Clustering Paolo Ferragina Dipartimento di Informatica Università di Pisa This is a mix of slides...
44
Clustering Paolo Ferragina Dipartimento di Informatica Università di Pisa This is a mix of slides taken from several presentations, plus my touch !
-
Upload
greta-netter -
Category
Documents
-
view
214 -
download
0
Transcript of Clustering Paolo Ferragina Dipartimento di Informatica Università di Pisa This is a mix of slides...

Clustering
Paolo FerraginaDipartimento di Informatica
Università di Pisa
This is a mix of slides taken from several presentations, plus my touch !
This is a mix of slides taken from several presentations, plus my touch !
Objectives of Cluster Analysis
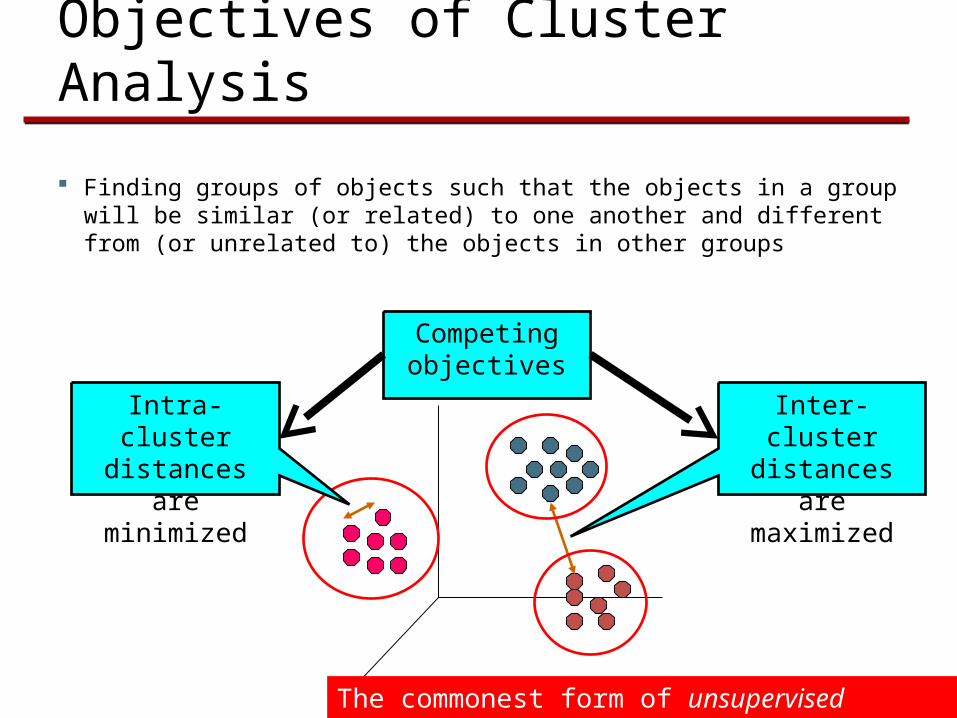
Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the objects in other groups
Inter-cluster distances are maximized
Intra-cluster distances are
minimized
Competing objectives
The commonest form of unsupervised learning

Google News: automatic clustering gives an effective news presentation metaphor

For improving search recall
Cluster hypothesis - Documents in the same cluster behave similarly with respect to relevance to information needs
Therefore, to improve search recall: Cluster docs in corpus a priori When a query matches a doc D, also return other docs in the
cluster containing D
Hope if we do this: The query “car” will also return docs containing automobile
Sec. 16.1
But also for speeding up the search operation
But also for speeding up the search operation

For better visualization/navigation of search resultsSec. 16.1

Issues for clustering
Representation for clustering Document representation
Vector space? Normalization? Need a notion of similarity/distance
How many clusters? Fixed a priori? Completely data driven?
Sec. 16.2

Notion of similarity/distance
Ideal: semantic similarity Practical: term-statistical similarity
Docs as vectors We will use cosine similarity. For many algorithms, easier to think in
terms of a distance (rather than similarity) between docs.

