
Chandrakant Patel, Ratnesh Sharma, Cullen Bash, Sven Graupner HP Laboratories Palo Alto Energy Aware...
21
Chandrakant Patel, Ratnesh Sharma, Cullen Bash, Sven Graupner HP Laboratories Palo Alto Energy Aware Grid: Global Workload Placement based on Energy Efficiency
-
Upload
annabel-green -
Category
Documents
-
view
214 -
download
0
Transcript of Chandrakant Patel, Ratnesh Sharma, Cullen Bash, Sven Graupner HP Laboratories Palo Alto Energy Aware...

Chandrakant Patel, Ratnesh Sharma, Cullen Bash, Sven Graupner
HP Laboratories Palo Alto
Energy Aware Grid: Global Workload Placement based on Energy Efficiency

Grid Computing
• New paradigm in distributed and pervasive computing for scientific as well as commercial applications.
• Based on coordinated resource sharing and problem solving in dynamic, multi institutional virtual organizations.

Energy Aware Grid
• Objective:– Build an energy aware grid.
• Problem:– Thermal and energy management issues due to aggregation of
computing, networking and storage hardware.
• Solution:– Data center energy efficiency coefficients: Workload placement
decisions will be made across the Grid, based on these coefficients.
– Provide a global utility infrastructure explicitly incorporating energy efficiency and thermal management among data centers.

Cooling Issues
• Example :– A data center, with 1000 racks, approximately 25,000
square feet.– Requires 10 MW of power for the computing
infrastructure.– An additional 5 MW would be required to remove the
dissipated heat.– At $100/MWh, cooling would cost $4 million per
annum.

Data Center thermo-mechanical architecture
• Rows of racks with multiple air-cooled hardware.
• Presence of multiple air-conditioning units.
• Higher airflow rates required due to “slim servers” and “blade servers”.

Problems in Data Center Cooling:
• Cooling at Chip Level– 10% of total power
• Cooling at Data Center Level– 50% of the total power
• Additional thermodynamic work for cooling.
• Non-uniform temperature and airflow patterns.
• The data center has no well defined boundaries.– No control mechanism to dissipate
high heat loads.

Contributions of the paper
• Propose an energy-aware co-allocator that redistributes computing within the global network of data centers.
• Examine the methods for evaluating energy efficiency and thermal management parameters applicable to any data center cooling infrastructure.

Globus resource managementarchitecture Ian Foster, Carl Kesselman :The Grid , Blueprint for a New Computing Infrastructure, 1999.

• RSL (Resource Specification Language) – Application specifies resource needs.
• Broker Infrastructure– Resolving higher-ordered RSL specifications into elementary,
ground resource specifications.
• Ground RSL specification – List of physical resources (machines, storage units, devices)
needed to perform a computation.
• GRAMs (Globus Resource Allocation Managers)– Allocates RSL ground resources from its resource pool for a
scheduled time period.– Assigns them to a specific computation.
• GIS– information about resources and their availability.

Energy Aware Co-Allocator
• Has information about a data center– Resource Types – machines, OS etc.– Capacity of the resources.– Schedules of allocations and reservations.– The energy efficiency coefficient of the data center.
• Represents the energy cost when placing a workload in a particular data center.
• Data Center selection process– Co-allocator will choose one or more GRAMs– Necessary Conditions -
• Functional: Appropriate types of resources available.• Quantitative: Sufficient amounts of resources available.• Schedule: Sufficient amounts of resource instances.• Constraints: Restrictions, if provided by the application.

Energy Efficiency Coefficient ( )• A composite indicator of energy efficiency and thermal
management of a data center.
• Factors which affect the coefficient– Low condenser temperature.– Relative humidity (RH).– Cooling load.– Using ground as a heat sink.– Local Thermal Management.
• The efficiency coefficient of ith data center is given by
χ i =ξ i ⋅COPi
– ξ is a factor of the Local Thermal Management.– COP is the Coefficient of Performance, based on the condenser
temperature.

