

Clickstream Analysis with Apache Spark
40
CLICKSTREAM ANALYSIS WITH APACHE SPARK Andreas Zitzelsberger
-
Upload
qaware-gmbh -
Category
Technology
-
view
222 -
download
0
Transcript of Clickstream Analysis with Apache Spark

CLICKSTREAM ANALYSIS WITH APACHE SPARK
AndreasZitzelsberger

THE CHALLENGE

ONE POT TO RULE THEM ALL
Web Tracking Ad Tracking
ERP CRM
▪ Products
▪ Inventory
▪ Margins
▪Customer
▪Orders
▪Creditworthiness
▪Ad Im
pressions
▪Ad Costs
▪Clicks & Views
▪Conversions

ONE POT TO RULE THEM ALL
Retention Reach
Monetarization
steer … ▪ Campaigns ▪ Offers ▪ Contents

REACT ON WEB SITE TRAFFIC IN REAL TIME
Image: https://www.flickr.com/photos/nick-m/3663923048

SAMPLE RESULTS
Geolocated and gender-specific conversions.
Frequency of visits
Performance of an ad campaign

THE CONCEPTS
Image: Randy Paulino

THE FIRST SKETCH
(= real-time)
SQL

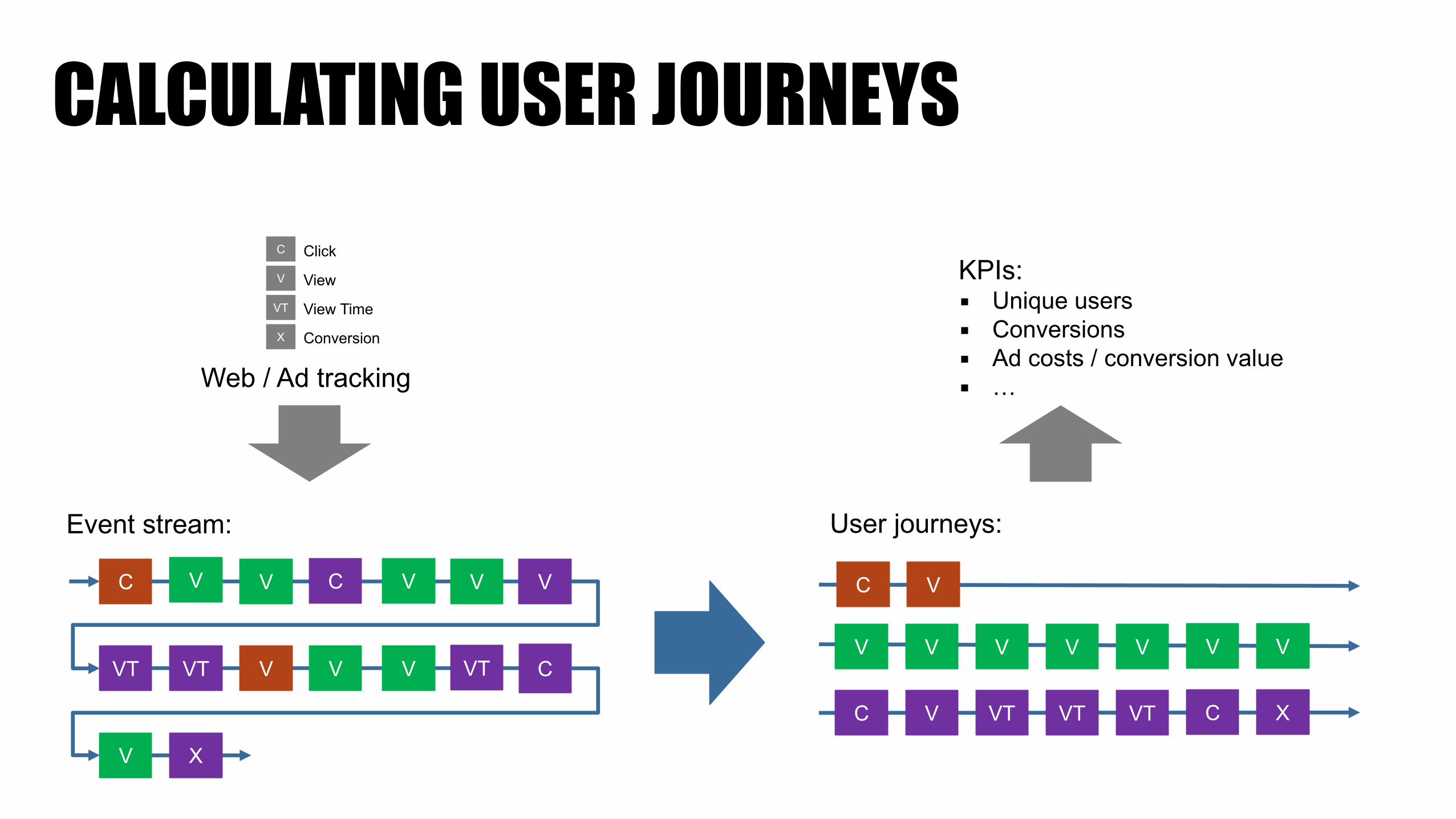
CALCULATING USER JOURNEYS
C V VT VT VT C X
C V
V V V V V V V
C V V C V V V
VT VT V V V VT C
V X
Event stream: User journeys:
Web / Ad tracking
KPIs:▪ Unique users▪ Conversions▪ Ad costs / conversion value▪ …
V
X
VT
C Click
View
View Time
Conversion

