

Creating PostgreSQL-as-a-Service at Scale
45
Creating PostgreSQL-as-a-Service at Scale Care and Feeding of Elephants in a Zoo 2015-09-18
-
Upload
sean-chittenden -
Category
Technology
-
view
791 -
download
0
Transcript of Creating PostgreSQL-as-a-Service at Scale

Creating PostgreSQL-as-a-Service at ScaleCare and Feeding of Elephants in a Zoo
2015-09-18

Background on Cats• Groupon has sold more than 850 million units to date,
including 53 million in Q2 alone1,4.
• Nearly 1 million merchants are connected by our suite of tools to more than 110 million people that have downloaded our mobile apps.
• 90% of merchants agree that Groupon brought in new customers2.
• Groupon helps small businesses — 91% of the businesses Groupon works with have 20 employees or fewer2.
• 81% of customers have referred someone to the business — Groupon customers are “influencers” who spread the word in their peer groups3.
1) Units reflect vouchers and products sold before cancellations and refunds. 2) AbsolutData, Q2 2015 Merchant Business Partnership Survey, June 2015 (conducted by Groupon). 3) ForeSee Groupon Customer Satisfaction Study, June 2015 (commissioned by Groupon) 4) Information on this slide is current as of Q2 2015

SOA Vogue and Acquisitions• Four acquisitions in 2015 and six acquisitions in 2014
• Internally many services and teams

SOA Consequences
SOA is a fancy way of saying lots of apps talk to lots of database instances.

Building Database Systems
• Ogres are like onions: they have layers.

Building Database Systems
• Ogres are like onions: they have layers.
• Databases are like onions: they have layers, too.

Building Database Systems
* No pun intended, I promise.
• Ogres are like onions: they have layers.
• Databases are like onions: they have layers, too.
• Databases do not operate in a vacuum*.

Database Functionality
Typical web stack:
• Browser
• CDN
• Load Balancer
• App Tier
• API Tier
• Database

Where are databases in most web stacks?
Typical stack:
• Browser
• CDN
• Load Balancer
• App Tier
• API Tier
• Database

Where are databases in most web stacks?
Typical stack:
• Browser
• CDN
• Load Balancer
• App Tier
• API Tier
• Database
• Wouldn't it be nice if something was here?

Macro Components of a Database
Typical stack:
• Browser
• CDN
• Load Balancer
• App Tier
• API Tier
• Database
- Query && Query Plans
- CPU
- Locking
- Shared Buffers
- Filesystem Buffers
- Disk IO
- Disk Capacity
- Slave Replication
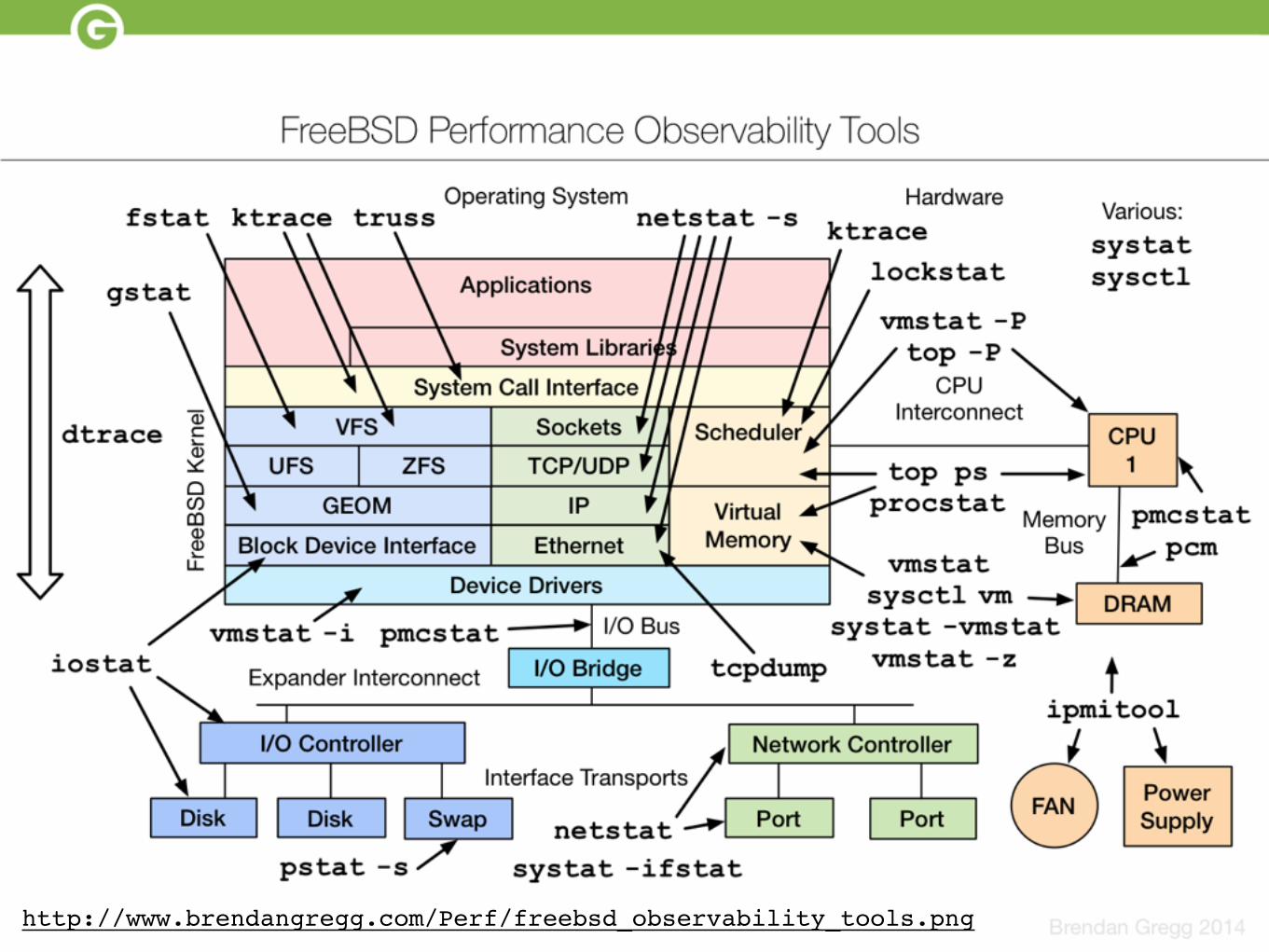
http://www.brendangregg.com/Perf/freebsd_observability_tools.png

