
CLOUD COMPUTING IT0530 - SRM University IT0530.pdfinfrastructure services to businesses in the form...
93
CLOUD COMPUTING‐IT0530 G.JEYA BHARATHI Asst.Prof.(O.G) Department of IT SRM University
Transcript of CLOUD COMPUTING IT0530 - SRM University IT0530.pdfinfrastructure services to businesses in the form...

CLOUD COMPUTING‐IT0530
G.JEYA BHARATHIAsst.Prof.(O.G)Department of ITSRM University

2
CASE STUDY :
Amazon Case study : Introduction to Amazon Cloud Computing services, Queues and Cloud Front, Practical Amazon.
Introduction to MapReduce: Discussion of Google Paper, Discussion of BigTables, GFS, HDFS, Hadoop Framework

3
About AWSLaunched in 2006, Amazon Web Services (AWS) began exposing key
infrastructure services to businesses in the form of web services -- now widely known as cloud computing.
The ultimate benefit of cloud computing, and AWS, is the ability to leverage a new business model and turn capital infrastructure expenses into variable costs.
Businesses no longer need to plan and procure servers and other IT resources weeks or months in advance.
Using AWS, businesses can take advantage of Amazon's expertise and economies of scale to access resources when their business needs them, delivering results faster and at a lower cost.
Today, Amazon Web Services provides a highly reliable, scalable, low-cost infrastructure platform in the cloud that powers hundreds of thousands of businesses in 190 countries around the world.

4
With data center locations in the U.S., Europe, Singapore, and Japan, customers across all industries are taking advantage of the following benefits:
1. Low Cost2. Agility and Instant Elasticity3. Open and Flexible4. Secure

5
Products & ServicesComputeContent DeliveryDatabaseDeployment & ManagementE-CommerceMessagingMonitoringNetworkingPayments & BillingStorageSupportWeb TrafficWorkforce

6
Products & ServicesCompute›Amazon Elastic Compute Cloud (EC2)Amazon Elastic Compute Cloud delivers scalable, pay-as-you-go compute capacity in the cloud.›Amazon Elastic MapReduceAmazon Elastic MapReduce is a web service that enables businesses, researchers, data analysts, and developers to easily and cost-effectively process vast amounts of data.›Auto ScalingAuto Scaling allows to automatically scale our Amazon EC2capacity up or down according to conditions we define.Content Delivery›Amazon CloudFrontAmazon CloudFront is a web service that makes it easy to distribute content with low latency via a global network of edge locations.

7
Database›Amazon SimpleDBAmazon SimpleDB works in conjunction with Amazon S3 and AmazonEC2 to run queries on structured data in real time.›Amazon Relational Database Service (RDS)Amazon Relational Database Service is a web service that makes it easy to set up, operate, and scale a relational database in the cloud.›Amazon ElastiCacheAmazon ElastiCache is a web service that makes it easy to deploy, operate, and scale an in-memory cache in the cloud.E-Commerce›Amazon Fulfillment Web Service (FWS)Amazon Fulfillment Web Service allows merchants to deliver products using Amazon.com’s worldwide fulfillment capabilities.

8
Deployment & Management›AWS Elastic BeanstalkAWS Elastic Beanstalk is an even easier way to quickly deploy and manage applications in the AWS cloud. We simply upload our application, and Elastic Beanstalk automatically handles the deployment details of capacity provisioning, load balancing, auto-scaling, and application health monitoring.›AWS CloudFormationAWS CloudFormation is a service that gives developers and businesses an easy way to create a collection of related AWS resources and provision them in an orderly and predictable fashion.Monitoring›Amazon CloudWatchAmazon CloudWatch is a web service that provides monitoring for AWS cloud resources, starting with Amazon EC2

9
Messaging›Amazon Simple Queue Service (SQS)Amazon Simple Queue Service provides a hosted queue for storing messages as they travel between computers, making it easy to build automated workflow between Web services.›Amazon Simple Notification Service (SNS)Amazon Simple Notification Service is a web service that makes it easy to set up, operate, and send notifications from the cloud.›Amazon Simple Email Service (SES)Amazon Simple Email Service is a highly scalable and cost-effective bulk and transactional email-sending service for the cloud.Workforce›Amazon Mechanical TurkAmazon Mechanical Turk enables companies to access thousands of global workers on demand and programmatically integrate their work into various business processes.

