
CRM Segmentation Segmentation of Textual Data Zhangxi Lin.
49
CRM Segmentation Segmentation of Textual Data Zhangxi Lin
-
Upload
gertrude-gibbs -
Category
Documents
-
view
235 -
download
2
Transcript of CRM Segmentation Segmentation of Textual Data Zhangxi Lin.

CRM Segmentation
Segmentation of Textual Data
Zhangxi Lin

2
Overview Text Mining Review Converting Unstructured Text to Structured Data Segmenting Textual Data Demonstrations

3
Text Mining Review

Text Mining – Why and How
The volume of text data is much greater than that of numeric data
The means dealing with text data is far from enough

5
What Text Mining Is Text mining is a process that employs a set of
algorithms for converting unstructured text into structured data objects and the quantitative methods used to analyze these data objects.
“SAS defines text mining as the process of investigating a large collection of free-form documents in order to discover and use the knowledge that exists in the collection as a whole.” (SAS Text Miner: Distilling Textual Data for Competitive Business Advantage)

6
What Text Mining Is Not
Text mining is not a text summarization tool an information extraction methodology a natural language processor.
7
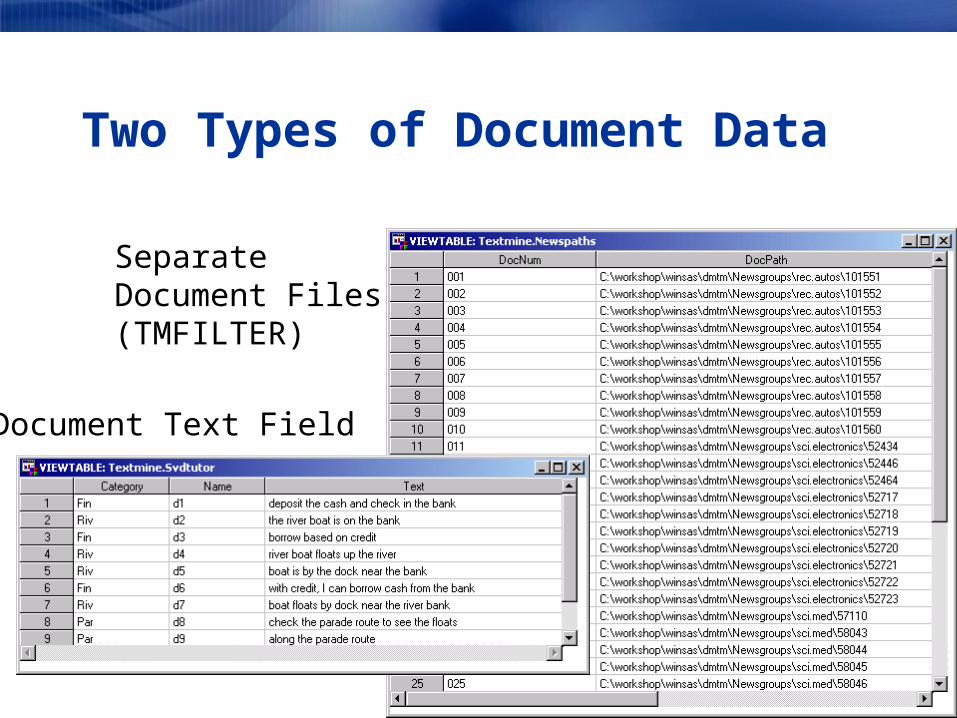
Two Types of Document Data
Document Text Field
SeparateDocument Files(TMFILTER)

8
The SAS Text Mining Process1. Preprocess document files to create a SAS data set.
TMFILTER macro SAS language features
2. Parse the document field. PARSE tab in Text Miner Stemming Part-of-speech tagging Entities Stop/start lists Synonym lists And so forth
continued...

