
Clustering Homogenous XML Documents (CS501 Final Report) (1)
24
Page | 1 PORTLAND STATE UNIVERSITY Clustering Homogenous XML Documents Evaluation of current clustering methodologies and the proposal of signature-based clustering By Abdussalam Alawini 8/12/2011 Supervised by: Prof. David Maier
-
Upload
abdussalam-alawini -
Category
Documents
-
view
280 -
download
0
Transcript of Clustering Homogenous XML Documents (CS501 Final Report) (1)

Page | 1
PORTLAND STATE UNIVERSITY
Clustering Homogenous
XML Documents Evaluation of current clustering methodologies
and the proposal of signature-based clustering
By
Abdussalam Alawini
8/12/2011
Supervised by:
Prof. David Maier

Page | 2
Table of Contents Abstract ......................................................................................................................................................... 3
1. Introduction .......................................................................................................................................... 3
1.1. Problem Statement ....................................................................................................................... 4
2. Background ........................................................................................................................................... 6
2.1. XML Data Model ........................................................................................................................... 6
2.2. XML Structural Clustering ............................................................................................................. 6
2.3. Important definitions .................................................................................................................... 6
2.3.1. Structured Product Labeling (SPL) ........................................................................................ 6
2.3.2. Homogenous XML documents .............................................................................................. 6
2.3.3. Heterogeneous XML documents .......................................................................................... 7
3. XML Structural Clustering Approaches ................................................................................................. 7
3.1. Tree-edit Distance ......................................................................................................................... 7
3.2. Graph-based Clustering ................................................................................................................ 8
3.3. Tree-based Clustering ................................................................................................................. 10
4. Why a New Approach is needed for Clustering Homogenous XML Documents ................................ 14
4.1. Losing important structure information ..................................................................................... 14
Tree-edit distance ............................................................................................................................... 14
Graph-based clustering ....................................................................................................................... 15
Tree-based Clustering ......................................................................................................................... 16
4.2. Expensive computation time ...................................................................................................... 17
Tree-edit distance ............................................................................................................................... 17
4.3. Poor quality Clusters for homogenous XML documents ............................................................ 17
S-graph-based Clustering .................................................................................................................... 17
Tree-based Clustering ......................................................................................................................... 18
5. Proposed Abstract Solution: Signature-based Clustering ................................................................... 18
5.1 Stage 1: Extracting XML Structural Summary ................................................................................... 19
5.2 Stage 2: Performing initial signature-based clustering ..................................................................... 20
5.3 Stage 3: Refining clusters based on user input ................................................................................. 21
Appendix A: XML Summary Extractor Code ................................................................................................ 24

Page | 3
Abstract Huge amount of information is being stored as XML documents due to the standardization of XML as
information exchange language over the internet. This means that more applications need to process
XML documents for different purposes. One of the important applications is grouping XML documents
that have a single XML Schema or DTD based on their structure, especially for XML documents with ill-
defined XML Schema or DTD. Mining such structural information may provide important clues about the
meaning of the data enclosed in these documents. This paper evaluates the application of current XML
structural clustering approaches (tree-edit, graph-based and tree-based clustering approaches) on
homogenous XML documents. The results suggest that these approaches are not efficient for clustering
this kind of XML document, hence new approach has to be developed for clustering XML documents
that are based on single Schema or DTD. This paper also provides a detailed description of an abstract
design of signature-based clustering approach that is developed for clustering homogenous XML
documents.
1. Introduction Extendible Markup Language (XML) is the internet standard for exchanging structured data over the web
[1]. Its powerful ability for managing, displaying and organizing data as well as providing interoperability
and enabling automatic processing of Web resources drive many real-world applications to quickly
adapted [1]. The major advantage of XML over HTML is that XML can describe the content and structure
of the data it encompasses while HTML focuses only on presenting instructions to web browsers on how
the data it encompasses should be displayed [1]. As a result, more information is being stored in more
structurally rich documents, from HTML to XML [2].
With more applications adapting XML as a standard for transferring structured data over the web, the
need to automatically process those documents for information extraction, similarity clustering, and
search applications is significantly increasing [2]. XML data processing and management as well as
content mining have been a very popular research area. However, the focus on mining XML documents
based on their structure information is still emerging. Due to the fact that XML documents’ well
organized structure may provide very important clues on what the content of the data might be, more
researchers are focusing on mining XML documents structural information.
Grouping XML documents with similar structure is an important functionality for many applications such
as XML query processing and information extraction [2]. The focus of many of XML clustering
approaches has been on clustering XML documents from different sources [3][4][6][7][8][9]; for
example, documents with different XML Schema, different DTD or no schema at all. In contrast,
clustering XML documents based on single Schema or DTD has not received strong attention. Clustering
these homogenous documents is very important for many applications especially when the XML Schema
for a group of documents is ill-defined.
In this research, I first present the main three approaches for clustering XML documents based on their
structure. Then I show that these approaches are not efficient for clustering homogenous XML

