
Chapter 29 Transcription and the Regulation of Gene Expression
116
Reginald H. Garrett Charles M. Grisham Chapter 29 Transcription and the Regulation of Gene Expression
description
Chapter 29 Transcription and the Regulation of Gene Expression. Outline. Central Dogma: DNA RNA Protein Gene transcription in prokaryotes. Regulated of transcription in prokaryotes. Gene transcription in eukaryotes. Gene regulatory protein recognition of specific DNA sequences. - PowerPoint PPT Presentation
Transcript of Chapter 29 Transcription and the Regulation of Gene Expression

Reginald H. GarrettCharles M. Grisham
Chapter 29Transcription and the Regulation of
Gene Expression

Outline
• Central Dogma: DNA RNA Protein• Gene transcription in prokaryotes. • Regulated of transcription in prokaryotes. • Gene transcription in eukaryotes. • Gene regulatory protein recognition of specific
DNA sequences. • Processing eukaryotic transcripts and delivering
them to the ribosomes for translation. • A proposal for a unified theory of gene
expression.

Cells Contain Three Major Classes of RNA
• mRNA, rRNA, tRNA and snRNA all participate in protein synthesis.
• All of these RNAs are synthesized from DNA templates by DNA-dependent RNA polymerases in a process called transcription.
• Only mRNAs direct the synthesis of proteins.• Transcription is tightly regulated in all cells. • Only 3% of genes in a typical eukaryotic cell are
undergoing transcription at any given moment. • The metabolic conditions and growth status of the
cell dictate which gene products are needed at any moment.

29.1 Genes Transcription in Prokaryotes
• In prokaryotes, virtually all RNA is synthesized by a single species of DNA-dependent RNA polymerase.
• RNA polymerases link NTPs (ATP, GTP, CTP, and UTP) in the order specified by base pairing with a DNA template.
• The RNA polymerase moves along the DNA strand in the 3'-5' direction and the RNA chain grows 5'-3' during transcription.
• Subsequent hydrolysis of PPi to inorganic phosphate by pyrophosphatases makes the polymerase reaction thermodynamically favorable.

Identifying Transcription Start Sites
• Transcription is initiated in prokaryotes by an RNA polymerase holoenzyme. It has the subunit composition: α2ββ'σ.
• α = scaffold and regulation• β = part of polymerase active site • β' = binds to and unwinds DNA• σ = binds to promoter for initiation. Note: there is a nonstoichiometric subunit, ω, of
unknown function in the holoenzyme that our author does not discuss, making: α2ββ'ωσ.

Identifying Transcription Start Sites
• The core polymerase is α2ββ' or α2ββ'ω.
• The core polymerase (without σ) can transcribe DNA into RNA, but cannot initiate transcription.
• Binding of the σ subunit allows the polymerase to recognize different DNA sequences that act as promoters. (E.coli has a number of different σ subunits which seek different promoters.)
• Promoters are nucleotide sequences that identify the location of transcription start sites, where transcription begins.
• RNA polymerases do not require a primer.

Conventions Used in Expressing the Sequences of Nucleic Acids and Proteins
• Certain conventions are used in describing information transfer from DNA to protein:
• The strand of duplex DNA that is read by RNA polymerase is termed the template stand.
• The strand not read is the nontemplate strand.• The template is read by the RNA polymerase
moving 3'-5' along the template DNA strand, so the RNA product, the transcript, grows in the 5'-3' direction.
• In procaryotes, polycistronic transcripts are common (1 promoter/several genes).

Conventions Used in Expressing the Sequences of Nucleic Acids and Proteins• By convention, when the order of nucleotides in DNA
is shown as a single strand, it is the 5'-3' sequence of nucleotides in the nontemplate strand that is shown or in dsDNA it is the top strand.
UpstreamDownstream
5' ------nontemplate strand (sense strand)……….3' 3' ------template strand (antisense strand)……….5'
There is no #0 in DNA; the transcription start site = +1• The nontemplate strand is the coding strand.• RNA formed has the same sequence as the sense
strand and is formed from the antisense strand.

Conventions Used in Expressing the Sequences of Nucleic Acids and Proteins

The Process of Transcription Has Four Stages
Transcription can be divided into four stages:
• Binding of RNA polymerase holoenzyme to template DNA at promoter sites.
• Initiation of polymerization. • Chain elongation. • Chain termination.
• These are the same steps that applied in replication.

Binding of Polymerase to Template DNA
• The holoenzyme (α2ββ'σ) binds nonspecifically to DNA with low affinity and migrates downstream looking for a σ promoter region. Kd = 10-6 to 10-9 M
• The σ subunit recognizes the promoter sequence and locks on. The holoenzyme and promoter form a "closed promoter complex" (DNA is not unwound). Kd = 10-6 to 10-9 M.
• Polymerase then unwinds about 12 pairs in the -9 to +3 region to form an "open promoter complex". Kd = 10-14 M.

RNA Polymerase and DNA
• α2ββ'σ + random DNA t1/2 = 3 sec
• α2ββ'σ + open promoter t1/2 = 2-3 hours
• α2ββ' + random DNA t1/2 = 60 min
• RNA polymerase binding protects a nucleotide sequence spanning the region from -70 to +20.
• Promoters recognized by the σ factor typically consist of a 40 bp region on the 5'-side of the transcription start site (+1) .

Prokaryotic Promoter Regions
• Within the promoter are two consensus sequence elements:
• The -35 region, (consensus TTGACA). The σ subunit appears to bind here. The more the -35 region sequence corresponds to the consensus sequence of the σ subunit, the greater is the efficiency of gene transcription.
• The Pribnow box near -10, (consensus TATAAT). This region is ideal for unwinding. It is rich in A and T, which only form two H bonds per base pair. This is also called the TATA box.

The Nucleotide Sequences of Representative E. coli Promoters
Figure 29.4 Consensus sequences for the -35 region, the Pribnow box, and the initiation site are shown at the bottom. The numbers represent the percent occurrence of the indicated base. In this figure, sequences are aligned relative to the Pribnow box.

Initiation of Polymerization
• RNA polymerase requires supercoiled dsDNA and Mg++. It copies only one DNA strand.
• RNA polymerase has two binding sites for NTPs • The initiation site prefers to bind ATP and GTP
(most RNAs begin with a purine at 5'-end).• The elongation site binds the second incoming
NTP. • 3'-OH of first attacks α-P of second to form a new
phosphoester bond (eliminating PPi). • Unwinding and synthesis of first residues is slow.
When a 6-10 unit oligonucleotide has been made, sigma subunit dissociates, completing "initiation“.
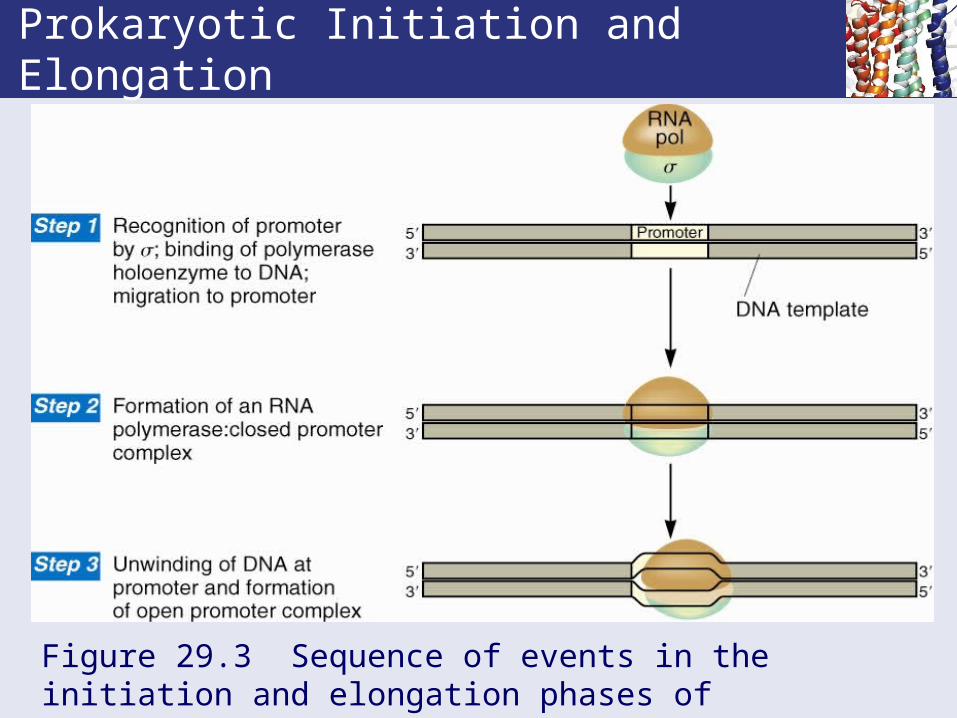
Prokaryotic Initiation and Elongation
Figure 29.3 Sequence of events in the initiation and elongation phases of transcription as it occurs in prokaryotes.
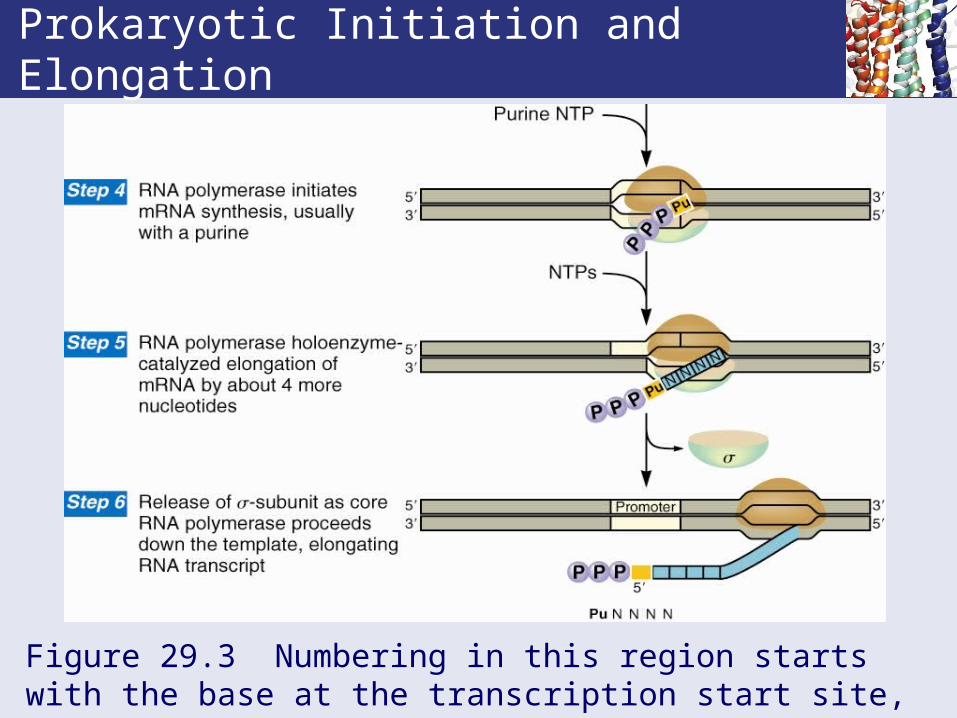
Prokaryotic Initiation and Elongation
Figure 29.3 Numbering in this region starts with the base at the transcription start site, which is designated +1.