10
Networking›Amazon Route 53Amazon Route 53 is a highly available and scalable Domain Name System (DNS) web service.›Amazon Virtual Private Cloud (VPC)Amazon Virtual Private Cloud (Amazon VPC) lets you provision a private, isolated section of the Amazon Web Services (AWS) Cloud where we can launch AWS resources in a virtual network that you define. With Amazon VPC, we can define a virtual network topology that closely resembles a traditional network that you might operate in your own datacenter.›AWS Direct ConnectAWS Direct Connect makes it easy to establish a dedicated network connection from your premise to AWS, which in many cases can reduce our network costs, increase bandwidth throughput, and provide a more consistent network experience than Internet-based connections.›Elastic Load BalancingElastic Load Balancing automatically distributes incoming application traffic across multiple Amazon EC2 instances.

11
Payments & Billing›Amazon Flexible Payments Service (FPS)Amazon Flexible Payments Service facilitates the digital transfer of money between any two entities, humans or computers.›Amazon DevPayAmazon DevPay is a billing and account management service which enables developers to collect payment for their AWS applications.Storage›Amazon Simple Storage Service (S3)Amazon Simple Storage Service provides a fully redundant data storage infrastructure for storing and retrieving any amount of data, at any time, from anywhere on the Web.›Amazon Elastic Block Store (EBS)Amazon Elastic Block Store provides block level storage volumes for use with Amazon EC2 instances. Amazon EBS volumes are off-instance storage that persists independently from the life of an instance.›AWS Import/ExportAWS Import/Export accelerates moving large amounts of data into and out of AWS using portable storage devices for transport.

12
Support›AWS Premium SupportAWS Premium Support is a one-on-one, fast-response support channel to help you build and run applications on AWS Infrastructure Services.Web Traffic›Alexa Web Information ServiceAlexa Web Information Service makes Alexa’s huge repository of data about structure and traffic patterns on the Web available to developers.›Alexa Top SitesAlexa Top Sites exposes global website traffic data as it is continuously collected and updated by Alexa Traffic Rank.

13
Amazon CloudFrontAmazon CloudFront is a web service for content
delivery. It integrates with other Amazon Web Services to give
developers and businesses an easy way to distribute content to end users with low latency, high data transfer speeds, and no commitments.
Amazon CloudFront delivers our static and streaming content using a global network of edge locations.
Requests for our objects are automatically routed to the nearest edge location, so content is delivered with the best possible performance.

14
Amazon CloudFrontAmazon CloudFront is optimized to work with other
Amazon Web Services, like Amazon Simple Storage Service (S3) and Amazon Elastic Compute Cloud (EC2).
Amazon CloudFront also works seamlessly with any origin server, which stores the original, definitive versions of our files.
Like other Amazon Web Services, there are no contracts or monthly commitments for using Amazon CloudFront –we pay only for as much or as little content as you actually deliver through the service.

15
Amazon Simple Queue Service (Amazon SQS)Amazon Simple Queue Service (Amazon SQS) offers a reliable,
highly scalable, hosted queue for storing messages as they travel between computers.
By using Amazon SQS, developers can simply move data between distributed components of their applications that perform different tasks, without losing messages or requiring each component to be always available.
Amazon SQS makes it easy to build an automated workflow, working in close conjunction with the Amazon Elastic Compute Cloud (Amazon EC2) and the other AWS infrastructure web services.

16
Amazon Simple Queue Service (Amazon SQS)
Amazon SQS works by exposing Amazon’s web-scale messaging infrastructure as a web service.
Any computer on the Internet can add or read messages without any installed software or special firewall configurations.
Components of applications using Amazon SQS can run independently, and do not need to be on the same network, developed with the same technologies, or running at the same time

17
BigTableBigtable is a distributed storage system for managing structured
data that is designed to scale to a very large size: petabytes of data across thousands of commodity servers.
Many projects at Google store data in Bigtable, including web indexing, Google Earth, and Google Finance.
These applications place very different demands on Bigtable, both in terms of data size (from URLs to web pages to satellite imagery) and latency requirements (from backend bulk processing to real-time data serving).
Despite these varied demands, Bigtable has successfully provided a fexible, high-performance solution for all of these Google products.

