
Chapter 6 The Standard Deviation as a Ruler and the Normal Model Math2200.
26
Chapter 6 The Standard Deviation as a Ruler and the Normal Model Math2200
-
Upload
aileen-day -
Category
Documents
-
view
226 -
download
0
Transcript of Chapter 6 The Standard Deviation as a Ruler and the Normal Model Math2200.

Chapter 6
The Standard Deviation as a Ruler and the Normal Model
Math2200

Examples: How do we compare measurements on different scales ?
SAT score 1500 versus ACT score 21Women’s heptathlon
200-m runs, 800-m runs, 100-m high hurdles Shot put, javelin, high jump, long jump
Make them on the same scale by standardization Count how many standard deviations away
from the mean

The Standard Deviation as a Ruler The standard deviation tells us how the whole
collection of values varies, so it’s a natural ruler for comparing an individual to a group.
Standardizing with z-scores We compare individual data values to their mean,
relative to their standard deviation using the following formula:
We call the resulting values standardized values, denoted as z. They can also be called z-scores.
z
y y s

Heptathlon: Kluft versus Skujyte
Carolina Kluft (Sweden)
Gold Medal
Austra Skujyte (Lithuania)
Silver Medal

Kluft versus Skujyte
Long jump shot put
mean 6.16m 13.29m
sd 0.23m 1.24m
Kluft 6.78m 14.77m
z-score 2.70 = (6.78-6.16)/0.23 1.19 = (14.77-13.29)/1.24
Skujyte 6.30m 16.40m
z-score 0.61 = (6.30-6.16)/0.23 2.51=(16.40-13.29)/1.24
Total z-score Kluft 2.70+1.19=3.89
Skujyte 0.61+2.51=3.12

Standardizing with z-scores (cont.)
Standardized values (z-scores) have no units.
z-scores measure the distance of each data value from the mean in standard deviations.
A negative z-score tells us that the data value is below the mean, while a positive z-score tells us that the data value is above the mean.

Benefits of Standardizing
Standardized values have been converted from their original units to the standard statistical unit of “standard deviations from the mean.” Thus we can compare values that are measured on different scales, or in different units.

