

Cloud, Services and You Na 2 SO 4 Conference, Kirkland, WA, 09/30/2012 Denis Altudov, Eugene Bobukh,...
22
Cloud, Services and You Na 2 SO 4 Conference, Kirkland, WA, 09/30/2012 Denis Altudov, Eugene Bobukh, Konstantin Erman, Eugene Nonko, Margarita Rita Otto, Michael Rayhelson
-
Upload
anthony-small -
Category
Documents
-
view
212 -
download
0
Transcript of Cloud, Services and You Na 2 SO 4 Conference, Kirkland, WA, 09/30/2012 Denis Altudov, Eugene Bobukh,...

Cloud, Services and You
Na2SO4 Conference, Kirkland, WA, 09/30/2012
Denis Altudov, Eugene Bobukh, Konstantin Erman, Eugene Nonko, Margarita Rita Otto, Michael Rayhelson

Moving to the Cloud

Moving to the Cloud: Trends
• More and more “traditional” software sees “cloud” version counterparts or replacements– Streets & Trips (example on the next page) -> Google Maps, Bing Maps– MS Office -> Office 365, Google Docs– Winamp, Windows Media Player -> Amazon cloud player (no download by default)
• Action item: if two people buy the same MP3 on Amazon, will there be any difference in files detected?
• Patterns observed– Client versions for most co-exist now, but not sure for how long that would continue– Cloud software often requires sign-in/registration for all but the most basic operations– Client-side data storage processing, organizing, search are often absent or rudimentary
• Vendors’ motives– Cut the costs & lags for patching and updates (no need to distribute them to millions of boxes)– Ease support by data collection and analysis– Reduce piracy: as software is in provider’s cloud, they can check or revoke the license at any moment– Reduce abuse by increased control (e.g., can easily ban spammers)– Not the lack of CPU power: CPU demand in most end user’s tasks did not grow much since ~2000– Not really one-to-many communication problems (e.g., blogs, forums, sharing services)– (Somewhat) Many-to-many interaction scenarios (e.g., Spotify)
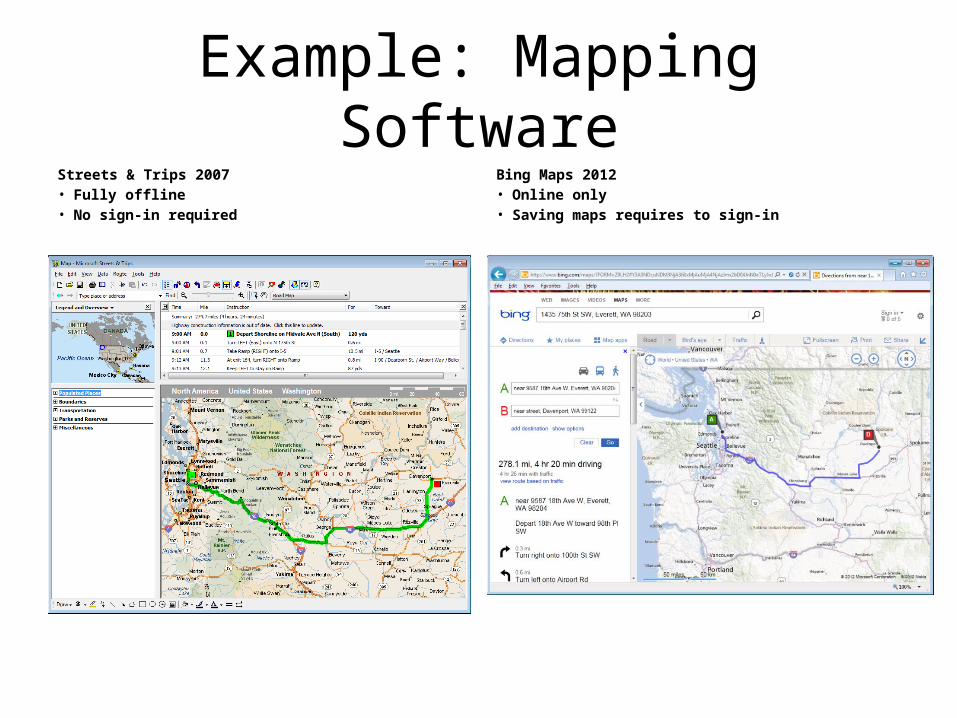
Example: Mapping SoftwareStreets & Trips 2007• Fully offline• No sign-in required
Bing Maps 2012• Online only• Saving maps requires to sign-in

Moving to the Cloud: Customer Concerns
• Your data access is subject to maintaining good relationship with your Cloud Providers– They decide whether you violated the License Agreement– They have the switch to cut off your access – instantly– Any gray area doubt is not to your benefit
• You don’t really know who else reads your data– Government? Hackers? Employees?– [Yes, same for home machines to some degree]
• Possible disappearance of client (offline) software– Even if you back up all your files, what would you do if most devices
won’t be able to view, edit, search them standalone?– Will Surface or iPad have Office, Visual Studio, Audacity, Photoshop on
them in 5-10 years?