Page | 4
documents, and that a new approach is needed especially for clustering those kinds of documents.
Finally, we present an abstract design for a novel homogenous clustering approach called signature-
based clustering. This paper is organized as following: section 1 introduces the paper and describe the
problem statement, section 2 gives some important background information related to the paper topic,
section 3 presents three different clustering approaches for heterogeneous XML documents, section 4
discusses why these approaches are not appropriate for clustering XML documents that based on a
single Schema or DTD, section 5 discusses signature-based clustering as a solution, and finally future
work and research conclusion are presented in section 6.
1.1. Problem Statement
The first question that comes to your mind when you hear “clustering XML documents that are based on
single Schema or DTD” is that why we need to cluster such documents if all these documents have
similar structure rules? The simple answer is that some XML Schemas or DTDs may be ill-defined and
allow for XML documents to contain data that is not well structured. Mining XML structural information
for such documents may give important hints on how these documents could be better structured.
To better understand this problem, we will discuss this issue in a real-life application; Structured Product
Labeling (SPL) for FDA drug establishing registration and drug listing [15]. SPL documents contain two
major parts: product data elements and content of labeling. The first part is very well structured and
each data item is assigned to one element. These elements contain essential drug/device information
such as drug name, ingredients…etc. The second part contains the content of product labeling along
with additional machine readable information. Elements in this part contains sections such as adverse
reactions, over dosage, etc. that can be found in regular drug labels. In contrast to the first part, these
sections don’t encompass structured data. The way elements are used in these sections is very similar to
the way HTML elements are used; each component has a text element which contains the whole textual
content of a section. These text elements do not contain any descriptive elements; all elements are
mainly used for browsing proposes. The only elements allowed inside the text element are formatting
elements such as font, color, table, list, etc.
Some of the sections are very important such as adverse reactions and over dosage. For example, a
simple task of listing all the adverse reactions by body system or ingredients cannot be performed in
such unstructured data. Having this sensitive information in human readable format (with no machine
readable descriptive elements) deprives any SPL tools from using XML technologies to retrieve or check
the content of SPL sections. Without the descriptive elements inside labeling sections, it is very hard to
automate any task for processing the data within product labeling sections.
However, elements (which contain no descriptive information) that construct the text element may
contain some important structural information that may be exploited as clues for understanding the
meaning of the data stored in these elements. For instance, the text tag of adverse reactions section
may contain several paragraph elements that represent a structural division such that each paragraph is
dedicated for each body system reaction or for each ingredient affect. . Drug manufactures may be
using similar standards for describing product labeling information within SPL product labeling sections.

Page | 5
Thus, mining structural information of these sections may reveal some patterns that can be useful for
understanding the meaning of the text in these
Figure 1 shows adverse reactions section (a) with its corresponding XML structure (b) as an example of
how structure information could potentially lead to content understanding. Adverse reactions section in
this example is organized human body system such as skin, renal toxicity etc. The structure of this
document could lead to understand text content. As we can see in figure 1 (b) the text element consists
of several paragraph elements; each of which contain a body system part embedded in content
element. Understanding this structure will certainly lead to reveal the content meaning.
In perusing solution for this problem, I first evaluated the most common, and successful, approaches for
clustering XML documents. Unfortunately, and to the best of my knowledge, all these approaches are
developed for XML documents that are based on different XML Schema or DTD. Thus, a new approach
to cluster homogenous XML documents is a necessity.

Page | 6
2. Background
2.1. XML Data Model
Unlike structured databases, XML documents are considered to be semi-structured data that have
flexible structure. Document Type Description (DTD) as well as XML Schema are used to contain the
structure of an XML document. DTD makes use of regular languages to precisely describe a document
structure. XML documents may have no document structure container such as DTD or Schema. In such a
case, XML documents have to be a well formed document that must confirm to XML grammar. In a well-
formed document, all tags must be well parenthesized and the documents must contain a single root
[4].
XML documents can be represented by ordered labeled trees. The root of the documents is the root
node of the tree and tag names corresponds to the labels of the tree nodes. In XML tree, each node may
have any number of children nodes [3].
2.2. XML Structural Clustering
Information extraction, search applications, similarity grouping are some of the applications that require
the use of data mining techniques on XML documents. However, until recent time, mining techniques
were applied to XML documents without considering their structural information. XML documents were
mined based on their content which is treated as bag of text. When excluding structural information,
important data relations and logical information that can be used as meaning clues will be lost [2].
XML structural clustering is one of the most common methods of utilizing XML structural information. It
is defined as the process of grouping XML documents (or sections of documents) based on their
structural similarity. As an example, in information extraction applications, structural information can
help in sorting a large number of different sites’ pages into sets that are comparable. Then software
application can group the set of documents that have similar structure which will help the information
extraction algorithm to produce more accurate results.
2.3. Important definitions
2.3.1. Structured Product Labeling (SPL)
Structured Product Labeling (SPL) is a document markup standard, approved by health level 7
(HL7), that is used by FDA as mechanism of exchanging product information. SPL defines the
content of a drug labeling in an XML format. SPL documents have to adhere to SPL schema that
defines the document structure and format [4].
2.3.2. Homogenous XML documents
Homogenous XML documents are XML documents that adhere to a single XML Schema or DTD
rules. For example, FDA has a database of about 10,000 SPL file that are all based on one single
XML Schema called SPL Schema.