Risk ManagementIt's Friday afternoon (a.k.a. let's have some fun):
# postgresql.conf#fsync = onsynchronous_commit = off
Risky?

Risk ManagementIt's Friday afternoon, let's have some fun:
# postgresql.conf#fsync = onsynchronous_commit = off
zfs set sync=disabled tank/foovfs.zfs.txg.timeout: 5
What cost are you willing to accept for 5sec of data?
Discuss.Mandatory Disclaimer: we don't do this everywhere, but we do by default.

• Query Engine
• Serialization Layer
• Caching
• Storage
• Proxy
Real Talk: What are the components of a Database?

• Query Engine - SQL
• Serialization Layer - MVCC
• Caching - shared_buffers
• Storage - pages (checksums to detect block corruption)
• Proxy - FDW
Real Talk: What are the components of a Database?

Database Service Layers

Database Service Layers
PostgreSQL

Database Service Layers
PostgreSQL PostgreSQL

Database Service Layers
L2 VIP, LB, DNS VIP
PostgreSQL PostgreSQL
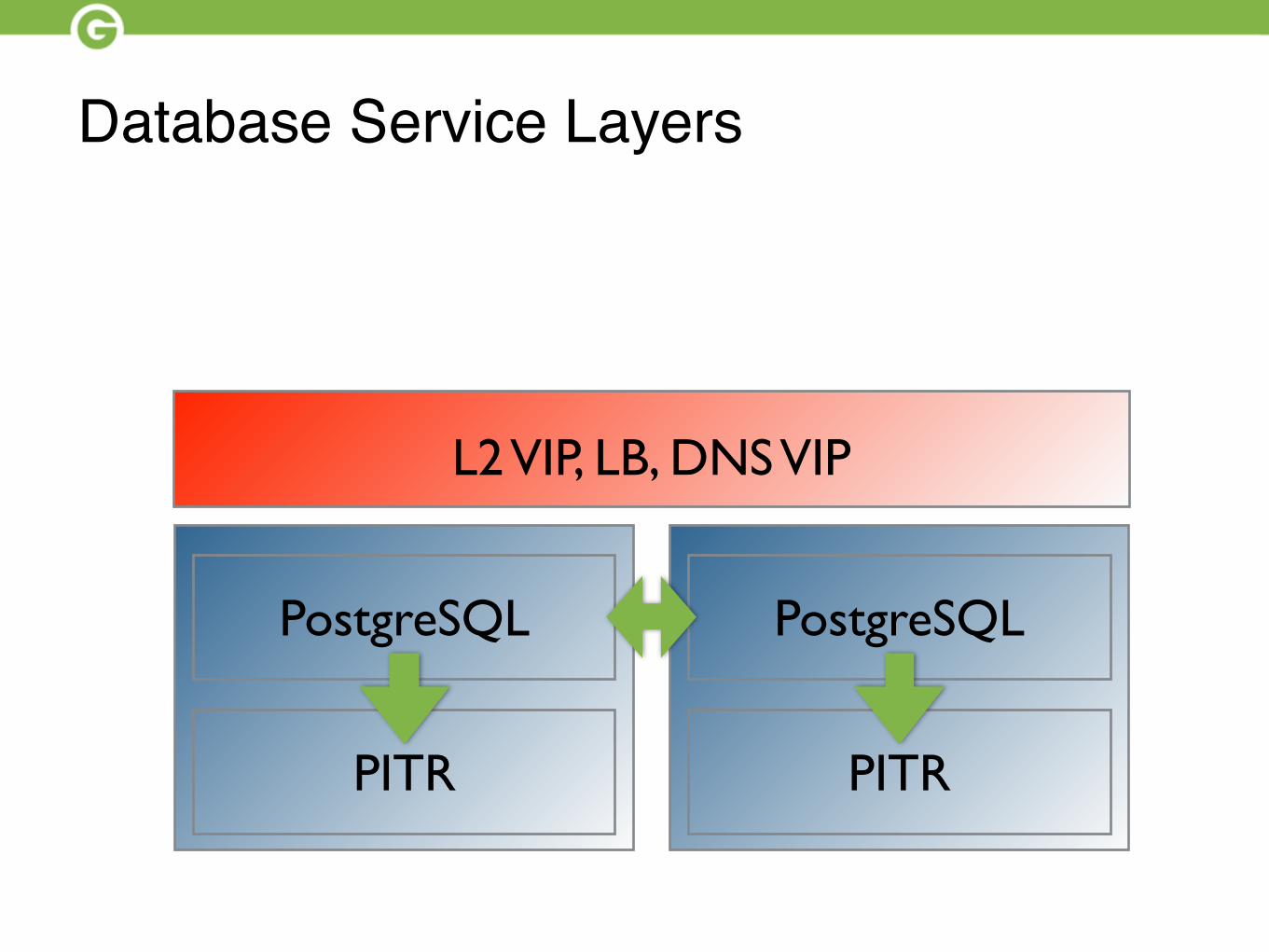
Database Service Layers
L2 VIP, LB, DNS VIP
PostgreSQL PostgreSQL
PITR PITR

Database Service Layers
L2 VIP, LB, DNS VIP
PostgreSQL
pgbouncer
PostgreSQL
pgbouncer
PITR PITR

Database Service Layers
L2 VIP, LB, DNS VIP
PostgreSQL
pgbouncer
PostgreSQL
pgbouncer
PITR PITR
• WAN Replication• Backups
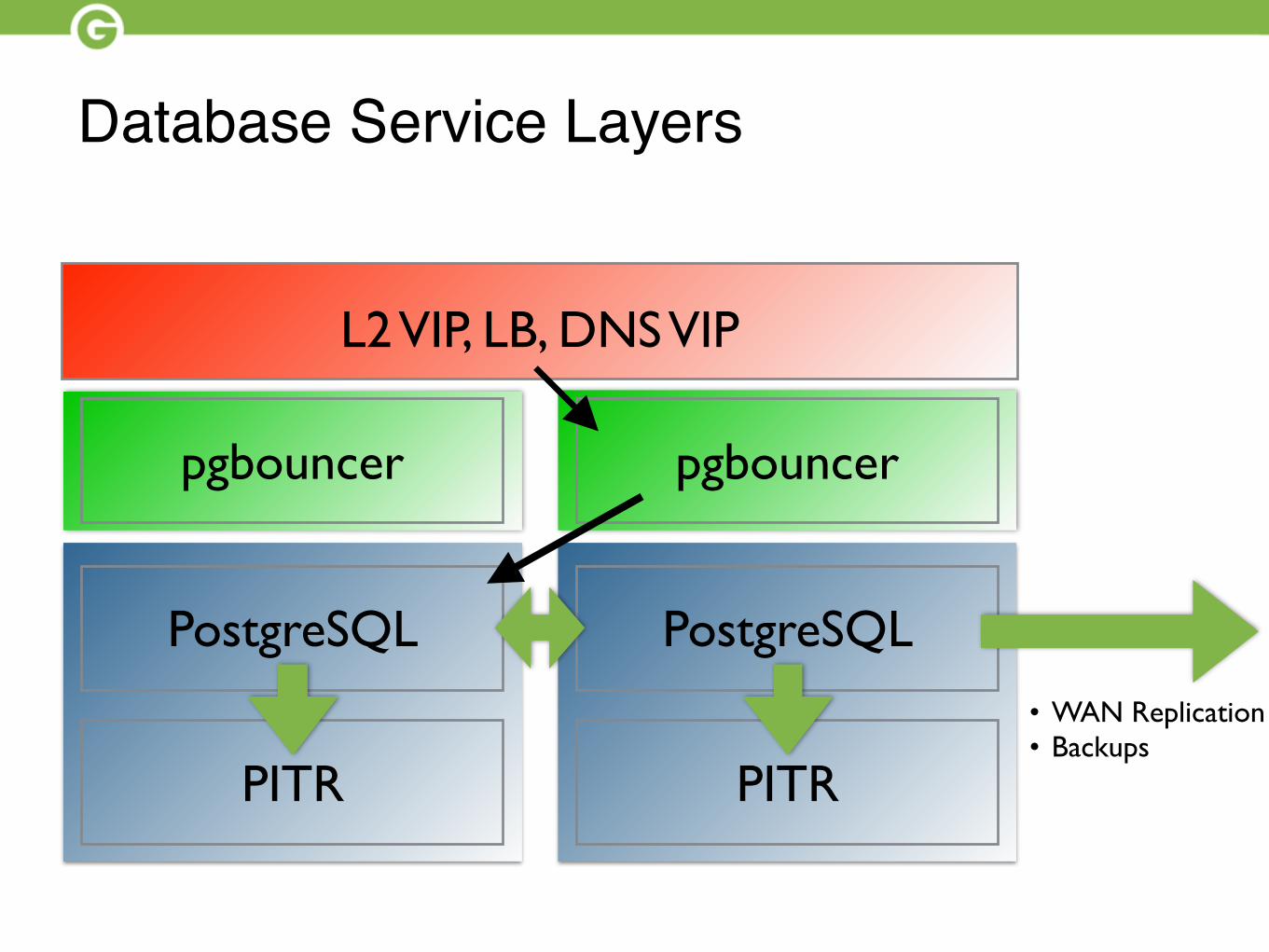
Database Service Layers
L2 VIP, LB, DNS VIP
PostgreSQL PostgreSQL
PITR PITR
pgbouncer pgbouncer
• WAN Replication• Backups

