
COMPOSING SERVICES INTO STRUCTURED PROCESSES
29
November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final International Journal of Cooperative Information Systems c World Scientific Publishing Company COMPOSING SERVICES INTO STRUCTURED PROCESSES RIK ESHUIS and PAUL GREFEN Eindhoven University of Technology, School of Industrial Engineering P.O. Box 513, 5600 MB Eindhoven, The Netherlands {h.eshuis|p.w.p.j.grefen}@tue.nl Service composition languages like BPEL and many enactment tools only support struc- tured process models, but most service composition approaches only consider unstruc- tured process models. This paper defines an efficient algorithm that composes a set of cooperative services with their dependencies into a structured process. The algorithm takes as input a dependency graph and returns a structured process model that orches- trates the services while respecting their dependencies. The algorithm is embedded in a lightweight, semi-automated service composition approach, in which first dependencies between services are derived in a semi-automated way and next the algorithm is used to construct a structured composition. The approach has been implemented in a prototype that supports the dynamic formation and collaboration of dynamic virtual enterprises using cross-organizational service-oriented technology. Keywords : Service composition; structured processes; collaborative cross-organizational process management 1. Introduction Today, organizations more and more focus on their core competences, relying on competences of other organizations to deliver requested products or services. The resulting cross-organizational collaborations give rise to networked organizations, in which one organization acts as main contractor and the network partners cooperate by delivering products and services to the main contractor. The market dictates that these networks are highly agile and efficient. 1 This typically means that networks are formed ad hoc, depending upon a specific service requested by a customer. One of the most promising technologies to support this way of working is web services, 2,3 which are self-contained functions that are defined in an implementation- independent way, usually by means of WSDL. 4 Their descriptions are published in a publicly accessible repository, which are searched by service consumers to find and invoke specific web services, which are offered by service providers. A main contractor can play the rˆ ole of service consumer. Upon request of a customer, the main contractor then searches the repository for basic services offered by service providers. Next, the main contractor can orchestrate these services into a com- posite service that meets the customer’s request. When the composite service is enacted, the main contractor (service composer) invokes the basic services in the 1
Transcript of COMPOSING SERVICES INTO STRUCTURED PROCESSES

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
International Journal of Cooperative Information Systemsc© World Scientific Publishing Company
COMPOSING SERVICES INTO STRUCTURED PROCESSES
RIK ESHUIS and PAUL GREFEN
Eindhoven University of Technology, School of Industrial EngineeringP.O. Box 513, 5600 MB Eindhoven, The Netherlands
{h.eshuis|p.w.p.j.grefen}@tue.nl
Service composition languages like BPEL and many enactment tools only support struc-tured process models, but most service composition approaches only consider unstruc-tured process models. This paper defines an efficient algorithm that composes a set ofcooperative services with their dependencies into a structured process. The algorithmtakes as input a dependency graph and returns a structured process model that orches-trates the services while respecting their dependencies. The algorithm is embedded in alightweight, semi-automated service composition approach, in which first dependenciesbetween services are derived in a semi-automated way and next the algorithm is used toconstruct a structured composition. The approach has been implemented in a prototypethat supports the dynamic formation and collaboration of dynamic virtual enterprisesusing cross-organizational service-oriented technology.
Keywords: Service composition; structured processes; collaborative cross-organizationalprocess management
1. Introduction
Today, organizations more and more focus on their core competences, relying oncompetences of other organizations to deliver requested products or services. Theresulting cross-organizational collaborations give rise to networked organizations, inwhich one organization acts as main contractor and the network partners cooperateby delivering products and services to the main contractor. The market dictates thatthese networks are highly agile and efficient.1 This typically means that networksare formed ad hoc, depending upon a specific service requested by a customer.
One of the most promising technologies to support this way of working is webservices,2,3 which are self-contained functions that are defined in an implementation-independent way, usually by means of WSDL.4 Their descriptions are published ina publicly accessible repository, which are searched by service consumers to findand invoke specific web services, which are offered by service providers. A maincontractor can play the role of service consumer. Upon request of a customer, themain contractor then searches the repository for basic services offered by serviceproviders. Next, the main contractor can orchestrate these services into a com-posite service that meets the customer’s request. When the composite service isenacted, the main contractor (service composer) invokes the basic services in the
1

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
2 Rik Eshuis and Paul Grefen
order specified in the service orchestration.While BPEL5 has emerged as the standard language for describing service com-
positions, the actual problem of how to orchestrate a set of given services, still re-mains open. Formal approaches6,7,8,9,10,11 focus on automated service compositionand require that the effect of each service is modeled with a pre- and post-condition.This allows the application of techniques from AI planning and program synthe-sis to orchestrate the services into a composite service. However, these approachesburden the service provider with the task of formally specifying its services and an-notating its WSDL specifications with this additional information. Moreover, pre-and post-conditions may be hard to state in real-world business applications.
Other approaches are more pragmatic and derive graph-based compositions ina semi-automated way, by analyzing input/output dependencies between servicesand translating these directly into control flow.12,13 In the resulting graph-basedcompositions, services are coordinated through control elements like AND-forks,AND-joins, XOR-forks, and XOR-joins. Though such approaches do not requireany annotation of the web services, they suffer from another disadvantage: graph-based process models can contain flaws, for example deadlocks. Executing such aflawed composition could result in failures at run-time, which involves considerableexpense to repair. Sometimes such flaws can be detected already at design-time, butsuch checks can be computationally expensive, and next, several design iterationsmay need to be made to find a flawless composition.
This problem with graph-based models disappears if the models are block-structured or structured for shorta, i.e., if the models consist of blocks and eachblock has a unique start and a unique end point.14,15 Blocks can be nested, but arenot allowed to overlap. Models that are not block-structured are similar to programscontaining goto statements. Due to the block-structure, structured models do notcontain any flaws, such as deadlocks. The most important orchestration languages,BPEL5 and OWL-S,16 are structured (BPEL is actually semi-structured: it doesallow cross links, but only between parallel services and parallel blocks). Next, pro-cess enactment tools, which can be used for executing orchestrations, all supportstructured process models.17 Thus, expressing service compositions as structuredprocess models is a reasonable choice.
However, composing a structured process model from a set of services and theirdependencies is not straightforward, since directly translating each dependency di-rectly into control flow may lead to an unstructured composition. For example, adirect mapping from dependencies to control flow may result in a composition inwhich a fork node matches multiple join nodes. This corresponds to a block thathas multiple end nodes, which is not allowed in (block-)structured models. Also,there can be services whose dependencies do not correspond to any structured com-
aStructured process models should not be confused with structured processes, which are processeswhose structure can be specified in any model, including graph-based ones. For example, processessupported by groupware are unstructured.

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 3
position. Consequently, the main problem is to analyze the dependencies in such away that a structured composition can be derived. Section 2 illustrates these issuesin more detail.
This paper defines an algorithm that composes a given set of services with theirdependencies into a structured process model. The services and their dependenciesare specified in a dependency graph, which generalizes a flow graph. The struc-tured process model orchestrates the services respecting their dependencies. Thealgorithm generalizes an existing algorithm for structuring flow graphs18 and runsin almost linear time. Next, the paper defines constraints on dependency graphsunder which the algorithm operates correctly.
The composition algorithm is embedded in a semi-automated two-step approachfor composing services into structured processes. In the first step, dependencygraphs are constructed, while in the second step, a structured process model isconstructed from the dependency graph. While the second step is fully automated,the first step requires user input as argued in Section 3.1. In this paper, depen-dencies are derived from data flow between services, but dependencies can also bedue to events or business logic constraints. We have implemented such a two-stepservice composition approach in a prototype system in the context of the IST Cross-Work project,19 which has developed technology to support the dynamic formationof instant virtual enterprises.20 In this setting, organizations offer their businessprocesses as services to a virtual enterprise. Section 6 gives more details on theCrossWork project and how service composition has been applied there.
Though there is ample related work on service composition (see Section 7),there are but a few service composition approaches that support the constructionof structured process models.6,11 However, these approaches are fully automated, soservices need to be formally specified using pre- and post-conditions, whereas oursemi-automated approach is much more lightweight, since it only requires depen-dencies between services. Moreover, the actual composition algorithms used in theseapproaches have a non-polynomial time complexity, so they are much less efficientthan the almost linear-time algorithm defined in this paper.
In sum, the main contribution of this paper is an efficient algorithm for compos-ing a set of services into a structured process, and a lightweight, semi-automatedservice composition approach in which the algorithm is embedded. The resultingstructured process compositions can be straightforwardly encoded in standard com-position languages like BPEL5 and OWL-S.16 Another contribution is the appli-cation of wellknown techniques from compiler theory18,21 to the field of servicecomposition.
Since the focus of the paper is on the control flow aspects of service composition,we consider here structured process models without explicit data flow. So variablesand parameters of services are not modeled. We do model choice conditions toenforce a proper execution order of the services, but these conditions are set in thecomposition model, not in a service; see Section 3 for more details.
The remainder of this paper is organized as follows. Section 2 introduces the

