Cluj meetup bigdata-final-version
19
Cluj – Timisoara – Bucharest => Big Data meetup group Cluj-Romania March 2015 Apache Spark The next level for data processing Radu MOLDOVAN
-
Upload
moldovan-radu-adrian -
Category
Data & Analytics
-
view
10.902 -
download
0
Transcript of Cluj meetup bigdata-final-version

Cluj – Timisoara – Bucharest => Big Data meetup group
Cluj-Romania March 2015
Apache SparkThe next level for data processing
Radu MOLDOVAN

About me
20 years of programming mostly with open source projects
last 3 years worked in Big Data
team lead@ building the 5th generation of
xPatterns Platform
mail: [email protected], skype: r.moldovan

Content
- modules- programming model (RDDs)- architecture - Spark & Mesos (cluster Resource Manager) - demo (Spark Core + Spark SQL - Scala code)
Spark experience [0.8.0 → 1.2.0]
Source: spark.apache.org/

SPARK - introduction
- started in 2009 by Matei Zaharia at Berkeley AMPLab (Ion Stoica)- cluster computing platform (scalability & flexibility)- in-memory data processing for large datasets- best alternative for Hadoop Map-Reduce, compatible with Hadoop eco-system(HDFS & fileFormat)

Core: Scala, Java, PythonStreaming: real-time streams processingSQL: structured data and queriesMLlib: built-in machine learning libraries GraphX: graph processing
SPARK - modules

SPARK – programming modelRDDs (Resilient Distributed DataSet)
- distributed and immutable collection of items + fault tolerance(auto rebuild on failure)
- create RDDs (from files(HDFS/Tachyon), parallelize data, from other RDDs)
- persistence (MEMORY_ONLY*, MEMORY_AND_DISK*, DISK_ONLY, OFF_HEAP)
Operations (much more than map-reduce) – more than 80
- Transformation(new RDDs):
map, filter, join, distinct, union, intersection, groupByKey, reduceByKey
- Actions(data on driver):
count, collect, foreach, reduce(func), first, saveAs{Text, Sequence,Object}File
!!! nested RDDs are not supported
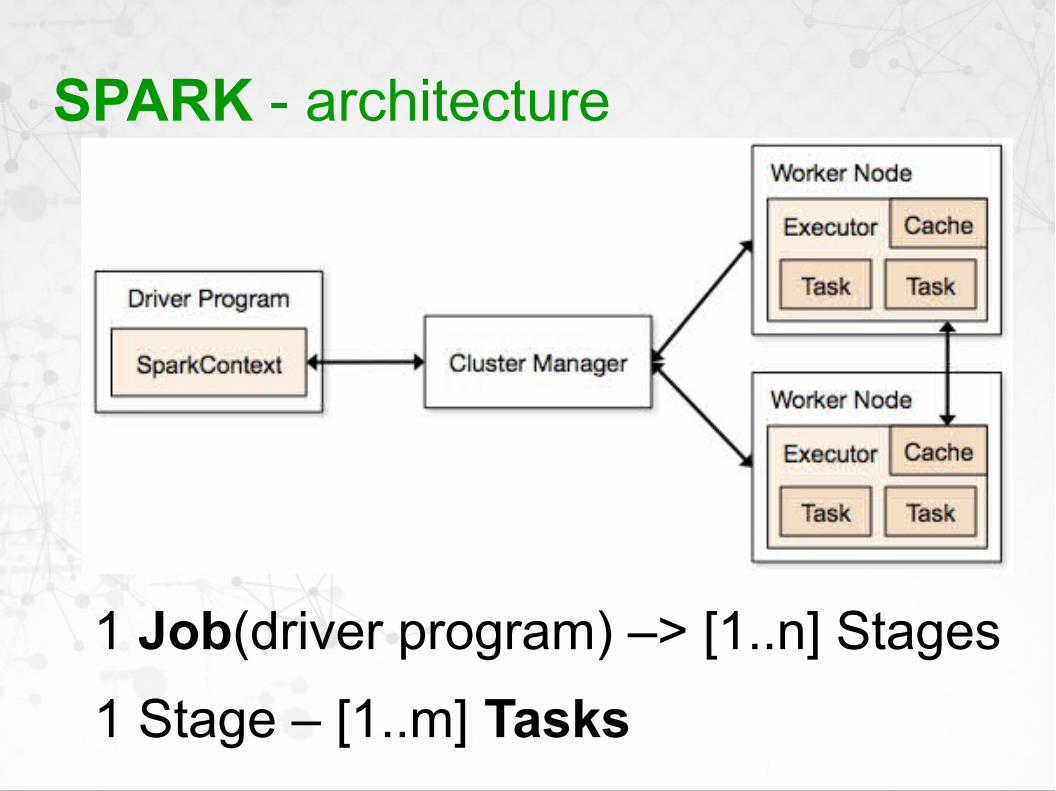
SPARK - architecture
1 Job(driver program) –> [1..n] Stages
1 Stage – [1..m] Tasks
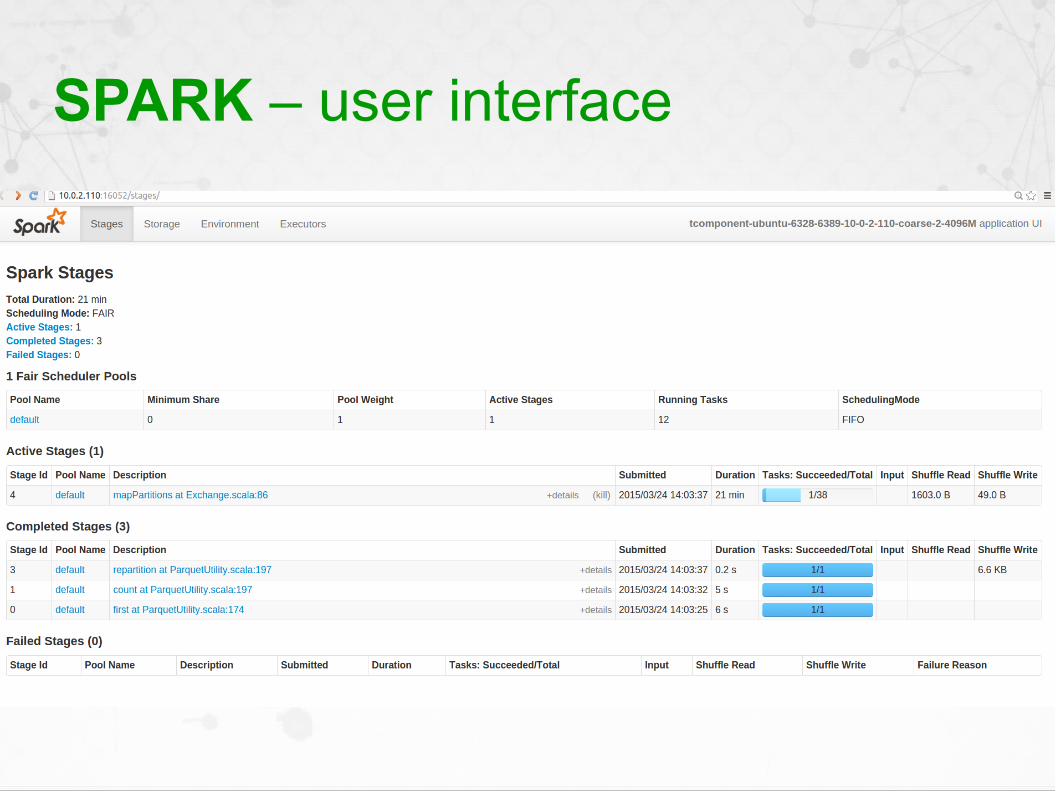
SPARK – user interface