Shifting DataAdding (or subtracting) a constant to every
data value adds (or subtracts) the same constant to measures of position.
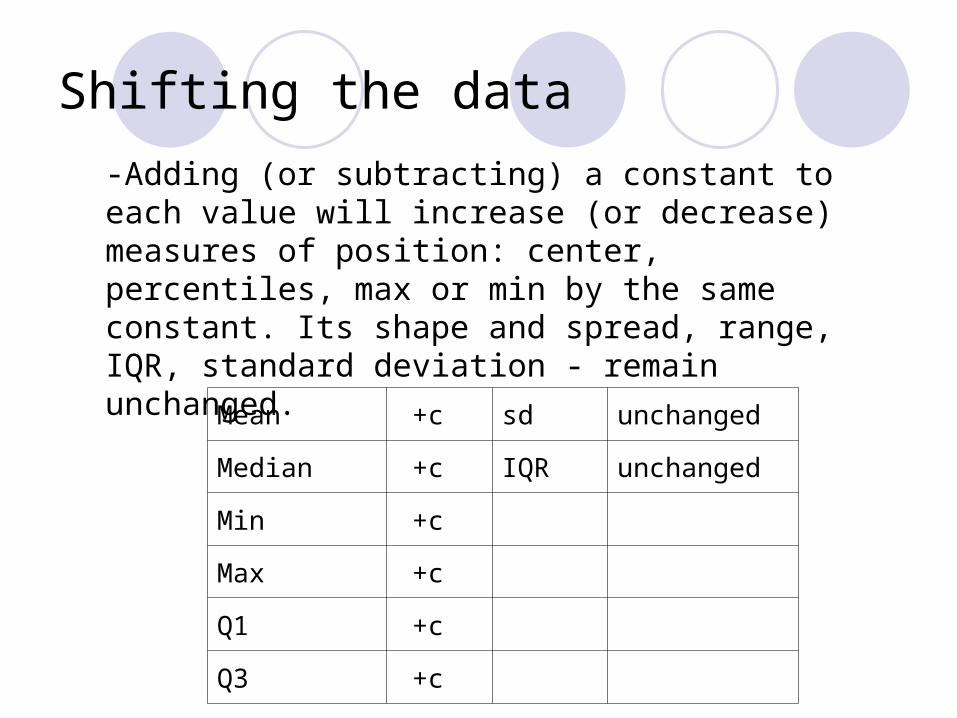
Shifting the data
Mean +c sd unchanged
Median +c IQR unchanged
Min +c
Max +c
Q1 +c
Q3 +c
-Adding (or subtracting) a constant to each value will increase (or decrease) measures of position: center, percentiles, max or min by the same constant. Its shape and spread, range, IQR, standard deviation - remain unchanged.
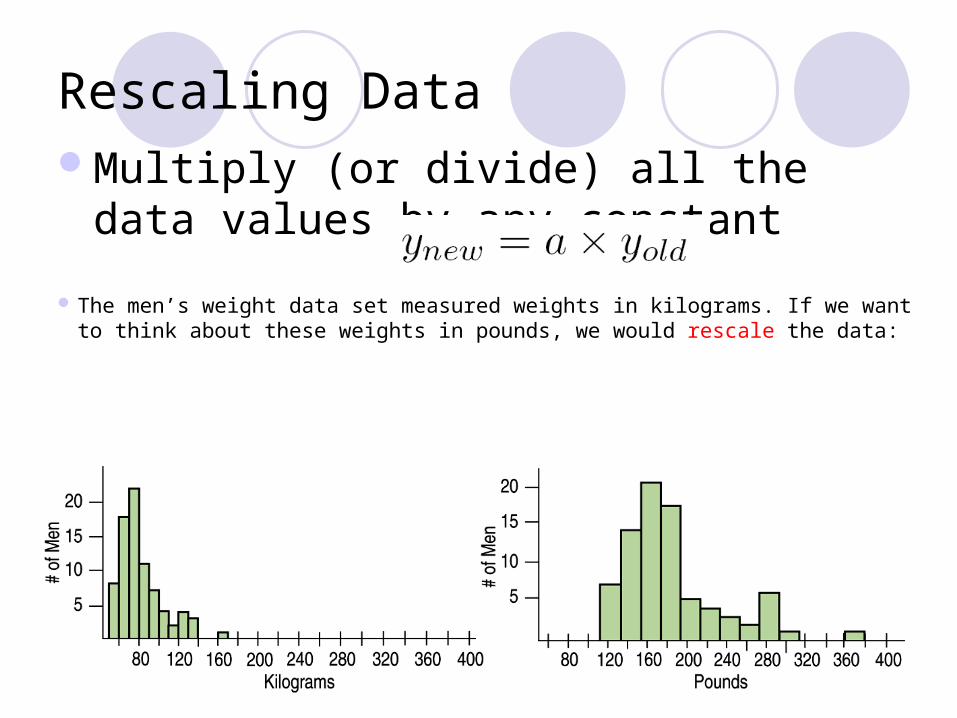
Rescaling DataMultiply (or divide) all the data values by
any constant
The men’s weight data set measured weights in kilograms. If we want to think about these weights in pounds, we would rescale the data:
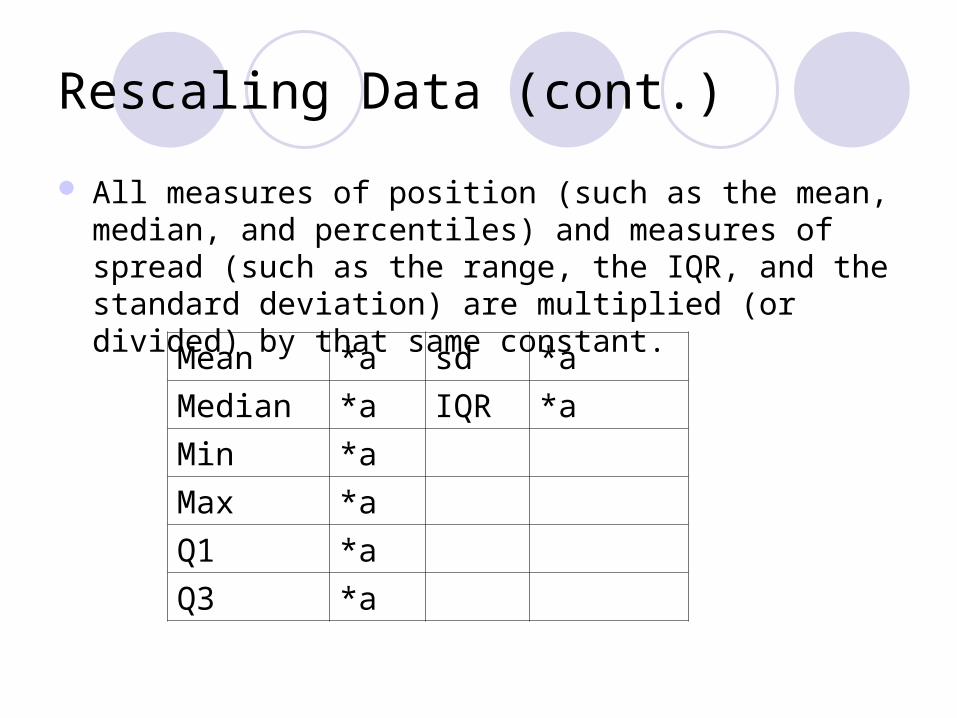
Rescaling Data (cont.)
All measures of position (such as the mean, median, and percentiles) and measures of spread (such as the range, the IQR, and the standard deviation) are multiplied (or divided) by that same constant.
Mean *a sd *a
Median *a IQR *a
Min *a Max *a Q1 *a Q3 *a

