
CPSC 668 DISTRIBUTED ALGORITHMS AND SYSTEMS
38
CPSC 668 DISTRIBUTED ALGORITHMS AND SYSTEMS Spring 2014 Prof. Jennifer Welch CSCE 668 Set 6: Mutual Exclusion in Shared Memory 1
-
Upload
cassandra-mckee -
Category
Documents
-
view
25 -
download
0
description
CPSC 668 DISTRIBUTED ALGORITHMS AND SYSTEMS. Spring 2014 Prof. Jennifer Welch. Shared Memory Model. Processors communicate via a set of shared variables, instead of passing messages. Each shared variable has a type , defining a set of operations that can be performed atomically. - PowerPoint PPT Presentation
Transcript of CPSC 668 DISTRIBUTED ALGORITHMS AND SYSTEMS

CPSC 668DISTRIBUTED ALGORITHMS AND SYSTEMS
Spring 2014Prof. Jennifer WelchCSCE 668
Set 6: Mutual Exclusion in Shared Memory 1

Shared Memory Model
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
2
Processors communicate via a set of shared variables, instead of passing messages.
Each shared variable has a type, defining a set of operations that can be performed atomically.
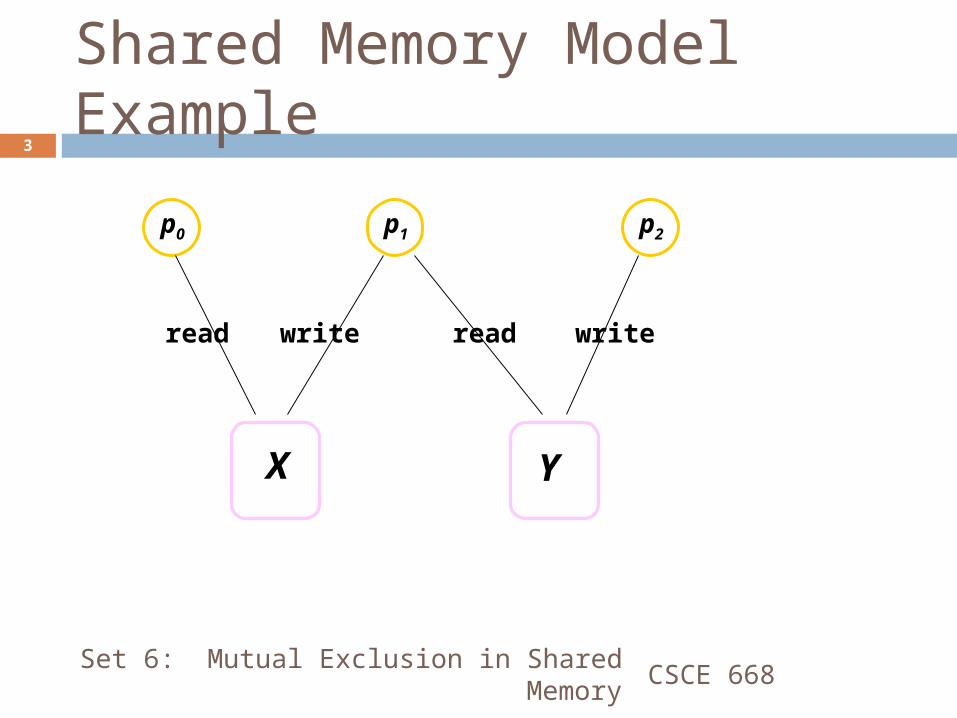
Shared Memory Model Example
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
3
p0 p1 p2
X Y
read write writeread

Shared Memory Model
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
4
Changes to the model from the message-passing case: no inbuf and outbuf state components configuration includes a value for each
shared variable only event type is a computation step by a
processor An execution is admissible if every
processor takes an infinite number of steps

Computation Step in Shared Memory Model
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
5
When processor pi takes a step: pi 's state in old configuration specifies
which shared variable is to be accessed and with which operation
operation is done: shared variable's value in the new configuration changes according to the operation's semantics
pi 's state in new configuration changes according to its old state and the result of the operation

Observations on SM Model
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
6
Accesses to the shared variables are modeled as occurring instantaneously (atomically) during a computation step, one access per step
Definition of admissible execution implies asynchronous no failures

