
Cray XE6 Performance WorkshopCray XE6 Performance Workshop Modern HPC Architectures David Henty...
19
13/11/2012 1 EPCC, University of Edinburgh Cray XE6 Performance Workshop Modern HPC Architectures David Henty [email protected] Modern HPC Architectures 2 Overview • Components • History • Flynn’s Taxonomy – SIMD – MIMD • Classification via Memory – Distributed Memory – Shared Memory – Clusters • Summary 20/11/2012
Transcript of Cray XE6 Performance WorkshopCray XE6 Performance Workshop Modern HPC Architectures David Henty...

13/11/2012
1
EPCC, University of Edinburgh
Cray XE6
Performance
Workshop
Modern HPC Architectures
David Henty
Modern HPC Architectures 2
Overview
• Components
• History
• Flynn’s Taxonomy
– SIMD
– MIMD
• Classification via Memory
– Distributed Memory
– Shared Memory
– Clusters
• Summary
20/11/2012

13/11/2012
2
Modern HPC Architectures 3
Building Blocks of Parallel Machines
• Processors
– to calculate
• Memory
– for temporary storage of data
• Interconnect
– so processors can talk to each other and the outside world
• Storage
– disks and tapes for long term archiving of data
• These are the basic components
– but how do we to put them together ...
20/11/2012
Modern HPC Architectures 4
Processors
• Most are RISC architecture
– Reduced Instruction Set Computer
– simplify instructions to maximise speed
• Calculations performed on values in registers
– separate integer and floating point
– loading and storing from memory must be done explicitly
• a = b + c is not an atomic operation
– involves 2 loads, an addition and a store
20/11/2012

13/11/2012
3
Modern HPC Architectures 5
Clock Speed
• Rate at which instructions are issued
– modern chips are around 2-3 GHz
– integer and floating point calculations done in parallel
– can also have multiple issue, e.g. simultaneous add and multiply
• Whole series of hardware innovations
– pipelining
– out-of-order execution, speculative computation
– ...
• Details become important for top performance
– most features are fairly generic
20/11/2012
Modern HPC Architectures 6
Moore’s Law
• “CPU power doubles every 24 months”
– strictly speaking, applies to transistor density
• Held true for ~35 years
– now maybe self-fulfilling?
• People have predicted its demise many times
– but it hasn’t happened yet
• Increases in power are due to increases in parallelism as
well as in clock rate
– fine grain parallelism (pipelining)
– medium grain parallelism (hardware multithreading)
– coarse grain parallelism (multiple processors on a chip)
• First two seem to be (almost) exhausted: main trend is now
towards multicore
20/11/2012

13/11/2012
4
Modern HPC Architectures 7
Memory
• Memory speed is often the limiting factor for HPC
applications
– keeping the CPU fed with data is the key to performance
• Memory is a substantial contributor to the cost of systems
– typical HPC systems have a few Gbytes of memory per processor
– technically possible to have much more than this, but it is too expensive and power-hungry
• Basic characteristics
– latency: how long you have to wait for data to arrive
– bandwidth: how fast it actually comes in
– ballpark figures: 100’s of nanoseconds and a few Gbytes/s
20/11/2012
Modern HPC Architectures 8
Cache memory
• Memory latencies are very long
– 100s of processor cycles
– fetching data from main memory is 2 orders of magnitude slower than doing arithmetic
• Solution: introduce cache memory
– much faster than main memory
– ...but much smaller than main memory
– keeps copies of recently used data
• Modern systems use a hierarchy of two or three levels of
cache
20/11/2012

13/11/2012
5
Modern HPC Architectures 9
Memory hierarchy
Registers
CPU
L1 Cache
L2 Cache
L3 Cache
Main Memory
Speed (and cost) Capacity ~1 Kb
~100 Kb
~1-10 Mb
~10-50 Mb
~1 Gb
1 cycle
~20 cycles
~300 cycles
~50 cycles
2-3 cycles
20/11/2012
Modern HPC Architectures 10
Serial v Parallel Computers
• Serial computers are easier to program than parallel
computers
• …but there are limits on single processor performance
– physical: speed of light, uncertainty principle
– practical: design, manufacture
• Parallel computers dominate HPC because
– they allow highest performance
– they are more cost effective
• Achieving good performance requires
– high quality algorithms, decomposition and programming
20/11/2012