Page | 7
2.3.3. Heterogeneous XML documents
Heterogeneous XML documents are those documents that are based on different XML Schema
or DTD rules. For example, RSS feed XML documents that are generated from different news
agency may have different XML Schemas
3. XML Structural Clustering Approaches In this section, I provide a detailed explanation of how the three major XML structural clustering
approaches, namely: Tree-edit distance, graph-based clustering, and tree-based clustering approaches,
perform structural clustering on XML documents. By understanding how these methods work, we will be
able to study and analyze their shortcomings and limitations on clustering homogenous XML
documents.
3.1. Tree-edit Distance
In order to define tree-edit distance, we first need to define tree-edit sequence. Tree-edit sequence is a
sequence of tree editing operations such as insert-node, delete-node, replace-node and move sub-tree
that transforms one rooted ordered tree to another [6]. To better understand tree-edit sequence, figure
2 presents an example of transforming XML tree ������ by performing delete, insert and replace
operations on ��.
Figure 2: Tree-edit sequence operations - Source [6]
If we have two rooted ordered labeled trees ��and ��,and we have a cost model that assign a fixed cost
for every tree edit operation, then tree edit distance between these two trees “is the minimum cost
between the costs of all possible tree edit sequences that transform ��to ��” [6].
There are several different tree-edit distance algorithms that are all based on dynamic programming
techniques including Selkow’s algorithm [7], Zhang’s algorithm [8], Chawathe’s algorithm [9], and
Chawathe’s algorithm II [10]. All of these algorithms have a common issue which is the high
computational cost that is required to calculate the edit-distance between any two XML trees.

Page | 8
Dalamagasa, T et. al. suggest an efficient tree-edit based algorithm for clustering XML documents by
structure [6]. This algorithm makes use of structural summaries which is a compact tree representation
that reduces node repetition and nesting of the actual XML document tree structure. Figure 3 shows an
example of extracting a structural summary of original XML tree. Tree ��represents a structural
summary of �� after reducing node nesting (��) as well as reducing node repetition (��). The use of
structural summaries, as claimed by the authors, do not affect clustering results and reduces the time
needed to go over the entire XML tree which will increase efficiency and reduce computation time.
Figure 3: XML tree nesting and reputation reduction – Source [6]
Figure 4 illustrates the steps of Dalamagasa algorithm. Initially, each tree in the data set is considered to
be a single cluster. Next structural summaries are created by applying nesting and repetition reduction.
Then process of calculating structural distance between clusters begins. Structural distance between any
two trees ����� is defined as the tree-edit distance between two structural summaries divided by the
cost to delete all nodes from �� and insert all nodes from�� [6]. The clusters with the minimum distance
are merged and the distance between the new cluster and the remaining clusters is recalculated. The
process of merging clusters and recalculating distance between them continuous until clusters reach
some of level of defined quality.
Figure 4: Tree-edit approach for cluster XML document by structure – source [6]
3.2. Graph-based Clustering
For data with no apparent or semi-structured structure, labeled graph are commonly used to represent
the structure of such data [12]. A graph data structure is a set of ordered pairs. Each pair consists of
nodes or vertices and arcs or edges. A graph is denoted by (N,E) where N is the set of nodes and E is the
set of relations where (x,y) ϵ E iff x points to y.

Page | 9
S-GRACE algorithm [11] and Shanmugasundaram et. al. algorithm [13] are two XML Structural clustering
algorithms that utilizes graph for representing XML documents structure and then perform clustering
based on the new graph representation. In this paper, we will focus on S-GRACE algorithm [11] due to
the fact that the structure graphs are extracted from XML documents and not from documents’ DTD as
it is the case in Shanmugasundaram et. al. algorithm [13].
To understand how S-GRACE algorithm works, we first need to define structure graph (s-graph). The s-
graph for a set of XML documents C (denoted by sg(C)) is a directed graph (N,E) where N is the set of all
the elements and attributes in the documents in C and (x,y) ϵ N iff x is a parent element of element y or
y is an attribute of element x in some document in C [11]. To illustrate how s-graph can capture a set of
XML documents structure, Figure 5 presents an example of two XML documents represented by a single
s-graph. The labels in this graph represent the set of nodes in either doc1 or doc2, while the directed
arrows indicate parent-child/element-attribute relationships between nodes in either doc1 or doc 2.
Figure 5: S-graph representation of doc1 and 2 – source [11]
S-graph clustering approach is implemented in two steps: in step one, structural information is extracted
and encoded. In this step, all XML documents are scanned and their corresponding s-graph is computed
then encoded in a data structure called SG. Each SG record consists of two fields: a bit string encoding of
s-graph and a set of XML documents ids of all the documents whose s-graphs are represented by this bit
string [11]. Figure 6 illustrates an example of three XML documents and how they are encoded within SG
data structure. In this example, we can see that doc1 and doc2 are represented by the same bit string as
they have similar structure. Doc3 has its own s-graph as it defers from doc1 and doc2.