Mutual Exclusion (Mutex) Problem
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
7
Each processor's code is divided into four sections:
entry: synchronize with others to ensure mutually exclusive access to the …
critical: use some resource; when done, enter the…
exit: clean up; when done, enter the… remainder: not interested in using the resource
entry
critical
exit
remainder

Mutual Exclusion Algorithms
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
8
A mutual exclusion algorithm specifies code for entry and exit sections to ensure: mutual exclusion: at most one processor
is in its critical section at any time, and some kind of "liveness" or "progress"
condition. There are three commonly considered ones…

Mutex Progress Conditions
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
9
no deadlock: if a processor is in its entry section at some time, then later some processor is in its critical section
no lockout: if a processor is in its entry section at some time, then later the same processor is in its critical section
bounded waiting: no lockout + while a processor is in its entry section, other processors enter the critical section no more than a certain number of times.
These conditions are increasingly strong.

Mutual Exclusion Algorithms
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
10
The code for the entry and exit sections is allowed to assume that no processor stays in its critical section
forever shared variables used in the entry and exit
sections are not accessed during the critical and remainder sections

Complexity Measure for Mutex
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
11
An important complexity measure for shared memory mutex algorithms is amount of shared space needed.
Space complexity is affected by: how powerful is the type of the shared
variables how strong is the progress property to be
satisfied (no deadlock vs. no lockout vs. bounded waiting)

Mutex Results Using RMW
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
12
When using powerful shared variables of "read-modify-write" type

Mutex Results Using Read/Write
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
13
When using read/write shared variables

Test-and-Set Shared Variable
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
14
A test-and-set variable V holds two values, 0 or 1, and supports two (atomic) operations: test&set(V):
temp := VV := 1return temp
reset(V):V := 0

Mutex Algorithm Using Test&Set
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
15
code for entry section:repeat t := test&set(V)until (t = 0)An alternative syntactic construction is:wait until test&set(V) = 0
code for exit section:reset(V)

Mutual Exclusion is Ensured
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
16
Suppose not. Consider first violation, when some pi enters CS but another pj is already in CS
pj enters CS:sees V = 0,sets V to 1
pi enters CS:sees V = 0,sets V to 1
no node leaves CS so V stays 1
impossible!

No Deadlock
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
17
Claim: V = 0 iff no processor is in CS. Proof is by induction on events in
execution, and relies on fact that mutual exclusion holds.
Suppose there is a time after which a processor p is in its entry section but no processor ever enters CS.
p is in entry but no processor enters CS
p is still in entry, no processor is in CSV always equals 0, next t&s by p returns 0p enters CS, contradiction!

What About No Lockout?
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
18
One processor could always grab V (i.e., win the test&set competition) and starve the others.
No Lockout does not hold. Thus Bounded Waiting does not hold.

Read-Modify-Write Shared Variable
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
19
The state of this kind of variable can be anything and of any size.
Variable V supports the (atomic) operation rmw(V,f ), where f is any functiontemp := VV := f(V)return temp
This variable type is so strong there is no point in having multiple variables (from a theoretical perspective).

Mutex Algorithm Using RMW
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
20
Conceptually, the list of waiting processors is stored in a shared circular queue of length n
Each waiting processor remembers in its local state its location in the queue (instead of keeping this info in the shared variable)
Shared RMW variable V keeps track of active part of the queue with first and last pointers, which are indices into the queue (between 0 and n-1) so V has two components, first and last

Conceptual Data Structure
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
21
The RMW shared object just contains these two"pointers"
1 23
4
5
6
78
91011
12
13
14
15
0first
last

Mutex Algorithm Using RMW
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
22
Code for entry section:// increment last to enqueue selfposition := rmw(V,(V.first,V.last+1))// wait until first equals this valuerepeat queue := rmw(V,V)until (queue.first = position.last)
Code for exit section:// increment first to dequeue selfrmw(V,(V.first+1,V.last))

Correctness Sketch
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
23
Mutual Exclusion: Only the processor at the head of the
queue (V.first) can enter the CS, and only one processor is at the head at any time.
n-Bounded Waiting: FIFO order of enqueueing, and fact that no
processor stays in CS forever, give this result.

Space Complexity
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
24
The shared RMW variable V has two components in its state, first and last.
Both are integers that take on values from 0 to n-1, n different values.
The total number of different states of V thus is n2.
And thus the required size of V in bits is 2*log2 n .