Provisioning
•No fewer than 5x components just to get a basic database service provisioned.
• Times how many combinations?
Plug: giving a talk on automation and provisioning at HashiConf in 2wks

Provisioning Checklist
VIPs (DNS, LB, L2, etc)PostgreSQL instanceSlaves (LAN, OLAP, & WAN)BackupspgbouncerPITRStats Collection and ReportingGraphingAlerting

Provisioning Checklist
VIPs (DNS, LB, L2, etc)PostgreSQL instanceSlaves (LAN, OLAP, & WAN)BackupspgbouncerPITRStats Collection and ReportingGraphingAlerting
*= # VIPs*= initdb + config*= number of slaves*= # backup targets*= # pgbouncers*= # PG instances*= # DBs && Tables*= # relevant graphs*= # Thresholds

Provisioning Checklist
VIPs (DNS, LB, L2, etc)PostgreSQL instanceSlaves (LAN, OLAP, & WAN)BackupspgbouncerPITRStats Collection and ReportingGraphingAlerting
Known per-user limitsInheriting existing applicationsDifferent workloadsDifferent compliance and regulatory requirements

Provisioning
• Automate• Find a solution that provides a coherent view of the world (e.g. ansible)
• Idempotent Execution (regardless of how quickly or slowly)
• Immutable Provisioning• Changes requiring a restart are forbidden by automation: provision new things and fail over.
• Get a DBA to do restart-like activity

Efficacy vs Efficiency
• Cost justify automation and efficiency.• Happens only once every 12mo?
• Do it by hand.• Document it.• Don't spend 3x man months automating some process for the sake of efficiency.
• 100% automation is a good goal, but don't forget about the ROI.