18
The Google File System(GFS)The Google File System (GFS) is designed to meet the rapidly growing demands of
Google’s data processing needs. GFS shares many of the same goals as previous distributed file systems such as
performance, scalability, reliability, and availability. It provides fault tolerance while running on inexpensive commodity hardware, and it
delivers high aggregate performance to a large number of clients.While sharing many of the same goals as previous distributed file systems, file
system has successfully met our storage needs.It is widely deployed within Google as the storage platform for the generation and
processing of data used by our service as well as research and development efforts that require large data sets. The largest cluster to date provides hundreds of terabytes of storage across
thousands of disks on over a thousand machines, and it is concurrently accessed by hundreds of clients.

19

What Is ?
• Distributed computing frame work– For clusters of computers
– Thousands of Compute Nodes
– Petabytes of data
• Open source, Java
• Google’s MapReduce inspired Yahoo’s Hadoop.
• Now part of Apache group20

What Is ?• The Apache Hadoop project develops open‐source software for
reliable, scalable, distributed computing. Hadoop includes:– Hadoop Common utilities– Avro: A data serialization system with scripting languages.– Chukwa: managing large distributed systems.– HBase: A scalable, distributed database for large tables.– HDFS: A distributed file system.– Hive: data summarization and ad hoc querying.– MapReduce: distributed processing on compute clusters.– Pig: A high‐level data‐flow language for parallel computation.– ZooKeeper: coordination service for distributed applications.
21

The Idea of Map Reduce
22

Map and Reduce
• The idea of Map, and Reduce is 40+ year old– Present in all Functional Programming Languages.
– See, e.g., APL, Lisp and ML
• Alternate names for Map: Apply‐All
• Higher Order Functions – take function definitions as arguments, or
– return a function as output
• Map and Reduce are higher‐order functions.
23

Map: A Higher Order Function
• F(x: int) returns r: int
• Let V be an array of integers.
• W = map(F, V)– W[i] = F(V[i]) for all I
– i.e., apply F to every element of V
24

Map Examples in Haskell
• map (+1) [1,2,3,4,5]== [2, 3, 4, 5, 6]
• map (toLower) "abcDEFG12!@#“== "abcdefg12!@#“
• map (`mod` 3) [1..10]== [1, 2, 0, 1, 2, 0, 1, 2, 0, 1]
25

reduce: A Higher Order Function
• reduce also known as fold, accumulate, compress or inject
• Reduce/fold takes in a function and folds it in between the elements of a list.
26

Fold‐Left in Haskell
• Definition– foldl f z [] = z
– foldl f z (x:xs) = foldl f (f z x) xs
• Examples– foldl (+) 0 [1..5] ==15
– foldl (+) 10 [1..5] == 25
– foldl (div) 7 [34,56,12,4,23] == 0
27

Fold‐Right in Haskell
• Definition– foldr f z [] = z
– foldr f z (x:xs) = f x (foldr f z xs)
• Example– foldr (div) 7 [34,56,12,4,23] == 8
28

Examples of theMap Reduce Idea
29

Word Count Example
• Read text files and count how often words occur. – The input is text files
– The output is a text file• each line: word, tab, count
• Map: Produce pairs of (word, count)
• Reduce: For each word, sum up the counts.
30

Grep Example
• Search input files for a given pattern• Map: emits a line if pattern is matched
• Reduce: Copies results to output
31

Inverted Index Example
• Generate an inverted index of words from a given set of files
• Map: parses a document and emits <word, docId> pairs
• Reduce: takes all pairs for a given word, sorts the docId values, and emits a <word, list(docId)> pair
32