9
The SAS Text Mining Process3. Derive the term by document frequency matrix.
The Text Miner Transform tab Frequency weights Term weights
4. Transform the term by document frequency matrix. The Text Miner Transform Tab Singular Value Decomposition (SVD) Roll Up Terms
5. Perform the analysis. Exploration Clustering/unsupervised learning Predictive modeling

10
Text Mining Strengths Clustering documents in a corpus Investigating word (token) distribution across
documents within a corpus Identifying words with the highest discriminatory
power Classifying documents into predefined
categories Integrating text data with structured data to
enrich predictive modeling endeavors

11
Text Mining Deficiencies
Text mining algorithms perform poorly in distinguishing negations, for example: Herman was involved in a motor vehicle accident. Herman was NOT involved in a motor vehicle accident.
Text mining cannot generally make value judgments, for example, classifying an article as positive or negative with respect to any tokens it contains.

12
Text Mining Deficiencies
Text mining algorithms do not work well with large documents. Performance is slow. Increased term occurrence across documents
decreases separation of documents.

13
The SAS Text Mining Process1. Preprocess document files to create a SAS data set.
TMFILTER macro SAS language features
2. Parse the document field. PARSE tab in Text Miner Stemming Part-of-speech tagging Entities Stop/start lists Synonym lists And so forth
continued...

14
The SAS Text Mining Process3. Derive the term by document frequency matrix.
The Text Miner Transform tab Frequency weights Term weights
4. Transform the term by document frequency matrix. The Text Miner Transform Tab Singular Value Decomposition (SVD) Roll Up Terms
5. Perform the analysis. Exploration Clustering/unsupervised learning Predictive modeling

15
This demonstration illustrates how to use the TMFILTER macro to process groups of text files.
Using the TMFILTER Macro with the Newsgroups Data

16
SAS Text Miner Text Processing Features
Text parsing Removal of stop words Part-of-speech tagging Stems and synonym handling Entities

