
Compressed Suffix Arrays based on Run-Length Encoding Veli Mäkinen Bielefeld University Gonzalo...
34
Compressed Suffix Arrays based on Run- Length Encoding Veli Mäkinen Bielefeld University Gonzalo Navarro University of Chile BWT RL FID
-
date post
20-Dec-2015 -
Category
Documents
-
view
223 -
download
0
Transcript of Compressed Suffix Arrays based on Run-Length Encoding Veli Mäkinen Bielefeld University Gonzalo...

Compressed Suffix Arrays based on Run-Length Encoding
Veli Mäkinen
Bielefeld University
Gonzalo Navarro
University of Chile
BWT RL FID

20.6.2005 Compressed suffix arrays based on run-length encoding
2
Abstract
We introduce a new full-text index that occupies O(Hk|T|) bits and supports counting queries in O(|P|) time.- optimal space / search time on constant alphabet- works on any alphabet size , adding log to the space/time bounds.

20.6.2005 Compressed suffix arrays based on run-length encoding
3
Introduction
We consider exact string matching on static text.
The task is to construct an index for the text such that the occurrences of a given pattern can be found efficiently.
Well known optimal solution exists: build a suffix tree over the text.

20.6.2005 Compressed suffix arrays based on run-length encoding
4
Introduction...
The suffix-tree-based solution takes O(|T| log |T|) bits of space.
Text itself can be represented in O(|T| log ) bits.- or even less space if text is compressible.
In many applications the space usage is the real bottleneck, not the search efficiency.

20.6.2005 Compressed suffix arrays based on run-length encoding
5
Introduction...
During the last 15 years, many practical / theoretical solutions with reduced space complexities have been proposed.
The work can roughly be divided into three categories:(1) Reducing constant factors(2) Concrete optimization(3) Abstract optimization

20.6.2005 Compressed suffix arrays based on run-length encoding
6
Reducing constant factors
Suffix arrays (Manber & Myers 1990) Suffix cactuses (Kärkkäinen 1995) Sparse suffix trees (Kärkkäinen & Ukkonen
1996) Space-efficient suffix trees (Kurtz 1998) Enhanced suffix arrays (Abouelhoda &
Ohlebusch & Kurtz 2002)

20.6.2005 Compressed suffix arrays based on run-length encoding
7
Concrete optimization
“ Minimizing automata” DAWGS (Blumer & Blumer & Haussler &
McConnel & Ehrenfeucht 1983) Compact DAWGS (Crochemore & Vérin
1997) Compact suffix arrays (Mäkinen 2000)

20.6.2005 Compressed suffix arrays based on run-length encoding
8
Abstract optimization
Objective: Use as few space as possible to support the functionality of a given abstract definition of a data structure.
Space is measured in bits and usually given proportional to the entropy of the text.

20.6.2005 Compressed suffix arrays based on run-length encoding
9
Abstract optimization: Example
A full text index for a given text T supports the following operations:- Exists(P): is P a substring of T? - Count(P): how many times P occurs in T?- Report(P): list occurrences of P in T.

20.6.2005 Compressed suffix arrays based on run-length encoding
10
Abstract optimization...
Seminal work by Jacobson 1989: rank-select queries on bit-vectors.
Rank-select-type structures for suffix trees (Munro & Raman & Rao & Clark 1996-)
Lempel-Ziv index (Kärkkäinen & Ukkonen 1996)

20.6.2005 Compressed suffix arrays based on run-length encoding
11
Abstract optimization...
Compressed suffix arrays (Grossi & Vitter 2000, Sadakane 2000, 2002)
FM-index (Ferragina & Manzini 2000) LZ-self-index (Navarro 2002) Space-optimal full-text indexes (Grossi & Gupta &
Vitter 2003, 2004) Alphabet friendly FM-index (Ferragina & Manzini
& Mäkinen & Navarro) See also ISAAC'04, SODA'05,...

20.6.2005 Compressed suffix arrays based on run-length encoding
12
This talk
We show that combining FM-index with compact suffix array gives a practical full-text index with good space / search time tradeoff.
Our structure, Run-Length FM-index, usesO(min(|T|(Hk log +1),|T|log ) bits and supports Count(P) in O(|P|log ) time.