Connection Management: pgbouncer
• Databases support unlimited connections, am i rite?
• More connections == faster
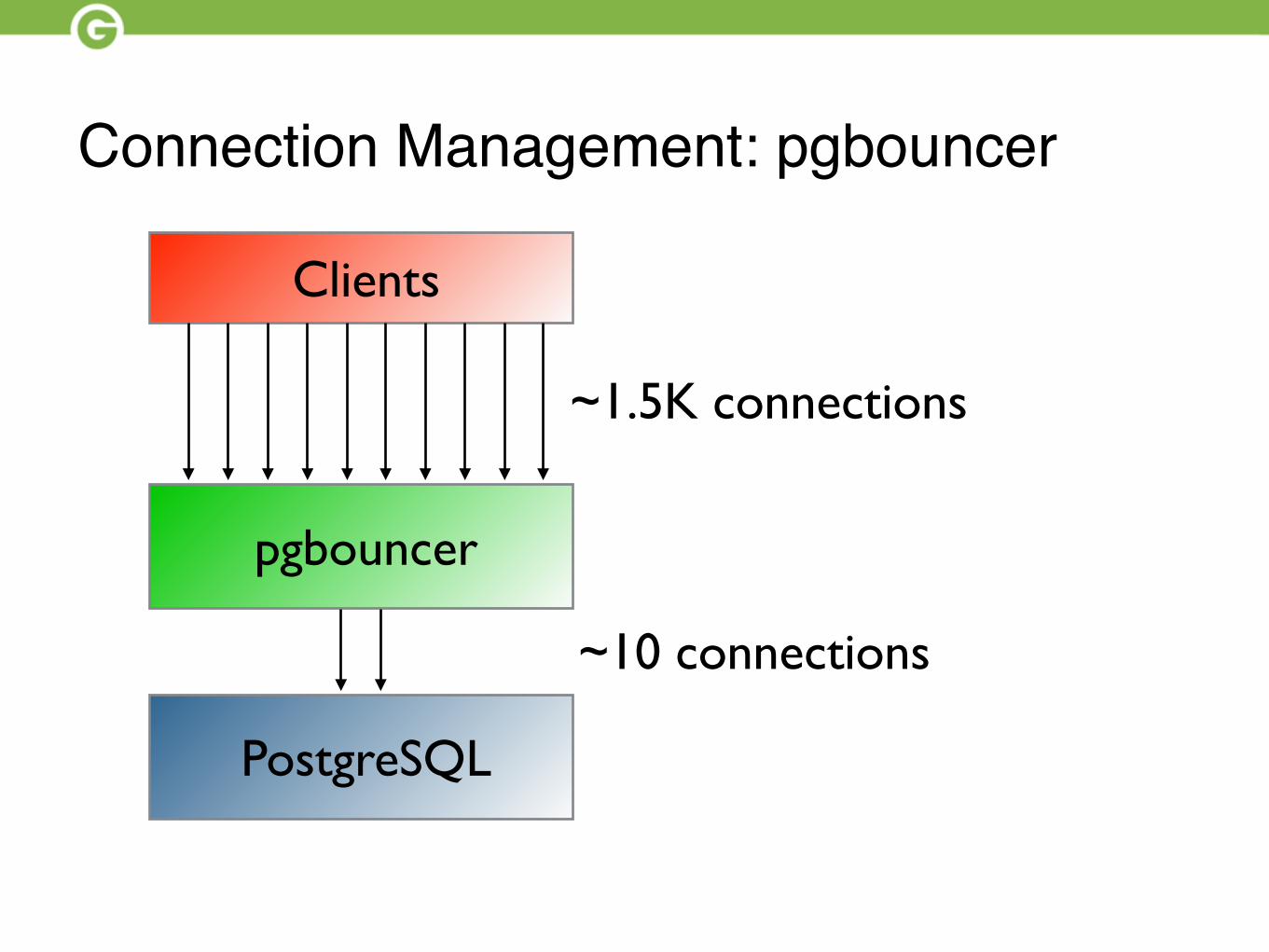
Connection Management: pgbouncer
Clients
pgbouncer
PostgreSQL
~1.5K connections
~10 connections
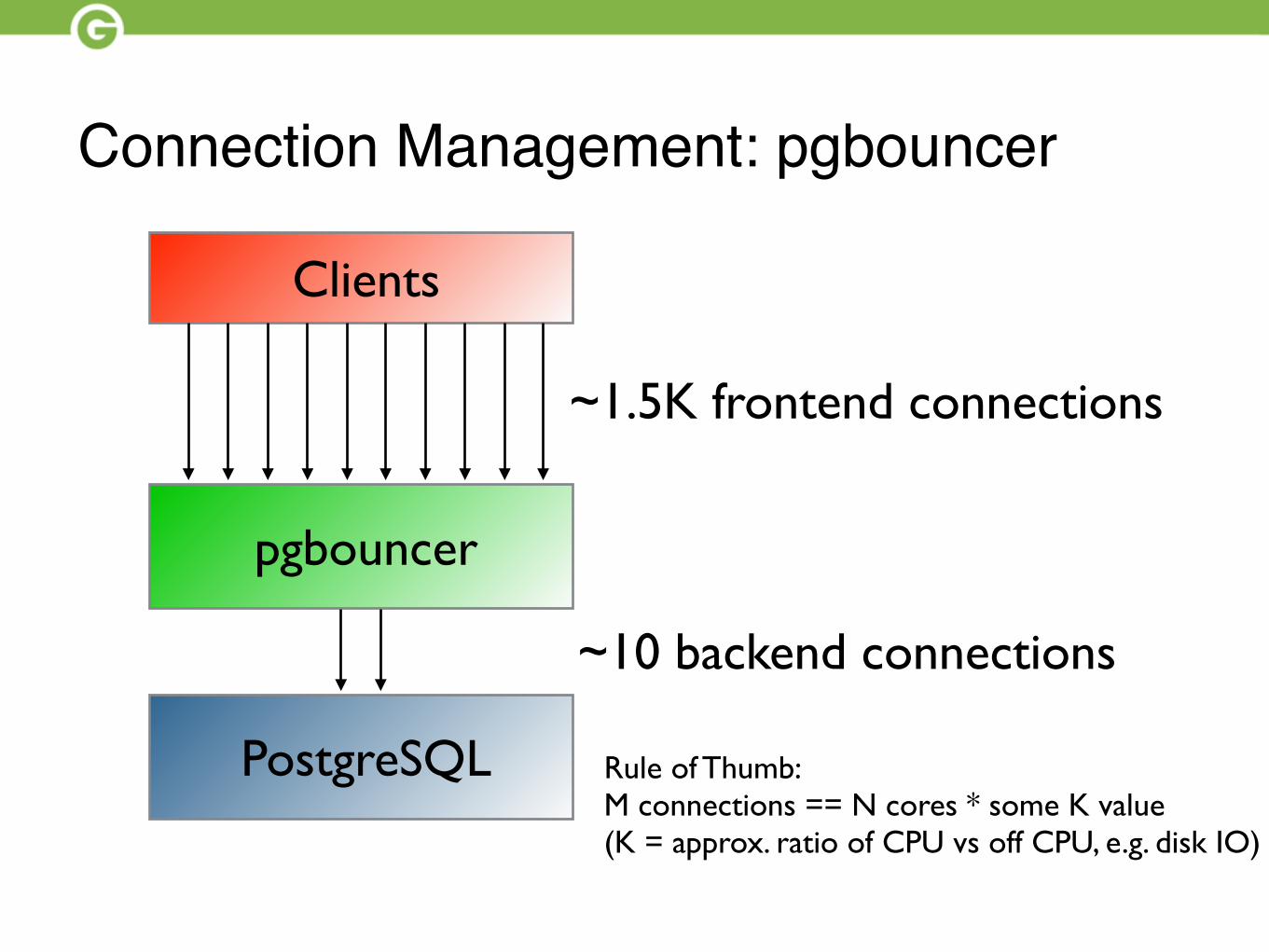
Connection Management: pgbouncer
Clients
pgbouncer
PostgreSQL
~1.5K frontend connections
~10 backend connections
Rule of Thumb:M connections == N cores * some K value(K = approx. ratio of CPU vs off CPU, e.g. disk IO)