17
Stop Words Stop words are words that have little or no value in
identifying a document or in comparing documents. Standard stop lists contain stop words that are
Articles (the, a, this) Conjunctions (and, but, or) Prepositions (of, from, by).
Custom stop lists identify low information words, like the word “computer” in a collection of articles about computers.
18
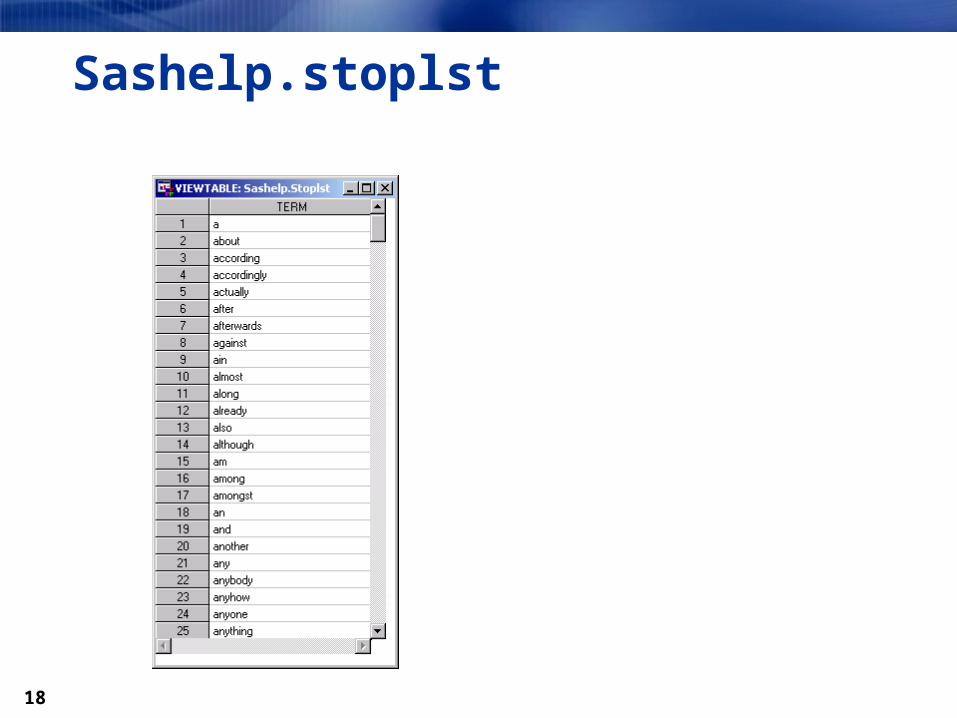
Sashelp.stoplst
19
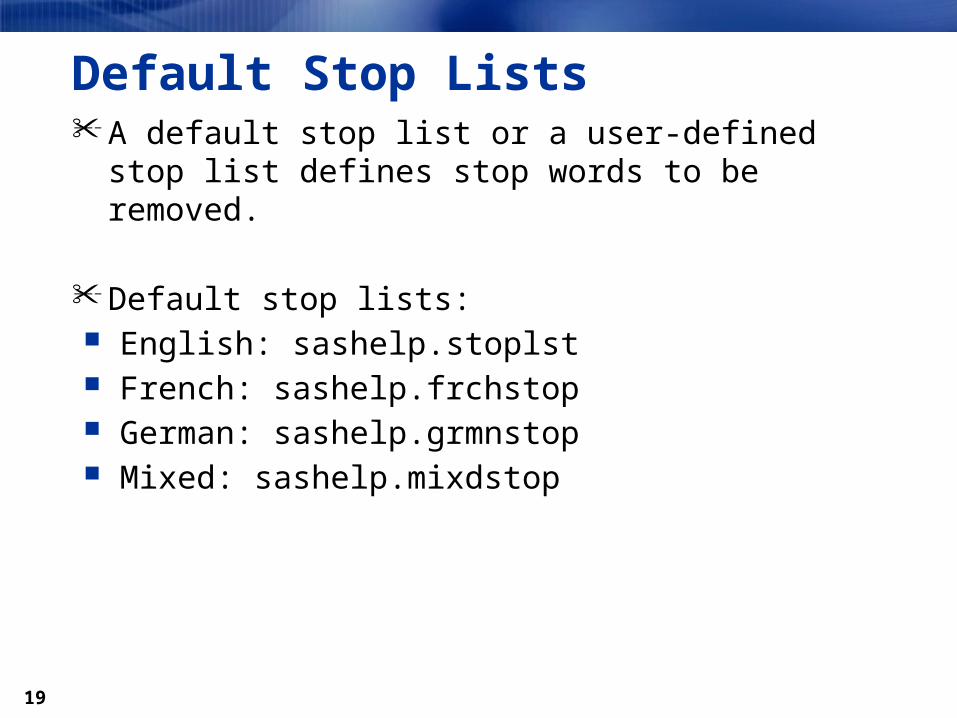
Default Stop Lists A default stop list or a user-defined stop list defines
stop words to be removed.
Default stop lists: English: sashelp.stoplst French: sashelp.frchstop German: sashelp.grmnstop Mixed: sashelp.mixdstop

20
Stop List versus Start List Use a start list when
– documents are dominated by “technical jargon”– domain expertise can enhance text mining.
Use a stop list when– documents are loosely related: news, business
reports, Internet searches– domain expertise is not available.

21
Issues in Creating a Start List Do not just add high frequency terms.
– Low frequency terms that only appear in a few documents may be good discriminators.
– High frequency terms may be candidates for a stop list.
Data-derived start lists should be reviewed by domain experts.