Chain Elongation
• The core polymerase (without σ) is theelongation enzyme. NusA protein comes in after σ dissociation to prevent early termination.
• RNA polymerase is accurate - only about 1 error in about 104 - 106 bases.
• This error rate is acceptable, since many transcripts are made from each gene.
• Elongation rate is 20-50 bases per second. Slower in G/C-rich regions and faster in AT.
• Topoisomerases precede and follow polymerase to relieve supercoiling so the bubble size is constant.
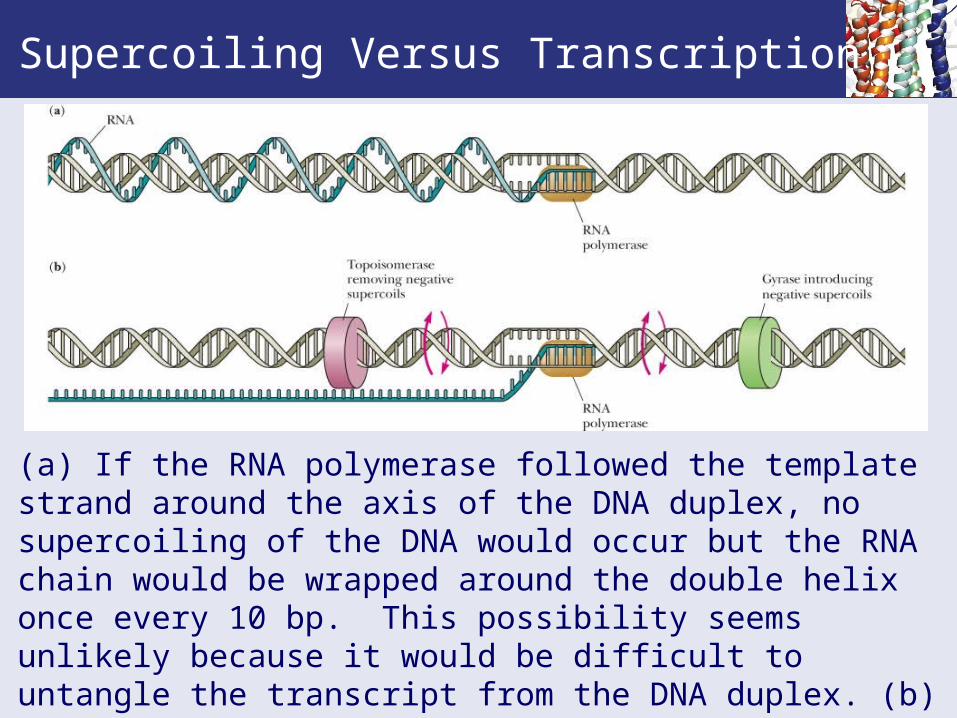
Supercoiling Versus Transcription
(a) If the RNA polymerase followed the template strand around the axis of the DNA duplex, no supercoiling of the DNA would occur but the RNA chain would be wrapped around the double helix once every 10 bp. This possibility seems unlikely because it would be difficult to untangle the transcript from the DNA duplex. (b) Alternatively, gyrases and topoisomerases lead and follow the bubble to remove the torsional stresses induced by transcription.

Chain Termination
• Two types of transcription termination mechanisms operate in bacteria:
• Rho termination factor (a protein):• rho is an ATP-dependent helicase.
• it binds at a specific recognition sequence in the transcript upstream of the termination site.
• it then moves along RNA transcript, finds the “transcription bubble", unwinds the RNA from the bubble and releases RNA chain.
• It is likely that the RNA polymerase stalls in a G:C rich termination region, allowing rho factor to overtake it.
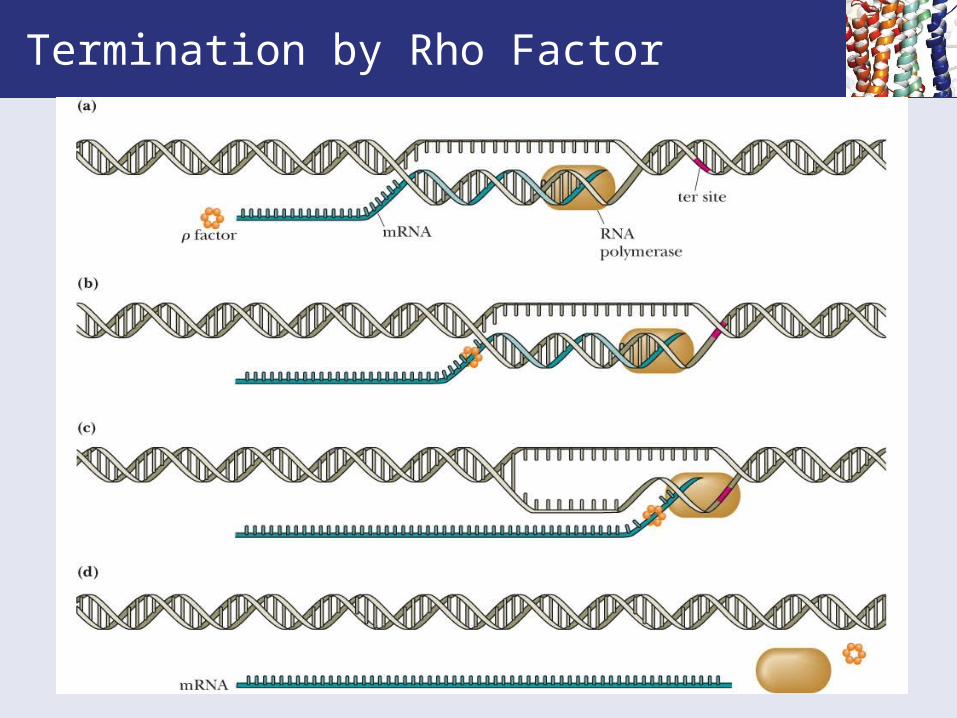
Termination by Rho Factor

Intrinsic Termination
• Intrinsic termination (hairpin):• In this case, termination is determined by
specific sequences (termination sites) in the DNA.
• Termination sites consist of 3 structural features.• inverted repeats, rich in G:C, which form a
stable stem-loop structure (hairpin) in RNA transcript.
• A nonrepeating segment that punctuates the inverted repeats.
• A run of 6-8 A in the DNA template, coding for U in the transcript.

Figure 29.7 Transcription termination by rho factor.Intrinsic Termination
The transcript forms a hairpin structure using the GC rich inverted repeat which gives tight binding. The short polyAT segment at the end of the transcription unit produces polyU in the transcript. These are loosely held and the transcript dissociates. NusA assists in pausing at the termination site.

29.2 – Regulation of Transcription in Prokaryotes
• Operon: A segment of DNA transcribed as a single mRNA strand (may be polycistronic) and includes the promoter and operator. An operon is also called a transcription unit.
• Promoter: Region of DNA where initiation occurs. Unique for a given transcription unit.
• Operator: A DNA sequence close the promoter regulates the transcription start.
• Regulatory proteins work with operators to control transcription of the genes.

The General Organization of Operons
Figure 29.8 Operons consist of transcriptional control regions and a set of related structural genes, all organized in a contiguous linear array along the chromosome. The transcriptional control regions are the promoter and the operator, which lie next to, or overlap, each other, upstream from the structural genes they control. Operators may lie at various positions relative to the promoter, either upstream or downstream. Expression of the operon is determined by access of RNA polymerase to the promoter, and occupancy of the operator by regulatory proteins influences this access. Induction activates transcription from the promoter; repression prevents it.

Transcription of Operons is Controlled by Induction and Repression
• Increased synthesis of enzymes in response to the presence of a metabolite is induction.
• Decreased synthesis in response to a metabolite is repression.
• Some substrates induce enzyme synthesis even though the enzymes can’t metabolize the substrate - these are gratuitous inducers - such as IPTG (isopropyl β-thiogalactoside).

IPTG is a Gratuitous Inducer
Figure 29.10 The structure of IPTG (isopropyl β-thiogalactoside).
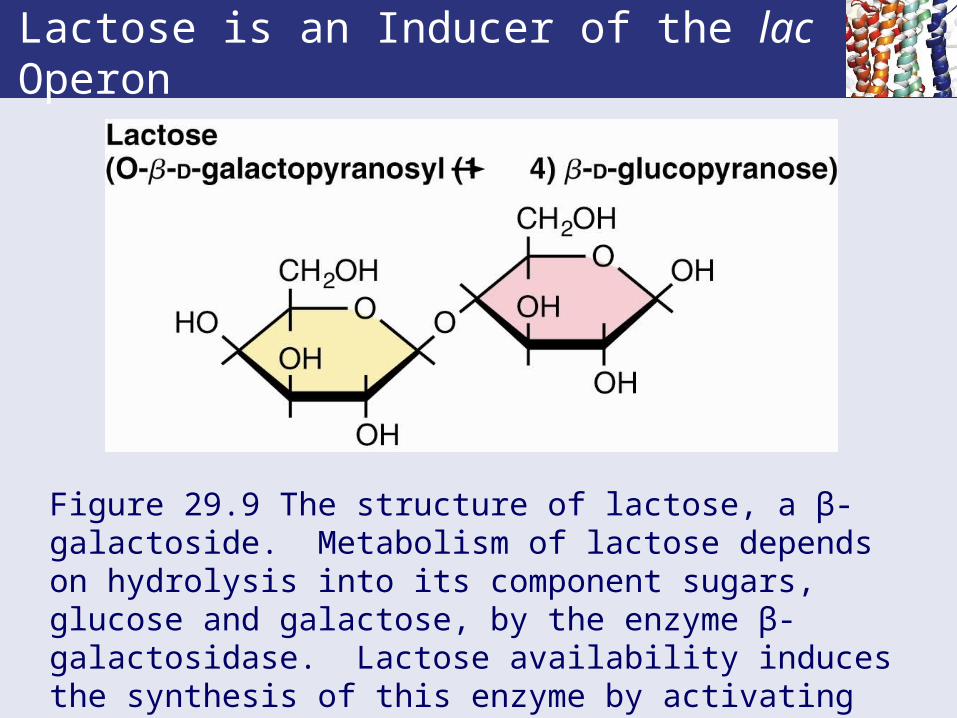
Lactose is an Inducer of the lac Operon
Figure 29.9 The structure of lactose, a β-galactoside. Metabolism of lactose depends on hydrolysis into its component sugars, glucose and galactose, by the enzyme β-galactosidase. Lactose availability induces the synthesis of this enzyme by activating transcription of the lac operon.