13/11/2012
6
Modern HPC Architectures 11
Flynn's Taxonomy
• Classification of architectures by instruction stream and data
stream
• SISD: Single Instruction Single Data
– serial machines
• MISD: Multiple Instructions Single Data
– (probably) no real examples
• SIMD: Single Instruction Multiple Data
• MIMD: Multiple Instructions Multiple Data
20/11/2012
Modern HPC Architectures 12
SIMD Architecture
• Single Instruction Multiple Data
• Every processor synchronously executes same instructions
on different data
• Instructions issued by front-end
• Each processor has its own memory where it keeps its data
• Processors can communicate with each other
• Usually thousands of simple processors
• Examples:
– DAP, MasPar, CM200
20/11/2012

13/11/2012
7
Modern HPC Architectures 13
SIMD Architecture
P PM
P PM
P
P PM
P PM
P PM
P
P PM
P PM
P PM
P PM
P PM
P PM
P P P PM
PM
PM
PM
PM
Front-end
Network
Peripherals
20/11/2012
Modern HPC Architectures 14
MIMD Architecture
• Multiple Instructions Multiple Data
• Several independent processors capable of executing
separate programs
• Subdivision by relationship between processors and memory
20/11/2012

13/11/2012
8
Modern HPC Architectures 15
Distributed Memory
• MIMD-DM – each processor has its own local memory
• Processors connected by some interconnect mechanism
• Processors communicate via explicit message passing – effectively sending emails to each other
• Highly scalable architecture – allows Massively Parallel Processing (MPP)
• Examples – Cray XE, IBM BlueGene, workstation/PC clusters (Beowulf)
20/11/2012
Modern HPC Architectures 16
Distributed Memory
P M
P M P M
P M
P M P M
P M
P M
Interconnect
20/11/2012

13/11/2012
9
Modern HPC Architectures 17
Distributed Memory
• Processors behave like distinct workstations
– each runs its own copy of the operating system
– no interaction except via the interconnect
• Pros
– adding processors increases memory bandwidth
– can grow to almost any size
• Cons
– scalability relies on good interconnect
– jobs are placed by user and remain on the same processors
– potential for high system management overhead
20/11/2012
Modern HPC Architectures 18
Shared Memory
• MIMD-SM
– each processor has access to a global memory store
• Communications via write/reads to memory
– caches are automatically kept up-to-date or coherent
• Simple to program (no explicit communications)
• Scaling is difficult because of memory access bottleneck
• Usually modest numbers of processors
20/11/2012