Moving to the Cloud: Solutions?1. Resist the move?
– …and miss all the opportunities and connections? – Not really a solution. “Resistance is futile!”
2. Encrypt everything? Mostly won’t help:– Forget “cumbersome”. For data to work, it needs to be effectively shared. To
be shared, it needs to be decrypted. Over.– Complex shared PKI structures might solve that… but that’s like rebuilding a
new social network from scratch.
3. Make local backups of all your data? Definitely helpful:– Issue1: cloud formats change rapidly and non-transparently. Yes, you can
export all your Gmail, but only Gmail will be able to fully read back that data!– Data Liberation Front group in Google works to ease this issue.– Issue2: even “traditional” formats work only while legacy editing software is
available– Denis Altudov: it will be available for at least the next 5-15 years via
JavaScript virtual machines, and due to the necessity to preserve thick OS layer in most hardware since devices will remain primarily occasionally connected for the next 5-10 years, for commercial reasons such as bandwidth overbooking and political such as towers fears

Moving to the Cloud: Solutions?1. Choose only those Cloud Providers that provide certain guarantees? In the ideal world, that would be:
1. A promise to always keep all your data encrypted: questionable2. A promise to never deny you access to your data: questionable (legal, etc.)3. A promise of one-click “get me all my data in a ZIP file”: must have4. 100% transparency to what’s stored: unlikely5. 100% control over what’s stored: very unlikely6. No sign-in for operations that don’t need it by their nature: questionable7. …and if all met, then, well, how about a holy halo?
2. Clearly the above won’t work. So how about a relaxed & reworked version?1. Provider must expose all stored data for offline backup, in formats open for parsing2. Provider must demonstrate good culture and attitude towards user’s security & privacy
1. Action item: build a checklist for Provider’s assessment
3. Build your own cloud? Not as crazy as may seem:1. Denis Altudov has very interesting proprietary ideas.
4. Switch to Linux? Should be explored as a backup parachute:1. GPL v3 is essentially anti-Cloud2. Certainly that society cares about their data security and ownership more than of a direct profit3. Client-oriented software is commonly built for most day-to-day operations4. Issue: often poorer quality of many software (no profit driver!)5. Issue: some services are essentially of a Cloud nature, will they ever be available in the Linux world?

Facebook: Background
• Value– Contacts directory. I can send a message to any of my 700+
“friends” without having to look up their email address or phone• To those curious: no, I do not friend random unknown strangers
– 24x7 connection with important people– Platform for sharing photos, texts, videos, other content– Powerful tool to organize Events, Groups
• Facebook’s motives?– Sometimes it looks like “boost ads response rate at any
cost”. Or am I missing something?

Facebook: Customer Concerns• FB exposes only those friends news feeds that are interesting to me –
according to what FB algorithm defines as “interesting”!– Very little user control over it– Creates “filter bubble” by showing you only what makes you feel comfortable– What if the algorithm is more than just “a little bit” wrong?
• If it was, you may never learn that even after the fact!
• FB stores most or all data indefinitely, which will inevitably lead to leaks– FB messages can’t be deleted at all– Posts, events, tags appear to be erasable one by one, but it’s unclear whether they are
actually deleted
• Privacy: lots of data exposed, yet hard to control what exactly• Numerous rumors of FBI presence on FB
– Not a problem in itself, but where is the guarantee it’s all lawful?
• Tremendous distraction: useful info mixed with tons of low quality, highly interruptive content

Facebook: Solutions?• Don’t use FB messages for anything sensitive
– Caveat: you don’t know what might be sensitive in 10 years• Self-discipline? E.g., keep it under 20 minutes per day
– Somebody: “Problem solved, next!” • Find an alternative? G+ and others, some offer very good services
– Showstopper issue: FB has more people. 90% of Value == People.• Custom lists: create your own lists of friends whose feeds are important to you.
– Multiple lists provide multiple views and/or sharing visibility options ( “Coworkers”, “No Russian”, “Local”, “Not Local”, “Readers”, “Clubbers”, etc.)
– Works like a chime, but… that is a marginal feature. Most people have no idea of it; the whole G+ introduction was built on the notion of “absence” of such feature in FB! So you never know when it may suddenly disappear
• Boost up all privacy settings– At minimum enable tags preview
• Hire a secretary who would be providing you with a summary or relevant/interesting data in your FB feeds?– Not as crazy as it sounds. Philippines are known for offering these kinds of services by
fairly educated people for reasonable $$.