20.6.2005 Compressed suffix arrays based on run-length encoding
13
This talk...
Hk=Hk(T) is the order-k empirical entropy of T, i.e., “the average number of bits needed to encode a symbol using a fixed codebook for each possible combination of k previous symbols”.
There holds 0 Hk Hk-1 ... H0 log

20.6.2005 Compressed suffix arrays based on run-length encoding
14
FM-index
Let us first describe a simple variant of the FM-index that:- occupies O(|T| log bits, and- supports counting queries in O(|P| log ) time.

20.6.2005 Compressed suffix arrays based on run-length encoding
15
Simple FM-index
Construct the Burrows-Wheeler-transformed text bwt(T) [BW94].
From bwt(T) it is possible to construct the suffix array sa(T) of T in linear time.
Instead of constructing the whole sa(T), one can add small data structures besides bwt(T) to simulate a search from sa(T).

20.6.2005 Compressed suffix arrays based on run-length encoding
16
Burrows-Wheeler transformation
Construct a matrix M that contains as rows all rotations of T.
Sort the rows in the lexicographic order. Let L be the last column and F be the first
column. bwt(T)=L associated with the row number of
T in the sorted M.

20.6.2005 Compressed suffix arrays based on run-length encoding
17
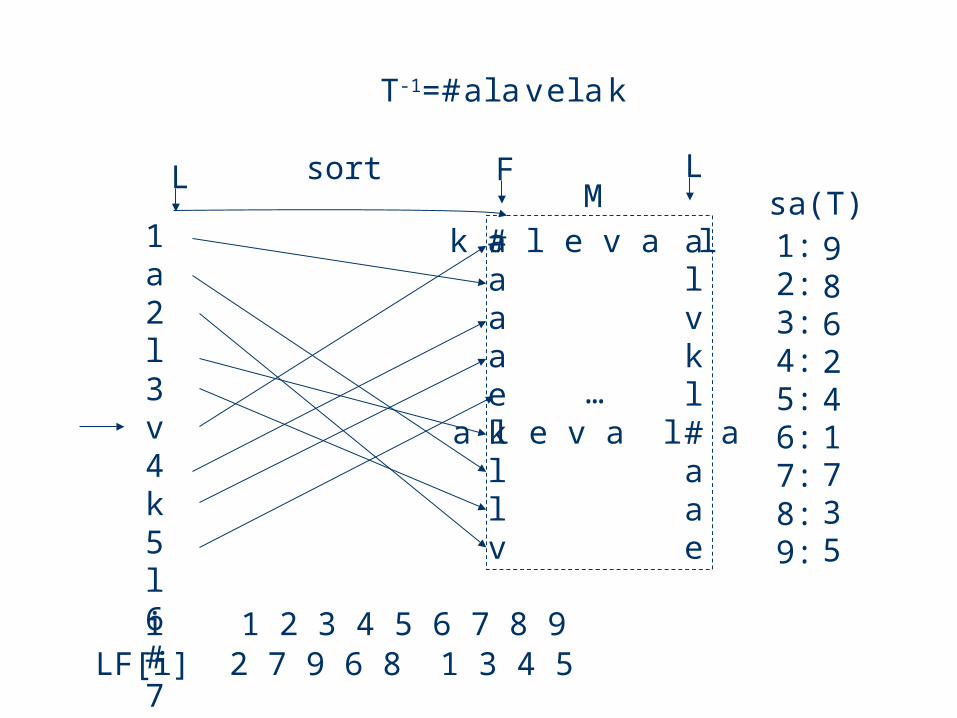
Example
pos 123456789T = kalevala#
1:9 #kalevala2:8 a#kaleval3:6 ala#kalev4:2 alevala#k5:4 evala#kal6:1 kalevala#7:7 la#kaleva8:3 levala#ka9:5 vala#kale
==>
L = alvkl#aae, row 6
Exercise: Given L and the row number, how to compute T and sa(T)?
sa M LF
1 a2 l3 v4 k5 l6 #7 a8 a9 e
#aa a ekl l v
1:2:3:4:5:6:7:8:9:
#
9
a
8
l
7
a
6
v
5
e
4
l
3
a
2
1
k
sortsa(T)
T-1=
L F
…
alvkl#aae
ML
LF[i] 2 7 9 6 8 1 3 4 5i 1 2 3 4 5 6 7 8 9
a l e v a l a
k a l e v a l