How does the standardization changes the distribution?
Standardizing data into z-scores shifts the data by subtracting the mean and rescales the values by dividing by their standard deviation.
Shape No change
Mean 0 after standardization
Standard deviation 1 after standardization

How should we read a z-score?
The larger a z-score is (negative or positive), the more unusual it is.
How do we evaluate how unusual it is?
Long jump shot put
mean 6.16m 13.29m
sd 0.23m 1.24m
Kluft 6.78m 14.77m
z-score2.70 = (6.78-
6.16)/0.231.19 = (14.77-
13.29)/1.24
Skujyte 6.30m 16.40m
z-score0.61 = (6.30-
6.16)/0.232.51=(16.40-
13.29)/1.24
Total z-
score
Kluft 2.70+1.19=3.89
Skujyte 0.61+2.51=3.12

Normal models Quantitative variables Unimodal & symmetric N(μ,σ)
μ : mean σ: sd Standard normal N(0,1)
Parameters (μ,σ) Statistics ( , )
z
y y s
If (μ,σ) are given,
If (μ,σ) are not given,

Data, Model
Data , StatisticsModel , Parameter
A tool to describe the data with a number of parameters
Questions related to the data can be answered by the value of the parameters
Estimate parameters by certain statistics Mean from the model, sample mean SD from the model, sample standard deviation Proportion parameter, sample proportion

