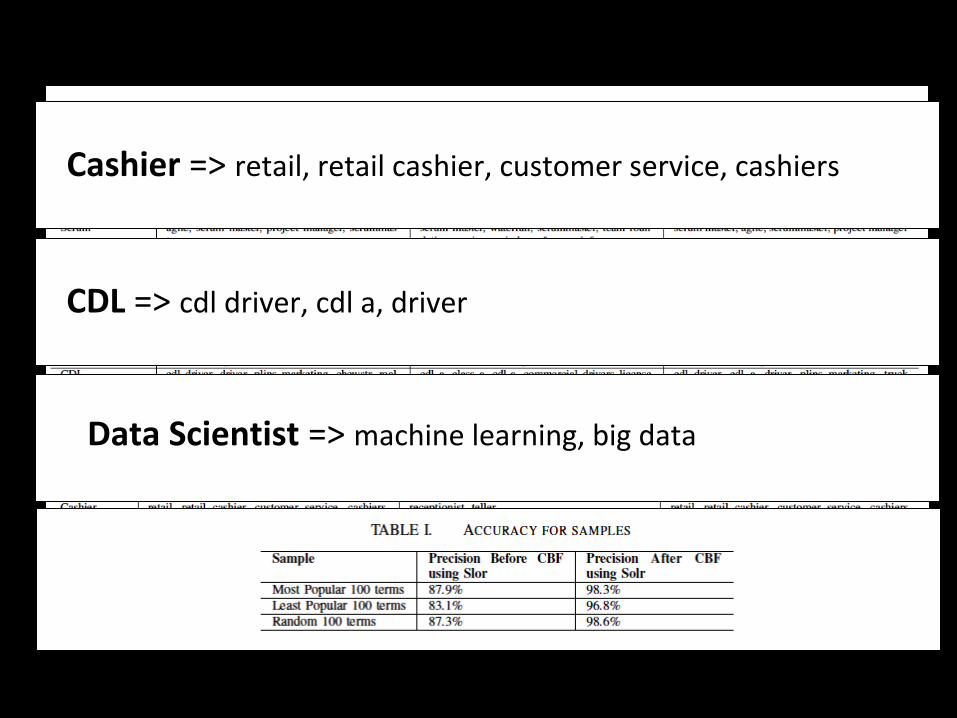
Example output
Cashier => retail, retail cashier, customer service, cashiers
CDL => cdl driver, cdl a, driver
Data Scientist => machine learning, big data

Final System Architecture

Follow-on work: Differentiating related Jargon
Synonyms: cpa => Certified Public Accountant rn => Registered Nurse r.n. => Registered Nurse
Ambiguous Terms*: driver => driver (trucking) ~80% driver => driver (software) ~20%
Related Terms: r.n. => nursing, bsn hadoop => mapreduce, hive, pig
*disambiguated based upon user and query context

Applicability of Methodology
• Can be used to discover domain-specific jargon across most domains (not just employment search)
• Can be used to discover related jargon in any language since the jargon and relationships is crowd-sourced at the phrase level
• The high-precision results achieved by intersecting input from both sides of a two-sided market is optional. If you only have a single source of user queries, you will just get lower-precision mappings.
• The only absolute requirement is sufficient search log history mapping users to multiple search phrases

Q&A

Semantic Search “under the hood”
Contact Info
Yes, WE ARE HIRING @CareerBuilder. Come talk with me if you are interested…
▪ Trey [email protected]@treygrainger
Other presentations: http://www.treygrainger.com http://solrinaction.com


















