
Cloud Storage: All your data belongs to us! Theo Benson This slide includes images from the...
28
Cloud Storage: All your data belongs to us! Theo Benson This slide includes images from the Megastore and the Cassandra papers/conference slides
-
Upload
robert-jacobs -
Category
Documents
-
view
219 -
download
0
Transcript of Cloud Storage: All your data belongs to us! Theo Benson This slide includes images from the...

Cloud Storage:All your data belongs to us!
Theo Benson
This slide includes images from the Megastore and the Cassandra papers/conference slides

Outline
• Storage review
• Workload
• Cassandra [FB]– High reads, high writes
• Megastore [Google]– High reads, low writes

NoSQL vs. RDBMS
• NoSQL (Bigtable, HBase, Cassandra)– Pros:
• Highly scalable• Highly available
– Cons:• Lean with few features put/get of keys
– Bad schema, query, limited API
• Eventual consistency loose consistency

NoSQL vs. RDBMS
• RDBMS (mysql, sql-server)– Pro:
• Very mature and well understood,• Strong consistency strong transactional semantics
– Cons:• Hard to scale takes lots of time• Synchronous replication may have performance and
scalability issues• may not have fault tolerant replication mechanisms‐

Motivation• Existing solutions not sufficient
• NoSQL vs. RDBMS
• Goal: (Software Storage)– global, – Reliable,– arbitrarily large in scale
• Reality: (hardware system)– geographically confined, – failure-prone, – suffer limited capacity.

Building Blocks for Storage
– Commodity server• limited resources• Fails quite easily• Quite Cheap
– Geodistributed data centers• Many servers• Potential for low latency

Big Data Wants …
• Best of both worlds• Highly scalable good performance!• Highly available fault tolerant• Very mature and well understood,• Strong consistency strong transactional semantics
• What is good performance? (Difference in workloads)– Read-heavy: search– Read/Write heavy: social networks

Outline
• Storage review
• Workload
• Cassandra [FB]– High reads, high writes
• Megastore [Google]– High reads, low writes

Motivation
• online services should be highly scalable (millions of users)
• responsive to users• highly available• provide a consistent view of data (update
should be visible immediately and durable)• it is challenging for the underlying storage
system to meet all these potential conflicting requirements

Workloads
Facebook• Personalized data is localized
• Delay in page load time is somewhat acceptable
• Who will you use?– MySpace?
• Constantly updating and reading– Scope is localized– High reads/high writes
Google• Same data used by
everyone
• Delay in load is unacceptable
• Index once, many infinite times– High reads/low writes

Outline
• Storage review
• Workload
• Cassandra [FB]– High reads, high writes
• Megastore [Google]– High reads, low writes