Page | 10
Figure 6: SG data structure – Source [11]
Step two involves the creation of clusters based on the structural information of the XML documents
that have been encoded as s-graphs in the previous step. Since s-graphs are encoded as bit strings, the
problem has changed from clustering XML documents to clustering smaller sets of bit strings which
increases efficiency and reduces computation time. For performing clustering over s-graphs, S-GRACE
algorithm is used.
S-GRACE clustering algorithm is a representative categorical algorithm that is considered to be a
hierarchical clustering algorithm on XML documents. It applies ROCK which is a suitable algorithm for
clustering categorical data such as s-graphs. What makes S-GRACE algorithm superior to pure tree-edit
distance algorithms is that it considers common neighbors metric along with distance metric between
clusters. In order to compute common neighbors between any two s-graphs, the distance between each
pair is computed and stored in a matrix called DIST. If the distance between any two s-graph is less than
a threshold Θ, then they are considered to be neighbors. Using the distance matrix (DIST), S-GRACE can
calculate the common neighbors metric. So if two s-graphs share a large number of neighbors, then they
will be merged in one cluster even if they are not close in distance. Link property is used to merge
appropriate clusters’ pairs. Link is defined as following: “for any pair of clusters��, ��, link[��, ��] is the
number of cross links between elements in ��, ���” [11].
3.3. Tree-based Clustering
Tree-based clustering approach is based on the notion of XML cluster representative. Each group of
similar XML documents (XML cluster) will be represented by XML tree that summarizes the most
relevant features of a group of XML documents within a cluster. The most important advantage of
cluster representatives is the compact representation of a group of XML files while retaining the
specifics of all the documents within the cluster it represents. As a result of utilizing cluster
representatives, the overall computation of XML clusters will be reduced due to the fact that the
similarity search is now performed on a much smaller tree (i.e. clusters representatives) and not on the
much larger original XML trees [14].
XRep [14] is one of the algorithms that utilizes the notion of tree-based clustering. This algorithm adapts
a hierarchical approach in clustering XML documents which has proven to result in high quality clusters
[14]. Figure 7 shows an abstract of XRep hierarchical algorithm. First, each XML tree in the set S of XML

Page | 11
trees (��,,,��) is considered as a single tree cluster �� that is represented by the original XML tree. Then
tree-edit distance between each pair of clusters representation is computed and stored in distance
matrix Md. The distance between each pair of clusters is computed by the following formula:
����, ��� � 1 �|�������� ∩ ��������|
max�|��������|, |��������|�
Where �������� is the set of paths in�� , �������� ∩ �������� is the set of common paths between
����� [14]. It is important to notice that the distance is measured based on the similarity on paths
and that duplicated paths are eliminated. Next, the algorithm goes on a loop where the following steps
are performed until an optimal clusters partition is reached:
• Choose pair of clusters, �� and ��, that has minimal distance
• Compute the tree representation r of cluster C which is the union of �� and ��
• Update the set of clusters to reflect the new merge between �� and �� and update the distance
matrix ��
Figure 7: XRep algorithm – Soruce [14]
Computing XML representatives for clusters with two or more trees is the most challenging process in
XRep algorithm. Any approach used to compute cluster summary tree has to be able to include the most
relevant specifications of all documents that a cluster includes while maintaining a compact
representation tree. XML tree matching and merging is the heuristic approach that the notion of cluster
representative relies on. An optimal matching tree is initially built for a given set of XML documents.
Structural resemblances that characterize the original documents are used to build the optimal tree of a
given cluster. Then a merge tree that includes all the characteristics of a cluster is built. The goal of this
tree is to include substructures that are not recurring across the cluster documents. Then the process of
creating a cluster representative starts by pruning the merge tree while keeping the optimal tree as a
measuring level to the lower-bound until the representation tree is extracted.
The pruning approach for computing cluster representatives is conducted in three stages: optimal tree
construction stage, computing merge tree stage and the pruning of the merge tree stage. Before we
explain the first stage, two important notions have to be defined: strong matching and matching tree.
For any two given nodes (u, v), where u∈ ��, v ∈ �� we say that these nodes have strong matching if

Page | 12
node u and v share both the same tag names and depth level. Tree t is a matching tree, denoted by t=
match (�� , ���, if the following conditions hold:
1. Two mappings f1 : t →�� and f2 : t →�� associating nodes and edges in t with a sub-tree in �� and
�� are exists
2. nodes in the matching tree t have strong matching with nodes in �� ���
3. The root of the matching tree is the same root of ����� as well as any edge in the matching
tree
Can be found in �����
Figure 8: (a) Strong matching, (b) multiple matching, (c) matching trees – Source [14]
In stage 1, the process of XML tree matching is used to construct the optimal tree of a cluster. This
process consists of three parts: matching detection, selection of best matching and the construction of
the optimal tree. A matrix �! of |"#$ X "#% | is built where "#$ is the number of nodes in XML tree �� and
"#% is the number of nodes in XML tree��. �! rows represent nodes of �� and its columns represent
nodes of �� (i.e. element (i,j) of �! corresponds to nodes &� ∈"#$ and '� ∈"#%) and stores a weight
'!(&�, '�) that represents the matching between &� and '�. If '!(&�, '�) = 0 then there’s no match
between &� and '�. If '!(&�, '�) = 1 then a strong matching exists. Figure 8 show an example strong (a)
and multiple matching (b) with their corresponding matching trees (c).