Map/Reduce Implementation Idea
33

Execution on Clusters
1. Input files split (M splits)
2. Assign Master & Workers
3. Map tasks
4. Writing intermediate data to disk (R regions)
5. Intermediate data read & sort
6. Reduce tasks
7. Return
34

Map/Reduce Cluster Implementation
split 0split 1split 2split 3split 4
Output 0
Output 1
Input files
Output files
M map tasks
R reduce tasks
Intermediate files
Several map or reduce tasks can run on a single computer
Each intermediate file is divided into Rpartitions, by partitioning function
Each reduce task corresponds to one partition35

Execution
36

Fault Recovery
• Workers are pinged by master periodically–Non‐responsive workers are marked as failed
–All tasks in‐progress or completed by failed worker become eligible for rescheduling
• Master could periodically checkpoint–Current implementations abort on master failure
37

• Component Overview
38

• http://hadoop.apache.org/• Open source Java• Scale
– Thousands of nodes and – petabytes of data
• Still pre‐1.0 release– 22 04, 2009: release 0.20.0– 17 09, 2008: release 0.18.1– but already used by many
39

Hadoop
• MapReduce and Distributed File System framework for large commodity clusters
• Master/Slave relationship– JobTracker handles all scheduling & data flow between TaskTrackers
–TaskTracker handles all worker tasks on a node– Individual worker task runs map or reduce operation
• Integrates with HDFS for data locality
40

Hadoop Supported File Systems• HDFS: Hadoop's own file system. • Amazon S3 file system.
– Targeted at clusters hosted on the Amazon Elastic Compute Cloud server‐on‐demand infrastructure
– Not rack‐aware• CloudStore
– previously Kosmos Distributed File System– like HDFS, this is rack‐aware.
• FTP Filesystem– stored on remote FTP servers.
• Read‐only HTTP and HTTPS file systems.
41

"Rack awareness"
• optimization which takes into account the geographic clustering of servers
• network traffic between servers in different geographic clusters is minimized.
42

HDFS: Hadoop Distributed File System• Designed to scale to petabytes of storage, and run on top of the file systems of the underlying OS.
• Master (“NameNode”) handles replication, deletion, creation
• Slave (“DataNode”) handles data retrieval• Files stored in many blocks
– Each block has a block Id– Block Id associated with several nodes hostname:port (depending on level of replication)
43

44
Hadoop Distributed File System(HDFS)An HDFS cluster consists of a single NameNode, a
master server that manages the file system namespace and regulates access to files by clients.
In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on.
HDFS exposes a file system namespace and allows user data to be stored in files.
Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes.

45
Hadoop Distributed File System(HDFS)The NameNode executes file system namespace
operations like opening, closing, and renaming files and directories.
It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and
write requests from the file system’s clients. The DataNodes also perform block creation, deletion,
and replication upon instruction from the NameNode.

46

Hadoop v. ‘MapReduce’
• MapReduce is also the name of a framework developed by Google
• Hadoop was initially developed by Yahoo and now part of the Apache group.
• Hadoop was inspired by Google's MapReduce and Google File System (GFS) papers.
47

MapReduce v. Hadoop
MapReduce HadoopOrg Google Yahoo/Apache
Impl C++ Java
Distributed File Sys GFS HDFS
Data Base Bigtable HBase
Distributed lock mgr Chubby ZooKeeper
48
wordCount
• A Simple Hadoop Examplehttp://wiki.apache.org/hadoop/WordCount
49

Word Count Example
• Read text files and count how often words occur. – The input is text files
– The output is a text file• each line: word, tab, count
• Map: Produce pairs of (word, count)
• Reduce: For each word, sum up the counts.
50

