
Computational Methods for Testing Adequacy and Quality of Massive Synthetic Proximity Social...
43
Computational Methods for Testing Adequacy and Quality of Massive Synthetic Proximity Social Networks Huadong Xia, Christopher Barrett, Jiangzhuo Chen, Madhav Marathe IEEE BDSE2013 Network Dynamics and Simulation Science Laboratory Virginia Tech NDSSL TR-13-153
-
Upload
bethanie-elliott -
Category
Documents
-
view
216 -
download
1
Transcript of Computational Methods for Testing Adequacy and Quality of Massive Synthetic Proximity Social...

Computational Methods for Testing Adequacy and Quality of Massive Synthetic Proximity Social Networks
Huadong Xia, Christopher Barrett, Jiangzhuo Chen, Madhav Marathe
IEEE BDSE2013
Network Dynamics and Simulation Science LaboratoryVirginia Tech
NDSSL TR-13-153

We thank our external collaborators and members of the Network Dynamics and Simulation Science Laboratory (NDSSL) for their suggestions and comments.This work has been partially supported by DTRA Grant HDTRA1-11-1-0016, DTRA CNIMS Contract HDTRA1-11-D-0016-0001, NIH MIDAS Grant 2U01GM070694-09, NSF PetaApps Grant OCI-0904844, NSF NetSE Grant CNS-1011769.
Acknowledgement

• Background and Contributions• Methods: Network Synthesis• Comparison of Large Scale Networks• Conclusions
Outline

• Pandemics cause substantial social, economic and health impacts– 1918 flu pandemic, killed 50-100 million people or 3
to 5 percent of world population.– …– SARS 2003, H1N1 2009, Avian flu (H7N9) 2013
• Mathematical and Computational models have played an important role in understanding and controlling epidemics – controlled experiments are not allowed for ethic
consideration.– understand the space-time dynamics of epidemics
Importance of Computational Epidemiological Models

• Heterogeneous• Spatial-Temporal features of populations• Massive, Irregular, Dynamic and Unstructured• Social contact networks are usually synthesized
Networked Epidemiology
(Figure From the Internet)

Volume
Facts in Delhi13.85M Population
2.67M Households
>200M Contacts
2.64M Locations
The Four V’s in Networked Epidemiology
VelocityInteractions Change every second
Node Status changes every second
They are modeled in minute scale
Variety• Demographics• Geographic• Temporal Feature• Virus Infectivity• … …
Veracity• DataDo we collect enough raw data to render a clear picture?
• MethodDo we extract all useful information out of available raw data?
9am
7am
3pm
8pm

• The Veracity of the network one makes depends on: – Time available to make such a network (human, computational)– The data available to make the network– The specific question that one would like to investigate
• Different level of networks may be retrieved for the same region.
• How do we evaluate networks that span large regions?– How to compare two networks constructed for the same
population?– When is the synthesized network adequate?
Social Contact Network Modeling and Analysis

• Propose a number of network measurements to understand and compare urban scale social contact networks which are extremely large, dynamics and unstructured.
• Explore quantitatively the adequacy standards in modeling proximity networks.
Contributions

• Background and Contributions• Methods: Network Synthesis• Comparison of Large Scale Networks• Conclusions
Outline

Synthetic Populations and Their Contact Networks
Goal: Determine who are where
and when.
Process: Create a statistically
accurate baseline population
Assign each individual to a home
Estimate their activities and where these take place
Determine individual’s contacts & locations throughout a day.

Constructing Synthetic Social Contact Networks

• Networks capture social interaction pertinent to the disease• We focus on flu like diseases and the appropriate network is a social
contact network based on proximity relationship.
What Is a Network
Edge attributes:• activity type: shop, work,
school• (start time 1, end time 1)• (start time 2, end time 2)• …
Vertex attributes:• (x,y,z)• land use• …
Locations
Vertex attributes:• age• household size• gender• income• …
People

Two Sets of Data Sources and Generation Methods for Delhi Synthetic Population and Network
Data & Methods the coarse network the detailed network
data
demographics India census 2001India census 2001 + micro-
data (India Human Development Survey - UMD)
geographic data LandScan 2007 MapMyIndia
activity generic activity templatesThane travel survey
residential contact survey
method
people distribution distribution/IPF
locations density Real locations+ home along roads
activity schedules categorized templates
decision tree + templates
configuration model
activity locations gravity model

Residential Contacts: for the Detailed Network Only
OfficeMall
SchoolResidential Area