Page | 13
Figure 9: Matching and selection matrixes – Source [14]
For selecting the best matching, the weight of each node is calculated by taking into account the
matching of children nodes as well. By doing so, the issue of multiple matching can be overcame by just
considering nodes with high matching weights. A marking vector is used to track the overall best
matching. A marking vector "!� = {j∗&�, . . . , j∗&�}, whose generic i-th entry indicates the node of ��
with which &� ∈"#) has the best matching. "!� [i] is set to −1 for the node &� ∈"#) with no matching
[14]. An example of best matching matrix with its marking vectors is shown in Figure 9 (b)(c).The final
part in stage one is the construction of optimal matching tree which can be simply done by exploiting
the marking vectors by removing all nodes with no matching. Figure 10 (a) shows the resulted optimal
matching tree of the two XML trees in Figure 9 (a).
Figure 10: (a) Optimal matching tree, (b) Merge tree, (c) Cluster representative – Source [14]

Page | 14
In stage two, the computation of a merge tree is done. Merge trees resemble the idea of optimized
union. In its simplest form, a merge tree could be the union of two trees. However, to avoid duplicate
nodes, optimal matching tree, computed in stage 2, must be used to avoid adding duplicated nodes. A
merge tree is simply the optimal tree plus the nodes that has no matching in either tree plus the nodes
that have multiple matching. Going back to Figure 10 (b), we see that the merge tree is the optimal tree
plus nodes with no matching from t1 and t2 (8, 11 from t1 and 9, 10, 11 from t2), plus nodes with
multiple matchings from t1 and t2 (nodes 2, 5 from t1 and 8 from t2).
Now with optimal matching tree and merge tree are ready, the final stage of creating a cluster
representative is ready to begin. In this stage, nodes are removed from the leaf level of the merge tree.
Each time a node is removed, the distance between the refined merge tree and the original trees in the
cluster is calculated. The process of removing nodes stops when the distance between the refined
merge tree and the original XML trees on the cluster cannot be further decreased. At this point, the
cluster representative is the final version of the refined merge tree.
Cluster representative is used to compare the cluster with other clusters and merge clusters that have
similar structure as described in XRep algorithm above. If any new cluster added to the cluster, the
cluster representative has to be updated to reflect the new merged cluster(s).
4. Why a New Approach is needed for Clustering Homogenous XML
Documents
4.1. Losing important structure information
Tree-edit distance
One of the major advantages discussed in algorithm [6] is the introduction of structural summaries
to calculate tree-edit distances between XML trees. The use of structural summaries improves tree-
edit algorithm efficiency by decreasing computation time as the algorithm will perform pair-wise
comparisons on much smaller trees. Structural summaries also provide more accurate clustering
results due to the removal of nesting and repetition in original trees. However, all these claims make
sense only when tree-edit algorithm is applied to a set of heterogynous XML documents.
Dalamagasa,T. et. all state that “A tree edit algorithm will output a large distance between two XML
documents which are based on the same DTD, with one of the two being quite long due to many
repeated elements.” [6] As we explained in the problem statement section above, our problem is to
find structural similarities in homogenous XML documents- XML documents that share the same
XML Schema (or DTD). By removing nodes repetition and nesting, homogenous XML documents will
lose essential and very important structural information that could significantly help in the process
of clustering those documents.
To better understand this issue, we will apply the structural summaries notion on selected section of
actual SPL documents. Figure 11 shows adverse reactions sections for two different SPL documents.
Adverse effects information for “SPL Doc 1” is stored with no specific structure in one paragraph tag.