13/11/2012
10
Modern HPC Architectures 19
• Each processor in an SMP has equal access to all parts of memory
– same latency and bandwidth
Symmetric MultiProcessing
• Examples
– IBM servers, Sun HPC Servers, multicore PCs
P P P P P P
Bus
Memory
20/11/2012
Modern HPC Architectures 20
Shared Memory
• Looks like a single machine to the user
– a single operating system covers all the processors
– the OS automatically moves jobs around the CPU cores
• Pros
– simple to use and maintain
– CC-NUMA architectures allow scaling to 100’s of CPUs
• Cons
– potential problems with simultaneous access to memory
– sophisticated hardware required to maintain cache coherency
– scalability ultimately limited by this
20/11/2012
13/11/2012
11
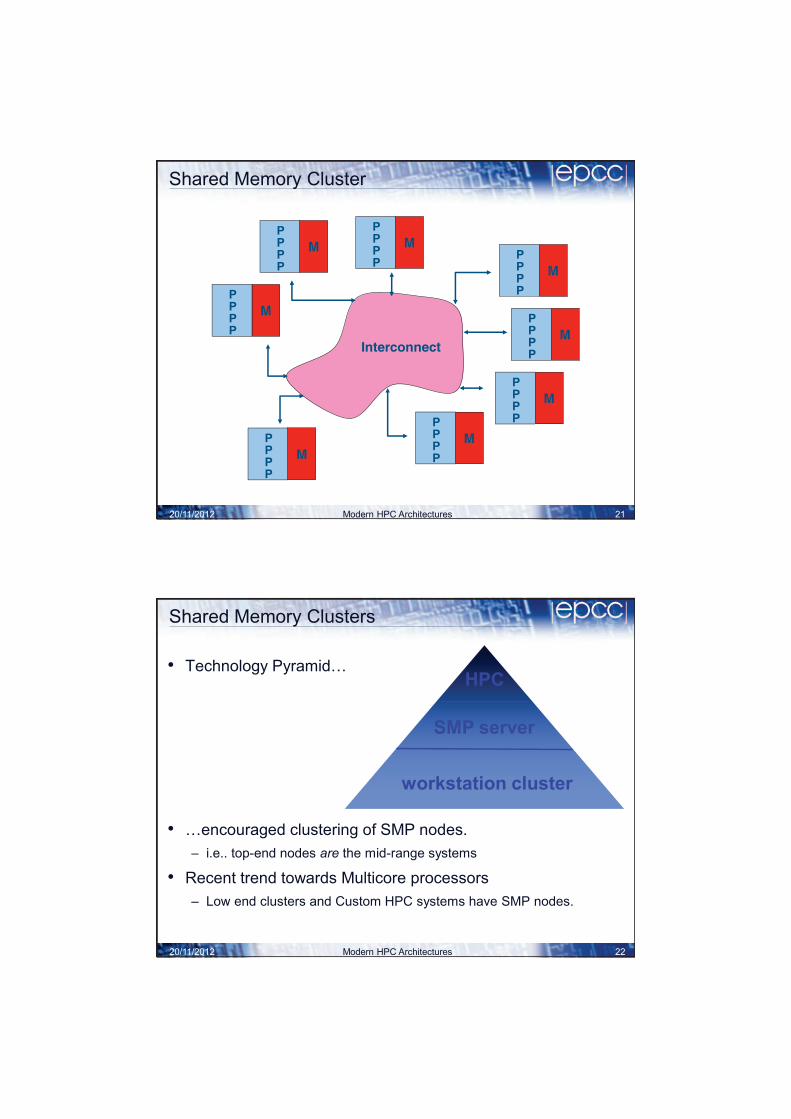
Modern HPC Architectures 21
Shared Memory Cluster
Interconnect
P P
P P
M
P P
P P
M
P P
P P
M
P P
P P
M P P
P P
M
P P
P P
M P P
P P
M
P P
P P
M
20/11/2012
Modern HPC Architectures 22
Shared Memory Clusters
• Technology Pyramid…
• …encouraged clustering of SMP nodes.
– i.e.. top-end nodes are the mid-range systems
• Recent trend towards Multicore processors
– Low end clusters and Custom HPC systems have SMP nodes.
SMP server
workstation cluster
HPC
20/11/2012

13/11/2012
12
Modern HPC Architectures 23
Shared Memory Clusters
• Combine features of two architectures – shared-memory within a node
– distributed memory between nodes
• Pros – constructed as a standard distributed memory machine
– but with more powerful nodes
• Cons – may be hard to take advantage of mixed architecture
– more complicated to understand performance
– combination of interconnect and memory system behaviour
• Examples – clusters of Intel servers, Bull machines, …
– all modern PC clusters
20/11/2012
HECToR: Cray XE6
• Built from 16-core AMD Interlagos CPUs
– each a mini 16-way SMP with internal bus
20/11/2012 Modern HPC Architectures 24