Population for the coarse network Population for the detailed network
Population Synthesis
M47
F22F4
M71
M17 F22
F11
F46
M23
M33
F2
M53
Split into HHs
F36
F6
M13
M65
M47
F22
F4
M71M17
F22
F11 F46
M23
M13
F2
M53F36
F6
M13
M65
M47
F22
F6
M65
M17F22
F2
F46
M23M1\23
F4 M53
F36 F11M33
M71
Extract individuals
M47
F22
F4
M71M17
F22
F11 F46
M23
M21
F2
M53F36
F6
M13
M65

• Metrics– Entity level: the population, built infrastructure and their layout– Collective level: validate against aggregate statistics.– Network level: structural properties– Epidemic dynamics level: policy effects
How to Compare Two Networks

Individual level age-gender structure
Comparison for Synthetic Populations
Household level demographic structure
Entropy: 1.35 v.s. 1.02

the Coarse Network
Precision of Location Distribution
the Detailed Network
LandScan GridSynthetic Locations Real Locations

Activity Statistics

Note: First Row: the coarse network; Second Row: the detailed network
Temporal Visiting Degree in Random Selected Locations

travel distance distribution radius of gyration distribution
GPL: Temporal and Spatial Properties

GPL: Structural Properties
• The people-location network GPL: the degree of a large portion of nonhome Locations have a power law like distribution.

People-People Network GP

Disease Spread in a Social Network
• Within-host disease model: SEIR
• Between-host disease model:– probabilistic transmissions along edges of social contact
network– from infectious people to susceptible people

Epidemic Simulations to Study the Delhi Population
• Disease model Flu similar to H1N1 in 2009: assume R0=1.35, 1.40, 1.45, 1.60
(only the results when R0=1.35 are shown, but others are similar) SEIR model: heterogeneous incubation and infectious durations 10 random seeds every day
• Interventions Vaccination: implemented at the beginning of epidemic; compliance rate 25% Antiviral: implemented when 1% population are infectious; covers 50% population;
effective for 15 days School closure: implemented when 1% population are infectious; compliance rate
60%; lasts for 21 days Work closure: implemented when 1% population are infectious; compliance rate
50%; lasts for 21 days
• Total five configurations (including base case). Each configuration is simulated for 300 days and 30 replicates

Comparison in Epidemic Simulations
• Impact to Epidemic Dynamics (R0=1.35):– The coarse network exploits generic activity schedules, where people travel much more frequently.
Therefore, the two networks show very different epidemic dynamics in base case.

• Similarities of two networks:– Vaccination is still most effective strategy.– Pharmaceutical interventions is more effective than the non-pharmaceutical.– School closure is more effective than work closure
• Differences of two networks– Severity is significantly different– In delaying outbreak of disease, school closure is more effective than Antiviral in the
coarse network, which is on the contrary in the detailed network.
Epidemic Simulation Results: Interventions

Categories Metrics
Underlying Synthetic Population
Household Structure
Location Layout
Duration of Activities
Number of Daily Activities
Travel Distance
Radius of Gyration
GPL
Temporal Degree of Random Locations
Degree of People-Location Graphs
GPDegree, Clustering Coefficient, Contact Duration, Shortest Path
Epidemic DynamicsNo Interventions
Pharmaceutical InterventionsNon-Pharmaceutical Interventions
Metrics Review

• Novel methodologies in creating a realistic social contact network for a typical urban area in developing countries
• Comparison to a coarser network suggests:– Similarity reflects generic properties for social contact networks– Region specific features are captured in the detailed model– The epidemic dynamics of the region is strongly influenced by activity
pattern and demographic structure of local residents– A higher resolution social contact network helps us make better public
health policy
• A realistic representation of social networks require adequate empirical input. We propose the criteria of adequacy:– Does the new input decrease uncertainty of the system?– Does the new input significantly change epidemics and intervention
policy?
Conclusions

END
Questions?