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
4 Rik Eshuis and Paul Grefen
composition algorithm by showing examples of dependency graphs and the re-sulting structured process compositions. It also shows that not every dependencygraph has a corresponding structured composition. Section 3 defines dependencygraphs and structured process models. Section 4 defines the actual compositionalgorithm, which fully automatically constructs a structured process model froma dependency graph. Next, constraints on dependency graphs are defined underwhich the algorithm operates correctly, i.e. the returned composition correspondsto the dependency graph. Also the correctness and complexity of the algorithm areanalyzed. Section 5 defines a lightweight semi-automated service composition ap-proach in which the algorithm of Section 4 is embedded. Section 6 discusses howthe semi-automated service composition approach has been implemented in a pro-totype system that supports the dynamic formation of instant virtual enterprisesin the CrossWork project.19 Next, a medium-sized case study from CrossWork ispresented, and the approach is evaluated. Section 7 gives an overview of relatedwork. Finally, Section 8 winds up with conclusions and further work.
This paper is partly based on preliminary work reported at BPM 2006.22
2. Overview of composition algorithm
To introduce the salient features of the composition algorithm, we consider a quota-tion process for a production company. In the process, a client asks for a quotationfor an order request. First, the request is checked for completeness and the customeris asked for clarification if needed. Next, the amount of credit of the customer ischecked. If the check is not successful, the quotation is canceled and the client isinformed through the customer service department. Otherwise, a quotation is sentto the customer, consisting of a cost statement plus production and shipment plan.The client can decide either to accept the quotation by paying the cost statement,or to reject the quotation. If the quotation is rejected, the customer service depart-ment is informed, so that they can do some follow-up inquiries with the customer.Finally, the quotation is archived.
Figure 1 shows the dependency graph of this process, which consists of a numberof services and dependencies between them (see Section 3.1 for a formal definitionof dependency graphs). In the figure, a dotted arrow from A to B indicates that B
depends on A. For example, service Receive Request depends on input from Check
Request. This dependency information can, for example, be derived from the sig-natures of the services (see Section 5). If a service has more than one incoming(outgoing) dependency, then either all the predecessor (successor) services are exe-cuted (AND) or only one (XOR). To comply with this constraint, an empty serviceDummy has been inserted immediately after Check Credit. Section 3.1 gives moredetails on this insertion step.
Figure 2 shows the structured composition constructed by the algorithm. Thecomposition is represented as a process tree, in which the leaf nodes are the servicesand the internal nodes represent the blocks. Each block specifies an ordering con-

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 5
Receive Request
Check Credit
Make Production
Plan
InformCustomerService
Get Shipment
Plan
Make Fulfillment Schedule
Cancel Order
AND
AND
XOR
XOR
Check Request
Dummy
XOR
SendQuote
AskForClarification
HandlePayment
HandleRejection
Archive
XOR XOR
XORGet
PriceRates
AND
Fig. 1. Services for quotation process and their dependencies
Receive Request
GetPriceRates
Make Production
Plan
Send Quote
Get Shipment
Plan
Make Fulfillment Schedule
CheckCredit
Check Request
Dummy2
AskForClarification
CancelOrder
HandleRejection
HandlePayment
InformCustomerService
Archive
SEQ
REPEATUNTIL
in(Dummy1)
SEQ
XOR
Dummy1
AND
SEQ
AND
SEQ
XOR
XOR XOR
g1g2
g1=in(Handle Payment)|in(Inform Customer Service)g2=in(Handle Rejection)|in(Cancel Order)
Fig. 2. Structured composition for Figure 1
straint, for example parallelism (AND) or sequence (SEQ). For a sequence node, theordering of its subnodes is from left to right, so for example Receive Request is done

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
6 Rik Eshuis and Paul Grefen
B C D
XOR
A
AND XOR
Fig. 3. Dependency graph not having any corresponding structured composition
before Check Request. Note that each process tree represents a block-structured pro-cess, so unstructured processes cannot be expressed in process trees. A structuredprocess language, in which process trees can be expressed textually, is defined inSection 3.
Compared to Figure 1, two additional dummy services, Dummy1 and Dummy2,have been introduced, which correspond to empty else-branches of an if-statement.They are automatically inserted by the algorithm. Service Dummy is not explicitlyrepresented in the composition; it is implicitly represented by the composite ANDnode containing Make Production Plan, Get Shipment Plan, Get Price Rates and Make
Fulfillment Schedule. The algorithm ignores for the composition empty (dummy) forkservices.
The structured composition can specify executions that are not possible accord-ing to the dependency graph. For example, according to the control flow skeletonin Figure 2, an execution is possible in which Handle Payment is executed before In-
form Customer Service, even though the XOR-join Archive in the dependency graphspecifies that only one these services is done, not both. To rule out such spuriousexecutions, we use guard conditions that state that a service can only be executedif one of its immediate predecessor services, according to the dependency graph,has been executed. For example, in Figure 2 service Inform Customer Service canonly be started if services Handle Rejection or Cancel Order have been executed. Thealgorithm described in Section 4 generates these guard conditions automatically.
Finally, there are dependency graphs that do not have a corresponding struc-tured composition, for example the one in Figure 3. The AND-fork inside the loopin Figure 3 specifies that each iteration of the loop starts a new instance of serviceD. No structured composition supports such a dynamic instantiation of service D.In Section 4.2 we define healthiness constraints on dependency graphs which ruleout dependency graphs like Figure 3. If a dependency graph satisfies the healthinessconstraints, the algorithm returns a corresponding structured composition.
3. Preliminaries
We define dependency graphs and a language for expressing structured processes.The algorithm in the next section takes as input dependency graphs and outputsstructured processes that are expressions in this language.

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 7
3.1. Dependency graphs
First we define and explain dependency graphs. Next, we describe a semi-automatedapproach for constructing dependency graphs.
3.1.1. Definition
Let S be a set of services and D a set of empty dummy services. A dependencygraph is a tuple (N, E, start, end, forkType, joinType) with
• N = S ∪ D are the nodes of the graph,• E ⊆ N × N the set of edges, representing dependencies,• start ∈ N the unique start node such for each node n ∈ N there is a path
from start to n,• end ∈ N the unique final node such that for each node n ∈ N there is a
path from n to end,• forkType : S → {AND, XOR} is a partial function that labels a service
having more than one outgoing dependency with its branching type,• joinType : S → {AND, XOR} is a partial function that labels a service
having more than one incoming dependency with its branching type.
The notion of dependency graph can be seen as an extension of the definition offlow graphs18,21 with parallelism (branching types can have type AND). A minordifference is that nodes in flow graphs model assignments, whereas in dependencygraphs they model services. Liang et al.13 also use dependency graphs in the contextof service composition, but do not consider structured compositions and do notconsider flow graphs.
A node having more than one incoming dependency is called a join whereas anode with more than one outgoing dependency is called a fork . Functions forkType
and joinType assign one type only to incoming resp. outgoing dependencies, whichmight seem restrictive. For example, languages like XPDL23 allow that some in-coming or outgoing arcs have type AND while other have type XOR. Thus, thedependency graph in Figure 4(a) would be valid in XPDL. However, we rule itout since it is ambiguous: it is not specified whether for example B and D can beexecuted both or are exclusive.
This restriction can be overcome by using empty dummy services, which have noimplementation but whose sole purpose is to describe dependencies. For example,Figure 4(b) shows a partial dependency graph (without end node) with the sameservices and dependencies as in Figure 4(a), but now two empty services are in-cluded. Now, the dependency between for example B and D is made precise: eitherB is executed or D but not both. In Figure 1, an empty service Dummy has beeninserted for the same reason.
When defining the algorithm in Section 4, we use a few auxiliary functions ondependency graphs. Given a node n, its set of precondition nodes, written pre(n) arethose nodes on which n depends. Symmetrically, the set of postcondition services

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
8 Rik Eshuis and Paul Grefen
AND
XOR
A
B
C
D
E
AND
XOR
XOR
A
Dummy1
Dummy2
B
C
D
E
(a) (b)
Fig. 4. Invalid partial dependency graph (a) and valid partial dependency graph with same de-pendencies as (b)
of n, written post(n), are those services that depend on n:
pre(n) = { x | (x, y) ∈ E ∧ y = n }post(n) = { y | (x, y) ∈ E ∧ x = n }.
3.2. Structured process language
Usually, structured processes are defined as a syntactic restriction of unstructuredprocesses.14,24 However, we take a different approach and explicitly define a lan-guage for structured processes. So, unstructured processes cannot be expressed inthe language.
Let S be a set of services, ranged over by s, and let D be a set of dummyservices, ranged over by d. The language of structured processes, ranged over by P ,is generated by the following grammar:
P ::= seq | and{seq, seq, .., seq} | xor{grd�seq, grd�seq, .., grd�seq}| repeat seq until grd | atomic
atomic ::= s | d
seq ::= < P, P, .., P >
grd ::= in(atomic) | grd ∨ grd | true
Expression < P, P, .., P > indicates that the elements in the list are executedone by one, according to the order specified in the list, and{seq, seq, .., seq} specifiesthat the elements in the set are executed in parallel, xor{g�seq, g�seq, .., g�seq}specifies that exactly one of the guarded expressions in the set is executed, whilerepeat seq until grd specifies that expression seq is executed until condition grd
holds.For a service x ∈ S ∪ D, guard in(x) is true if x was executed previously. The
predicate abbreviates a test of a local variable vx that is created for each service x.Variable vx is initially false, set to true immediately after x is executed, and set to