SPARK – Core - demo part 1

SPARK – Core – demo part 2

SPARK – Core – demo part 3

SPARK – SQL – demo part 1

SPARK – SQL – demo part 2

SPARK – SQL – demo part 3

SPARK – with Mesos (part 1)

SPARK – with Mesos (part 2)

0.8.0 - first POC … lots of OOM0.8.1 – first production deployment, still lots of OOM 20 billion healthcare records, 200 TB of compressed hdfs data, ¾ PB of uncompressed data Hadoop MR: 100 Amazon instances - m1.xlarge (4cores x 15GB RAM x 2-4TB HDD) Daily processing reduced from 14 hours to 1.5 hours!
0.9.0 - fixed many of the problems, but still requires patches! spilling on the reducer side fixed (less OOM)
1.1.0 & 1.2.0 extensive usage of SchemaRdds, Rows & Parquet file format
1.3.0 – just released this year
SPARK experience [0.8.0 → 1.2.0]

…what's next for Bigdata meetup?ContributorsJaws, xPatterns http spark sql server!
Restful service for running Spark SQL/Shark queries on top of Spark - Spark 0.9.1 with Shark - Spark 1.0.1, 1.0.2, 1.1.0 and 1.0.2 with SparkSQL as backend framework. Backend in spray io (REST on Akka) http://github.com/Atigeo/http-spark-sql-serverSpark Job Server solves inability to run multiple Spark contexts from the same JVM multiple Spark contexts with distinct JVM
job submission in Java + Scala https://github.com/Atigeo/spark-job-rest
… BIG thank you!!!