13/11/2012
13
A bespoke Cray interconnect
• essentially a high-end SMP cluster
– network is a 3D torus, not a switch
2 8 GB
main
memory
12.8 GB/sec direct connect memory
(DDR 800)
6.4 GB/sec direct connect HyperTransport
Cray SeaStar2+
Interconnect
20/11/2012 Modern HPC Architectures 25
Modern HPC Architectures 26
HECToR System Specifications cont.
• Cray XE6 parallel processors
• 2816 compute nodes which contain
two AMD 2.3 GHz 16-core Opteron
processors => 90,112 cores
• Theoretical peak of 827 Tflops
• 32 GB main memory per processor,
shared between 32 cores => total
memory of 90 TB
• 10 login nodes
• Gemini interconnect
• 12 IO nodes
26 20/11/2012

13/11/2012
14
Modern HPC Architectures 27
Summary
• Flynn’s taxonomy looks somewhat dated
– SIMD likely to remain a niche market
• Wide variety of memory architectures for MIMD
– need to sub-classify by memory
• Many parallel systems based on commodity microprocessors
or clusters of SMPs
– … providing leverage with commercial products
• Parallel architectures appear to be the present and future of
HPC
20/11/2012
Modern HPC Architectures 28
Message Passing Model
• The message passing model is based on the notion of
processes
– can think of a process as an instance of a running program, together with the program’s data
• In the message passing model, parallelism is achieved by
having many processes co-operate on the same task
• Each process has access only to its own data
• Processes communicate with each other by sending and
receiving messages
20/11/2012

13/11/2012
15
Modern HPC Architectures 29
Process Communication
a=23 Recv(1,b)
Process 1 Process 2
23
23
24
23
Program
Data
Send(2,a) a=b+1
20/11/2012
Modern HPC Architectures 30
Quantifying Performance
• Serial computing concerned with complexity
– how execution time varies with problem size N
– adding two arrays (or vectors) is O(N)
– matrix times vector is O(N2), matrix-matrix is O(N3)
• Look for clever algorithms
– naïve sort is O(N2)
– divide-and-conquer approaches are O(N log (N))
• Parallel computing also concerned with scaling
– how time varies with number of processors P
– different algorithms can have different scaling behaviour
– but always remember that we are interested in minimum time!
20/11/2012

13/11/2012
16
Modern HPC Architectures 31
Performance Measures
• T(N,P) is time for size N on P processors
• Speedup
– typically S(N,P) < P
• Parallel Efficiency
– typically E(N,P) < 1
• Serial Efficiency
– typically E(N) <= 1
20/11/2012
Modern HPC Architectures 32
The Serial Component
• Amdahl’s law
“the performance improvement to be gained by parallelisation is limited by the proportion of the code which is serial”
Gene Amdahl, 1967
20/11/2012

13/11/2012
17
Modern HPC Architectures 33
Amdahl’s law
• Assume a fraction a is completely serial
– time is sum of serial and potentially parallel
• Parallel time
– parallel part 100% efficient
• Parallel speedup
– for a = 0, S = P as expected (ie E = 100%)
– otherwise, speedup limited by 1/ a for any P
– impossible to effectively utilise large parallel machines?
20/11/2012
Modern HPC Architectures 34
Gustafson’s Law
• Need larger problems for larger numbers of CPUs
20/11/2012

13/11/2012
18
Modern HPC Architectures 35
Utilising Large Parallel Machines
• Assume parallel part is O(N), serial part is O(1)
– time
– speedup
• Scale problem size with CPUs, ie set N = P
– speedup
– efficiency
• Maintain constant efficiency (1-a) for large P
20/11/2012
Modern HPC Architectures 36
• Real Speed-up graphs
• Improving load balance / algorithm increases the turn-over to
a higher numbers of processors
– better scaling = ability to utilise larger computers
Scaling
Speed-up vs No of PEs
0
50
100
150
200
250
300
0 50 100 150 200 250 300
No of PEs
Sp
ee
d-u
p
linear
actual
20/11/2012

13/11/2012
19
Modern HPC Architectures 37
Summary
• Useful definitions
– Speed-up
– Efficiency
• Amdahl’s Law – “the performance improvement to be gained
by parallelisation is limited by the proportion of the code
which is serial”
• Gustafson’s Law – to maintain constant efficiency we need to
scale the problem size with the number of CPUs.
20/11/2012


