WordCount Overview3 import ...12 public class WordCount {13 14 public static class Map extends MapReduceBase implements Mapper ... {17 18 public void map ...26 } 27 28 public static class Reduce extends MapReduceBase implements Reducer ... {29 30 public void reduce ...37 }38 39 public static void main(String[] args) throws Exception {40 JobConf conf = new JobConf(WordCount.class);41 ...53 FileInputFormat.setInputPaths(conf, new Path(args[0]));54 FileOutputFormat.setOutputPath(conf, new Path(args[1]));55 56 JobClient.runJob(conf);57 }58 59 }
51

wordCount Mapper14 public static class Map extends MapReduceBase implements Mapper<LongWritable, Text,
Text, IntWritable> {15 private final static IntWritable one = new IntWritable(1);16 private Text word = new Text();17 18 public void map(
LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {19 String line = value.toString();20 StringTokenizer tokenizer = new StringTokenizer(line);21 while (tokenizer.hasMoreTokens()) {22 word.set(tokenizer.nextToken());23 output.collect(word, one);24 }25 }26 }
52

wordCount Reducer
28 public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
29 30 public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output,Reporter reporter)
throws IOException {31 int sum = 0;32 while (values.hasNext()) {33 sum += values.next().get();34 }35 output.collect(key, new IntWritable(sum));36 }37 }
53

wordCount JobConf
40 JobConf conf = new JobConf(WordCount.class);41 conf.setJobName("wordcount");42 43 conf.setOutputKeyClass(Text.class);44 conf.setOutputValueClass(IntWritable.class);45 46 conf.setMapperClass(Map.class);47 conf.setCombinerClass(Reduce.class);48 conf.setReducerClass(Reduce.class);49 50 conf.setInputFormat(TextInputFormat.class);51 conf.setOutputFormat(TextOutputFormat.class);
54

WordCount main
39 public static void main(String[] args) throws Exception {40 JobConf conf = new JobConf(WordCount.class);41 conf.setJobName("wordcount");42 43 conf.setOutputKeyClass(Text.class);44 conf.setOutputValueClass(IntWritable.class);45 46 conf.setMapperClass(Map.class);47 conf.setCombinerClass(Reduce.class);48 conf.setReducerClass(Reduce.class);49 50 conf.setInputFormat(TextInputFormat.class);51 conf.setOutputFormat(TextOutputFormat.class);52 53 FileInputFormat.setInputPaths(conf, new Path(args[0]));54 FileOutputFormat.setOutputPath(conf, new Path(args[1]));55 56 JobClient.runJob(conf);57 }
55

Invocation of wordcount
1. /usr/local/bin/hadoop dfs ‐mkdir <hdfs‐dir>2. /usr/local/bin/hadoop dfs ‐copyFromLocal
<local‐dir> <hdfs‐dir> 3. /usr/local/bin/hadoop
jar hadoop‐*‐examples.jar wordcount [‐m <#maps>] [‐r <#reducers>] <in‐dir> <out‐dir>
56

Mechanics of Programming Hadoop Jobs
57

Job Launch: Client
• Client program creates a JobConf– Identify classes implementing Mapper and Reducer interfaces
• setMapperClass(), setReducerClass()
– Specify inputs, outputs• setInputPath(), setOutputPath()
– Optionally, other options too:• setNumReduceTasks(), setOutputFormat()…
58

Job Launch: JobClient
• Pass JobConf to – JobClient.runJob() // blocks
– JobClient.submitJob() // does not block
• JobClient: – Determines proper division of input into InputSplits
– Sends job data to master JobTracker server
59

Job Launch: JobTracker
• JobTracker: – Inserts jar and JobConf (serialized to XML) in shared location
– Posts a JobInProgress to its run queue
60

Job Launch: TaskTracker
• TaskTrackers running on slave nodes periodically query JobTracker for work
• Retrieve job‐specific jar and config
• Launch task in separate instance of Java– main() is provided by Hadoop
61

Job Launch: Task
• TaskTracker.Child.main():– Sets up the child TaskInProgress attempt
– Reads XML configuration
– Connects back to necessary MapReduce components via RPC
– Uses TaskRunner to launch user process
62

Job Launch: TaskRunner
• TaskRunner, MapTaskRunner, MapRunner work in a daisy‐chain to launch Mapper – Task knows ahead of time which InputSplits it should be mapping
– Calls Mapper once for each record retrieved from the InputSplit
• Running the Reducer is much the same
63

Creating the Mapper
• Your instance of Mapper should extend MapReduceBase
• One instance of your Mapper is initialized by the MapTaskRunner for a TaskInProgress– Exists in separate process from all other instances of Mapper – no data sharing!
64