The lac Operon is a Pardigm of Operons
• lacI mutants express the genes needed for lactose metabolism.
• The structural genes of the lac operon are controlled by negative regulation.
• lacI gene product is the lac repressor, a tetrameric protein.
• The lac operator is a palindromic DNA segment.• lac repressor: a tetramer that has a DNA binding
domain on the N-terminus; the C-terminus binds inducer.

The lac Operon
Figure 29.11 The operon consists of two transcription units. In one unit, there are three structural genes, lacZ, lacY, and lacA, under control of the promoter, plac, and the operator O. In the other unit, there is a regulator gene, lacI, with its own promoter, placI.
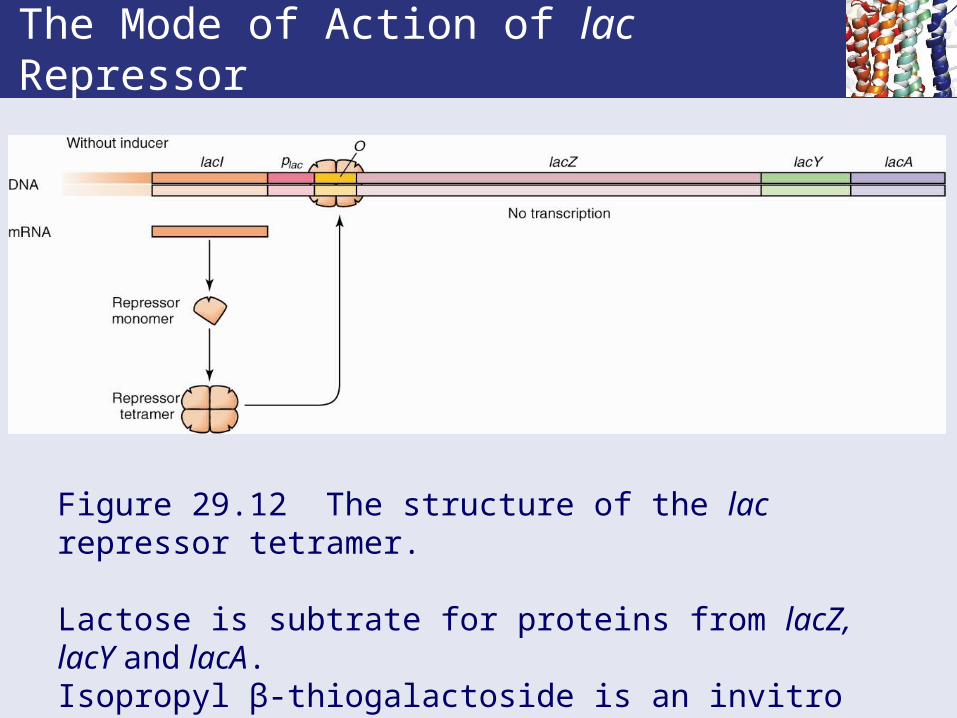
The Mode of Action of lac Repressor
Figure 29.12 The structure of the lac repressor tetramer.
Lactose is subtrate for proteins from lacZ, lacY and lacA. Isopropyl β-thiogalactoside is an invitro inducer.Allolactose is the invivo inducer.

The Mode of Action of lac Repressor
Figure 29.12 The structure of the lac repressor tetramer, with bound IPTG (purple) is also shown.
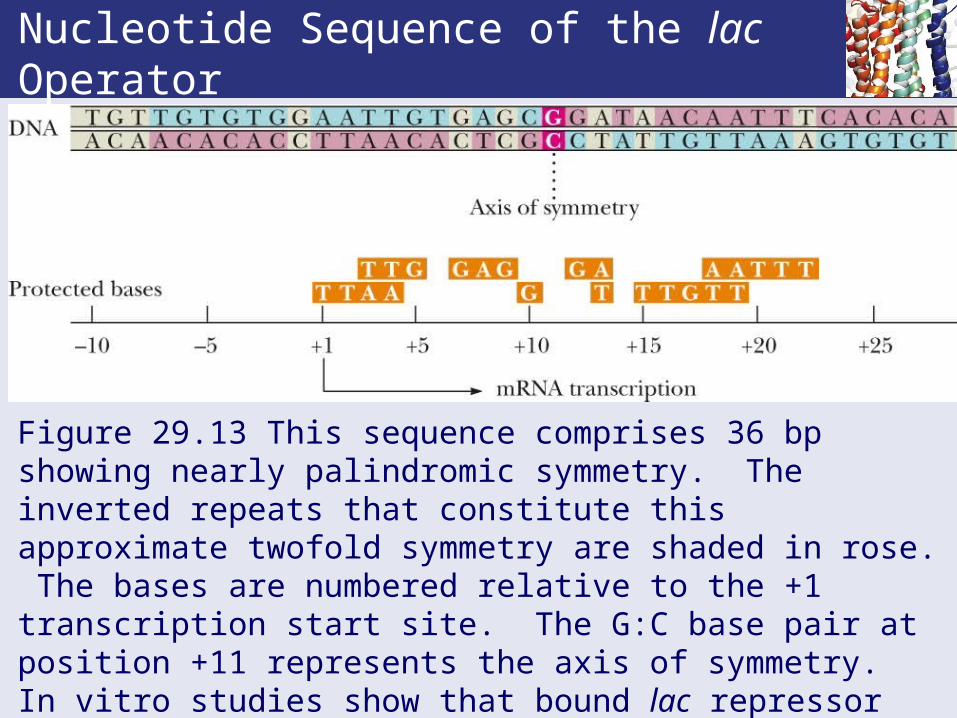
Nucleotide Sequence of the lac Operator
Figure 29.13 This sequence comprises 36 bp showing nearly palindromic symmetry. The inverted repeats that constitute this approximate twofold symmetry are shaded in rose. The bases are numbered relative to the +1 transcription start site. The G:C base pair at position +11 represents the axis of symmetry. In vitro studies show that bound lac repressor protects a 26 bp region from -5 to +21 against nuclease digestion. Bases that interact with bound lac repressor are indicated below the operator.

Lac Repressor Is a Negative Regulator of the lac Operon
* Kb = binding constant. † ratio of the two values.

Catabolite Activator Protein Provides Positive Control of the lac Operon
• Some promoters require an accessory protein to speed transcription.
• Catabolite activator protein or CAP is one such protein, a dimer of 22.5 kD peptides.
• N-terminus binds cAMP; C-terminus binds DNA.• Binding of CAP-(cAMP)2 to DNA assists formation
of closed promoter complex.• Catabolite repression is a global cell control based
on a favored substrate. It ensures that the operons necessary for metabolism of alternative energy sources (the lac and gal operons) remain repressed until the supply of glucose is exhausted.

The Mechanism of Catabolite Repression and CAP Action
Figure 29.14 The mechanism of catabolite repression and CAP action.Glucose promotes catabolite repression by lowering cAMP levels through control of phosphorylation/dephosphorylation. cAMP is necessary for CAP binding near promoters of operons whose gene products are involved in the metabolism of alternative energy sources such as lactose, galactose, and arabinose.

The Mechanism of Catabolite Repression and CAP Action
Figure 29.14 The mechanism of catabolite repression and CAP action. The binding sites for the CAP-(cAMP)2 complex are consensus DNA sequences containing the conserved pentamer TGTGA and a less well conserved inverted repeat, TCANA (where N is any nucleotide).

Summary of Control of the lac Operon
Glucose Repression Lactose LR/I Transcription /Activation
+ CR - LR None
+ CR + I Slow
- CAP - LR None
- CAP + I Rapid
Catabolite repression overrides inducer but CAP:cAMP does not override LR.

Negative and Positive Control Systems are Fundamentally Different
• Negative and positive control systems operate in fundamentally different ways.
• Genes under negative control are transcribed unless they are turned off by the presence of a repressor protein.
• Often, transcription activation is merely the release from negative control.
• In contrast, genes under positive control are expressed only in presence of an active regulator protein.

Negative and Positive Control Systems are Fundamentally Different
Figure 29.16 Control circuits governing the expression of genes.

Attenuation is a Prokaryotic Mechanism for Post-Translational Regulation of Expression
• In addition to repression, expression of the trp operon is controlled by transcription attenuation.
• Unlike the mechanisms discussed thus far, attenuation regulates transcription after it has begun and is coordinated with translation.
• Attenuation is any regulatory mechanism that manipulates transcription termination or transcription pausing to regulate gene transcription downstream.
• In prokaryotes, transcription and translation are coupled, and the translating ribosome is affected by the formation and persistence of secondary structure in the mRNA.

DNA: Protein & Protein: Protein Interactions are Essential to Transcription Regulation• DNA: protein interactions are a central feature in
transcriptional control.• The DNA sites where regulatory proteins bind
commonly display at least partial dyad symmetry or inverted repeats.
• DNA-binding proteins themselves are generally even-numbered oligomers (dimers, tetramers, etc.) that have innate twofold rotational symmetry.
• Protein: protein interactions are an essential component of transcriptional activation.
• Proteins that activate transcription work through protein: protein contacts with RNA polymerase.

DNA Looping Allows Multiple DNA-Binding Proteins to Interact With One Another• Because transcription must respond to a variety of
regulatory signals, multiple proteins are essential for appropriate regulation of gene expression.
• These regulatory proteins are the sensors of cellular circumstances.
• They communicate this information to the genome by binding at specific nucleotide sequences.
• But DNA is a one-dimensional polymer, with limited space for proteins to bind.
• DNA looping permits additional proteins to convene at the initiation site and to exert their influence on creating and activating the initiation complex.

DNA Looping Allows Multiple DNA-Binding Proteins to Interact With One Another
Figure 29.22 Formation of a DNA loop delivers DNA-bound transcriptional activator to RNA polymerase positioned at the promoter. Protein: protein interactions between the transcriptional activator and RNA polymerase activate transcription.

29.3 Gene Transcription in Eukaryotes
• There are three classes of RNA polymerases (I, II and III) which transcribe rRNA, mRNA and tRNA genes, respectively. • Pol I is in the nucleolus and transcribes rRNA
genes.• Pol II is in the nucleoplasm and makes hnRNA
(pre-mRNA) for proteins and some snRNA.• Pol III is in the nucleoplasm and makes tRNA,
5S rRNA, U6 snRNA and some others. • All 3 are large, multimeric proteins (500-700 kD).