Vapor Condensation Mechanism
• Heat extraction system in a data center is based on a variation of reverse power cycle (also known as vapor compression cycle).
• Efficiency (η)
• Pressure (P)- enthalpy (h) diagram for a vapor compression cycle – Heat addition in the evaporator (C-D)
– Work input at the compressor (D-A)
– Heat rejection at the condenser (A-B)

Coefficient of Performance
• COP – Coefficient of Performance– the ratio of desired output (i.e. heat
extracted from the data center, Qevap) over the work input (i.e. Wc).
• Lower condenser temperature improves coefficient of performance of cooling system.
• Heat can only be rejected to the ambient surroundings over a negative temperature gradient.
• Workload placement in data centers located in regions with higher ambient temperatures can increase the energy consumption per unit workload.

Example
• Comparison of temperatures of New Delhi and Phoenix.
• Calculate the COP– Delhi – 3.32– Phoenix – 7.61
• Workload placement in New Delhi will be 56% more energy intensive than that in Phoenix.
• Energy-Aware Grid: Workload placement should be carried out based on lowest available heat rejection temperature.

Relative Humidity
• Cooling of data center supply air also depends on the humidity.
• Energy-Aware Grid: Workload placement should avoid the potential disadvantages associated with high ambient humidity conditions.
• Regions with low seasonal humidity and ambient temperature can directly utilize outside air to provide cooling.

Cooling Load
• COP of cooling systems varies with load.
• COP can deteriorate by 20%, if the load drops to 50% of rated capacity.
• Energy-Aware Grid : Workload placements across data centers should strive to maintain optimum load levels for highest possible coefficient of performance.

Using ground as a heat sink
• Higher COP at a slightly higher initial cost.
• Temperature variation is barely observable below a depth of 1 m.
• Heat from the condenser is rejected to the ground– Underground piping with water/glycol.
• Energy- Aware Grid: Aware of efficiency of these systems for prospective workload placement during adverse ambient conditions.