22
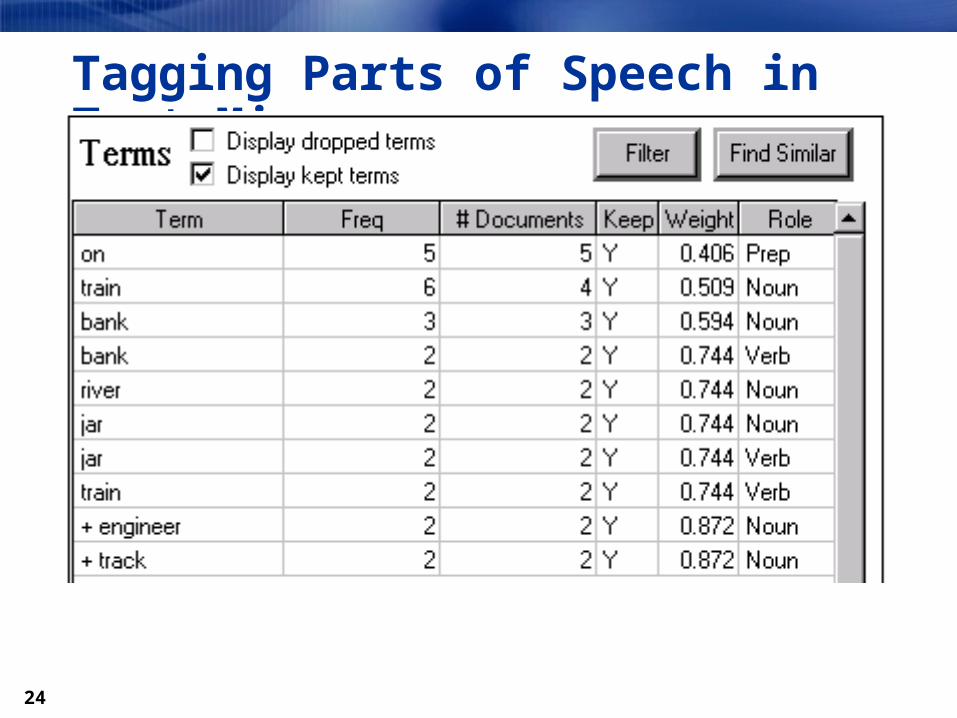
Tagging Parts of Speech Determines if the word is a common noun, verb,
adjective, proper noun, adverb, and so forth. Disambiguate parts of speech when a word is used in a
different context, I wish that my bank had more ATM machines. You can bank on either Philadelphia or Oakland
winning the Super Bowl next year. Settlers living on the west bank of the river were
forced to relocate.

23
Tagging Parts of Speech in Text Miner
continued...
24
Tagging Parts of Speech in Text Miner
25
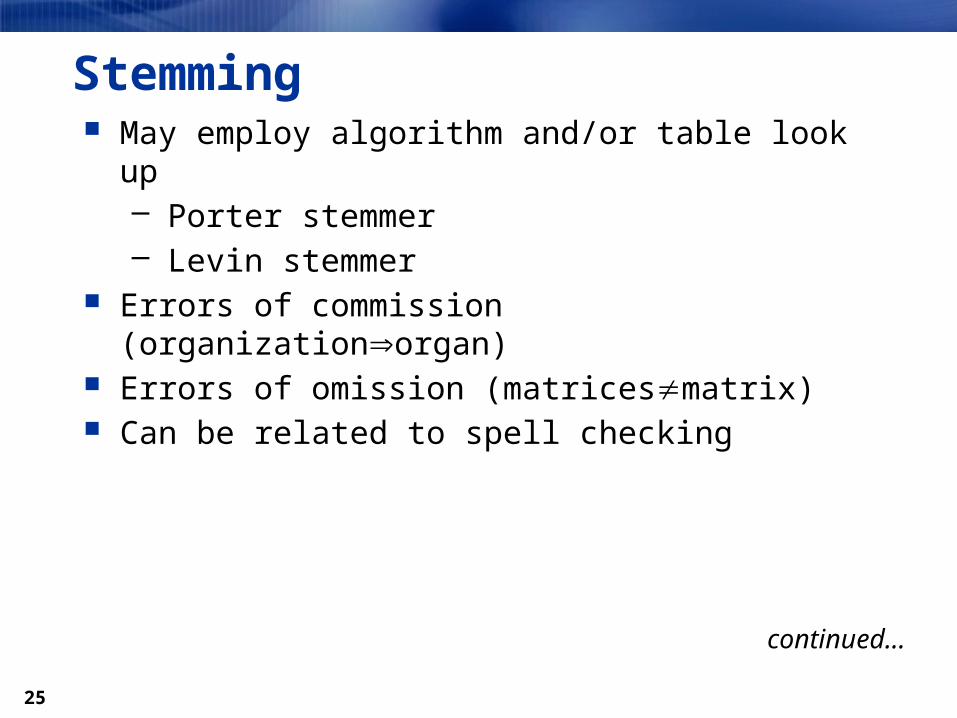
Stemming May employ algorithm and/or table look up
– Porter stemmer– Levin stemmer
Errors of commission (organizationorgan) Errors of omission (matricesmatrix) Can be related to spell checking
continued...