Mapper
void map (WritableComparable key,Writable value,OutputCollector output,Reporter reporter
)
65

What is Writable?
• Hadoop defines its own “box” classes for strings (Text), integers (IntWritable), etc.
• All values are instances of Writable
• All keys are instances of WritableComparable
66

Writing For Cache Coherency
while (more input exists) {
myIntermediate = new intermediate(input);
myIntermediate.process();
export outputs;
}
67

Writing For Cache Coherency
myIntermediate = new intermediate (junk);
while (more input exists) {
myIntermediate.setupState(input);
myIntermediate.process();
export outputs;
}
68

Writing For Cache Coherency
• Running the GC takes time
• Reusing locations allows better cache usage
• Speedup can be as much as two‐fold
• All serializable types must be Writable anyway, so make use of the interface
69

Getting Data To The Mapper
70

Reading Data
• Data sets are specified by InputFormats– Defines input data (e.g., a directory)
– Identifies partitions of the data that form an InputSplit
– Factory for RecordReader objects to extract (k, v) records from the input source
71

FileInputFormat and Friends
• TextInputFormat– Treats each ‘\n’‐terminated line of a file as a value
• KeyValueTextInputFormat– Maps ‘\n’‐ terminated text lines of “k SEP v”
• SequenceFileInputFormat– Binary file of (k, v) pairs with some add’l metadata
• SequenceFileAsTextInputFormat– Same, but maps (k.toString(), v.toString())
72

Filtering File Inputs
• FileInputFormat will read all files out of a specified directory and send them to the mapper
• Delegates filtering this file list to a method subclasses may override– e.g., Create your own “xyzFileInputFormat” to read *.xyz from directory list
73

Record Readers
• Each InputFormat provides its own RecordReader implementation– Provides (unused?) capability multiplexing
• LineRecordReader– Reads a line from a text file
• KeyValueRecordReader– Used by KeyValueTextInputFormat
74

Input Split Size
• FileInputFormat will divide large files into chunks– Exact size controlled by mapred.min.split.size
• RecordReaders receive file, offset, and length of chunk
• Custom InputFormat implementations may override split size– e.g., “NeverChunkFile”
75

Sending Data To Reducers
• Map function receives OutputCollector object– OutputCollector.collect() takes (k, v) elements
• Any (WritableComparable, Writable) can be used
76

WritableComparator
• Compares WritableComparable data– Will call WritableComparable.compare()
– Can provide fast path for serialized data
• JobConf.setOutputValueGroupingComparator()
77

Sending Data To The Client
• Reporter object sent to Mapper allows simple asynchronous feedback– incrCounter(Enum key, long amount)
– setStatus(String msg)
• Allows self‐identification of input– InputSplit getInputSplit()
78
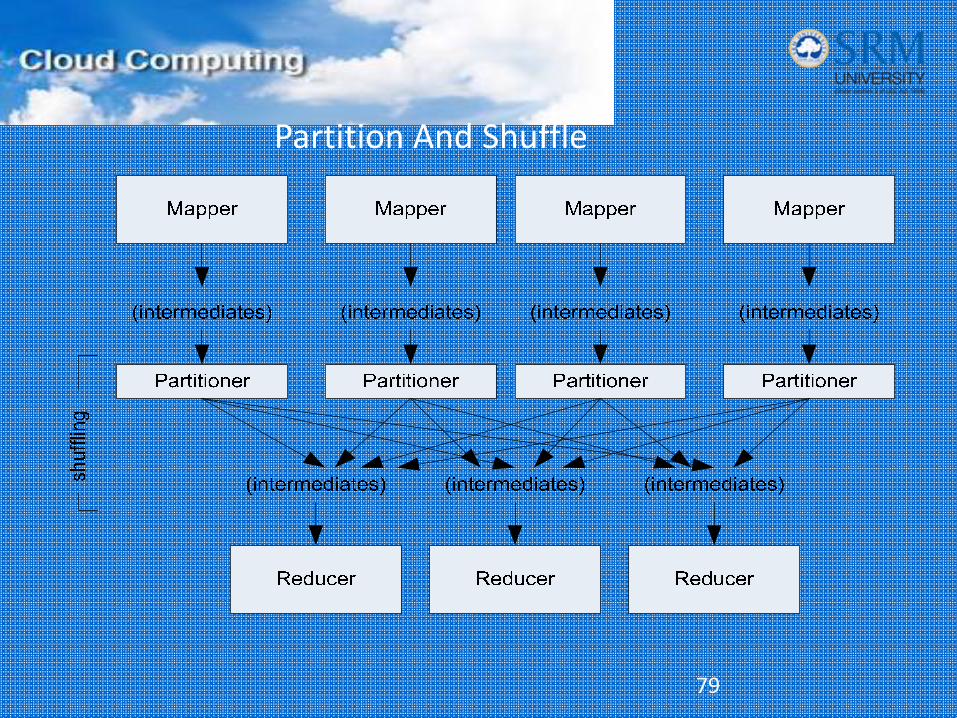
Partition And Shuffle
79