29.3 Gene Transcription in Eukaryotes
• All have 2 large subunits with sequences similar to and ' in E.coli RNA polymerase, so catalytic site may be conserved.
• All three need transcription factors. These are different except for TATA binding protein (TBP).
• Pol II is most sensitive to -amanitin, an octapeptide from Amanita phalloides ("destroying angel mushroom").
• Pol III is less sensitive to -amanitin. • Pol I is insensitive to the toxin.
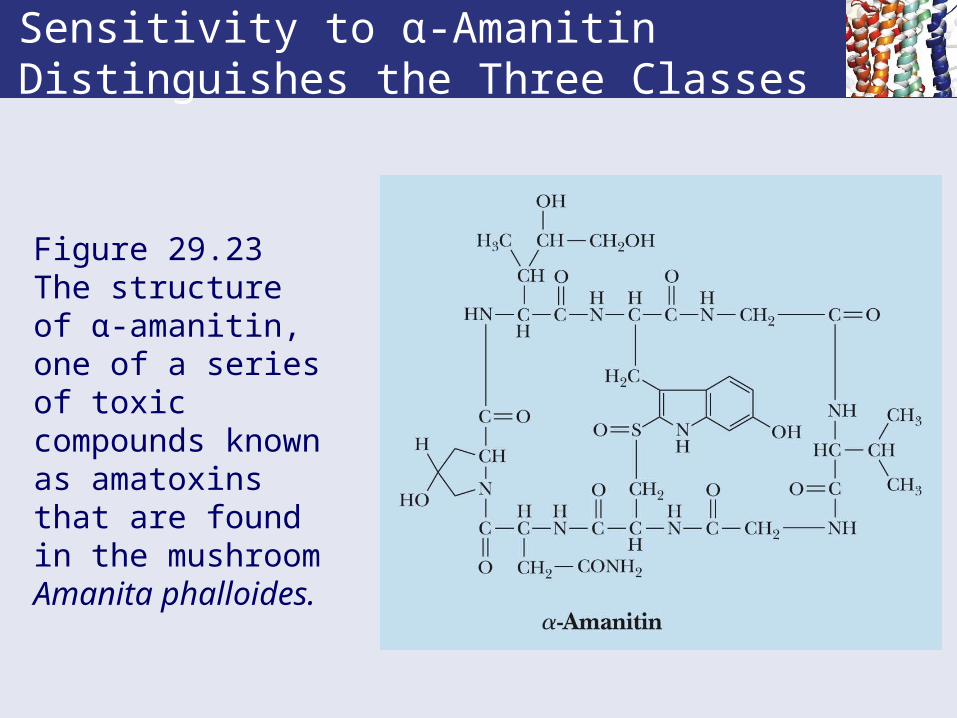
Sensitivity to α-Amanitin Distinguishes the Three Classes
Figure 29.23 The structure of α-amanitin, one of a series of toxic compounds known as amatoxins that are found in the mushroom Amanita phalloides.

• With three categories of polymerases acting on three sets of genes for three RNAs, there are also at least three categories of promoters that are used to maintain specificity.
• Eukaryotic promoters are different from prokaryotic promoters.
• All three eukaryotic RNA polymerases interact with their promoters via transcription factors.
• Transcription factors are DNA-binding proteins that recognize and accurately initiate transcription at specific promoter sequences.
29.3 Gene Transcription in Eukaryotes

RNA Polymerase II Transcribes Protein-Coding Genes
• RNA Pol II must be capable of transcribing a great diversity of genes, but must also function at any moment only on the genes whose products are appropriate to the needs of the cell.
• The RNA Pol II enzymes from yeast and humans are homologous. The structure of RNA Pol II from yeast is known and consists of 12 polypeptides.
• The 12 subunits of yeast RNA Pol II (RPB1 - RPB12) are listed in Table 29.2.
• RNA polymerases adopt a claw-like structure, to grasp the DNA duplex.

RNA Polymerase II Transcribes Protein-Coding Genes
• The CTD of Pol II (RPB1) contains many repeats of the heptad sequence: YSPTSPS• CTD = carboxy terminal domain• NTD = amino terminal domain
• This sequence in the CTD has many OH groups which are potential phosphorylation sites. Only RNA Pol II whose CTD is NOT phosphorylated can initiate transcription.
• TATA box (TATAAA) is a consensus promoter.

RNA Polymerase II Transcribes Protein-Coding Genes
* A similar Pol II is in Humans. † RNA polymerase B (~Pol II )

The Regulation of Gene Expression is More Complex in Eukaryotes
• Regulatory elements in eucaryotes: • Promoters: contain short conserved sequences
usually upstream of the initiation site, where general transcription factors bind.
• Enhancers (for activators) or Silencers (for repressors): more distantly located regulatory elements called upstream activation sequences (UAS).
• Response Elements: sequences near promoter that respond to a physiological signal or challenge.

The Site of Transcription Initiation Includes an Initiator (Inr) and a TATA Box
Figure 29.25 The Inr (initiator) and TATA box in selected eukaryotic genes. The consensus sequence of a number of such promoters is presented in the lower part of the figure, the numbers giving the percent occurrence of various bases at the positions indicated.

Promoter Regions of Several Representative Eukaryotic Genes
Figure 29.26

Promoter Regions of Several Representative Eukaryotic Genes
DNA looping permits multiple proteins to bind to DNA sequences.

Response Elements are Promoter Modules Responsive to Common Regulation• Promoter modules in genes responsive to common
regulation are termed response elements.• Examples include: • the heat shock element (HSE),• the glucocorticoid response element (GRE) and• the metal response element (MRE).
• Many genes are subject to multiple regulatory influences.
• Regulation of such genes is achieved through the presence of an array of different regulatory elements.
• The metallothionein gene is a good example (Figure 29.27).

Response Elements are Promoter Modules Responsive to Common Regulation

Metallothionein Gene
Figure 29.27 The metallothionein gene possesses several constitutive elements in its promoter (the TATA and GC boxes) as well as specific response elements such as MREs and a GRE. The BLEs are elements involved in basal level expression (constitutive expression). TRE is a tumor response element activated in the presence of tumor-promoting phorbol esters such as TPA (tetradecanoyl phorbol acetate).

Transcription Initiation by RNA Pol II
• The eukaryotic transcription initiation complex for mRNA consists of:
• RNA polymerase II.• Five general transcription factors (GTFs).• TATA binding protein (TBP)• A 20-subunit complex called Mediator (Srb/Med).• The CTD of Pol II anchors Mediator.• Mediator allows Pol II to communicate with
transcriptional activators bound at sites distant from the promoter.

Transcription Initiation by RNA Polymerase II Requires TBP and the GTFs
There are a total of six RNA Pol II general transcription factors (GTFs). Five of these are needed for transcription: TFIIB, TFIID, TFIIE, TFIIF and TFIIH. The other factor, TFIIA, is used for stabilization.RNA Pol III has three GTFs: TFIIIA, TFIIIB and TFIIIC (not shown).

Figure 29.28 Transcription initiation. (a) Model of the TATA-binding protein (TBP, gold) in complex with a DNA TATA sequence. (b) Formation of a preinitiation complex at a TATA-containing promoter.
Transcription Initiation

The Role of Mediator in Transcription Activation and Repression• Transcription activation requires Mediator which is a
bridge between gene-specific transcription co-activators bound to enhancers and the RNA polymerase II/GTF transcription machinery bound at the promoter.
• Once DNA is accessible (through chromatin remodeling), a transcription co-activator binds to an enhancer and recruits Mediator to the gene.
• Mediator promotes the binding of GTFs and RNA polymerase II at the promoter.
• Mediator is 1 million daltons in mass, with a core comprised of about 20 distinct subunits in yeast and 30 subunits in humans.
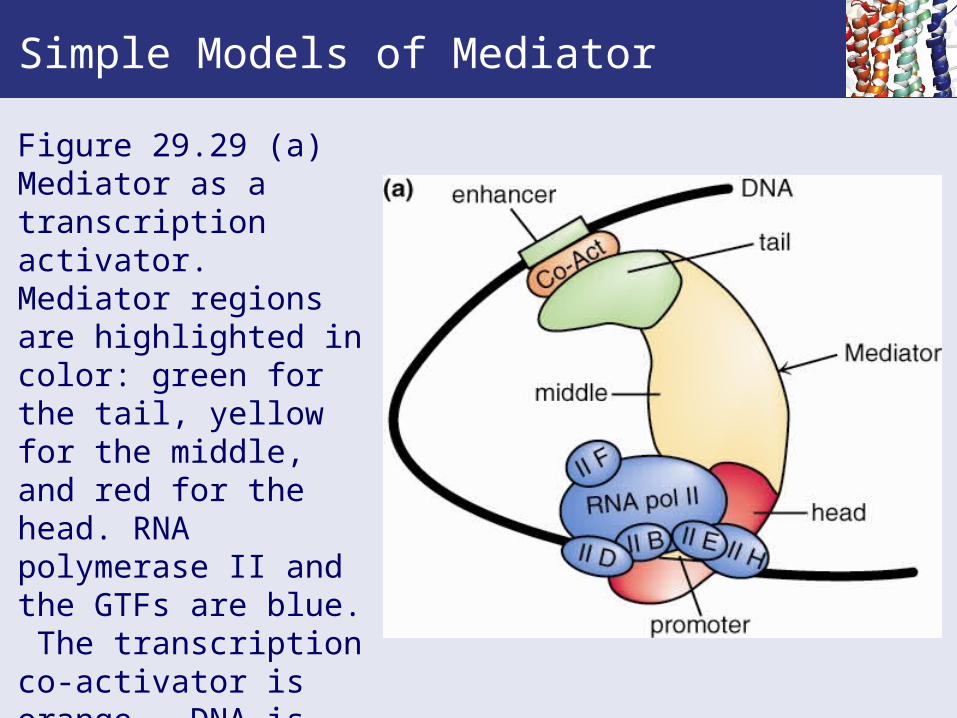
Simple Models of Mediator
Figure 29.29 (a) Mediator as a transcription activator. Mediator regions are highlighted in color: green for the tail, yellow for the middle, and red for the head. RNA polymerase II and the GTFs are blue. The transcription co-activator is orange. DNA is shown as a black line.
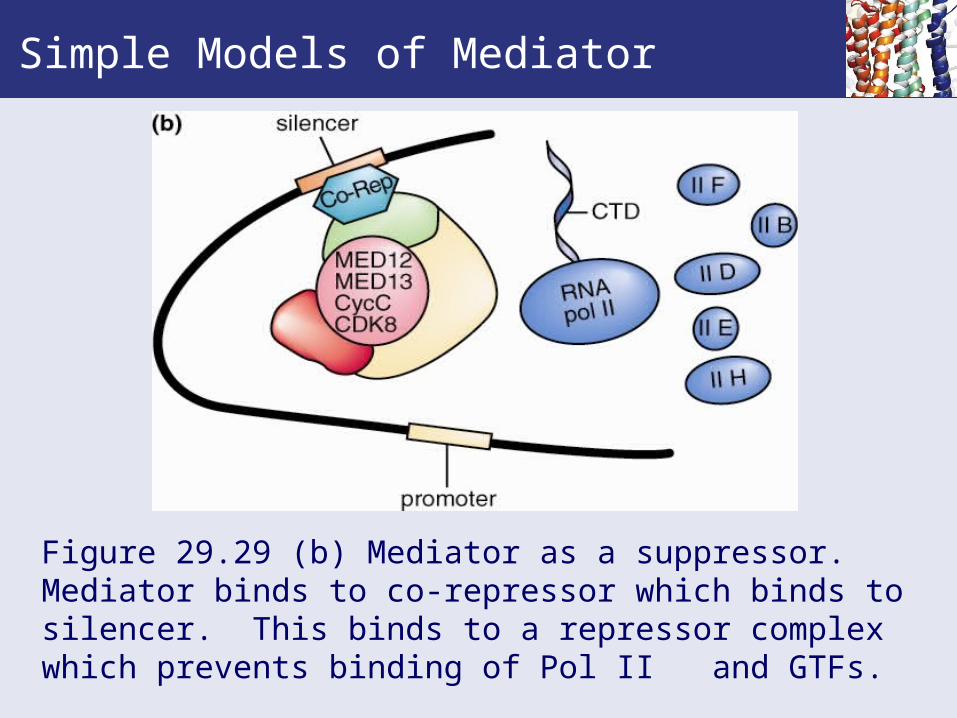
Figure 29.29 (b) Mediator as a suppressor.Mediator binds to co-repressor which binds to silencer. This binds to a repressor complex which prevents binding of Pol II and GTFs.
Simple Models of Mediator