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 9
false immediately after the test has been done. To avoid cluttering the compositionswith variable definitions, assignments and tests, we decided to use a special predicatein, rather than introducing variables and tests explicitly.
In the algorithm, we use some additional functions, which are defined on theparse trees of the structured process expressions. Leaf nodes of a parse tree cor-respond to services. An internal node of a parse tree is called a block . Given ablock b, we denote by children(b) the children of b and by parent(b) the uniqueparent block of b. Since we consider a hierarchical structure, each block hasone parent, except the root of the hierarchy which has no parent. For example,children(xor{in(W )�X, in(Y )�Z}) = {in(W )�X, in(Y )�Z}. Next, services(b) de-notes the set of services that are a direct or indirect child of b. For example,services(and{seq[X, Y ], seq[Z]}) = {X, Y, Z}.
Structured process expressions are graphically represented by their parse trees;an example is given in Figure 2. Guards of an XOR block are shown at theedges that connect the XOR block to its children, as illustrated in Figure 2.For example for the structured process in Figure 2, the XOR block in thetop right followed by Archive represents expression <xor{<(in(Handle Payment) ∨in(Inform Customer Service))�<Dummy2>>, <(in(Handle Rejection) ∨in(Cancel Order))�<Inform Customer Service>>}, Archive>.
4. Composition algorithm
In this section, we define an algorithm that takes as input a dependency graphmeeting specific healthiness constraints and outputs a structured composition thatsatisfies the dependencies. First, we explain how block structures can be inferredfrom unstructured dependency graphs. Next, we define healthiness constraints ondependency graphs. If the constraints are satisfied, the algorithm can be appliedcorrectly. We then define two preprocessing steps on dependency graphs. The firstpreprocessing step helps to simplify the algorithm while the second one leads tostructured compositions with more parallelism. Next, we define the actual algo-rithm, which extends in two different ways an existing algorithm by Baker18 forstructuring flow graphs in which each loop has a single entry point. First, we useguard conditions to ensure proper control flow, whereas Baker uses goto statementsfor this purpose. Goto statements are not expressible in structured process lan-guages. Second, dependency graphs allow branching type AND in addition to typeXOR, whereas flow graphs only use type XOR.
4.1. Finding structure in dependency graphs
Since the dependency graph is unstructured, inferring the structure from the de-pendency graph is not straightforward. The approach sketched here is based onBaker.18 The notions introduced are used in the algorithm.
The first problem is to identify the nesting structure for the loops of the struc-tured process to be constructed. To this end, we use the concept of dominator.18,21

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
10 Rik Eshuis and Paul Grefen
Receive Request
GetPriceRates
Make Production
Plan
Send Quote
Get Shipment
Plan
Make Fulfillment Schedule
CheckCredit
Check Request
Dummy
AskForClarification
CancelOrder
HandleRejection
HandlePayment
InformCustomerService
Archive
Fig. 5. Dominator tree for Figure 1
For a dependency graph (N, E, start, end, forkType, joinType), node p dominatesnode q if every path from start to q passes through p. Node p is the immediatedominator of node q if every dominator of q other than p also dominates p. LetDOM(p) denote the immediate dominator of p. DOM(p) is unique for p.21 Fig-ure 5 represents the dominators for Figure 1 in a dominator tree.21 In the tree, eachparent of a child is the immediate dominator of that child.
Next, we identify loops. A back edge is an edge (x, y) ∈ E in the depen-dency graph such that y dominates x,21 so every path from start to x passesthrough y. Intuitively, a back edge closes a loop that is started at y. An edgethat is not a back edge is called a forward edge. Figure 1 has only one back edge:(Ask For Clarification, Check Request), all the other edges are forward edges. For eachback edge (x, y), its natural loop can be computed, which is the set of nodes thatcan reach x without going through y, plus y. Node y is the header of the naturalloop. If two natural loops have different headers, they are either disjoint or one isnested inside the other.21 If two different natural loops have the same header, theycan be merged.21
A node that is target of some back edge is called a loop node. For a non-loopnode n, its head, denoted HEAD(n), is the header of the most nested naturalloop containing n. In the structured composition, n is contained in the repeat

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 11
statement constructed for HEAD(n). For a loop node l, HEAD(l) is the headerof the most nested loop that strictly contains the natural loops headed by l. Ifn is not contained in a loop, node HEAD(n) is undefined. For convenience, ifHEAD(n1) and HEAD(n2) are undefined, then HEAD(n1) = HEAD(n2) by def-inition. For the dependency graph in Figure 1, we have HEAD(Check request) =HEAD(Ask For Clarification) = Receive order. For all other nodes n, HEAD(n) isundefined.
For each node p, DOM and HEAD are used to define the set FOLLOW (p),containing all nodes that are immediately after p at the same level of nesting in thestructured composition.
For a fork node p, so |post(p)| > 1, let
FOLLOW (p) = { q | q is a join ∧ p = DOM(q) ∧ HEAD(p) = HEAD(q) }.For a loop node p, so some back edge enters p, define
FOLLOW (p) = { q | DOM(q) is in a natural loop headed by p }.For each other node p, define
FOLLOW (p) = { q | HEAD(p) = HEAD(q) ∧ p = DOM(q) }.The following properties of FOLLOW are important for the algorithm.18
For every pair of distinct nodes p, q, the sets FOLLOW (p) and FOLLOW (q)are disjoint. Every node is in a FOLLOW set, except the first nodes ateach level of nesting. Conversely, the last node at each level of nestinghas an empty FOLLOW set. For Figure 1, FOLLOW (Receive Request) ={Check Credit}, FOLLOW (Check Credit) = {Inform Customer Service, Archive},FOLLOW (Dummy) = {Make Fulfillment Schedule, Send Quote}; all other nodeshave empty FOLLOW sets. In particular, Archive �∈ FOLLOW (Send Quote), sinceSend Quote does not dominate Archive.
4.2. Constraints
For the algorithm, we require that each dependency graph satisfies the followingconstraints:
C1 Each fork has a subsequent join of the same type.C2 Each loop has a single entry and a single exit point of type XOR.
Constraint C1 may seem restrictive, but still allows a fork that belongs to multiplejoins or a join that belongs to multiple forks, provided the forks and subsequent joinshave the same type. For example, in Figure 1 fork Check Credit has two subsequentjoins of the same type. Thus, Constraint C1 allows unstructured dependency graphslike Figure 1. We now explain and motivate these constraints. In the next section,we will formalize them.

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
12 Rik Eshuis and Paul Grefen
C1. We require that each pair of fork f and subsequent join j have the same type,so if j ∈ FOLLOW (f), then forkType(f) = joinType(j). An XOR-fork that isfollowed by an AND-join would imply a deadlock at the join, whereas an AND-fork followed by an XOR-join would imply multiple execution of the XOR-join.Such behaviors cannot be expressed in structured processes, and therefore suchdependency graphs are ruled out by C1.
C2. We require that each loop has one unique entry point, i.e. the dependencygraph is reducible.21 Formally stated, for each back edge (x, y), y dominates x, so y
is the unique entry point to x. We adopt this constraint to simplify the algorithm.Moreover, using techniques like node splitting,21 irreducible dependency graphs canbe transformed to equivalent reducible ones.
In addition, we require that each loop has a single exit point, so for each loopnode l we have FOLLOW (l) = {x} for some node x, and of all the edges enteringx, at most one leaves a node that has l has head. That node is the exit pointof the loop. The constraint can be relaxed to allow that a loop has multiple exitpoints. However, that would require the introduction of boolean variables (similarto the constructions used in compiler theory to structure flow graphs). Since suchconstructs have been well studied in compiler theory,21 we do not consider themhere. Zhao et al.25 focus explicitly on how loops with multiple entries and exits canbe rewritten into loops with single entries and single exits.
Finally, as explained in Section 2, parallelism is not allowed to cross the borderof loops. Such behavior cannot be expressed in structured processes, and thereforethe resulting constructed structured process would not correspond to the inputdependency graph. We therefore require that the entry point and exit point of aloop have type XOR. For example, Figure 3 violates C2.
4.3. Preprocessing dependency graphs
Before invoking the algorithm on a dependency graph, we preprocess the graph.In the first step, dummy loop and fork nodes are inserted in order to simplify thealgorithm. In the second step, forks hidden inside other forks are eliminated, inorder to increase the parallelism in the constructed compositions. In both steps,dummy services are inserted. Step 1 is obligatory while Step 2 is optional. Step 1is defined for loop nodes by Baker,18 but Step 2 is not, since flow graphs cannotcontain parallelism.
Step 1: Inserting loop and fork nodes. To simplify the algorithm, we requirethat each loop node and each fork node in the dependency graph is a dummy service.To ensure this, we insert before each loop node n ∈ S a fresh dummy service d ∈ D,which represents the repeat statement in the structured composition. The originalloop node n is then the first statement of the repeat statement. Replace each edge(x, n) ∈ E by (x, d) and add dependency (d, n) to E. Similarly, we insert after each