Partitioner
• int getPartition(key, val, numPartitions)– Outputs the partition number for a given key
– One partition == values sent to one Reduce task
• HashPartitioner used by default– Uses key.hashCode() to return partition num
• JobConf sets Partitioner implementation
80

Reduction
• reduce( WritableComparable key, Iterator values, OutputCollector output, Reporter reporter)
• Keys & values sent to one partition all go to the same reduce task
• Calls are sorted by key – “earlier” keys are reduced and output before “later” keys
81

Finally: Writing The Output
Out
putF
orm
at
82

OutputFormat
• Analogous to InputFormat
• TextOutputFormat– Writes “key val\n” strings to output file
• SequenceFileOutputFormat– Uses a binary format to pack (k, v) pairs
• NullOutputFormat– Discards output
83

HDFS Limitations
• “Almost” GFS (Google FS)– No file update options (record append, etc); all files are write‐once
• Does not implement demand replication
• Designed for streaming – Random seeks devastate performance
84

NameNode
• “Head” interface to HDFS cluster
• Records all global metadata
85

Secondary NameNode
• Not a failover NameNode!
• Records metadata snapshots from “real” NameNode– Can merge update logs in flight
– Can upload snapshot back to primary
86

NameNode Death
• No new requests can be served while NameNode is down– Secondary will not fail over as new primary
87

NameNode Death, cont’d
• If NameNode dies from software glitch, just reboot
• But if machine is hosed, metadata for cluster is irretrievable!
88

Bringing the Cluster Back
• If original NameNode can be restored, secondary can re‐establish the most current metadata snapshot
• If not, create a new NameNode, use secondary to copy metadata to new primary, restart whole cluster ( )
• Is there another way…?
89

Keeping the Cluster Up
• Problem: DataNodes “fix” the address of the NameNode in memory, can’t switch in flight
• Solution: Bring new NameNode up, but use DNS to make cluster believe it’s the original one
90

Further Reliability Measures
• Namenode can output multiple copies of metadata files to different directories– Including an NFS mounted one
– May degrade performance; watch for NFS locks
91

Making Hadoop Work
• Basic configuration involves pointing nodes at master machines– mapred.job.tracker– fs.default.name– dfs.data.dir, dfs.name.dir– hadoop.tmp.dir– mapred.system.dir
• See “Hadoop Quickstart” in online documentation
92

Eclipse Plugin
• Support for Hadoop in Eclipse IDE– Allows MapReduce job dispatch
– Panel tracks live and recent jobs
• http://www.alphaworks.ibm.com/tech/mapreducetools
93









![11PPMI Program Outline E › p2m › seminar › aots › 11PPMI Program Outline _E_.pdfInfrastructure Construction and Plant Engineering [PPMI] 6 – 17 February 2012 ... coal gasification](https://static.fdocuments.us/doc/165x107/5ed5a79a740631020e41ceaf/11ppmi-program-outline-e-a-p2m-a-seminar-a-aots-a-11ppmi-program-outline.jpg)