Page | 15
For “SPL Doc 2”, there are seven paragraphs under the text tag which could potentially mean that
adverse effects section may contain important structural hints.
Figure 11: Adverse effects sections from two different SPL documents
However, when we create the structural summary for “SPL Doc 1” (the same as the original tree as
there’s no repetition or nesting within this document) and “SPL Doc 2”, we notice that the later will
have exactly the same structural summary of “SPL Doc 1” (Figure 12 shows the trees of SPL doc 1
and 2 along with the resulted structural summary of “SPL doc 2”). As a result, the two documents
will be later added to the same cluster by the clustering algorithm even though SPL Doc 2 has more
structural information that makes it structurally different from “SPL Doc 1”. Important structural
information of doc 2 was lost in the node repetition reduction, which is a part of structural summary
building process, was applied to this document tree.
Figure 12: Applying reputation reduction in SPL Doc 2
Graph-based clustering
The first stage in S-GRACE algorithm is the extraction of s-graphs from XML trees. S-graph encodes
nodes’ parent-child relationships of all nodes in an XML tree as edges. All Edges repetition is not
Page | 16
considered in the SG data structure. The aim of repetition removal is to make s-graphs as small as
possible for efficient pair-wise comparison that will be later performed on these s-graphs. However,
and similar to tree-edit approach issue, the removal of edge repetition will result in removal of
sensitive structural information that significantly affects clustering homogenous XML documents.
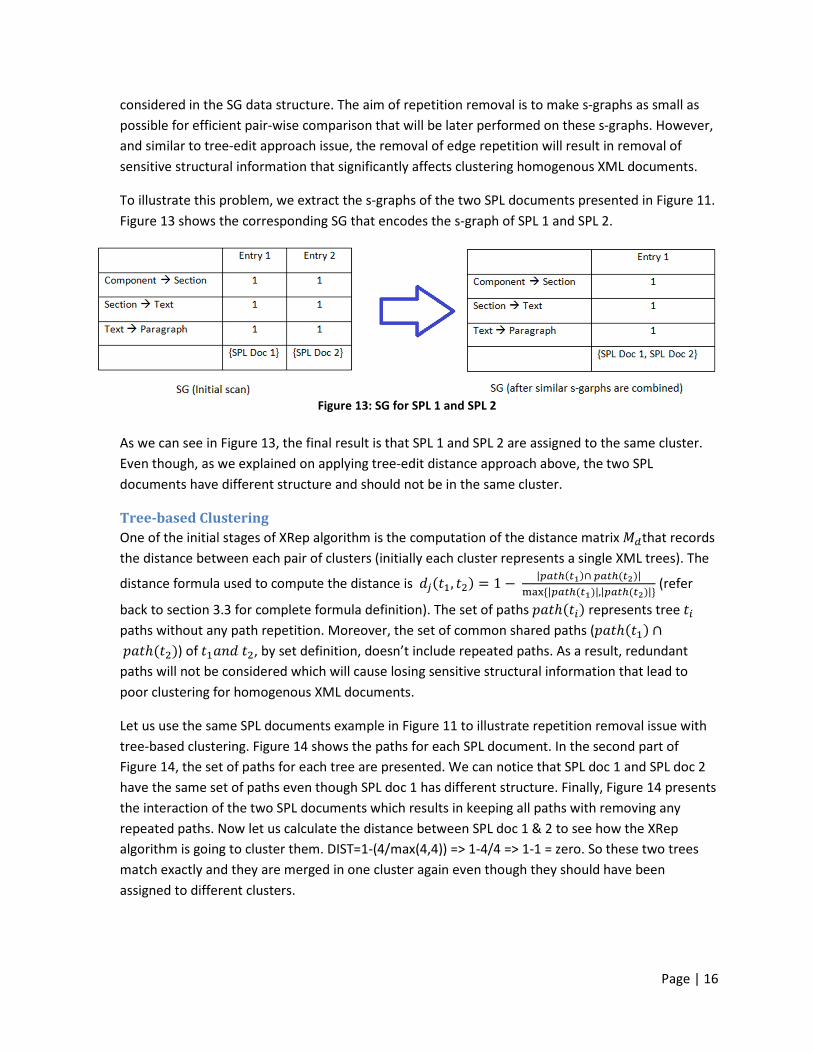
To illustrate this problem, we extract the s-graphs of the two SPL documents presented in Figure 11.
Figure 13 shows the corresponding SG that encodes the s-graph of SPL 1 and SPL 2.
Figure 13: SG for SPL 1 and SPL 2
As we can see in Figure 13, the final result is that SPL 1 and SPL 2 are assigned to the same cluster.
Even though, as we explained on applying tree-edit distance approach above, the two SPL
documents have different structure and should not be in the same cluster.
Tree-based Clustering
One of the initial stages of XRep algorithm is the computation of the distance matrix ��that records
the distance between each pair of clusters (initially each cluster represents a single XML trees). The
distance formula used to compute the distance is ����, ��� � 1 �|*+#,�#)�∩*+#,�#-�|
./0�|*+#,�#)�|,|*+#,�#-�|� (refer
back to section 3.3 for complete formula definition). The set of paths �������� represents tree ��
paths without any path repetition. Moreover, the set of common shared paths (�������� ∩
��������) of�����, by set definition, doesn’t include repeated paths. As a result, redundant
paths will not be considered which will cause losing sensitive structural information that lead to
poor clustering for homogenous XML documents.
Let us use the same SPL documents example in Figure 11 to illustrate repetition removal issue with
tree-based clustering. Figure 14 shows the paths for each SPL document. In the second part of
Figure 14, the set of paths for each tree are presented. We can notice that SPL doc 1 and SPL doc 2
have the same set of paths even though SPL doc 1 has different structure. Finally, Figure 14 presents
the interaction of the two SPL documents which results in keeping all paths with removing any
repeated paths. Now let us calculate the distance between SPL doc 1 & 2 to see how the XRep
algorithm is going to cluster them. DIST=1-(4/max(4,4)) => 1-4/4 => 1-1 = zero. So these two trees
match exactly and they are merged in one cluster again even though they should have been
assigned to different clusters.

Page | 17
Figure 14: Clusters distance calculation using tree-based algorithm
4.2. Expensive computation time
Tree-edit distance
In tree-edit distance approach, each XML tree has to be compared to all the other documents in the
set of documents that needs to be clustered. Mathematically, [N * (N – 1) / 2] comparisons have to
be performed to calculate tree-edit distance between all documents in a set of N documents. The
FDA database contains over 12,000 SPL documents and the number is increasing periodically [5].
This means that to cluster SPL documents using tree-edit approach, we approximately need to
perform [10000*9999/2] = 49,995,000 comparison operation. As stated in [6], the average time to
compare original SPL tree (structural summaries are not appropriate for homogenous documents as
discussed above) is 700 milliseconds (ms). To find the time it takes to compare all these documents
we first multiply the number of comparisons operations with the time it takes to perform single
comparison operation (49,995,000 * 700ms) which is equal to 34996500000 ms. This means that it
will take about 13.5 months to finish all SPL pair-wise comparisons
4.3. Poor quality Clusters for homogenous XML documents
S-graph-based Clustering
S-GRACE algorithm was developed to find similarities in XML documents from different sources
(documents with different DTDs or XML Schemas). It measures similarities by calculating how many
common edges a pair of s-graphs may have. Thus, it considers that two s-graphs should be placed in
two different clusters, if they have few overlapping edges (which means that fewer path expressions
can be answered by both XML trees). However, this notion is valid for only heterogeneous XML trees