EXTRA SLIDES
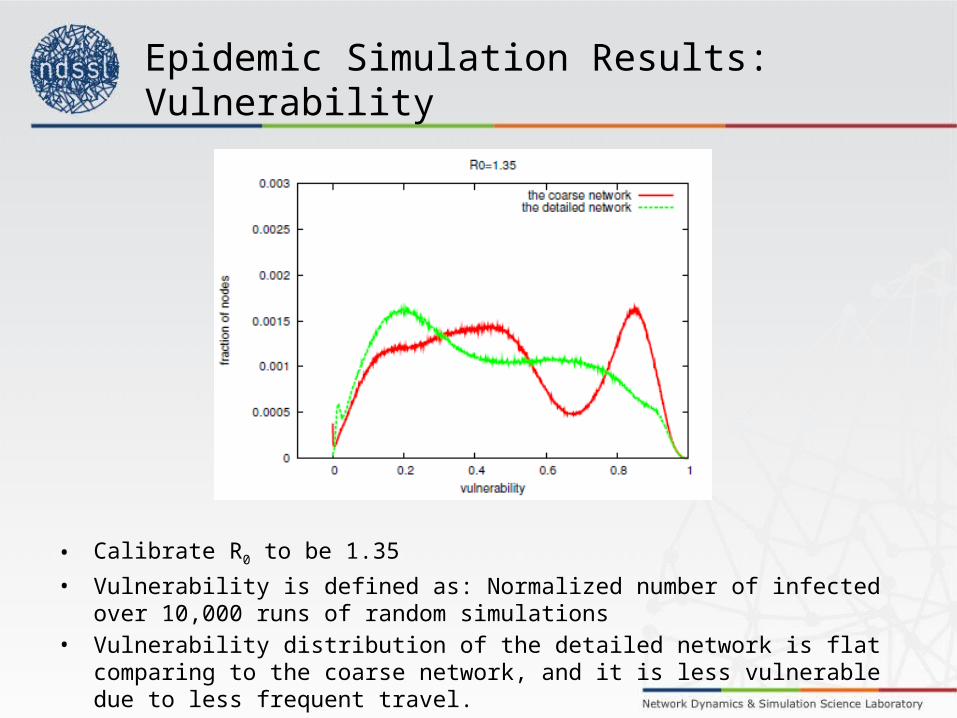
• Calibrate R0 to be 1.35• Vulnerability is defined as: Normalized number of infected over 10,000 runs of random
simulations• Vulnerability distribution of the detailed network is flat comparing to the coarse network,
and it is less vulnerable due to less frequent travel.
Epidemic Simulation Results: Vulnerability

• Calibrate R0 to be 1.35
Epidemic Simulation Results

• Case study:– Delhi (NCT-I): a representative south Asian city that was never studied
before.• Statistics:
– 13.85 million people in 2001; 22 million in 2011– Most populous metropolis: 2nd in India; 4th in the world– 573 square miles, 9 regions (refer to the pic)– The Yamuna river going through urban area.
• Unique socio-cultural characteristics: – Large slum area– Tropical weather– Environmental hygiene
Delhi: National Capital Territory of India

Two Versions of Delhi Networks
• The coarse network:– Based on very limited data– Generic methodology applicable to any region in world
• The detailed network:– Requires household level micro sample data and other detailed data,
not available for all countries
• Improvement on results is expected:– to evaluate the network generation model;– to understand importance of different levels of details.

• Population generationInput: Joint distribution of age and gender of the population in Delhi (from the India
census 2001)
Algorithm:– Normalize the counts in the joint distribution of age and gender into a joint
probability table– Create 13.85 million individuals one by one.
For each individual: Randomly select a cell c with the probability of each cell of the city.Create a person with the age and gender corresponding to the cell c.
End
Output: 13.85 million individuals are created, each individual is associated with disaggregate attributes of gender and age.
V1: Synthetic Population Generation

• Demographic Data: basic census data + India Micro-Sample– India Census 2001– Micro sample for household structure: India Human Development Survey 2005 by the University
of Maryland and the National Council of Applied Economic Research, which tells about each household sample: hh size, hh head’s age, hh income, house types, animal care; and also for each individual in the hh: demographic details, religion, work, marital status, relationship to head, etc.
• Activity Data: Thane travel survey + residential contacts survey– Activity templates from 2001 Household Travel Survey statistics for Thane, India, and
2005-2009 school attendance statistics from the UNESCO Institute of Statistics (UIS)o Activity templates are extracted with CART, and assigned to synthetic population with
decision tree.
– Survey on residential area contacts in India, conducted by NDSSLo Approximate 40% adults in India do not travel to work. The survey focused on them.o Collected people’s age, gender, and contact durations/frequencies near their home.
• Location Data: MapMyIndia data– Ward-wise statistics for population and households.– Coordinates for locations such as schools, shopping centers, hotels etc.– Infrastructures such as roads, railway stations, land use etc.– Boundary for each city, town and ward.
Data Input