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 13
fork node f ∈ S a fresh dummy service d ∈ D, which represents the XOR or AND
composite node. Replace each edge (f, x) ∈ E by (d, x) and add edge (f, d) to E.For the dependency graph in Figure 1, Step 1 inserts for every fork and every loopnode a dummy service, except for Dummy, since that is already a dummy service.
Step 2: Eliminating implicit forks. In a dependency graph, some joins can haveimplicit forks, i.e. forks that are part (subset) of another fork. For example, in Fig-ure 1 join Make Fulfillment Schedule has an implicit fork inside Dummy. Since Make
Fulfillment Schedule is in FOLLOW (Dummy), Make Fulfillment Schedule will be atthe same level of nesting in the structured composition as Dummy and thereforeafter Get Price Rates. However, it is more natural that Make Fulfillment Schedule isin parallel with Get Price Rates.
To allow suitable nesting and increase the parallelism in the returned structuredcomposition, it is desirable to replace implicit AND-forks by explicit ones. This canbe done by inserting a dummy service that acts as explicit fork. For this preprocess-ing step, we only consider the forward edges of each fork, not its back edges. Foreach AND-join j, take its immediate dominator d, which is an AND-fork by C1. Letsucc(d) be the set of forward successor nodes of d, so for each x ∈ succ(d), (d, x) isa forward edge. Let X ⊆ succ(d) be the set of successor nodes of d that are post-dominated by j. (Node p postdominates node q if every path from q to end passesthrough p, and the immediate postdominator is the postdominator closest to q. Justas a dominator is the unique entry point of a block in a structured composition,the postdominator is the unique exit point of a block.) If X �= post(d) then d hasa successor node that is not postdominated by j. In that case, there is an implicitAND-fork that has an incoming dependency from d and outgoing dependencies tothe nodes in X . To make this fork explicit, create a dummy service e with fork typeAND, replace for each x ∈ X each edge (d, x) ∈ E by (e, x) and add edge (d, e) toE.
4.4. Algorithm
The structured composition algorithm is listed in Figure 6. It requires as inputa set N of nodes, a set E of edges, function forkType and joinType, a partialfunction grd that maps edges to guard expressions, and the node current that isto be processed. The algorithm returns a sequential block that starts with current.For a dependency graph (N, E, start, end, forkType, joinType), the initial call isStructuredComposition(N, E, forkType, joinType, ∅, start).
The algorithm has two main parts. In the first part (l. 2-26), the node current
is processed by creating a sequential block P containing current and all its indirectsuccessors that are not in FOLLOW (current). In the second part (l. 27-34), thenodes in FOLLOW (current) are processed and the resulting block is appended toP . Finally (l. 35), P is returned as the structured composition for current.
We now explain these parts in more detail. For the first part (processing

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
14 Rik Eshuis and Paul Grefen
1: procedure StructuredComposition((N,E, forkType, joinType, grd, current))2: if current is fork node then3: children := ∅4: for n ∈ post(current) do5: if n not in any FOLLOW set then6: Cn := StructuredComposition(N, E, forkType, joinType, grd, n)7: else8: Cn :=< dummycurrent,n >9: end if
10: if forkType(current) = XOR then11: Cn := grd(current, n)�Cn
12: end if13: children := children ∪ {Cn}14: end for15: if forkType(current) = XOR then16: Pcomp := xor children17: else18: Pcomp := and children19: end if20: P :=< Pcomp >21: else if current is loop node with successor node x and FOLLOW node n then22: Px := StructuredComposition(N, E, forkType, joinType, grd, x)23: P :=< repeat Px until in(dummycurrent,n) >24: else25: P :=< current >26: end if27: if FOLLOW (current) �= ∅ then28: if |FOLLOW (current)| > 1 then29: insert unique FOLLOW node after current30: end if31: next := the unique node following current32: Q := StructuredComposition(N, E, forkType, joinType, grd, next)33: P := P�Q34: end if35: return P36: end procedure
Fig. 6. Algorithm for constructing structured compositions
current), there are three cases. If current is a fork node (l. 2), a composite blockPcomp having a set children of child blocks is created. Each successor n of current,so n ∈ post(current), is processed. If n is not in a FOLLOW set (l. 5), algorithmStructuredComposition is recursively called with n as current and returns ablock that contains n (l. 6). If the fork has type XOR (l. 10), the guard for n isadded as a precondition (l. 11); the guard is constructed before in Figure 7. Oth-erwise (l. 7), n is in FOLLOW (x) for some node x. Then a block for n will becreated when the node x is being processed in the algorithm, so when x = current.Therefore, now a block with a dummy service is created (l. 8). To illustrate this, for

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 15
1: f := a fresh node not in N2: N := N ∪ {f}3: Efollows := { (x, y)|(x, y) ∈ E ∧ x ∈ services(P )∧ y ∈ FOLLOW (current) }4: Enew := { (x, f), (f, y)|(x, y) ∈ Efollows }5: E := (E \ Efollows) ∪ Enew
6: forkType = forkType ∪ {f �→ forkType(current)}7: if forkType(current) = XOR then8: grd := grd∪ {(f, y) �→ formulaPreCondition(y)|(x, y) ∈ Efollows}9: end if
Fig. 7. Code for inserting unique FOLLOW node after current (l. 29 of Fig. 6)
Figure 1, if current = Check Request and n = Check Credit, then a dummy nodeis created at l. 8, since Check Credit ∈ FOLLOW (Receive Request). In both cases(l. 5 and l. 7), for n a block Cn is created. This block is added to children (l. 13).Next, a composite block Pcomp is created, whose type depends upon the fork typeof current (l. 15). Block Pcomp is appended to P (l. 20).
If current is a loop node (l. 21), then by constraint C2 there is a unique node n
that follows current, so FOLLOW (current) = {n}. Since current is a loop node,current also has a unique successor node x due to preprocessing step 1. For x,a block Px is created by invoking StructuredComposition with x as current
(l. 22). The last node of block Px is dummy service dummycurrent,n. To see why,note that since each loop has a single exit point (C2), there is a unique predecessorp of n that is part of the loop. Moreover, then node p must be a fork, since p canreach both the start of the loop as well as n. Since n ∈ FOLLOW (current), thealgorithm will create a dummy service dummycurrent,n when fork p is processed ascurrent. The loop can be left if dummycurrent,n is reached, so in(dummycurrent,n) istrue.
If current is not a fork and not a loop node (l. 24), then a sequential block< current > is created (l. 25). Unlike the previous two cases, the successor nodes ofcurrent are now not processed immediately. In the previous two cases, the successornodes of current appear at a more nested level than current in the structuredcomposition, while in this case, the unique successor node of current appears at thesame level of nesting as current. Consequently, since current is not a fork or a loopnode, the unique successor node x of current is in some set FOLLOW (n), wheren is a node. If current is the only predecessor of x, then x ∈ FOLLOW (current),so current = n. Otherwise, x is a join node and n is a fork node. In both cases, x
is processed in l. 27-34 if n = current.In the second part (l. 27-34), the nodes in FOLLOW (current) are processed.
If current has more than one FOLLOW node, then a node is inserted just beforethe nodes in FOLLOW (current) (l. 29). The detailed code for this step is listed inFigure 7 and discussed below. Observe that if current has more than one FOLLOW
node, then current must be a fork, since each non-fork and each loop node havesingleton FOLLOW sets by definition and by constraint C2, respectively. After this