20.6.2005 Compressed suffix arrays based on run-length encoding
19
Implicit LF[i]
Ferragina and Manzini (2000) noticed the following connection:
LF[i]=CT[L[i]]+rankL[i](L,i)
Here CT[c] : amount of letters 0,1,...,c-1 in L=bwt(T)rankc(L,i) : amount of letters c in the prefix L[1,i]

20.6.2005 Compressed suffix arrays based on run-length encoding
20
Rank/Select
001001001101
001112223445rank1(L,i)
L
select1(L,j) 3 6 9 10 12
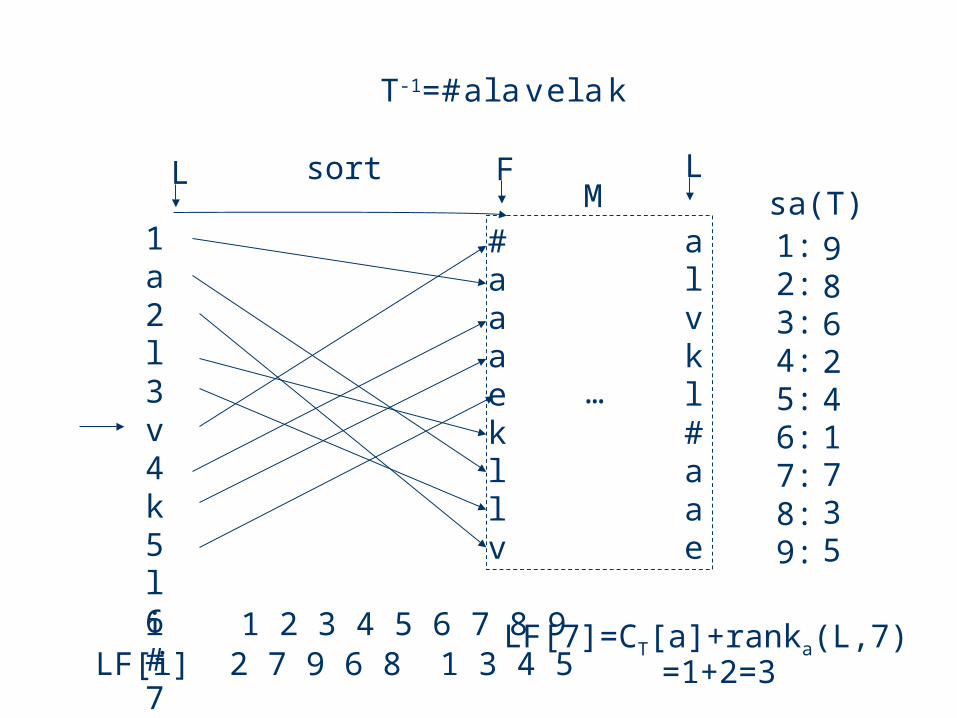
LF[i] 2 7 9 6 8 1 3 4 5i 1 2 3 4 5 6 7 8 9 LF[7]=CT[a]+ranka(L,7)
=1+2=3
1 a2 l3 v4 k5 l6 #7 a8 a9 e
#aa a ekl l v
1:2:3:4:5:6:7:8:9:
#
9
a
8
l
7
a
6
v
5
e
4
l
3
a
2
1
k
sortsa(T)
T-1=
L F
…
alvkl#aae
ML

20.6.2005 Compressed suffix arrays based on run-length encoding
22
Backward search on bwt(T)
Observation: If [i,j] is the range of rows of M that start with string X, then the range [i’,j’] containing cX can be computed as
i’ := CT[c]+rankc(L,i-1)+1, j’ := CT[c]+rankc(L,j).