• Same methodology as we did for US populations:Input: total # of households
Aggregate distribution of demographic properties from Census: hh size, householder’s age
Household micro-samplesOutput: Synthetic population with household structure. Each individual is assigned an age and gender.Algorithm:
1. Estimate joint distribution of household size and householder’s age: 1) construct a joint table of hh size and householder’s age: fill in # of samples for each cell2) multiply total # of households to distributions to calculate marginal totals for the table3) run IPF to get a convergent joint table4) normalize: divide counts in each cell with (total # of samples), it’s probability for each
cell.(illustrated in next slide)
2. create the synthetic households and population:1) randomly select a cell with the probability in joint table2) select a household sample h from all samples associated with that cell uniformly at
random3) create a synthetic household H, so that H has same members as h, each member in H has
same demographic attributes as those in h.4) repeat step 2.1-2.3, until # of synthetic households is equal to the total # of households
from Census.
V2: synthetic population creation method

IPF example
Row Adjustment Column Adjustment
Iteration 129.62 39.61 30.76 35 40 25
20 8.00 8.00 4.00 20.78 9.45 8.08 3.2530 8.57 10.71 10.71 29.65 10.13 10.82 8.7135 11.25 12.50 11.25 35.06 13.29 12.62 9.1415 1.80 8.40 4.80 14.51 2.13 8.48 3.90
Iteration 234.81 40.09 25.10 35 40 25
20 9.10 7.77 3.13 20.02 9.15 7.76 3.1230 10.25 10.95 8.81 30.00 10.30 10.92 8.7735 13.27 12.60 9.13 35.01 13.34 12.57 9.0915 2.20 8.77 4.03 14.98 2.21 8.75 4.02
Iteration 3: Finished34.99 40.00 25.00 35 40 25
20 9.14 7.75 3.11 20.00 9.14 7.75 3.1130 10.30 10.92 8.78 30.00 10.30 10.92 8.7735 13.34 12.57 9.09 35.00 13.34 12.57 9.0915 2.21 8.76 4.02 15.00 2.21 8.76 4.02
Row Column
20 3530 4035 2515
Start35 40 25
20 6 6 330 8 10 1035 9 10 915 3 14 8

V2: household distribution – a snapshot
• Households are distributed along real streets/community blocks.• V2 avoids to distribute households on rivers, lakes and green land etc. (V1 distribute them
uniformly within each 1(miles)*1(miles) block)

• Activity templates generation
Flowchart: Generating Activity Sequences based on Thane Survey for Delhi-V2
Frequency distribution of
reported activity sequences
Demographics of the Thane sample
population;UIS stat
1) Demographics2) Act template:Activity sequenceActivity duration
Commute categories
Activity sequences
sampling
Data sources:
Outcome:
samplingdecision tree
Frequency distribution of trips:
Trip start time Trip length

• Motivation of the residential contact network: – Approximate 40% adults in India do not travel to work. The network model interaction
among them around their homes (within residential area).
• Survey data collected:– age, gender of staying at home people: node label– contact durations/frequencies of each person near their home: edge label/node
degree
• Formal question: generate a random network s.t.– Given degree distribution of a bunch of nodes– Given label of each node– Assumption: network tend to be homophilous (nodes of the similar labels is connected
with higher probability )
• Method: – Configuration model with the added feature of node homophilous.– Refer to the next slide for details.
Generation of the Residential Network

For each edge-type in (long-dur, mid-dur, short-dur), do:1. Initialize each node with a degree drawn i.i.d. from the degree distribution
according to its label (age/gender)2. Form a list of “stubs” – connections of nodes that haven’t be matched with
neighbors. Call it stubList.3. Pick a starting node v0 randomly.
4. For each of v0’s stubs, choose an element v1 from the stubList as described in following:1) v1 is chosen randomly from the stubList;
2) if v1 is same as v0 or already connected to v0, go to 4.1).3) with a probability p (>0.5), we do
test if v1 is similar to v0,
if not, go to 4.1) and repeat the selection.4) create an edge between v0 and v1, its duration is computed randomly based on the edge-type (long, mid or short duration)
Done.
Random Network Generation: configuration model with the added feature of node homophilous.










![Linux XIA: An Interoperable Meta Network Architecture to ...XIA, a native implementation of XIA [12] in the Linux ker-nel, as a candidate. We first describe Linux XIA in terms of](https://static.fdocuments.us/doc/165x107/5ee11665ad6a402d666c1866/linux-xia-an-interoperable-meta-network-architecture-to-xia-a-native-implementation.jpg)