pgbouncer: JDBC edition
pgbouncer <1.6: ?prepareThreshold=0 pgbouncer >=1.6: ???

pgbouncer: Starting Advice
•Limit connections per user to backend by number of active cores per user.
•M backend connections = N cores * K•K = approx. ratio of CPU vs queued disk IO

Backups
•Slaves aren't backups•Replication is not a backup•Replication + Snapshots? Debatable, depends on retention, and failure domain.

Backups
•Slaves aren't backups•Replication is not a backup•Replication + Snapshots? Debatable, depends on retention, and failure domain.
-- Dev or DBA "Oops" MomentDROP DATABASE bar; DROP TABLE foo;TRUNCATE foo;

Remote User Controls
•DROP DATABASE or DROP TABLE happen•Automated schema migrations gone wrong•Accidentally pointed dev host at prod database
•Create and own DBs using the superuser account•Give teams ownership over a schema with a "DBA account"
•Give teams one or more "App Accounts"
(??!!??!?! @
#%@#!)

Remote User Controls: pg_hba.conf• DBA account:
•# TYPE DATABASE USER ADDRESS METHOD host foo_prod foo_prod_dba 100.64.1.25/32 md5 host foo_prod foo_prod_dba 100.66.42.89/32 md5
•ALTER ROLE foo_prod_dba CONNECTION LIMIT 2;
• App Account:•# TYPE DATABASE USER ADDRESS METHOD host foo_prod foo_prod_app1 10.23.45.67/32 md5
•ALTER ROLE foo_prod_app1 CONNECTION LIMIT 10;