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
16 Rik Eshuis and Paul Grefen
step, current has unique node next that follows current, so FOLLOW (current) ={next} (l. 31). The algorithm is invoked with next as current (l. 32), and thereturned block is appended to P (l. 33).
The code in Figure 7 details how the dummy service is inserted at l. 29. Afresh node f not in N is created (l. 1) and added to N (l. 2). Next, each edge(x, y) such that x ∈ services(P ), so x is in the block created for current, andy ∈ FOLLOW (current), is split in two edges (x, f) and (f, y) (l. 3-5). The forktype of f is the fork type of current (l. 6). If the fork type of f is XOR (l. 7), thena guard condition g is created (l. 8). Since current is a fork node of type XOR
and y ∈ FOLLOW (current), node y is a join and by C1 y has type XOR. Theguard condition ensures that each successor y of f is only enabled if one the relevantpredecessor nodes of y is executed in block P . Next, service p that is predecessorof y according to the input dependency graph, so (p, y) ∈ Efollows, is sometimes afork. In that case, a statement dummyp,y is created at l. 8 of Figure 6, since y is inthe FOLLOW set of current. So not p, but dummyp,y is the predecessor of y in theconstructed block. For a given service y, its guard condition g is therefore definedas formulaPreCondition(y) =
∨p∈pre(y) formula(p) where formula(p) = in(p) if
p is not a fork, and formula(p) = in(dummyp,y) otherwise.To illustrate the code in Figure 7, consider the running example shown in Fig-
ure 1 and let current = Check Credit. Two nodes, Inform Customer Service andArchive are in the FOLLOW set of Check Credit. Then Efollows becomes {(Handle
Rejection,Inform Customer Service),(Cancel Order,Inform Customer Service),(Handle
Payment,Archive)}. A fresh node f is inserted immediately before Inform Customer
Service and Archive. The guard condition created for (f, Inform Customer Service) isin(Handle Rejection)∨ in(Cancel Order) (guard g2 in Figure 2), while the guard con-dition created for (f, Archive) is in(Handle Payment) ∨ in(Inform Customer Service)
(guard g1 in Figure 2).
4.5. Correctness and complexity
As explained in the introduction of this section, for dependency graphs only havingXOR types for forks and joins, the algorithm is similar to the algorithm of Baker,18
which structures reducible flow graphs into structured sequential programs. We havemade two main extensions to Baker’s algorithm. First, we use guard conditions toensure proper control flow, whereas Baker uses goto statements for this purpose.Second, dependency graphs allows branching type AND in addition to type XOR,whereas flow graphs only use type XOR. We argue now for the correctness of theextensions made.
First, the guard conditions are needed when a node x has multiple FOLLOW
nodes. To represent the choice, a XOR branching point is inserted at l. 29 of Figure 6immediately before the FOLLOW nodes of x. Only a bounded number of branchingpoints is inserted, since the FOLLOW sets induce an acyclic order on the nodesof the dependency graph, that is, two different nodes cannot indirectly follow each

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 17
other. Thus, the composition procedure terminates. Furthermore, guard conditionsare only needed after an XOR block is completed, in order to ensure that the rightnext service s is enabled. The guard conditions created at l. 8 in Figure 7 ensurethat s is only reached if its relevant predecessor services have been executed, asargued in the previous subsection.
Second, regarding the correctness of using branching type AND, observe thatthe algorithm ignores information from function joinType to construct blocks. Thisignorance is allowed under constraint C1 and C2. Constraint C1 ensures that if ajoin j has type AND, then each preceding fork f , so j ∈ FOLLOW (f), has typeAND as well. Constraint C2 ensures that if j is in a loop, then f is in the sameloop as well. This ensures that parallelism does not cross the boundary of a repeator an XOR node, and can be expressed in a structured process.
Regarding complexity, though the algorithm is recursive, we now argue that eachnode in the dependency graph is processed at most once as current by examiningthe three lines in which the algorithm is invoked recursively. Consequently, thealgorithm runs in time linear in the size of the dependency graph. For l. 6, supposethere are two different forks f1, f2 such that n ∈ post(f1) ∩ post(f2). Then n is bydefinition a join node. But each join node is in a FOLLOW set, which contradictsthe test in l. 5. Thus, at l. 6, node n is only a successor of current, so the algorithmis invoked for n only once. For l. 22, each loop node has a single successor node bypreprocessing step 1. So the algorithm is invoked for x only once. For l. 32, sincethe FOLLOW sets induce an acyclic order on the nodes, the algorithm is invokedfor next only once. Thus, each node in the dependency graph is processed at mostonce as current in the algorithm.
Next, the algorithm uses FOLLOW sets. To compute these, dominators andloop headers need to be computed. Dominators can be computed in almost lineartime using Lengauer and Tarjan’s algorithm.26 Loop headers can also be computedin almost linear time using an algorithm due to Tarjan.27,28 Both computationsare done sequentially: first dominators are computed, next loop headers. Thus, theFOLLOW sets can be computed in almost linear time. Therefore, the completealgorithm, including the computation of the FOLLOW sets, runs in almost lineartime.
5. Service composition approach
We embed the algorithm in a lightweight service composition approach. Input to theapproach is a set of services. Output is a structured composition that orchestratesthe services. The approach consists of three steps:
S1 Analyzing dependencies between the input services. The result is anabstract dependency graph with empty fork and join types. This step canbe fully automated, as explained below.
S2 Adding branching types to the abstract dependency graph constructedin the previous step. Output is concrete dependency graph with non-empty

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
18 Rik Eshuis and Paul Grefen
fork and join types. This step needs user input, as explained below.S3 Executing the structured composition algorithm. Input is the con-
crete dependency graph constructed in the previous step, and output isa structured composition. This step is fully automated, since it is imple-mented by the algorithm shown in Figure 6.
We next explain these steps in more detail.
Analyzing dependencies. Dependencies can be due to data flow, events, busi-ness logic, etc. We now describe a semi-automated approach for detecting dataflow dependencies between services. Services communicate with each other throughmessages. Each service has an input or an output message or both. Each messageconsists of a set of typed data items. In line with existing work on ontology-basedmatching of data types in the context of services,29,30 we consider business typeshere, not low-level data types. For example, a message could comprise a data itemof type order and a data item of type customer. Business types can be derived fromlow level types actually used in web services in a semi-automated way, using inputfrom either ontological tools31 or from a domain expert that annotates services.32
Based on the input/output data types of each service, we can define depen-dencies between services. If a service a outputs a data item with a certain typeand service b needs as input a data item with the same type, then b depends ona. More advanced notions of matching outputs to inputs, for example those basedon ontological concepts,29,30 can be easily used instead. If multiple messages referto the same stateful data item, additional dependencies based on the states needto be defined, but we do not consider that here. This way, the dependencies of adependency graph can be derived completely automatically from the signature ofthe services.
Labeling branching types. The previous step results in a dependency graphwithout branching types, i.e. fork and join types are not specified. In this step,these branching types are specified by a user (a domain expert) either manually orsemi-automatically. Labeling cannot be done fully automatically since for exampledata dependencies are usually not sufficient to decide on the type of a dependency.For example, consider two services that both have as input an order for some goods.If both services deal with shipping, they would be exclusive and type XOR would beused. If one service deals with picking up the requested goods from the warehouseand another with calculating the total fee to be paid, both services are requiredand type AND would be useful. For similar reasons, domain knowledge of a useris needed to resolve violations of the healthiness constraints that are defined inSection 4.2.
Executing structured composition algorithm. This step is implemented bythe algorithm described in Section 4.4. The input dependency graph is output of

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 19
the previous step. If the dependency graph satisfies the healthiness constraints ofSection 4.2, the algorithm operates correctly. However, the algorithm also returnsa composition if the healthiness constraints are violated, but then the compositionis not guaranteed to be compliant with the dependency graph, as explained inSection 2.
In the next section, we discuss how this approach has been used in the CrossWorkproject. In Section 7, we compare the approach to other related service compositionapproaches. There, we show that our approach is much more lightweight than exist-ing ones, since our approach does not require that services have formal descriptions.
6. CrossWork
We explain how the lightweight service composition approach of the previous sectionhas been applied and implemented in the context of the IST CrossWork project.19,20
First we explain the CrossWork prototype system and its architecture. Next, wediscuss a medium-sized case study from the project, which is based on a real-lifebusiness scenario.
6.1. Architecture
The goal of CrossWork was to support the dynamic formation of Instant VirtualEnterprises (IVEs) within a Network of Automotive Excellence (NoAE). These net-works consist of automotive suppliers that are potential collaborators. Upon requestof an Original Equipment Manufacturer (OEM), which produces cars or trucks, anIVE is formed to deliver a requested product or component. Members of the IVE
GoalDecomp.
GoalDecomp.
TeamFormat.
TeamFormat.
WFPrototyp.
WFPrototyp.
WFCompos.
WFCompos.
WFVerificat.
WFVerificat.
Monitor.UI
Monitor.UI
Format.UI
Format.UI
Infra
Prod.
Market
Pattern
WFUI
WFUI
GlobalEnactm.
GlobalEnactm.
LegacyIntegrat.
LegacyIntegrat.
LocalEnactm.
LocalEnactm.
Fig. 8. CrossWork architecture