When to use the Normal model?
When we use the Normal model, we are assuming the distribution is Normal. Nearly Normal Condition: The shape of the
data’s distribution is unimodal and symmetric. This condition can be checked with a histogram
or a Normal probability plot.
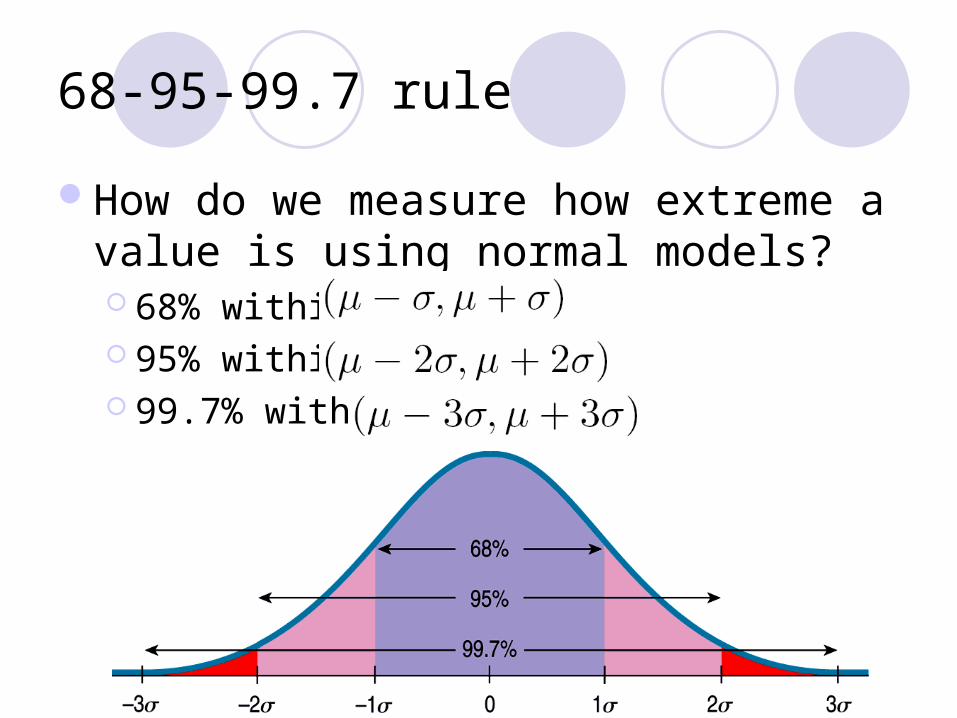
68-95-99.7 rule
How do we measure how extreme a value is using normal models? 68% within 95% within 99.7% within

Finding normal probability using TI-83
2nd + VARS (DISTR) normalcdf(lowerbound, upperbound, μ,σ)
If the data is from N(0,1), what is the chance to see a value between -0.5 and 1?
normalcdf(-0.5,1,0, 1) = 0.5328072082
If the data follow the N(1,1.5) distribution, what is the chance to see a value less or equal to 5?
normalcdf(-1E99, 5,1,1.5) = 0.9961695749

From probability to Z-scores
For a given probability, how do we find the corresponding z-score or the original data value.
Example: What is Q1 in a standard Normal model?
TI-83: invNorm(probability, μ,σ) invNorm(0.25,0,1) = -0.6744897495

Example: SAT score
A college only admits people with SAT scores among the top 10%. Assume that SAT scores follow the N(500,100) distribution. If you want to be admitted, how high your SAT score needs to be? invNorm(0.9,500,100) = 628.1551567