26
Stemming Examples
BIG: BIG, BIGGER, BIGGEST REACH: REACH, REACHES, REACHED, REACHING WORK: WORK, WORKS, WORKED, WORKING
CHILD: CHILD, CHILDREN KNIFE: KNIFE, KNIVES
PERRO: PERRO, PERRA (Spanish, male and female dog)
27
Stemming in Text Miner
continued...

28
Stemming in Text Miner Text Miner performs stemming to derive stem
synonyms, for example, run/ran/runs/running, and combines these with defined synonyms, for example, run/sprint.
The default synonym data set for Text Miner, sashelp.engsynms, is primarily for illustration.
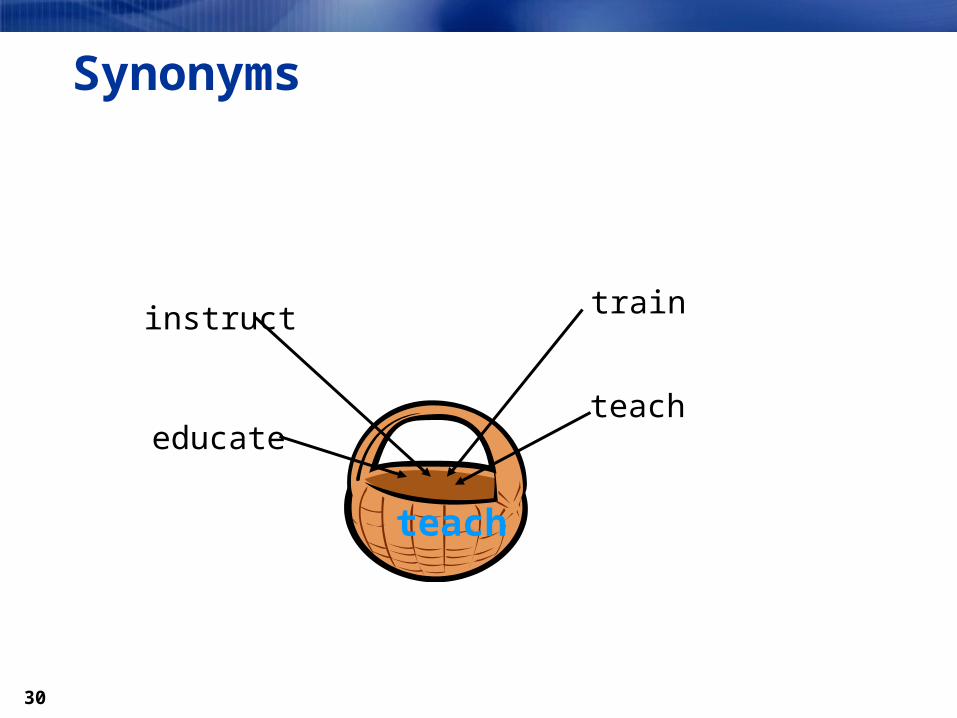
Synonyms may split based on part of speech, for example, teach/train=verb, locomotive/train=noun.

29
Synonyms Language dictionaries Technical jargon Abbreviations Specialty dictionaries
Note: This could be associated with stemming in file preprocessing.
continued...
30
Synonyms
instruct train
educateteach
teach

31
Synonym Lists Default: sashelp.engsynms (ToolsSettings) User Defined
– SAS Data Set– Three fields: TERM ($25.), PARENT ($25.),
CATEGORY ($12.)– Example: TERM=EM, PARENT=Enterprise Miner,
CATEGORY=PRODUCT
continued...