Page | 18
and not homogenous ones. In measuring distance between any two given s-graphs, if we consider
that similarity is only based on how many common edges both are sharing, and keeping in mind that
edges are representing a node parent-child relationships and not full XML paths (no repetition nor
nesting is represented in s-graphs), then documents that adhere to one XML Schema or DTD will
mostly be place in a one cluster.
The results of the experiment that I’ve performed on a sample of SPL files support this finding. S-
GRACE was manually tested on a selected set of SPL documents. To simplify this experiment, I’ve
focused only on adverse effects section of the SPL document. Out of 20 SPL documents, only three
clusters were generated. 18 of which were assigned to the first cluster that contains all documents
with the following edges: Component � Section, Section � text, text � paragraph. The second
cluster contains one SPL document that has same edges as cluster one with the extra edge text �
table. The third cluster also has only one SPL document. This cluster contains similar edges as cluster
one along with Section � excerpt, excerpt � highlight, and highlight � text edges (see Figure 15).
After computing distance between each pair of clusters, cluster 1 and 2 was merged in one cluster.
Even though the 18 SPL documents in the first cluster have different structures, S-GRACE algorithm
has assigned them all to the same cluster just because they share the same set of nodes.
Figure 15: SG data structure before and after merging similar SPL clusters
Tree-based Clustering
Taking off path repetition in computing distance metric will result in computing major structural
differences that mainly come from differences in XML Schema or DTD that define these documents.
So, if two XML trees represent XML documents from the same XML Schema or DTD, then the
distance between these trees will be very close and will be assigned to the same cluster. This issue
will result in few clusters that do not actually contain significant structural differences for
homogenous XML documents.
5. Proposed Abstract Solution: Signature-based Clustering As discussed in the above sections, current clustering approaches are designed for XML documents that
are based on different XML Schemas or DTDs. In calculating heterogeneous XML documents’ clusters,
the structural information that is considered irrelevant could be very sensitive information that may
have significant impact on the quality of homogenous XML documents clusters. Thus, for XML
documents with a single schema, as the case with SPL documents, different approaches have to be
implemented.

Page | 19
In this section, I propose an abstract design of novel approach for clustering homogenous XML
documents. I call this approach signature-based clustering (SBC). SBC approach is a staged approach that
utilizes human inputs to refine the resulted clusters. Initially, structural summaries of each XML
document will be extracted in the first stage. These summaries do not include irrelevant XML elements
as well as the text content of each element. These summaries are then stored in a data structure called
SS, that contains three fields: a reference ID, file name of the actual XML document (XML document
name) and a field that contain the structural summary stored as an XML document. In stage two, quick
and poor quality clusters that are based on summaries of XML documents’ structure generated in stage
one are calculated and presented to the user with some samples of the actual XML files that each cluster
represents. The user decides which clusters are relevant and which are not and provide some
description that will be later used to refine clusters. In stage three, irrelevant clusters will be removed.
Then each remained cluster will be further refined by mining the text content of the actual documents
within this cluster for more clustering hints based on user inputs. Figure 16 show a detailed illustration
model for SBC approach.
Figure 16: Signature-base Clustering Model
5.1 Stage 1: Extracting XML Structural Summary
In order to perform quick clustering over a large set of XML documents, it is better to perform clustering
process over XML tree summaries and not the original trees. However, in extracting structural
summaries, neither node repetition nor nesting is removed. Only irrelevant elements and element text
content are removed (XQuery code used to extract structural summaries from SPL documents can be
reviewed in appendix A). The following figure shows a pseudo-code for stage one.

Page | 20
Figure 17: Stage one: Extracting XML Structural Summary
Next, structural summaries are stored in a data structure called SS. The importance of this data structure
is to link each summary to its original XML document. Each record is SS consists of three fields: doc_id
which is used as a reference to XML document and its structural summary, doc_name which stores the
original XML document name, and finally struct_summ in which structural summary is stored as XML
document. Figure 18 shows an example of SS data structure with one record for books.xml document
and its summary.
Figure 18: SS data structure
5.2 Stage 2: Performing initial signature-based clustering
In this stage, a preliminary clustering is performed over structural summaries that are stored in SS. The
clustering approach used here is signature-based clustering that is aimed to reduce the number of pair-
wise comparisons between structural summaries. For each summary, a signature is calculated and
immediately searched on the signature tables. In case the signature was found, the current structure
summary is assigned to the group of summaries that this signature represents. If it was not found, a new
entry in the signature table is created for this new signature and the current summary will be the first
document to be assigned to this group. The signature table is a data structure that contains all unique
signature discovered after scanned all XML documents in the set of documents to be clustered. Each
record consists of sign_id field that contains a reference id to the signature record, signature field which
contains the actual signature, and the sign_grp which stores the set of documents (doc_ids from SS file)
with the same signature.