THE ARCHITECTURE
Big Data

„LARRY & FRIENDS“ ARCHITECTURE
Runs not well for morethan 1 TB data in terms ofingestion speed, query timeand optimization efforts

Image: adweek.com
Nope. Sorry, no Big Data.

„HADOOP & FRIENDS“ ARCHITECTUREAggregation takes too long
Cumbersomeprogramming model(can be solved withpig, cascading et al.)
Not interactiveenough

Nope.Toosluggish.

Κ-ARCHITECTURE
Cumbersomeprogramming model
Over-engineered: We only need15min real-time ;-)
Stateful aggregations (unique x, conversions) require a separate DB with high throughput and fast aggregations & lookups.
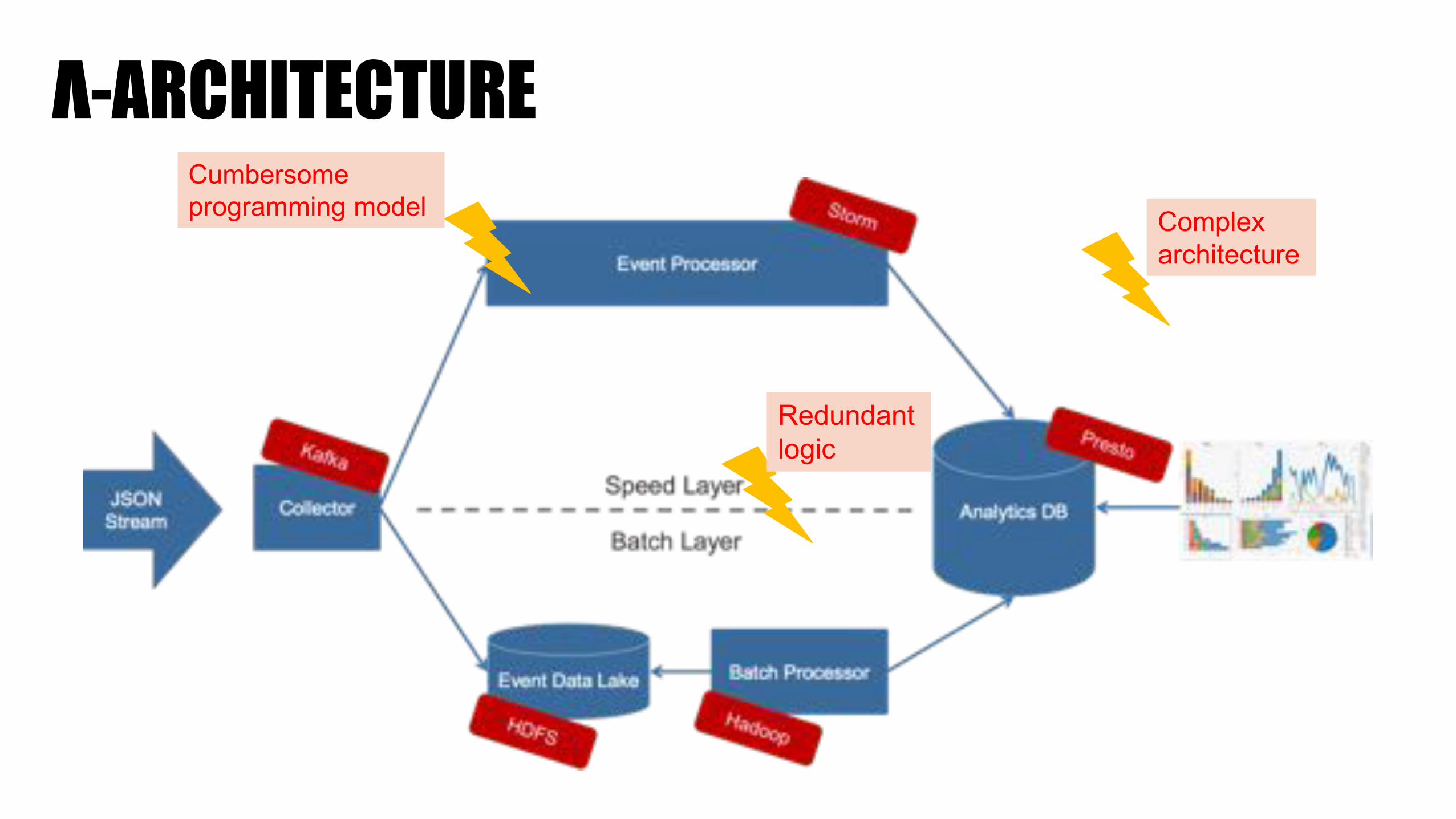
Λ-ARCHITECTURECumbersomeprogramming model Complex
architecture
Redundant logic