32
Converting Unstructured Text to Structured Data
33
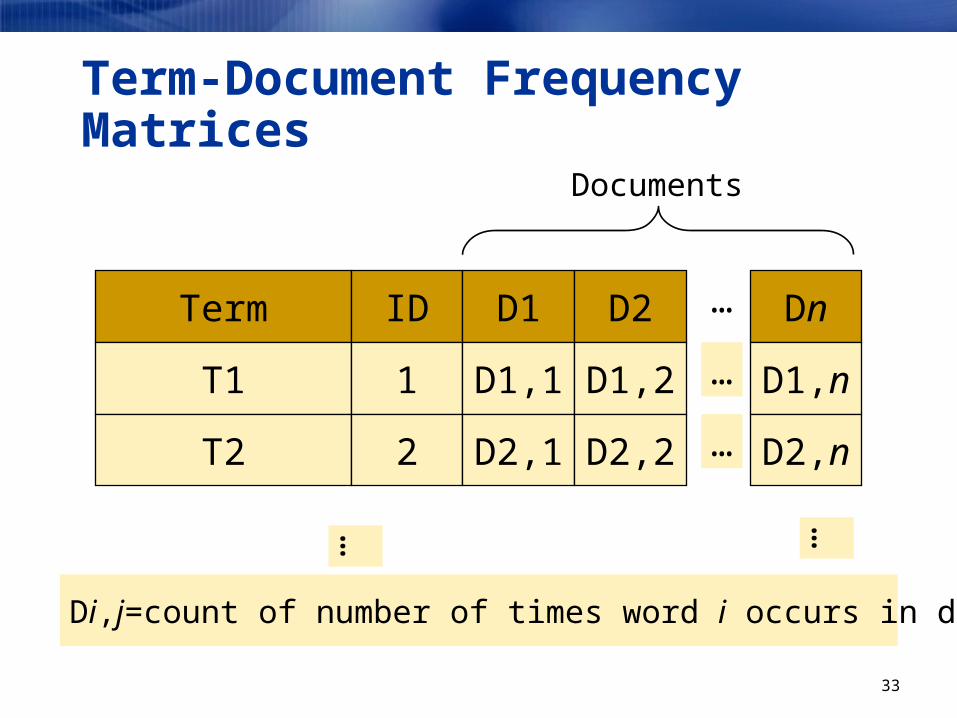
Term-Document Frequency Matrices
Term ID D1 D2 Dn…
T1 1 D1,1 D1,2 D1,n…
T2 2 D2,1 D2,2 D2,n…
… …
Di,j=count of number of times word i occurs in document j
Documents

34
Term-Document Frequency Matrices
Pitfalls Sparse cells (many zeroes) Weak discriminatory power Too large
Solution Term frequency functions Singular value decomposition
35
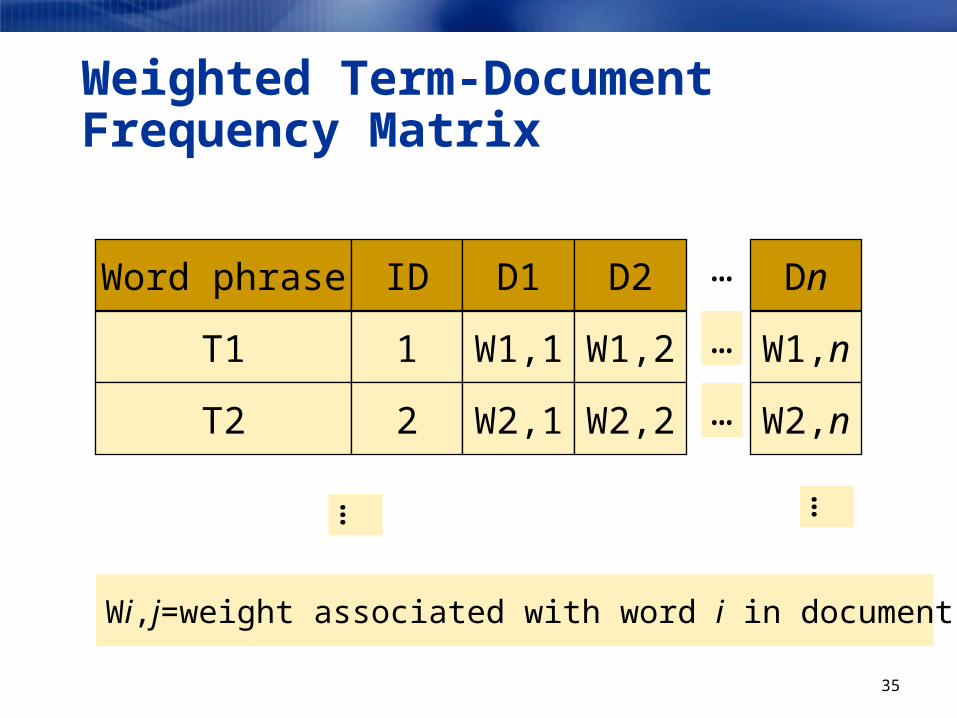
Weighted Term-Document Frequency Matrix
Word phrase ID D1 D2 Dn…
T1 1 W1,1 W1,2 W1,n…
T2 2 W2,1 W2,2 W2,n…
… …
Wi,j=weight associated with word i in document j