Facebook: Mind Fragmentation• So, FB feeds are “micro-blogs” by nature:
– Overwhelming flow of single pictures and very short posts– Context switching forced hundreds times per hour– Lots of content – let’s face it – is trash
• Not really FB to be blamed for that. Common culture often confuses “emotionally striking” for “true”
• Not an FB-only problem: most of the Internet content is served in that “rapid fire” (or “high fructose”) mode today
• Human’s brain adapts to the prevailing mode of perception => damage ensues– Difficulty focusing & relaxing, ADD-like symptoms, “jumping” mind– Inability to perceive or work with concepts that require more than ~60 seconds of attention
span
• Possible solutions?– Self-discipline (helps only those who already have it )– According to Nicholas Carr’s book, regular uninterrupted good reading helps combat these
effects (per Denis Altudov, but as a prolific reader I tend to agree: it is akin to meditation and helps with building focusing skills. Plus, hey, it makes one smarter )

Excessive Data Collection and Services Conglomeration

Excessive Collection & Conglomeration
• Trend:– Services collect tremendous amounts of “scattered” information about their
customers• Seemingly benign things like clicks, movie preferences, clothing color preferences,
vocabulary, times when you are online, your “Likes” patterns, your friend names
– Services partner to use each other’s data to mutual benefit:• Spotify needs Facebook; Chrome wants Gmail; YouTube wants your phone #; Pandora or
Live Journal can post your likes to your FB, and so on.
• Provider’s motives:– Serve customers’ needs better by:
• Cross-referencing their data from partner sources• Collecting and analyzing more data
– Competitive pressure: everybody does it – fear to miss the train; “let’s collect today and figure what to do with it tomorrow”.
– Reduce accounts compromise or abuse (e.g., spam) by better establishing owner’s identity

Hotmail/LiveID/Outlook.com example
• Suddenly blocks email access until you provide either of these pieces
• There is no “skip” button except for some hacks

Excessive Collection & Conglomeration: Customer Concerns 1/2
• Increase of information stored makes account loss more damaging– Paradoxically, providers mitigate against account loss by increasing the amount
of information stored on it: phone #, secondary email, trusted PCs, explicit linking to other services, etc.
– I don’t want to care if my account is compromised or lost. I want to be able to erase it and create a new one (from backups) at any moment of time.
• Violation of minimal privilege principle– The more data you store, the more you lose upon a compromise– Abuse potential– Espionage: rumors of FBI presence on FB, Patriotic Act data disclosures, etc.– For 80% businesses, I don’t need an account at all – I’m making a one-time
purchase only• Many services offer no knobs to tune the level of service offered vs.
amount of information collected (it’s “all or go away” or “public vs. sign-in” at best)

Excessive Collection & Conglomeration: Customer Concerns 2/2
• Analysis of scattered data: – Data mining on petabytes of seemingly benign vectors may potentially lead to
learning something about me that even I don’t know, and then using that against me, without my awareness. E.g.: • “Irresistible” ads• Prediction of major life decisions• Revelation of health conditions or psychiatric disorders• Proneness to certain crimes or misbehaviors under well-orchestrated conditions
– Lack of legal regulation about storing and using scattered “low value” data (contrary to “high value” like SSN or Credit Card #)
• Creation of single point of failure: – To access my email, SMS, photos, preferences, friend names, travel history, search
history, purchases, list of apps installed hackers needed to break 12 accounts in the past. Now they need to break only one (see the (in)-famous Mat Honan hacking case).
– Password reset attack: if a hacker gets access to my email where many accounts chain to, the game is over for most of them!

Excessive Collection & Conglomeration: Customer Concerns: Solutions 1/2
• General sanitization: reveal as little as possible, abandon services that want too much data– Not much choice today, they all want it and data collection is
automatic for core business reasons– There is really no anonymity on the Internet today anyways: a
typical browser passes 10-50 fingerprinting parameters to the server
• Isolate services access: one app per one service rule– Use email client (e.g., Windows Live Mail) instead of a browser– Access Facebook via designated mobile app instead of a browser– On the desktop, if you are browsing Facebook, open all other
sites in a different browser

Excessive Collection & Conglomeration: Customer Concerns: Solutions 2/2
• Isolate your email: one service per one email– Or at least not too many (scalability problems may prevent 1:1 mapping)– Ideally those email addresses should be all from different providers– Passwords must be unique – a challenge for many– Regularly back up your email offline; do not store service communication email
at the server– Issue: how would that work with services that thrive on synergy (e.g., Spotify?)
• “Throw stones” (highly questionable effectiveness):– Provide false/misleading data whenever convenient and legal -- to choke data
mining algorithms– Share “proxy” accounts used by multiple people (in essence, that’s what Tor
does)– Issue: may create such a distorted image of your personality that this would
invite the unwelcome attention of FBI or customer support

Renewal of Information Sources

Filter bubble (illustrated by Google)

Renewal of Information Sources• Issues
– Filter bubble: many services always offer you a “tailored” view of information. You don’t even know whether something is deliberately hidden from you and how much.
– You build your information sources infrastructure (e.g., news, blogs, favorite sites) when you feel like you have free time to read. Then you stop. How do you expand beyond these limits? How do you systemically renew & enhance your data sources?
• Solutions (not really much discussion was done here)– There is no “true” information, there are only different perspectives. So
set up 2-4 viewpoints (e.g., via Tor, proxy, other trusted people), and that may be enough.
– Open question: any good RSS reader that does not require signing up with yet another bloody “account”?


