FEELS OVER-ENGINEERED…
http://www.brainlazy.com/article/random-nonsense/over-engineered

The Final Architecture**) Maybe called µ-architecture one day ;-)

FUNCTIONAL ARCHITECTURE
Strange Events
IngestionRaw Event Stream
Collection Events Processing Analytics Warehouse
FactEntries
Atomic Event Frames
Data Lake
Master Data Integration
▪ Buffers load peeks▪ Ensures message
delivery (fire & forgetfor client)
▪ Create user journeys andunique user sets
▪ Enrich dimensions▪ Aggregate events to KPIs▪ Ability to replay for schema
evolution
▪ The representation of truth▪ Multidimensional data
model▪ Interactive queries for
actions in realtime anddata exploration
▪ Eternal memory for all events (even strangeones)
▪ One schema per eventtype. Time partitioned.
▪ Fault tolerant message handling▪ Event handling: Apply schema, time-partitioning, De-dup, sanity
checks, pre-aggregation, filtering, fraud detection▪ Tolerates delayed events▪ High throughput, moderate latency (~ 1min)

SERIAL CONNECTION OF STREAMING AND BATCHING
IngestionRaw Event Stream
Collection Event Data Lake Processing Analytics Warehouse
FactEntries
SQL InterfaceAtomic Event
Frames
▪ Cool programming model▪ Uniform dev&ops
▪ Simple solution▪ High compression ratio due to
column-oriented storage▪ High scan speed
▪ Cool programming model▪ Uniform dev&ops▪ High performance▪ Interface to R out-of-the-box▪ Useful libs: MLlib, GraphX, NLP, …
▪ Good connectivity (JDBC, ODBC, …)
▪ Interactive queries▪ Uniform ops▪ Can easily be replaced
due to Hive Metastore
▪ Obvious choice forcloud-scale messaging
▪ Way the best throughputand scalability of all evaluated alternatives

public Map<Long, UserJourney> sessionize(JavaRDD<AtomicEvent> events) { return events // Convert to a pair RDD with the userId as key .mapToPair(e -> new Tuple2<>(e.getUserId(), e)) // Build user journeys .<UserJourneyAcc>combineByKey( UserJourneyAcc::create, UserJourneyAcc::add, UserJourneyAcc::combine) // Convert to a Java map .collectAsMap(); }