Spinning
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
25
A drawback of the RMW queue algorithm is that processors in entry section repeatedly access the same shared variable called spinning
Having multiple processors spinning on the same shared variable can be very time-inefficient in certain multiprocessor architectures
Alter the queue algorithm so that each waiting processor spins on a different shared variable

RMW Mutex Algorithm With Separate Spinning
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
26
Shared RMW variables:Last : corresponds to last "pointer" from previous algorithm
cycles through 0 to n-1 keeps track of index to be given to
the next processor that starts waiting
initially 0

RMW Mutex Algorithm With Separate Spinning
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
27
Shared RMW variables (continued):Flags[0..n-1] : array of binary variables
these are the variables that processors spin on
make sure no two processors spin on the same variable at the same time
initially Flags[0] = 1 (proc "has lock") and
Flags[i] = 0 (proc "must wait") for i > 0

Overview of Algorithm
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
28
entry section: get next index from Last and store in a
local variable myPlace increment Last (with wrap-around)
spin on Flags[myPlace] until it equals 1 (means proc "has lock" and can enter CS)
set Flags[myPlace] to 0 ("doesn't have lock")
exit section: set Flags[myPlace+1] to 1 (i.e., give the
priority to the next proc) use modular arithmetic to wrap around

Question
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
29
Do the shared variables Last and Flags have to be RMW variables?
Answer: The RMW semantics (atomically reading and updating a variable) are needed for Last, to make sure two processors don't get the same index at overlapping times.

Invariants of the Algorithm
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
30
1. At most one element of Flags has value 1 ("has lock")
2. If no element of Flags has value 1, then some processor is in the CS.
3. If Flags[k] = 1, then exactly (Last - k) mod n processors are in the entry section, spinning on Flags[i], for i = k, (k+1) mod n, …, (Last-1) mod n.

Example of Invariant
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
31
0 0 1 0 0 0 0 0
0 1 2 3 4 5 6 7
Flags
5Last
k = 2 and Last = 5.So 5 - 2 = 3 procs are in entry, spinning on Flags[2], Flags[3], Flags[4]

Correctness
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
32
Those three invariants can be used to prove: Mutual exclusion is satisfied n-Bounded Waiting is satisfied.

Lower Bound on Number of Memory States
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
33
Theorem (4.4): Any mutex algorithm with k-bounded waiting (and no-deadlock) uses at least n states of shared memory.
Proof: Assume in contradiction there is an algorithm using less than n states of shared memory.

Lower Bound on Number of Memory States
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
34
Consider this execution of the algorithm:
There exist i and j such that Ci and Cj have the same state of shared memory.
p0 p0 p0 … p1 p2 pn-1
C C0 C2 Cn-1C1……
p0 inCS byND
p1 inentrysec.
p2 inentrysec.
pn-1 inentrysec.
initialconfig.,all in rem.

Lower Bound on Number of Memory States
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
35
Shared memory state is same in Ci as in Cj
Ci Cjp0 in CS,p1-pi in entry,rest in rem.
p0 in CS,p1-pj in entry,rest in rem.
pi+1, pi+2, …, pj
= sched. in whichp0-pi take steps in round robin
by ND, some ph
has entered CSk+1 times
ph enters CSk+1 times whilepi+1 is in entry

Lower Bound on Number of Memory States
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
36
But why does ph do the same thing when executing the sequence of steps in when starting from Cj as when starting from Ci?
All the processors p0,…,pi do the same thing because: they are in same states in the two configs shared memory state is same in the two configs only differences between Ci and Cj are
(potentially) the states of pi+1,…,pj and those processors don't take any steps in

Discussion of Lower Bound
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
37
The lower bound of n just shown on number of memory states only holds for algorithms that must provide bounded waiting in every execution.
Suppose we weaken the liveness condition to just no-lockout in every execution: then the bound becomes n/2 distinct shared memory states.
And if liveness is weakened to just no-deadlock in every execution, then the bound is just 2.

"Beating" the Lower Bound with Randomization
CSCE 668Set 6: Mutual Exclusion in Shared
Memory
38
An alternative way to weaken the requirement is to give up on requiring liveness in every execution
Consider Probabilistic No-Lockout: every processor has non-zero probability of succeeding each time it is in its entry section.
Now there is an algorithm using O(1) states of shared memory.