Clustering Algorithms Flat algorithms
Create a set of clusters Usually start with a random (partial) partitioning Refine it iteratively
K means clustering
Hierarchical algorithms Create a hierarchy of clusters (dendogram) Bottom-up, agglomerative Top-down, divisive

Hard vs. soft clustering
Hard clustering: Each document belongs to exactly one cluster More common and easier to do
Soft clustering: Each document can belong to more than one cluster. Makes more sense for applications like creating browsable
hierarchies News is a proper example Search results is another example

Flat & Partitioning Algorithms
Given: a set of n documents and the number K Find: a partition in K clusters that optimizes the
chosen partitioning criterion Globally optimal
Intractable for many objective functions Ergo, exhaustively enumerate all partitions
Locally optimal Effective heuristic methods: K-means and K-medoids algorithms

K-Means
Assumes documents are real-valued vectors. Clusters based on centroids (aka the center of gravity
or mean) of points in a cluster, c:
Reassignment of instances to clusters is based on distance to the current cluster centroids.
cx
xc
||
1(c)μ
Sec. 16.4

K-Means Algorithm
Select K random docs {s1, s2,… sK} as seeds.
Until clustering converges (or other stopping criterion):
For each doc di: Assign di to the cluster cr such that dist(di, sr) is minimal.
For each cluster cj
sj = (cj)
Sec. 16.4

K Means Example (K=2)
Pick seeds
Reassign clusters
Compute centroids
xx
Reassign clusters
xx xx Compute centroids
Reassign clusters
Converged!
Sec. 16.4

Termination conditions
Several possibilities, e.g., A fixed number of iterations. Doc partition unchanged. Centroid positions don’t change.
Sec. 16.4

Convergence
Why should the K-means algorithm ever reach a fixed point? K-means is a special case of a general procedure known as
the Expectation Maximization (EM) algorithm EM is known to converge Number of iterations could be large
But in practice usually isn’t
Sec. 16.4

Convergence of K-Means
Define goodness measure of cluster c as sum of squared distances from cluster centroid: G(c,s) = Σi (di – sc)2 (sum over all di in cluster c) G(C,s) = Σc G(c,s)
Reassignment monotonically decreases G It is a coordinate descent algorithm (opt one component at a time)
At any step we have some value for G(C,s)1) Fix s, optimize C assign d to the closest centroid G(C’,s) < G(C,s)2) Fix C’, optimize s take the new centroids G(C’,s’) < G(C’,s) < G(C,s)
The new cost is smaller than the original one local minimum
Sec. 16.4

Time Complexity
The centroids are K Each doc/centroid consists of M dimensions Computing distance btw vectors is O(M) time. Reassigning clusters: Each doc compared with all
centroids, O(KNM) time. Computing centroids: Each doc gets added once to
some centroid, O(NM) time.
Assume these two steps are each done once for I iterations: O(IKNM).
Sec. 16.4

Seed Choice
Results can vary based on random seed selection. Some seeds can result in poor
convergence rate, or convergence to sub-optimal clusterings.
Select good seeds using a heuristic doc least similar to any existing
centroid According to a probability distribution
that depends inversely-proportional on the distance from the other current centroids
In the above, if you startwith B and E as centroidsyou converge to {A,B,C}and {D,E,F}If you start with D and Fyou converge to {A,B,D,E} {C,F}
Example showingsensitivity to seeds
Sec. 16.4

How Many Clusters?
Number of clusters K is given Partition n docs into predetermined number of clusters Finding the “right” number of clusters is part of the
problem Can usually take an algorithm for one flavor and
convert to the other.

Bisecting K-means
Variant of K-means that can produce a partitional or a hierarchical clustering

Bisecting K-means Example

K-means
Pros Simple Fast for low dimensional data It can find pure sub-clusters if large number of
clusters is specified (but, over-partitioning)Cons K-Means cannot handle non-globular data of
different sizes and densities K-Means will not identify outliers K-Means is restricted to data which has the notion of
a center (centroid)

Hierarchical Clustering
Build a tree-based hierarchical taxonomy (dendrogram) from a set of documents
One approach: recursive application of a partitional clustering algorithm
animal
vertebrate
fish reptile amphib. mammal worm insect crustacean
invertebrate
Ch. 17

Strengths of Hierarchical Clustering
No assumption of any particular number of clusters Any desired number of clusters can be obtained by
‘cutting’ the dendogram at the proper level
They may correspond to meaningful taxonomies Example in biological sciences (e.g., animal kingdom,
phylogeny reconstruction, …)

Hierarchical Agglomerative Clustering (HAC)
Starts with each doc in a separate cluster Then repeatedly joins the closest pair of
clusters, until there is only one cluster.
The history of mergings forms a binary tree or hierarchy.
Sec. 17.1

Closest pair of clusters
Single-link Similarity of the closest points, the most cosine-similar
Complete-link Similarity of the farthest points, the least cosine-similar
Centroid Clusters whose centroids are the closest (or most cosine-
similar)
Average-link Clusters whose average distance/cosine between pairs of
elements is the smallest
Sec. 17.2