STREAM VERSUS BATCH
https://en.wikipedia.org/wiki/Tanker_(ship)#/media/File:Sirius_Star_2008b.jpghttps://blog.allstate.com/top-5-safety-tips-at-the-gas-pump/

APACHE FLINK
■ Alsohasanice,Spark-likeAPI■ Promisessimilarorbetter
performancethanspark
■ Lookslikethebestsolutionforaκ-Architecture
■ Butit’salsothenewestkidontheblock

EVENT VERSUS PROCESSING TIME■ There’sadifferencebetweeneventime(te)andprocessingtime
(tp).
■ Eventsarriveout-oforderevenduringnormaloperation.
■ Eventsmayarrivearbitrarylate.
Applyagraceperiodbeforeprocessingevents.
Allowarbitraryupdatewindowsofmetrics.

EXAMPLE
Minute
Hour
Day
Week
Month
Quarter
Year
I
U
U
U
U
U
U
I
U
U
U
U
U
U
U
Resolution inTime
Time
dtp
tp
tp: ProcessingTimeti: Ingestiontimete: EventTime
dtp: Aggregationtime framedtw: Graceperiod
: Insertfact: Updatefact
dtw
te
ti

LESSONS LEARNED
Image: http://hochmeister-alpin.at

BEST-OF-BREED INSTEAD OF COMMODITY SOLUTIONS
ETL
Analytics
Realtime Analytics
Slice & Dice
Data Exploration
Polyglot Processing
http://datadventures.ghost.io/2014/07/06/polyglot-processing

POLYGLOT ANALYTICS
Data Lake Analytics Warehouse
SQL lane
R lane
Timeserieslane
Reporting Data ExplorationData Science

NO RETENTION PARANOIA
Data Lake
Analytics Warehouse
▪ Eternal memory ▪ Close to raw events ▪ Allows replays and refills
into warehouse
Aggressive forgetting with clearly defined retention policy per aggregation level like: ▪ 15min:30d ▪ 1h:4m ▪ …
Events
Strange Events

BEWARE OF THE HIPSTERS
Image: h&m

ENSURE YOUR SOFTWARE RUNS LOCALLY
The entire architecture must be able to run locally. Keep the round trips low for development and testing.
Throughput and reaction times need to be monitored continuously. Tune your software and the underlying frameworks as needed.

TUNE CONTINUOUSLY
IngestionRaw Event Stream
Collection Event Data Lake Processing Analytics Warehouse
FactEntries
SQL InterfaceAtomic Event
Frames
Load generator Throughput & latency probes
System, container and process monitoring

IN NUMBERSOverall dev effort until the first release: 250 person days
Dimensions: 10 KPIs: 26
Integrated 3rd party systems: 7Inbound data volume per day: 80GB
New data in DWH per day: 2GB
Total price of cheapest cluster which is able to handle production load:


BONUS SLIDES

CALCULATING UNIQUE USERS
■Weneedanexactuniqueusercount.
■ Ifyoucan,youshoulduseanapproximationsuchasHyperLogLog.
U1
U2
U3
U1
U4
Time
Use
rs
3 UU 2 UU
4 UU
Flajolet, P.; Fusy, E.; Gandouet, O.; Meunier, F. (2007). "HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm". AOFA ’07: Proceedings of the 2007 International Conference on the Analysis of Algorithms.