System Architecture
• Partitioning: provides high throughput– How data is partitioned across nodes?
• Load balancing• Overcome failures
• Replication: overcome failureHow data is duplicated across nodes
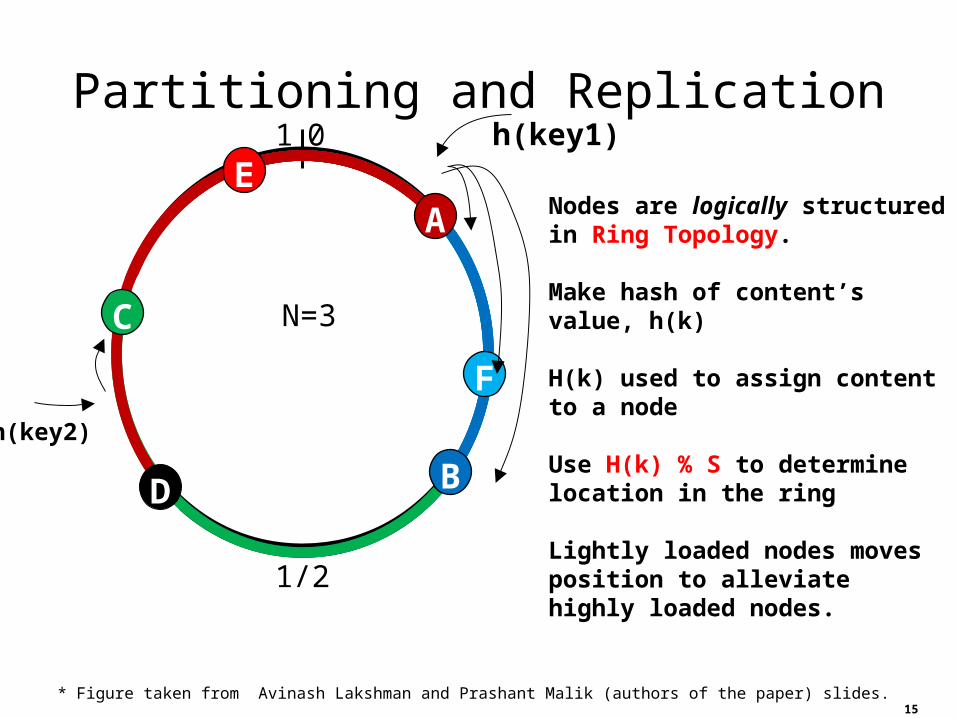
Partitioning and Replication01
1/2
F
E
D
C
B
A
N=3
h(key2)
h(key1)
15* Figure taken from Avinash Lakshman and Prashant Malik (authors of the paper) slides.
Nodes are logically structured in Ring Topology.
Make hash of content’s value, h(k)
H(k) used to assign content to a node
Use H(k) % S to determine location in the ring
Lightly loaded nodes moves position to alleviate highly loaded nodes.

Challenges with Partition scheme
• Partition doesn’t account for– Load imbalance (some items are more popular)– Key imbalance (items aren’t evenly distributed to
keys)• How to solve this?
– Have a node appear in multiple locations– Move lightly loaded nodes in the ring

System Architecture
• Partitioning: provides high throughputHow data is partitioned across nodes?What do we want from a good partition algorithm?
• Replication: overcome failureHow data is duplicated across nodes?

System Architecture
• Partitioning: provides high throughputHow data is partitioned across nodes?What do we want from a good partition algorithm?
• Replication: overcome failure– How data is duplicated across nodes? Challenges:
• Consistency issues• Overhead of replication

Replication
• Each data item is replicated at N (replication factor) nodes.
• Different Replication Policies– Rack Unaware – replicate data at N-1 successive nodes after its
coordinator– Rack Aware – uses ‘Zookeeper’ to choose a leader which tells
nodes the range they are replicas for– Datacenter Aware – similar to Rack Aware but leader is chosen at
Datacenter level instead of Rack level.
• Why??

Local Persistence
• Relies on local file system for data persistency.
• Write operations happens in 2 steps– Write to commit log in local disk of the node– Update in-memory data structure.
• Read operation– Looks up in-memory ds first before looking up files on disk.– Uses Bloom Filter (summarization of keys in file store in memory)
to avoid looking up files that do not contain the key.

Read Operation
Query
Closest replica
Cassandra Cluster
Replica A
Result
Replica B Replica C
Digest QueryDigest Response Digest Response
Result
Client
Read repair if digests differ
* Figure taken from Avinash Lakshman and Prashant Malik (authors of the paper) slides.

Failure Detection
• Traditional approach– Heart-beats (Used by HDFS & Hadoop): binary (yes/no)– If you don’t get X number of heart beats then assume failure
• Accrual failure approach– Returns a # representing probability of death
• X of the last Y messages were received: (X/Y)*100%
– Modify this # to reflect N/W congestion & server load– Based on the distribution of interarrival times of update
messages• How would you do this?

Outline
• Storage review
• Workload
• Cassandra [FB]– High reads, high writes
• Megastore [Google]– High reads, low writes
• Storage in the Cloud– HDFS in VMWare

HDFS (also GFS)
• A version of NoSQL
• Provides get/put API
• Optimized for high read throughput – Uses replication
• Bad write performance!