Finding the parameters
While only 5% of babies have learned to walk by the age of 10 months, 75% are walking by 13 months of age. If the age at which babies develop the ability to walk can be described by a Normal model, find the parameters? Z-score corresponding to 5%:
(10- μ)/ σ = invNorm(0.05,0,1) = -1.644853626 Z-score corresponding to 75%:
(13- μ)/ σ = invNorm(0.75,0,1) = 0.6744897495 Solve the two equations, we have
μ=12.12756806 σ=1.293469536
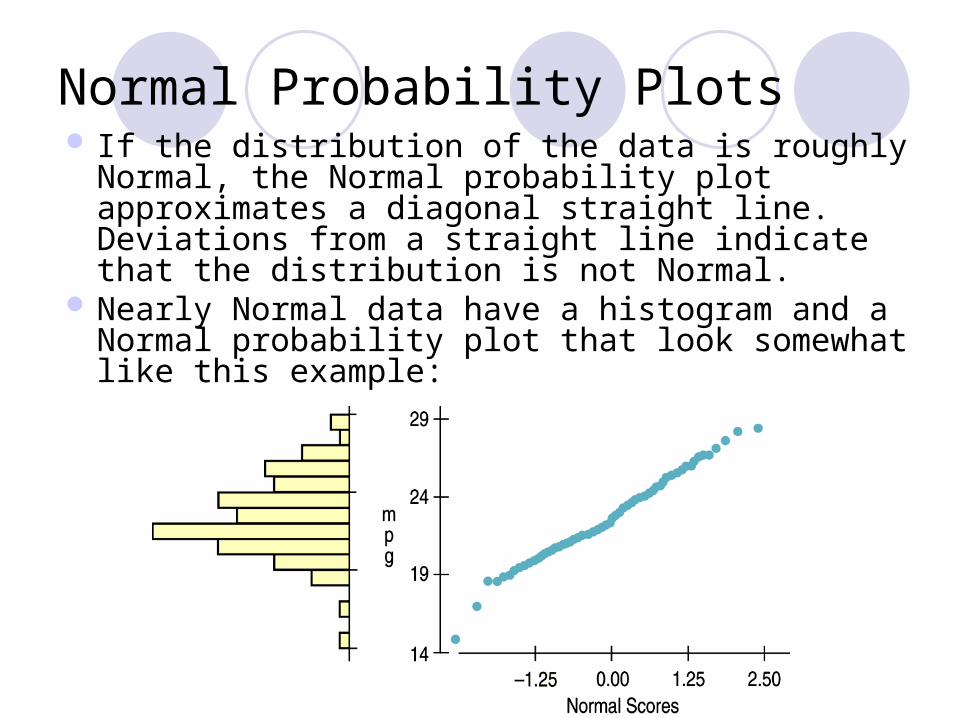
If the distribution of the data is roughly Normal, the Normal probability plot approximates a diagonal straight line. Deviations from a straight line indicate that the distribution is not Normal.
Nearly Normal data have a histogram and a Normal probability plot that look somewhat like this example:
Normal Probability Plots
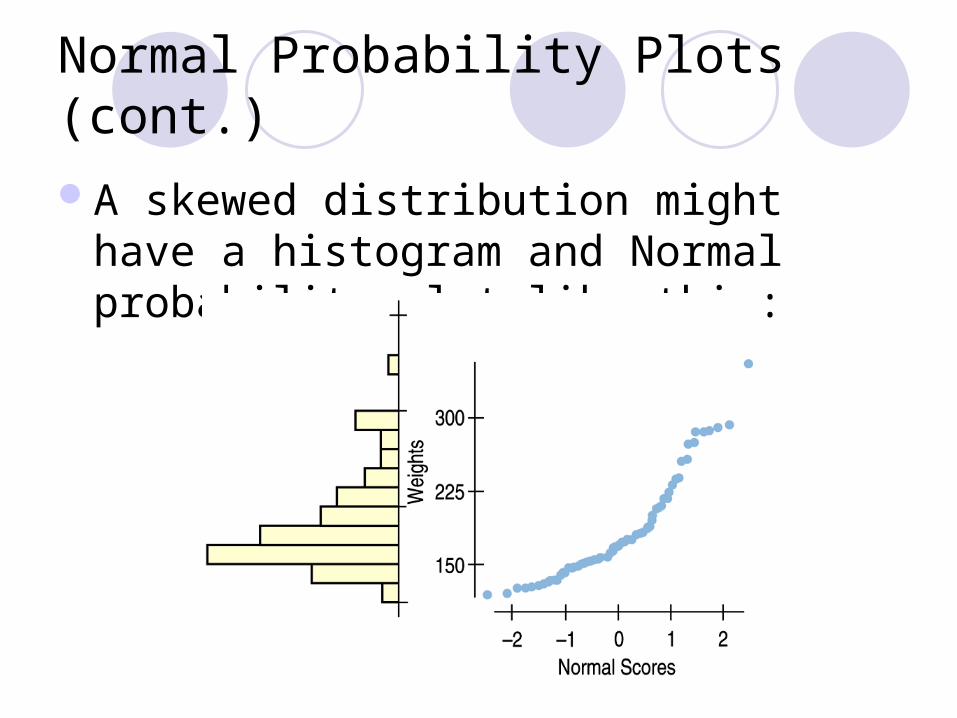
A skewed distribution might have a histogram and Normal probability plot like this:
Normal Probability Plots (cont.)