Adjusting Nucleosomes for Transcription
• The central structural unit of nucleosomes, the histone “core octamer”, is constructed from the eight histone-fold protein domains of the eight various histone monomers comprising the octamer.
• Interactions between histone tails contributed by core histones in adjacent nucleosomes are an important influence in establishing higher orders of chromatin organization.
• Activation of eukaryotic transcription depends on:• Relief from repression imposed by chromatin
structure.• Interaction of RNA polymerase II with promoter
and transcription regulatory proteins.

Chromatin-Remodeling Complexes Alleviate Repression Due to Nucleosomes
• Two sets of factors are important to eukaryotic transcription:
• Chromatin-remodeling complexes that mediate ATP dependent conformational changes in nucleosome structure to make access easier.
• Histone-modifying enzymes that introduce covalent modifications into the N-terminal tails of the histone core octomer.
• Chromatin remodeling and histone modification are closely linked processes.

Chromatin-Remodeling Complexes Alleviate Repression Due to Nucleosomes
• Chromatin-remodeling complexes are nucleic-acid –stimulated multisubunit ATPases.
• Chromatin-remodeling complexes are enormous (MW = 1 megadalton).
• These assemblies serve to loosen the DNA:protein interactions in nucleosomes by sliding, ejecting, inserting, or otherwise restructuring core.
• Chromatin is remodeled through the actions of enzymes that covalently modify side chains on histones within the core octamer.

Covalent Modification of Histones
• Initial events in transcriptional activation include acetylCoA-dependent acetylation of ε-amino groups on lysine residues in histone tails by histone acetyltransferases (HATs).
• Phosphorylation of Ser residues and methylation of Lys residues in histone tails also contribute to transcription regulation.
• Attachment of small proteins to histone C-terminal Lys residues through ubiquitination and sumolyation are two other forms of covalent modification.

Diagram of the nucleosome.
Figure 29.30 Nucleosome diagram.

Covalent Modification of Histones Forms the Basis of the Histone Code• A code based on histone-tail covalent modifications
determines gene expression through selective recruitment of proteins.
• Proteins that cause chromatin compaction (heterochromatin formation) lead to repression.
• Proteins giving easier access to DNA through relaxation of histone:DNA interactions favor the possibility of gene expression.
• Prominent forms of histone covalent modification are lysine acetylation, lysine methylation, serine phosphorylation, lysine ubiquitination, and lysine sumoylation.

Methylation and Phosphorylation Act as a Binary Switch in the Histone Code• As cells enter mitosis, the chromatin becomes
condensed and histone H3 is not only methylated at K9 and phosphorylated at the adjacent serine, S10.
• S10 phosphorylation triggers dissociation of HP1 from the heterochromatin.
• Thus phosphorylation next to K9 trumps HP1 binding.• Similarly phosphorylation of Thr (T3) neighboring K4 in
the histone H3 tail evicts CHD1 from its site on the methylated K4.
• Lysine methylation is the “on” position for the binary switch that recruits proteins to the histone tail and phosphorylation at a neighboring residue turns the switch to “off” by ejecting the bound proteins.

Nucleosome Alteration and Interaction of RNA Polymerase II are Essential• Gene activation (initiation of transcription) requires two
principal steps:
(1)Alterations in nucleosomes (and thus chromatin) that relieve the general repressed state imposed by chromatin structure, then:
(2)The interaction of RNA polymerase II and the GTFs with the promoter.
• Transcription activators initiate the process by recruiting chromatin-altering proteins (the chromatin-remodeling complexes and histone-modifying enzymes).
• Once these have occurred, promoter DNA is accessible to TBP:TFIID, other GTFs, and RNA Pol II.

Figure 29.30 Diagram of the nucleosome.
• The following slide shows a schematic diagram of the nucleosome, illustrating the various covalent modifications on the n-terminal tails of histones:• Ack = acetylated lysine residue.• meK = methylated lysine residue.• meR = methylated arginine residue.• PS = phosphorylated serine residue.
• The numbers indicate the positions of the amino acids in the amino acid sequences. Note the prevalence of modifiable sites, particularly acetylatable lysine, on the N-terminal tails of histones H2B, H3, and H4.
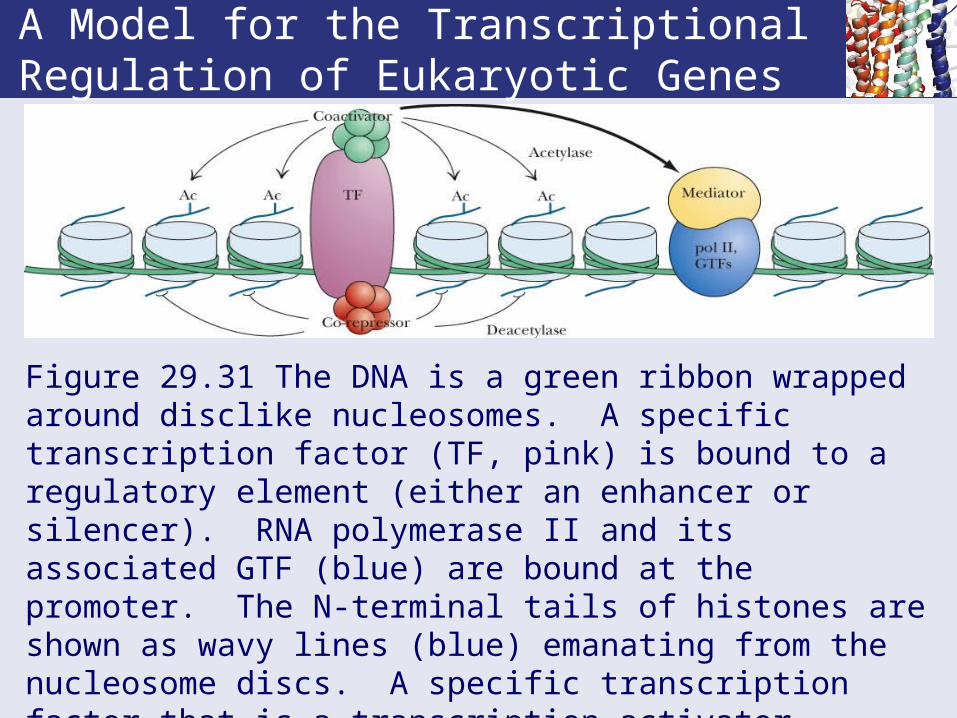
A Model for the Transcriptional Regulation of Eukaryotic Genes
Figure 29.31 The DNA is a green ribbon wrapped around disclike nucleosomes. A specific transcription factor (TF, pink) is bound to a regulatory element (either an enhancer or silencer). RNA polymerase II and its associated GTF (blue) are bound at the promoter. The N-terminal tails of histones are shown as wavy lines (blue) emanating from the nucleosome discs. A specific transcription factor that is a transcription activator stimulates transcription through interactions with a co-activator whose HAT activity renders DNA more accessible.

29.4 How Do Gene Regulatory Proteins Recognize Specific DNA Sequences?
• Proteins that recognize nucleic acids do so by the basic rule of macromolecular recognition:
• They present a three-dimensional shape that is structurally and chemically complementary to the surface of a DNA sequence.
• Protein contacts with the bases of DNA usually occur within the major groove of the DNA (but not always).
• Protein contacts with DNA involve H bonding and salt bridges with electronegative oxygen atoms of the phosphodiester linkages.

29.4 How Do Gene Regulatory Proteins Recognize Specific DNA Sequences?
• 80% of DNA-binding proteins below to one of three principal classes based on their structures:• The helix-turn-helix (HTH) motif.• The zinc-finger (or Zn-finger) motif.• The Leucine zipper-basic region (or bZIP).
• Alpha helices fit into the major groove of B-DNA.• The α-helix and B-form DNA are the predominant
structures involved in protein:DNA interactions.

Alpha Helices and DNA
A perfect fit
• A recurring feature of DNA-binding proteins is the presence of -helical segments that fit directly into the major groove of B-form DNA.
• Diameter of the -helix is 1.2 nm (including amino acid side-chains).
• Major groove of DNA is about 1.2 nm wide and 0.6 to 0.8 nm deep.
• Proteins can recognize and bind to specific sites in DNA.

Proteins With the Helix-Turn-Helix Motif Use One Helix to Recognize DNA
• The HTH motif is a protein structural domain consisting of two successive α-helices separated by a sharp β-turn (Figure 29.32).
• All contain two alpha helices separated by a loop with a beta turn.
• The C-terminal helix (denoted helix 3) fits in major groove of DNA; the N-terminal helix (helix 2) creates a stable structural domain by hydrophobic interactions with helix 3 that lock helix 3 into its DNA interface.
• Recognition of DNA sequence involves the sides of base pairs that face the major groove.