Page | 21
Figure 19: Stage two - Signature-based structural clustering
The resulted clusters are presented to the user at the end of stage two. Along with the resulted clusters,
some examples of original XML documents of each cluster are presented to the user for better
evaluation as well as to facilitate decision making process on what clusters make sense and what are
not.
5.3 Stage 3: Refining clusters based on user input
As we previously discussed in the problem statement section, clustering process for homogenous XML
documents depends on the application. The user feedback is very important to help SBC algorithm learn
what the user is looking for. The user inputs consists of two parts: the first part is a simple yes or no
answer to the question of “Is this cluster make sense?” The second part is that user can refine some of
the clusters by adding key words or patterns that will assist the algorithm in optimizing clusters’ quality.
Stage three consists of two steps: in the first step, user inputs are used for filtering all the irrelevant
clusters from the signature table. In step two, the second part of the user inputs, key words and/or
patterns, is utilized for mining the text content of the original XML files. This process combines structural
and textual mining for tuning clusters quality. Accepted clusters from stage two may be split, joint or
even deleted as a result of the tuning process in stage three. The final clusters are then presented to the
user at the end of this stage. Figure 20 shows the pseudo-code that summarizes stage three.
Figure 20: Stage three: Refining clusters based on user input

Page | 22
6. Conclusion and future work
The main aim of this research is to shade the light on the problem of clustering homogenous XML
documents and provide guidelines for how the solution of this problem could be implemented.
Signature calculation algorithm is the essence of signature-based clustering that defines the quality of
produced clusters. As a continuation of this work, an effective signature calculating algorithm should be
implemented. Next, signature-based methodology should be evaluated using SPL documents and
validated by some manually inspected samples.
To the best of my knowledge, there is no clustering methodology that clusters homogenous XML
documents based on their structural information. I have shown that the conventional clustering
algorithms don not produce accurate results when tested with XML documents that based on single
XML Schema or DTD. Thus, a new approach for clustering homogenous XML documents must be
implemented using different techniques and methods from the ones that are used in clustering
heterogeneous XML documents. In our research, we suggest a schema design for a methodology,
signature-based clustering, that is aimed to solve this issue. This new approach is a semi-automated
approach that utilizes human inputs to refine the quality of computer-generated clusters.

Page | 23
References
[1] Hunter, D. et al. (2007). Beginning XML. Wiley Publication. 4th
edition. pp. 4-20.
[2] Buttler, D. (ND). A Short Survey of Document Structure Similarity Algorithms. Lawrence Livermore
National Laborator.
[3] Nierman, A. and Jagadush, H. (ND). Evaluating Structural Similarity in XML Documents
[4] Candillier, L. et al. (2008). Mining XML documents.
[5] FDA. (Feb. 2011)
http://www.fda.gov/ForIndustry/DataStandards/StructuredProductLabeling/default.htm
[6] Dalamagasa, T. et. al. (2004). A methodology for clustering XML documents by structure. Elsevier.
Information Systems 31 (2006) 187–228
[7] S.M. Selkow, The tree-to-tree editing problem, Inform. Process. Lett. 6 (1977) 184–186.
[8] K. Zhang, D. Shasha, Simple fast algorithms for the editing distance between trees and related
problems, SIAM J. Comput. 18
(1989) 1245–1262.
[9] S.S. Chawathe, A. Rajaraman, H. Garcia-Molina, J. Widom, Change Detection in Hierarchically
Structured Information, in:
Proceedings of the ACM SIGMOD Conference, USA, 1996, pp. 493–504.
[10] S.S. Chawathe, Comparing hierarchical data in external memory, in: Proceedings of the VLDB
Conference, Edinburgh, Scotland,
UK, 1999, pp. 90–101.
[11] Wang, L; Cheung, DWL; Mamoulis, N; Yiu, SM. (2004). An efficient and scalable algorithm for
clustering XML documents by structure. IEEE Transactions on Knowledge & Data Engineering. v. 16 n. 1,
p. 82-96. Retrieved from http://hdl.handle.net/10722/43670
[12] Buneman, Peter. Davidson, Susan. Fernandez, Mary. Suciu, Dan. (1997) Database Theory: Adding
structure to unstructured data. Springer Berlin / Heidelberg. Pp. 336-350 v. 1186. Retrieved from
http://dx.doi.org/10.1007/3-540-62222-5_55
[13] J. Shanmugasundaram, K. Tufte, G. He, C. Zhang, D. DeWitt, and J. Naughton, (1999). Relational
Databases for Querying XML Documents: Limitations and Opportunities,” Proc. 25th Int’l Conf. Very
Large Data Bases, pp. 302-314.
[14] Gianni Costa, Giuseppe Manco, Riccardo Ortale, and Andrea Tagarelli. (April 2004). A Tree-based
Approach to Clustering XML Documents by Structure
[15] FDA, “SPL Implementation Guide for FDA Drug Establishment Registration and Drug Listing v2.0”,
ND.
(http://www.fda.gov/downloads/ForIndustry/DataStandards/StructuredProductLabeling/UCM162024.p
df)

Page | 24
Appendix A: XML Summary Extractor Code


