How to make Normal Probability Plots?
Suppose that we measured the fuel efficiency of a car 100 times
The smallest has a z-score of -3.16 If the data are normally distributed, the model
tells us that we should expect the smallest z-score in a batch of 100 is -2.58. This calculation is beyond the scope of this class.
Plot the point whose X-axis is for the z-scores given by the normal model and Y-axis is for that from the data
Keep doing this for every value in the data set If the data are normally distributed, the two
scores should be close, and graphically, all the points should be roughly on a diagonal line.
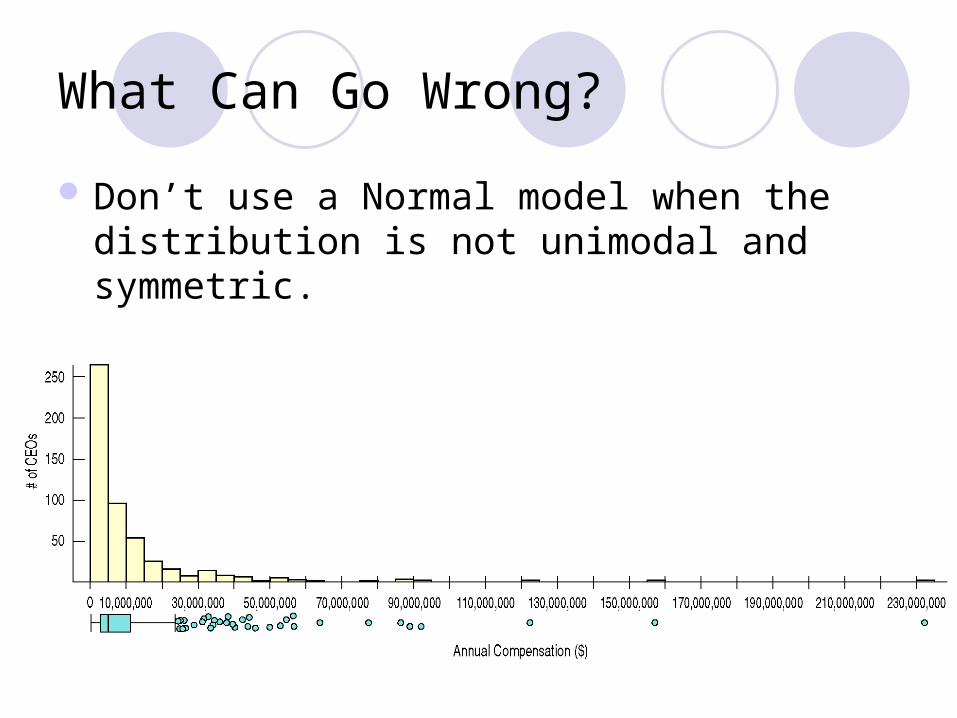
What Can Go Wrong?
Don’t use a Normal model when the distribution is not unimodal and symmetric.

What Can Go Wrong? (cont.)
Don’t use the sample mean and sample standard deviation when outliers are present—the mean and standard deviation can both be distorted by outliers.
Don’t round your results in the middle of a calculation.


