Proteins With the Helix-Turn-Helix Motif Use One Helix to Recognize DNA
• An HTH motif example: antp is a member of a family of eukaryotic proteins involved in the regulation of early embryonic development that have in common an amino acid sequence element known as the homeobox domain.
• The homeobox is a DNA motif that encodes a 60-residue sequence (the homeobox) found among proteins of virtually every eukaryote.
• The homeobox domain contains an HTH motif.• Homeobox domain proteins are sequence-specific
transcription factors.
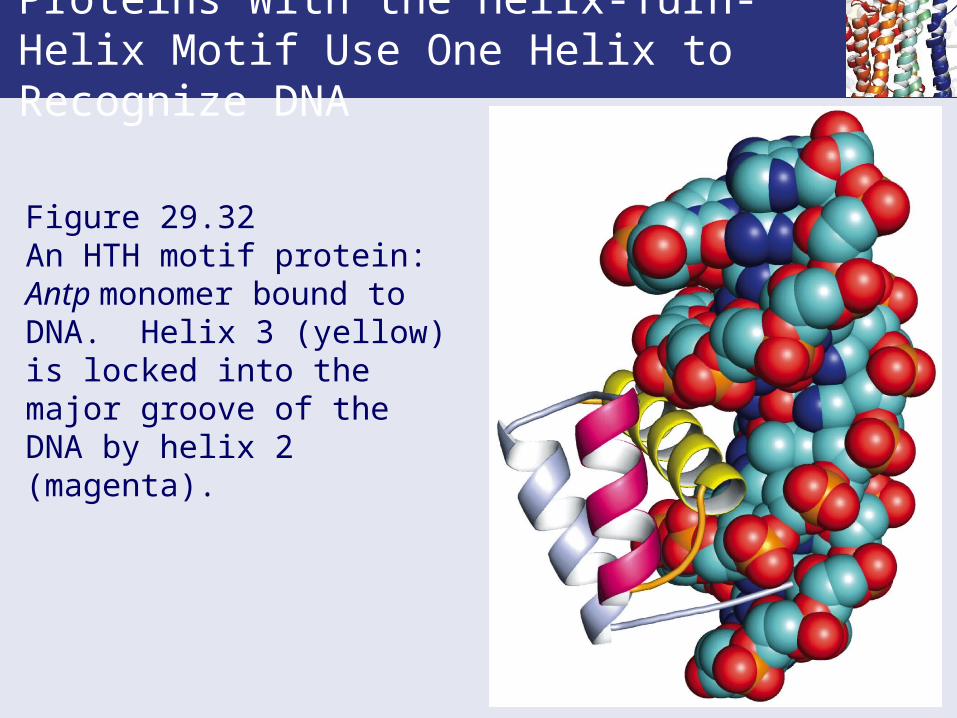
Proteins With the Helix-Turn-Helix Motif Use One Helix to Recognize DNA
Figure 29.32 An HTH motif protein: Antp monomer bound to DNA. Helix 3 (yellow) is locked into the major groove of the DNA by helix 2 (magenta).

Some Proteins Bind to DNA via Zn-Finger Motifs
First discovered in TFIIIA from Xenopus laevis, the African clawed toad
• Zn-finger motifs exist in nearly all organisms. • Two main classes: C2H2 and Cx.• C2H2 domains consist of Cys-x2-Cys and His-x3-His
domains separated by at least 7-8 amino acids.• This motif can be repeated as many as 13 times
throughout the primary structure of a Zn-finger protein.
• Cx domains consist of 4, 5 or 6 Cys residues separated by various numbers of other residues. • The Cx proteins have a variable number of Cys
residues available for Zn chelation.
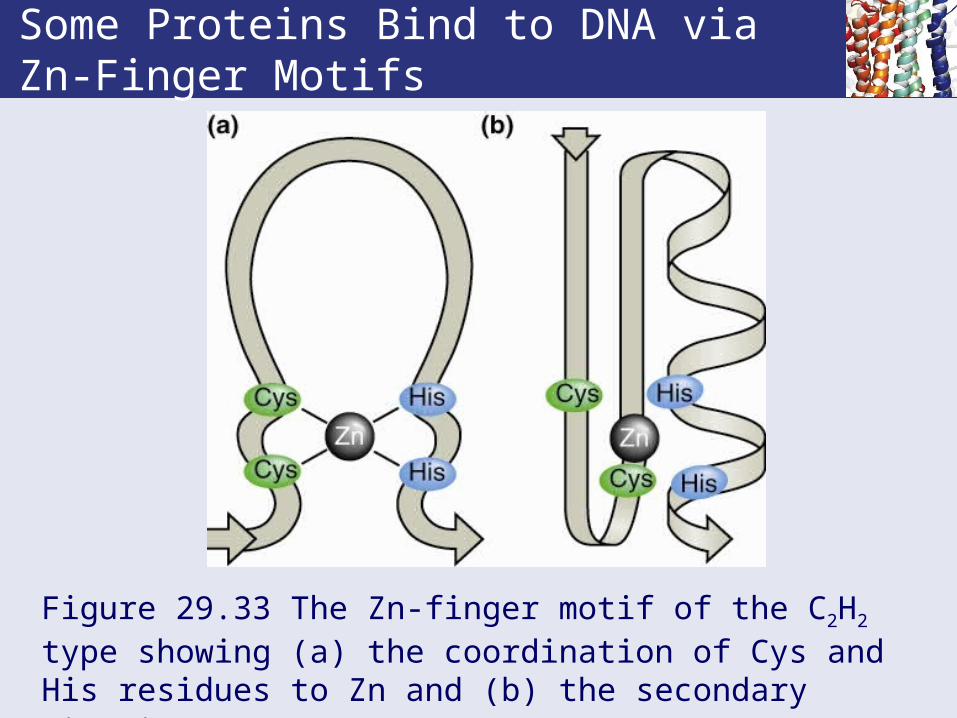
Some Proteins Bind to DNA via Zn-Finger Motifs
Figure 29.33 The Zn-finger motif of the C2H2 type showing (a) the coordination of Cys and His residues to Zn and (b) the secondary structure.
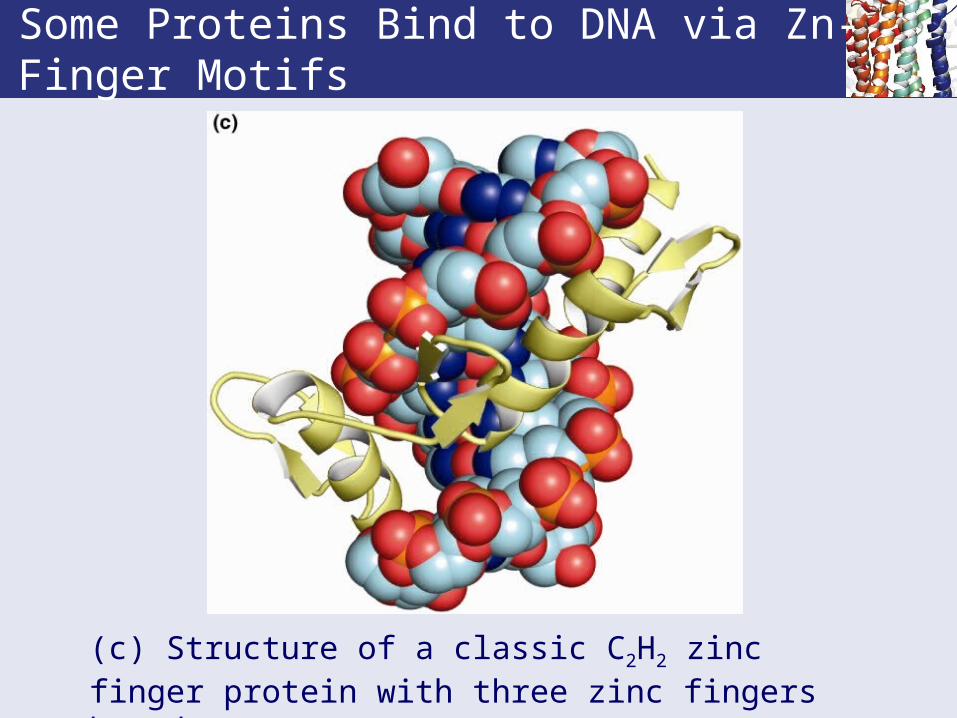
Some Proteins Bind to DNA via Zn-Finger Motifs
(c) Structure of a classic C2H2 zinc finger protein with three zinc fingers bound to DNA.

Some Proteins Bind to DNA via Zn-Finger Motifs
• Comparison of secondary and tertiary structures.• C2H2 -type Zn fingers form a folded beta strand
and an alpha helix that fits into the DNA major groove.
• Cx-type Zn fingers consist of two mini-domains of four Cys ligands to Zn followed by an alpha helix: the first helix is the DNA recognition helix, second helix packs against the first.

Some DNA-Binding Proteins Use a Basic Region Leucine Zipper (bZIP) Motif
First found in C/EBP, a DNA-binding protein in rat liver nuclei
• The Leucine zipper is found in nearly all organisms.
• Characteristic features: a 28-residue sequence with Leu every 7th position and a "basic region".
• What do you know by now about 7-residue repeats ?
• This suggests amphipathic alpha helices and a coiled-coil dimer (see Chapter 6, page 148).

Model for a Dimeric bZIP Protein
Figure 29.34 BR-A and BR-B are basic regions A and B.