CHARTING TECHNOLOGY
https://github.com/qaware/big-data-landscape
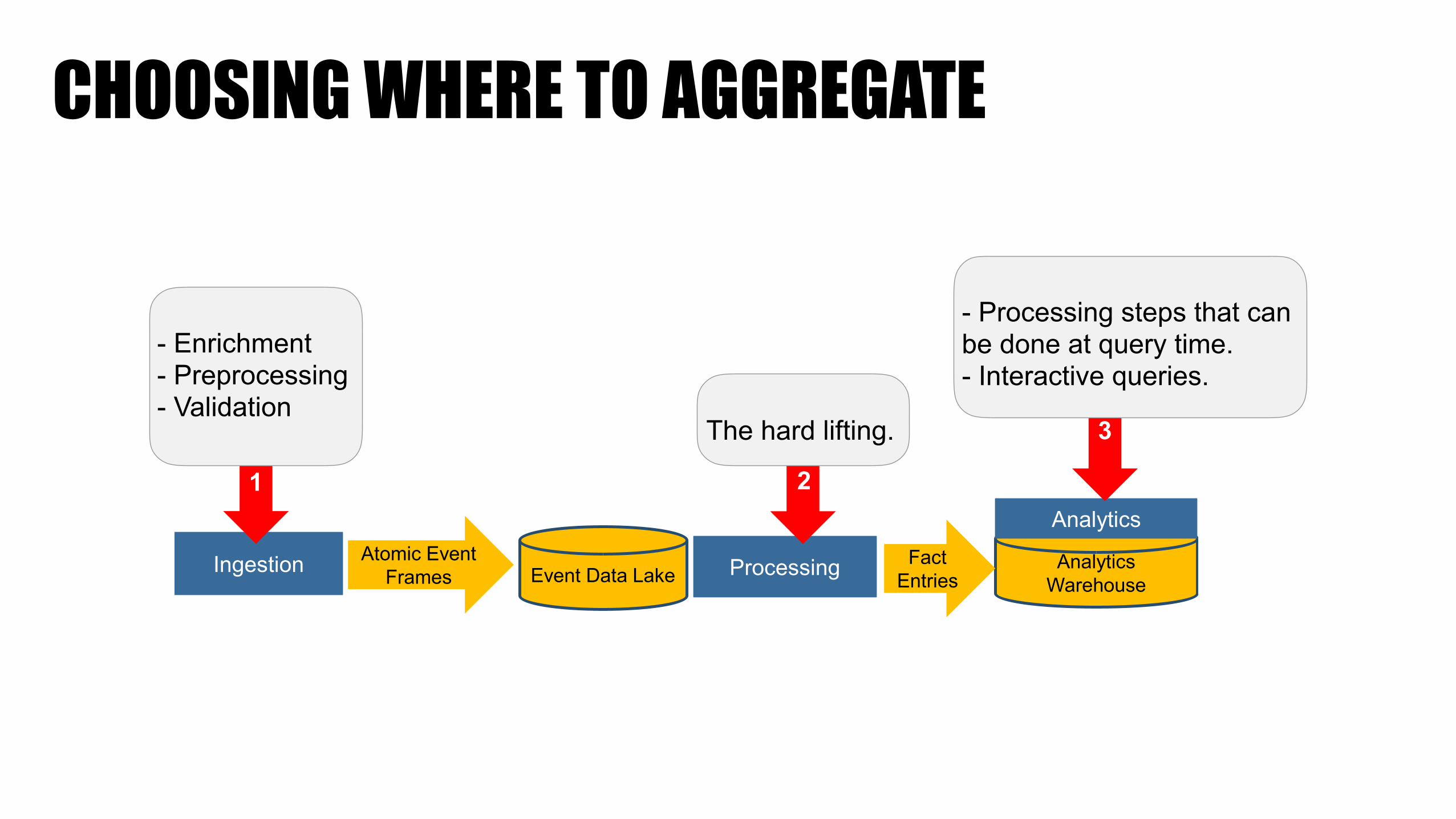
CHOOSING WHERE TO AGGREGATE
Ingestion Event Data Lake Processing Analytics Warehouse
FactEntries
AnalyticsAtomic Event
Frames
1 2
3
- Enrichment - Preprocessing - Validation
The hard lifting.
- Processing steps that can be done at query time. - Interactive queries.






![[@NaukriEngineering] Apache Spark](https://static.fdocuments.us/doc/165x107/588304451a28abe70d8b6157/naukriengineering-apache-spark.jpg)