Contribution
• Overcome limitations by Combining NoSQL w/ RDBMS
• Partition High throughput + Scale:– Partition data-space into a number of distinct little DBs
• Replicationlow-latency+Fault tolerance:– Replicate each little DB across the world
• Optimizes latency Optimize for long links
– synch fault tolerant log system (Paxos)
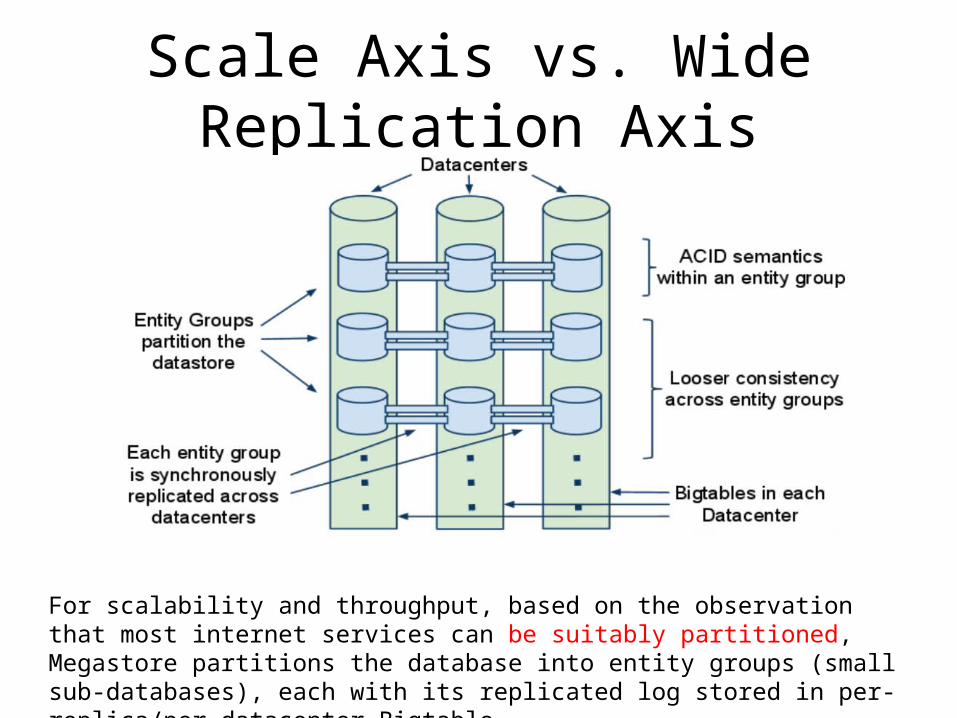
Scale Axis vs. Wide Replication Axis
For scalability and throughput, based on the observation that most internet services can be suitably partitioned, Megastore partitions the database into entity groups (small sub‐databases), each with its replicated log stored in per replica/per datacenter Bigtable.‐ ‐

More Features
• Enriches traditional GFS/HDFS– Adds rich primitives: e.g. ACID transactions,
consistency– Simplifies application development
• Biggest challenge is consistency across replicas

Consistency
• Recall, read and write can be simultaneous
• Different read consistency: trade-off time V consistency– Current read– Snapshot read– Inconsistent read

Distributed Storage Side by Side
Cassandra• Facebook
– High throughput reads– Focus on within a datacenter
• NoSQL
• Partition throughput– Scales
• Replication– Fault tolerance
Megastore• Google
– High throughput reads– Low latency writes
• NoSQL+RDBMS
• Partition throughput– scales
• Replication low latency– Fault tolerance

Questions











![Megastore: Providing Scalable, Highly Available Storage ... · Apache Hadoop’s HBase [1], or Facebook’s Cassandra [6] are highly scalable, but their limited API and loose consis-tency](https://static.fdocuments.us/doc/165x107/5ecd583c539fc95edb18eb4e/megastore-providing-scalable-highly-available-storage-apache-hadoopas-hbase.jpg)