The Structure of the Leucine Zipper
Its DNA complex
• Leucine zipper proteins (aka bZIP proteins) dimerize, either as homo- or hetero-dimers.
• The basic region is the DNA-recognition site. • Basic region is often modeled as a pair of helices
that can wrap around the major groove. • Homodimers recognize dyad-symmetric DNA. • Heterodimers recognize non-symmetric DNA. • Fos and Jun heterodimers are classic bZIPs.
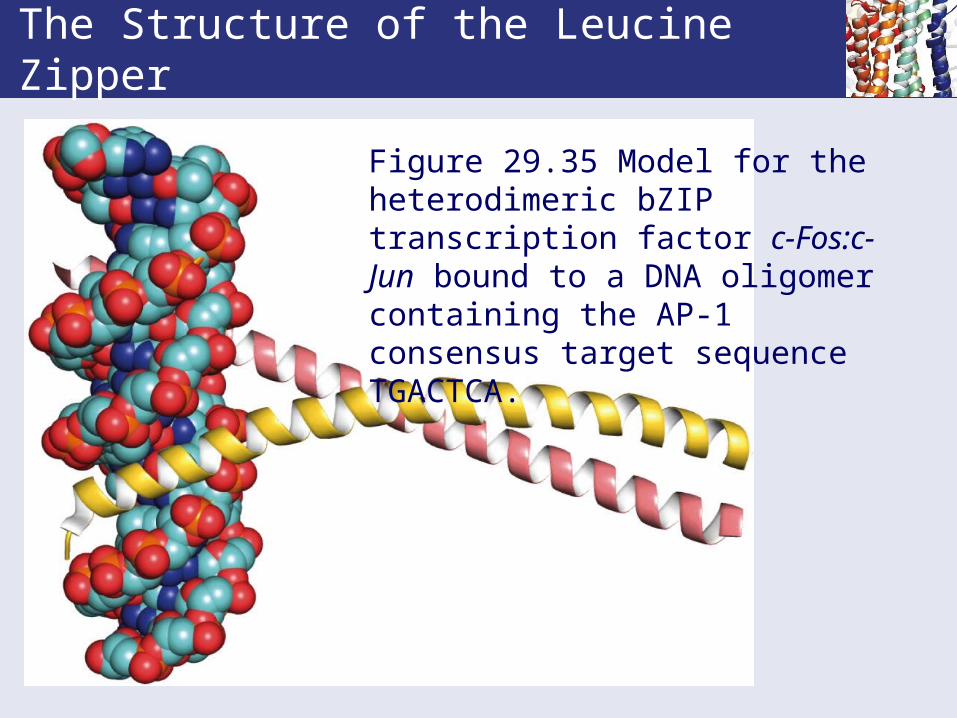
The Structure of the Leucine Zipper
Figure 29.35 Model for the heterodimeric bZIP transcription factor c-Fos:c-Jun bound to a DNA oligomer containing the AP-1 consensus target sequence TGACTCA.

29.5 How Are Eukaryotic Transcripts Processed and Delivered to the Ribosomes for Translation?
• In prokaryotes, transcription and translation are concomitant processes.
• In eukaryotes, the two processes are spatially separated: transcription occurs on DNA in the nucleus, and translation occurs on ribosomes in the cytoplasm.
• Thus, transcripts must be transported from the nucleus to the cytosol to be translated.
• On the way, these transcripts undergo processing.• Alterations that convert the newly synthesized
RNAs (primary transcripts) into mature mRNAs.• And unlike prokaryotes, eukaryotic mRNAs encode
only one polypeptide; i.e., they are monocistronic.

Eukaryotic Genes are Split Genes
• Split genes refer to the fact that parts of the primary transcript are not translated.
• Introns are intervening sequences between exons which are expressed sequences.
• Examples: actin gene has 309-bp intron between first three amino acids and the other 350 or so.
• But chicken pro α-2 collagen gene is 40-kbp long, with 51 exons of only 5 kbp total.
• In these cases, the exons range in size from 45 to 249 bases.
• The mechanism by which introns are excised and exons are spliced together is complex and must be precise.

Eukaryotic Genes are Split Genes
Figure 29.36 The organization of split eukaryotic genes.

Eukaryotic Genes are Split Genes
Figure 29.37 The organization of the mammalian gene for dihydrofolate reductase (DHRF) in three species. Note that the exons are much shorter than the introns and that the exon pattern is more highly conserved than the intron pattern.

Eucaryotic mRNA Processing
• Post transcriptional processing involves several events.• 5' Capping• 5'-end Methylation • 3' Polyadenylation• Splicing (removing introns)
• The primary transcripts called heterogeneous nuclear RNA (hnRNA) or pre-mRNA do not leave the nucleus.
• These are capped by addition of a guanylyl group. • This occurs before the transcript has 20 residues.
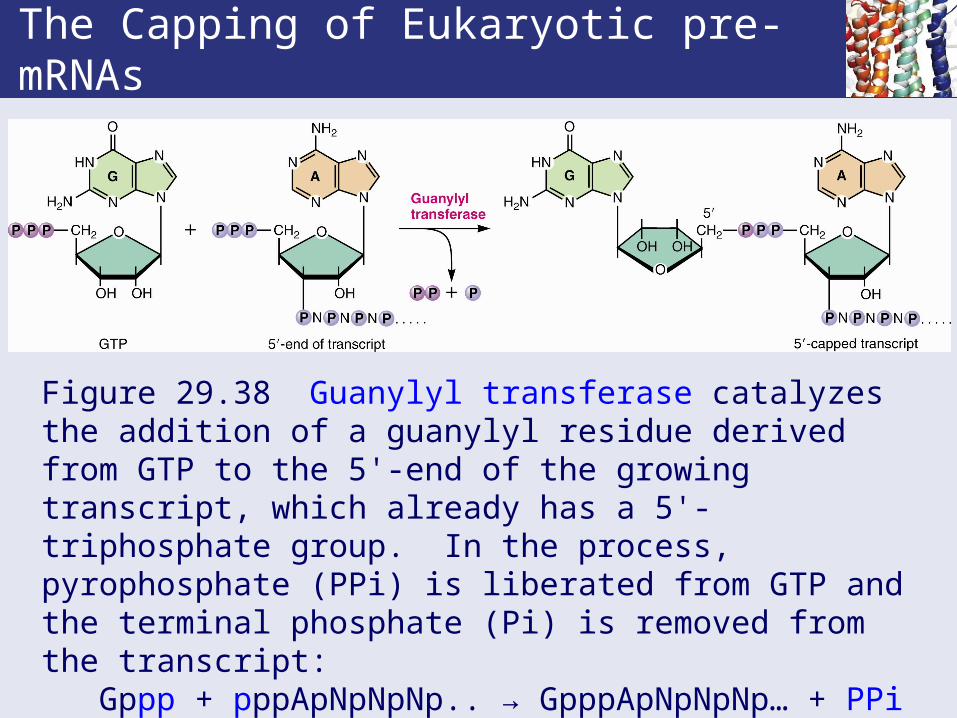
The Capping of Eukaryotic pre-mRNAs
Figure 29.38 Guanylyl transferase catalyzes the addition of a guanylyl residue derived from GTP to the 5'-end of the growing transcript, which already has a 5'-triphosphate group. In the process, pyrophosphate (PPi) is liberated from GTP and the terminal phosphate (Pi) is removed from the transcript: Gppp + pppApNpNpNp.. → GpppApNpNpNp… + PPi + Pi(A is often the initial nucleotide in the primary transcript.)

• The reaction is catalyzed by guanylyl transferase.• The newly attached Cap (G residue) is then
methylated at the N7-position using SAM. • Additional methylations at 2'-O positions of next
two residues and at 6-amino of the first adenine provide several capping arrangements.
• 5' Cap functions: • protect the end from exonuclease activity.• defines the translation start site.• needed to bind at 40S ribosome.
Eucaryotic mRNA Processing
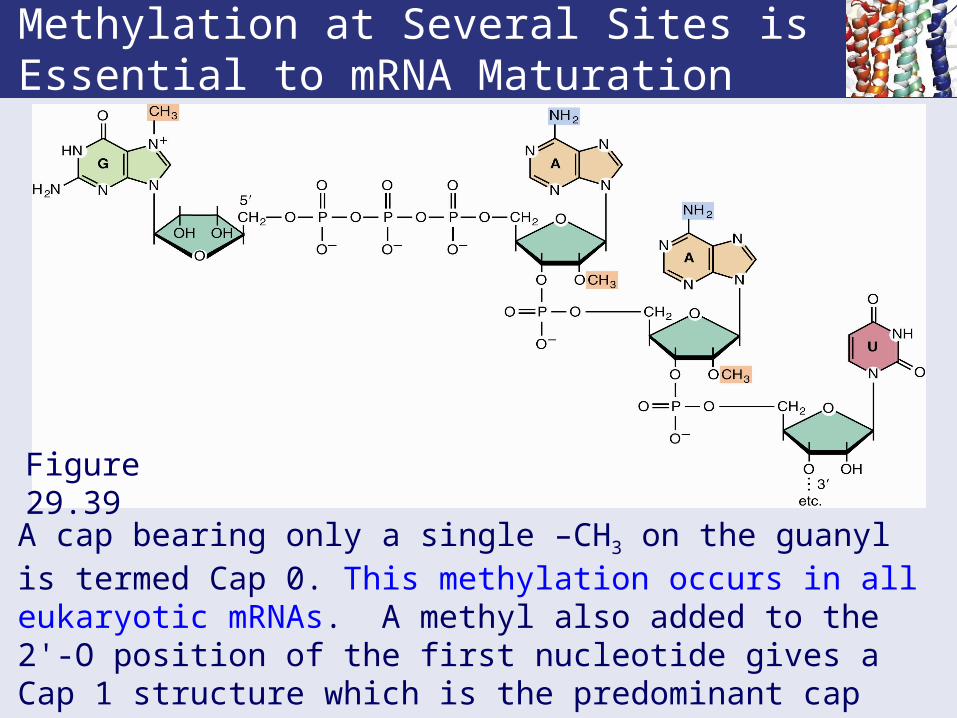
Methylation at Several Sites is Essential to mRNA Maturation
Figure 29.39
A cap bearing only a single –CH3 on the guanyl is termed Cap 0. This methylation occurs in all eukaryotic mRNAs. A methyl also added to the 2'-O position of the first nucleotide gives a Cap 1 structure which is the predominant cap form in all multicellular eukaryotes. A methyl likewise added next residue gives Cap 2.

3'-Polyadenylylation of Eukaryotic mRNAs
• Termination of transcription occurs only after RNA polymerase has transcribed past a consensus sequence (AAUAAA) called the poly(A) addition site but it is not where addition actually occurs.
• 10-35 nucleotides past this site, cleavage occurs (requires CPSF and cleavage factors, CFs) and then a string of about 200 adenine residues are added to the new 3'end of the pre-mRNA transcript (the poly(A) tail).
• Poly(A) polymerase (PAP) adds these A residues. It does not require a primer.
• Poly(A) tail enhances mRNA stability and may assist in transport out of the nucleus.

Figure 29.40 Poly (A) addition to the 3'-ends of transcripts occurs 10 to 35 nucleotides downstream from a consensus AAUAAA sequence, defined as the polyadenylylation signal. CPSF (cleavage and polyadenylylation specificity factor) binds to this signal sequence and mediates looping of the 3'-end of the transcript through interactions with a G/U-rich sequence even further downstream.
Poly(A) Addition

Nuclear Pre-mRNA Splicing
• Within the nucleus, hnRNA associates with a characteristic nuclear proteins to form ribonucleoprotein particles (RNPs).
• These nuclear proteins maintain the hnRNA in an untangled and accessible conformation.
• The substrate for splicing, that is, intron excision and exon ligation, is the capped, polyadenylated primary transcript emerging from the RNA polymerase II transcriptional apparatus.
• Splicing occurs exclusively in the nucleus.• Consensus sequences define the exon/intron
junctions in eukaryotic mRNA precursors.