20.6.2005 Compressed suffix arrays based on run-length encoding
23
M L
…
alvkl#aae
Backward search on bwt(T) …
#ka#al al evkala le va
X=a
i
j
vX=va?
rankv(L,i-1)=0
rankv(L,j)=1
C[’v’]=8
i’ := 8 + 0 + 1
j’ := 8 + 1
i’, j’

20.6.2005 Compressed suffix arrays based on run-length encoding
24
Algorithm Count(P[1,m], L[1,n],CT[1,)(1) c = P[m]; k = m;
(2) i = CT[c]+1; j = CT[c+1];(3) while (i ≤ j and k>1) do begin(4) c = P[k-1]; k = k-1;
(5) i = CT[c]+rankc(L,i-1)+1;
(6) j = CT[c]+rankc(L,j); end;(7) if (j<i) then return 0 else return (j-i+1);
Backward search on bwt(T) …

20.6.2005 Compressed suffix arrays based on run-length encoding
25
Backward search on bwt(T)...
Array CT[1,] takes O( log |T|) bits.
L=Bwt(T) takes O(|T| log ) bits. Assuming rankc(L,i) can be computed in
constant time for each (c,i), the algorithm takes O(|P|) time to count the occurrences of P in T.

20.6.2005 Compressed suffix arrays based on run-length encoding
26
Answering rankc(L,i)
Wavelet tree (GGV 2003) is a data structure replacing L=bwt(T):- supports rankc(L,i) in O(log ) time, and- occupies |T|H0(T) +o(|T|) bits.
Generalized wavelet tree (FMMN 2004) improves query time to constant when =O(polylog(|T|)).

20.6.2005 Compressed suffix arrays based on run-length encoding
27
Simple FM-index...
We obtained a structure that- occupies O(|T|H0(T)bits, supports counting queries in O(|P|log ) time.
Original FM-index takes O(Hk|T|) bits, but only on constant alphabet.
Compression boosting can be applied to improve simple FM-index to take only O(|T|Hk(T)bits (FMMN 2004).

20.6.2005 Compressed suffix arrays based on run-length encoding
28
To partition or not...
All alphabet-friendly solutions obtaining O(|T|Hk(T)space for compressed suffix arrays use optimal partitioning of BWT text, and store explicitly the distribution for each piece.- always (k+1) overhead.
MTF+zeroth order coding take O(|T|Hk(T)(k), but supporting queries on larger alphabets is non-trivial.

20.6.2005 Compressed suffix arrays based on run-length encoding
29
Run-Length FM-index
We make the following changes to the previous FM-index variant:- L=Bwt(T) is replaced by a sequence S[1,n’] and two bit-vectors B[1,|T|] and B’[1,|T|],- Cumulative array CT[1,c] is replaced by CS[1,c],- wavelet tree is build on S, and- some formulas are changed.

20.6.2005 Compressed suffix arrays based on run-length encoding
30
Run-Length FM-index...
cccaaggatt
L
1001010110
B
cagat
S
1011001010
B’
aaacccggtt
F
cccaaggatt
L

20.6.2005 Compressed suffix arrays based on run-length encoding
31
Changes to formulas
Recall that we need to compute CT[c]+rankc(L,i) in the backward search.
Theorem: C[c]+rankc(L,i) is equivalent to select1(B’,CS[c]+1+rankc(S,rank1(B,i)))-1,when L[i] c, and otherwise to select1(B’,CS[c]+rankc(S,rank1(B,i)))+i-select1(B,rank1(B,i)).

20.6.2005 Compressed suffix arrays based on run-length encoding
32
Example, L[i]=c
cccaaggatt
L
aaacccggtt
F LF[8]= select1(B’,CS[a]+ranka(S,rank1(B,8)))+ 8-select1(B,rank1(B,8))
1001010110
B
cagat
S
1011001010
B’
= select1(B’,0+ranka(S,4))+8-select1(B,4)
= select1(B’,0+2)+8-8= 3

20.6.2005 Compressed suffix arrays based on run-length encoding
33
Space requirement
CS[1,] takes O( log |T|) bits.
B and B’ with rank/select dictionaries take 2|T|+o(|T|) bits.
S represented using wavelet tree occupies |S|H0(S)+o(|S|) bits.
In CPM 2004, we have shown that |S| Hk|T| +k.

Comparison
0,01
0,10
1,00
10,00
100,00
1000,00
pattern length
se
co
nd
s
BMH 1.0
LZ 1.49
FM 0.36
CSA256 0.39
CCSA 1.65
CSA32 0.61
RLFM 0.67
SSA 0.87
FM-Nav 1.07
Compact SA 2.73
SA 4.37
5 60


