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
20 Rik Eshuis and Paul Grefen
are selected from the NoAE. Examples of a product requested by the OEM are theinterior of a car or a watertank for a truck. The OEM incorporates the IVE productin its own product. Suppliers need to collaborate with each other since an individualsupplier typically does not have the capability to handle a product request of anOEM all by itself.
The IVE is formed dynamically, depending upon the specific product requestreceived by one specific supplier (the main contractor). The two main steps in thedynamic formation of an IVE is finding the partner suppliers that can deliver partsof the requested product (team formation) and constructing a global IVE work-flow that coordinates and integrates the local workflows of the individual suppliers(workflow formation).
To support this way of working, a prototype system has been developed, thearchitecture of which is shown in Figure 8. The goal decomposition module receivesan order specification from an OEM and decomposes it into a required set of com-ponents and services, using a product knowledge base. Next, the team formationmodule finds for each identified component and service a partner using a marketand infrastructure knowledge base.33 The market knowledge base stores per orga-nization the services and components it delivers and which activities it offers, whilethe infrastructure knowledge base stores information about the legacy systems oforganizations. The team formation module composes the retrieved partners intoa team that can cooperate according to the market and infrastructure knowledgebase.
Next, the workflow composition module queries the team members for their localworkflow models (not shown) and composes these into a global process model usingthe algorithm of Section 4. Each local workflow model is abstracted into a blackbox service. The constructed global workflow model can be verified and validated.Finally, the global workflow model can be enacted. The global workflow coordinatesthe local workflows of the team partners. The process language used to modelprocesses is a structured process language based on XRL.34 For the enactment,this language is mapped to BPEL.5 Finally, the monitoring UI allows the maincontractor to view internal progress of the global workflow. This module uses processviews offered by local workflows.
The algorithm as implemented in the workflow composition module assumesthat each fork has a unique FOLLOW node. Thus, no guard conditions are createdor used in the constructed structured composition. If this assumption is lifted, theoutput BPEL process use boolean variables to encode the in predicates, as explainedin Section 3.2.
The workflow module is realized in Java. To compute dominators, we use thesimple almost linear time algorithm by Lengauer and Tarjan,26 while we use an al-most linear time algorithm by Tarjan27,28 to compute loop headers. To facilitate in-tegration with the agent-based Team Formation module, the workflow compositionmodule is implemented on top of JADE, a platform for multi-agent-based systems.To interface with the BPEL Global Enactment Module, which is based on Ac-

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 21
prepare Order
produce Watertank body
produce Pump
produce Motor
produce Grommet
assemble Motorpump
produce Cap
assembleWatertank
buy Motorpump
Fig. 9. Abstract dependency graph
tiveBPEL, we implemented an XSLT-based translation that maps the constructedstructured XRL process to a BPEL process. More details on the implementationcan be found elsewhere.20
6.2. Watertank case study
We illustrate the CrossWork composition approach with a medium case study fromCrossWork. An OEM requests a watertank from one member of a cluster of auto-motive suppliers. We assume the member has selected the partners. Figure 9 showsthe abstract dependency graph obtained by analyzing the dependencies betweenthe black-box workflows of each partner. Thus, the internal structure of each localworkflow is hidden inside a service, but a partner supplier can offer an external pro-cess view to the entire network through some additional interfaces.35,20 In reality,the dependency graph is much larger, since a watertank contains over twenty differ-ent components, to but to ease the presentation, we only show the most importantones.
The abstract dependency graph in Figure 9 violates the second constraint ondependency graphs, since there is, among others, an edge connecting prepare Order
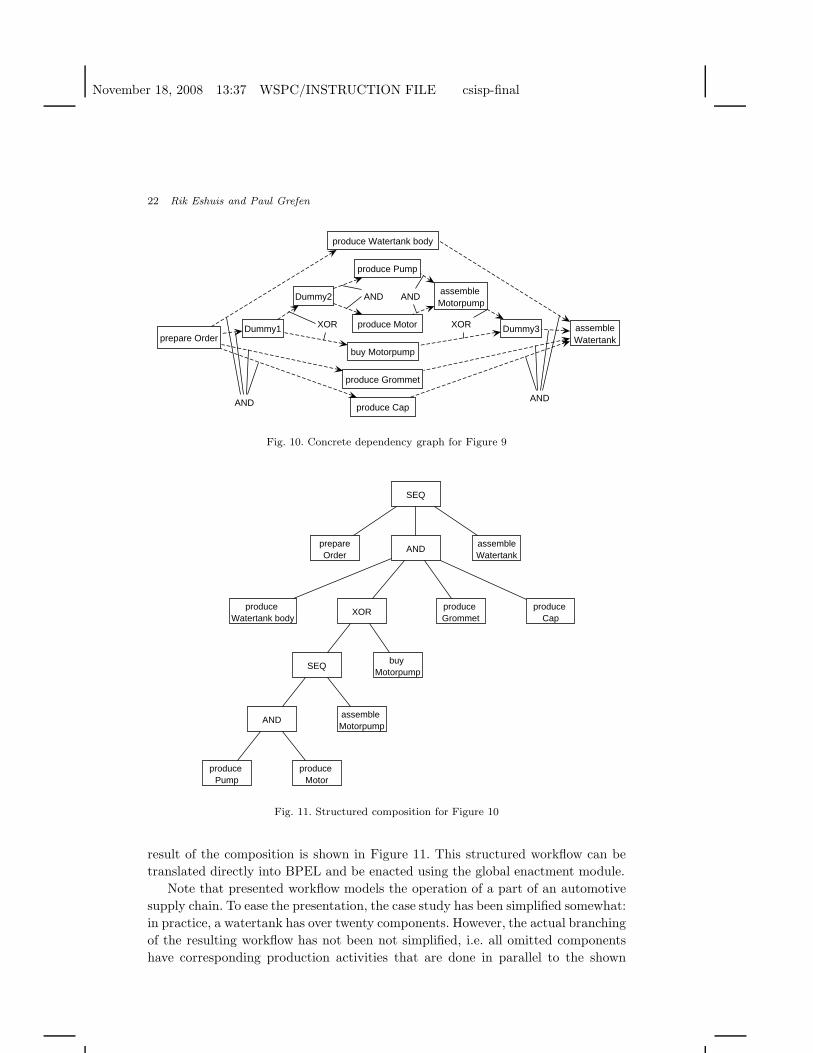
and assemble Motorpump. Therefore, the user (a domain expert) has to provide acorrected version, and also needs to annotate the dependencies with types. Figure10 shows a corrected dependency graph with branching types. Some direct depen-dencies, e.g. between prepare Order and assemble MotorPump have been removed,because the user decided they are redundant (e.g. prepare Order delivers input toassemble MotorPump by means of produce Motor and produce Pump). Furthermore,by typing the dependency graph, the user has decided that a motorpump is ei-ther bought or produced. Three dummy services have been inserted to type thedependency graph in a correct way.
Finally, the workflow is composed using the algorithm defined in Section 4. The
November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
22 Rik Eshuis and Paul Grefen
prepare Order
produce Watertank body
produce Pump
produce Motor
produce Grommet
assemble Motorpump
produce Cap
assembleWatertank
buy Motorpump
Dummy1
Dummy2
XOR
AND
AND
Dummy3XOR
AND
AND
Fig. 10. Concrete dependency graph for Figure 9
prepareOrder
produce Watertank body
produce Pump
produce Motor
produce Grommet
assemble Motorpump
produce Cap
assembleWatertank
buy Motorpump
SEQ
AND
XOR
AND
SEQ
Fig. 11. Structured composition for Figure 10
result of the composition is shown in Figure 11. This structured workflow can betranslated directly into BPEL and be enacted using the global enactment module.
Note that presented workflow models the operation of a part of an automotivesupply chain. To ease the presentation, the case study has been simplified somewhat:in practice, a watertank has over twenty components. However, the actual branchingof the resulting workflow has not been not simplified, i.e. all omitted componentshave corresponding production activities that are done in parallel to the shown

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 23
production activities.
6.3. Evaluation
A main feature of the CrossWork approach is its reliance on gradual automation.20
The user parties have clearly stated that complete automation of knowledge anddecision procedures is at this moment not feasible as many of these have not yetbeen formalized enough to allow automation. Also, complete automation is at thispoint not desirable since the domain is not yet ready to accept fully computer-led business, even if complete domain knowledge would be available. Therefore, aservice composition approach that requires services to be modeled with pre andpost conditions was not feasible. Instead, we have chosen to model services in alightweight manner, using descriptions that are either based on user input or basedon lightweight ontological descriptions which are derived from for example Billof Materials. From such descriptions, dependencies among services can be easilyderived. In addition, this approach supports the goal of gradual automation, sinceinitial descriptions can be very coarse grained, only referencing a few data entities,while later descriptions can be more detailed, up to the level of being formallyspecified. However, for the automotive application domain that we considered inCrossWork, we expect complete formal descriptions for services are not feasible, forreasons mentioned above.
Next, the actual composition models constructed for the CrossWork case studiesare not so complex, though their size is greater than that of the model presentedabove. For example, in practice a watertank has over twenty components, for whichproduction and assembly steps are needed. However, the actual branching is not socomplex, since most steps are done in parallel. We conjecture that this simplicity isdue to the nature of supply chains: all dependencies between different activities aredue to movements of physical goods, and only a few choices are made during a pro-cess. Despite their simplicity, the models do capture part of an existing automotivesupply chain, and can be used as starting point for enacting and monitoring In-stant Virtual Enterprises that are responsible for supplying car parts to an OEM.20
Since the algorithm has an almost linear time complexity, the approach can also beapplied to dependency graphs having more complex branching conditions.
Thus, for the CrossWork project, the service composition approach proved tobe useful and easy to implement.
7. Related work
The topic of service composition has attracted the attention of many researchers.Existing approaches can be classified into three categories: manual, partly auto-mated, or fully automated.12 Approaches in the manual category assume that auser manually designs a service composition, including the binding to concrete webservices. This category includes languages like BPEL,5 OWL-S16 and JOpera36 andconcrete composition prototypes.37,38