Splicing of Pre-mRNA
Capped, polyadenylated RNA, in the form of a RNP complex, is the substrate for splicing
• In "splicing", the introns are excised and the exons are ligated to form mature mRNA.
• The 5'-end of an intron in higher eukaryotes is always GU and the 3'-end is always AG.
• All introns have a "branch site" 18 to 40 nucleotides upstream from 3'-splice site.
• The branch site is essential to splicing.

• 5'-Splice Site Consensus:
- - A G - G U A A G U - - -
exon intron
• 3'-Splice Site Consensus:
Py Py Py Py Py Py Py Py C A G - G ---
intron exon
• Branch site weakly conserved sequence:
Py N Py Pu A Py
Figure 29.41 Consensus Sequences at the Splice Sites in Vertebrate Genes

The Splicing Reaction Proceeds via Formation of a Lariat Intermediate
• Figure 29.42 shows the splicing mechanism.• The branch site is usually YNYRAY, where Y =
pyrimidine, R = purine and N is any residue.• A lariat, a covalently closed loop of RNA, is
formed by attachment of the 5'-P of the intron's invariant 5'-G to the 2'-OH at the branch A site.
• The exons then join, excising the lariat.• The lariat is unstable; the 2'-5' phosphodiester is
quickly cleaved and the intron is degraded in the nucleus.

The Splicing Reaction Proceeds via Formation of a Lariat Intermediate
Figure 29.42 Splicing of mRNA precursors. A representative precursor mRNA is depicted. Exon 1 and Exon 2 indicate two exons separated by an intervening sequence (an intron) showing consensus 5', 3', and branch sites.

Splicing Depends on snRNPs
• Splicing uses a unique set of small nuclear ribonucleoprotein particles - snRNPs, (= "snurps").
• An snRNP consists of a small RNA (snRNA) which is ~100-200 bases long together with about 10 different proteins. snRNAs have a 2,2,7-trimethylG-ppp-N- Cap2 structure.
• Some of the 10 proteins are general for all snRNPs and some are specific for given snRNPs.
• Major snRNP species are abundant, with more than 100,000 copies per nucleus.
• snRNPs and pre-mRNA form the spliceosome.

Splicing pre-mRNA uses snRNPs
snRNP U3 is involved with eucaryotic rRNA processing.

snRNPs Form the Spliceosome
• Splicing occurs when the various snRNPs come together with the pre-mRNA to form a multicomponent complex called the spliceosome.
• The spliceosome is a large complex, about the size of a ribosome; its assembly requires ATP.
• snRNPs: U1 binds at the 5'-splice site, U5 at the 3'-splice site and U2 binds at the branch site.
• Interaction between the snRNPs brings 5'- and 3'- splice sites together so lariat can form and exon ligation can occur.
• Spliceosome assembly requires ATP-dependent RNA rearrangements catalyzed by spliceosomal DEAD-box ATPases/helicases.
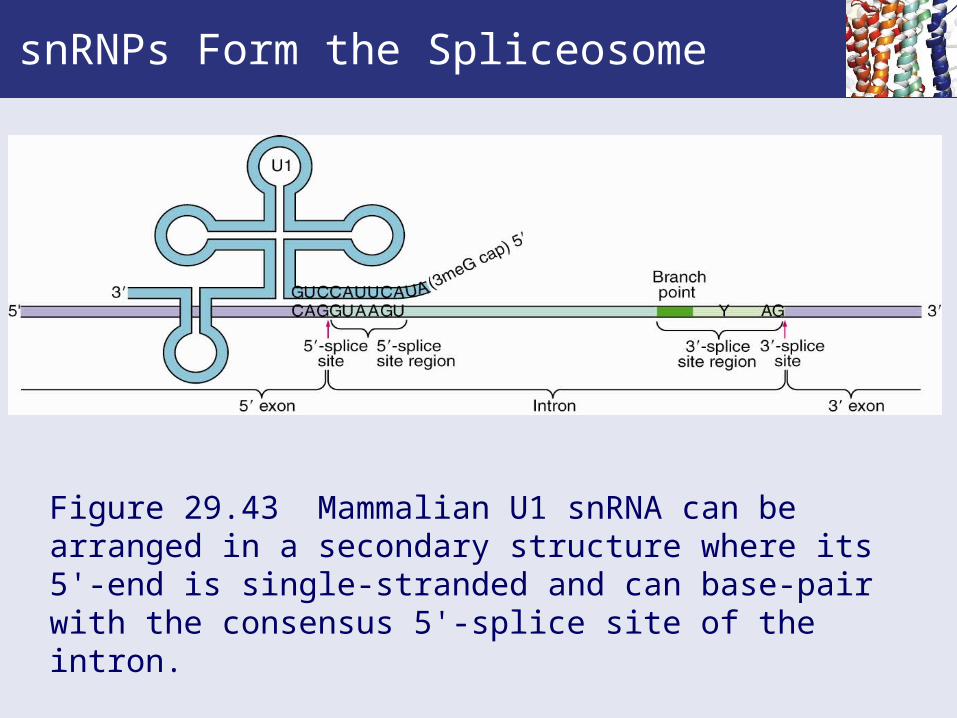
snRNPs Form the Spliceosome
Figure 29.43 Mammalian U1 snRNA can be arranged in a secondary structure where its 5'-end is single-stranded and can base-pair with the consensus 5'-splice site of the intron.
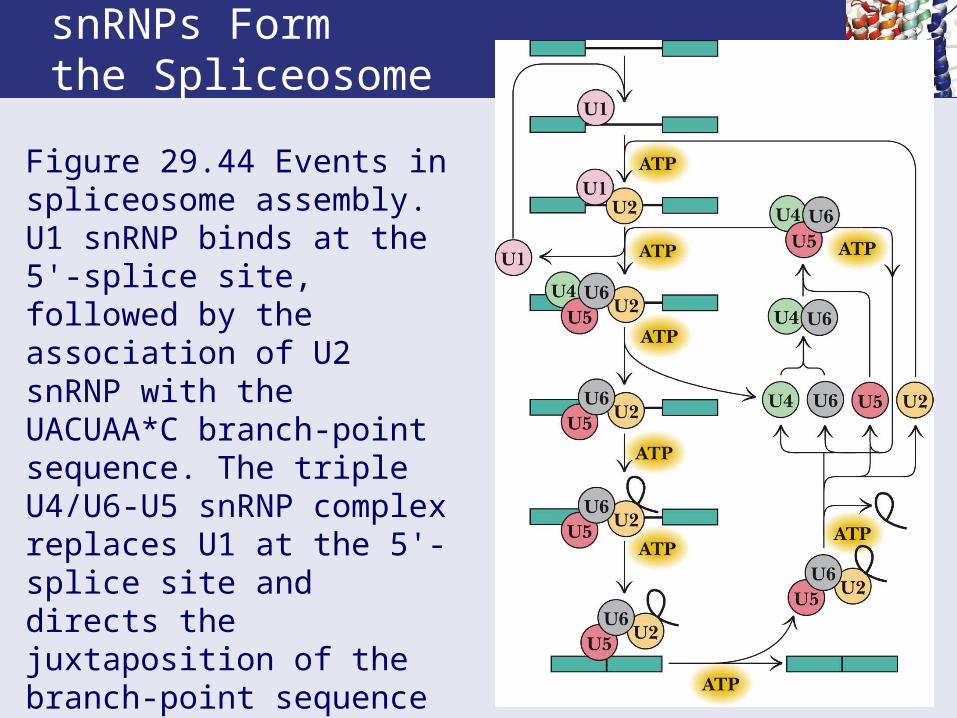
snRNPs Form the Spliceosome
Figure 29.44 Events in spliceosome assembly. U1 snRNP binds at the 5'-splice site, followed by the association of U2 snRNP with the UACUAA*C branch-point sequence. The triple U4/U6-U5 snRNP complex replaces U1 at the 5'-splice site and directs the juxtaposition of the branch-point sequence with the 5'-splice site, whereupon U4 snRNP is released.

Alternative RNA Splicing Creates Protein Isoforms
• In constitutive splicing, every intron is removed and every exon is incorporated into the mature RNA.
• This produces a single form of mature mRNA from the primary transcript.
• However, many eukaryotic genes can give rise to multiple forms of mature RNA transcripts.
• This may occur by:• Use of different promoters.• Selection of different polyadenylylation sites.• Alternative splicing of the primary transcript, or• A combination of these three mechanisms.

Alternative RNA Splicing Creates Protein Isoforms• Different transcripts from a single gene generate a
set of related polypeptides, termed protein isoforms, each with a slightly altered function.
• The isoforms of fast skeletal muscle troponin T are an example of alternative splicing.
• This gene consists of 18 exons, 11 of which are found in all mature mRNAs and are constitutive.
• Five of the exons (4 through 8) are combinatorial, in that they may be included or excluded.
• Two (16 and 17) are mutually exclusive – one is always present but never both.
• 64 different mature mRNAs can be formed from this gene by alternative splicing.

Alternative RNA Splicing Creates Protein Isoforms
Figure 29.45 Organization of the fast skeletal muscle troponin T gene and the 64 possible mRNAs that can be generated from it. Exons are constitutive (yellow), combinatorial (green), or mutually exclusive (blue or orange).

RNA Editing: Another Way To Increase the Diversity of Genetic Information
• RNA editing is a process that changes one or more nucleotides in an RNA transcript by deaminating a base, either A→I or C→U.
• These changes alter the coding possibilities in a transcript, because I will pair with G (not U as A does) and U will pair with A (not G as C does).
• RNA editing can increase protein diversity by:
(1) Changing amino acid coding possibilities.
(2) Introducing premature stop codons.
(3) Changing splice site in a transcript.

• Both procaryotic and eucaryotic tRNA and rRNA are made from primary transcripts.
• 35-40% of the 75-80 bases in tRNA are modified by methylation, hydrogenation, carboxymethylation, changing U to pseudoU and others.
• Transcripts are then cut: RNaseP cleaves the 5'end and another endonuclease cleaves the 3'end. Some will have excision from the anticodon loop.
• RNaseD then trims the 3'end and tRNA nucleotidyl transferase adds CCA to the 3 end which requires two CTP and one ATP.
Pre-tRNA

• Primary transcripts of procaryotic rRNA contain one copy each of pre-16S, 23S and 5S RNAs as well as several pre-tRNAs.
• Initial cleavage of the primary transcript is done by endonuclease RNase III.
• Trimming the ends of the pre-16S, 23S and 5S RNAs is performed by endonucleases M16, M23 and M5, respectively.
Procaryotic Pre-rRNA

Cleavage Sites for Procaryotic Pre-rRNA

End Chapter 29Transcription and the Regulation of
Gene Expression


