How to Define Inter-Cluster Similarity
p1
p3
p5
p4
p2
p1 p2 p3 p4 p5 . . .
.
.
.
Similarity?
Single link (MIN) Complete link (MAX) Centroids Average Proximity
Matrix

How to Define Inter-Cluster Similarity
p1
p3
p5
p4
p2
p1 p2 p3 p4 p5 . . .
.
.
.Proximity Matrix
MIN MAX Centroids Average

How to Define Inter-Cluster Similarity
p1
p3
p5
p4
p2
p1 p2 p3 p4 p5 . . .
.
.
.Proximity Matrix
MIN MAX Centroids Average

How to define Inter-Cluster Similarity
p1
p3
p5
p4
p2
p1 p2 p3 p4 p5 . . .
.
.
.Proximity Matrix
MIN MAX Centroids Average

How to Define Inter-Cluster Similarity
p1
p3
p5
p4
p2
p1 p2 p3 p4 p5 . . .
.
.
.Proximity Matrix
MIN MAX Centroids Average

Starting Situation
Start with clusters of individual points and a proximity matrix
p1
p3
p5
p4
p2
p1 p2 p3 p4 p5 . . .
.
.
. Proximity Matrix
...p1 p2 p3 p4 p9 p10 p11 p12

Intermediate Situation
After some merging steps, we have some clusters
C1
C4
C2 C5
C3
C2C1
C1
C3
C5
C4
C2
C3 C4 C5
Proximity Matrix
...p1 p2 p3 p4 p9 p10 p11 p12
C1 C3 C2 C5 C4

Intermediate Situation We want to merge the two closest clusters (C2 and C5) and update
the proximity matrix.
C1
C4
C2 C5
C3
C2C1
C1
C3
C5
C4
C2
C3 C4 C5
Proximity Matrix
...p1 p2 p3 p4 p9 p10 p11 p12
C1 C3 C2 U C5 C4

After Merging
The question is “How do we update the proximity matrix?”
C1
C4
C2 U C5
C3? ? ? ?
?
?
?
C2 U C5C1
C1
C3
C4
C2 U C5
C3 C4
Proximity Matrix
...p1 p2 p3 p4 p9 p10 p11 p12
C1 C3 C2 U C5 C4

Cluster Similarity: MIN or Single Link
Similarity of two clusters is based on the two most similar (closest) points in the different clusters Determined by one pair of points, i.e., by one link in the
proximity graph.
I1 I2 I3 I4 I5I1 1.00 0.90 0.10 0.65 0.20I2 0.90 1.00 0.70 0.60 0.50I3 0.10 0.70 1.00 0.40 0.30I4 0.65 0.60 0.40 1.00 0.80I5 0.20 0.50 0.30 0.80 1.00
1 2 3 4 5
??

Strength of MIN
Original Points Two Clusters
• Can handle non-elliptical shapes

Limitations of MIN
Original Points Two Clusters
• Sensitive to noise and outliers

Cluster Similarity: MAX or Complete Linkage
Similarity of two clusters is based on the two least similar (most distant) points in the different clusters Determined by all pairs of points in the two clusters
I1 I2 I3 I4 I5I1 1.00 0.90 0.10 0.65 0.20I2 0.90 1.00 0.70 0.60 0.50I3 0.10 0.70 1.00 0.40 0.30I4 0.65 0.60 0.40 1.00 0.80I5 0.20 0.50 0.30 0.80 1.00 1 2 3 4 5
??

Strength of MAX
Original Points Two Clusters
• Less susceptible to noise and outliers

Limitations of MAX
Original PointsTwo Clusters
•Tends to break large clusters
•Biased towards globular clusters

Cluster Similarity: Average
Proximity of two clusters is the average of pairwise proximity between points in the two clusters.
||Cluster||Cluster
)p,pproximity(
)Cluster,Clusterproximity(ji
ClusterpClusterp
ji
jijjii
I1 I2 I3 I4 I5I1 1.00 0.90 0.10 0.65 0.20I2 0.90 1.00 0.70 0.60 0.50I3 0.10 0.70 1.00 0.40 0.30I4 0.65 0.60 0.40 1.00 0.80I5 0.20 0.50 0.30 0.80 1.00
1 2 34 5

Hierarchical Clustering: Comparison
Average
MIN MAX
1
2
3
4
5
61
2
5
34
1
2
3
4
5
61
2 5
3
41
2
3
4
5
6
12
3
4
5

How to evaluate clustering quality ?
Assesses a clustering with respect to ground truth … requires labeled data
Produce the gold standard is costly !!
Sec. 16.3