Local Thermal Management
• Prevent local hot-spots by proper arrangement of rack and unit layouts.
• Depends on the data center infrastructure.• Propose a data center-level thermal multiplier
– Account for the ability of the data center infrastructure to cope with new workload placement.
– Tref : air supply temperature to the data center.
– SHI: denotes effect of hot air infiltration at the inlet to server or rack.
• Higher ξ indicates a greater potential for vulnerability.
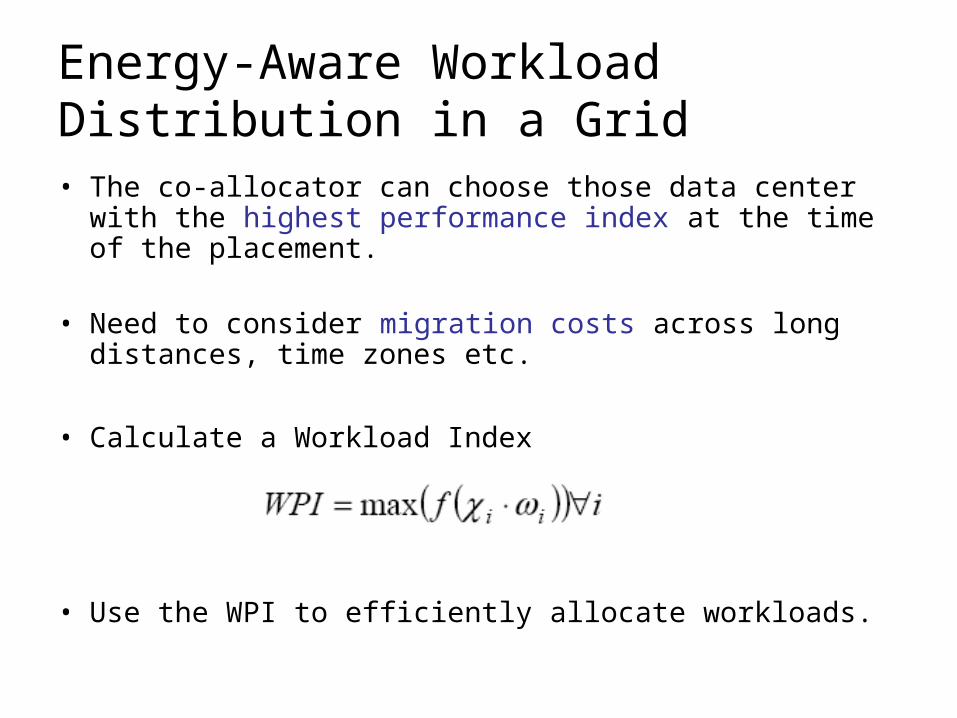
Energy-Aware Workload Distribution in a Grid• The co-allocator can choose those data center with the
highest performance index at the time of the placement.
• Need to consider migration costs across long distances, time zones etc.
• Calculate a Workload Index
• Use the WPI to efficiently allocate workloads.
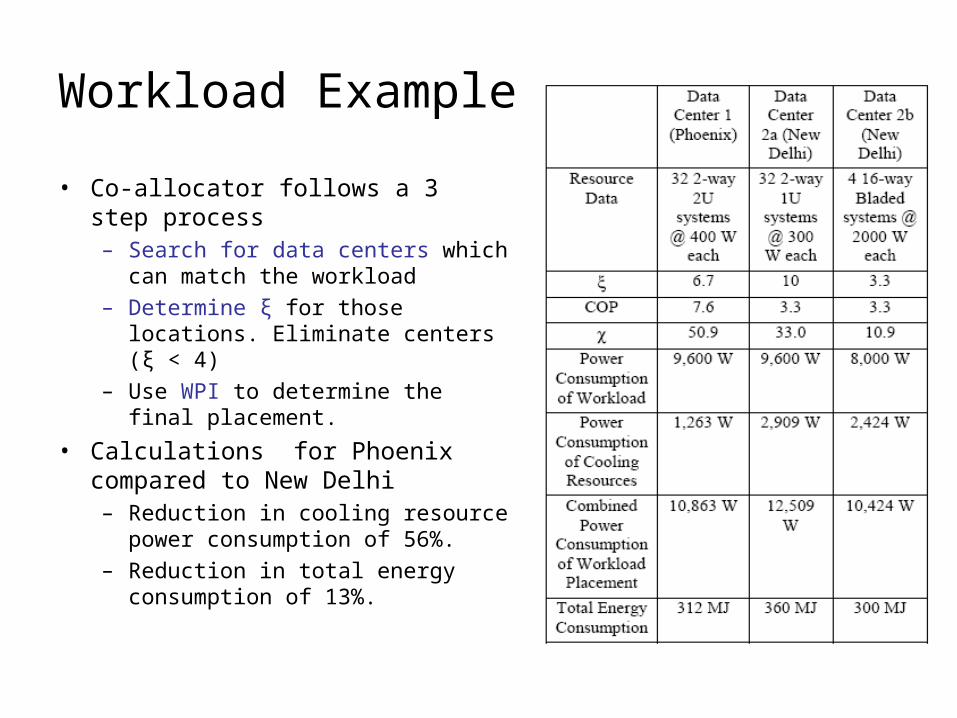
Workload Example
• Co-allocator follows a 3 step process– Search for data centers which can
match the workload
– Determine ξ for those locations. Eliminate centers (ξ < 4)
– Use WPI to determine the final placement.
• Calculations for Phoenix compared to New Delhi– Reduction in cooling resource
power consumption of 56%.
– Reduction in total energy consumption of 13%.

Conclusion
• Energy-Aware policy for distributing computational workload in the Grid resource management architecture.
• Data center energy coefficient.


