36
Frequency and Term Weights Notation
jia ji document in appears that termfrequency ,
collection
documentin appears that termfrequency igi
collection in the documents ofnumber nappears ermin which t documents ofnumber idi
i
jiji ga
p ,,

37
Deriving the Weighted Term-Document Frequency Matrix
ijiij LGa ˆ
frequency expectedˆ ija
weighttermiG
weightfrequency ijL

38
Transformed Term-Document Frequency Matrix Elements
The original frequencies
in the Term-Document Frequency Matrix are transformed to the “expected” frequencies
jia ,
ijiji GLa ,,ˆ

39
Default Weights
j iji
i
ijijj
ijiji ag
g
ap
n
ppG ,,
)(log
)(log1
2
2
)1(log2 ijij aL
Term Weight=Entropy
Frequency Weight=Log

40
Frequency Weights
)1(log2 ijij aLLog
Binary
otherwise 0
document in is termif 1 jiLij
Noneijij aL

41
Singular Value Decomposition
Classical SVD in statistics: A=UV For term-document frequency matrix A, U is the matrix of term
vectors, is a diagonal matrix with singular values along the diagonal, and V is the matrix of document vectors.
The projection V* is output as a set of SVD dimensions for each document, with the dimensions stored in the variables COL1, COL2, and so forth. V* is a sub-matrix of V determined by the maximum dimension specified by the user.
Resolution (low/medium/high) changes the cutoff value for selecting a “significant” number of dimensions.

42
SVD is very useful for
Compression Noise reduction Finding ”concepts” or ”topics” (text mining/LSI) Data exploration and visualizing data (e.g. spatial
data/PCA) Classification (of e.g. handwritten digits)

43
SVD appears under different names
Principal Component Analysis (PCA) Latent Semantic Indexing (LSI)/Latent Semantic
Analysis (LSA) Karhunen-Loeve expansion/Hotelling transform (in
image processing)

Segmenting Textual Data

45
The Text Mining Project
Document analysis is the goal of the project– Exploratory analysis of document collections– Clustering of documents as an aid to human
evaluation of documents

46
Text Mining as Part of a Data Mining Project
Predictive modeling with many fields, one or more of which are unstructured text
Recommender systems Others

Precision vs. Recall
Measure to describe how effective a binary text classifier predicts documents that are relevant to a particular category.
Precision – The percentage of the predicted positive in all positive instances
– Precision = TP / (TP + FN) Recall – How well the classifier can find relevant documents and
properly assign them to their correct category– Recall = TP / (TP + FP)
47

48
Text Mining as Part of a Data Mining Project
The goals of the project influence how text mining is performed.
A single unstructured text field becomes a set of K quantitative inputs.

Memory-Based Reasoning
Memory-based reasoning is a process that identifies similar cases and applies the information that is obtained from these cases to a new record. In Enterprise Miner, the Memory-Based Reasoning node is a modeling tool that uses a k-nearest neighbor algorithm to categorize or predict observations.
The k-nearest neighbor algorithm takes a data set and a probe, where each observation in the data set is composed of a set of variables and the probe has one value for each variable. The distance between an observation and the probe is calculated. The k observations that have the smallest distances to the probe are the k-nearest neighbor to that probe.
49


