Incident Response• Develop playbooks • Develop checklists • DTrace scripts
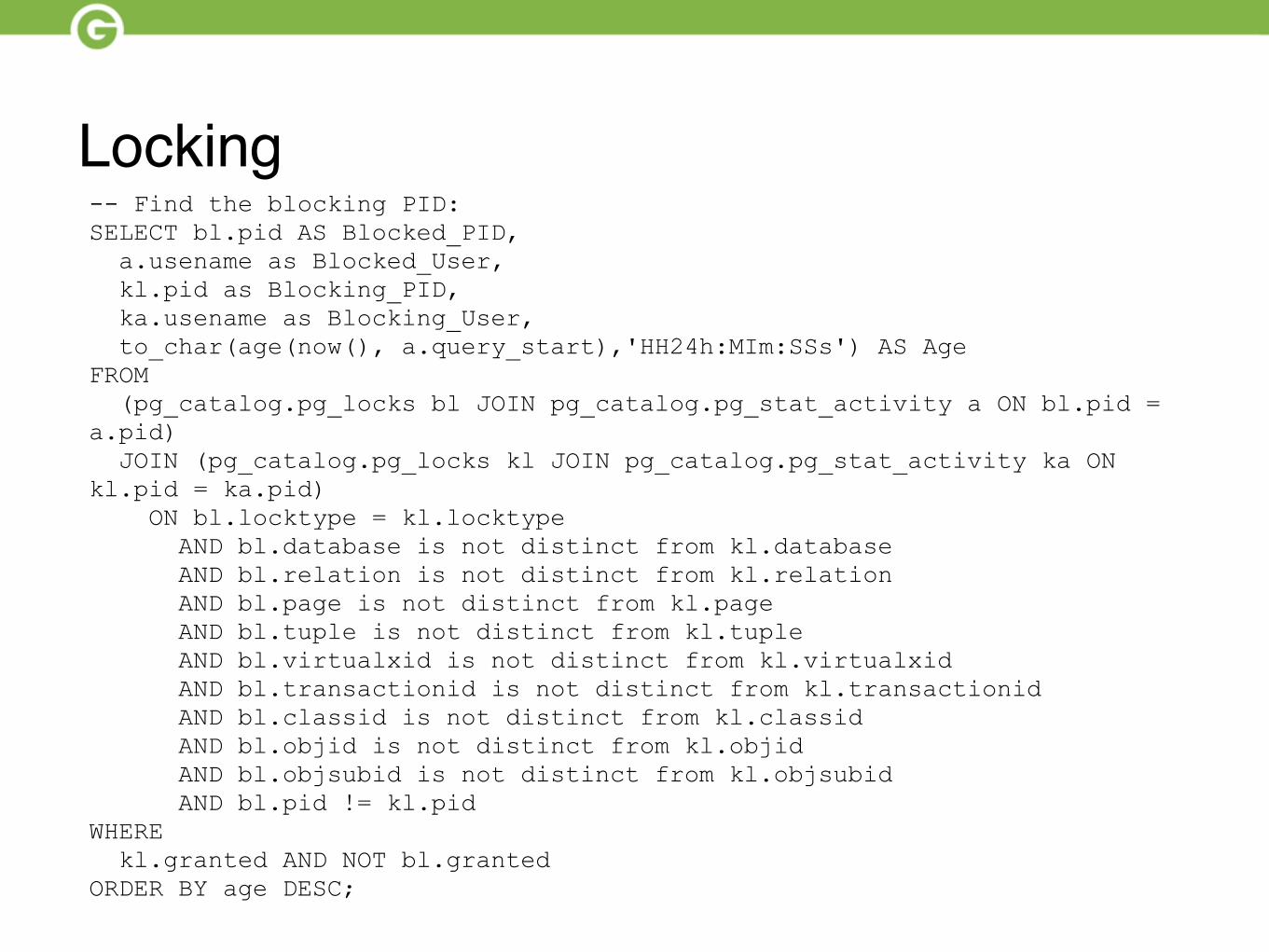
Locking-- Find the blocking PID: SELECT bl.pid AS Blocked_PID, a.usename as Blocked_User, kl.pid as Blocking_PID, ka.usename as Blocking_User, to_char(age(now(), a.query_start),'HH24h:MIm:SSs') AS Age FROM (pg_catalog.pg_locks bl JOIN pg_catalog.pg_stat_activity a ON bl.pid = a.pid) JOIN (pg_catalog.pg_locks kl JOIN pg_catalog.pg_stat_activity ka ON kl.pid = ka.pid) ON bl.locktype = kl.locktype AND bl.database is not distinct from kl.database AND bl.relation is not distinct from kl.relation AND bl.page is not distinct from kl.page AND bl.tuple is not distinct from kl.tuple AND bl.virtualxid is not distinct from kl.virtualxid AND bl.transactionid is not distinct from kl.transactionid AND bl.classid is not distinct from kl.classid AND bl.objid is not distinct from kl.objid AND bl.objsubid is not distinct from kl.objsubid AND bl.pid != kl.pid WHERE kl.granted AND NOT bl.granted ORDER BY age DESC;