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
24 Rik Eshuis and Paul Grefen
In approaches in the semi-automated category,12,13,39,40 the user must eitherprovide a template with a composition skeleton which defines the process logic, orgive input to a composition procedure that constructs the template. This templatecan then be instantiated automatically by searching for atomic services that matcheach of the services specified in the skeleton.39,40 The focus of some approaches39,40
lies on automatically finding substitute services for specified services in a template,while others12,13 consider the problem of constructing a composition skeleton.
Fully automated approaches6,7,8,9,10,11,41,42,43 mostly come from the field of AIplanning or formal reasoning. These approaches require that web services are speci-fied formally with pre- and post-conditions. This puts a considerable burden on theshoulders of service designers, since WSDL specifications do not require that level ofdetail and hence need to be annotated with the additional pre- and post-conditions.
Our approach has some features in common with semi-automatedapproaches12,13 and fully automated approaches.6,11 We now examine more closelythe differences and similarities between our approach and these two groups of relatedwork. Similar to the approaches in the semi-automated category that construct acomposition skeleton,12,13 our approach composes services by analyzing dependen-cies. However, the current semi-automated approaches focus on constructing un-structured process models, by translating dependencies directly intro control flow,whereas we focus on constructing structured process models. As explained in Sec-tion 2, constructing structured models is more complex, since dependencies cannotbe translated directly into structured control-flow. Thus, the main difference withthese semi-automated approaches is the use of the structured composition algorithmin our approach.
Regarding fully automated approaches, most of them7,8,9,10,11,41,42,43 only con-sider sequential compositions, whereas we consider compositions containing paral-lelism. Nevertheless, there are a few automated approaches6,11 that construct struc-tured process models. Duan et al.6 consider structured process models with choiceand parallelism, but Sirin et al.11 only consider sequential structured compositions.The time complexity of these approaches is not clearly indicated. However, theapproach of Duan et al.6 requires back tracking, which suggests a non-polynomialtime complexity, whereas the AI planning technique used by Sirin et al.11 is NP-complete. In contrast, our algorithm is almost linear time and thus polynomial. Ourapproach is also more lightweight, since we do not require formally specified pre-and post-conditions, and thus users do not have to provide as much input as in thementioned other approaches. Note that we do use guard conditions in the compo-sitions, but these are generated automatically by the algorithm and are not due topre- or post-conditions of services. Drawback, however, is that our approach is lessprecise, since service dependencies are less detailed than pre- and post-conditions.In addition, we have defined healthiness constraints under which the algorithm op-erates correctly. All fully automated approaches do not use such constraints; thusit is unclear when a given set of services with pre- and post-conditions can be

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 25
composed together successfully. Thus, the main difference with the fully automatedapproaches is the use of an efficient algorithm and the use of lightweight servicedescriptions in our approach.
Another way of dealing with the unstructuredness problem would be to trans-form a dependency graph into an unstructured process model using e.g. Refs. 12,13and to transform that process model into a structured one, using approaches forstructuring process models.14,15,25,44,45,46 Most approaches for structuring processmodels14,15,25,44,45 only sketch how techniques developed in the 70’s and 80’s tostructure sequential programs with goto statements can be used to structure processmodels containing parallelism. Unfortunately, converting an unstructured processmodel into a structured one has revealed to be quite intricate, because process mod-els can contain parallelism while programs are sequential. Consequently, automatedtransformations exist only for sequential process parts. Ouyang et al.46 focus on rec-ognizing structured patterns in unstructured process models and mapping those tostructured BPEL fragments, but do not address how an unstructured process modelcan be structured. For example, the unstructured process model corresponding toFigure 1 cannot be structured using the approach of Ouyang et al. Our approachis more powerful than all these approaches since we use an automated structuringalgorithm for unstructured dependency graphs that may contain parallelism. Thisalgorithm generalizes an existing algorithm for structuring sequential flow graphs.18
Moreover, we identified healthiness constraints on dependency graphs under whichthe structuring algorithm operates correctly; we are unaware of other work definingsimilar constraints for process graphs that contain parallelism.
Finally, there are approaches47,48,49 that consider the problem of decomposing aglobal process view into a set of local process models that collaboratively implementthe global process view. The problem there is to ensure that the behaviors in theglobal process view are preserved by the collaborative local processes. Instead, ourapproach focuses on how to compose a global process view from a set of localservices that do not have a behavioral interface. An interesting extension of ourapproach would be to consider local services that do have a behavioral interface.In that case, the techniques of Refs. 47,48,49 can be useful to show the correctnessof the constructed composition, i.e. that the global composition can be realized bythe local services.
In summary, the most distinguishing feature of our approach is the usage of anefficient algorithm that builds on concepts from compiler theory, whereas the mostclosely related other service composition approaches are either not algorithmic12,13
or build upon AI planning11 or formal reasoning,6 which results in less efficientalgorithms and requires formal annotation. Our approach is especially useful insettings where detailed information about services is lacking and cannot be providedthat easily, as is the case in the CrossWork cases.

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
26 Rik Eshuis and Paul Grefen
8. Conclusions and further work
We have presented a simple yet efficient algorithm for composing a set of coop-erative services into a structured process model. Given a dependency graph, thealgorithm constructs a structured composition satisfying the given dependencies.The algorithm is embedded in a lightweight, semi-automated service compositionapproach, which needs domain knowledge in the form of user input to annotatedependency graphs with branching types and to resolve constraint violations. How-ever, these activities are less laborious than annotating services with formal pre- andpost-conditions, which is required by most other comparable service compositionapproaches, and is also applicable if services are not formally specified. Moreover,the overall approach is more efficient than comparable approaches and thereforeuseful in business settings where speed is important.20
The main advantage of using structured processes is that such processes only usebasic workflow patterns that are supported by virtually every process enactmenttool.17 This feature enables the constructed structured compositions to be encodedstraightforwardly into any process language including BPEL,5 OWL-S16 and otherstandard languages like XPDL.23 However, it considerably complicates the compo-sition task, since dependencies cannot be translated directly into control-flow links.
The service composition approach has been implemented in a prototype in thecontext of the CrossWork project.19 This project studied the dynamic formationand collaboration of virtual enterprises. Though the case studies are of mediumsize, the approach has been applied successfully to construct workflows that specifyparts of automotive supply chains. Since the algorithm runs in almost linear time,it scales up to larger models. Though structured process models are less expressivethan unstructured ones, for supply chains complex branching types are not used inpractice, so structured process models can model supply chain processes satisfacto-rily. Further work includes extending the approach to support the composition oflocal services that have a behavioral interface.35 Another interesting extension is tolet quality of service aspects guide decisions made in the composition phase.50
Acknowledgements
Sven Till is thanked for implementing the first version of the composition moduleof the CrossWork system. All CrossWork partners are acknowledged for their workon the CrossWork project and system. This work has been supported by the ISTproject CrossWork (No. 507590) and the IST Network of Excellence INTEROP(No. 508011).
References
1. P. Grefen. Towards dynamic interorganizational business process management(keynote talk). In S. Reddy, editor, Proc. WETICE 2006, pages 13–18. IEEE Com-puter Society, 2006.

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 27
2. G. Alonso, F. Casati, H. Kuno, and V. Machiraju. Web Services: Concepts, Architec-tures and Applications. Springer, 2004.
3. M.P. Papazoglou. Web Services: Principles and Technology. Prentice Hall, 2007.4. E. Christensen, F. Curbera, G. Meredith, and S. Weerawarana. Web Services Descrip-
tion Language (WSDL) 1.1. http://www.w3.org/TR/wsdl, 2001.5. A. Alves, A. Arkin, S. Askary, C. Barreto, B. Bloch, F. Curbera, M. Ford,
Y. Goland, A. Guzar, N. Kartha, C. K. Liu, R. Khalaf, D. Koenig, M. Marin,V. Mehta, S. Thatte, D. Rijn, P. Yendluri, and A. Yiu. Web services businessprocess execution language version 2.0 (OASIS standard). WS-BPEL TC OASIS,http://docs.oasis-open.org/wsbpel/2.0/wsbpel-v2.0.html, 2007.
6. Z. Duan, A. Bernstein, P. Lewis, and S. Lu. A model for abstract process specification,verification and composition. In Proceedings of the 2nd international conference onService oriented computing (ICSOC’04), pages 232–241. ACM Press, 2004.
7. T. Madhusudan and N. Uttamsingh. A declarative approach to composing web servicesin dynamic environments. Decision Support Systems, 41(2):325–357, 2006.
8. M. Matskin and J. Rao. Value-added web services composition using automatic pro-gram synthesis. In C. Bussler, R. Hull, S.A. McIlraith, M.E. Orlowska, B. Pernici, andJ. Yang, editors, CAiSE’02 workshop on Web Services, E-Business, and the Seman-tic Web, Revised Papers, Lecture Notes in Computer Science 2512, pages 213–224.Springer, 2002.
9. S.A. McIlraith and T.C. Son. Adapting golog for composition of semantic web services.In D. Fensel, F. Giunchiglia, D.L. McGuinness, and M.-A. Williams, editors, Proc. ofthe 8th International Conference on Principles and Knowledge Representation andReasoning (KR-02), pages 482–496. Morgan Kaufmann, 2002.
10. S.R. Ponnekanti and A. Fox. Sword: A developer toolkit for building composite webservices. In Proc. of the 11th International World Wide Web Conference, 2002.
11. E. Sirin, B. Parsia, D. Wu, J.A. Hendler, and D.S. Nau. HTN planning for web servicecomposition using SHOP2. Journal of Web Semantics, 1(4):377–396, 2004.
12. A. Brogi and R. Popescu. Towards semi-automated workflow-based aggregation ofweb services. In F. Casati, P. Traverso, and B. Benatallah, editors, Proceedings ofThird International Conference on Service Oriented Computing (ICSOC05), LectureNotes in Computer Science 3826. Springer, 2005.
13. Q. Liang, L. N. Chakarapani, S. Su, R. Chikkamagalur, and H. Lam. A semi-automaticapproach to composite web services discovery, description and invocation. Int. Journalon Web Service Research, 1(4):64–89, 2004.
14. B. Kiepuszewski, A.H.M. ter Hofstede, and C. Bussler. On structured workflow mod-elling. In B. Wangler and L. Bergman, editors, Proc. CAiSE ’00, pages 431–445.Springer, 2000.
15. R. Liu and A. Kumar. An analysis and taxonomy of unstructured workflows. InW.M.P. van der Aalst, B. Benatallah, F. Casati, and F. Curbera, editors, Proc. 3rdConference on Business Process Management (BPM 2005), Lecture Notes in Com-puter Science 3649, pages 268–284, 2005.
16. D. Martin (editor), M. Burstein, J. Hobbs, O. Lassila, D. McDermott, S. McIl-raith, S. Narayanan, M. Paolucci, B. Parsia, T. Payne, E. Sirin, N. Srini-vasan, and K. Sycara. Owl-s: Semantic markup for web services, 2004.http://www.daml.org/services/owl-s/1.1/ overview.
17. W.M.P. van der Aalst, A.H.M. ter Hofstede, B. Kiepuszewski, and A.P. Barros. Work-flow patterns. Distributed and Parallel Databases, 14(1):5–51, 2003.
18. B.S. Baker. An algorithm for structuring flowgraphs. Journal of the ACM, 24(1):98–120, 1977.

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
28 Rik Eshuis and Paul Grefen
19. CrossWork consortium. Crosswork project, IST no. 507590.http://www.crosswork.info.
20. P. Grefen, N. Mehandjiev, G. Kouvas, G. Weichhart, and R. Eshuis. Dynamic busi-ness network process management in instant virtual enterprises. Beta Working PaperSeries, WP 198, 2007. To appear in Computers in Industry.
21. A.V. Aho, R. Sethi, and J.D. Ullman. Compilers: Principles, Techniques, and Tools.Addison Wesley, 1986.
22. R. Eshuis, P. Grefen, and S. Till. Structured service composition. In S. Dustdar, J.L.Fiadeiro, and A. Sheth, editors, Proc. of the 4th International Conference on BusinessProcess Management (BPM 2006), Lecture Notes in Computer Science 4102, pages97–112. Springer, 2006.
23. Workflow Management Coalition. Workflow process definition interface – XML pro-cess definition language. Technical Report WFMC-TC-1025, Workflow ManagementCoalition, 2002.
24. M. Reichert and P. Dadam. ADEPTflex: Supporting Dynamic Changes of Workflowwithout Loosing Control. Journal of Intelligent Information Systems, 10(2):93–129,1998.
25. W. Zhao, R. Hauser, K. Bhattacharya, B.R. Bryant, and F. Cao. Compiling businessprocesses: untangling unstructured loops in irreducible flow graphs. Int. Journal ofWeb and Grid Services, 2:68–91, 2006.
26. T. Lengauer and R.E. Tarjan. A fast algorithm for finding dominators in a flowgraph.ACM Transactions on Programming Languages and Systems, 1(1):121–141, 1979.
27. G. Ramalingam. Identifying loops in almost linear time. ACM Transactions on Pro-gramming Languages and Systems, 21(2):175–188, 1999.
28. R.E. Tarjan. Testing flow graph reducibility. Journal of Computer and System Sci-ences, 9(3):355–365, 1974.
29. J. Cardoso and A. Sheth. Semantic e-workflow composition. Journal of IntelligentInformation Systems, 21(3):191–225, 2003.
30. M. Paolucci, T. Kawamura, T.R. Payne, and K.P. Sycara. Semantic matching of webservices capabilities. In I. Horrocks and J.A. Hendler, editors, Proc. InternationalSemantic Web Conference (ISWC’02), Lecture Notes in Computer Science 2342, pages333–347. Springer, 2002.
31. T. Syeda-Mahmood, G. Shah, R. Akkiraju, A.-A. Ivan, and R. Goodwin. Searchingservice repositories by combining semantic and ontological matching. In Proc. ICWS2005, pages 13–20. IEEE Computer Society, 2005.
32. A. Hess and N. Kushmerick. Machine learning for annotating semantic web services.In Proc. AAAI Spring Symposium on Semantic Web Services, 2004.
33. M. Carpenter, N. Mehandjiev, and I.D. Stalker. Flexible behaviours for emergentprocess interoperability. In S. Reddy, editor, Proc. WETICE 2006, pages 249–255.IEEE Computer Society, 2006.
34. W.M.P. van der Aalst and A. Kumar. XML Based Schema Definition for Support ofInter-organizational Workflow. Information Systems Research, 14(1):23–46, 2003.
35. P. Grefen, H. Ludwig, A. Dan, and S. Angelov. An analysis of web services sup-port for dynamic business process outsourcing. Information and Software Technology,48(11):1115–1134, 2006.
36. C. Pautasso and G. Alonso. The JOpera visual composition language. Journal ofVisual Languages & Computing, 16(1-2):119–152, 2005.
37. B. Benatallah, Q.Z. Sheng, and M. Dumas. The self-serv environment for web servicescomposition. IEEE Internet Computing, 7(1):40–48, 2003.
38. J. Yang and M. Papazoglou. Service components for managing the life-cycle of service

November 18, 2008 13:37 WSPC/INSTRUCTION FILE csisp-final
Composing Services into Structured Processes 29
compositions. Information Systems, 29(2):97–125, 2004.39. F. Casati and M.-C. Shan. Dynamic and adaptive composition of e-services. Informa-
tion Systems, 26(3):143–162, 2001.40. B. Medjahed, A. Bouguettaya, and A. Elmagarmid. Composing Web services on the
Semantic Web. The VLDB Journal, 12(4):333–351, 2003.41. D. Berardi, D. Calvanese, G. De Giacomo, M. Lenzerini, and M. Mecella. Automatic
service composition based on behavioral descriptions. International Journal of Coop-erative Information Systems, 14(4), 2005.
42. P. Traverso and M. Pistore. Automated composition of semantic web services intoexecutable processes. In S.A. McIlraith, D. Plexousakis, and F. van Harmelen, editors,Proc. Third International Semantic Web Conference ISWC (2004), Lecture Notes inComputer Science 3298, pages 380–394. Springer, 2004.
43. R. Hull, M. Benedikt, V. Christophides, and J. Su. E-services: A look behind thecurtain. In Proc. of the 22nd ACM Symposium on Principles of Database Systems,pages 1–14. ACM, 2003.
44. J. Koehler and R. Hauser. Untangling unstructured cyclic flows - a solution based oncontinuations. In R. Meersman and Z. Tari, editors, Proc. CoopIS/DOA/ODBASE2004, Lecture Notes in Computer Science 3290, pages 121–138. Springer, 2004.
45. R. Hauser, M. Friess, J.M. Kuster, and J. Vanhatalo. Combining analysis of unstruc-tured workflows with transformation to structured workflows. In Proc. Tenth IEEE In-ternational Enterprise Distributed Object Computing Conference (EDOC 2006), pages129–140. IEEE Computer Society, 2006.
46. C. Ouyang, M. Dumas, A. ter Hofstede, and W.M.P. van der Aalst. Pattern-basedtranslation of BPMN process models to BPEL web services. International Journal ofWeb Services Research, 5(1):42–61, 2008.
47. W.M.P. van der Aalst and M. Weske. The P2P approach to interorganizational work-flows. In K.R. Dittrich, A. Geppert, and M.C. Norrie, editors, Proc. of the 13th Int.Conference on Advanced Information Systems Engineering (CAiSE’01), Lecture Notesin Computer Science 2068, pages 140–156. Springer, 2001.
48. R. Khalaf and F. Leymann. E role-based decomposition of business processes usingbpel. In Proc. ICWS 2006, pages 770–780, 2006.
49. J.M. Zaha, M. Dumas, A.H.M. ter Hofstede, A.P. Barros, and G. Decker. Serviceinteraction modeling: Bridging global and local views. In Proc. EDOC 2006. IEEEComputer Society, 2006.
50. D. Ardagna and B. Pernici. Adaptive service composition in flexible processes. IEEETransactions on Software Engineering, 33(6):369–384, 2007.


