Index BloatWITH btree_index_atts AS ( SELECT nspname, relname, reltuples, relpages, indrelid, relam, regexp_split_to_table(indkey::text, ' ')::smallint AS attnum, indexrelid as index_oid FROM pg_index JOIN pg_class ON pg_class.oid=pg_index.indexrelid JOIN pg_namespace ON pg_namespace.oid = pg_class.relnamespace JOIN pg_am ON pg_class.relam = pg_am.oid WHERE pg_am.amname = 'btree' ), index_item_sizes AS ( SELECT i.nspname, i.relname, i.reltuples, i.relpages, i.relam, s.starelid, a.attrelid AS table_oid, index_oid, current_setting('block_size')::numeric AS bs, /* MAXALIGN: 4 on 32bits, 8 on 64bits (and mingw32 ?) */ CASE WHEN version() ~ 'mingw32' OR version() ~ '64-bit' THEN 8 ELSE 4 END AS maxalign, 24 AS pagehdr, /* per tuple header: add index_attribute_bm if some cols are null-able */ CASE WHEN max(coalesce(s.stanullfrac,0)) = 0 THEN 2 ELSE 6 END AS index_tuple_hdr, /* data len: we remove null values save space using it fractionnal part from stats */ sum( (1-coalesce(s.stanullfrac, 0)) * coalesce(s.stawidth, 2048) ) AS nulldatawidth FROM pg_attribute AS a JOIN pg_statistic AS s ON s.starelid=a.attrelid AND s.staattnum = a.attnum JOIN btree_index_atts AS i ON i.indrelid = a.attrelid AND a.attnum = i.attnum WHERE a.attnum > 0 GROUP BY 1, 2, 3, 4, 5, 6, 7, 8, 9 ), index_aligned AS ( SELECT maxalign, bs, nspname, relname AS index_name, reltuples, relpages, relam, table_oid, index_oid, ( 2 + maxalign - CASE /* Add padding to the index tuple header to align on MAXALIGN */ WHEN index_tuple_hdr%maxalign = 0 THEN maxalign ELSE index_tuple_hdr%maxalign END + nulldatawidth + maxalign - CASE /* Add padding to the data to align on MAXALIGN */ WHEN nulldatawidth::integer%maxalign = 0 THEN maxalign ELSE nulldatawidth::integer%maxalign END )::numeric AS nulldatahdrwidth, pagehdr FROM index_item_sizes AS s1 ), otta_calc AS ( SELECT bs, nspname, table_oid, index_oid, index_name, relpages, coalesce( ceil((reltuples*(4+nulldatahdrwidth))/(bs-pagehdr::float)) + CASE WHEN am.amname IN ('hash','btree') THEN 1 ELSE 0 END , 0 -- btree and hash have a metadata reserved block ) AS otta FROM index_aligned AS s2 LEFT JOIN pg_am am ON s2.relam = am.oid ), raw_bloat AS ( SELECT current_database() as dbname, nspname, c.relname AS table_name, index_name, bs*(sub.relpages)::bigint AS totalbytes, CASE WHEN sub.relpages <= otta THEN 0 ELSE bs*(sub.relpages-otta)::bigint END AS wastedbytes, CASE WHEN sub.relpages <= otta THEN 0 ELSE bs*(sub.relpages-otta)::bigint * 100 / (bs*(sub.relpages)::bigint) END AS realbloat, pg_relation_size(sub.table_oid) as table_bytes, stat.idx_scan as index_scans FROM otta_calc AS sub JOIN pg_class AS c ON c.oid=sub.table_oid JOIN pg_stat_user_indexes AS stat ON sub.index_oid = stat.indexrelid ) SELECT dbname as database_name, nspname as schema_name, table_name, index_name, round(realbloat, 1) as bloat_pct, wastedbytes as bloat_bytes, pg_size_pretty(wastedbytes::bigint) as bloat_size, totalbytes as index_bytes, pg_size_pretty(totalbytes::bigint) as index_size, table_bytes, pg_size_pretty(table_bytes) as table_size, index_scans FROM raw_bloat WHERE ( realbloat > 50 and wastedbytes > 50000000 ) ORDER BY wastedbytes DESC;
Go here instead:https://gist.github.com/jberkus/9923948

Duplicate Indexes-- Detect duplicate indexes SELECT ss.tbl::REGCLASS AS table_name, pg_size_pretty(SUM(pg_relation_size(idx))::bigint) AS size, (array_agg(idx))[1] AS idx1, (array_agg(idx))[2] AS idx2, (array_agg(idx))[3] AS idx3, (array_agg(idx))[4] AS idx4FROM ( SELECT indrelid AS tbl, indexrelid::regclass AS idx, (indrelid::text ||E'\n'|| indclass::text ||E'\n'|| indkey::text ||E'\n'|| coalesce(indexprs::text,'')||E'\n' || coalesce(indpred::text,'')) AS KEY FROM pg_index ) AS ssGROUP BY ss.tbl, KEY HAVING count(*) > 1ORDER BY SUM(pg_relation_size(idx)) DESC;

Frequently Used Queries
• Top Queries:• Sorted by average ms per call• CPU hog• number of callers
• Locks blocking queries• Table Bloat• Unused Indexes• Sequences close to max values• Find tables with sequences


















